
My 2020 MozCon presentation was a short film created by the iPullRank team.
I’m not going to spoil it because I’d rather you watched it, but the movie is one part “Batman: The Animated Series” and one part “Mr. Robot” presented in a mixed-media format.
If you haven’t seen it, we’ve just released a Director’s Cut as well as all the related resources and code (all the tactics and code are real) from the film, so please have a look. We made it for you!
What I want to highlight today, though, is the scene toward the end of the film wherein the concept of scalable text generation is explored.
Have a look:
In this scene we’re depicting our protagonist, Casey Robins, figuring out how to programmatically generate copy for ecommerce category pages and incorporating data into that copy based on the JSON object used to populate that page.
Yeah, that was a mouthful, but it’s the coolest tactic that I’ve devised in the past five years, so bear with me!
DataToText Is Still Academic, But Here’s a Hack
As I mention in the dialog, there’s a field of Natural Language Generation study called DataToText wherein people are taking structured data and using it to generate copy.
In academic research, engineers have highlighted use cases like giving recaps on sports games and also for generating copy for ecommerce product pages.
Here’s an example of copy generated for a sports game recap from the paper, A hierarchical model for data to text generation.

Here’s an example of copy being generated for a product detail page from the paper, Storytelling from Structured Data and Knowledge Graphs.
Naturally those use cases are a direct reflection of things that would support scalable content creation for SEO.
So, I figured DataToText would be ready to roll and I could just hand some structured data off to an API and be all set.
So I skim-read a few of these papers and tried to run some of the code.
I was, frankly, out of my technical depth and not willing to commit to reading thoroughly enough to truly figure out how to do it.
What do you want from me? I have two children and I’m responsible for two businesses during a global pandemic.
So, instead, I’ve identified a shortcut based on what I already know how to do.
Many ecommerce sites are built on Single Page Applications.
This means that there is an API endpoint somewhere that the client-side code accesses in order to populate its content when a page is being constructed or updated.
By design, many of those API endpoints are open and available to us and the authentication is often little to none.
We can use these same endpoints to gather features and derived data points to generate unique and relevant content.
We can use this data to develop a series of sentences with a significant amount of variance to get the data into a paragraph.
Then we can use a natural language generation library (hello GPT-2!) to complete those paragraphs.
Varying the length of the paragraphs and where that varied sentence falls in a given paragraph will yield a wealth of completely unique and relevant content that features our key data points.
Ok, but before we get into how we do that, let’s talk about how we got here.
How I Was Wrong About the Future of Text Generation
When I gave a talk on Machine Learning at SearchLove a few years back, I said that SEOs should avoid ML-driven content creation because it wasn’t good enough.
There have been well-known instances of this type of content going sideways when used to generate financial reports and sports recaps.
There have also been companies such as Narrative Science and Automated Insights that have occupied this space for years.
Those solutions heavily rely on templates with variation and the insertion of variables rather than the generation of truly unique text.
At the time I gave that talk, I didn’t think we’d have anything viable for effective and distinct copy generation for at least another decade.
I was wrong and I later corrected myself two years ago at TechSEOBoost. I’d predicted that in the next five years that text generation would be ubiquitous.
Well, the time to begin to capitalize on this technology for SEO is right now.
An Incomplete & Self-Referential History of Content Generation in SEO
Earlier in my SEO career, I didn’t know much about the SEO community at large, so I reinvented the wheel a few times.
I say this because the concept of content spinning is explained effectively by how I arrived at it.
In 2007, there was a song by the rapper Canibus called “Poet Laureate Infinity.”
The core premise of that song was that the emcee had recorded five versions of a 200 bar verse that you could use to form a new verse.
The verses were multi-tracked on top of each other, but bar one in one version rhymed with bar two in another verse and so on.
The song was presented with a visual interface on the Canibus.com website that allowed the listener to toggle which version of the verse was playing at any given moment.
Effectively, you could have infinite permutations of the 200 bar verse you heard based on what you toggled.

At the time that was released, I was working for a company that had a network of sites only really differing only by their location and company name. I thought to myself, we can apply the same concept to content.
So, after using some math from my Discrete Structures textbook to build a business case, I’d worked with a copywriter on my team (what’s up, Jacques!) to write five versions of a piece of content.
He made all the paragraphs the same number of sentences and all the sentences in each version work with the sentences in the next.
I’d also instructed him to leave markers in it for locations and company names so that we could populate them into the content.
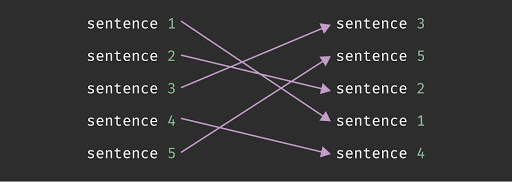
I put them all in a multi-dimensional array, randomized them, and did a string replace on the markers and generated copy.
I also compared the edit distance to other versions of the content that were generated and only spit out a version that was at least 70% unique.
This was 2007, before algorithm updates named after animals were on the scene, so the tactic worked like magic.
Naturally, the SEO community is full of very smart people who’d already arrived at this same conclusion without the help of a nerdy rapper.
Some of the SEOs that I now call friends, were doing more sophisticated implementations of this using Markov chains and variants on the word and phrase level.
I’d later come to know that there are programs that do this using what is called “spintax” as seen below.

This tactic is known as content spinning.
Oftentimes, it is used on other people’s articles to duplicate existing articles by just changing the words around.
Content spinning as I described above is in the bucket of tactics that people reference when they talk about “SEO content.”
It tends to be very keyword-rich, repetitive, and generally not for human consumption.
In a lot of cases, the content does not even make sense because people don’t check the output before publishing.
Both “SEO content” and content spinning are not tactics I recommend.
However, the reality is that there are many ecommerce sites out there that have seen significant organic search traffic improvements from madlibbed copy and duplicate content.
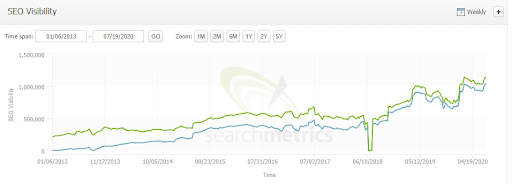
Case in point, in the graph below, you’re seeing the growth of visibility for a large ecommerce site.
The green line represents all of its organic search visibility. The light blue line represents the visibility for a directory that houses nothing but duplicate content.
Those lines get closer together after the deployment of a few sentences of madlibbed copy.
If you’ve done SEO for large websites with high authority, you know that just following best practices means losses in opportunity.
However, being that this does work so well, it’s worth considering a much better way that can yield content with more utility for the user.
Enter GPT-2
Natural Language Generation is what content spinning wanted to be when it grew up.
There are still tools out there like RosaeNLG that refer to themselves as natural language generation tools, but they are simply good content spinners.
The Natural Language, Processing, Understanding, and Generation fields have evolved dramatically in recent years on the backs of neural networks and the ubiquity of processing power.
If you’ve paid attention to Google Search’s announcements regarding natural language in the past couple of years, you may have heard of BERT.
BERT stands for Bidirectional Encoder Representations from Transformers.
The keyword here is “transformer.”
To oversimplify, Transformer technology is built on the idea of learning from content and using that learning to determine probabilities of what the next word is most likely to be based on the previous word or the previous series of words.
This is the technology behind the predictive text in your Gmail and in your text messages, if you’re on Android.
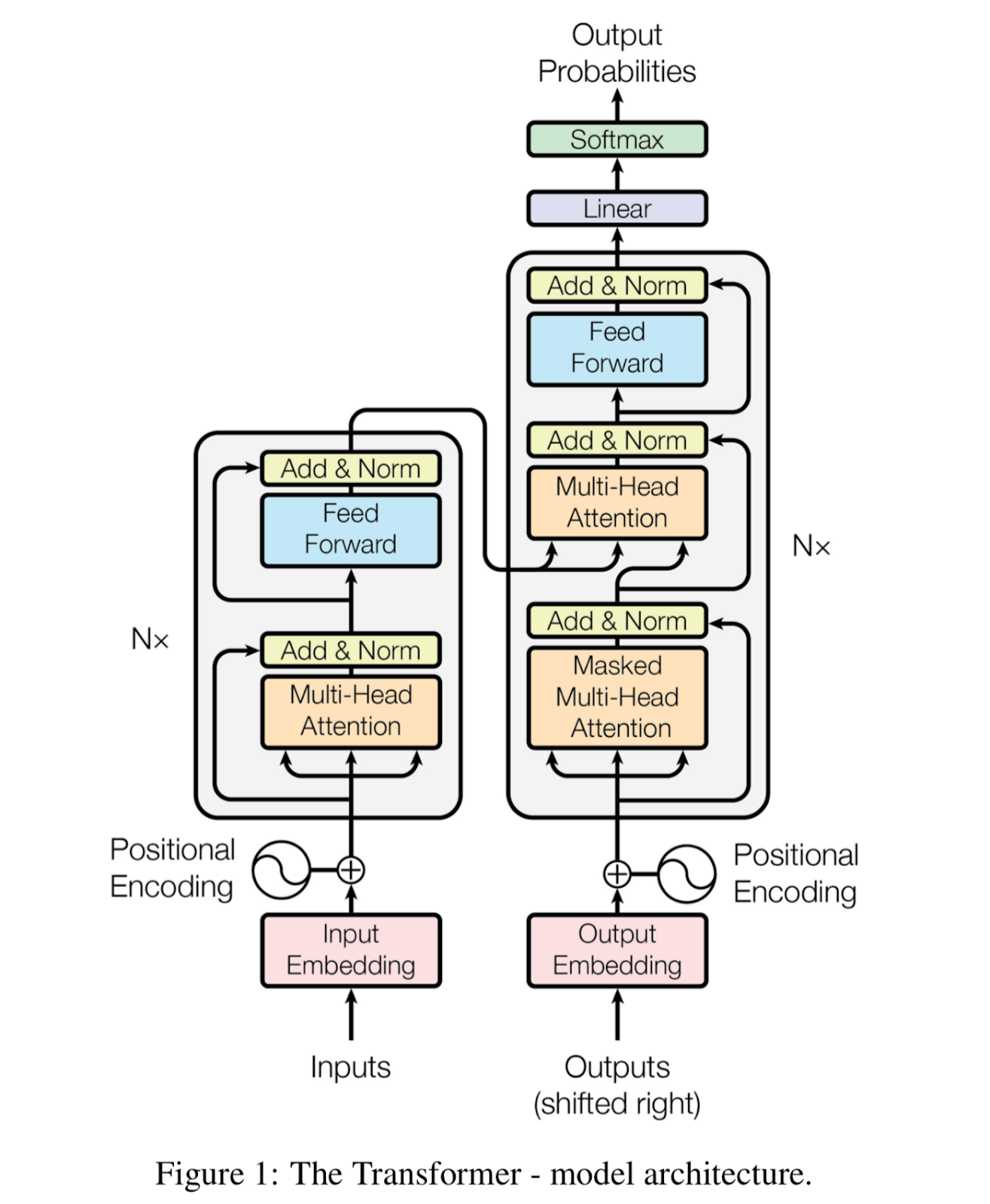
GPT has revolutionized the text generation space in using that concept to create copy.
GPT-2 is the second generation of Elon Musk’s OpenAI team’s Generative Pretrained Transformer library and it is capable of writing copy that you will find very difficult to distinguish from a human.
When they first announced GPT-2, it was in the wake of the fake news outbreak, and they said it was too dangerous to release to the public. (Note: the antagonist in Runtime references this directly).
Ultimately, they did release it, but with fewer parameters than they’d trained it on.
Rather than 1.5 billion parameters, they originally released it with a maximum of 774 million parameters.
Despite that, the available pre-trained models are very good at generating copy and you can fine-tune the model based on any data you want to provide it.
In the film, Casey fine-tunes the model by using scraped copy from a competitor’s website.
If your site has a substantial amount of copy, you should train it on that.
GPT-2 works in practice by giving it a prompt and some parameters to tell it to generate a certain amount of words.
With the tactic that I’m describing, I’m recommending that you use content spinning as your mechanism of feeding it the prompt.
Effectively, you get your data into a sentence using your content spinner and then feed that spun content into GPT-2 as a prompt.
From there you’d generate n words and then pull your next sentence and keep doing that until you have however much copy you want.
It is important to note that GPT and its successors are not the only models for this type of text generation.
- Google has one called T5 that was trained on a cleaned version of the CommonCrawl.
- Salesforce has one called CTRL trained on 1.6 billion parameters.
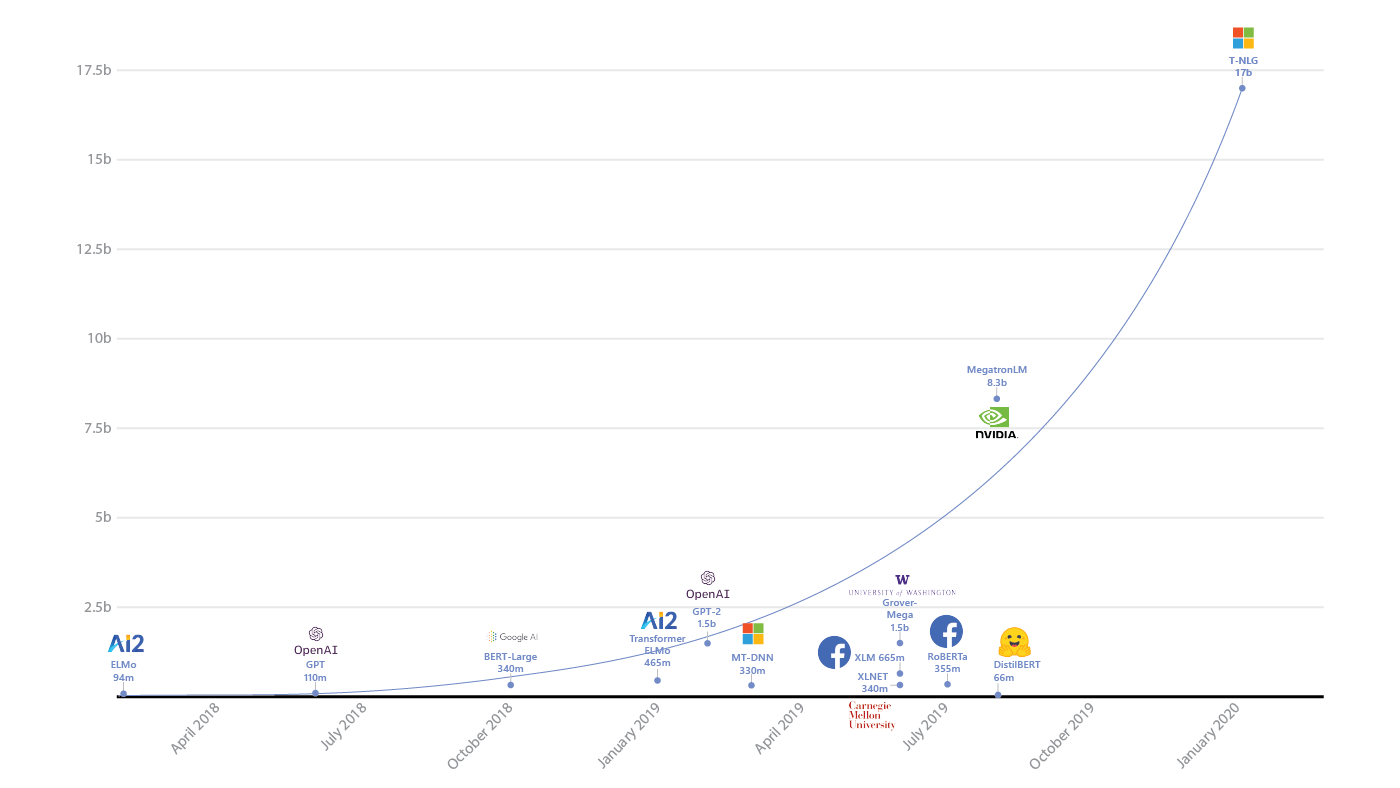
- Microsoft has one called TuringNLG which is trained on 17 billion parameters.
So, it’s not just Elon Musk that is about to cause an explosion in machine-created content that floods the SERPs.
GPT-2 perhaps has the simplest implementations that I’ve come across due to its popularity.
And while I’m on the subject of different models, I’d like to give a shoutout to Hamlet Batista who has been leading the thoughts in our space around practical applications of NLP and NLG.
How to Find the Data That Populates a Page
In the film, Casey identifies the endpoint and HTTP request from the Network tab in Chrome that contains the data points used to build the category page.
You shouldn’t have to do this for your own site because you should have direct access to the data model.
For illustrative purposes, you’d typically find that data by limiting your Network transactions to XHR.
Once you’ve rifled through the AJAX requests and found the ones with all the data, right-click the request in Chrome to pull the details.
Here’s an example from Nike.com. This is their Men’s Basketball page.
Nike.com is built with the Single Page Application framework React. The site has an API endpoint that lives at https://api.nike.com/cic/browse/v1.
That endpoint is used to populate products on pages.
Within Chrome, you can get the exact details of the HTTP request as a fetch, NodeJS, or cURL command used to ping that endpoint by right-clicking the request.
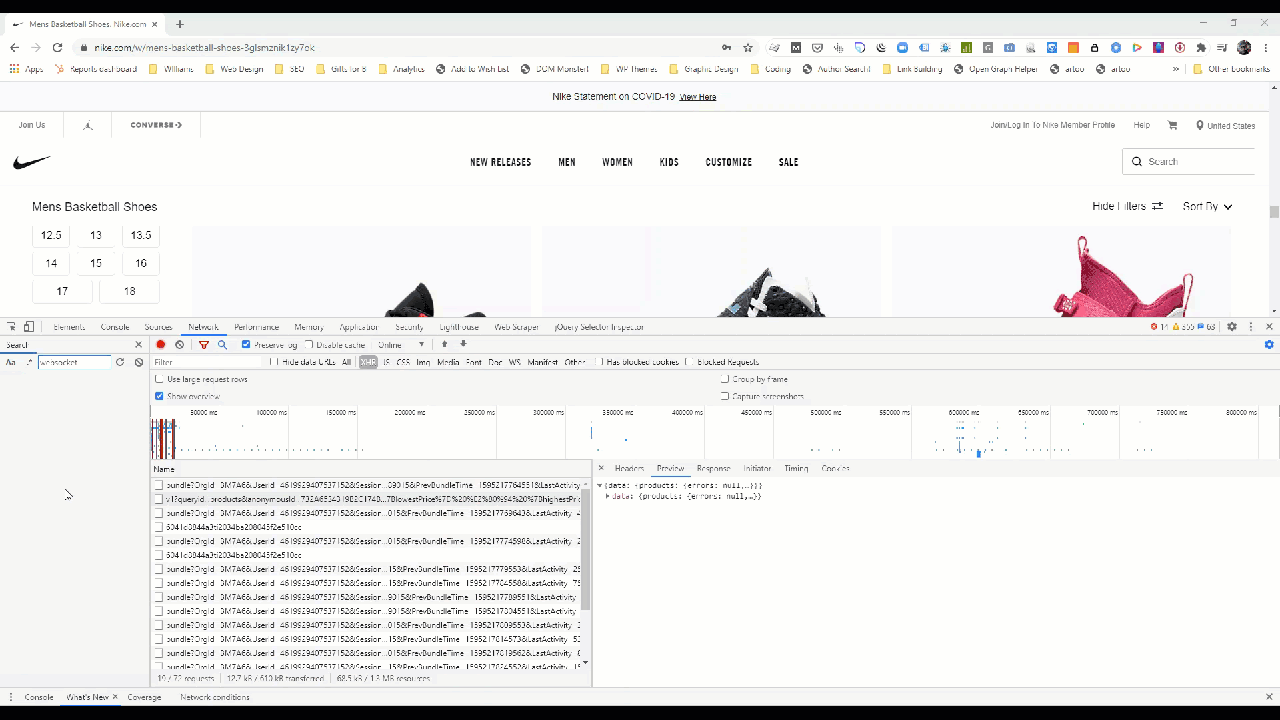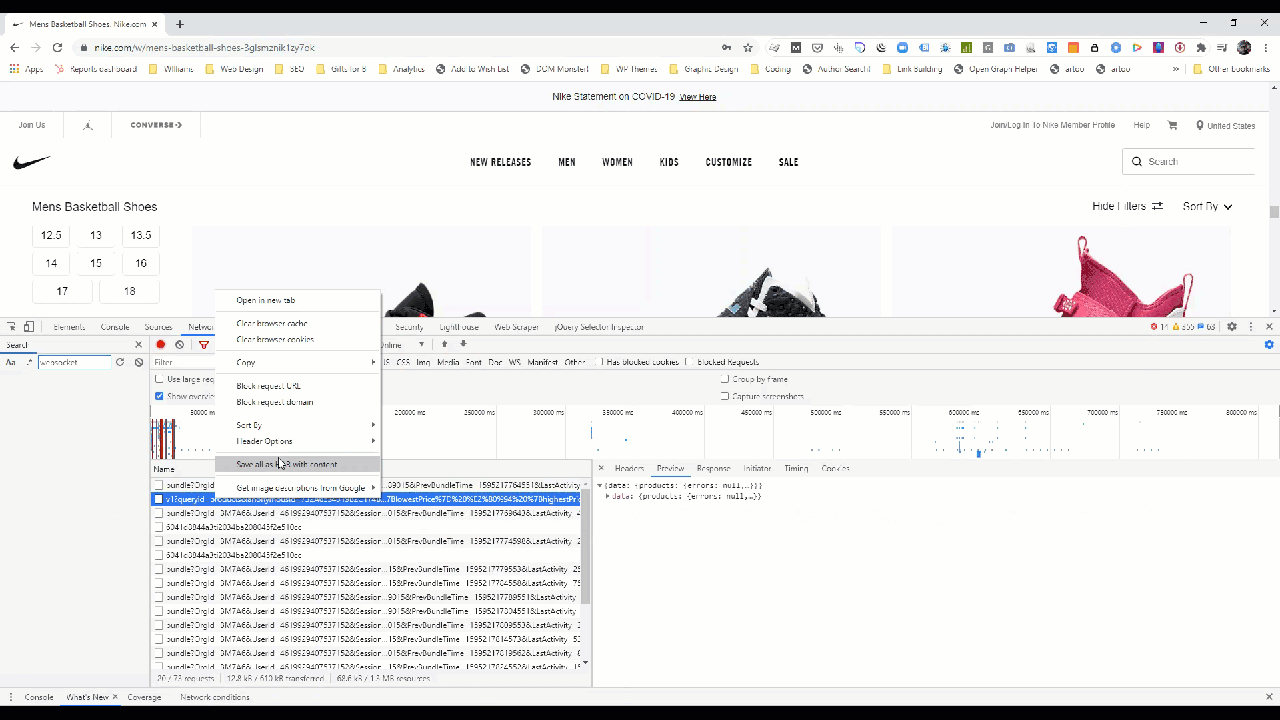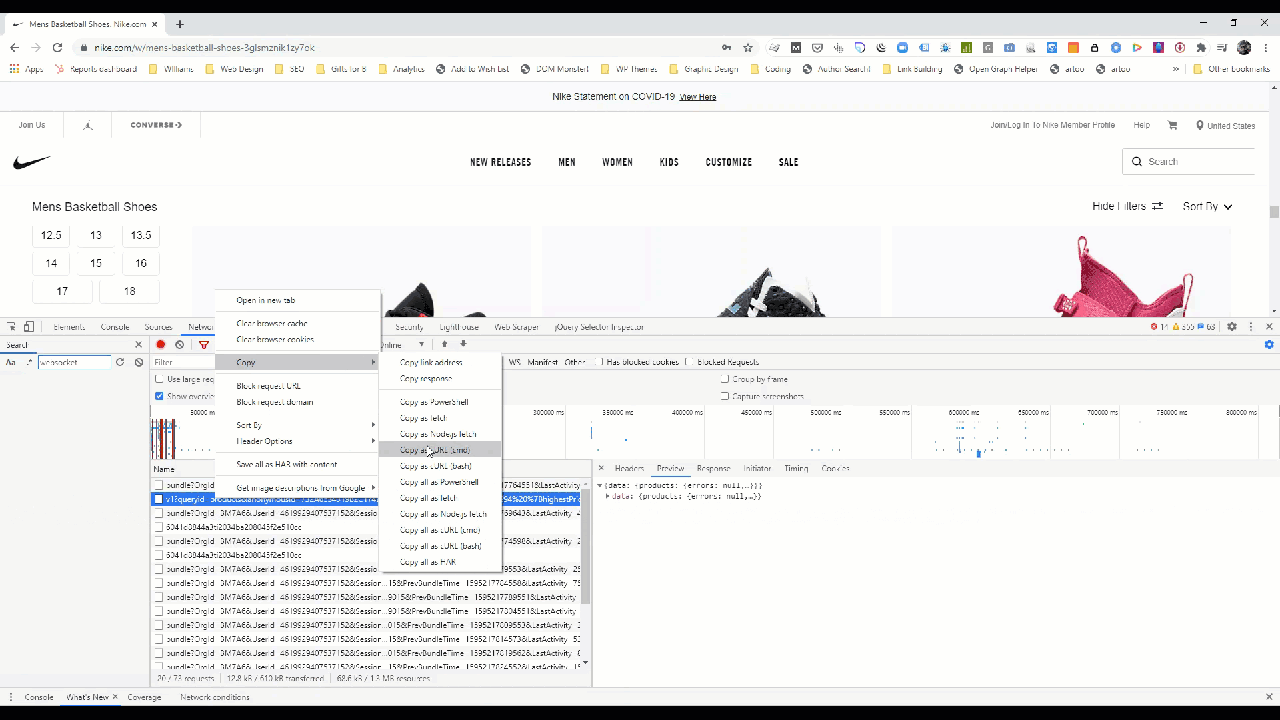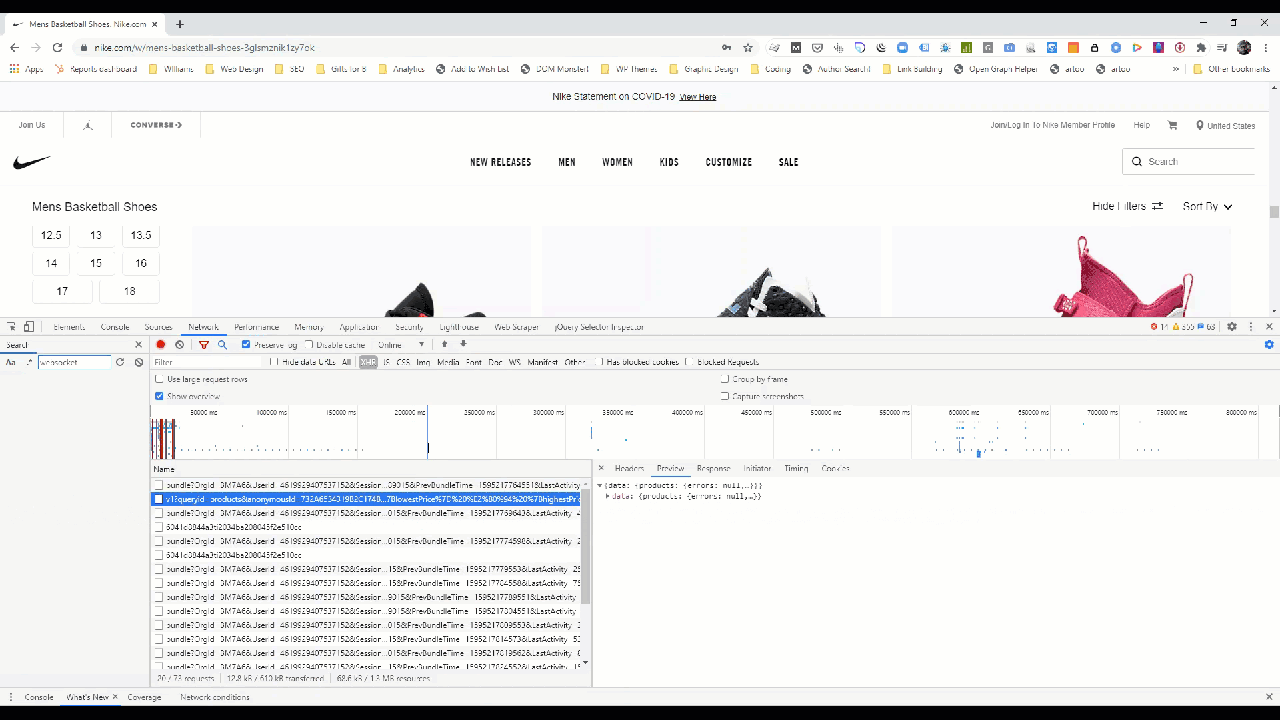
In this example the cURL request looks like this:
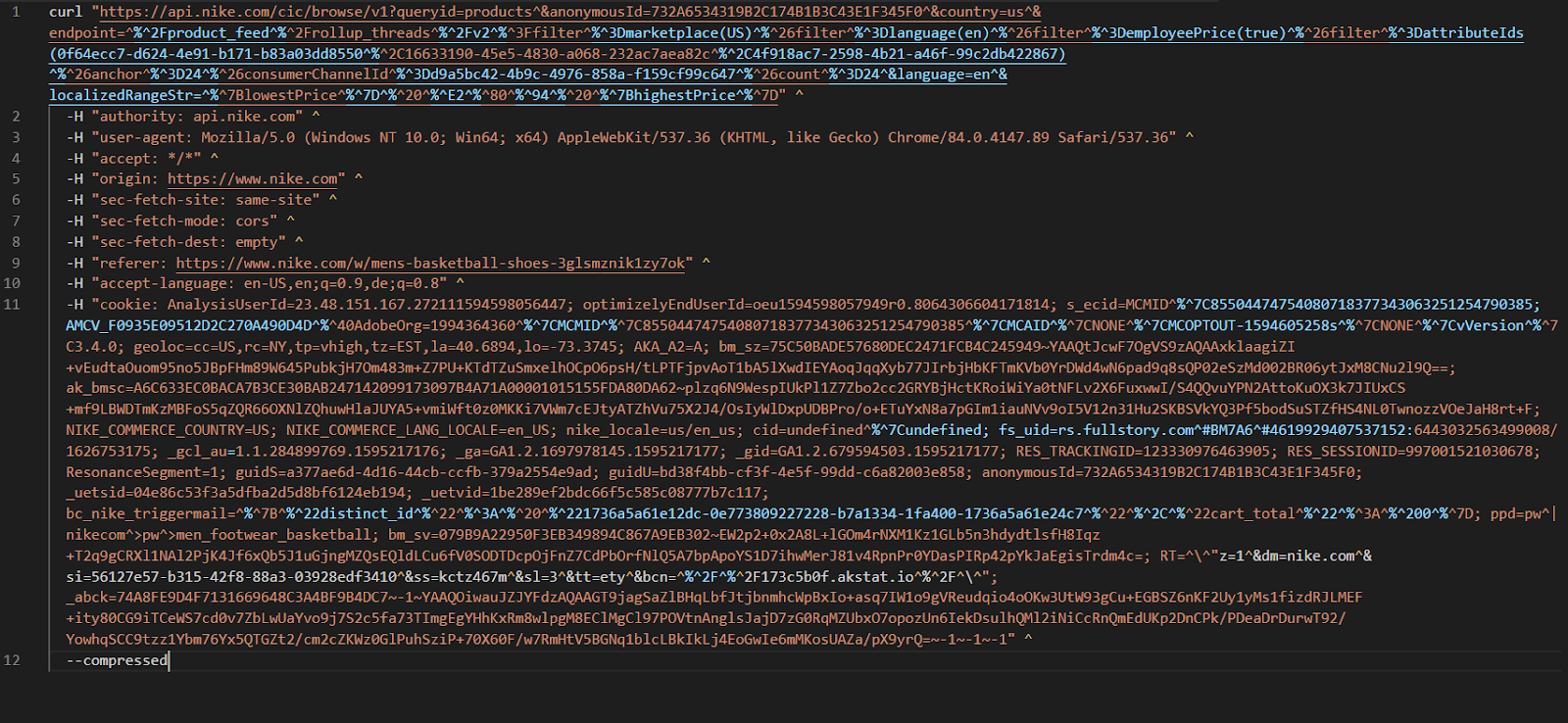
Granted, some sites are sophisticated in that they don’t allow you to easily access these endpoints from a command line and Nike is one such site.
So, you’d likely want to use Puppeteer to load the page, intercept and save the XHR responses from api.nike.com.
The JSON payload you’re looking for tends to have several nested nodes.
You can see this in the Network tab by going through the individual requests in the waterfall.
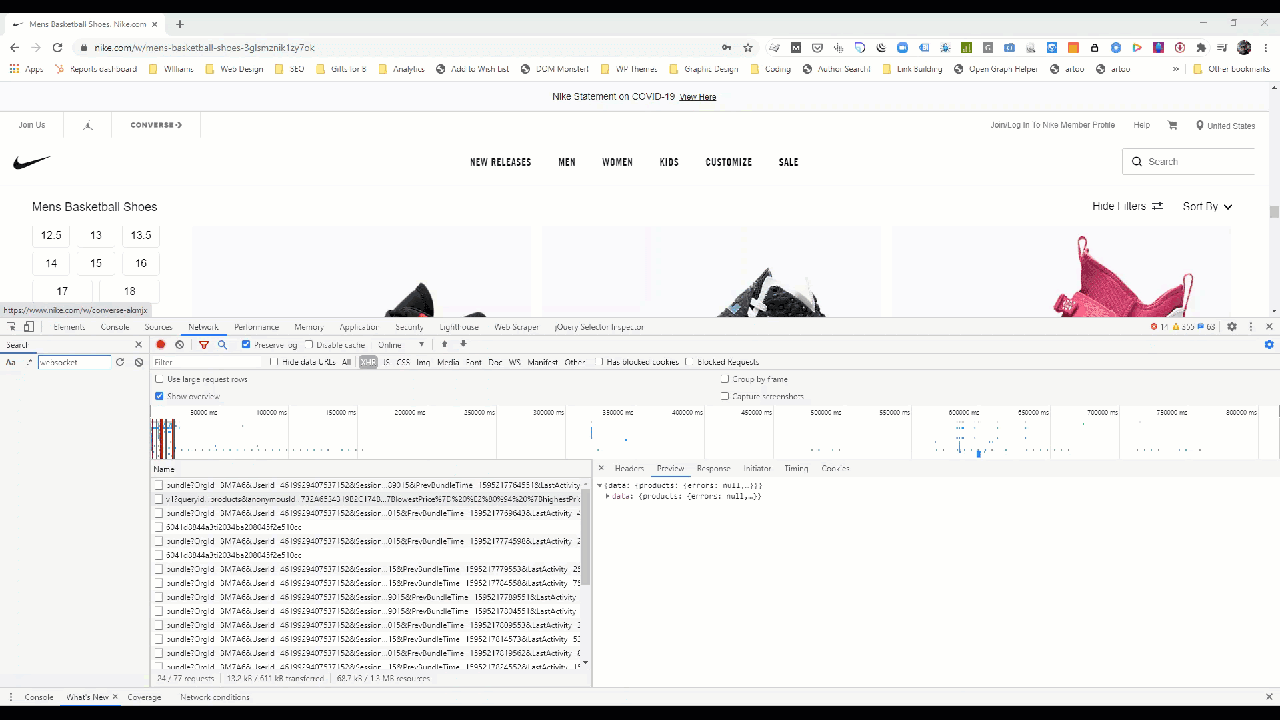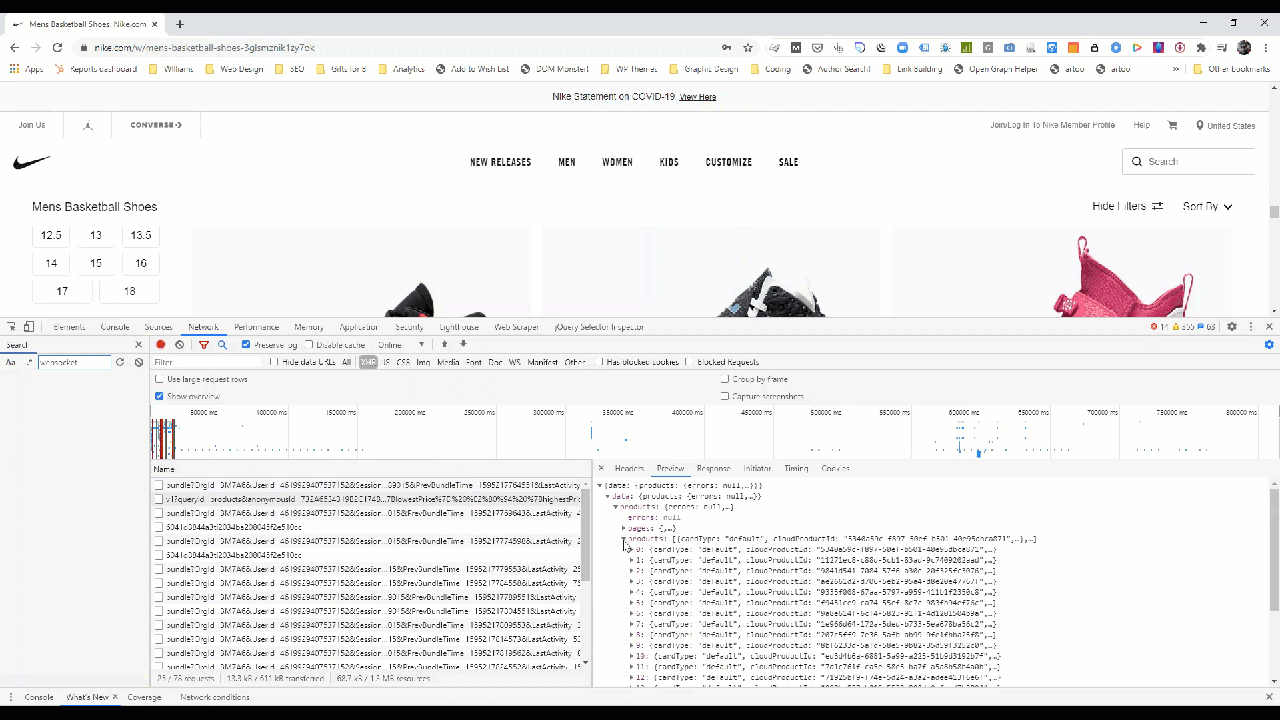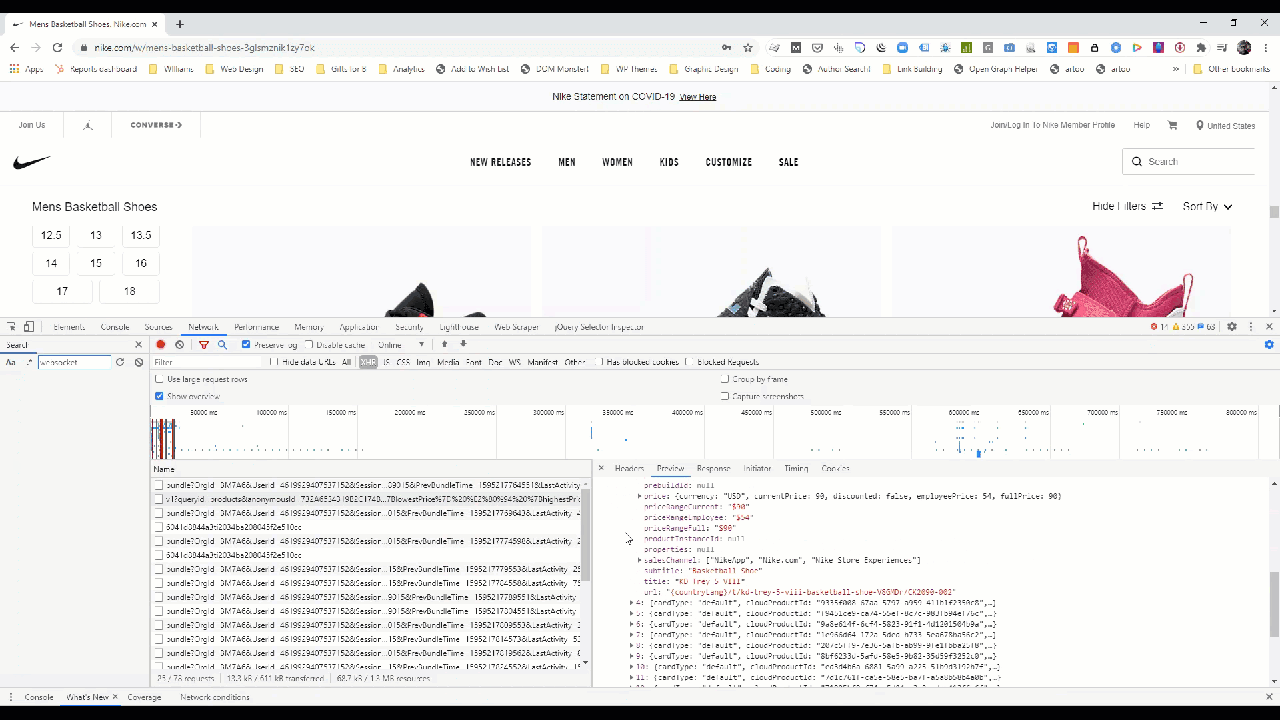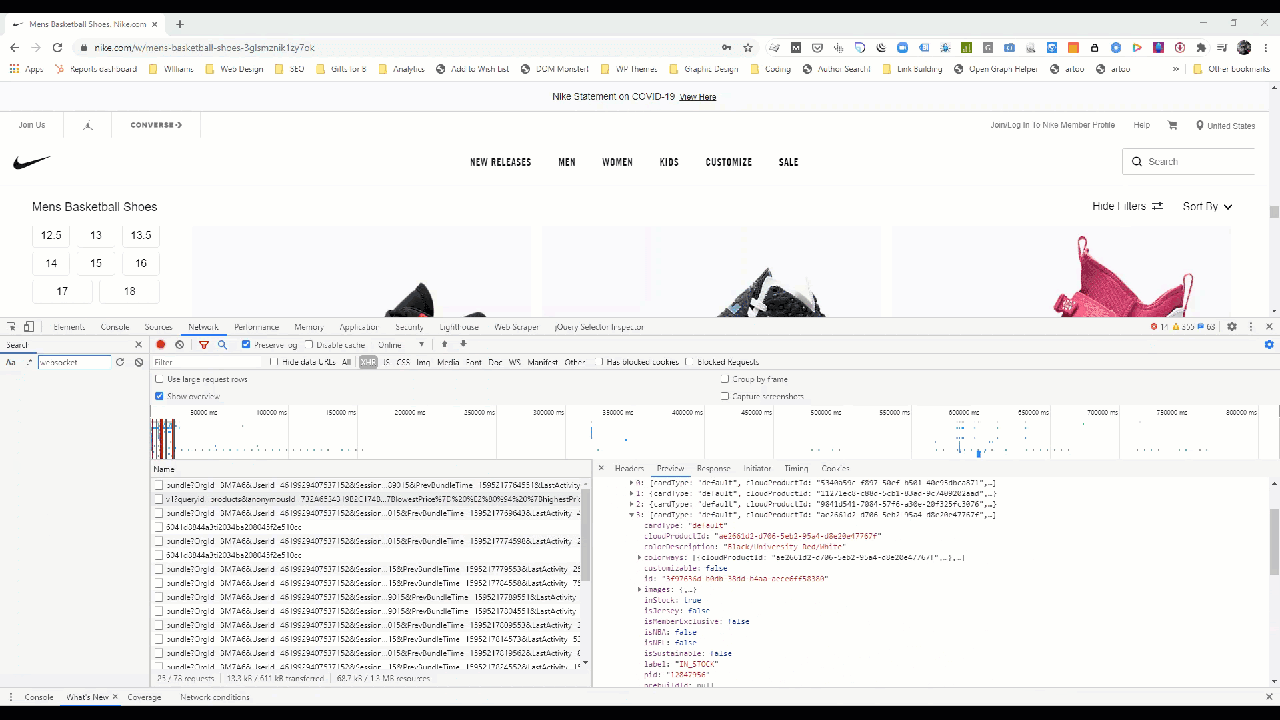
If we zoom in a bit, we can see the features in the data model that Nike makes available in the construction of this page.
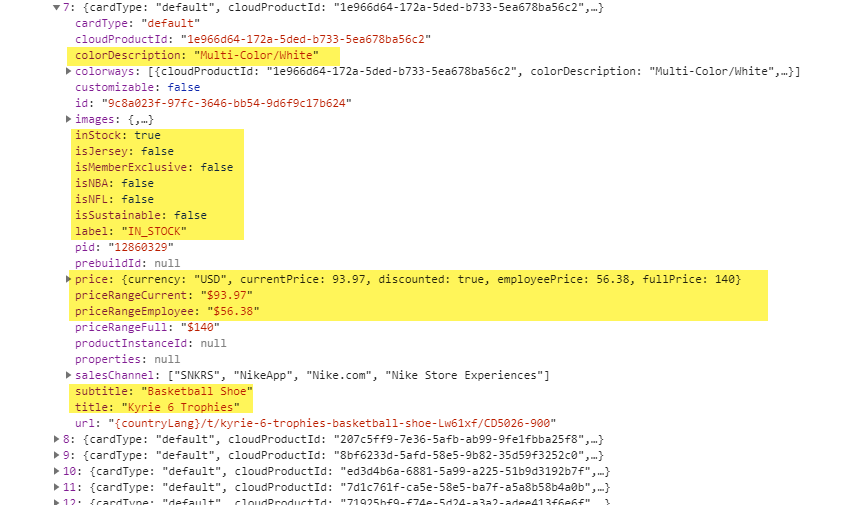
Consider in this case that we have the following available to us:
- Color Description: The high-level colorway of the sneaker.
- inStock, isJersey, isMemberExclusive, isNBA, isNFL, isSustainable: Boolean features to indicate key characteristics of the item.
- Price: In case you know someone who works for Nike, you now know the employee price.
- Subtitle: Type of the item.
- Title: The name of the item.
Now you have the endpoint. You can take a look at a series of different pages to better understand the parameters in the request so you can extract what you need.
Review the data thoroughly and think through which data points you can use directly and which data points you can derive from those.
For instance, if you have prices for 10 items, you can derive an average price from that data point. If you have in-stock numbers, you can potentially derive popularity.
In the example above, we could derive an understanding of the sustainability of the sneakers and put together some language related to that.
To simplify, these variables could be used to build a sentence like:
Looking for the best Basketball Shoe? We’ve got the Kyrie 6 Trophies.
The template for that sentence becomes:
Looking for the best {subtitle}? We’ve got the {title}.
From that sentence GPT-2 could generate this paragraph:
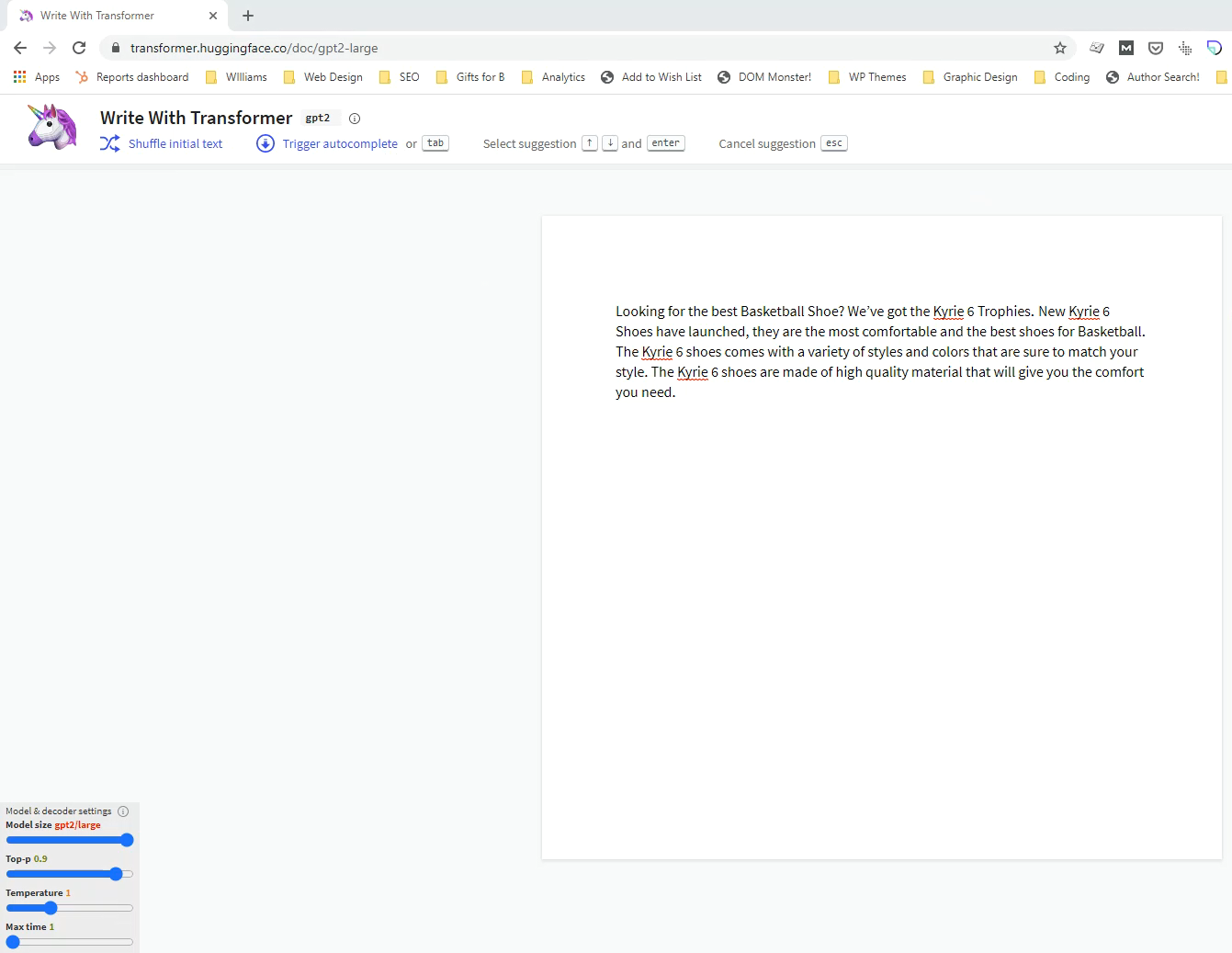
You can play around with this idea on the WriteWithTransformer.com site by the HuggingFace team.
Keep in mind that this site allows you to generate copy using the GPT-2 large model rather than the 355mm parameter version being used in the examples below.
If you get stuck on identifying variants of the phrases you’re preparing, you can use data from Paraphrase.org.
How to Generate Copy for Category Pages
Now for the moment, you’ve been waiting for.
Here’s a Colab notebook using GPT-2-Simple to illustrate the text generation concept.
To paraphrase Britney Muller, it’s all just Control+Enter.
Here’s the step-by-step explanation of what needs to be done to get to this point:
1. Review Your Site’s Data Model
Looking at the data that is available will drive how you develop the data-injected blocks.
2. Generate a Series of Sentences That Incorporate Those Data Points
Identify phrase variants from Paraphrase.org.
This is an optional step if you run out of phrases or don’t have a copywriter you can work with, you can download the data from the Paraphrase.org project to get a list of phrases by breaking your phrases down into n-grams.
3. Collect/Scrape as Much Text Content as You Can That Is Relevant to Your Space
If your site has a wealth of copy, you can pull that. Otherwise, pull from your competitors.
In this case, I pulled from the #main > div > section:nth-child(4) element on Foot Locker’s category pages and fed it to the model.
You save everything you scrape into one text file with end-of-page markers at the end of each page. In this case, I’ve used “<|endoftext>|.”
4. Fine-Tune a GPT-2 Model
Feed the text file into GPT-2 to build a model that you can use going forward.
5. Populate the Sentences With Data From the Data Model
Generate your individual sentences through content spinning using a library like wink-nlp-utils.
It has a function called composeCorpus that can be used like any other content spinning tool.
6. Use Your Data-Driven Sentences as Prompts
Each of those sentences is then fed to GPT-2 as prompts to generate as much copy as you’d like.
You can vary the length of the generated content and the placement.
For instance, you could place one sentence and say give me 50 words or place two sentences and then prompt it to give you 200 words.
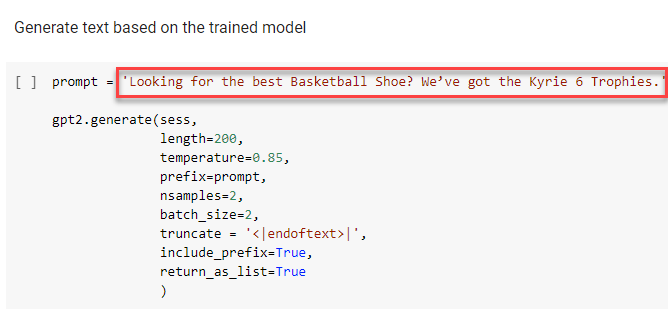
Change the copy in red to see what happens when you add your own prompt.
7. Review & Edit
Once you’ve got your copy, make sure it makes sense and edit whatever doesn’t, or have the model generate another option.
8. Deploy
Once the copy meets your brand voice, tone, and user expectations, put it on the site and watch your keyword-relevance soar.
Can You Do This With Editorial Content?
This was already examined by Vox and the New Yorker, but I was curious about it as I started writing this post.
So, I scraped all the blog posts that I’ve written about digital marketing and used them to fine-tune a GPT-2 model using 355m parameters.
I took some of the beginnings of sentences that I wrote in this post and looked to see what it might give me.
Here are some examples of what it spit out:
When I gave a talk on Machine Learning at SearchLove a few years back, I said that SEOs should avoid ML-driven content creation because it wasn’t good enough. I also said at the time that SEOs should avoid using models that didn’t align with the viewpoints of the people that the content is for.
I was obviously incredibly misguided, and very much the definition of an optimizer lies within those words. However, I also fundamentally believe that the results of using those words are that we waste time and Google is right to weed out the bad actors.
I talk at length about how I arrived at this position, why I changed my mind and why I changed my recommendation at the end of June. I also share a secret weapon that I use in the incubation phase of every New SEO project.
It is precisely this shared interest in content that makes the two of us unique and why so many people tell us they want to help us grow together. I imagine there are plenty of opportunities for us to share more about what we come up with together, or at the very least, have someone print out our whiteboard based presentations.
This one was especially funny to me:
Earlier in my SEO career, I didn’t know much about the SEO community at large, so I reinvented the wheel a few times. I said I wanted to be a renowned speaker, and I did. I made a lot of friends while I was doing it. It was a great experience; I learned a lot, and many people I now interact with everyday are incredibly talented.
But it was the internet that got me. It was through one of my very first interactions that I learned about the Social Side of SEO.
Getting This Into Production
Another point I make in the film is that Python is great, but JavaScript is much easier to get into production.
This is not to say that Python is impossible to get into production. Rather, it is reflective of how all tech stacks for websites natively support JavaScript.
If the site is a Single Page Application, you can be sure that NodeJS is configured and every modern browser runs JavaScript.
However, you can’t be sure that the server has Python installed. If it does, you’d need to build an API on top of getting the libraries to work.
That said, the pipeline that is relatively easy to deploy would be in spaCyJS with the Hugging Face transformer add-on.
This gives us easy access to GPT-2. Effectively, spaCyJS is a NodeJS API for spaCy’s primary Python library. Using that, it is not difficult to use this pipeline to build API endpoint.
However, to keep this as easy as possible, we can create a serverless API using Google Cloud Run.
Once you’ve configured the API, you can send text as prompts and get back data.
You’d definitely want to pre-process and edit this content rather than populating directly to a site the copy on the fly.
Some Caveats
The most important thing to know about GPT-2 is that it is trained on web pages, so the text that is generated is not always factually accurate.
The more parameters you use and the bigger your training set is, the better it becomes.
Here are a few more details that the devil may be hiding out in:
This Type of Content Can Be Detected
When OpenAI first developed the GPT technology, they said they were not going to release it because it was too dangerous.
In typical Elon Musk fashion, they have walked that back, recently developing a third generation of the software they are releasing commercially.
That said, there are also a series of tools available to identify generated content. Here are a few examples:
- https://huggingface.co/openai-detector/
- https://github.com/openai/gpt-2-output-dataset/tree/master/detector
- https://gltr.io/
As these mechanisms for content generation become more popular, it would only make sense for search engines to consider using these detection libraries as part of content classifiers.
I imagine it being added to subsequent iterations of the Panda algorithm if Google determines text generation to be a problem.
Editorial Teams Are Not Dead
Natural Language Generation does not supplant editorial teams – yet.
As of now, you cannot generate copy and not expect to have a writing professional review it. GPT-2 focuses on word probabilities rather than identifying brand voice and tone.
So, you should use it as a first draft for editorial staff to review and adjust before deploying live.
Although, it is worth knowing that Google has indicated that its algorithms don’t solve for accuracy.
It is possible that the features of inaccurate content could satisfy processing and ranking algorithms.
You Should Not Deploy This Ad Nauseam
Fight the urge to generate hundreds of millions of pages.
Content blocks such as these are best deployed through A/B testing to make sure they truly have a positive impact.
Although, again, there are sites that have seen meaningful traffic impacts from three sentences of Madlib copy, so who am I to tell you not to blast the index with 9 billion pages of original, relevant, and potentially valuable content?
Tools in the NLG Space
As mentioned above, the key players in the content generation space have historically been Automated Insights and Narrative Science.
At the time of this writing, those companies are not doing what I’ve described in this post.
In fact, folks at Narrative Science are actively against creating on top of technology like GPT-2 because it does not generate factual content.
That’s certainly not a reason to not use the technology.
So here are a couple of other companies that I’m aware of that are using tech similar to what I’ve described here.
- InferKit: The person behind InferKit previously had a demo site called TalkToTransformer which allowed you to see what GPT-2 would generate based on the prompt that you provided it. He recently took that site down and built a SaaS API that does exactly what I’ve demonstrated above. InferKit allows you to use the core GPT-2 model or fine-tune it using training content that you provide.
- OpenAI: Elon Musk’s team recently indicated that they will be rolling out a commercial API for GPT-3 soon.
- MarketMuse First Draft: Closer to home, orbiting the SEO space is Marketmuse. The company released their First Draft product which uses NLG to 300-500 word drafts presumably based on the content briefs you create.
You can certainly expect that there will be plenty more companies that will pop up in the near future for this type of content.
GPT-3 Is Here & It Is Amazing
The latest version, GPT-3 boasts 175 billion parameters where GPT-2 was trained on only 1.5 billion parameters.
As you might imagine, with that much of a library of text to learn from, it’s even better than what we’ve just played with.
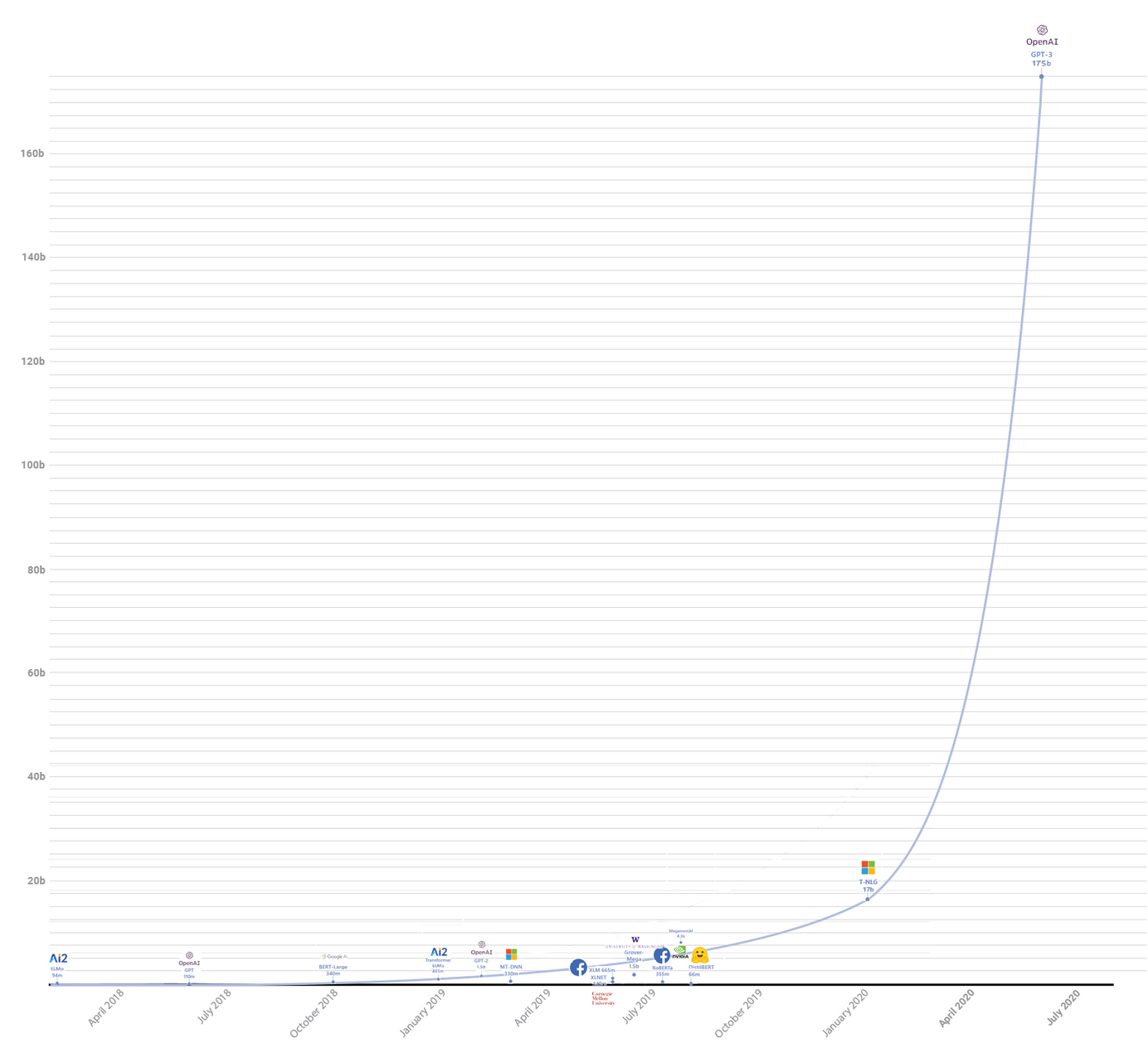
In fact, this content generation use case for SEO is actually a bit pedestrian compared to what people are figuring out now with GPT-3.
As of late, my timeline is full of developers who have gotten early access to GPT-3; they are using it to not just write copy, but to generate code and build search engines.
The more I think about it, the use case for propaganda generation is alarming considering the upcoming election, but that’s a problem outside my wheelhouse.
I expect that there will be many creative use cases that will change the web in the coming months.
Suffice to say, if you aren’t considering using this tech, your competitors are and I’m encouraging them to.
This Is the Future of This Type of Content
Over the past two years, you may have heard me talk a lot about what I call “Technical Content Optimization.”
We have leveraged text analysis concepts such as Latent Dirichlet Allocation and Named Entity Recognition to inform how we optimize sites and create content.
I believe there is a world wherein Attention and Transformer technologies are used against a SERP or a corpus from the Common Crawl and a given site’s data model to generate the perfectly optimized content against a query.
I’m imagining a world where you could ingest the text content on every page that ranks for your target keyword and use it to train your model.
Then you could give it a prompt and it writes content that scores perfectly.
At that point, though, it’s all algorithms vs algorithms and it will be back on us humans to stand out creatively.
It won’t be about whether or not we have the resources to create content.
It will be about how do we generate content that penetrates filter bubbles?
The real question is, are you ready?







