Despite all of the changes that have happened since I started doing digital marketing, one thing remains constant, the need to pull down unstructured data from web pages. Many of us call this “screen scraping” or just “scraping.” And you can find hundreds of people on every freelance hiring site that will do this for you for a nominal fee.
Scraping is generally a technical endeavor in that people write custom code to do it. Others have used solutions for Excel or Google Sheets to yank data out of pages. One of the problems is that it has to be consistently monitored in cases where the code structure of the page may change (Hello Google SERPs!). Outside of that there have been a number of point and click solutions that have popped up in recent years. Import.io and Kimono Labs come to mind, but they the latter has been acquired and are phasing out the solution. I’m going to show you a way to scrape that uses the old fashioned coding way, but my hope is that I make it simple enough that even if you’re not a coder you can do it. Let me know how I do in the comments.
One of the big problems with scraping is JavaScript. Most scrapers are text-based, meaning that they don’t load the page the same way a user sees it in the browser. Instead they download, but do not execute, the code entirely. This is because JavaScript requires a virtual machine to interpret the code. Although libraries for this exist, they are not commonplace. Many things that happen after the initial paint on the client side is not shown to most scraping implementations. This is one of the key limitations of most SEO software as well because many of these software solutions are using cURL (a client-side URL transfer library) or something similar for crawling.
Programmatically, you can get around this using a headless browser or with a JavaScript rendering library like V8, but that’s not what we’re going to talk about today. Instead, I’m going to show you how to use your actual browser to scrape.
To be clear, in the title of this post, the accent was on Single.
First, Let’s Talk About Scrape Similar
Scrape Similar (officially “Scraper”) is a Chrome Extension that I have a bit of a love/hate relationship with. You can right-click on text and it will pull all of the text that is similarly formatted and give you the option to place it in a Google Sheet. When it works, it’s pretty magical, but the problem is that it often over-assumes specificity based on what you click.
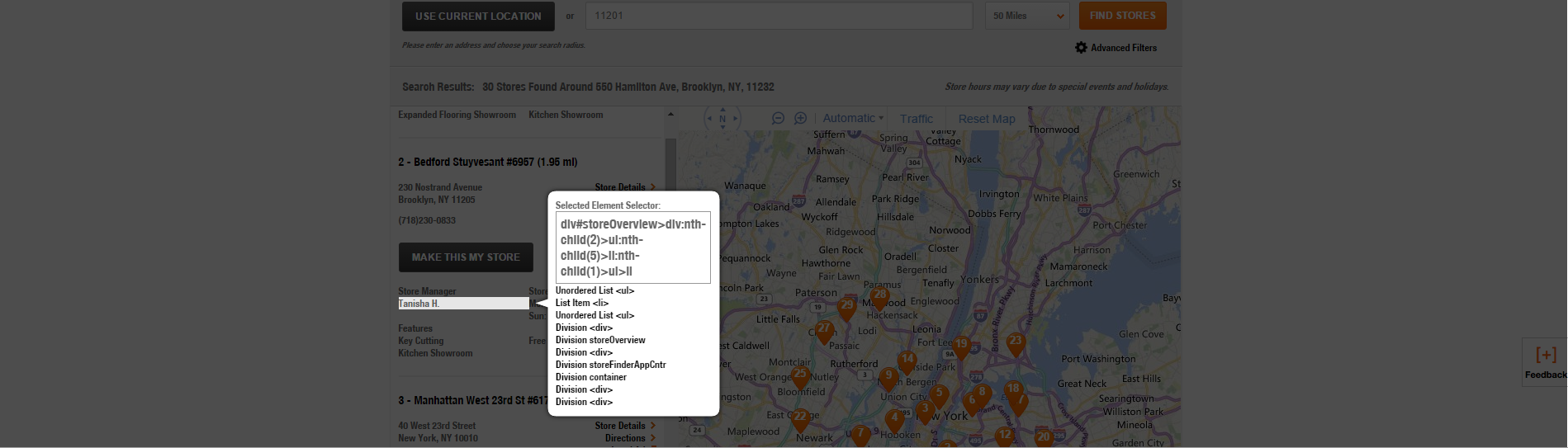
For instance, if I’m looking to get all of the names specified for each of these locations in the Home Depot screenshot below, I’d expect to be able to right click “Nazan P,” click Scrape Similar and get a full list.
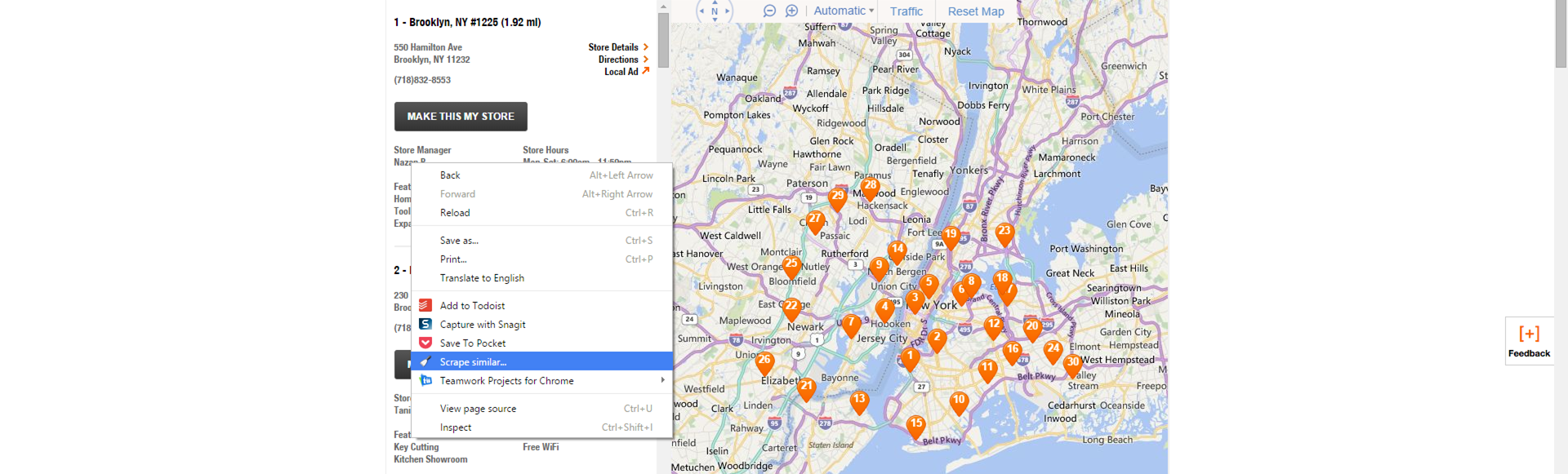
Instead what happens is I get a list of all of the unordered list (ULs) items in that DIV from the XPath that it assumes from my click. The XPath is basically saying, find all of the instances where text is wrapped in a child DIV tag, 3rd child UL tag followed by an LI, UL and LI tag in that order. In this case the DIV tag adds a level of specificity that causes the tool to pull the data that I did not expect from the DOM.
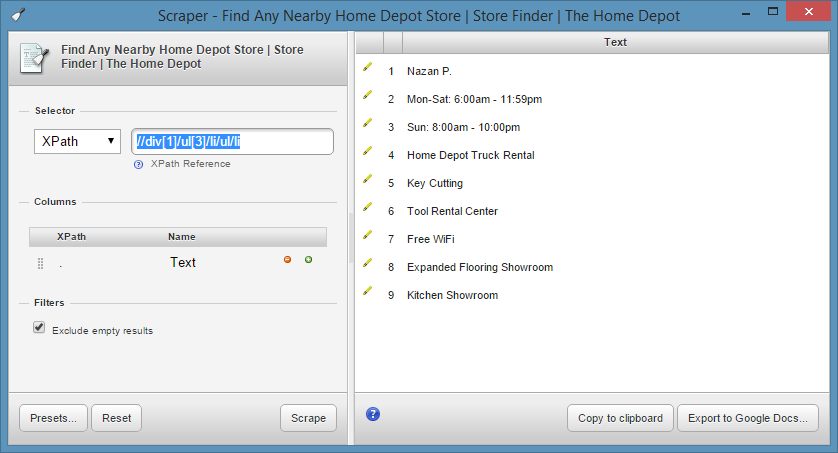
Because I’m not a fan of XPath and I find CSS3 selectors to be a much more fun time, I switch the Selector type to jQuery and then get exactly what I want. In this case, the jQuery reference (ul:nth-child(5)>li:nth-child(1)>ul>li) does not include the div tag at all. Just in case you’re wondering, the XPath equivalent is //ul[3]/li[1]/ul/li.
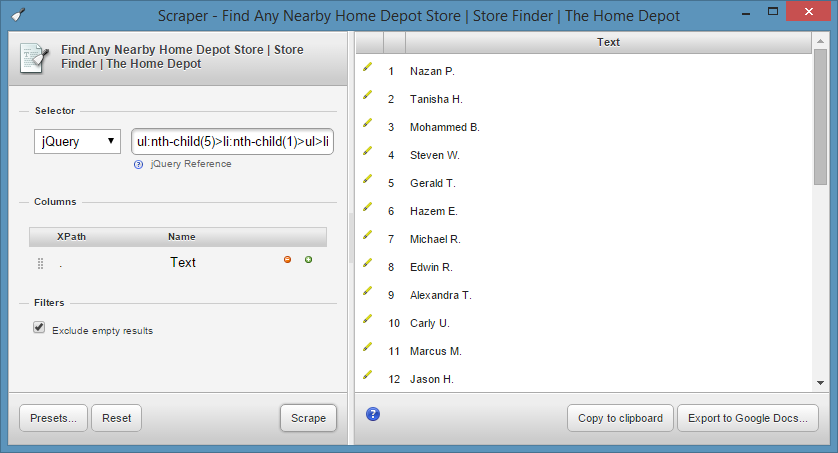
Using jQuery selectors with Scrape Similar is all well and good, but as you can see you cannot capture multiple columns using jQuery like you can with XPath using this tool. That puts us at a disadvantage if we want to get structured data out of a page and into a spreadsheet pretty easily. So, let me introduce you to another way.
Some Background
For this scraping job, we are going to make light usage of jQuery. jQuery is an incredibly popular library of JavaScript functions for many of the common actions that a developer might want to do on the frontend. For example, sliders, animations, showing and hiding components are all common functions in the jQuery cache.
We’re also going to make heavy usage of CSS3 selectors. Many popular scraping techniques leverage XPath or some other method and, honestly, if you’re going to learn XPath, you might as well just learn how to code. But I digress.
The main thing that we are going to do is use jQuery to select the CSS3 selectors and print them to the Console in a format that is conducive to turning it into a spreadsheet. After that, we’ll export the contents of the console and slice and dice in Excel.
What You’ll Need
To make this as painless as possible, you’ll need some things to help you out:
- jQuery Unique Selector – This is a Chrome Extension that determines the selectors for a given element that is clicked. Surely, you can do the same with DevTools in Chrome, but this is an easier to copy and paste. Previously, when I identified the CSS3 selector for the name list I could have used jQuery Unique Selector to quickly find the right one.Now all you’ll need to do is click the magnifying glass, highlight the element you’re looking to scrape and then determine which of the selectors gets you what you want. The tool allows you to be as specific or as vague as you want.
- jQuery-injector Chrome Extension – While 78% of the top million websites have jQuery on them, according to BuiltWith, you will certainly come across pages that do not. Truthfully, a lot of pages user jQuery that don’t really need it, but that’s a different post for another day. Using the jQuery-injector Chrome extension, you can install jQuery into any page at the click of a button and begin manipulating the page using jQuery functions. You can check before you inject by simply typing $ into the console.
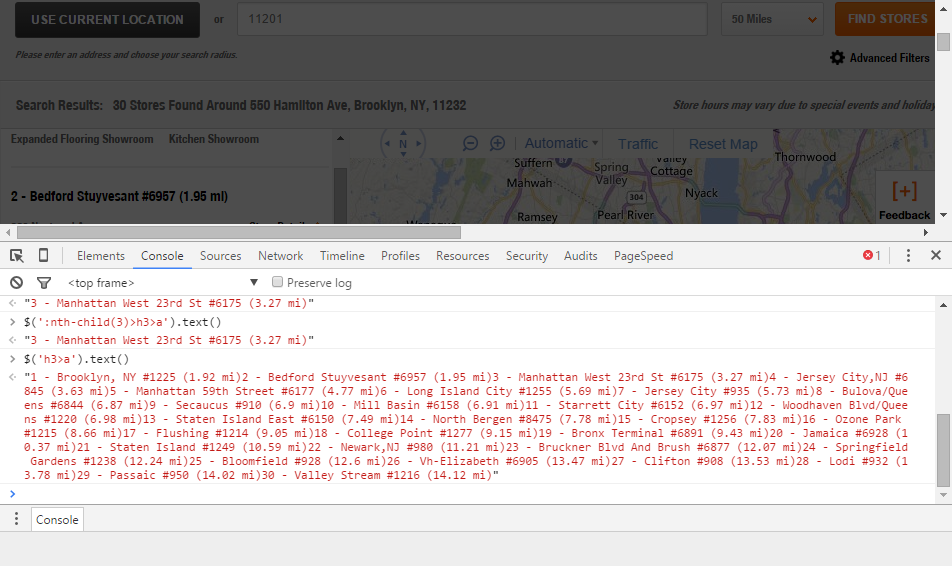
- The Chrome DevTools Console (you already have this is you use Chrome, just hit Ctrl+Shift+I) – This is where you’ll be entering jQuery functions to select data. Here’s an example of me pulling the third result’s location name and then pulling all of the results location names.
How to “Select” in jQuery
Most of what we’re doing here is selecting DOM elements and extracting the text therein. So understanding how to select in jQuery is clutch. The key difference from most scraping mechanisms is that we are scraping from the fully rendered page and as such have access to everything.
- Identify the CSS3 selector with jQuery Unique Selector.
-
Use the jQuery select statement in the Console. A select statement is executed by simply wrapping the CSS selector in quotes, parentheses, and using the jQuery alias $. Then we’ll want to convert whatever we select into text using the chainable .text() function. So to select all of the links on the page we’d write $(‘a’).text(); Running that in the Console window will give you the anchor text of all of the links on the page as an unformatted string.
It’s that simple, but now we have to structure the data.
Retrieving and Structuring Every Instance of Your Data
The whole purpose here, though, is to pull every instance of it off the page and format the data so that it’s usable for your purposes.
So let’s say I want all of the NAP (name address phone number) data from this page.
- Ensure jQuery is active. Home Depot is using jQuery, so you don’t have to enable jquery-injection, but in the case of a page that did not have it, you would. You can check by typing $ in the console. If you get an error, then inject. (Note: Keep in mind that the developer could have aliased jQuery differently.)
-
Find the Repeating Container with jQuery Unique Selector. Without an understanding of the DOM, this can be tricky. So feel free to guess and check based on the options that jQuery Unique Selector gives you below the Selected Element Selector. You can just test them by typing in $(‘insert selector here’).text() and seeing what is returned.
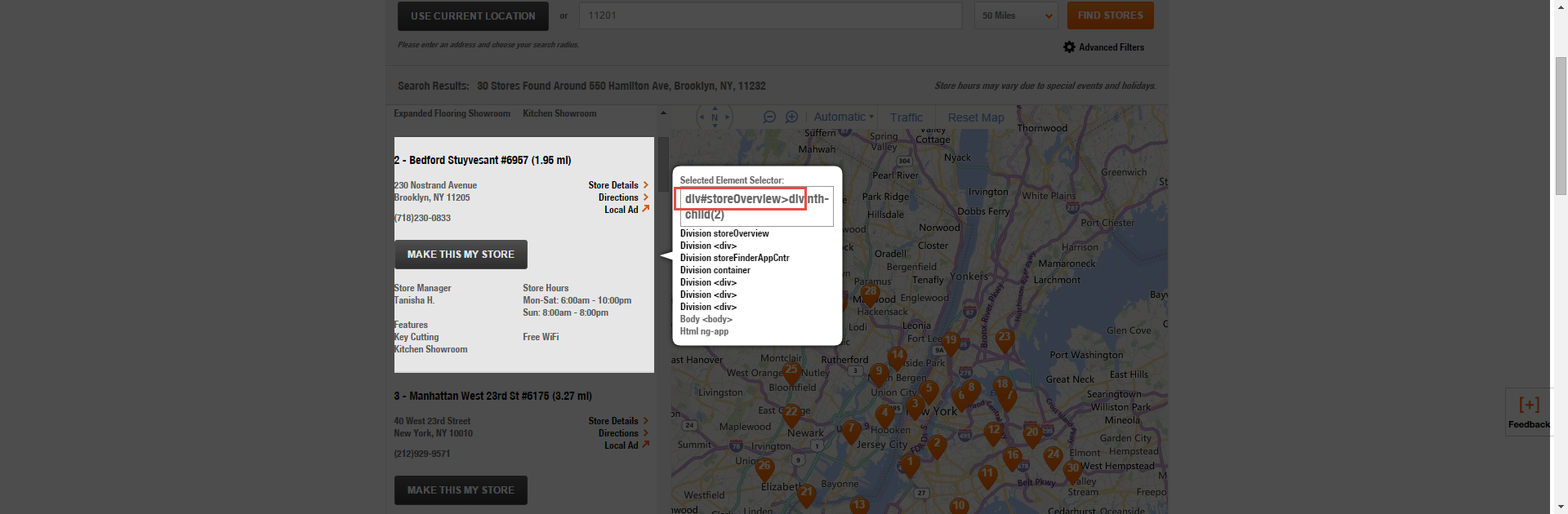
In this case, the repeating container is div#storeOverview>div. That is to say, the DIV that wraps the code on the site is named and therefore it is what we want to continually access and refer to. Selecting it in the console as text using $(‘div#storeOverview>div’).text() gives me all of the unformatted copy without HTML, but again this is not structured in the way I want.
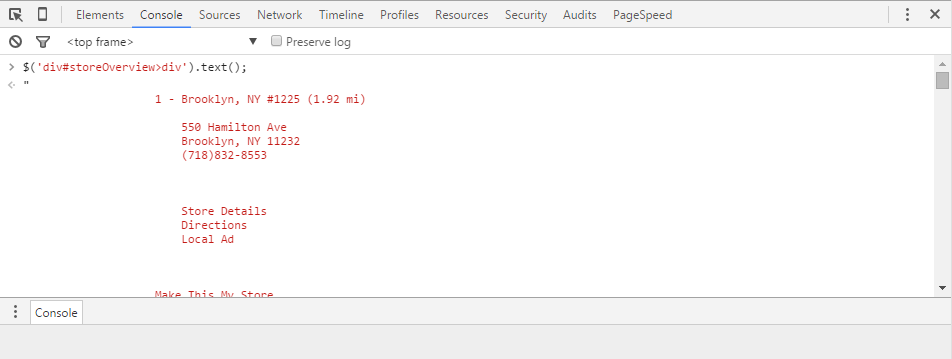
Also, if you type in $(‘div#storeOverview>div’), it will just give you the code of those specific sections. Give a try.
- Highlight the Location Name with the jQuery Unique Selector. In this case, the name field selector is div#storeOverview>div:nth-child(2)>h3>a.
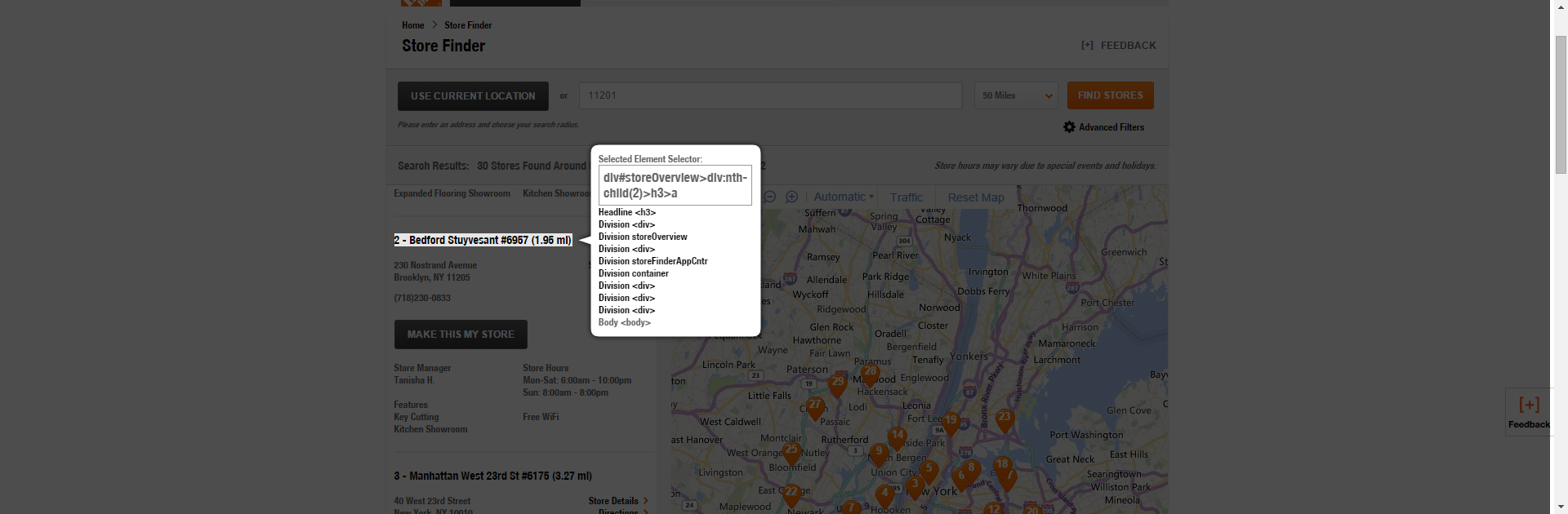 However, in this case, this is again too specific since we’re trying to grab every location name on the page, so we can go ahead and put $(‘h3>a’).text() into the Console and you’ll see an unformatted list of all of the location names will appear.
However, in this case, this is again too specific since we’re trying to grab every location name on the page, so we can go ahead and put $(‘h3>a’).text() into the Console and you’ll see an unformatted list of all of the location names will appear.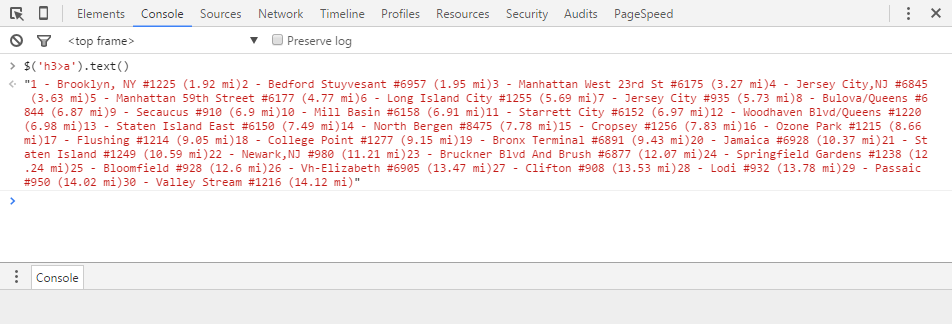
-
Get the Address Selectors – In this case, several separate elements make up each address line, which is great, because you may want to segment the dataset by a given location’s city state or postal code. It will only matter that we identify the unique parts of the selector. Later on when we extract all of the data, we will doing so with reference to each given repeating container. This allows us to limit the section to the DOM items that are specifically within each given location block. We will extract of the following separately and then concatenate them later.
First we’ll get the street address.
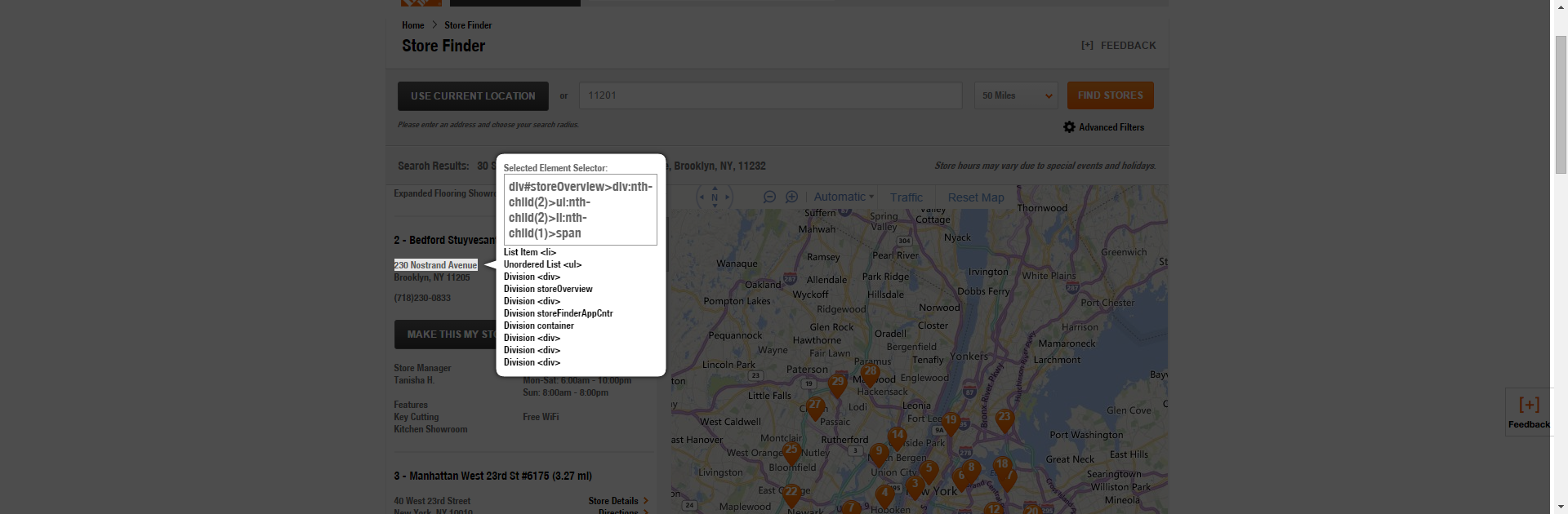
Then we’ll get the city.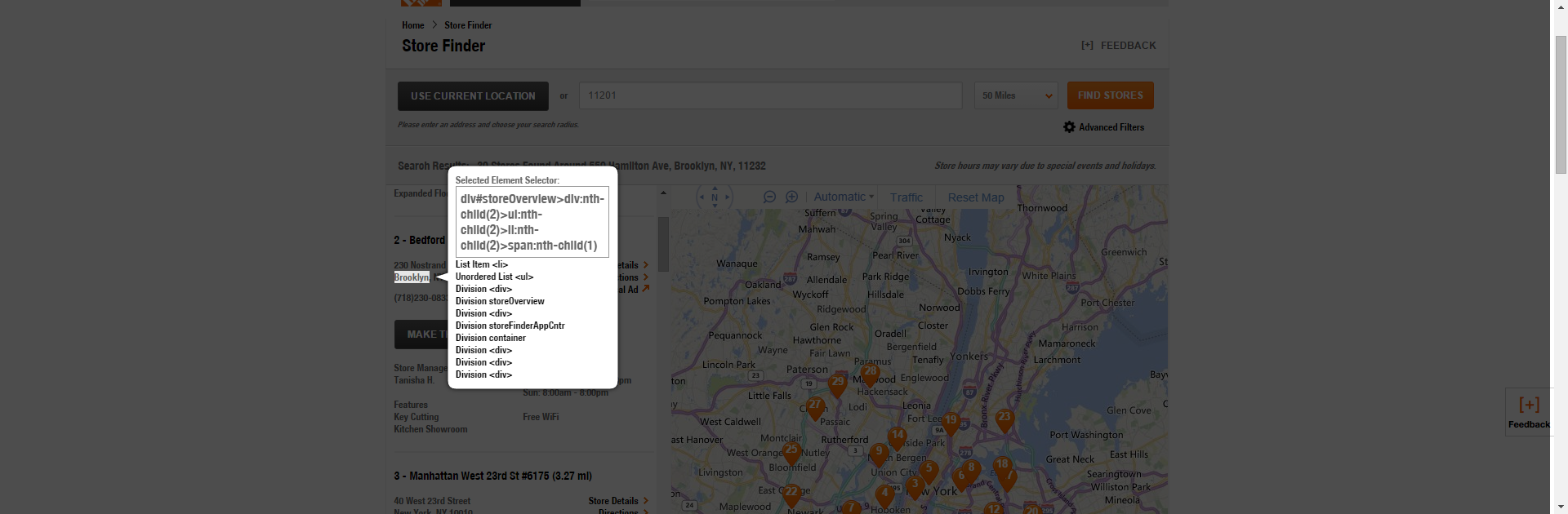
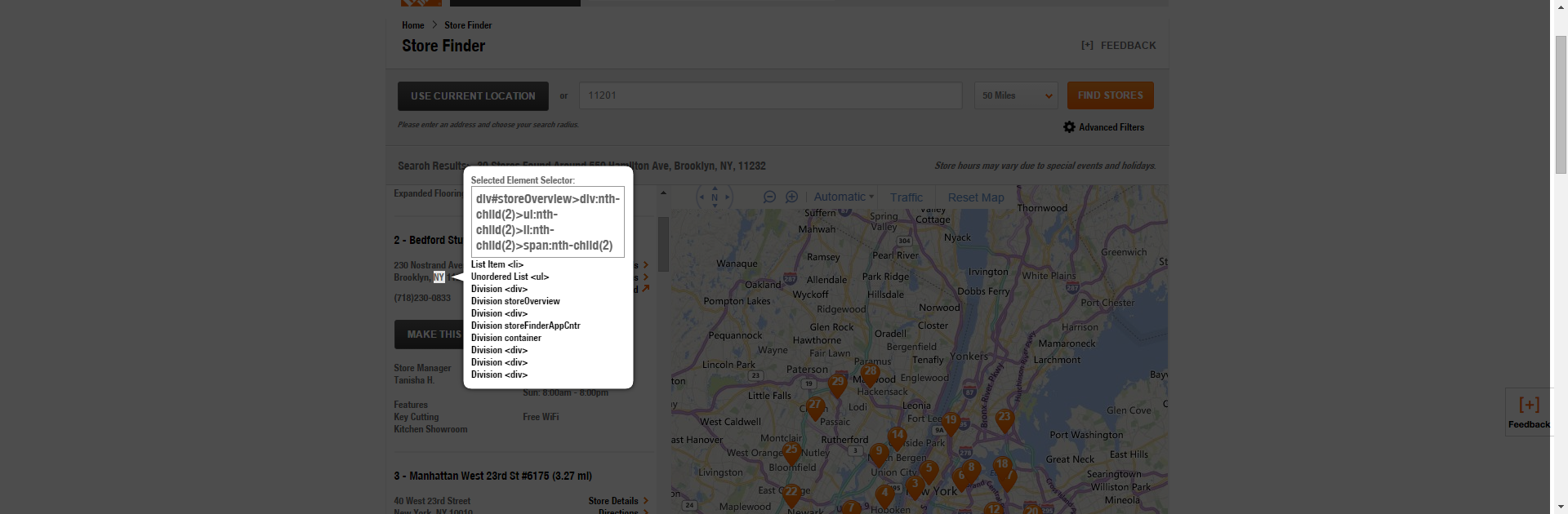
Then we’ll get the state.
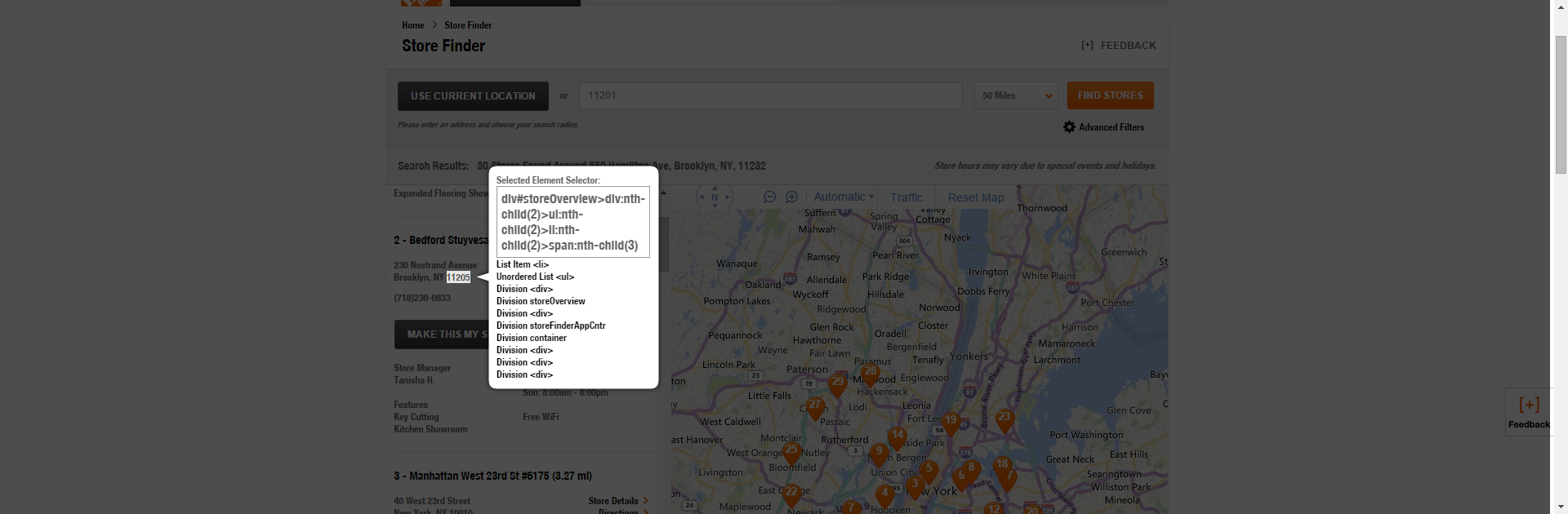
Then we’ll get the postal code.
-
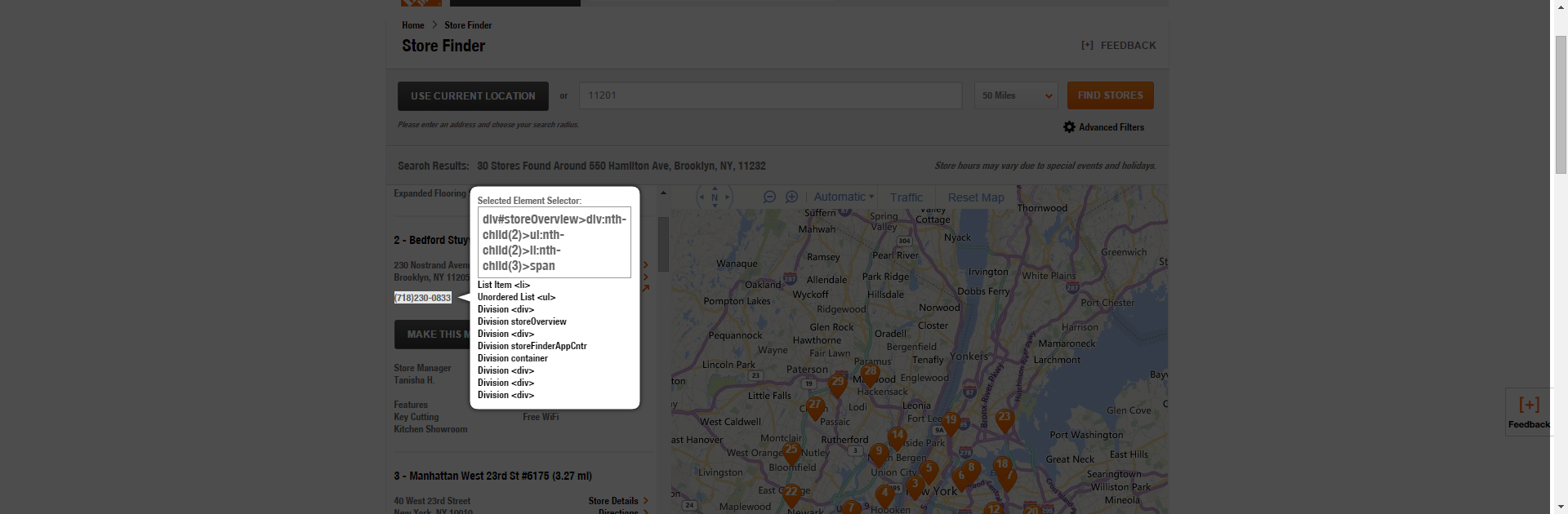
Now get the phone number selector.
-
Loop and Format – This is the only moderately technical part of using this technique. We are going to identify every instance of the repeating container and loop through all of them with a chainable jQuery function called “each.” As we iterate over each of those containers, we are going to reference the children of those objects, get the text within them and save them to a variable. Once we’ve got the data, we are going to concatenate it with pipes as the delimiter and print it to the console window using the console.log function. The code to do so is as follows:
[cc lang=”javascript”]
$(‘div#storeOverview>div’).each(function (index, value) {
branch = $(‘h3>a’, this).text();
streetAddress = $(‘ul:nth-child(2)>li:nth-child(1)>span ‘, this).text();
city = $(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(1)’, this).text();
state = $(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(2)’, this).text();
zip = $(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(3)’, this).text();
phone = $(‘li:nth-child(3)>span’,this).text();
console.log(branch + “|” + streetAddress + “|” + city +”|” + state + “|” + zip + “|” + phone);
});[/cc]
Alternatively, we could simplify this by eliminating the variable assignments:
[cc lang=”javascript”]$(‘div#storeOverview>div’).each(function (index, value) {
console.log( $(‘h3>a’, this).text() + “|” $(‘ul:nth-child(2)>li:nth-child(1)>span ‘, this).text() + “|” + $(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(1)’, this).text() + “|” + $(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(1)’, this).text() + “|” +$(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(2)’, this).text() + “|” +$(‘ul:nth-child(2)>li:nth-child(2)>span:nth-child(3)’, this).text() + “|” + $(‘li:nth-child(3)>span’,this).text));
});
[/cc]Notice that it does not look too different from the commands you’ve been putting into the console thus far. The biggest difference is that we are referencing “this” as a shortcut for identifying DOM element. The output of the code looks like:
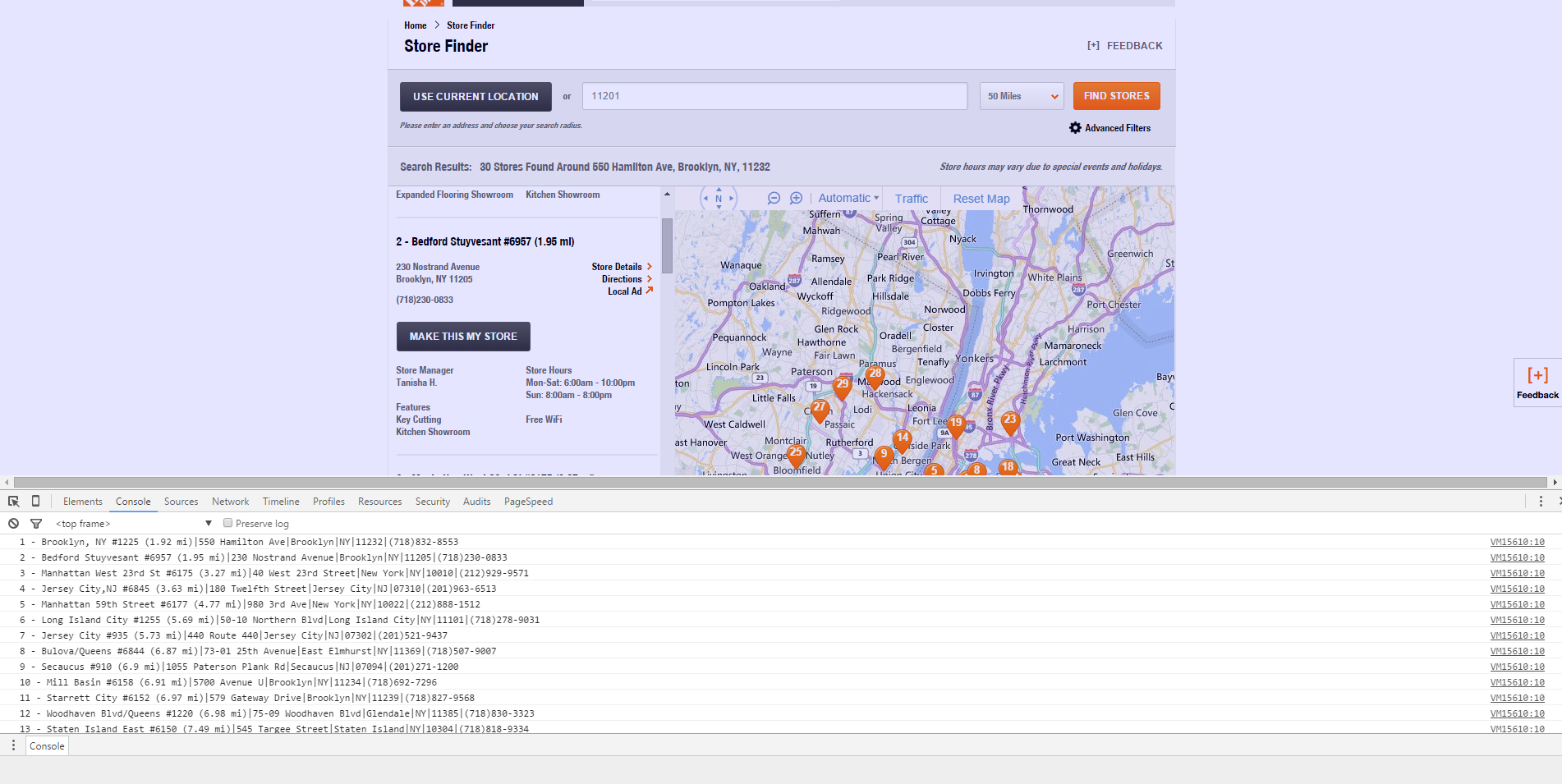
- Right-click and save your Console output. Now that we’ve got our data in a structured format we can save it. If you have a ton of stuff in your console window, you can clear it before saving the file so that the only thing in your log file is your data.
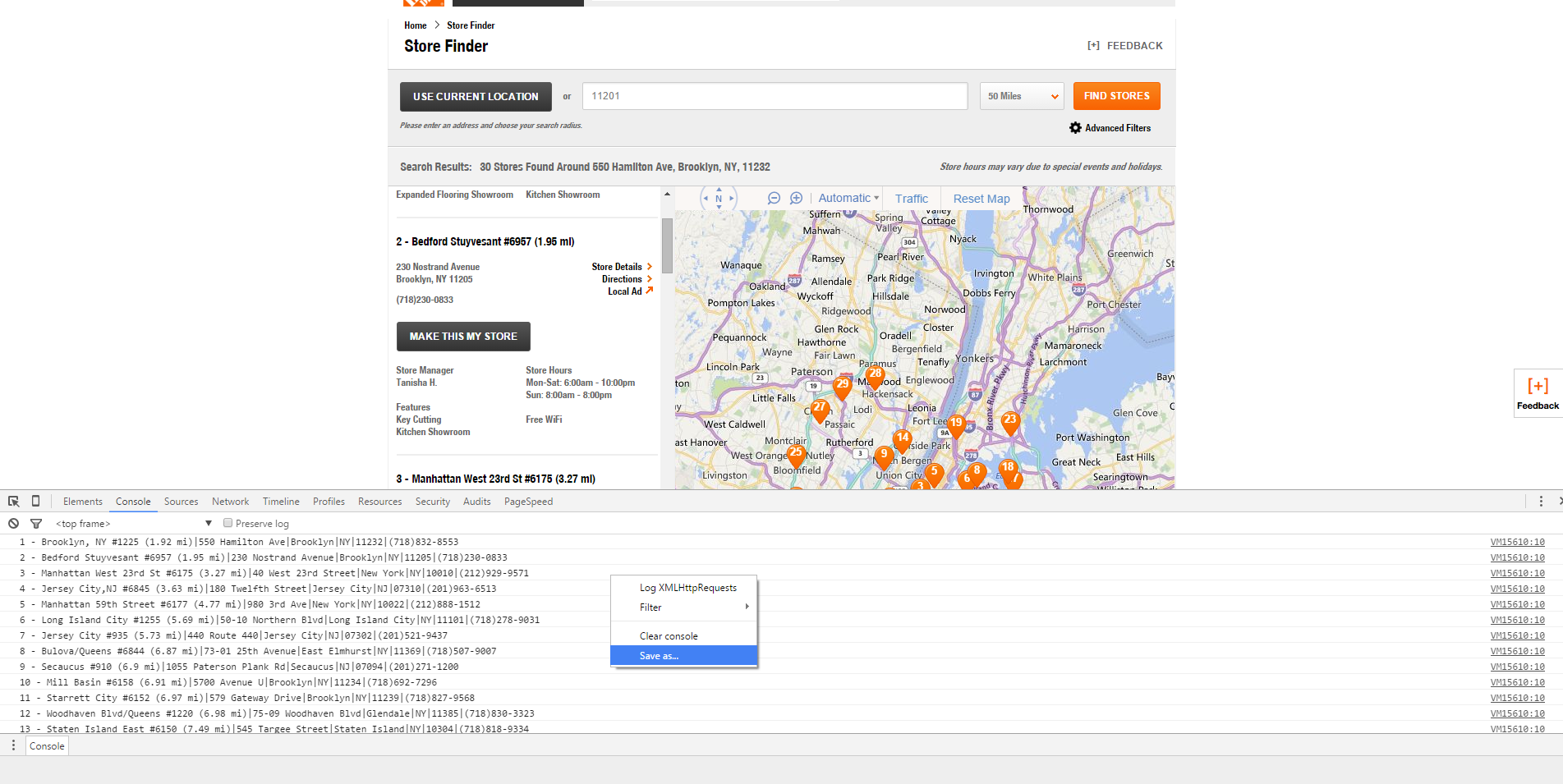
-
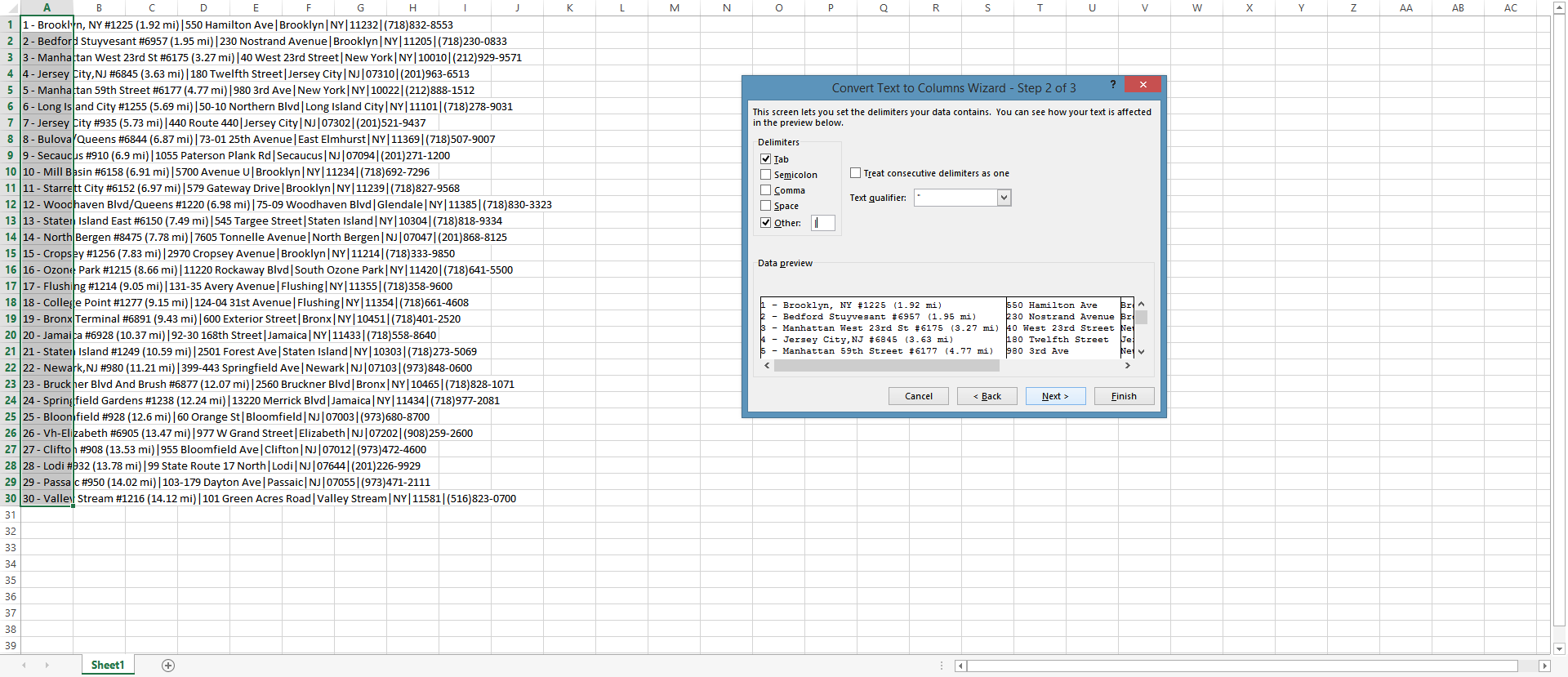
Open the text in Excel. Using the text to columns feature where the delimiter is a pipe “|,” you’ll be able to turn this is into data that is easy to manipulate.
-
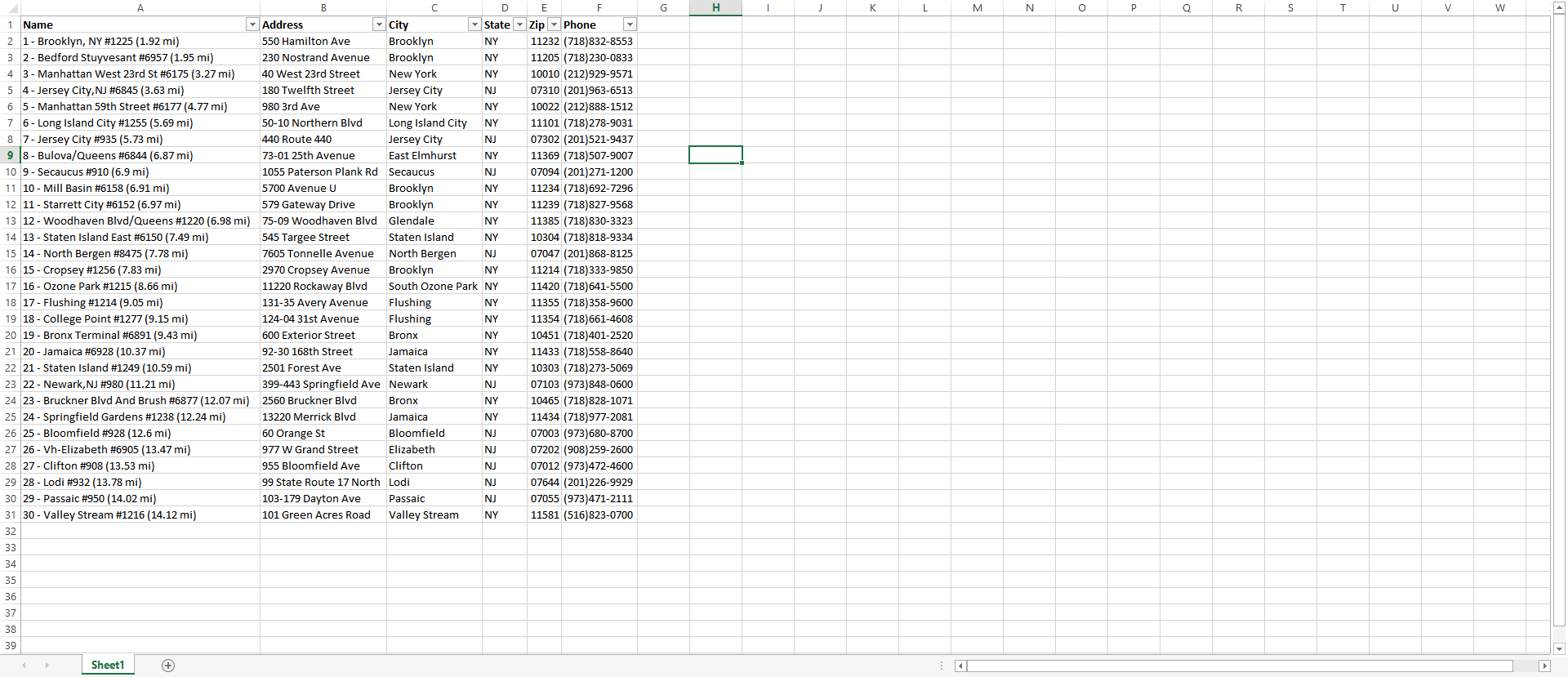
Manipulate You Data. Set up your filtering and such and you now have structured data.
You Can Do This on Any Page
I wanted to focus this on example on a practical use case that applies to many every day marketers, so this Home Depot page may not be the most JS-heavy page there is, but even the mighty Google Trends Trending Queries is no match for this technique.
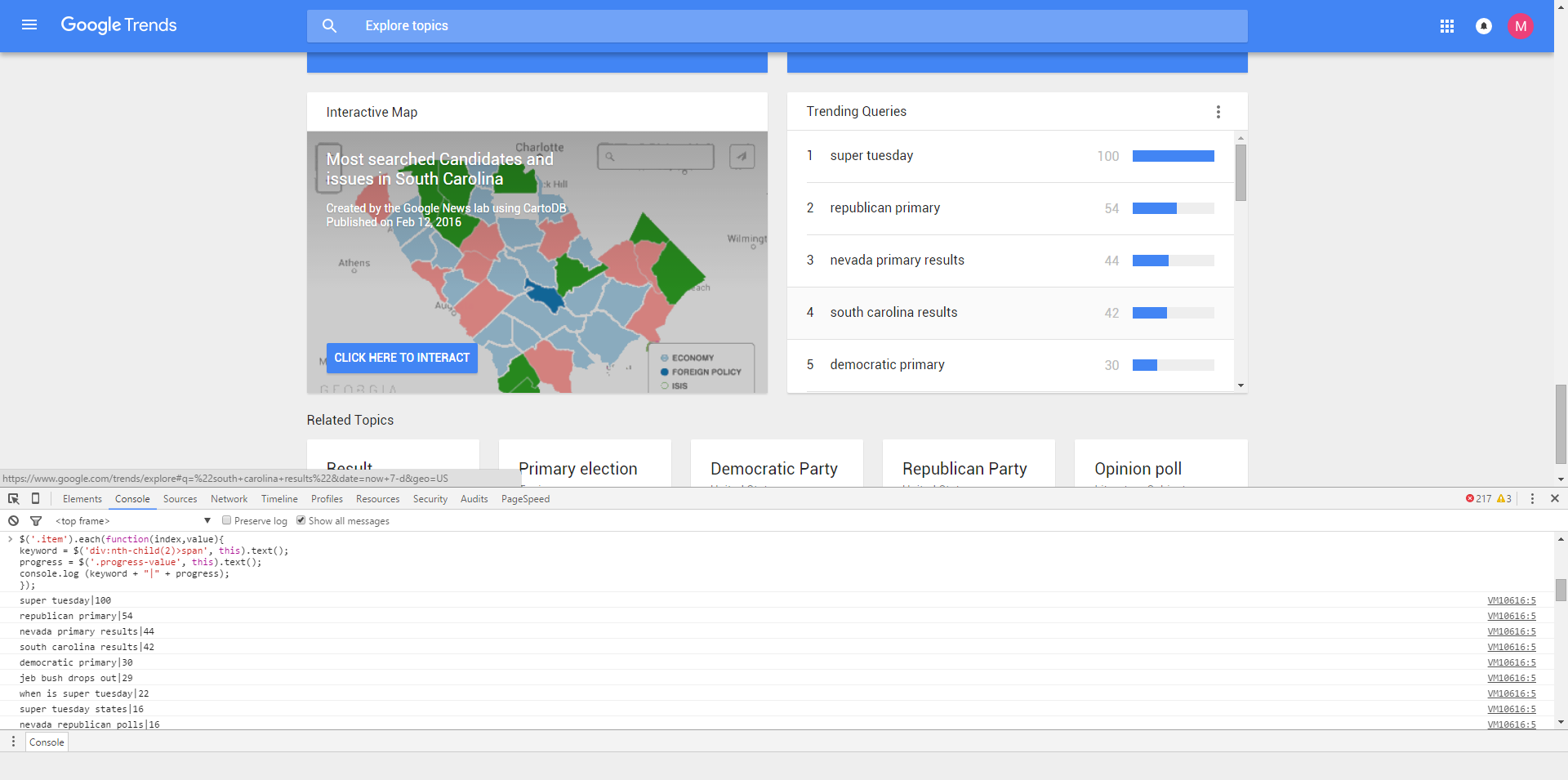
You can also scrape anything that is behind a login this way.
If you want to take this concept to the next level, and have a crawler in your browser, check out bookmarklet called ArtooJS. It takes a lot of what we’ve done here and simplifies it.
For now, to make this post more actionable, let me know what you’re trying to scrape and I’ll walk you through how to make it happen in the comments.