
Vector Embeddings is All You Need: SEO Use Cases for Vectorizing the Web with Screaming Frog
Since learning of the importance and magnitude of vector embeddings, I have been proposing that a link index should vectorize the web and make those

Since learning of the importance and magnitude of vector embeddings, I have been proposing that a link index should vectorize the web and make those

WEBINAR REPLAY: AI Content for SEO – WATCH One of the biggest predictions in the marketing world for 2023 was an increase in the use

Are you helping Google surface your products to your potential customers? The search engine has developed a wide range of new opportunities for e-commerce brands

Have you ever worked on a site with a million pages? At that scale, Googlebot doesn’t always crawl every page, let alone index them. With
In November 2021, Google announced that it will roll out its desktop version of the Page Experience Update between February and March 2022. This implies
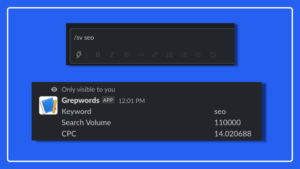
Continuing with our GrepWords API webinar series, we know there are those scenarios where you’re discussing SEO strategy with a team member and a keyword
The SEO world depends on search volume to inform their strategy, but is the data out there reliable? The truth is, search volume should be
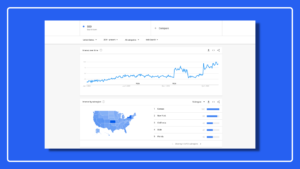
The 20 percent of keywords driving 80 percent of your sales… Will they continue to be profitable, or will they become a money pit leading

Pivot tables are one of Excel’s best and most powerful tools. Very often, beginners may find them to be intimidating and difficult to create based

Many users have heard of the VLOOKUP function for Excel but aren’t clear about what it does. Others might just need a refresher. Either way,

The Basics of Smart Speaker Assistants Even if you don’t own one yourself, you’ve probably encountered smart speaker devices. These nifty little pieces of tech

What is Firebase? “Firebase is a mobile and web application platform with tools and infrastructure designed to help developers build high-quality apps.” —- Wikipedia. So





