MACHINE LEARNING FOR MARKETERS
A Comprehensive Guide to Machine Learning

A Comprehensive Guide to Machine Learning

By 2020, the digital universe will be 40,000 exabytes, or 40tn gigabytes, in comprehensive size. In contrast, the human brain can hold only 1 million gigabytes of memory. Too much data exists for humans to parse, analyze, and understand. Here is where Machine Learning is finding its value: The raw amount and constant growth of data creates a need for methods to make sense of that data overload in ways that can impact an array of professions and lifestyles.
Although it has many uses, Machine Learning usually gets deployed to solve problems by finding patterns in data we can’t see ourselves. Computers give us the power to unearth concepts that are either too complex for humans or would take us longer to than we’d like to practically use them as a solution. The first step in Machine Learning is identifying the rules. The automation, or machine part, comes secondary. Rules are essentially the logic upon which we build the automation.
The first step in rule creation is finding the basic breakdown of the data you want to learn about. Think of this area as the labels you give your data in an Excel sheet or database.
Google called these labels “Parameters: the signals or factors used by the model to form its decisions” during a Machine Learning 101 event it held in 2015. A good example here would be working with stock prices to see how different variables can affect the market. In our case, the Parameters would be the stock price, the dates, and the company.
Next, identify the positive and negative results your automation looks to unearth. Essentially, think of this idea in terms of programmatic words such as “True” and “False.” You need to essentially “teach” your program how you, and it, should evaluate your data. Google calls this teaching the “Model: the system that makes predictions or identifications.”
Based on our example we used for the “Parameters,” let’s look at how a basic setup of the “model” would look.
For marketers, we can find a clear use case we can talk about for this basic description of Machine Learning: Google. What would our life be like without it?
Even in its early form, Google took indexed web pages and unstructured data points around them and arranged them based on logic created using the original PageRank. All of this arrangement happened because of tools used to create a result: a search engine results page (SERP).
Marketers have been dealing with Machine Learning in one form or another for some time now. Facebook feeds, Twitter trends, and algorithmic ad-buying platforms all use a form of Machine Learning to make decisions easier.
One of the largest fallacies with Machine Learning is that it’ll replace the need for humans. But didn’t we just show you above how humans work among several levels of the process? This idea goes beyond basic data scientists and engineers, extending to people who can shape the problems that Machine Learning will solve, extract the results from the learning process, and apply those results in a meaningful way. As we’ve seen with Google quality raters, humans must also qualify the results and help refine the logic used for learning.
Machine Learning is actually a method for human capital enrichment. It can super-charge the results achieved by marketers and expand the scope of what we even consider positive results and returns.
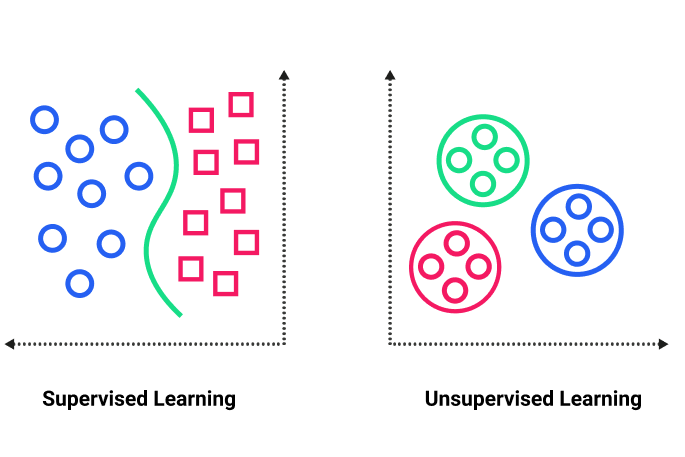
We can further break apart Machine Learning into two parts: supervised and unsupervised learning.
Are you still with us so far? Good, because now we’re getting to some cool stuff.
Artificial Intelligence, Deep Learning, and Natural Language Processing: They’re shock-and-awe words, but what do they mean? Well, they’re related concepts that have perhaps larger implications on human capital replacement and interaction.
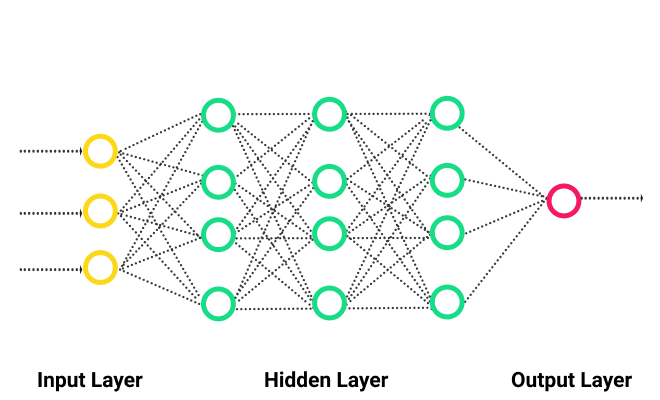
However, deeper concepts guide AI development today than merely parroting of human language via computers. AI research looks to develop technology that takes action based on learned patterns. You can break down AI into the smaller segments of deep learning — sometimes called neural networks — and natural language processing.
Google DeepMind’s AlphaGo program — it made headlines when it beat the world’s top-ranked players at the ancient board game Go — is an example of deep learning in action. The complexities of the game Go means that a computer can’t simply brute force patterns as you can with a game like chess. The computer must learn from patterns and use intuition to make choices. This level of operation isn’t something basic Machine Learning around a base data set can do; however, deep learning allows for the layered neurons to rework the data in unlimited ways by looking at every possible solution.
Deep learning is mostly unsupervised and aims to avoid the need for human intervention. At its core, it looks to learn by watching. When you think about the AlphaGo use case, it all starts to make sense.

In its current and expanding variation, Machine Learning is something that is often seen as a confusing topic. However, as we’ve just described, it breaks neatly into some basic concepts.
We’ll take a deeper look into several of these topics as we move into decoding the industry jargon associated with Machine Learning and its variants.
![]()
![]()
By 2020, the digital universe will be 40,000 exabytes, or 40tn gigabytes, in comprehensive size. In contrast, the human brain can hold only 1 million gigabytes of memory. Too much data exists for humans to parse, analyze, and understand. Here is where Machine Learning is finding its value: The raw amount and constant growth of data creates a need for methods to make sense of that data overload in ways that can impact an array of professions and lifestyles.
Although it has many uses, Machine Learning usually gets deployed to solve problems by finding patterns in data we can’t see ourselves. Computers give us the power to unearth concepts that are either too complex for humans or would take us longer to than we’d like to practically use them as a solution. The first step in Machine Learning is identifying the rules. The automation, or machine part, comes secondary. Rules are essentially the logic upon which we build the automation.
The first step in rule creation is finding the basic breakdown of the data you want to learn about. Think of this area as the labels you give your data in an Excel sheet or database.
Google called these labels “Parameters: the signals or factors used by the model to form its decisions” during a Machine Learning 101 event it held in 2015. A good example here would be working with stock prices to see how different variables can affect the market. In our case, the Parameters would be the stock price, the dates, and the company.
Next, identify the positive and negative results your automation looks to unearth. Essentially, think of this idea in terms of programmatic words such as “True” and “False.” You need to essentially “teach” your program how you, and it, should evaluate your data. Google calls this teaching the “Model: the system that makes predictions or identifications.”
Based on our example we used for the “Parameters,” let’s look at how a basic setup of the “model” would look.
For marketers, we can find a clear use case we can talk about for this basic description of Machine Learning: Google. What would our life be like without it?
Even in its early form, Google took indexed web pages and unstructured data points around them and arranged them based on logic created using the original PageRank. All of this arrangement happened because of tools used to create a result: a search engine results page (SERP).
Marketers have been dealing with Machine Learning in one form or another for some time now. Facebook feeds, Twitter trends, and algorithmic ad-buying platforms all use a form of Machine Learning to make decisions easier.
One of the largest fallacies with Machine Learning is that it’ll replace the need for humans. But didn’t we just show you above how humans work among several levels of the process? This idea goes beyond basic data scientists and engineers, extending to people who can shape the problems that Machine Learning will solve, extract the results from the learning process, and apply those results in a meaningful way. As we’ve seen with Google quality raters, humans must also qualify the results and help refine the logic used for learning.
Machine Learning is actually a method for human capital enrichment. It can super-charge the results achieved by marketers and expand the scope of what we even consider positive results and returns.
We can further break apart Machine Learning into two parts: supervised and unsupervised learning.
Are you still with us so far? Good, because now we’re getting to some cool stuff.
Artificial Intelligence, Deep Learning, and Natural Language Processing: They’re shock-and-awe words, but what do they mean? Well, they’re related concepts that have perhaps larger implications on human capital replacement and interaction.
However, deeper concepts guide AI development today than merely parroting of human language via computers. AI research looks to develop technology that takes action based on learned patterns. You can break down AI into the smaller segments of deep learning — sometimes called neural networks — and natural language processing.
Google DeepMind’s AlphaGo program — it made headlines when it beat the world’s top-ranked players at the ancient board game Go — is an example of deep learning in action. The complexities of the game Go means that a computer can’t simply brute force patterns as you can with a game like chess. The computer must learn from patterns and use intuition to make choices. This level of operation isn’t something basic Machine Learning around a base data set can do; however, deep learning allows for the layered neurons to rework the data in unlimited ways by looking at every possible solution.
Deep learning is mostly unsupervised and aims to avoid the need for human intervention. At its core, it looks to learn by watching. When you think about the AlphaGo use case, it all starts to make sense.
In its current and expanding variation, Machine Learning is something that is often seen as a confusing topic. However, as we’ve just described, it breaks neatly into some basic concepts.
We’ll take a deeper look into several of these topics as we move into decoding the industry jargon associated with Machine Learning and its variants.
![]()
![]()
