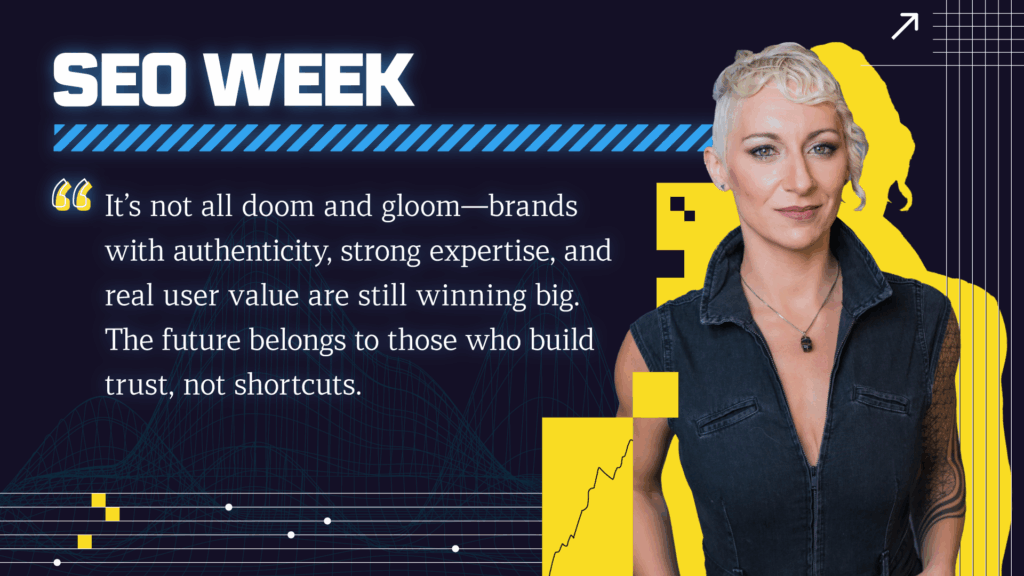
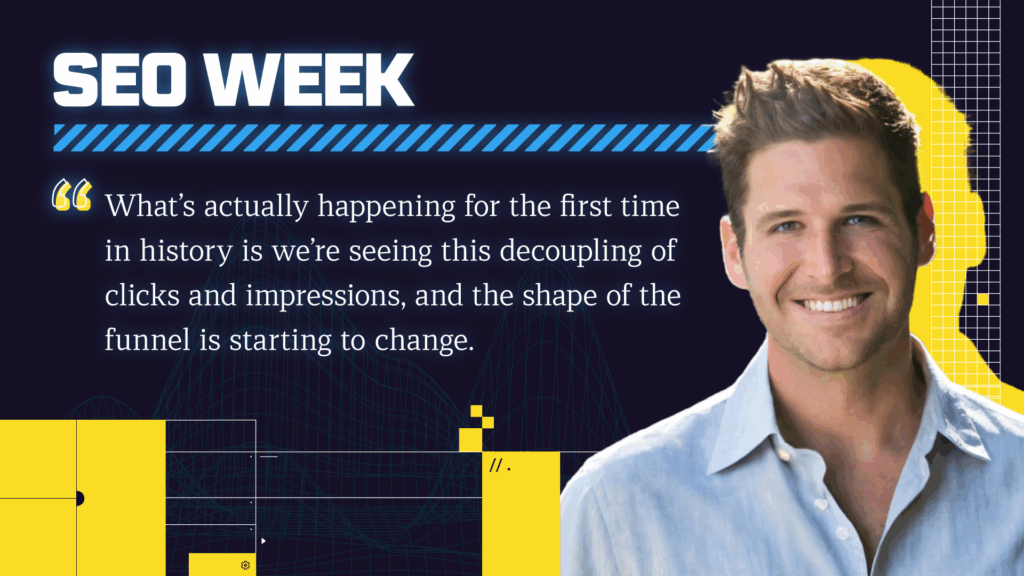
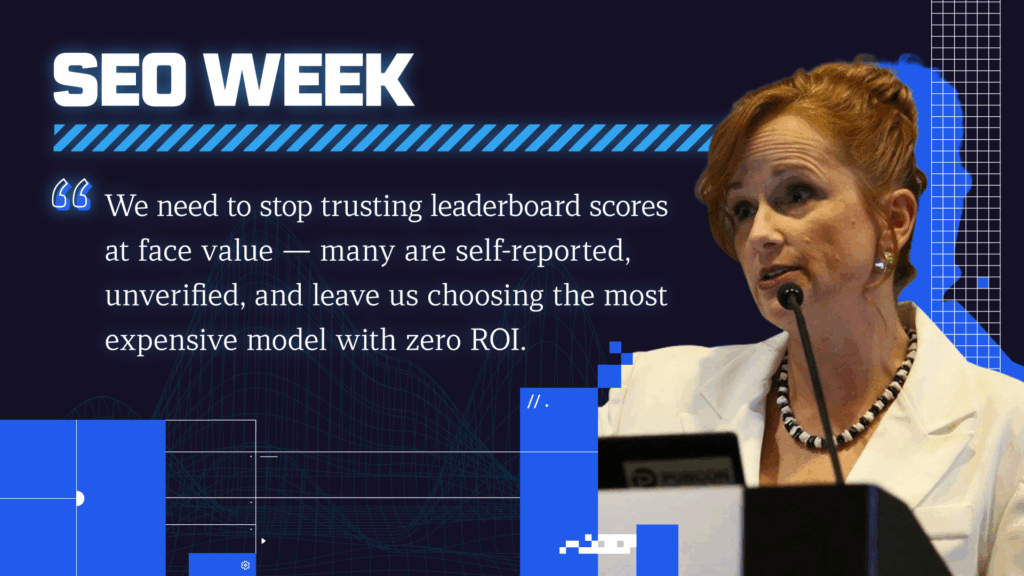
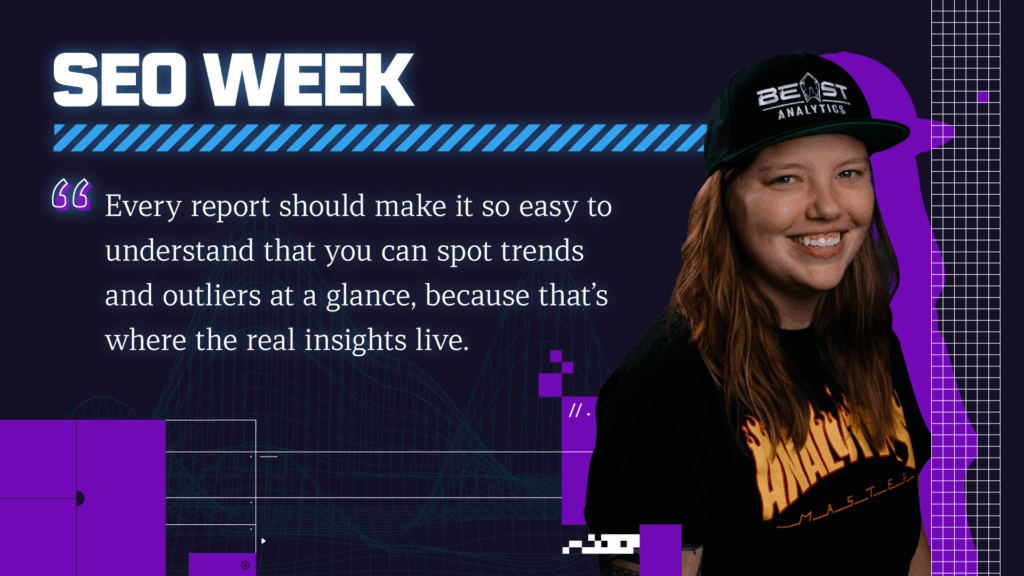
Elias highlights how SEOs can go beyond just learning Python to truly harness the power of data science. Using tools like Jupyter Notebooks and his advertools package, he shows how to analyze robots.txt files, sitemaps, and web content at scale, emphasizing reproducibility, structured insights, and the strategic use of bulk prompt engineering with LLMs to uncover actionable SEO data.
SEO Week 2025 set the bar with four themed days, top-tier speakers, and an unforgettable experience. For 2026, expect even more: more amazing after parties, more activations like AI photo booths, barista-crafted coffee, relaxing massages, and of course, the industry’s best speakers. Don’t miss out. Spots fill fast.

Elias works at the intersection of SEO, SEM, data science and software development.
He is the creator of advertools, a Python package and CLI, downloaded more than 3.5 million times. advertools provides an SEO crawler, tools for creating search ads, log file analysis, XML sitemaps, robots tools, and more. He is also the author of the book Interactive Dashboards & Data Apps with Plotly and Dash.
In his SEO Week talk, Elias explores the powerful intersection of data science and SEO, advocating for a deeper understanding of data principles over simply learning tools like Python. He challenges the industry’s fixation on automation and coding by demonstrating how tools like Jupyter Notebooks and his own open-source package, advertools, can empower SEOs to extract, analyze, and visualize web data meaningfully and reproducibly.
Through practical walkthroughs, Elias shows how to analyze robots.txt files, sitemaps, and website structures, and how to scale SEO insights using large language models via bulk prompt engineering. He emphasizes the value of reproducibility, transparency, and scalability in modern SEO work, ultimately equipping marketers to conduct smarter, data-driven research with clarity and precision.
I share most of my related work on GitHub; here are my projects.
Here’s the link to the code I presented at SEOWeek (on Github); my profile is there as well.
Focus on Fundamentals, Not Just Tools:
Learning Python is valuable, but true SEO data science requires understanding core concepts like data visualization, machine learning, and analysis, not just code syntax.
Reproducibility Matters:
By using Jupyter Notebooks and structured Python workflows, SEOs can create transparent, scalable, and shareable analyses that build trust and enable collaboration.
LLMs and Bulk Prompting at Scale:
Elias demonstrates how to use bulk prompt engineering with OpenAI’s API to systematically evaluate web content using Google’s helpful content guidelines, making large-scale content audits more efficient and structured.
SEO Week 2025 set the bar with four themed days, top-tier speakers, and an unforgettable experience. For 2026, expect even more: more amazing after parties, more activations like AI photo booths, barista-crafted coffee, relaxing massages, and of course, the industry’s best speakers. Don’t miss out. Spots fill fast.
Elias Dabbas: I would like to share my thoughts about the interplay between traditional software, which is more precise and tailored for more structured data and tasks, and LLMs which are less precise, and tailored for less structured data and tasks.
Utilizing both types of systems in the same workflow can maximize benefits, and enable us to use the best of both worlds.
For example we can throw an HTML page at an LLM and ask it to generate structured JSON-LD data for that page. But to improve our chances of getting something meaningful, we can use traditional software to provide a more structured input. Using a crawler we can extract key elements from the page, and provide them as (more structured) inputs to the LLM, thereby minimizing the probability of hallucinations. Now the LLM can be used to run the less structured task of figuring out the structured elements of our JSON-LD snippet (a task that traditional software would struggle with). The LLM gives us back extracted and structured data about our page, which now we can use as inputs for a more structured task like gaining some insights on some of the activities of the website, using traditional software. This can be an ongoing virtuous cycle. Here is an actual workflow where I go through these exact steps with code, and running in bulk for several pages.

Elias Dabbas: I’m increasingly finding myself spending an hour or two doing actual work with an LLM without very minimal Googling, and sometimes without Google. This was unthinkable a few months ago, but it is increasingly the case. This is of course an exceptional case because it involves code. Programming languages are precise and designed to be unambiguous because their instructions are interpreted and executed by non-thinking machines. A misplaced comma or dot somewhere will break the whole application.
Because of that, LLMs can much more easily detect character sequences in programming languages than they can in natural languages.
Another benefit with code is that I can easily verify it by running it, and I can also run automated tests to check whether or not it works as intended. On the other hand, if you are writing an article with an LLM, it’s much more difficult to verify facts and you’ll need to search and make sure they were not hallucinated.
A portion of my searches have disappeared, gone off the grid, and are never coming back. They have been replaced by long, complex, and detailed prompts, with an increasingly longer context window consisting of pages of instructions, guidelines, code, etc.
This is happening everywhere but in varying degrees, depending on the use-case, and user-adoption.
Mike King: There’s many ways that you can pronounce his name. And what I’ve noticed is that anyone and how they pronounce it, he’s like, yeah yeah yeah, that’s that’s how you say it. And I don’t know, I’m big on names, getting people’s names right, and so when I first talked to him over Zoom, was like, yo, how do you say your name? And he’s like, well, where? In the UK, in New York, wherever? Anyway, I finally got him to tell me last night that I was drunk, so I’m not really sure I remember. And although Elias Dabbas always posts code, he has no engineering or technical background. He went to business school and he barely passed the only programming course he took with a C. He makes python packages like he’s baking bread. Except instead of feeding people, he’s feeding his own obsession with data. Aren’t we all? He was once a partner in a small paper cup factory. Guess what he did with the cups? No guess. No answers? Cool. He ran an advertising campaign on the cups for one of his clients. Unlike brochures, no cafe is gonna throw away free cups and you’re going to have to look at your cup while drinking. Smart. Presenting The Rise of the SEO Data Scientists, please welcome Elias Dabbas.
Elias Dabbas: Okay. Hello, everyone. Voice okay? Great to be here. Thank you all for coming. And as Mike mentioned, I’m gonna be talking to you about data science and how it relates to SEO. So let me tell you a bit about myself very quickly. I work at the intersection of these fields. I don’t belong properly into any one of them, so just, you know, all over the place in these four. I’ve created a Python package called advertools, that has been installed around 3.7 million times. Times, not people. Hopefully, eventually. I also wrote a book about how to build interactive data apps and dashboards with a framework called Dash. And when I got excited at the beginning with data science and started to share and saw other people also sharing, I realized that we might have a slight keyword problem with the name of not my name, the name of the field. And I think it’s explained very well in this quote. So let me read it quickly. When some field is just getting started and you don’t really understand it very well, it is very easy to confuse the essence of what you’re doing with the tools that you use. So this thing has been called Python for SEO. And let me tell you why this might be problematic. Okay, so imagine I come to you and I say, I built this great website, it’s generating 100,000 clicks from Google and you say, oh great, how’d you do it? And I say, I did it with HTML.
Now it’s true, you build it with HTML, but that’s not the essence of what we are doing because the problem here is no matter how much HTML you you learn, you will never ever learn about keyword research, for example, because that has nothing to do with HTML. So you’re going to be focused on the tool, not on the essence of what you’re doing. And many people are frustrated by this. So the same thing here with data science. Many people are just learning Python, the tool, and not the principles of data analysis, visualization, machine learning, and all these things. And again, no matter how much Python you learn, you’re never gonna learn about data visualization, for example, or machine learning. Coding is another name, but that’s that’s the same problem because tell me about the tool. Automation is another popular name. Of course, automation is absolutely important, but it’s missing the part of insights. So for example, a visualization tells you a story about what’s happened with your traffic or with your website. And it’s not about repetitive tasks and just just doing being efficient with those, even though these are absolutely important.
And at the same time, we we have a counter movement. You don’t need Python to do SEO. For some reason, there there was this reason to reject it. Anyways, so generally the presentations here at SEO Week are like 25 minutes slides and then like five minutes deep dive and something that you can take with you. And with Mike’s permission, I flipped my own structure. I’m done with the slides. I’m gonna start with you with a deep dive of a bunch of things that you can take away with you and I hope you like. Okay. So before starting, I just wanna review three main topics that you already know and see how they apply to to Python and talk a bit about Jupyter Notebooks and start doing our work. Okay? So first up is the concept of variables. Okay? So in a spreadsheet, you click inside a code cell, you start typing code, and then you hit enter. The spreadsheet evaluates the code and prints the the result of that code. Okay? And if you wanna see the source code of that cell, can look at the formula bar and see, for example, here we have equals 10 + 5 and the result was, 15. Now, as as a side effect of doing this operation, Excel gives a name to this value. It calls it B2, for example, over here. And now I have a name that I can refer to anywhere in my spreadsheet. So I can say B2 + 5, whatever that B2. Because it doesn’t matter because it’s been defined. So if you want to expand it into code, it’s going to look like B2 = 10 + 5, as you can see here in the first bullet. And that’s generally the way to define variables. Name equals value.
The other thing is functions. And the way functions run is you type in the name of the function and you open parentheses and you have a bunch of parameters separated by commas and you hit enter and you run it. Now, great thing about this is that once you know how to how to use one function, you’ve learned them all. They all work the same way. They just have different sets of parameters. And the other interesting thing is that it’s the same way they work with Python.
Now, another way to access functions is through the right click, and these are contextual functions. So, if I right click on an image, I have these functions, and depends on the type of object. If I right click over a string of characters, I get a different set of functions. And if you want to do it with Python, this is a variable that I have. You use the dot notation dot and you hit the tab button and you see all the available functions that you have for you. Okay? And one final thing is is the Jupyter Notebook that we use a lot with with data science. This is a a file format. So in general, have file formats and applications that work on these file formats. So as long as you and I work in CSV, you are free to use any application you want, anyone that you prefer. And the other implication is that once you learn one of these spreadsheets, you can learn all the others, as well. Okay? So the same thing we have, Jupyter notebooks, which are files that end with I py n b, interactive Python notebook. And there are a bunch of applications that know how to process them and help you run the code and and and execute all the all the code that you want. Okay? So this is the minimum viable knowledge that we need to get started. And let’s get started.
So advertools is a Python package, which means from user perspective, it’s a bunch of functions. So just like spreadsheets, Python comes preloaded with a bunch of functions. Let’s say it has 500 built in functions. And now once you install a new package, you have 50 or 60 additional ones. Okay? And this is open source and free software, so I will shamelessly try to sell it to you at the price of zero. But you have to pay some attention. Okay. So you you go inside the code cell and type this this this code at at the left, and this is how you install it. And then when you wanna start, you import it, meaning like you start the application. And sometimes we have long names, we save them as with an alias, like ADV, for example. Now you can use the dot notation and see what functions we have available for us. Okay? So we’re going to go through the sequence that search engines typically do. Robots, XML sitemaps, URLs, crawling, and content evaluation.
Okay. So the first function is robots to DF. So as you can see, we were using the same pattern of name = value. And the name here is NYT_robots. So we no longer need to stick with the meaningless names that spreadsheets give us, like a 1, B2, a 3. We give it something meaningful. Okay? And this is a function just like any other function we talked about. And you put the name of the function, you open parentheses, and you give it the the argument. Now, once I run this, I have this variable available to me in the in the Jupyter Notebook and I can use it any way I want. So this is a data frame, which is a table. I’m not trying to sound fancy or anything, but that’s the name that’s used in in data science and I’m using it. But it’s a table, just just like this. So this robots file has been parsed. The first column is everything on the left hand side of the colon, and everything on the right is on the second colon. So sitemap:something, user agent:something else. So now I want to explore this file. I can run a simple filter. So don’t worry about the code over here. It’s just a filter that says, give me the rows of this data frame where the content column contains the pattern Google. And now we can see which user agents they have that contain this pattern. We can see one of them is duplicated, and we can see the two others that they have been using. Okay? So I’m gonna I’m gonna do this again one more time, but using a different pattern. And I’m gonna extract all these sitemaps that are available in this robots file.
So I have a new variable here called NYT sitemaps. And I’m going to do the same thing with user agents. So extract them. You don’t need to go and copy and paste and try to parse them manually. Okay. So a nice interesting feature about this function is that you don’t just have to give it one URL. You can give it multiple URLs and then with one line of code, you can can get a mapping of all the domains that you selected and the XML sitemaps that that are there. So I just used four here. You could have used 4,000 if you want, like a whole industry or something. Okay. So we’ve we’ve obtained a list of of XML sitemaps, I wanna convert one of them to a data frame. And the second function works exactly the same as the first one, sitemap to DF. Okay? So I’m going to take the news sitemap, convert it to a data frame, and save it to a variable called NYT news. Okay? And it looks like, as you can see here, it’s another data frame. And it has 671 rows and five columns. Okay? And one interesting thing about this function is you can give it a sitemap index file and it can go ahead and do recursively go through all the sitemaps, merge them into one data frame for you in one go. So you don’t have to do it multiple times.
Okay. So now I feel a bit overwhelmed in my data session. I’ve defined a bunch of variables. I don’t know where I am. You can easily get an inventory, so to speak, of what variables we have with the who’s there function. So this gives you a nice table showing you everything that you’ve created so far. Okay, so we have a robots URL, we have a list of user agents that we’ve defined as a variable, and we have list of sitemaps. So one thing you might want to do is test whether or not your robots file is blocking any of your URLs in the sitemap. And we have a function for that is robots_test, robots.txt_test. So once we run the function again, the result we take it, then we save it to something called NYT robots test. And when we look at it, it’s it’s another data frame that looks like this. Now if you if you if you notice in the bottom left corner, have almost 28, 29,000 rows, which means that this function has run 29,000 tests for us. We have like almost 600 URLs and we have 42+ user agents, all the combinations. So this first URL can be fetched by this user agent, and the last URL cannot be fetched by that user agent. Okay? And now we can easily run simple reports. We can see that we have 27,000 cases where we cannot fetch the URL and only 3,600 where we can. And as a percentage, we can see 88% have been blocked. So it’s a bit strange. But when you look at the actual file, you’ll see that they’ve been blocking so many user agents, as you can see. And so you explore this test in many different ways and interesting ways.
Okay. Next, we want to convert the URLs into a data frame, which again works in the same way. So URL to data frame. So if we give these URLs to this function, what it does is it splits the URLs into their components. As you can see, we have the scheme, network location, path, query, and fragment. And the path part is split for us into directory one, two, three, etcetera. Okay? So what I’m gonna do is I’m gonna run a very, very small and simple study. I’m gonna take two site maps, January 2010 and January 2020, and compare them. Okay? So this is the same way we did before. And now I’m going to take the URLs of each one of these sitemaps and split them into their components. Okay? So now let’s analyze the content that we have. Okay? So advis, advertools visualizations, it’s another package that I have that gives you a few interesting visualizations to use. So in 2010 we can see we have only three unique values under directory one. In 2020 we have many more. And you can see various observations here, like what what things have have changed. So directory two and three are not very interesting because they are the month and the day. So let’s go to directory four, which shows us the category of content that this article is talking about. Okay. So this is the difference. I’ve I’ve only highlighted two, observations here, that sports went down from #1 to #6 and that the total number of URLs was 6,000 and went down to 4,600. Okay? So now, just to make a quick observation of what was done, we ran a simple study here and I’m sharing with you the results of this study. But much more important for me is to share with you the full recipe so that you can reproduce the same results on your own computer simply by running the same sequence of code that I went through. Okay? So in other words, this sequence of code that I showed you here is not about the study, is not highlights from the study, it is the study. Okay? You don’t need anything beyond what you saw here to reproduce the same thing. So my my work took me, like, let’s say two hours. It’s gonna take you 20 seconds to come here at the same stage of this study.
So reproducibility, as as also Mike mentioned at the beginning, in the morning is is a is a crucial thing in everything we do with with data. And first, it’s trust. We wanna trust that that the work is correct, especially our own work. I always make mistakes. I’d like to trust my own work. The second thing is collaboration and building on others’ work. So once I give you this code, you can run it again and then take the research to a different level. So you can check why sports went down from 1 to #7 or why the URLs went down that much in total. And scalability. So once you have this done once, you can run an industry survey, an industry report every month and publish it and and build a good understanding of what’s going on.
Okay. So next is crawling. Crawling works in a very, simple way. You you the function is called crawl and it just crawls the URLs that you give it and saves to the output file that you created. That’s the minimal way of running this function. And you can do spider mode. But if you wanna do spider mode, all you have to do is add the follow links parameter and set it to true. Okay? So now you’re familiar with with everything we’ve done. I’d like to show you a recording of a of a crawling session and how it works and a few options of analyzing the website. So if you’re ready, let me show you how it works. Okay. I hope you like that. So so the first study was is available in a separate Jupyter Notebook in the project repository that I’ll share with you at the end. So it’s gonna be completely independent, reproducible, so you can you can run it again. This whole process is also in a separate Jupyter Notebook that you can play with and you don’t need to reinvent the wheel. Can just take my work and build on that. I hope you can also explore the other options to analyze the crawling behavior. So the code that I used was the simplest code possible. Just scroll this URL list, follow links, and save here. But typically you would have something much more extensive like this. Okay?
So you have quite an interesting set of options. You can stop crawling after 5,000 URLs. You can set the download delay between requests. You can set the depth limit. You can create your own user agent or even set the concurrent requests per domain. You can be really, really specific in what you do. So this puts everything in one place, which makes it very easy to audit. Sometimes if you have an issue, you can just send a question to someone and they can help you debug and see what went wrong. It also makes it shareable. So you can run the code and send it to me and I can run it. You can delegate this work to other people as well. And this is scalable. Once you’re once once you wrote the code once, you can rerun the same crawl, many other times.
Okay. Let’s do some some AI. So a lot is being talked about prompt engineering, and I I would like to propose a slightly different way of thinking about it. So if craftsmanship is making a set of four chairs on a table manually, let’s say, But engineering is about manufacturing a thousand sets of those. So it’s a different way of thinking, different way of operating. And I like to apply this to the concept of prompts and and bulk prompting. And that requires two main components. First, a prompt template and a mechanism of running things in bulk. Okay? Of course, we need structured data, but we obtained this already by by crawling, the website. So a prompt template is just a temp a prompt, but it has these placeholders for variables where you can plug in, a different price or a different color every time you you run this prompt. Okay. So one quick additional information. We use the dot notation at the beginning. Sometimes you have objects that are a bit more complex, so you have multiple dots. So in this case, assume you want to access the histogram function in Excel. What you do? You start Excel and then you go to insert, chart, and then you say histogram. And if Excel was a Python package, would import Excel and then say Excel dot insert dot chart dot histogram or Excel dot file dot import and so on. Okay?
So I’m gonna share with you the OpenAI package, which is the official package of OpenAI. And the way it works is you create a client, a variable, just like we did with everything else. But you put your own API key over there and now you can use the client to run additional functions. For example, client[.]chat[.]completions[.]create. This is a normal function just like any other function. It takes a bunch of its own parameters. You can use audio transcriptions create. If you wanna transcribe 100 files, you can use client[.]images[.]generate. Okay? Okay. So what I wanna do is take evaluate the content that I’ve crawled using an LLM. I wanna send the content to ChatGPT and say, evaluate this using Google’s helpful content guidelines. So I’m gonna create four variables. The first one is the intro, instructions on how to do it. And then I have 20 questions from the helpful content guidelines. So I’m gonna ask ChatGPT to evaluate the article based on each one of these criteria. And two other variables are the title and the body of the article. Okay? So this is my prompt template, just like I showed you a few slides ago. And now all I have to do is plug this template into the function client[.]chat[.]completions[.]create. This is a normal function just like we said in in everything we did. And now I have I I only have to save it as a variable and I call it response. You can call it anything you want.
And so I’m gonna run this in bulk on on this data frame that I created by crawling our website, over here. So now I need a mechanism to go through, run run these prompts in bulk and and it’s called a for loop. And it works just like you do in a spreadsheet when you double click on a formula, apply this formula to everything in this column. So assume we have a list of colors. As you can see here, I want to do something to all of these colors. So I just say for c in colors, print c. Instead of saying print blue, print green, print yellow, I just write it once and the variable here is c. I can do something more interesting. Can be printc[.]lower. Lower the case, process them in a in a certain way. But the most important aspect here for us is that now you have a prompt template in bulk for seeing colors. Please create an article about the color c. And every time you can it changes and this could be like 400 articles or prompts. Okay? So now this is the same function that I showed you two, three slides ago. All I have to do is add three lines of code. One is create an empty list and then write the for loop and then in every invocation of that for loop append the response to that list. So we have now a full list of all the evaluations done together. And now I can see the full evaluation per URL. I can do aggregates for my my articles, by article, by topic, by question.
And you can go crazy with the way you want to analyze this. Okay? So just to put this into perspective, imagine we have a spectrum of approaches. One is at the right extreme that we just did here, like binary questions, yes, no, yes, no. And on the other extreme, you have the normal manual prompting. So this this one is like focus groups, if you want, in research. And this one is like a binary research. So the focus group or the normal prompting is much more nuanced, obviously, because you get more react interactivity and so on. And this one is much less nuanced. But you can mitigate this with a detailed set of questions just like we did. But this one is much more scalable. You can run it on thousands of URLs. And it’s much more standardized and structured. You can run averages. You can get you know, you can compare any way you want. So this third Jupyter Notebook is also available that you can get as well to run it. And you can easily just replace the values that I use with any URL you want, any any website you want, and you can run this. So these we’ve done three notebooks so far. I’ll share them with you and I hope you like them and and try them and let me know what you think. Thank you very much.







Watch every SEO Week 2025 presentation and discover what the next chapter of search entails.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.