A Comprehensive Guide to Machine Learning

Now that we’ve pushed through both generalities of Machine Learning, its basic concepts, and how they apply to areas of marketing, it’s time to dive into the specifics of how companies are using these processes. We’ll look at a number of examples of how major companies are using Machine Learning to interact and deliver content to customers in an increasingly targeted and personalized way. We’ll also look at how some marketing companies are using this technology to increase their insights and their clients’ ROI.
This use case is one that Target’s PR department probably didn’t cook up. The story went viral and was the first experience that many people outside the marketing and advertising spaces had with the way major retailers were using Machine Learning to target their customers.
Target assigns all their customers Guest ID numbers tied to their credit card, name, and email address. Further, they use customer rewards products such as their Red Card and Cartwheel to gain even more data points to tie to these Guest IDs.
In this case, Target used the data from women who had signed up for their baby registry. They looked at the historical purchases to see what the data profile for a pregnant customer looked like. Going back to our Machine Learning terminology, they likely used a variation of a Naive Bayes to create a classification for the group.
Next, Target sent this classified group coupons for baby items. The recipients included a teenage girl whose father was unaware of her pregnancy. The coupon likely wasn’t the way the girl wanted her father to find out about her expected child or the way Target wanted the world to find out about its customer targeting. However, this story is an interesting and practical example revealing how retailers are collecting, learning about, and using data points.
Adobe’s Marketing Cloud puts several tools in the hands of marketers that can help them immediately put Machine Learning to work.
The Adobe Audience Manager allows users to centralize all of their customers’ data into a data management platform. From this platform, they can create distinct customer profiles and unified audience segments. Understanding audiences and segments allows Adobe’s customers to tailor content specifically for these consumers in their Experience Cloud products. Beyond delivering a targeted message, the tools in Adobe’s products allow you to find the segments in your customer base that have the highest yield and focus your effort and spend on those targets, thus maximizing your ROI.
Adobe has also brought about Virtual Analyst, powered by an artificial intelligence (AI) interface with its Adobe Sensei product. Virtual Analyst continually processes data and uses predictive algorithms and Machine Learning to drill into specifics of your business operations. Virtual Analyst is like the real-life data scientist working with you in your company. Adobe reports several benefits to customers using Virtual Analyst: increased revenues, major cost savings, mitigated risks, and bug detection.
Facebook wanted to understand more about the text content its users were sharing so the social media giant built DeepText. This reinforced learning platform helps users to make sense of the context of content and allows Facebook to filter spam and bring quality content to the surface. Of course, DeepText also has implications on ad segmentation and delivery.
The DeepText system is a deep neural network that uses FBLearner Flow for model training. The trained models go into the FBLearner Predictor platform. The scalable model allows constant model iterations for DeepText.
To understand the scale of DeepText, keep in mind that Facebook has 1.86 billion monthly active users. This user base is worldwide, and thus DeepText must have an understanding of many languages. The level of understanding goes beyond basic Natural Language Processing. Instead, the goal of DeepText is to have an understanding of the context and intent of the content, not simply what the content says only.
DeepText achieves contextual understanding by using a mathematical concept called “word embeddings.” This practice preserves the semantic relationship among various words. With this model, DeepText can see that “bae” (a term of endearment) and girlfriend are in a close space. Word embeddings also allows for terms across languages to have similarities aligned.
One practical use of DeepText can be found in the Messenger application. The Messenger app uses AI to figure out if someone is messaging someone with the intent to get a ride from a taxi somewhere. If Messenger recognizes this request, it offers up the options to “request a ride” from a ride-sharing application.
Future use cases that Facebook has floated include the ability for the system to understand when users want to sell products they’ve posted and offer them tools to help with the transaction. DeepText could also be helpful for bringing to the surface high-quality comments on posts by celebrities and other large threads.
With it’s new focus on improving the news feed, you can see where Facebook could deploy DeepText to help flag issues such as fake news at scale.
Additionally, Facebook is using AI to create chatbots that talk like humans. To do so, the social networking giant has developed a free software toolkit that people can download to help Facebook compile data, view research, and interact with others participating in the projects. The objective is to get computers to understand human conversations without failing; to do that, individuals can provide computers with real conversations and language used online to teach them. For example, information from Reddit discussions about films can train computers to converse with humans about movies.
Clarifai is an image and video recognition company based in New York. The firm has raised $40 million over two rounds from Menlo and Union Square Ventures to build a system that helps its customers detect nearduplicate images in large uncategorized repositories.
Clarifai’s technology can be used through one of the e-commerce examples we discussed in Chapter 3. The company’s “Apparel” model, which is in beta, claims to be able to recognize over 100 fashion-related concepts including clothing and accessories. Further, the company’s “Logo” model can be used by companies looking for a social listening tool for Snapchat and Instagram.
Clarifai’s “Demographics” model offers an interesting opportunity for marketers as well. The company is able to analyze images and return information on the age, gender, and multicultural appearance for each face detected. The opportunities for advertisers to target specific demographics in an increasingly visual internet landscape , where there is less text content to inform the intent, are arriving at the perfect time.
And just when you thought what Clarifai was doing was cool in itself, the company also allows customers to “train” their own model.
Sailthru is another New York–based company building solutions around Machine Learning. Their solution focuses around promotional emails. Sailthru’s system learns about customers’ interests and buying habits and generates a classification based on the information. This classifier tells the system how to craft the message and when to send the message to optimize performance.
One Sailthru customer. The Clymb, saw a 71% increase in total email revenue and 72% decrease in customer churn.
Sailthru also offers prediction and retention models that allow companies to be able to anticipate customers’ actions. After turning on these models, The Clymb saw a 175 percent increase in revenue per thousand emails sent and a 72 percent reduction in customer churn.
Netflix is incredibly transparent about how it has used Machine Learning to optimize its business. The most obvious place that you can see the effects of their use of Machine Learning is on the Netflix homepage. Netflix personalizes its homepage for every user.
One of the issues Netflix faces with its homepage is the sheer amount of content and products from which it chooses. The homepage has to not only pull content that the user is likely to want to the surface, but it also has to serve that content as a doorway to other content that the user may find interesting.
Netflix uses a series of videos grouped in rows. The company can group these rows by basic metadata such as genre. However, Netflix also creates rows based on personalized information, such as TV shows, that are similar to other shows the user has watched.
This system that Netflix uses is a great example of graph analysis. Netflix is able to examine the connection between various data points and recommend content based on the “edges” between the points. As an example, “The Rock” could be one edge that connects “The Fast and the Furious” movies with “The Scorpion King.”
Concepts such as Naive Bayes and logistic regression are likely used to help create profiles and match those profiles with the outputs from the content graph analysis. Naive Bayes would help classify groups of users by their behaviors, and the logistic regression would qualify whether that group should be served each type of content. For example, if a user is watching mostly content focused on preschoolers, Netflix knows not to serve horror movies as a suggestion.
On top of these two types of Machine Learning, with independent focus points on content and user behavior, Netflix also conducts A/B tests on the layout of the homepage itself. Historically, Netflix had displayed rows such as “Popular on Netflix,” but the company realized that this arrangement was not personalized for every user. In our example above of the preschool Netflix user, getting recommendations for the new season of “Orange Is the New Black” because the show is popular doesn’t make much sense for this audience. However, showing this user content grouped in rows by their favorite children’s entertainment characters would make logical sense.
Identifying who is truly leading the field in terms of success in SEO is still not an exact science. While you can easily view something such as a content marketing campaign and grade a company on its efforts in this area, SEO by its nature is more like a black box.
As such, iPullRank set out to create a view of the Inc 500 companies and their overall and market-level organic search performance. This study intended to predict a site’s performance in SEO from relevant link factors from Ahrefs, cognitiveSEO, Majestic, and Moz.
The data collection involved the following:
1. Scraping the Inc 500 list from the company’s site
2. Pooling the 100 winners and 100 losers from Searchmetrics
3. Establishing the URLs from each company
4. Pulling all the available domain-level metrics from Moz, SEMrush, Searchmetrics, Majestic, and Ahrefs.
5. Placing the 700 domains into cognitiveSEO
6. Using cognitiveSEO’s Unnatural Links Classifier
Next, iPullRank reviewed 116 features for every domain and used logistic regression, cross validation, random forest, and lasso to analyze the data.
From here, we collected two sets of training data. We used the 100 SEO winners and 100 SEO losers from Searchmetrics for our 2014 and 2015 Inc 500 data pulls, respectively. We then used the training data from 2014 to select the model. With the 2015 training data, we updated coefficients with the chosen model.
The sample size for 2014 training data was relatively small, and we knew that any statistical models would be sensitive to the data points selected as the training data set. We used 5-fold cross validation to choose the model, solve the sample size data, and reduce variance of the model.
We used several Machine Learning methods to select variables, including random forest and lasso. In the end, we selected eight factors in the final logistic regression model which are believed to influence the overall performance of a webpage. These eight important factors are as follows:
| Variable Name | Metric Provider | Metric Provider Description |
|---|---|---|
| umrr | Moz | The raw (zero to one, linearly-scaled) MozRank of the target URL |
| refclass_c | Ahrefs | Number of referring class C networks that link to the target |
| CitationFlow | Majestic | A score helps to measure the link equity or “power” the website or links carrie |
| TopicalTrustFlow_ Value_2 | Majestic | The Number shows the rlative influence of a web page, subdomain or root domain in any given topic or category |
| Rank | SEMrush | Site rank on Google |
| Unnatural.Links | CognitiveSEO | Number of unnatural links |
| OK.Links | CognitiveSEO | Number of OK links |
| fspsc | Moz | Spam score for the page’s subdomain |
Before predicting winners and losers for the 2015 Inc 500 companies, we used median imputation to handle missing values. Then we updated the final model coefficients with 2015 training data. The prediction results are plotted below:
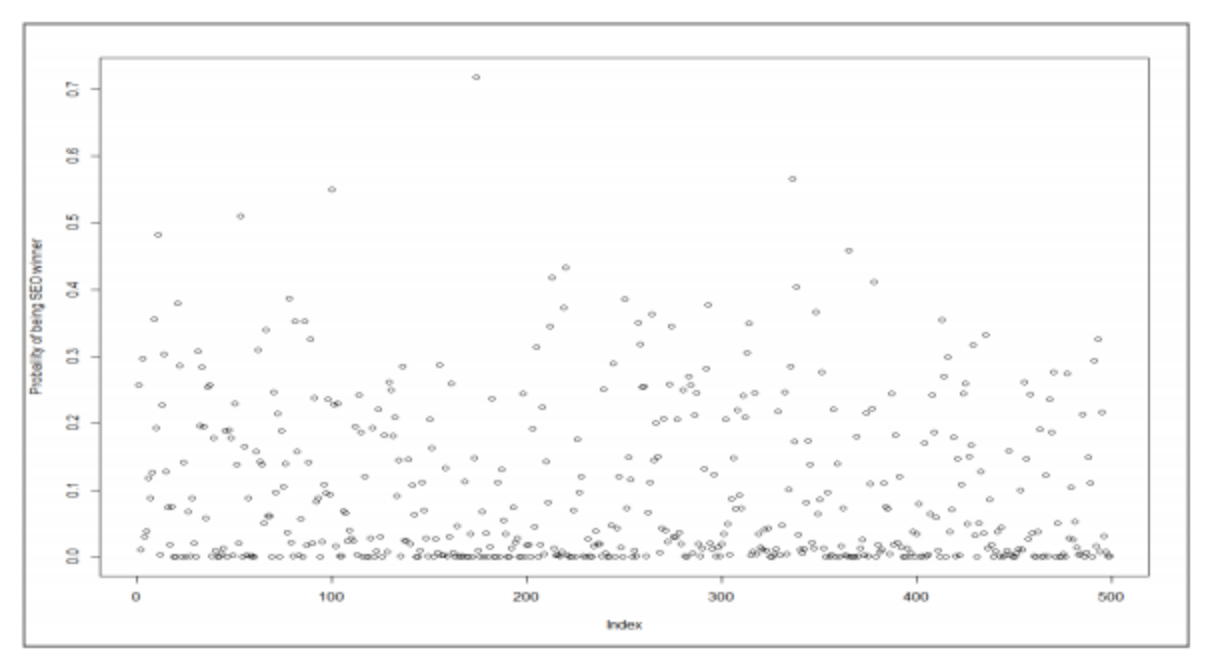
We noticed that most companies registered predictions as losers (probability < 0.5) based on these plot points. This result follows from the huge difference in the distribution of the 2015 training data set and 2015 Inc 500 company data. Put simply, the SEO winners and losers we used for training data are often more advanced in their SEO strategies and techniques than the standard Inc 500 company. Therefore, we came up with the alternative to grade each company based on the relative performance within Inc 500 companies.
The lower score between the above two methods was used to better identify underperforming com- panies from an SEO perspective. Overall performance using predicted probability of being a SEO winner gets decided by the following rules:
| A | Top 10% |
| B | Top 10% – 25% |
| C | Top 25% – 45% |
| D | Top 45% – 65% |
| E | Top 65% |
We found that 2015 Inc 500 companies had better organic search performance than 2014 Inc 500 companies in terms of spam score, trust metrics, link popularity, visibility, and unnatural links. In general, however, most Inc 500 companies have high grades in spam scores and unnatural links, but have poor link popularity and low trust metrics. This finding shows a general lack of off-site SEO and content marketing strategy by the group as a whole.
Below are the number of companies being assigned to each grade for 2014 and 2015, respectively:
| Grade | 2014 Inc.500 | 2015 Inc.500 |
|---|---|---|
| A | 34 | 47 |
| B | 63 | 76 |
| C | 54 | 102 |
| D | 127 | 91 |
| E | 222 | 183 |