When I first heard about data science in 2012, I immediately fell in love with this nerdy field and started my 6-year journey in Statistics. I was inspired by a New York Times cover story about how Target broke through to a new level of customer tracking with the help of statistics genius Andrew Pole.
Pole identified 25 products that when purchased together indicate a woman is likely pregnant. This pregnancy-prediction model once exposed a teen girl’s pregnancy through sending coupons to the girl’s family even before the father was aware of this situation. I was really amazed at how smart an algorithm can be, and my next thought was, am I also likely to receive promotions for things I want, before I even know I want them? The answer is YES! That’s why we need data science in digital marketing.

What Can Data Science Do?
The ongoing information explosion has created a situation where it’s possible to utilize rich data and different tools to improve digital marketing performance. There are countless examples of what you can achieve with data science. In this blog, I will discuss using data science to segment current customers, score new customer profile data, launch data-driven email marketing campaigns, and in the end, drive customer loyalty.
Customer Segmentation
Successful business starts with knowing your customer. It’s important to first divide your customer base into groups of individuals with shared characteristics that are relevant to marketing, such as age, gender, interests, profession and spending habits. Then target different segments with separate approaches tailored to specific customers.
A major challenge with customer segmentation is the lack of good, clean data. When people sign up for a mailing list, they often don’t answer additional questions in the questionnaire, or they purposefully lie about their personal information such as age, marital status, and etc. In many cases, all they care about is getting the 10% off their next purchase; they couldn’t care less about whether the company has accurate data.
That’s where big data comes in. Instead of asking people to describe themselves, the modern marketers can use external sources of data and advanced analytics to infer things about their customers. Marketers can accurately ascertain facts just by observing their customers’ purchase behavior.
After gathering data, we can conduct clustering or classification based on the data type and ideal output. Clustering produces the output of grouped customers based on a distance matrix. However, where a cluster should be split is based on a criterion which specifies the dissimilarity of elements in the cluster in the sets. In other words, clustering provides a little knowledge on which variables differentiate one customer from another.
Decision trees, on the other hand, are interpretable and can also be easily visualized in an organized format. The decision tree can be used to represent the shared characteristics of high business value customers. Essentially, decision trees automatically derive a set of if-then-else rules to classify data (in this case the data describing the customers) into classes (in this case high business value customers vs. low business value).
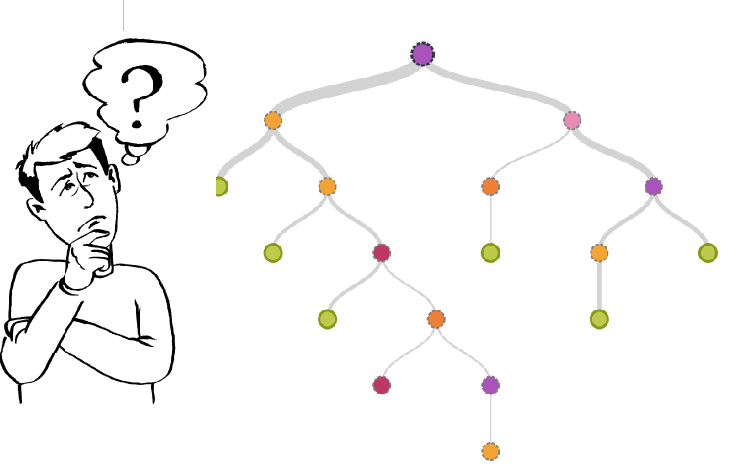
Source: Ask Analytics
Or you can build regression models to quantitatively score the customers. Once you have the segmentation model, it’s very easy to apply the model to score/classify new customer profile data. In the next blog, I will develop a step-to-step guide for customer segmentation.
Launch a Data-Driven Email Marketing Campaign
2015 was predicted as the year for “smart use of data” by EMarketer. This trend will continue and be fueled by personalizing email communications with customers. To achieve personalization, the first step is to collect valuable demographic and behavioral data. Here are some important metrics or information that help you better understand your customers:
- Demographic information: gender, age, profession, interest, and etc.
- Click-through rates, conversion rates and click-to-open rates
- Purchase activities on specific products
- Downloaded white papers or participated in a webinar
- Signed up for your newsletter or joined the email list
- Interacted with your social media sites as Facebook and Twitter
- Watched your promotional video
Gathering this data will allow you to segment your customers based on demographic and behavioral information and then send personalized messages with relevant content to each group. For example, send suggestions or promotions of other products people might be interested in purchasing based on products they’ve already purchased, or remind them that the products they’ve purchased will expire soon.
Timing is important to open rates. Research by MailChimp found that readers are more likely to open emails after 12 p.m. And that 23% of all email opens occur during the first hour after delivery. After 24 hours, an email’s chance of being opened drops below 1%!
Further research by Get Response shows that the best day to send emails in order to get the highest open rate is Tuesday.
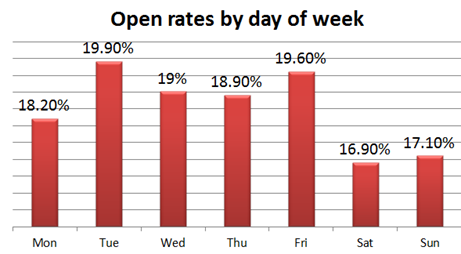
Source: SuperOffice
Now that you know on which day to send your emails, what about the time of day?
An interesting fact is that college aged recipients have an optimal time of 1 p.m. versus 10 a.m. for the people over 40s. College students during the summer likely drag themselves out of bed later and check their email later than older professionals.
If you collected the data for the time when your customer open emails, you can send an email customized to their behavior, or A/B test common-sense hypotheses, such as younger people open email at night, while older people open it at morning. A/B tests on send time give on average a 22% lift in engagement.
Drive customer loyalty
According to Forrester Research, it costs five times more to acquire new customers than it does to satisfy and retain current ones. As a result, smart companies are increasing their focus on retaining customer loyalty. The process to drive customer loyalty can be split into two parts: understanding of each customer’s behavioral patterns and churn prediction.
Understand customer’s behavioral patterns
If companies want to make their offers as targeted and personal as possible, they have to integrate and analyze large unstructured and streaming data from various data sources, such as text messages, e-mails, call center notes, voice recordings, surveys, GPS units and social media. Data scientists and engineers can help you incorporate and integrate your data into analytics and predictive models so that you can generate actionable information in minutes.
A good example in this case is how a global bank can improve their customer support. In the short time before the customer is connected to the representative, the representative can access customer data that may help predict why the customer is calling. Certain data can even indicate a major life event for this customer. As a result, agents are able to make the best response for that situation. For example, a customer may have a child ready to graduate from high school – this is a great time to discuss college loans.
Churn Prediction
To maximize your customer retention, companies should be focused on those customers that will likely leave. This is exactly what we do in Churn Prediction: building statistical models which estimate the likelihood that these customers will churn. Knowing which customers will likely churn is however not enough; you also need to know why these customers would leave you.
As we have discussed before in the customer segmentation, the decision tree algorithm can be selected as the predictive analytics algorithm for this application. From the decision tree, we can determine why customers will be churning, in order to properly address them, and to try to retain them through a personalized approach.
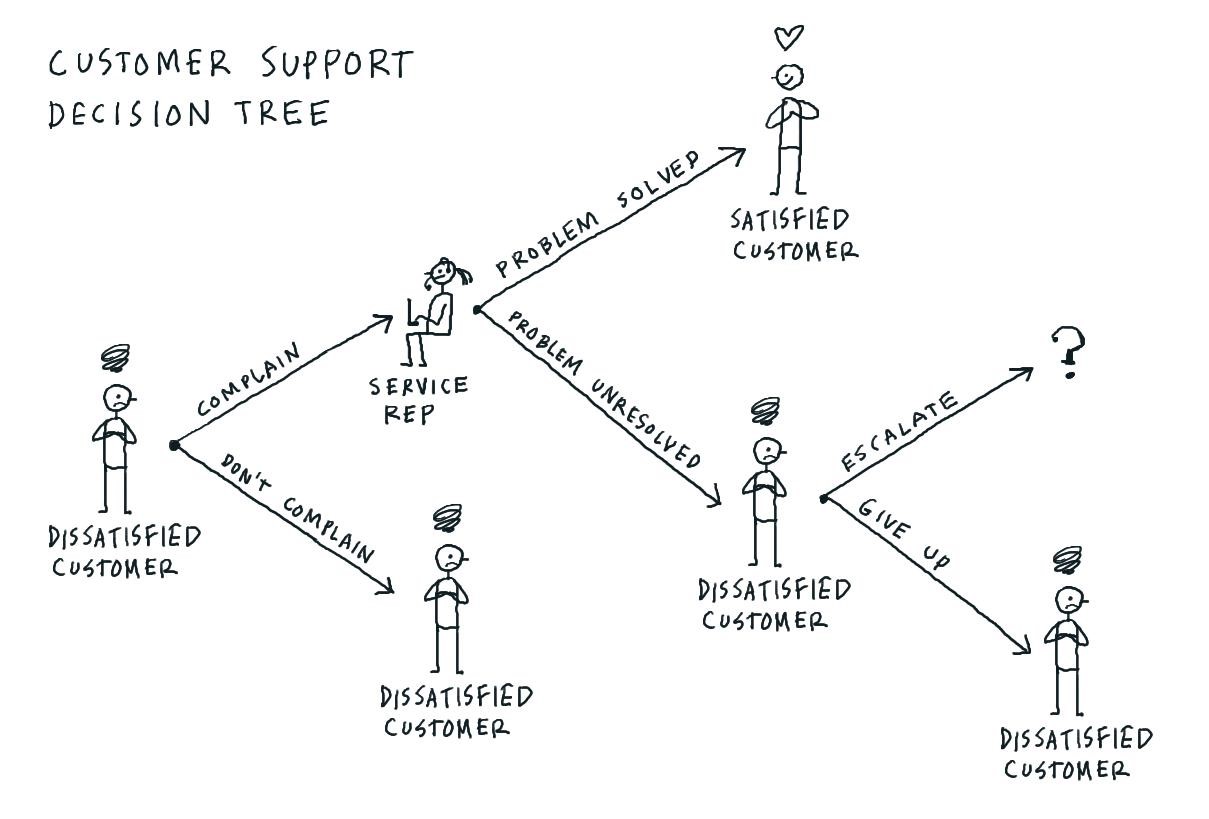
Source: Flickr
While the decision tree is not necessarily the model with the highest predictive accuracy; it is, however, a good model which can be easily interpreted and acted upon. For example, This would be useful in applications in which it is important to very accurately predict whether a customer will churn, but not so much why he or she would churn. Based on the predictions and insights obtained from this tree, well-targeted customer retention actions can be set up.
This blog is the first in a series and I hope it expands awareness of digital marketers on what can be achieved with data science. In next blog, I will develop a step-to-step guide for customer segmentation. If anyone has comments, feedback, or questions, please feel free to post Comments on the blog.
Here are some useful resources where you can learn more about the concepts I mentioned in the blog: