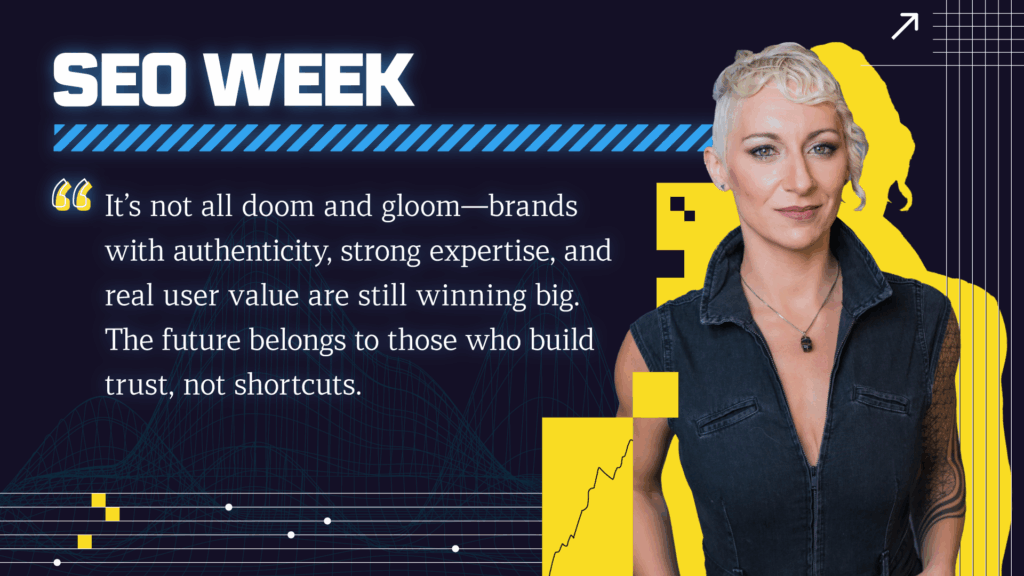
Dr. Krishna Madhavan of Microsoft explained how AI is shifting search from static indexing to dynamic, predictive, and outcome-focused experiences. While powered by LLMs and multimodal data, he emphasizes that authenticity, trust, and user value remain at the heart of effective search.
SEO Week 2025 set the bar with four themed days, top-tier speakers, and an unforgettable experience. For 2026, expect even more: more amazing after parties, more activations like AI photo booths, barista-crafted coffee, relaxing massages, and of course, the industry’s best speakers. Don’t miss out. Spots fill fast.

Dr. Krishna Madhavan is a Principal Product Manager at Microsoft AI, Bing, focused on advancing the web data platform and leading the IndexNow initiative to power Copilot and AI-driven search experiences.
With over 25 years in AI/ML, cloud infrastructure, and large-scale systems, he specializes in crawling, indexing, and content understanding.
In his SEO Week presentation, Dr. Krishna Madhavan explores how AI is fundamentally reshaping the nature of search, transforming it into a more conversational, personalized, and action-driven experience. He outlines how LLMs, fueled by the convergence of nanotechnology, cognitive science, biotechnology, and information technology, are shifting search from simply indexing pages to understanding, predicting, and even acting on user intent. Krishna highlights that the future of SEO will be defined by fresh, high-quality content and outcomes rather than rankings and clicks, as AI systems increasingly rely on real-time, user-centered data through technologies like retrieval-augmented generation.
He also touches on the future impact of quantum computing on search and AI performance, while reinforcing that human creativity, trust, and user value remain the true foundation of meaningful search.
Search is becoming agentic and outcome-driven:
AI is transforming search into a dynamic system that predicts, personalizes, and acts on users’ behalf. Success is measured less by clicks and more by how well the system delivers meaningful outcomes.
Authentic, user-centric content matters more than ever:
AI systems reward trust, originality, and helpfulness. Only the most relevant, high-quality content is surfaced, meaning traditional ranking strategies must evolve toward meeting actual user needs.
The convergence of AI, nano, bio, and cognitive sciences is accelerating change:
Innovations in chip technology and LLM design are reshaping SEO. As AI systems become more complex and multimodal, keeping content fresh, accessible, and valuable is key to staying visible.
SEO Week 2025 set the bar with four themed days, top-tier speakers, and an unforgettable experience. For 2026, expect even more: more amazing after parties, more activations like AI photo booths, barista-crafted coffee, relaxing massages, and of course, the industry’s best speakers. Don’t miss out. Spots fill fast.
Dr. Krishna Madhavan: I wish I was able to cover more about the importance of developing appropriate trust with AI systems. This is a really critical topic. I think people are very familiar with hallucinations and some potential harms of AI. But, there are real considerations for ensuring users are not over reliant on AI.

Dr. Krishna Madhavan: There are a number of product announcements that are critical to the SEO space. The pace of these changes is fast as usual. This does not change the framing of my presentation significantly – but, does bring forth the importance of deeper understanding of what AI is all about and how the changes are impacting the user experience.
Mike King: The web data engine behind Bing, Copilot and beyond. He’s a former Purdue professor, NSF career award winner, blending academic rigor with real world impact, and is obsessed with building scalable systems, mentoring future innovators, and probably brewing strong coffee while doing it. Presenting from A to Z, or AI to Z, The Technical Evolution of Search Engines, please welcome Krishna Madhavan.
Dr. Krishna Madhavan: Good morning, everybody. Thank you, Mike, for the great, great talk and for the great introduction. It’s awesome to be here. I’m Krishna Madhavan. I’m from Microsoft. I’m with the Bing team. I’m gonna be making a whole bunch of less profound statements than Mike just made.
And if you find yourself nodding along and saying, yeah, I I know this. I agree with this. This means I’m doing a good job, and, it’s good. If you kind of scratching your head and wondering what it is, I’m still doing a good job, and that’s that’s great too. So I’m gonna start off with a bunch of very profound statements, this morning, and I’m gonna start with this.
Cats rule the Internet. Okay? I have three cats, and it’s a contractual obligation in my household that if I don’t mention cats at least five times in all of my talks, then, it’s a no win situation for me. So they rule the Internet, and so AI and SEO are a distant second. And anybody who knows anything about New York culture will tell you that this is an AI generated image because the Mets fans and the Yankees fans, they don’t really go well together. And by the way, the cats are the colors of my cat. I have a black cat and a gray cat and a white fluffy cat.
Okay. So the the first profound statement that you keep hearing over and over again is that the age of simple search is over. I don’t think there is a single person in this audience or anybody who’s watching online that does not agree with this statement. The simple search is done. Right?
But the more important thing that we are all coming to realize that algorithms are no longer just indexing pages. They are understanding you, they’re predicting you, and they are acting for you. In fact, they act for you from within your browsers if you have already started using some of the agentic work that’s coming out.
In a world where AI systems and soon quantum computing, and I will talk a little bit about this. In my previous life, I used to teach nanotechnology, can reason in parallel across billions of possibilities. The only websites that will matter are the ones that matter to users in the first place. The value is always with the customer. And if they don’t use it, AI doesn’t care about it, search doesn’t care about it. So welcome to the next era of search where SEO is not just about rankings.
It’s about outcomes, trust, and intelligent connection. The intelligent connection part with AI is still a work in progress as you all know, and I’m gonna get into why the AI systems behave the way they do today. So my role at Microsoft is essentially to drive the collection and understanding of the Internet to drive major experiences that you all know about, Bing, Copilot, and beyond. In fact, we serve every segment, ads, videos, core search, whole bunch of other areas. And you also probably use all of the work that my team and me do in products like OpenAI and Meta and so on. So the scope of what we do is truly large. Understanding the web, archiving it, making sure it’s fresh and current and comprehensive is my job. And if, by the way, if, if you’re not seeing your content online, that’s my fault too.
But so, this talk is about the science of AI and how it is transforming SEO. So I’m gonna get a little bit geeky. On campus, on the Microsoft campus, many of my students are out there. And when I walk around, they keep yelling “professor!” every once in a while, reminding me that I used to teach some of this. So there is a bit of mathematics involved in my talk today, but I’ll keep it quite foundational and quite simple, kind of stuff that you probably already have seen.
And so let’s get into it. The AI era that you’re seeing right now is fueled by the convergence effects of nanotechnology, information technology, biotechnology, and cognitive sciences. And AI is coming together because of all of these fields making progress at the same time. But at the same time, you see that AI is also transforming search. Therefore, search is actually being fueled by the convergence effects that you’re seeing with nano, info, bio, and cogno. By the way, Tom, Friedman talked about it in his book, quite a few years back, but now you’re seeing the effects of this come into play. And today in my talk, I will be showing you with very concrete examples how this effect is actually improving the way we find information, but also is fueling a lot of the change that we are seeing today.
So some simple statements here. AI is transforming search into conversations and actions, and it is no longer being about static content that was gone a long time back, but it’s getting more and more tailored, and it’s getting more proactive. AI is making search smarter. In fact, in the systems that we build at Microsoft and at other places, large language models are a constant thing that we use in every part of our pipeline. And therefore, understanding them from a very fundamental level is super important for all of you as you design things that people use.
AI rewards what truly helps. So trust, originality, and quality content always win with AI. And I’m gonna tell you a little bit behind the why they’re this because of the math behind it. Clicks matter less. You’ve heard about this over and over again. AI measures success by outcomes, not just visits, and this is one of the reasons why you’re seeing data change the way that it does today. So you probably are familiar with this particular graph. This is an old graph that was shown when Bing chat was launched in 2023.
Relevance at Microsoft Bing jumped at its largest level that it had ever in two decade in the two prior decades. Right? So while this was happening, there was something much more profound going on at the platform stage. This was because LLMs were getting used wider and wider in all of the parts of the ecosystem. For example, we use LLMs for smart indexing. LLMs enhance the discovery and selection of the web. Just because you have content out there doesn’t mean that we discover it, and just because we discover it doesn’t mean we select it, and just because we select it doesn’t mean it gets into the index. Only the best content gets into the index.
The second thing that was happening was natural language processing was functioning at full blast, trying to understand the intent and the context behind a lot of what the users are asking and also to provide accurate results. In parallel, when people were just entering smaller queries before, you now see these longer queries. What what has transformed in the process is that the queries are getting expanded into much larger sets where we are predicting related terms, synonyms. You saw a little bit of what Mike was talking about is the science behind it. But it is not just one algorithm that’s doing it. There are multiple algorithms that are trained to look at this and that expand and look at what the intent of the query is in order to provide you with the results that you see on the SERP pages that we are all used to. Also, content awareness is pretty profound these days. Right? We interpret the search intent, but we also can deliver highly relevant content because we understand the specific context in which the content was created.
But also, at least we try to understand the context, but also map it on to what context the query is coming from. So this is pretty important. And also finally, the enhanced display of the results. You see summarization. You see a whole bunch of other methods that are being used, visual methods, video stitching. A lot of it comes into play when we present information on the front pages when the search is served. Now in just the time frame between 2023 and now, you’ve seen it go from just summarization and Q and A. A lot of the conversation is about the summary that you see on top of the page.
But search engines are already evolving to become data driven decision engines. Right? So they’ve already moved forward where you have a page of data. You can ask your favorite AI query tool, to look at the data and interpret it for you and drive some of the decision making processes.
It’s getting more and more personal because now we are introducing memory into the mix, and there is a lot of information that is available for people to actually just tailor the interactions and provide the query results that absolutely fit the user. This means that the query results that you see and what somebody else in your own household sees is going to be very different as a result of the personalization that is happening. And finally, we are getting into this whole agentic space. And by the way, this change is pretty profound.
The action by which AIs can autonomously or semi-autonomously function on your behalf is coming into a browser near you. Right? So you click on the browser, you can create these agents, and you can also have the agents work on your behalf. This means that methods to publish agents interact with data which is contained with the agents get much more profound.
By the way, as you go through all of this, from a scientific perspective, what is happening behind the scene is getting increasingly complex and increasingly multimodal in what we are doing. And the whole goal of all this is to drive customer value. And in the process of doing this, please know that the value of a changed SEO ecosystem with a different mindset and authentic great content will always be the driving force behind what we do online. So this is the part that does not change.
Now I also will tell you that there are products that are already happening. So you see the search results that are getting summarized, but you also see things like think deeper that are happening where you can do full on research, based on just a few simple query lines that you put into a window, which used to take many, many years, before when I was a student. About 10, 15 hours of work is now just 20 seconds of typing in a query, and it’s phenomenal. And it is translation translating all the way into Copilot actions, for example, which is an agentic system.
Agentic systems, by the way, rely on content at every stage of the decision making. So even though they are functioning autonomously or semi-autonomously, they are drawing on content in real time as you make these decisions, as they make the decisions moving forward through the processes that you have set up for them.
Now I just wanna give you a sense of where this convergence is starting to happen. What I did as part of my preparation for this talk is I went and looked at all of the LLM, the major LLM models that have been released since 2023 to now, and I’ve looked at how much the volume of the data that that we have, like the number of parameters that they use and the compute capacity that they use. So on the y axis is just the size of the model. So you see that not all models major models that have been released since 2023 are very big in size, but there are some pretty big ones.
By the way, I took the labels off because the the minute I put the labels on, people will be like, oh, this particular model is missing in the mix. Yeah. I understand. But the point of this is, just to show you that the compute capacity that is needed in order for these models is all read all the time. Right? So the reason why we are able to build these LLMs is because of Moore’s law, which you all probably know very well. Right? Like, compute capacity doubles every, every year.
By the way, the y axis over here is the number of transistors that are available on a single chip. And you will see that that’s a log scale, which means this is actually a power curve. Right? Because the numbers were getting so large, I couldn’t put them on this axis without making it extra long.
So you see that the as the power of these computes grow, so does the value of the models that we can create and so is the complexity of the models that we create. And by the way, predicted that the capacity will increase 2x every year. However, it’s starting to slow down. Right now, some of the largest chips that you have, Cerberus has a chip that has about 4 trillion transistors.
That is a lot of compute capacity on one chip. And also you see, more, the kinds of chips that we’re talking about with Nvidia and all of those, they are at about 80 billion, 90 billion capacity. So the capacity is increasing. This is why the in the convergence of nanotechnology, which facilitated the building of chips and the ability to bring these algorithms closer to the chip is driving the AI innovation that you’re seeing, and this is accelerating at a much faster pace every day. And I’m gonna talk to you a little bit about what happens when we get into quantum computing in a in a few minutes.
The other part that I wanna talk to you about is that the design of the large language models themselves are a derivative of how the human brain operates. I’m gonna show you this with a few simple math, steps here in a in a in a second. But now you’re seeing nanotechnology starting to converge with bio information and also with cognitive science to drive what is happening in the AI space. And I put this slide here, and I was thinking, this audience doesn’t really need a definition of what artificial intelligence is. But there are multiple types of artificial intelligence. Right? Some of them are narrow intelligence, and some of them are general intelligence kinds of things that you hear about in the news all the time.
AGI has always been a research endeavor, and it’s been an aspiration for a very, very long time, even before all of this AI craziness started. Right? But the inspiration was the human brain. I also put this here to indicate to you that people have talked about machine learning a lot in the past. And now it is all about deep learning and the systems that come with deep learning. The difference here is the intensity of the compute that you can apply. So the models that we are building today have such severe compute needs that you can imagine the kind of infrastructure that is needed in order for us to build these things.
And this is why the convergence of nanotechnology and the algorithms are powering the way the artificial intelligence steps the way that they are. A brief history, I’m not gonna dwell into this. It all started in, like, 1936 with somebody wanting to solve a theorem. Right? Like, oh, I just wanna solve a theorem. I want an automatic theorem solver. And that has led all the way to what we are seeing here today. I stopped the history at 2022 because I am I was a professor. And so if I didn’t have a history slide, you guys wouldn’t believe me. So, you know, so I had to have this in here.
By the way, 2017 was a pretty key step for a multiple reason. Right? Google published this paper that said attention is all you need, and that was the transformers paper. And, that was a pretty profound change that brought about a lot of the changes that you’re seeing here today. By the way, Microsoft also has been talking about bringing systems to human parity. I put this in here because as things were happening, in at Google and other places, there was also a lot of industry research that was happening. And so I just wanted to have this in here to show you that a lot of the things that you see in Copilot and OpenAI and all of these systems, they have a lot of genesis in research that was happening in this space for a very long time.
Generation, almost all forms of it, the algorithmic capability to generate using machine has long been an interest of scientists as far as I can remember studying computer science. Now what is generative AI? The deep learning algorithms that essentially drive it by the way, again, you see the three cat teams. This is part of my contractual obligation.
Essentially, this is how you teach machines how to acquire skills. Right? So how do you do that? How do you help machines understand skills like the way the humans do? Generative is built with five basic things that you all probably hear about, but I put them together so that you can see it in context of why is it that your content and SEO that is a changed SEO will actually have so much profound impact. Now this part of the talk is gonna get a little bit geeky.
I resorted to some very simple mathematics over here to explain this, and I will show you that in a second. The first thing that all of us know about and we hear about a lot is the large volumes of high quality data. This is needed for AI systems, and we hear about it a lot. There’s a lot of focus on content.
The other part of it, and I might mention this, very briefly in his presentation, is this idea of a transformer network. The transformer network is just a way of configuring nodes and edges in a way that information can flow through. However, the most important change that facilitated generative AI is this idea of self attention. Humans are capable of paying attention to things, and therefore, we are able to actually learn and bring our abilities into a very specific context. And that’s how the brain forms the networks that it does.
In the 2017 paper that Google published, the big change was not just a transformer model. There were sort of instances of it showing up in literature before. But this idea of self attention was particularly useful when they actually designed the algorithm that was talked about in that paper. It’s the transformer models. Right? BERT. Right? So the other thing that also changed is this idea of training models with the intent to generate content. Right? With the intent to use the content in some substantial way for human consumption later on.
This changed quite a bit. And, of course, the ability to fine tune these systems. So you take a bunch of data, you take a model that has already been trained, and you reuse the model with some additional aspects in order to fine tune it for your specific needs. For example, LNs get fine tuned for medical use all the time. So these are all the abilities that essentially change the way generative happens within AI systems. Now the critical role of neural networks in all of this is just beyond profound. Right? The human brain has, like, between 80 and 100 billion neurons.
And in deeply deep learning models essentially have this kind of a complexity going on behind it. Therefore, when you say that the AI systems make mistakes, it is because humans make mistakes. The architecture of AI systems are essentially designed to mimic the human brain. So if you make mistakes, the AI systems will make mistakes.
You can reduce it. You can increase the precision of it. But making it go away 100% is a very hard thing. And lots of people are working on it, but the human brain essentially, which is the motivation behind lots of these algorithms, drives the the kinds of behaviors you see in the algorithms themselves.
Now here’s where there is math and I resorted to some very old fonts that I used to use when I was a coding computer still. So on the left is a neuron, on the right is it is the neuron translated into computer terms. So essentially, think of a neuron as having two input points, x1 and x2. It has some sort of a function, and it produces some output. The function in the middle is probabilistic. Right? Which means it relies on a bunch of, like, oh, maybe this could happen, maybe it could not, in order to, produce the output. Now very simply, this is basic neuron ops, and I’m gonna tell you why your content is important in a minute. Okay?
So, the if you think about basic neuron ops, essentially, what you’re telling the neuron is, hey, take inputs x1 and x2, pass it through this function, and if x1 meets a certain value or if x2 meets a certain value, fire the neuron. Otherwise, don’t fire the neuron. Right? So it you’re making a very simple transformation over here. And this is called a pass through. Right? Like, so it’s a very simple process. Now not all neurons fire in the same way because there are different thresholds at which this happens. Right? Some people like really hot coffee. Some people don’t. There’s a neurons firing in different ways.
Right? So, essentially, how do you determine which of the inputs is more valuable to a neuron than other inputs. Right? This is a pretty profound problem. So each of these neurons are usually associated with a weight. Your content is more important. So authenticity of the content is a condition. So I’m gonna apply that on x1. And if it’s very more authentic, it’s gonna pass through. If it’s not, it’s not gonna pass through. So the systems are essentially designed to reward things that are of value because you’re fine tuning this algorithm all the time. Right?
And now you add weights to it, and the weights are even more interesting. Right? Because how do you actually figure out which part of the algorithm is more important, which input is more important? The weights determine that. And the weights are essentially pretty complicated equations where a whole bunch of things go in, and they’re all probabilistic by nature, and not all weights are equal.
So imagine this is just one neuron. Right? Like, I didn’t even go into all of the science of it. But a neural network is essentially hundreds of billions of these things put together, and this is why they are compute intensive. The complexity of what it takes, the algorithmic difficulty of what it takes to manage billions of parameters, weights, layers, and outputs is extremely hard and is super probabilistic in nature. So this is where you see nanotechnology.
Why do you need so much power? Because you’re storing all of this and you’re processing all of this. Right? And your models are getting bigger. Therefore, you see a convergence of nanotechnology, information technology, cognitive science, and cog bioengineering all coming together in these systems. And when you have one field driving progress in a specific space, that’s fast enough. But here, you have four different fields driving pretty rapid progress in a space. And this is why you’re change you’re seeing the change happen at such rapid pace across the board.
Now a foundation model is a very simple one. Right? Like it’s you train one model and you use it all over the place. The reason is you just saw it. It’s super complex to develop one of these things. And therefore, you train one and you apply it to numerous scenarios, like question answering, summarization, processes, etcetera. And there are so many of these. Now the cool thing about foundation models is that as the model scale increases, their performance increases across different tasks.
But what also happens is that new unanticipated capabilities start to generate. This is why LLMs suck at math. They were actually trained to generate the next token in your language model. They are not trained to do math. Therefore, you see that mathematics is an unintended, unanticipated effect of the algorithm, and so the model just learned that. Right? So you see these unanticipated capabilities becoming unlocked, and therefore, we popularly call it hallucination. Right?
It hallucinates a little bit because all of these probabilities are coming together, but also these unanticipated things start to creep up every once in a while because these models are super complex and they’re trying to mimic the brain. Right? And their reward function is a little bit different for every step. So that’s what happens.
So things to consider in the foundation model, trading data almost always is to a certain standpoint. So, you know, it does not we don’t train models on a continuous basis. People say, well, the model was trained. Even as I click on it, it learned from me. That’s a totally different thing. This is not the LLM or the large language model beneath what you’re doing. It does not have access to all of the context. It does not have access to your data. Long term memory is a major consideration. You see a lot of announcements that are happening today around memory, and this is how, you know, progress is happening.
Also, you see a lot of, progress happening around context length. How much context can the model actually react to? And there is a lot of research that says as the context length continues to grow, the attention span of the model, just like our humans, a human brain starts to dissipate. I’m pretty sure that your attention span right now is a lot lower than what it was when my talk started. So it’s the same same process. Reducing hallucinations and fabrications is a really important thing, and prompt input and results output actually have a size limit. And this, it’s much larger these days, but the size limit is pretty important.
The most important message from all of this that I can communicate to you is that all LLMs that are currently in the market and that are in development today, that I know of, and that I can talk about, currently have a knowledge cutoff date. Okay? So this means that fresh data and content is the fuel that powers AI. The brain of the AI systems does not have all the innate knowledge that you already assume that it should. Here’s a simple example. You go online and you ask an AI engine about the baseball calendar, for that particular month or for that particular city, it does not have this. Therefore, it’ll produce answers that it thinks you need, but it doesn’t actually really work well. Okay? So you have to actually give it fresh data. And for that, it uses this process called retrieval augmented generation.
Right? So here is a simple workflow. Without retrieval augmented generation, you don’t have any extra knowledge flowing into the model. Therefore, the model is gonna make up whatever it makes up based on the knowledge it already has. Right? But with retrieval augmented generation, it has a way for you to go, search the index, get fresh content, get comprehensive content, and then factor that in to the response that it provides you. Therefore, your content actually starts to become part of the brain of how the LLM works. And this is why authentic content is always gonna be super important.
Now IndexNow, that you may all have heard about, is one of the protocols that is out there that we are trying to actually make it quite open that allows you to keep your content fresh at any given time. Crawling as an activity was always, like, sort of an aggressive activity. Right? Like, we would go crawl things and, by the way, at Microsoft, one of my jobs is actually to look after the crawling product. Right? So we would go and guess when we would need to crawl, change the content, and, you know, we would detect it and we would process it. And sometimes it would lead to very poor processing. But rather, with IndexNow right now, what happens is you determine when we should crawl. You take control of the crawling process.
There’s so many bandwidth optimizations that you can do on your end. There is so much benefit for avoiding dead links and making sure that we surface the best content that you want. So this is real time control of the crawling systems. And by the way, if you try IndexNow and it doesn’t do it, you should let me know because I happen to know a thing or two about this. So, so please, if you’ve not done it, please adopt it. It’s pretty cool, and, that’s all I’ll say about that. Right?
I’m gonna get into one last slide on all this quantum craziness that is happening around us. And I want you all to simply look into this as a very, very far out future. It’s not that far, by the way. Right? Like, people are already announcing quantum systems out there. But there are three important concepts that I want you to leave today with. One is this idea of a qubit. Everybody is aware of what a binary thing is. Right? It’s zero or one. The answer is binary. But when you talk about qubits, because of something called superposition, the the model the the the atom can exist in multiple states, zero and one simultaneously, which means that you’re not only processing zero and ones, you are processing all the intermediary states between zero and one.
Therefore, any compute power that you think of is like super power right now is nothing compared to what we are gonna get when we get to true quantum computing, which is not that far away, by the way. It seems far enough in our lifetimes, but it actually is not. So AI seemed far enough a few years back. Right? In just a very simple terms, it is like going from a buggy to a rocketship when you go from, like, simple compute, what we have today, to quantum computing. So that is one of the reasons why that is is because of this qubits business where, an atom can exist in multiple states at the same time. The second idea is this notion of quantum entanglement.
Quantum entanglement means that regardless of distance, the states of two atoms are tied together without any barriers, which means you change the state of one is like changing the state of another. The reason why I mentioned this is imagine what happens if there was no web index. Your content is the index. You make a change and the change is the index. The Internet is the index.
So very profound change in how you think about systems of today that are already being thought about out there. The last thing that I will talk about is this idea of quantum interference, which is actually a thing that has a lot of applications in search where you reduce the negative effects of computing and increase the positive outcomes that you want. Think about what that means for AI and for machine learning and so on. And by the way, Grover’s algorithm, which is one of the standard algorithms in, in quantum computing, is a search algorithm. Right? It’s for searching unstructured data, and people are already looking at it. And by the way, with Grover’s algorithm, you see see a quadratic gain. Let’s say that you take n steps to solve a problem.
With Grover’s algorithm, you can do it in square root of n steps, which means that as your numbers get larger and larger, the number of steps that you have to take to solve the problem is smaller and smaller. So this is the future. This is where this is what it’s all coming to. I’m just about out of time.
The clock just turned zero over here. Summary of my main ideas here, cats rule the Internet. I’m sure you all knew it. And, please note that your content, your creativity, the human aspect of AI systems is still the most important aspect.
I do not want you to leave here thinking that search is about AI. Search is about you. Search is about people. Search is about creativity. Search is about making sure that we can find information as humans that make us valuable to society. Please don’t forget that. Thank you so much.









Watch every SEO Week 2025 presentation and discover what the next chapter of search entails.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.