
Your robots.txt file is a set of directions that lets search engines know which pages from your website should be crawled by search engines.
The robots.txt file is often misunderstood by SEOs. It’s not intended to block pages from being indexed. But misused, it can have severe consequences.
Add the wrong instruction and you could unintentionally tell Google to completely remove your website from the search results.
The importance of a properly set up robots.txt file cannot be understated. Learn how to correctly configure your robots.txt file, use it to your advantage, and avoid disaster.
Table of Contents
What is a Robots.txt File?
In simple terms, your robots.txt is a plain text file with instructions for web robots (also known as “spiders” or “bots”) that guides how the site should or shouldn’t be crawled. The robots.txt file is found in the root of the website and can be brought up by appending “robots.txt” on the homepage of a website.
https://www.example.com/robots.txt
Most major CMS platforms provide ways to edit the robots.txt either through their dashboard or through the use of plugins that don’t require a new text file to be created and saved every time a change is made.
Google, Bing, Yahoo, etc.
All search engines have these spiders that crawl the internet. Most search engine crawlers will respect a robots.txt file, but it’s not a failsafe as some may not. The robots.txt file serves as instructions for crawlers on how they should navigate your site.
If you have a smaller website then the importance of blocking crawlers from areas of your site may not be of concern. If you are operating a large ecommerce website with millions of pages, it is paramount that your robots.txt file be set up to block certain pages from being crawled. Large ecommerce sites tend to use faceted navigation or filters for their product pages. This can create endless amounts of parameterized URLs that do not need to be indexed. This can lead to index bloat as well as crawl budget issues if crawlers need to crawl through millions of parameterized URLs.
Things that are commonly included in a robots.txt file:
- User-agent: Specifies the web crawler to which the rule applies. A * can be used to apply the rules to all web crawlers.
- Disallow: Indicates which URLs or directories the specified web crawlers are not allowed to access.
- Allow: Specifies exceptions to the Disallow directives, indicating which URLs or directories the specified web crawlers can access. This is particularly useful for allowing access to a specific file within a disallowed directory.
- Sitemap: Provides the URL to the website’s sitemap, which helps crawlers find and index content more efficiently.
- Crawl-delay: Sets the number of seconds a crawler should wait between making requests to the server. This can help manage server load.
- Noindex: Directs crawlers not to index specific URLs. However, it’s important to note that the Noindex directive in a robots.txt file is not officially supported by all search engines, and using meta tags on the page itself is a more reliable method.
The structure of a robots.txt file is straightforward.
Each section consists of a user-agent(s) and a set of directives.
User-agent: (Name of the user-agent)
Disallow: (URL string you would not like to be crawled)
Allow: (URL string you want to be crawled)
Note: Wildcards and characters
Within the User-agents and Directives we can see a wildcard (*) and special characters (#, $). These provide additional information to crawlers about what can and cannot be crawled and we’ll discuss those further down.
User-agent
The “user-agent” declares the specific crawler. An example calling out Google and Bing would look like this:
User-agent: Googlebot
User-agent: Bingbot
Other examples of standard search engine crawlers and their user-agent are:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Yandex: YandexBot
- Duckduckgo: DuckduckBot
KeyCDN has a more comprehensive list of web crawlers out there.
User-agent Pro-tips:
- User-agents are case-sensitive and need to be entered correctly to make sure that the robots.txt file will properly block any crawlers called out.
- You can define as many user-agents as you like but if a user agent is listed twice, the second listing is the one that will be respected.
- Some search engines, like Google, have multiple user agents that will crawl for different reasons. Some of these user agents include
- Googlebot-News – Google News
- Googlebot-Image/1.0 – Google Images
- Googlebot-Video/1.0 – Google Video
- AdsBot-Google – Google Ads
- With the release of ChatGPT browser extensions some sites are looking to block ChatGPT from scraping their sites to generate answers as they don’t want their information taken with out proper citations. ChatGPT uses the user agent “ChatGPT-User” and can be blocked or allowed to crawl through directives like:
User-agent: ChatGPT-User
Disallow: /
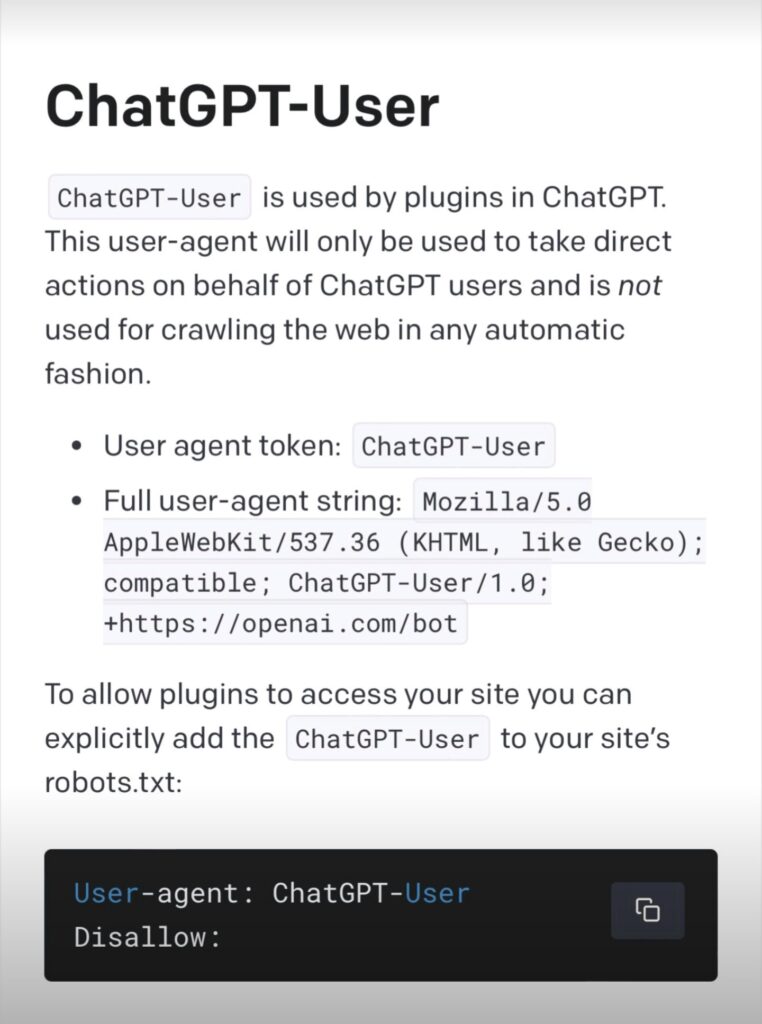
Source: https://platform.openai.com/docs/plugins/bot
The above example shows how to block ChatGPT from crawling your entire site. If you’d like it to crawl your site you could leave the disallow blank or use the “Allow” directive and list out the areas of your site you’d like ChatGPT to crawl.
Disallow and Allow Directives
Your robots.txt directives command the bots to either “Disallow” or “Allow” crawling of certain sections on your website. The “Disallow” directive tells crawlers that they are not allowed to crawl a specific page or subfolder of your site.
Before you start allowing and disallowing crawlers on your site, make sure you have a proper understanding of your website’s structure and what folders you do and don’t want to be crawled and indexed.
- Don’t look at a robots.txt file as a way to “hide” pages.
- Ensure you’ve selected the right sub-folders for crawling.
Let’s look at a disallow directive in action:
Disallow: /resources/
In the example above, we are disallowing the ‘resources’ subfolder. The resources section of the website would be off-limits to robots for crawling.
Using the “Allow” directive lets crawlers know where in the site they can crawl.
Many SEOs get thrown off by the trailing slash “/”. For the robots.txt file, a trailing slash “/” indicates that crawlers can crawl anything that comes afterward. In the case of crawling the entire site, it is more common to leave a blank “Disallow” directive than add a “/” to an “Allow” directive.
So why does the allow directive even matter? Consider a situation where you want an entire subfolder disallowed with the exception of one specific page. The “Allow” directive offers more granular control over crawling.
In the example mentioned above, if you wanted crawlers to be able to crawl a certain resource page the directives would look like this:
Disallow: /resources/
Allow: /resources/important-page/
Now the crawlers know that they can crawl the single resource page being called out in the directives, but not the entire subfolder.
Pro-tips for directives:
- When setting up the directives for your site, it is common practice to block pages that can include sensitive information.
-
- For an ecommerce site that could entail the shopping cart and checkout pages
- For a financial site it could be login pages
- For large ecommerce sites it is also common practice to block parameterized URLs from faceted navigation to be blocked to reduce index bloat.
- If you are using Shopify as a CMS it is worth noting that it comes with an out-of-the-box robots.txt file setup that can work for most sites. Until recently, the ability to edit this file was not allowed but is not possible to do.
Additional Directives
Beyond the standard Disallow and Allow directives, there are a few more directives that are commonly used by SEOs.
Sitemap:
You can include an XML sitemap in the robots.txt file using “Sitemap:” These can be added anywhere but best practice is to place them at the end of the file after all the directives. This would look like:
Sitemap: https://www.mysite.com/sitemap.xml-1
Sitemap: https://www.mysite.com/sitemap.xml-2
Sitemap: https://www.mysite.com/sitemap.xml-3
If you have more than one XML sitemap add the ones you’d like crawled most often or the main Index URL if you have your XML sitemaps grouped together in an index file. Google has stated they will only crawl the first 500kb of a robots.txt file and adding too many XML sitemaps can cause them to make the file too large.
Crawl-delay (Deprecated for Google):
The Crawl-delay directive slows down the speed at which crawlers can crawl through your site. This could be utilized if you have a large site and want to limit the number of requests the crawlers can make to your site. This can eliminate the possibility of a crawler overwhelming your servers with too many requests and potentially crashing your site. This is a very rare occurrence and would require log file audits to fully understand how often crawlers are hitting your website.
Google has stated that they stopped recognizing this directive in 2019 (source) but crawlers like Bing still recognize it.
Using a crawl delay directive would look like this:
User-agent: Bingbot
Crawl-delay: 4
This will force the Bingbot to wait 4 seconds between each crawl request on the site.
Special Characters
Robots.txt files employ the use of some special characters that allow for fine-tuning what or who you want crawling your site.
* wildcard
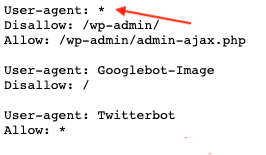
Wondering what that asterisk does in the Robots.txt file? This is known as a wildcard. The wildcard on its own includes ‘everything’. It can be used as the user-agent to include all crawlers or in the directives to designate the entire website or everything that follows a folder in a URL structure like:
User-agent: *
Disallow: /my-folder/*
This blocks all crawlers from crawling everything in the /my-folder/ category.
$ wildcard
In addition to the * wildcard, you can also use a $ wildcard to signify the end of a URL string.
An example of this would be:
User-agent: *
Disallow: /folder-name/*.xls$
This will tell crawlers they cannot crawl any URLs that end with .xls in /folder-name/.
If there are parameter options for the file, like /folder-name/file-name.xls?id=123456, then crawlers would be able to crawl the file. The “$” is not widely used as it can be can confusion about how to use it as well as some crawlers not respecting the directive. There are better ways to do what the “$” does by using the “*” wildcard.
# Hashtag
Hashtags “#” can be used to add notes in your robots.txt file.
Similar to programming comments that don’t impact the code, this can be used to leave notes in the file for future human users as crawlers will ignore the notes.
Some companies have taken advantage of this and added fun notes to their robots.txt files.

Noindex and Nofollow (Deprecated)
Remember that confusion around using the robots.txt file for preventing indexing? Well, there used to be a Noindex and Nofollow directive, but Google stopped recognizing the Noindex directive in 2019.
The Nofollow directive was never recognized. Best practice is to use these directives as on-page metatags.
For the sake of understanding how it used to function, these directives would appear as follows:
User-agent: Googlebot
Noindex: /resources/
Nofollow: /resources/
4 Ways Your Robots.txt Files Can Destroy Your SEO
You’d think that the simple series of commands in a robots.txt file wouldn’t impact SEO performance. This couldn’t be further from the truth.
Even with the simplicity of the file, it can have devastating impacts on a site when implemented incorrectly.
I have seen sites crippled by improperly deploying their robots.txt files.
One site was a large college aggregator site that did not remove the “/” from the disallow directive and Google hit this directive and marked the entire site as blocked by robots.txt.
We corrected the robots.txt file immediately and did everything we could to get Google to crawl the site again, such as resubmitting XML sitemaps and requesting indexing on pages in GSC, but the damage was done. It took over a week before the homepage was crawled and indexed and it was a painfully slow process of getting pages indexed.
After 3 months only 100 of the 200 initial pages had been indexed.
Robots.txt Problem #1: Case-sensitivity
Remember, all parts of the robots.txt file are case-sensitive. Using a capital or lowercase letter where it’s not meant to could result in your directives being ignored.
User-agent: googlebot
User-agent: BINGBOT
It is possible that the user agents would not be recognized as they are written with the proper case sensitivity.
Robots.txt Problem #2: Trailing slashes
One mistake that can cripple a website is using the “Disallow” directive and leaving a trailing slash in it like:
User-agent: *
Disallow: /
This tells crawlers they cannot crawl your website. This is sometimes done when a website is being built without a staging environment to keep the website out of search indexes while it’s being built. When the site goes live, it is imperative to make sure this has been changed to:
User-agent: *
Allow: /
Or…
User-agent: *
Disallow:
This ensures that crawlers can crawl your site. By leaving the “Disallow” directive in you can end up with “Blocked by Robots.txt” errors in GSC and depending on how long you leave it could cause your site to take longer to get indexed.
From previous experience, I have seen clients launch a new site with the site blocked by the robots.txt and it took Google over 2 weeks to start indexing the website, and after 1 month only 60% of the URLs had been indexed.
Robots.txt Problem #3: Conflicting directives
Issues can also arise if there are conflicting rules in place. An example of conflicting rules could look like:
User-agent: *
Disallow: /resources/
Allow: /resources
This can be confusing to crawlers and different crawlers may react differently to these directives. Google and Bing will respect the directive with more characters. “/resources/” is 1 more character than “/resources” and would recognize the disallow.
Some crawlers may recognize the first one but leaving it up to crawlers to choose the correct directive is not a wise decision as they may choose incorrectly or they could change how they look at multiple directives and suddenly you have parts of your website being crawled that you didn’t.
Robots.txt Problem #4: Large Files
Another lesser issue is having a robots.txt file over 500kb. Gary Ilyes recently shared that Googlebot stops crawling a robots.txt file at 500kb.
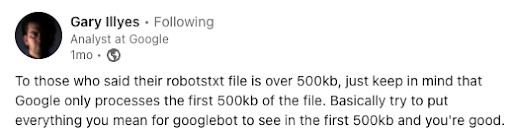
Pro-tip:
You can check the size of your robots.txt file by going to the “Network” tab in Developer Tools on Chrome or you can use Google’s Robots.txt testing tool.
To see pages being blocked by your robots.txt file simply navigate to the “Pages” report in Google Search Console under indexing.
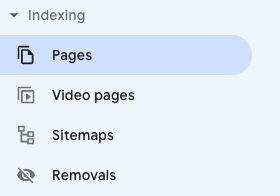
From there, navigate to the “Blocked by robots.txt” section. In this report, you will see a list of the 1000 most recent URLs that have been blocked by your robots.txt file.
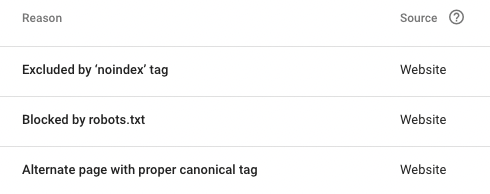
Having URLs appear in this report should not be viewed as a negative as you may have directives calling for certain URLs to not be crawled and indexed.
This can be a common sight on an e-commerce website that uses faceted navigation and has parameterized URLs blocked from being crawled.
By ensuring that you avoid these mistakes you can help your site get crawled and indexed properly and minimize wasted crawl budget on pages you do not want to be crawled and indexed.
A robots.txt file is not going to directly cause your website to rank better and realistically can do more direct damage if implemented improperly. With that in mind, having a properly implemented robots.txt file can help improve the crawling of your site which can improve indexing and that can help your site perform better.
How to Create and Implement a Robots.txt File
There are a few different ways to create and implement a robots.txt file. We will cover manually creating and implementing one on a website as many CMS platforms (like WordPress and Magento) provide plugins that can help you create and implement one. Some CMSs (like Wix) have native robots.txt files out of the box.
- Create a plain text file
Using a text editor (Notepad, TextEdit, BBEdit, etc) create your robots.txt file. An example of a simple robots.txt file that only blocks Bing from crawling the site:
User-agent: *
Disallow:
User-agent: Bingbot
Disallow: /
Sitemap: https://www.example.com/sitemap.xml
After you have finished adding all your directives to your file, save it as “robots.txt” without the quotes.
- Save The Robots.txt File in The Root Directory of Your Site
After you have created the file upload it to your site using an FTP or your websites control panel. If your site uses subdomains you will need to create and implement a robots.txt file for each subdomain. By implementing the robots.txt file on the root domain it will be accessible on example.com/robots.txt.
Below are some examples of different robots.txt files.
Block all crawlers
User-agent: *
Disallow: /
Allow all crawlers
User-agent: *
Disallow:
Block all crawlers from a subfolder
User-agent: *
Disallow: /dont-crawl-this-folder/
Block all crawlers from a file
User-agent: *
Disallow: /dont-crawl-this-file.pdf
Block all crawlers from parameterized URLs
User-agent: *
Disallow: /*?
Robots.txt file creation best practices
We’ve worked through how to create your robots.txt file, using the various user-agents, directives, and wildcard characters. Use these best practices so you’re not sabotaging your site with an unnecessary mistake that’s preventing your site from being crawled:
- When creating your file, ensure that important pages are not blocked from being crawled. This includes the homepage, category pages, and product pages not being blocked from crawling by being included in a “Disallow” directive.
- Make sure that content you do not want to appear in SERPs is being blocked from being crawled. The “Disallow” directive can be used here to block pages that contain private or secure information or parts of a website that does not need to be indexed. It is common to see “checkout” and “cart” pages listed with “Disallow” directives for e-commerce sites as these pages do not need to be indexed.
- When inputting the directives in your file, it is important that all directives use the proper case when it comes to syntax. Improper capitalization can cause errors with your file and return unwanted results with different crawlers.
- The robots.txt file should not be used to try to hide low-quality or spammy files. Along with not using the file to block low-quality content, the robots.txt file should not be the only way you try to stop crawlers from crawling and indexing pages you do not want to be crawled and indexed. Proper on-page SEO can be better in this situation by using “noindex” and “nofollow” tags in the meta robots field on individual pages.
How To Block Google's Bard Vertex AI API with your robots.txt file
On September 28, 2023, Google announced Google-Extended as a new user agent that is tied to their AI services. Site owners can choose to block or allow this user agent if they want the information on their site to be used by Google Bard or Vertex AI APIs. To block this user agent from crawling your site would be:
User-agent: Google-Extended
Disallow: /
Along with this update, Google has also brought a new report into Google Search Console for robots.txt files.
To view this report you’ll need to scroll down to “Settings”
From here you will see the Robots.txt report. Click “OPEN REPORT”
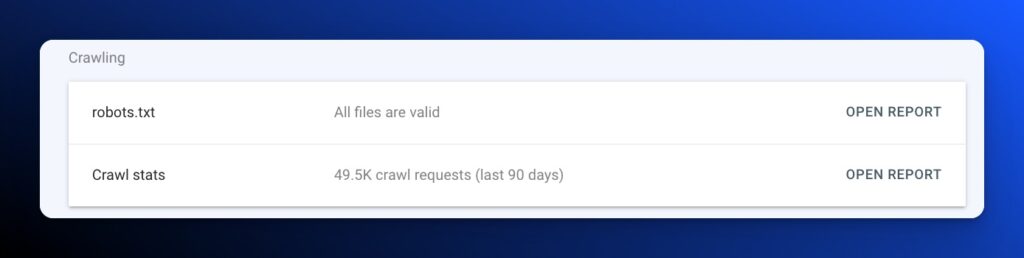
Check to see if Google has recognized your robots.txt file. Identify when it was last read, the size of the file, and if there are any issues with it.
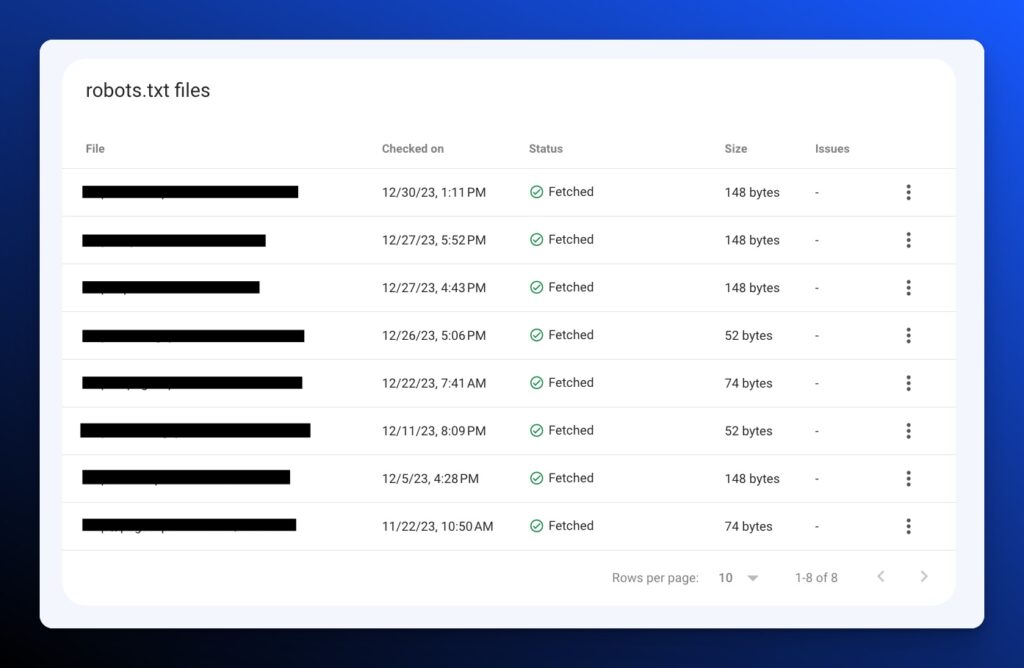
Unfortunately, it doesn’t appear to show any conflicting pages like the previous tool would but this is a new feature that will probably be tweaked as we move forward.
Along with the new report in the settings, there is a new feature in the “Blocked by robots.txt” section of the Pages Report. You can now see what directive is blocking the page in the list. This can be helpful when diagnosing new pages in the report. If these pages were not meant to be blocked by your robots.txt file you can quickly diagnose what’s causing the issue.
Robots.txt: Simple but Powerful
Attention to detail. That should be your mantra for your robots.txt file. Who would have thought that a few lines in a short non-descript file can have such a massive impact on your organic search traffic and website visibility? Your SEO team cannot afford to implement this incorrectly.
If the file is not monitored properly or ignored, you could wake up one day erased from Google search results. Don’t be the villain of the industry’s next SEO horror story.
Need Technical SEO assistance optimizing your Robots.txt file?
iPullRank offers complete Technical SEO audits as part of a larger holistic SEO strategy. Contact us to schedule a consultation.








