
Back in April 2023, sadly Bed, Bath & Beyond filed for bankruptcy. Unfortunately, it was not much of a shock due to the news that had been swirling around the company in the months prior, but still heartbreaking to see an American institution evaporate. What was shocking, though, was when Overstock.com announced they would acquire the name, trademark, and domain and rebrand itself as a Bed, Bath & Beyond.
For Overstock, this is a very smart move for a variety of reasons related to brand awareness. The mindshare of a brand born in the 1950’s with a presence in malls across the country is much larger than that of an e-comm site that got its start by selling overstock of failing dot com companies. As far as Organic Search goes, it’s a huge opportunity to quickly double Organic Search traffic. And, at the very least, there’s a possibility of nearly doubling the site’s external link equity. I’m proud of these folks for capitalizing on such a land grab.
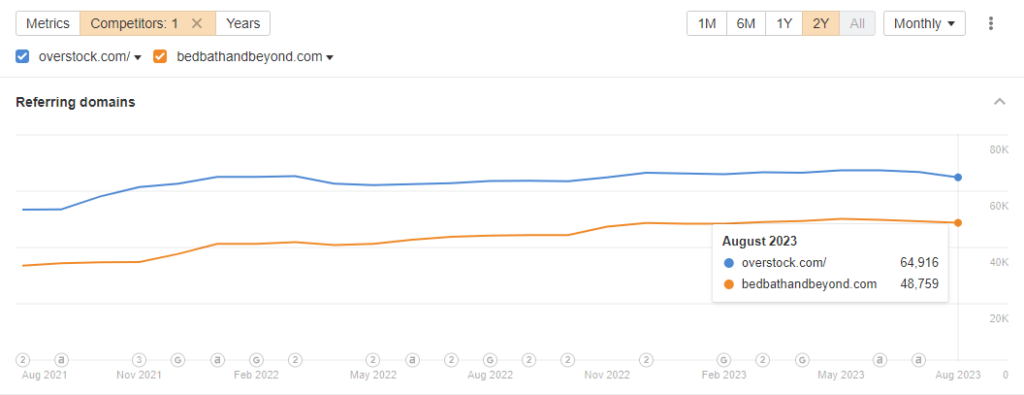
Considering the upside for Overstock when they got these assets at fire sale pricing, somebody on the M&A team deserves a raise. The links alone would cost more than what they paid for the brand. Now, as for the SEO that needs to work out the migration, your job will be much more challenging than Twitter rebranding to X.
Site Migrations Aren’t Difficult, They Are Tedious
Migrating a website from one domain to another is a technically simple and well-paved process. It’s really just 11 simple steps:
- Determine what content needs to be migrated
- Identify the mapping between source and target URLs
- Identify the mapping of broken link targets to new target URLs
- Move the content from the source to the target URLs
- Implement redirects from the source URL to the target URL
- Update the internal linking structure on the destination site to point to final destination URLs on the target site
- Update canonical directives on the target site (sitemap, rel-canonical, canonical headers)
- Implement new XML sitemaps with the new URLs on the target site
- Crawl the original site’s URLs to validate redirects to the new site and stress test the underlying services
- File a change of address in Google Search Console on the old site
Watch rankings, analytics, and log files of both sites with the goal of seeing the target site overtake the source site’s rankings
After you do this, it’s generally expected that you’ll see losses at the target site for around 6 months. However, at iPullRank we’ve been pretty fortunate to drive cross-domain migration recoveries in as few as 30 days. There are no magic tricks, we just do those 10 steps and work through the process with engineering teams to expand host load so Googlebot crawls more. We also leverage differential sitemaps to help with crawl penetration.
Outside of catastrophic failures of the site or any of its services, nothing in the process is especially difficult. However, it requires great attention to detail and typically a lot of coordination across many people. That’s why a lot of brands come to us with these projects. It’s really the mapping of source to target URLs that are the most important part of the process because of how Google reacts to situations where there is no parity between the source and target URL.
Google Never Forgets and Dislikes Irrelevant Redirects
Google’s index operates much like the Wayback Machine. It’s designed to store multiple copies of pages for the long term. This gives the search engine the capability of making version comparisons of pages and determining how often a page needs to be crawled based on how often substantive updates occur.
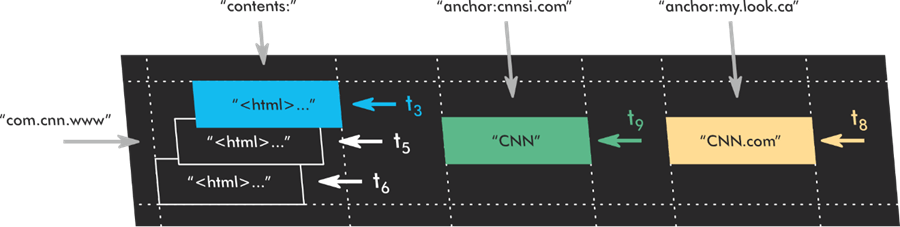
This persistent storage is also used for comparisons of parity. That is why it’s not enough to buy a dropped domain and throw unrelated content onto pre-existing URLs and expect to take over rankings it once had. This is also why redirecting a source URL to a target that is irrelevant (like a homepage) yields a quiet Soft 404. Google knows what was previously at the source URL and can compare what they have indexed previously with what is at the target URL.

Effectively, Google never forgets and they have progressively improved their ability to use historical data to circumvent attempts to quickly rank that used to work very well. What does still work is moving the same content from point A to point B and implementing a 301 redirect. This is still the best way to maintain the most rankings and traffic.
Ideally, Overstock would do a “lift and shift” of its content by simply copying it from Overstock.com to BedBathAndBeyond.com and then 301 redirecting the old URLs to the new. While the code will be different, the content and its semantic relevance will remain constant because content is extracted from the code to perform such operations.
Moreover, it would be ideal for the pre-existing content on BB&B to remain live on its URLs so the existing link equity is captured and combined with that of the redirected Overstock content. After all, that is the primary value SEO value of the domain. These pages should then have links to similar products in the Overstock inventory. If the taxonomies can be merged and topical clustering reinforced, even better. They should also carefully consider how to implement any messaging related to an item being out of stock so it doesn’t trigger a Soft 404. Failing that, the team could consider a large outreach effort wherein they request that sites update their links to point to the closest matching replacement product for the Overstock inventory.
Keep in mind that I’m talking about ideal conditions. Overstock may not have brokered the pre-existing content as part of the deal. The turnaround time may have been too quick to account for them. Or, they may be actively rebuilding relationships with the brands that BB&B previously worked with to get those products on the new site. They may also have other technical or operational challenges that make it difficult for the most optimal implementation. Frankly, that’s the most common issue with large sites. There’s no way to know from the outside, but knowing the skillset of some of the people in the organization, I’m sure it’s all well under control. So, let’s talk more about scaling the mapping.
Using Dense Vector Embeddings to Map Redirects
I don’t know if I have been loud enough about how much vector embeddings rule the world right now. At this point, I would find more value in a vector index of the web than I do from a link index of the web. After all, vector embeddings power search engines, large language models, and a host of other applications that are driving the web and other technologies forward. I continue to be befuddled by how much SEO tools don’t use them. After I walk through this, I suspect you will see how valuable it would be for a link index to provide embeddings as part of their datasets.
To combat the potential for Soft 404s, we need to map redirects using semantic similarity. Recently, I discussed how search engines measure relevance by computing the cosine similarity of vector embeddings. This is also how Google may compute content parity in determining whether the source and target of the 301 redirect are related. To compute the semantic distance between a previously indexed and new content at the same URL it is likely that if it is within a certain threshold then the redirect is valid and passes link equity. If it’s not that then it Soft 404s.
I’ll leave you with a Colab notebook so you can do it in Python, but the approach is as follows:
- Crawl each BedBathAndBeyond.com
- Extract the content from HTML
- Vectorize the content
- Store the URL and the vectorized content and in a vector database
- For each Overstock.com URL
- Crawl each URL
- Extract the content from HTML
- Vectorize the content
- Search the vector database to find the URL to get the closest semantic match
- Use this resulting URL as the redirect target
Internally, this would be far easier to do than it will be externally because of crawl throttling. There’s a possibility that the Overstock team has direct access to the historical content from BedBathAndBeyond.com so they could simply go through a database table and vectorize. We’re on the outside though, so let’s talk about how we’ll do it.
Getting this Started in Python
If you want to skip to the punchline, grab this Colab notebook with the completed code. Otherwise, I’ll go through the steps of how you set this URL mapping functionality up in Python. For a site this size, I recommend you run this code from the command line, but you can also subscribe to Coalb or run it from a Jupyter notebook.
Install the Libraries
The first thing you’ll need to do is install the libraries that will do most of the heavy lifting. We’ll need requests for crawling, Beautiful Soup 4 for HTML parsing, Tensorflow, and Tensorflow Hub to encode embeddings and the Pinecone client to access the vector database.
pip install requests beautifulsoup4 tensorflow tensorflow_hub pinecone-clientInstall the libraries with the code above. In Colab, you’ll see that most of these are already satisfied. If you’re at your CLI, you’ll likely see messages related to downloading and installing packages.
Import the Libraries
In your IDE (preferably VS Code), create a file and import those libraries into our code so we can access the functionality.
import requests
from bs4 import BeautifulSoup
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
from urllib.parse import urlparse
import pinecone
import csv
import concurrent.futures
from requests.adapters import HTTPAdapter
from urllib3.util.retry import RetryI’ve also included some other built-in helper libraries like NumPy, URLLib, and CSV to help with parsing data and saving data to a CSV file once we’re done, Concurrent so we can run operations simultaneously.
Configure Retries on Requests
Using the following code, I configure the crawling mechanism to retry URLs and progressively slow down the crawling if there are timeouts. Since we’re only using the Wayback Machine here, this is enough for our needs, but for crawling sites of these sizes you may want to consider proxies or using a headless browser like Puppeteer with stealth plugins. Keep in mind that the latter will slow things down considerably.
session = requests.Session()
retry = Retry(connect=3, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)Using the Wayback Machine API for BB&B
Normally, we’d crawl both the BB&B and Overstock to vectorize the content, but BedBathAndBeyond.com had a lot of throttling happening and full sections of the site were difficult to reach when I started this post. When that happens, the next best thing is to pull down someone else’s crawl of the site. Who better than the good folks at the Internet Archive who save a large portion of the web on a daily basis?
The Wayback Machine has an endpoint that returns all the URLs in the archive for a given domain. We limit it to those that are of the text/html mimetype. Then we individually retrieve the HTML from those URLs and extract the text. The following code does just that.
# URL for the Wayback Machine CDX Server API
CDX_API_URL = "http://web.archive.org/cdx/search/cdx"
def get_crawled_urls(domain):
"""Return a list of unique URLs crawled by the Wayback Machine for a specific domain."""
payload = {
'url': domain,
'matchType': 'prefix',
'filter': 'statuscode:200',
'filter': 'mimetype:text/html',
'collapse': 'urlkey',
'output': 'json',
'fl': 'original,timestamp'
}
response = session.get(CDX_API_URL, params=payload)
if response.status_code == 200:
return [(item[0], item[1]) for item in response.json()[1:]] # return both URL and timestamp
else:
return []
def download_html(url, timestamp):
"""Return the HTML of the page at the Wayback Machine URL."""
wayback_url = f'http://web.archive.org/web/{timestamp}id_/{url}' # create Wayback Machine URL
response = requests.get(wayback_url)
return response.text
def extract_text(html):
"""Return the visible text from the HTML."""
soup = BeautifulSoup(html, 'html.parser')
[s.extract() for s in soup(['style', 'script', '[document]', 'head', 'title'])]
visible_text = soup.getText()
return visible_textCrawling Overstock.com
Crawling Overstock.com is standard technical SEO fare. We could point a crawler at it and let it rip or we could use the XML sitemaps. I did not include a crawler here because of the edit below, but you could easily build one with the advertools library.
Vectorizing Content with the Universal Sentence Encoder
Just as we discussed in the relevance post, we’ll be using the Universal Sentence Encoder to convert the text for these pages into vector embeddings. See that post for more details on what all that means. Basically, we’re converting documents into a series of fixed-length vectors to then compare the values for Overstock.com and BB&B to determine the closest matching URL.

Alternatively, you could use OpenAI’s Embeddings API. Some argue that those embeddings are actually the best available. For SEO use cases, however, I prefer to use something Google built with the hope that we are closer to what they use in production, although, it may not actually matter. Perhaps in a future post, I’ll compare the results of the different types of embeddings, especially considering Sentence T5-XXL is a higher performer on the embeddings leaderboard.
To encode pages we simply extract the text from the code and hand it off to the USE which then returns the embeddings. We then store the embeddings in a Pinecone vector database. You could also use a library like Facebook’s FAISS or Google’s SCANN to do the same, but these are two big websites, so we don’t want to run into memory limitations.
Using USE requires we first load the model from the TF Hub to instantiate the encoder.
# Universal Sentence Encoder
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"encoder = hub.load(module_url)Then we create a function we can hand text off to for generating the embeddings.
def convert_to_embeddings(text)
"""Convert text to embeddings using Universal Sentence Encoder."""
embedding = encoder([text])[0].numpy()
return embedding.tolist() # Convert numpy array to Python listYes, it is that easy. It’s a wonder that SEO tools are not using these resources.
Storing Vector Embeddings in a Pinecone Database
The next step is to store the BB&B vectors in a vector database. This allows us to search using vectors to find the closest matching URL based on nearest neighbor searches. As you might imagine, there are many options to choose from for vector databases like Pinecone and Weaviate. Traditional databases like PostgreSQL and ElasticSearch also have plugins that let you convert them into vector stores. We’re using Pinecone because it was the easiest one I’ve found to get started with.
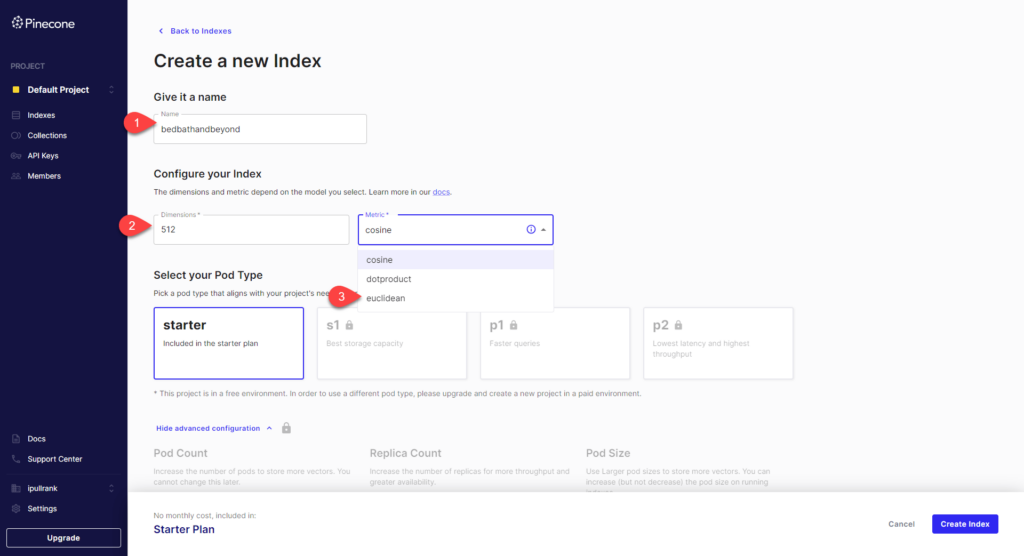
To get started you’ll make a free account. Then create an index through the UI. Here are the things you’ll need to configure.
- Give your database name
- Set your dimensions to 512
- Select metric. For our example, I’m using Euclidean.
If you don’t create the database using the UI, the code will create one for you.
Once you’re done, you’ll need to click on API keys and collect both your key and the environment that your index lives in. There are markers in the code below where you’ll place this information.
In our code, our main function brings this all together. In the code that follows you first initialize Pinecone using the API key and environment provided in the UI. Then it creates an index if it does not already exist and instantiates the index. Then it gets the URLs from the source domain from the Wayback Machine and loops through them concurrently (with our process_url function) to pull the HTML from the Wayback Machine converts them to embeddings and upserts (update or insert) them into the Pinecone database.
def process_url(url_timestamp):
url, timestamp = url_timestamp
print(f'Processing URL: {url}')
html = download_html(url, timestamp)
text = extract_text(html)
embeddings = [convert_to_embeddings(text)]
# Send URL and embeddings to Pinecone
index.upsert(vectors=[(url, embeddings)])
def main():
# Initialize Pinecone
pinecone.init(api_key="[YOUR API KEY HERE]", environment="[YOUR ENVIRONMENT HERE]")
# Create an index
index_name = "[YOUR INDEX NAME HERE]"
if index_name not in pinecone.list_indexes():
pinecone.create_index(name=index_name, metric="euclidean", shards=1, dimension=512)
# Instantiate index
index = pinecone.Index(index_name=index_name)
domain = "[THE SOURCE DOMAIN HERE]"
urls = get_crawled_urls(domain)
for url, timestamp in urls:
print(f'Processing URL: {url}')
html = download_html(url, timestamp)
text = extract_text(html)
embeddings = [convert_to_embeddings(text)]
# Send URL and embeddings to Pinecone
index.upsert(vectors=[(url, embeddings)])
print (<span style="font-family: monospace, Consolas, 'Courier New', monospace; font-size: 14px; text-wrap: nowrap; font-weight: var( --e-global-typography-text-font-weight ); color: #a31515;">"All finished!"</span><span style="background-color: #f7f7f7; color: #000000; font-family: monospace, Consolas, 'Courier New', monospace; font-size: 14px; text-wrap: nowrap; font-weight: var( --e-global-typography-text-font-weight );">)</span><br />
if __name__ == "__main__":
main()BedBathdndBeyond.com has 501k+ URLs in the Wayback Machine so we sped this up by using concurrency. At this point, there’s no definitive way for us to know how many URLs BB&B had historically from the outside, but we’re able to get a solid amount programmatically. Nevertheless, the process will be very slow for a large website. Once it’s completed, you can query against the database to build redirect maps.
Querying Pinecone for Redirect Mapping
Mapping the redirects follows the same approach as building the index except we don’t need to index the source site unless we want to. I didn’t because the free tier of Pinecone only allows for one index and it deletes it if your data after 7 days of inactivity. So, we’ve vectorized the source URLs from BB&B to query the index to get the single best match for the redirect mapping. Then the script saves it all to a CSV. Again, with so many URLs this will take some time to complete.
def process_comparison(url_timestamp):
url, timestamp = url_timestamp
print(f'Processing URL: {url}')
html = download_html(url, timestamp)
text = extract_text(html)
queryVector = convert_to_embeddings(text)
# Query Pinecone index
query_response = index.query(
top_k=1, # Change this as per your needs
include_values=True,
include_metadata=True,
vector=queryVector,
)
print ("Mapping: " + url +" - " +query_response['matches'][0]['id'])
return (url,query_response['matches'][0]['id'])
def query_comparison():
# Initialize Pinecone
pinecone.init(api_key="[YOUR API KEY HERE]", environment="[YOUR ENVIRONMENT HERE]")
index_name = "[YOUR INDEX HERE]"
# Instantiate index
index = pinecone.Index(index_name=index_name)
domain = "[YOUR SOURCE DOMAIN HERE]"
urls = get_crawled_urls(domain)
with open(domain + '-urls-mapped.csv', 'w') as f:
write = csv.writer(f)
write.writerow(['Source',"Target"])
# We create a ThreadPoolExecutor
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(process_comparison, urls)
for result in results:
write.writerow(result)
print (<span style="font-family: monospace, Consolas, "Courier New", monospace; font-size: 14px; text-wrap: nowrap; font-weight: var( --e-global-typography-text-font-weight ); color: rgb(163, 21, 21);">"All finished!"</span><span style="background-color: rgb(247, 247, 247); color: rgb(0, 0, 0); font-family: monospace, Consolas, "Courier New", monospace; font-size: 14px; text-wrap: nowrap; font-weight: var( --e-global-typography-text-font-weight );">)</span><br>
query_comparison()Looping through the whole list of URLs, we now have our redirect mappings in a CSV that can be used to generate 301s on the edge, in Apache, or Nginx quite easily.
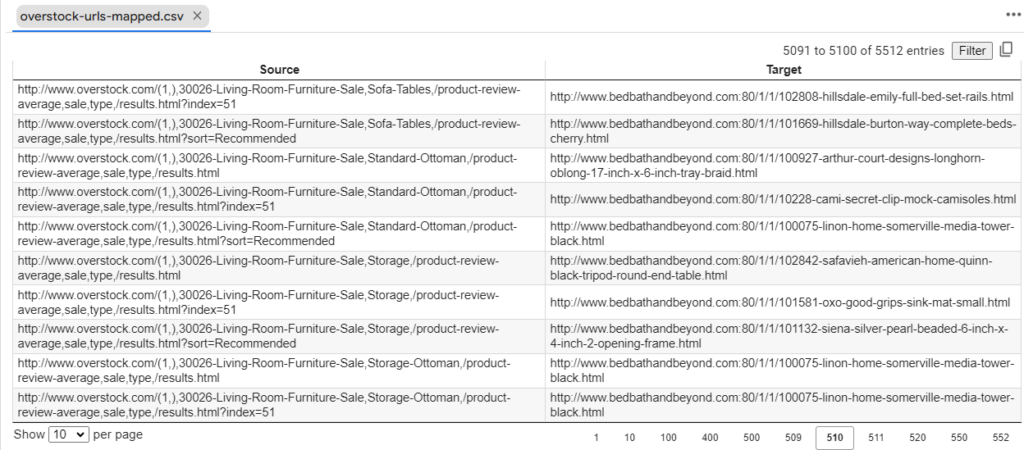
Here’s the Colab of all the code for you to play with. This version uses the Wayback Machine, but if you want to adjust this for a live crawling you’d want to adjust the code such that the crawling and vectorizing happen together.
Use this to Inform Internal Linking Too
The Overstock -> BB&B Migration Has Already Started
I started writing about this when the purchase was announced, but other priorities came up between then and now. Since then, the Overstock team has begun the migration. If you head to the homepage, you’ll see what looks like Overstock.com with a BB&B skin as compared to what BB&B used to look like. Here are some screenshots for to give you an idea of the changes.
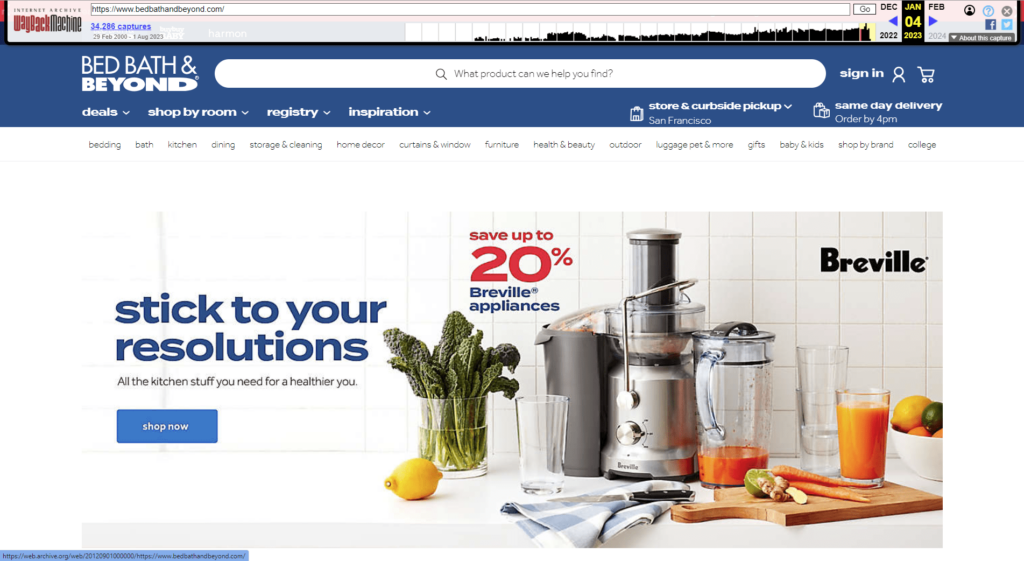
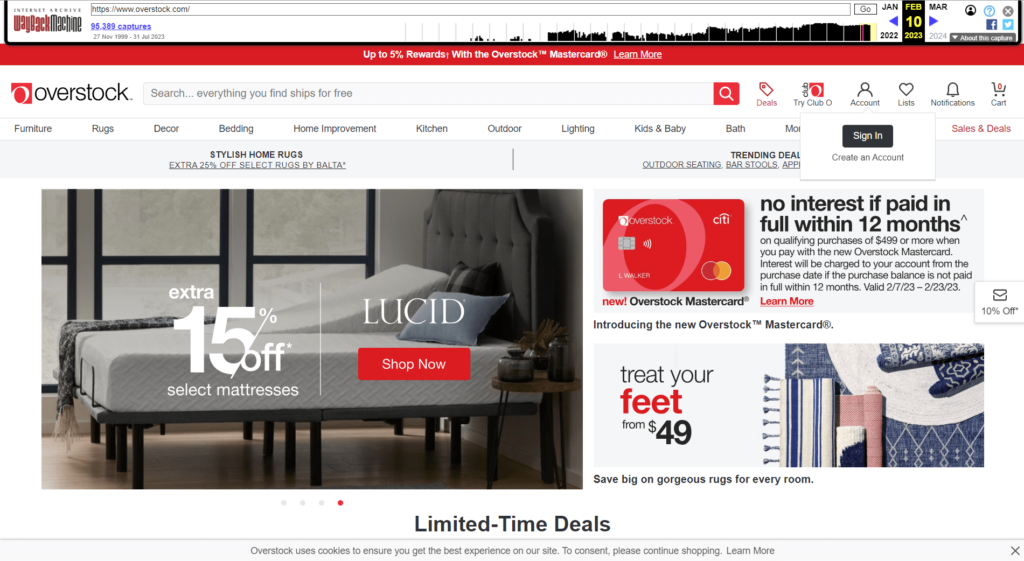
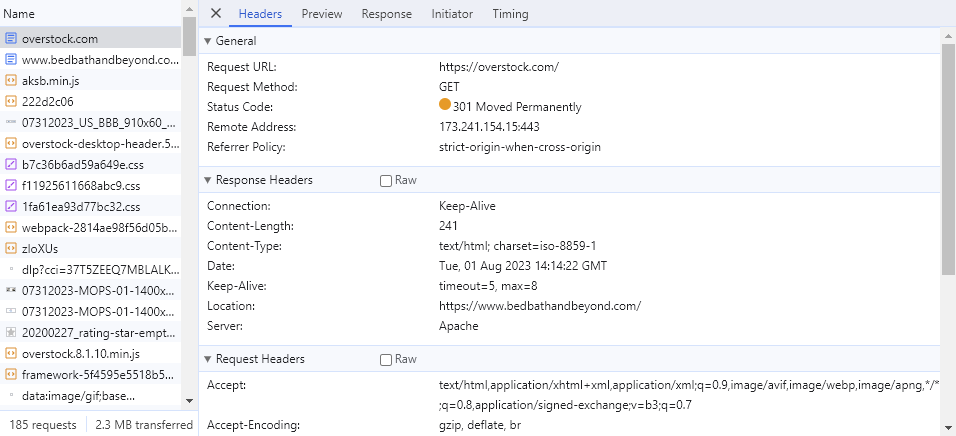
If you go to Overstock.com right now, you’re 301 redirected to BedBathandBeyond.com.
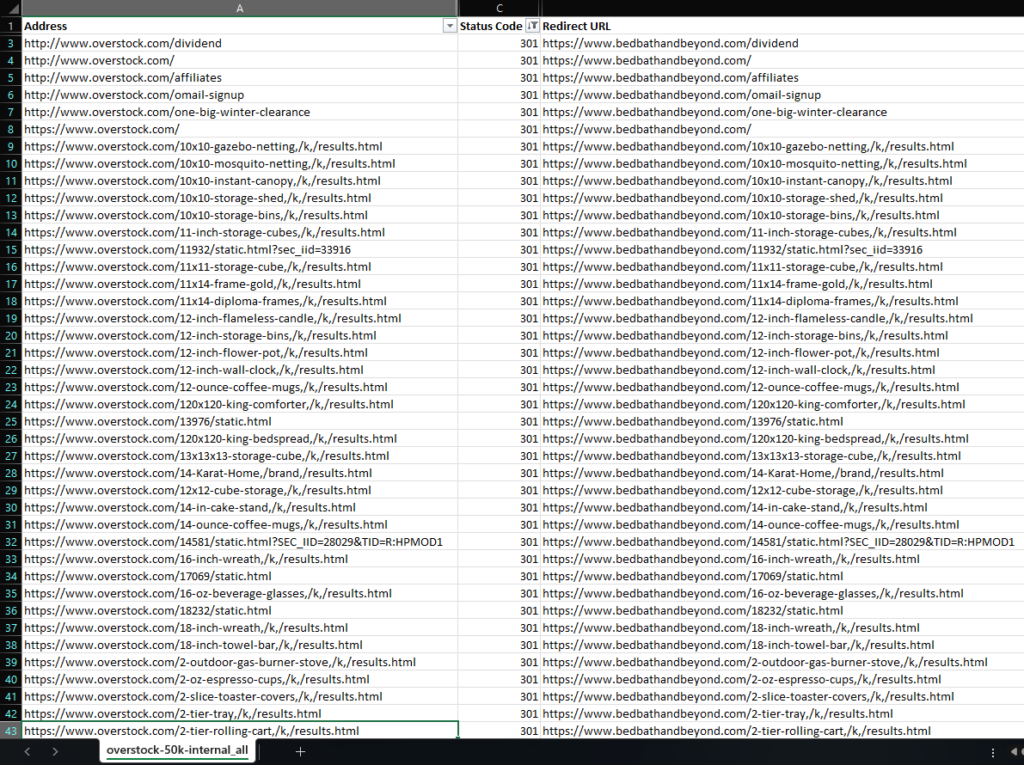
In fact, when I download 50k of the top URLs from Semrush, and crawled them using Screaming Frog SEO Spider, 99.8% of URLs are 301 redirected. The 0.2% of URLs that are not redirected are on the help.overstock.com subdomain. That’s pretty damn good for an initial rollout!

Reviewing those URLs indicates that Overstock did a lift and shift because all of the URLs remained completely intact. In this case, it appears that they reskinned the design of Overstock.com and pointed the BedBathAndBeyond.com domain to their servers. Then they set up redirects on Overstock.com to point to the corresponding new URLs on BedBathAndBeyond.com.
Organizations of this size with large sites like this usually launch such migrations in stages. As of right now, the migration implementation is not feature complete as it relates to the ideal specification, perhaps for the reasons I highlighted previously. When I pull the top 75k pages by links from Ahrefs, some of the URLs from the old BB&B site have been redirected to the homepage.
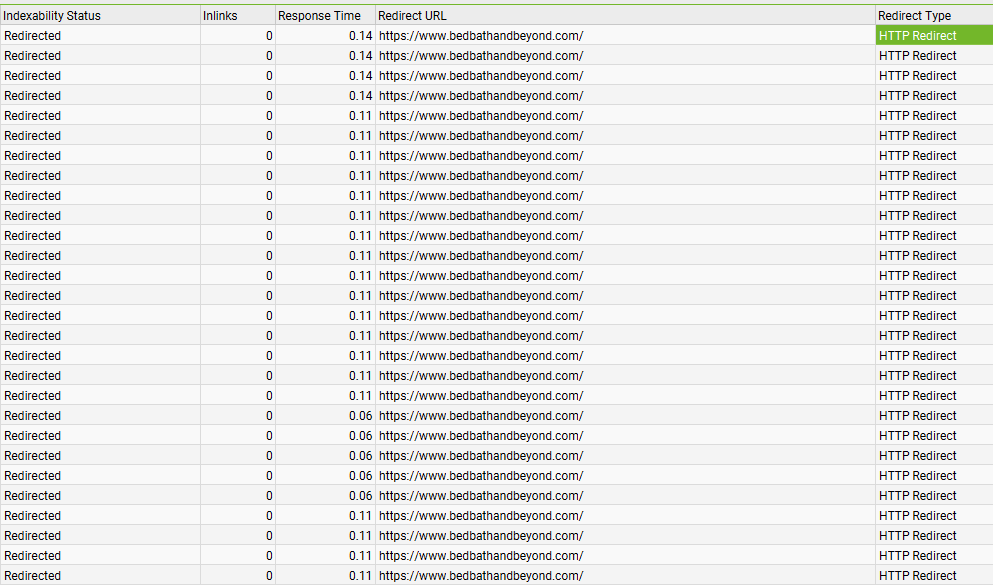
Reviewing that data further indicates that 37.99% of the URLs 404. However, it’s hard to know if this is a function of any categories or products that BB&B may have previously sunset prior to this migration.
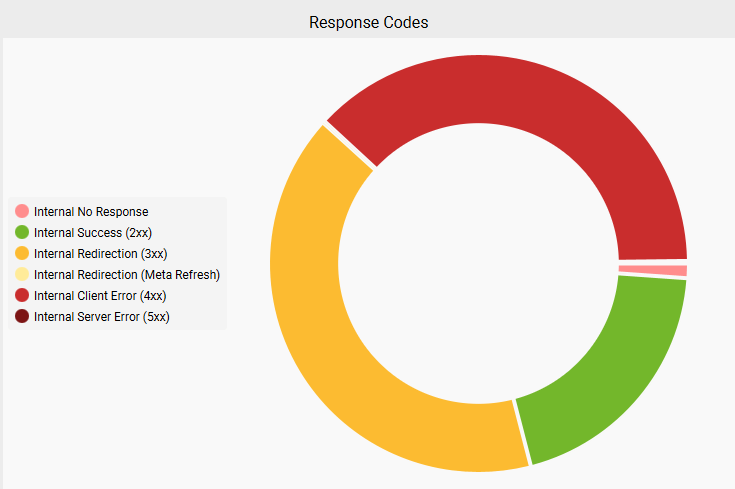
Ahrefs’s broken link report indicates 69.1K links point to pages that no longer exist. This number keeps growing every time I check it, so I suspect we will see it balloon as Ahrefs re-crawls more of the web.
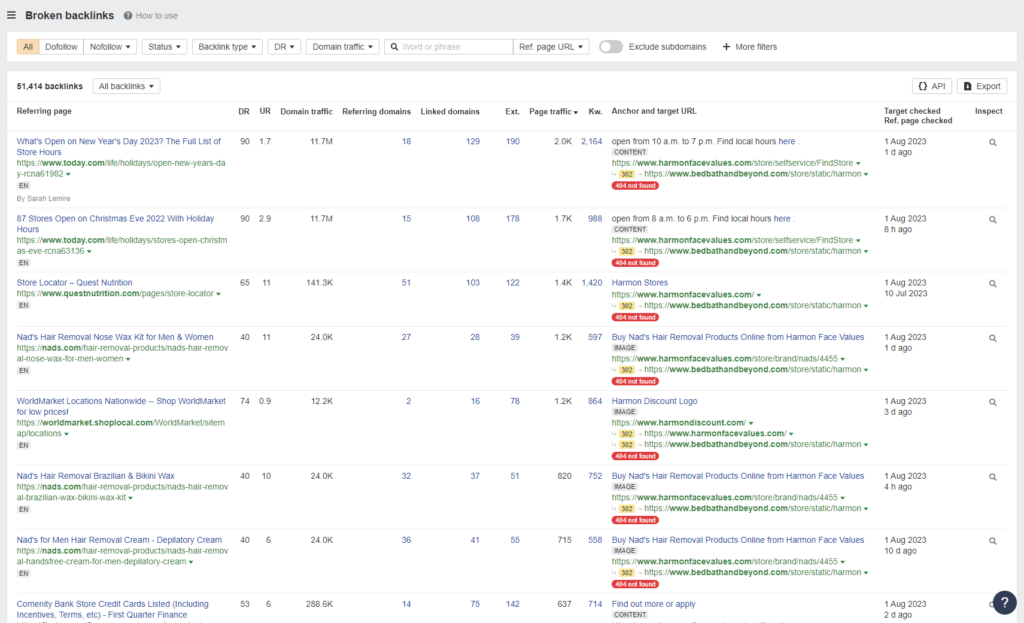
Again, both of these sites are large and complex. I anticipate that this is a work in progress and the team at Overstock is actively cleaning things up. Let’s check back in a month to see how it’s going.
Now, over to you, what approaches have you taken for scalable redirect mapping?







