Get iPullRank’s AI in Content and SEO Free Guide – DOWNLOAD
In 2018 I made a prediction at TechSEOBoost that we were 5 years away from any random script kiddie being able to leverage Natural Language Generation (NLG) to generate perfectly optimized content at scale using open source libraries. At that point, I’d been keeping a close eye on what was happening in the Natural Language Processing (NLP) space with Large Language Models (LLMs) beginning to mature. Conversations that I had when I got offstage after my keynote suggested that we were actually much closer to perfect automated content being deployed by cargo coders than I thought.
The next year I judged, hosted, and iPullRank provided the grand prize for the TechSEOBoost technical SEO competition. Ultimately, Tomek Rudzi would take home the prize, but there were two strong entries that demonstrated natural language generation in multiple languages from the late great Hamlet Batista and Vincent Terrasi from OnCrawl respectively. Personally, I found these to be the most compelling submissions, but the judging was done by committee.
Let’s take a step back though. What I imagine as “perfectly optimized content” is the combination of what content optimization tools (Frase, SurferSEO, Searchmetrics Content Experience, Ryte’s Content Success, WordLift, Inlinks, etc) do with what natural language generation tools (CopyAI, Jasper, etc) are doing. A key benefit of the latter set of tools is in how they look at relationships across the graph rather than just vertically down the SERP.
In practice, a user would submit a keyword with some instructions to a system that would derive entities, term co-occurrence, and questions as inputs from the SERP and then generate relevant and optimized copy with semantic markup and internal linking baked in. With the emergence of Generative Adversarial Networks (GANs) and the ubiquity of text-to-speech, the system could cook up related imagery and video transcripts as well.
If that sounds a bit like science fiction, it’s not. The components exist and innovative companies like HuggingFace and OpenAI are driving us there, but the elements have not been tied together into one system yet. However, there’s still a year left in my prediction and iPullRank has an engineering team, so make of that what you will.
In the meantime, user-friendly tools built from large language models that generate copy virtually indistinguishable from what a human may write are beginning to grab the attention of marketers and would-be spammers. The implications for a search engine that has been caught on the back foot by a social video platform and has a growing symphony of users drawing the conclusion that results limited to Reddit as a source are better than core search quality are potentially immense. Whether or not the two are related, we’re seeing the beginnings of a campaign to discourage the use of this type of generated content.
If it's a problem, Google created it (or What is a Large Language Model?)
Make no mistake, all the technologies that I am referencing herein are incredible albeit somewhat problematic for a number of reasons that we’ll discuss shortly. Google’s AI Research team has driven a quantum leap in the NLP/NLU/NLG fields with a few key innovations that have happened in recent years.
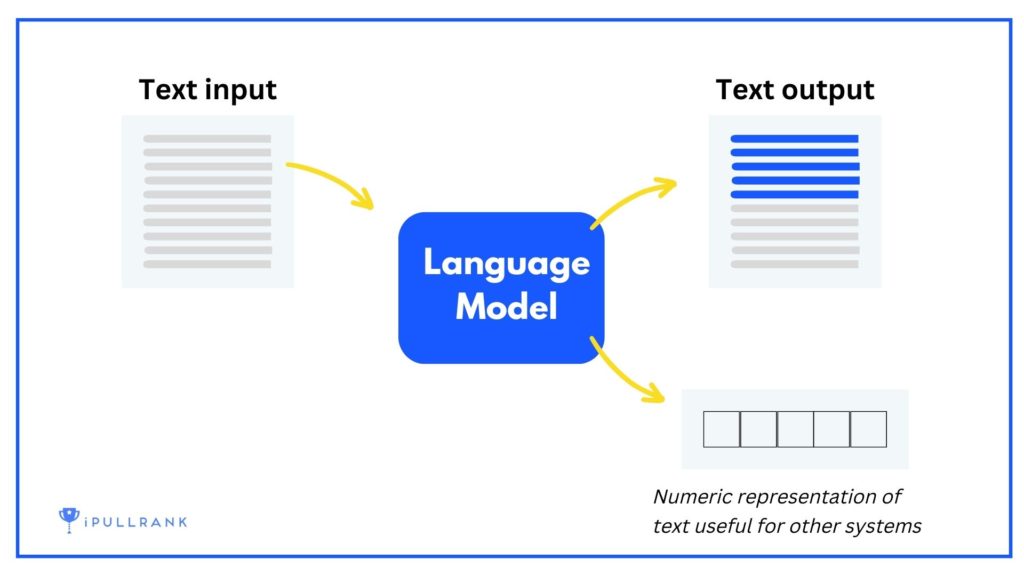
While the fledgling concepts behind them stretch back to prehistoric types of Computer Science theory, the Large Language Models, as they are called, were developed based on the concept of “Transformers.” These marvels of computational linguistics examine a colossal collection of documents and, basically, discover the probability for one word to succeed another word based on the likelihood of words appearing in a given sequence. I say “basically,” because word embeddings play a huge role here and there are also language modeling forms based on “masking” which allows the model to use the context of the surrounding words and not just the preceding words. Transformers were introduced by Google engineers and presented in a paper in 2017 called “All You Need is Attention,” explained in something closer to layman’s terms in a post called “Transformer: A Novel Neural Network Architecture for Language Understanding” The concepts would be brought to life in a way that SEOs took notice of with Bidirectional Encoder Representations from Transformers (BERT).
In August 2018, just prior to the open sourcing of BERT, the OpenAI team published their “Improving Language Understanding with Unsupervised Learning” post and the accompanying “Improving Language Understanding with Generative Pre-Training” paper and code wherein they introduced the concept of Generative Pre-Training Transformer or GPT-1.
How do Generative Language Models Work?
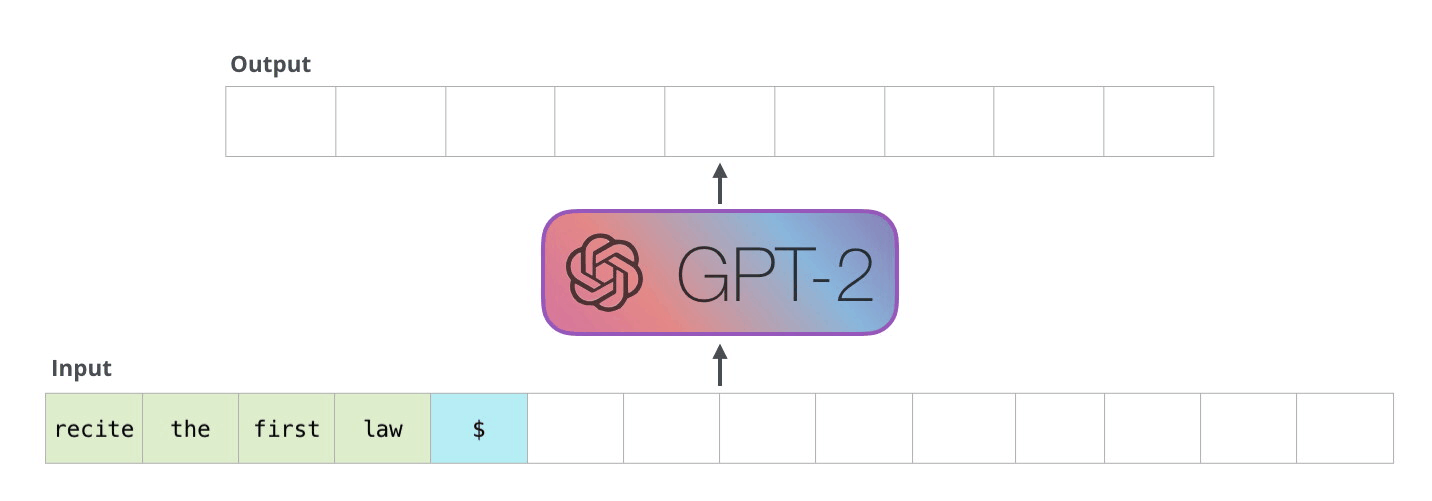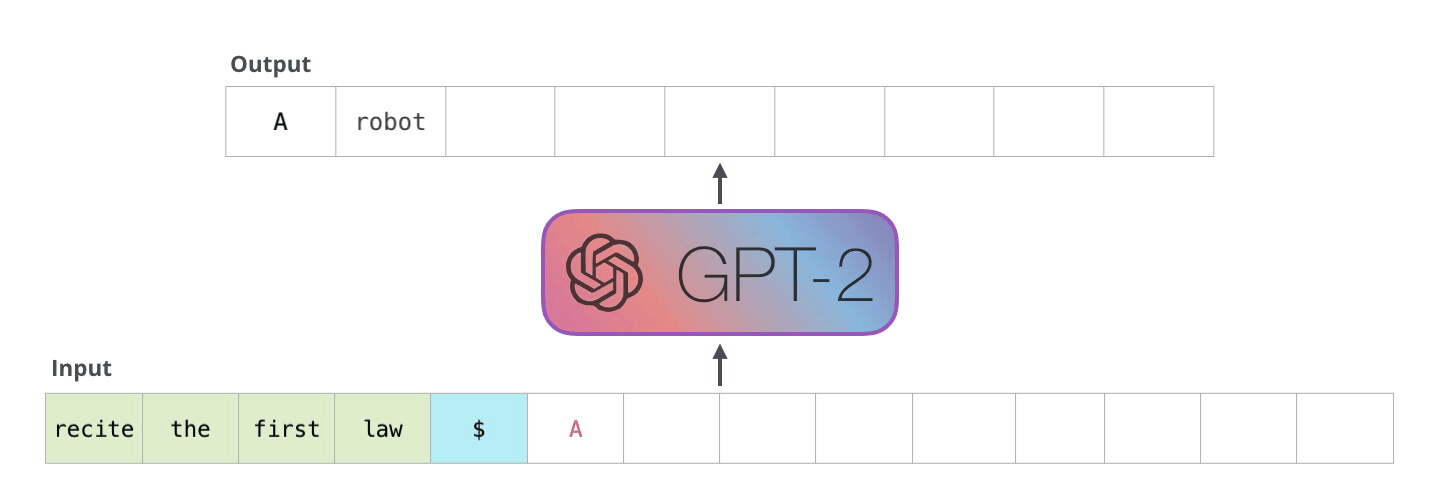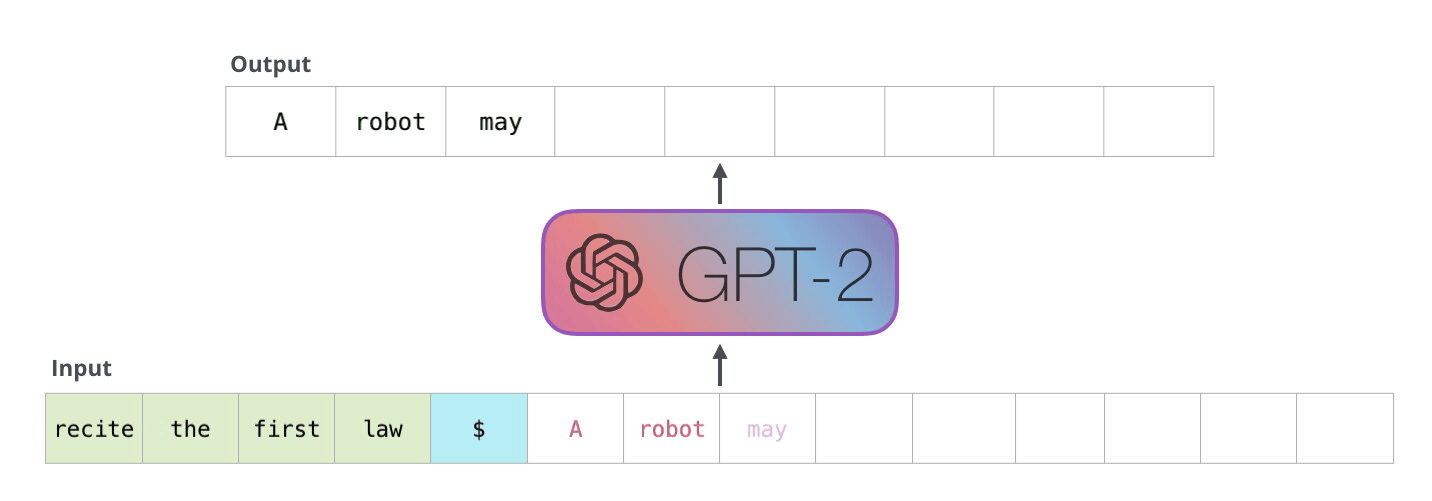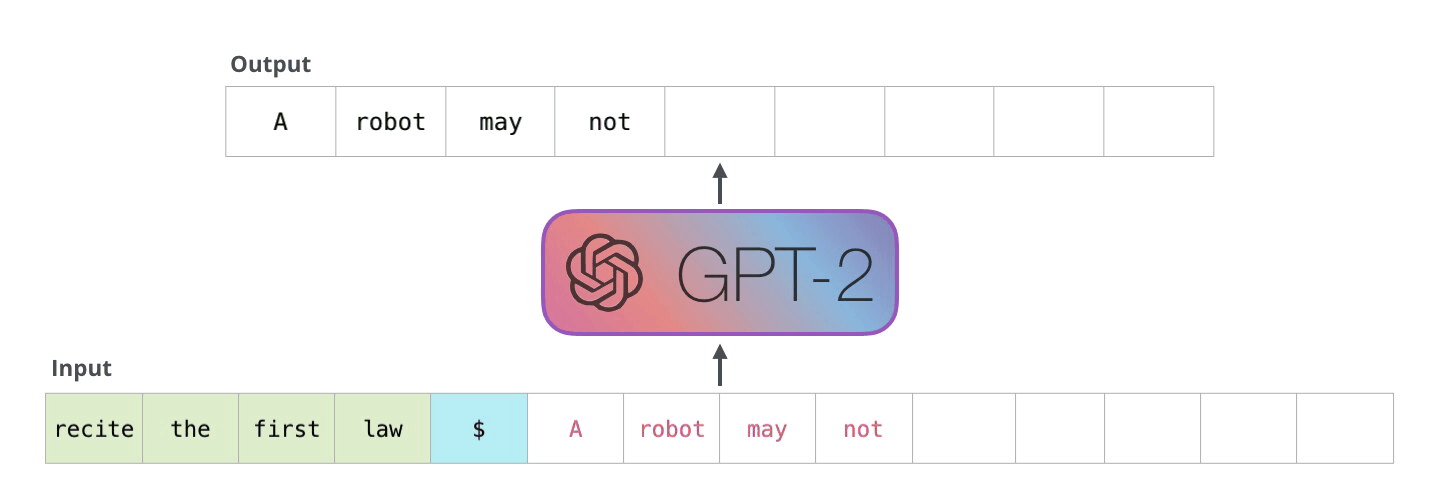
In practice, given a prompt, a large generative language model such as GPT-1 and its successors (GPT-2, GPT-3, T-5, etc.) extrapolate the copy to the length a user specifies using the probabilities of what is most likely to be the next token (word, punctuation, or even code) to appear in the sequence. In other words, if I tell the language model to finish the sentence “Mary had a little” it is likely that the highest probability for the next word is “lamb” due to how often that sequence is present in the texts from the Internet that it has learned from.

In effect, language models aren’t actually “writing” anything. They are emulating copy that they have encountered based on the number of parameters generated in their training. You can play with this live in a variety of ways, but Write With Transformer by HuggingFace has a variety of models that illustrate the concept.
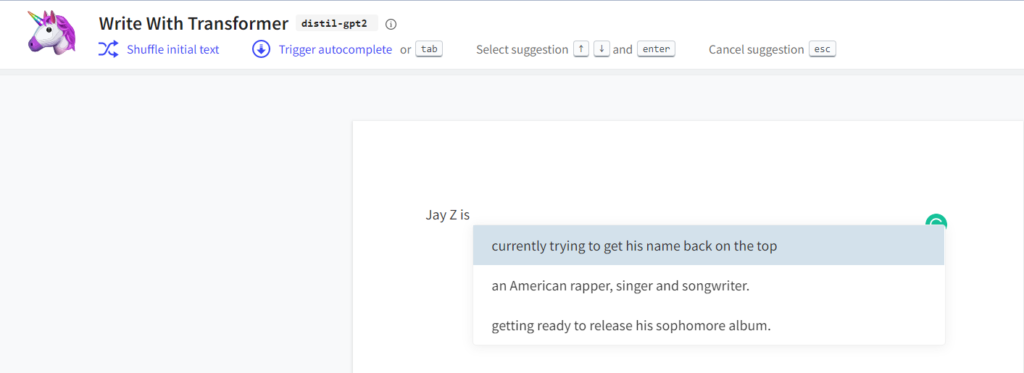
In this screenshot, you’re seeing the three different directions that the model feels confident about taking a sentence that starts with “Jay Z is.” The longer it goes further unprompted the more it will begin to meander into topics of disinterest.

This is the same functionality at play when Gmail or Google Docs attempts to autocomplete your sentence. The email or document is the prompt and Google’s language models are predicting your next word, phrase, or response as you write. Note: I suspect that it will be a bit discombobulating to see a portion of the same paragraph in the screenshot above, so I’m just writing an additional sentence to make this area visually easier to differentiate so readers don’t think it was a mistake.
While large language models will generate content just fine “out-of-the-box,” there is also an opportunity to “fine-tune” their output by feeding them additional content from which they can learn more parameters. This is valuable for brands because you can feed it all of your site’s content and the language model will improve its ability to mimic your brand voice. For anyone that is serious about leveraging this technology at scale, fine-tuning needs to be a consideration.
The Large Language Model Explosion
As with all types of machine learning models, a series of values that represent the relationship between variables known as “parameters” are learned in the training of a language model. Parameters in language models represent the pre-trained understanding of probabilities of words in a sequence. What has been found is that, generally, the more parameters, or the more word relationships examined using this process, the stronger the language model is at its various tasks. For instance, language generation substantially improved between GPT-2 and GPT-3.
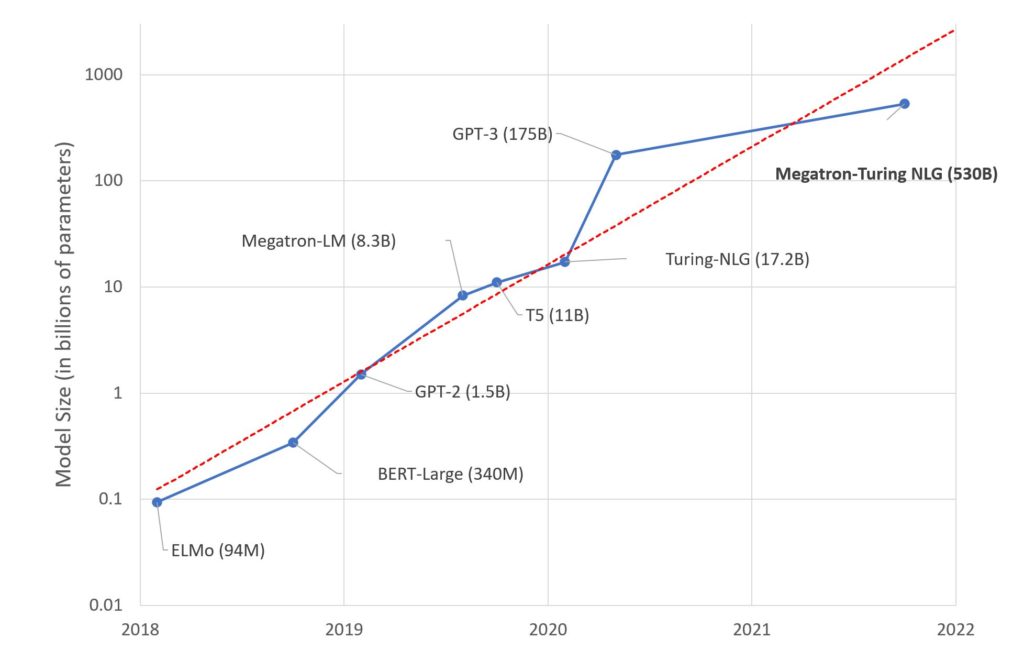
Despite projects like DeepMind’s RETRO being said to outperform GPT-3 with only 7 billion parameters, companies such as Google, Nvidia, Microsoft, Facebook, and the curiously named OpenAI, have been in proverbial arms race to build bigger models. Google themselves have a series of interesting models such as GLaM, LaMDA, and PaLM; they’ve also recently leaped into the lead with their 1.6 trillion parameter model Switch-C.
All of this technology is incredible, but these innovations certainly come at a cost.
What are Some Problems with Large Language Models?
When I say that these language models are trained from colossal collections of documents, I mean that the engineers building them take huge publicly available data stores from well-known corpora such as the Common Crawl, Wikipedia, the Internet Archive as well as WordPress, Blogspot (aka Spam City), New York Times, eBay, GitHub, CNN and (yikes) Reddit among other sources.
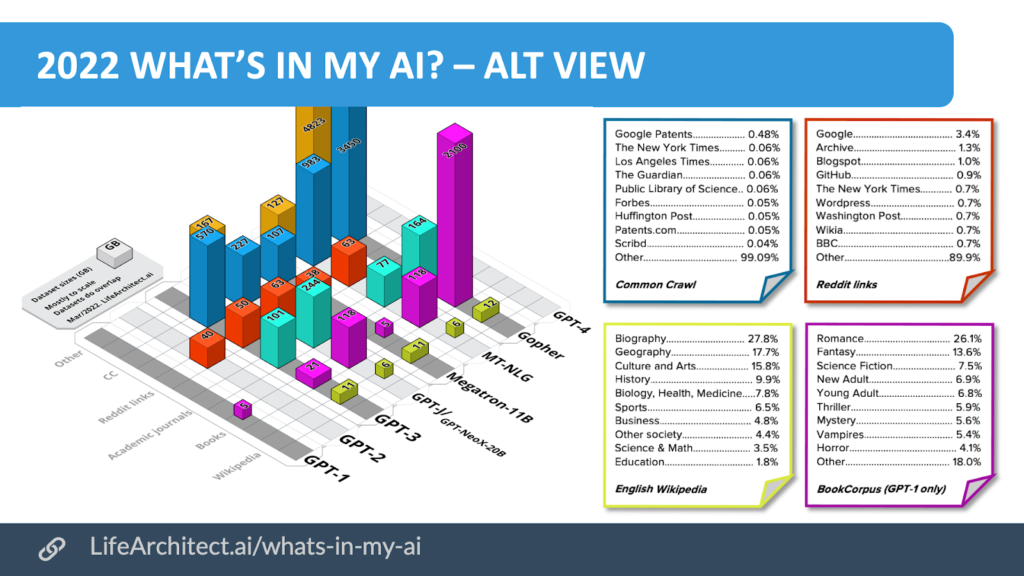
Naturally inherent in this is a series of biases, hate speech, and any number of potentially problematic elements that come from training anything on a dataset that does not take the time to filter such things out. Surely, I don’t have to reference the Microsoft chatbot that swiftly went Kanye once it was unleashed on Twitter, right?

Of course, there have been warnings from academics about the potential problems. Wrongfully terminated former Googler and founder of DAIR.AI Timnit Gebru along with Emily Bender, Angelina McMillan-Major, Shmargaret Mitchell, and other researchers that were not allowed to be named all questioned the ethics behind LLMs in their research paper “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜“
In the paper they highlight a series of problems:
- LLMs are not actually “writing” – As readers, we ascribe meaning to the output of large language models because they mimic word usage in the way that we expect, but the entity on the other side does not “mean” anything as it spits out the copy. The team clarifies this with: “Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.” This is something we should keep in mind as we use these tools so as to not prematurely believe these tools are self-aware.
- Computational expense – Although the quality of results improve as LLMs grow in size, the gains are incremental while the costs are exponential. The research reveals that for a 0.1 gain in BLEU score performance rating of a translation task, the computing costs increases $150k. They also highlight that this not just a language modeling problem, rather it is a problem across machine learning in general and compute requirements have been outpacing Moore’s Law. In the long term, the expense at the inference stage will also eclipse that of the training stage.
- Environmental and social expense – Dr. Gebru, et al note that training a big Transformer model yielded 5,680% more carbon emissions than the average human generates per year or in their own words “Training a single BERT base model (without hyperparameter tuning) on GPUs was estimated to require as much energy as a trans-American flight.” The downstream effect is perhaps more consequential in that the countries that experience geographic racism like those in Africa, for instance, will see more negative environmental impact than the countries for whose languages these models are trained.
- Biased training data – In the same way that documented history is a reflection of the perspectives of those who were in power at the time, training language models on datasets from the unfiltered Internet effectively codifies the hegemonic belief systems of the time. As the paper states, “the training data has been shown to have problematic characteristics resulting in models that encode stereotypical and derogatory associations along gender, race, ethnicity, and disability status.” This is both a function of the bias of those who are privileged enough to have access to the Internet, comfortable enough to be involved in its public discourse as well as a reflection of whose voices and viewpoints get amplified across it. Naturally, marginalized people and thinking represents the minority of the data in the training set. Perhaps this was at the heart of OpenAI’s original decision that GPT-2 was too dangerous to share.
- Static viewpoints – Language and beliefs evolve everyday. Large Language Models are typically trained once and used for long periods of time and thereby “value-locked” while the world itself changes. As we grow more diverse, inclusive, empathic, and sensitive to the experiences of others, words like “homeless” morph into “unhoused” and their semantic associations change. History is also revised as we grow as a society. This is reflected by updates to Wikipedia and additional news coverage. Large Language models being static do not benefit from these updates.
From my perspective, all of these insights are incredibly valid and well-researched. It’s both enraging and very unfortunate how Google disrespectfully ousted Dr. Gebru, and her colleagues in their attempts to ensure that the technology is handled ethically. I applaud her and her continued efforts to address algorithmic bias.
In fact, as with many machine learning technologies, I find myself conflicted by their exciting use cases and the potential harm they might cause. To that end, what the paper did not explicitly consider was a second order impact of marketers using LLMs to lay waste to the web and the circular effect of generated content finding its way back into future training datasets.
What are LLMs Good At in SEO?
Naturally, much of the Large Language Models conversation in the SEO space is about using them to create long-form content at scale. After all, we’re the industry that thought using content spinners built from Markov Chains was a good idea.
The scope of these applications is actually much bigger since they are capable of document summarization, sentence completion, translation, question answering, even coding, image creation, and even writing music. The concepts behind this tech have also been applied to generating images. In fact, several of Google’s more recent innovations have come on the back of applications from technologies that underpin LLMs or have been built on top of them. For instance, Google’s Multitask Unified Model (MuM) is built leveraging its T5 language model.

With respect to SEO and Content Marketing use cases of language models, the obvious threat is that people will dump million-page websites of raw generated long-form content onto the web. Further still, they could use a language model to write the code for the front end and incorporate its copy. We could see the proliferation of scripts and services allow someone to generate such a site in a few clicks.
For those who have goals that are less nefarious (in the eyes of Google) pursuits, there are three immediate use cases that come to mind:
- Short Form Text Generation – With respect to text generation, language models perform best when fine-tuned and are limited to short bursts of text created from very specific prompts. The longer the copy gets, the weaker it gets. Consider using them for generating summaries, meta descriptions, and ad copy.
- Content Brief Generation – Through a combination of prompts in the background, some of the existing tools on the market do a fantastic job at generating briefs and informing brainstorms. Consider using language models to spin up a wealth of content briefs on a variety of keyword driven topics.
- Image Generation – Despite the fact that DALL-E 2 generates images, it too is built from a generative language model. Marketers have the opportunity to move away from heavy usage of stock photography and instead use imagery that is generated from prompts. Consider them as an opportunity to build well-designed content.
Most importantly, although there have been efforts to improve, LLMs are generally quite bad at factual accuracy. So, no matter what you do, be prepared to edit before you do anything with your generated content.
The Problem is we all know that low utility content can drive relevance
At this point, many of us have witnessed how so many large websites drive a wealth of visibility and traffic with thousands or millions of near-duplicate content pages that feature unique copy either at the top or bottom of the page.
If you haven’t, it’s a very common tactic for both e-commerce sites and publishers. E-commerce sites create Product Listing Pages(PLPs) based on internal searches or n-grams present across the site and slap some Madlib copy on the bottom of the page. Similarly, publishers create Category or Tag pages that simply list articles with a description of the category at the top.
Heatmaps and analytics generally indicate that no one reads that content and, if they do, they deeply regret it when they are finished. In recent years, the question has been presented as to whether or not it actually yields improvement. I won’t waste anyone’s time sharing A/B tests that suggest the practice is not valuable. People tending to large sites that perform know definitively that implementing this sort of copy works and yields dramatic results. There’s even a 2 billion dollar company down the street from Google in Mountain View whose core product generates pages like this. Best practices be darned.
What we also know is that no human being should be subjected to writing this content. Sure, it can highlight facts that someone might want to know, but these very same data points are often provided in tables on the page. Certainly, the goal of the semantic web is to make those things extractable and surface them, but fundamentally that is not enough to drive visibility in Organic Search.
Remember, FUD is page one in the Search Quality playbook
Google’s search quality efforts are one part technology-driven and one part large-scale social engineering propaganda campaign. On the technology side, the engineering teams are creating earth-shattering applications that shift the state of the art. They are also open-sourcing components of what they build to leverage the power of the crowd in hopes of scaling innovation. They talk about this concept of “Engineering Economics” in the Google Open Source documentation.
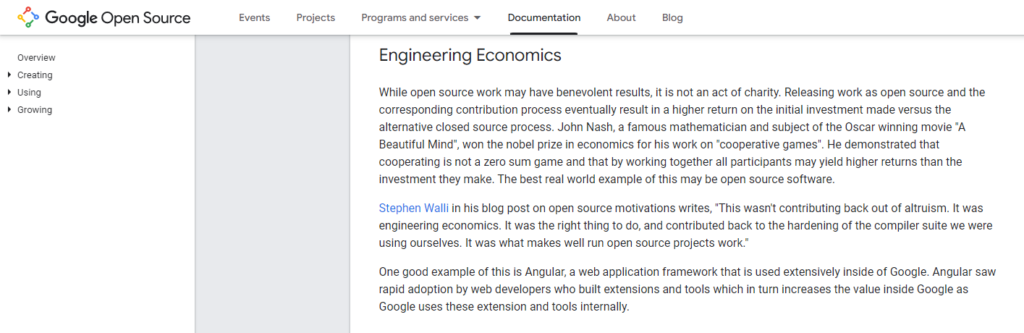
Effectively, they are saying engineering resources at Google are vast, but they are finite. Leveraging the power of the crowd, they are likely to get stronger diversity in ideas and execution by establishing bidirectional contributions between Google engineers and the motivated engineering talent of the planet.
You see an example of this within the progression of the technologies being discussed. Google released Transformers which begat the GPT family and influenced Google’s own increasingly expansive LLMs.
On the social propaganda side, the Search Quality teams make public examples of websites that go against their guidelines. Understanding that the reach of their spokespeople and documentation is limited, they apply the same power of the crowd approach to leverage the SEO community as evangelists and to offset the shortcomings of the tech. We sure did say “how high” when they told us to jump for Core Web Vitals, didn’t we?
Honestly, did people truly ever think Google could definitively determine all the guest posts on the web in order to penalize them? If you did, it was likely because risk-averse readers of SEO publications parroted back these somewhat hollow threats.
I don’t present any of this as a conspiracy theory per se. Rather, I present it as food for thought as we all look to understand how we’re being managed in this symbiotic relationship. After all, imagine what search quality would look like without us giving the scoring functions more ideal inputs.
The Helpful Content and Spam Updates may be the beginnings of an attempt to combat generated content
Recently, we all gripped the arms of our chairs in anticipation of the impact of the Helpful Content Update. Many people in the space speculated that sites using NLG tools to generate their content would be impacted as a result of this update or one of the recent Core or Spam updates.
Well, the Helpful Content algorithm came and went and the consensus across the space was that it was only sites that have little control over what content they serve like lyrics and grammar sites that got clobbered.
Although Google spokespeople are deferring to their broadly binary (no pun) guideline related to “machine created content,” I don’t believe that Google is sitting idly while an explosion of LLMs and AI writing tools happens. My guess is that the Helpful Content update was the initial rollout of a new classifier that is seeking to solve a series of problems related to content utility. Much like Panda before it, I suspect Google is testing and learning and, as Danny Sullivan indicates below, they will continue to refine their efforts.
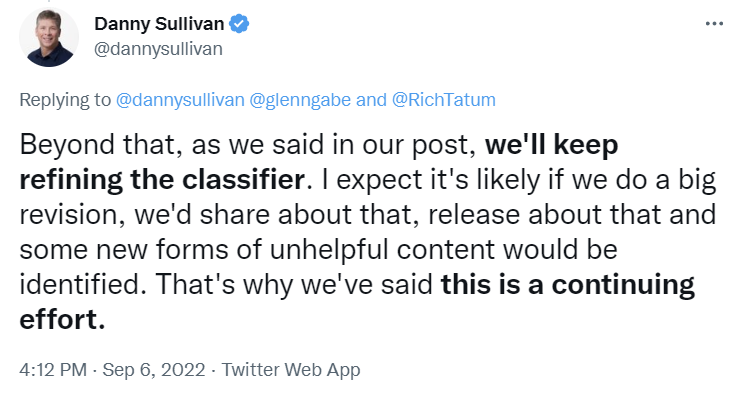
(emphasis and speculation mine)
So, especially egregious uses of generated content that offer no utility to users should be on high alert.
However we’re currently in a space where whenever there is a shift in visibility for a site there is a lot of speculation in the echo chamber that this is the moment that Google has dropped the hammer on “AI-created content.” For instance, writers using the pen name “Neil Patel” have indicated that their sites with “AI content” sustained losses in the Spam update.
Most missed this, but Google just dropped the hammer on AI-generated articles with their October Spam Update.
— Chris Frantz (@frantzfries) October 25, 2022
Neil Patel has 50 ranking sites, half pure AI-gen and half AI-gen with human editing. He charted the update’s impact below.
Big drops across the board for GPT-3 😬 pic.twitter.com/GyOlBZbsnz
Counterpoint: It is noteworthy that they also saw losses from their content that featured human involvement which suggests that their sites may have bigger problems that caused their losses.
Barry Schwartz recently highlighted that a site with auto-generated content recently was hit. Again, the echo chamber leaped to say that it is the result of content created from large language models.
This scraper site got hit hard by the Google spam update - it took Google's PAA results and auto-generated 10,000 or so pieces of content https://t.co/C8btY7V5P0 via @thetafferboy pic.twitter.com/lu2mQkhgXq
— Barry Schwartz (@rustybrick) October 31, 2022
Counterpoint: I reached out to Mark Williams-Cook on Twitter for a quick clarification:
Hey, so I understand here, were you scraping PAA and using it as prompts to generate content? Or were you scraping the results themselves and then doing some sort of content spinning on what appeared as the PAA answers?
— Mic King (@iPullRank) October 31, 2022
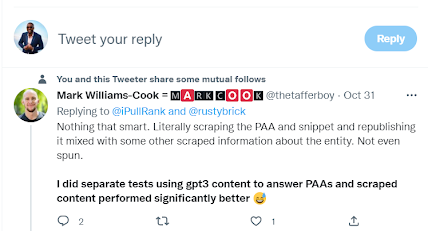
(emphasis also mine)
The hypothesis holds.
Since I started writing this post Glenn Gabe posted that he’s seen a site with “a ton of programmatic content” get “hammered.” Well, I’ll let him tell you in his own words:
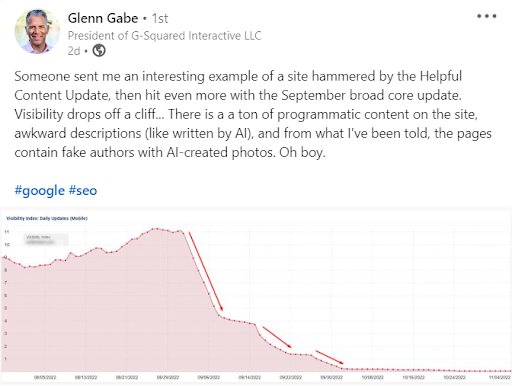
Counterpoint: First, looking at the visibility index on the Y-axis, this site never had much visibility to begin with. It’s not lost on me that this site has relatively lost all of its traffic. However, a visibility of 11 on a scale that goes into the millions could mean that it lost visibility for a handful of keywords, so I don’t know that this is truly a reflection of anything broadly illustrative. Secondly, relying solely on the description, I wonder if we need some clarity in our vocabulary to better make distinctions here. I worry that “programmatic content” is being conflated with lower quality methods such as content spinning or the Madlib style of content of historical tools like Narrative Science. Typically, what is yielded by large language models is not “awkward.” It may be factually incorrect, but the latest models are nearly indistinguishable from something that you’d expect to read online.
As it relates to “fake authors with AI-created photos,” I question how Google would technically distinguish between a new author and fake author… which brings me to my next point.
***Update:*** Glenn Gabe has responded. The site in question with the visibility loss of 11 ranked for 2.3 million keywords and was 175k pages.
Errata: I mistakenly believed that Sistrix’s visibility scores also went to the millions rather than the thousands.
Detection is full of false positives and false negatives
The problem inherent with detecting generated content built from LLMs is that, again, the content is statistically emulating the way that people naturally write. In other words, if a system writes based on probabilistic predictions based on natural word usage, a robust detection system is difficult since it’s comparing something text to how most writing on the web is done. So, it is highly likely that a detection system will yield many false positives and false negatives. In fact, we can see examples of that right now.
As of this writing, there are three open-source projects that I’m aware of that attempt to detect generated content. Grover, a fake news detector, GLTR, and the GPT-2 Output Detector built from RoBERTa.
In the screenshots below I’ve placed two pages from the same site that features generated copy. Both pages are currently live, indexed, and have continued to see visibility improve to the top 10 for over 100 long tail keywords (each) since we deployed the content. Neither has seen losses as a result of recent updates. Both pages were generated using the same fine-tuned LLM, prompts, means, and configuration aside from length. One version was 218 words and scored as 99.98% fake.

The other version is 198 words and scored as 99.98% real.
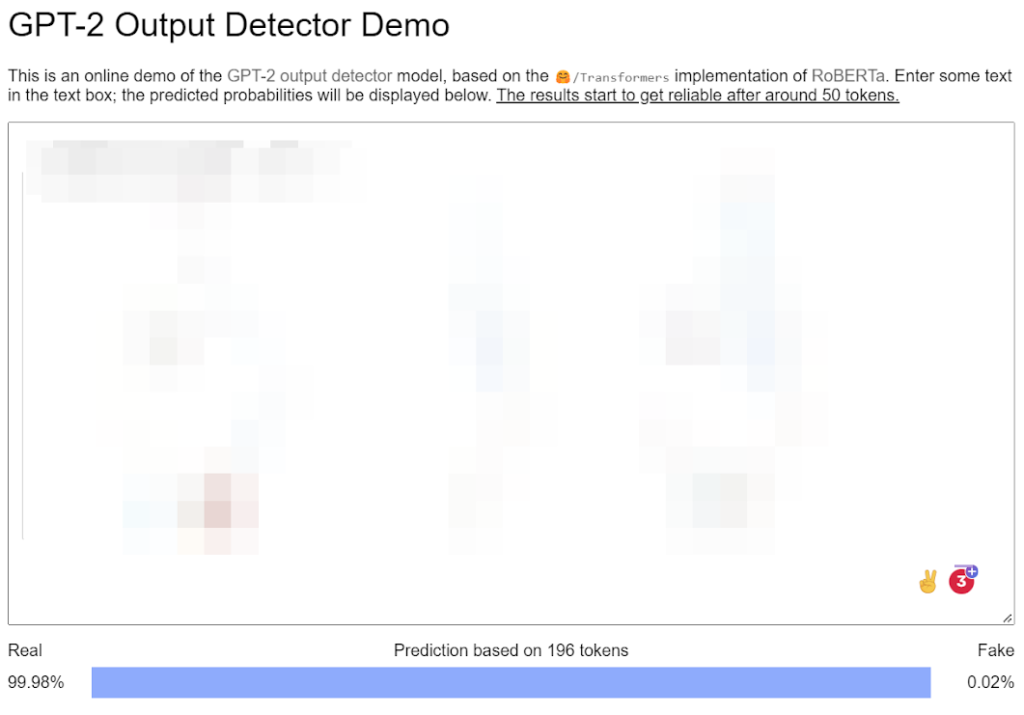
This is not to say that I don’t believe Google’s wealth of Math PhDs can’t (or hasn’t) come up with a stronger detection engine than what is available from the open-source community. I’m simply illustrating how easily such a system may swing in the wrong direction based on how text generation technologies work. I suspect that it will take many iterations to do this sort of detection with reasonable confidence at scale. But, then what happens when someone fine-tunes a language model on their own content (as we did above) or a new larger LLM is trained on the latest from a series of publications? There’s a high possibility that those actions may quickly render a detection system ineffective.
Effectively, the speed at which generated content could be deployed from new models would create a new cat-and-mouse game between marketers and algorithms. If I was Google, I’d simply recognize that the cat is out of the bag and continue down the path of strengthening subtopics and passage ranking to encourage people to make more robust content assets rather than terrorize the long tail.
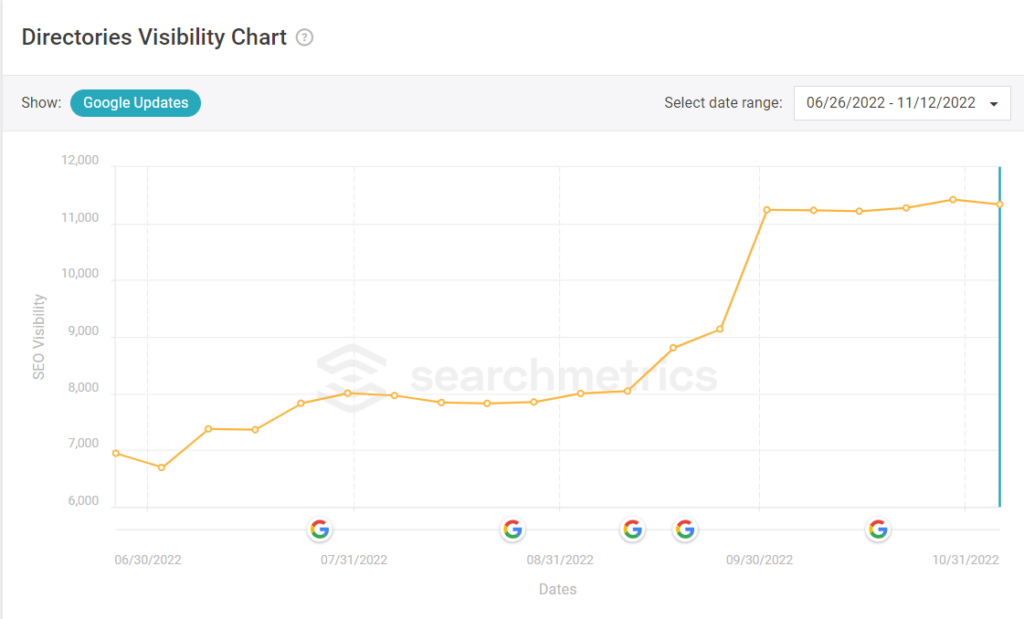
Oh, and for the record, here’s the visibility for that directory in which those pages I ran through the GPT-2 detector. The ~11k SEO visibility score represents about ⅓ of the site’s traffic and the site drives millions of visits monthly. For this subdirectory which features NLG content, it has actually seen some significant growth over the past few months and another small bump since the latest updates.
Use it, just be smart (Do’s and Don’ts)
In typical Mike King fashion, I’ve brought you a couple thousand words in and encouraged you to consider and reconsider a brave new world. Now how should you move forward with content from language models? Really, there are six things you should do to leverage them effectively:
- Fine-tune the model – You should be fine-tuning your model to generate copy that better reflects the brand voice. Rather than using off-the-shelf marketing tools (like GPT-3), you should work with your engineering team to construct a model that gives you what you want. Alternatively, where fine-tuning is not possible, you can prefix tune.
- Generate copy in short bursts – Rather than writing a single prompt and asking for 500 words, write a series of prompts and vary the length of what is returned by that prompt. The longer the copy, the more likely the language model will go off the rails. We’re clocking in at just 5000 words for this article, so I’m going to showcase more insights on how to do effective prompt engineering in a later post.
- Incorporate data – Underlying your website is a data model, leverage that data model as part of your prompts to generate more varied that is directly reflective of your offerings. This is especially easy if site is using a Single Page Application (SPA) and is consuming API endpoints with a bunch of JSON objects that expose the data in a structured way. Leverage those same endpoints to power the content you’re creating.
- Focus on utility content – NLG tools can inform creative brainstorms, but they are not the tools for building “creative” content…yet. In terms of SEO, you’ll want to limit your NLG content to the non-creative content like that of PLP or Category pages rather than expecting that your blog has become a push-button object.
- Put everything through an editorial layer – I cannot stress this point enough. Do. Not. Generate. Copy. And. Immediately. Publish. It. If you need to scale, consider a service like EditorNinja as part of the workflow.
- Apply a layer of optimization – NLG writing tools may result in similar co-occurring word usage that is encouraged by content optimization tools, but it also may not. It’s worthwhile to further optimize entity, word usage, internal linking, and semantic markup in service of positioning the content to perform.
I present these recommendations as a means of brand protection and to avoid publishing unusable content. I do not present them as a means to avoid penalization by Google. As with any SEO recommendation, your mileage will vary, so I recommend that you test anything you read before rolling it out at scale.
For some people, what I’ve suggested may be too resource-intensive and you may find that just writing the content is a better approach. Conversely, if your company has a website operating at enterprise-scale you’ll find these recommendations align very well with internal governance models.
How Close Are we to Perfectly Optimized Content?
The closest I’ve seen to my ideal state of automatically generated perfectly optimized content is the SurferSEO and Jasper AI integration. Since our deployments of natural language generation are custom builds, I have not had the opportunity to see this integration in action yet, but the demo suggests that the user is able to take elements from features extracted from ranking pages (via SurferSEO) and auto-generate copy (via JasperAI). That in and of itself is a brilliant move forward.
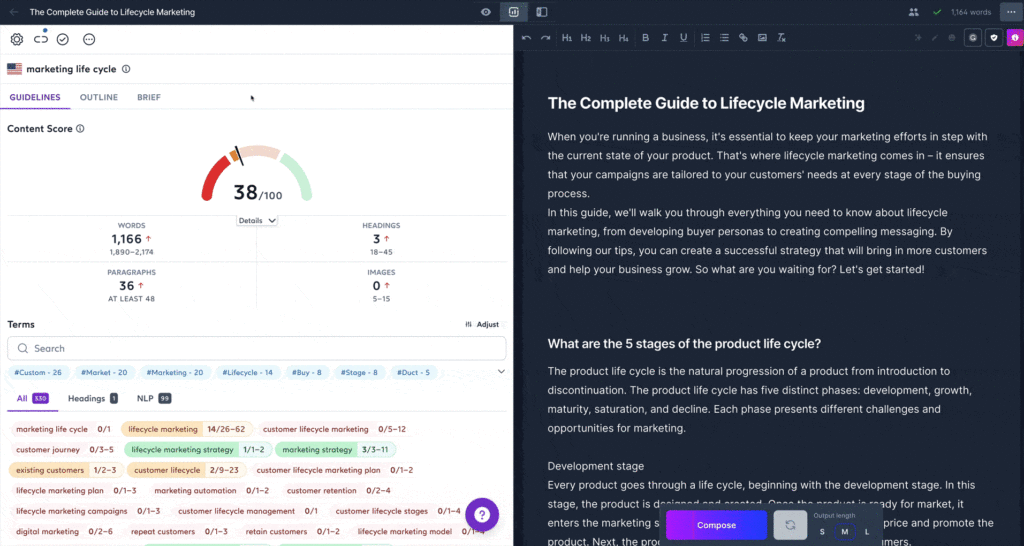
The automated internal linking, entity optimization, semantic markup, and transcription components do not appear to exist here yet. Those are great places for tools Inlinks or WordLift to close the gap. That said, all the technology exists, it’s really just up to someone to tie it together with those use cases in mind. Did I mention we have an engineering team?
Word is Bond
At the end of the day, this all raises three, perhaps, existential content questions for the Web:
- If the content actually shows utility to users, does it even matter how it is made?
- If the content is edited, is it still considered machine-generated content?
- If anyone can generate all the content, how do you determine what to rank first?
That last question is an indication that the link graph can never go away, but there are other concepts such as information gain that I’ll need more space to go into. Suffice it to say, the rarer information in the document set becomes more valuable when everyone else is covering the same things.
On the other two points, the latest version of Google’s guidelines, as they relate to “machine-generated content,” is actually a bit more liberal than expected. As of this writing, here’s what they are (emphasis mine):
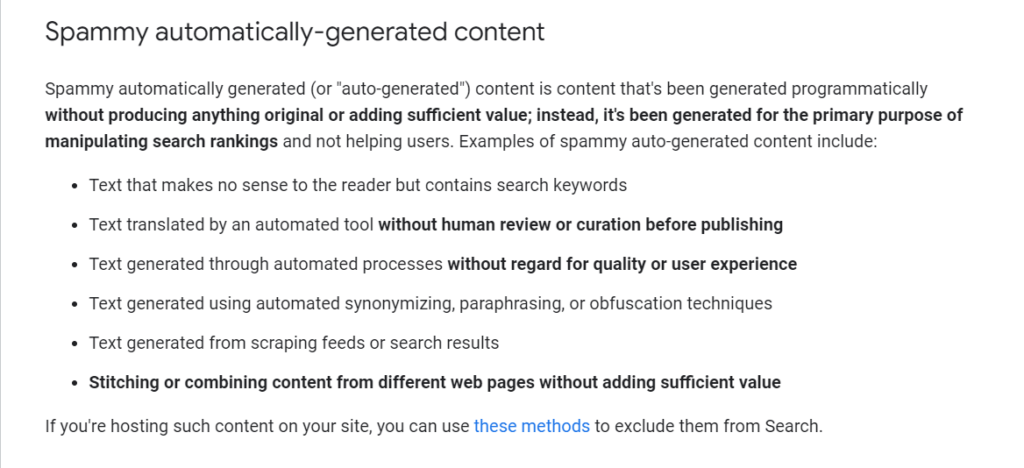
Much of what I’ve classified as “utility content” could fall under this definition, but if you’re going to create such content, you should be doing it with the rare user who will actually read it in mind rather than just for a search engine. Bullets two and three should naturally be covered by your site’s editorial requirements. Really, it’s the last bullet that places the output of a large language model technically in question. After all, conceptually, a large language model is just stitching or combining words based on what it’s learned from other websites, but again, your editorial guidance should ensure that sufficient value is added.
However, there has been content in the wild for years that more directly violates these guidelines, yet many people get value from it. For example, news wires, financial publications, and many sports news sites have published “machine generated” copy by parsing financial reports and data from games for years. People continue to derive value from those articles and journalists are freed up to write more creative or investigative pieces with the time they save from rote tasks.
Google Search demonizing the usage of large language models to improve and scale content would actually be quite hypocritical, especially in the context of AI Overviews. At the very least, Google given the advancements that they as a company have driven in the natural language space, their usage should be accepted. After all, once you’ve edited the content for brand voice and tone and made optimizations, it’s no longer automatically-generated content. It’s content that was guided by an LLM.
Oh, and for the record, nothing in this blog post was generated by a language model — or was it?
Are you or your team looking for an agency to put your generative AI content strategy in place? Schedule a call with me.
Next Steps
Here are 3 ways iPullRank can help you combine SEO and content to earn visibility for your business and drive revenue:
- Schedule a 30-Minute Strategy Session: Share your biggest SEO and content challenges so we can put together a custom discovery deck after looking through your digital presence. No one-size-fits-all solutions, only tailored advice to grow your business. Schedule your consultation session now.
- Get Our Newsletter: AI is reshaping search. The Rank Report gives you signal through the noise, so your brand doesn’t just keep up, it leads. Subscribe to the Rank Report.
- Enhance Your Content Relevancy with Orbitwise: Not sure if your content is mathematically relevant? Use Orbitwise to test and improve your content’s relevancy, ensuring it ranks for your targeted keywords. Test your content relevance today.
Want more? Visit our blog for access to past webinars, exclusive guides, and insightful blogs crafted by our team of experts.