MACHINE LEARNING FOR MARKETERS
A Comprehensive Guide to Machine Learning

A Comprehensive Guide to Machine Learning


Marketers and businesses who want to use Machine Learning beyond the tools previously discussed may require better customization to deploy their specific online models. In addition, marketers as well as business organizations may be able to come up with ways on how their developers can fully use their models which, in this case, may call for other helpful tools.
Oryx is primarily designed to work on Apache Hadoop. For those who are not familiar with Hadoop, this open-source software platform is designed for storing data sets and executing applications over groups of commodity hardware. It can store a substantial amount of data of any kind, provides a high level of processing power, and is capable of handling a virtually limitless amount of tasks or jobs.
Oryx 2 is a product of Lambda Architecture built upon Apache Kafka and Apache Spark; however, Oryx 2 is designed with a specialty in real-time Machine Learning at a large scale. This framework allows for easy creation of applications, but also comes with packaged, end-to-end apps designed for collaborative filtering, regression, clustering, and classification.
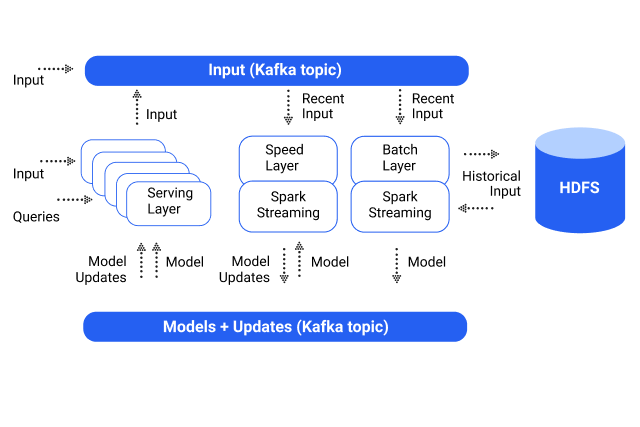
Oryx is composed of three tiers: Each tier builds over the one below:
1. The generic Lambda Architecture tier provides serving, batch, and speed layers that are not particular to ML.
2. Specialization over top provides ML simplifications for hyperparameter selecting and other selections.
3. The end-to-end execution of similar standard Machine Learning algorithms gives the application (k-means, random decision forests, or Alternating Least Squares Method for Collaborative Filtering) over the top.
Execute the three layers using:
You don’t have to use these layers over one machine; however, the application can also be possible if the configuration specifies various ports to accommodate the speed and batch layer Spark web user interface along with the port for serving layer API. You can run the serving layer over a number of machines.
Say the batch layer Spark user interface runs on the 4040 port of the machine where you started it — that is, unless this arrangement was altered by a configuration. As a default, the port 8080 will come with a web-based console designed for the serving layer.
A sample GroupLens 100K data set is found in a u.data file. The data set should be converted to CSV:

Provide the input over a serving layer, having a certain local command line tool such as a curl:

In case you are actually tailing the particular input topic, you will find substantial CSV data flow toward the topic:

After a few moments, you will find the batch layer triggering a new computation. This sample configuration will start per five-minute intervals.
The data provided is first delivered to HDFS. The sample configuration has it delivered to the directory hdfs:///user/example/Oryx/data/. Located inside are directories named by a timestamp with each one having a Hadoop part — files equipped with input being SequenceFiles of a text. Despite not being pure text, if you have to print them, you should be able to deliver recognizable data since it is actual text.

Afterward, a model computation will take place. This computation should show results in the form of a number of fresh distributed jobs over the batch layer. The Spark UI will be started over https://your-batch-layer:4040 as provided in the sample configuration.
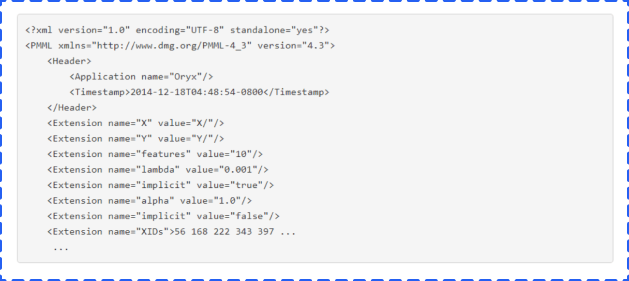
The model will then be complete and will be considered as a blend of PMML and various supporting data in the subdirectory of hdfs:///user/ example/Oryx/model/. Here’s an example: The model PMML files will be PMML files that contain elements such as the following:
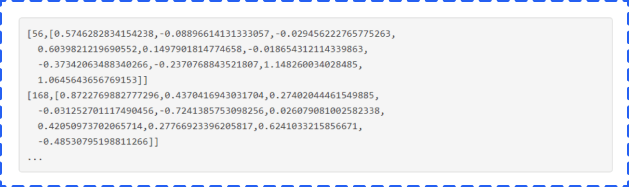
The Y/ and X/ subdirectories that go with it come with feature vectors such as:
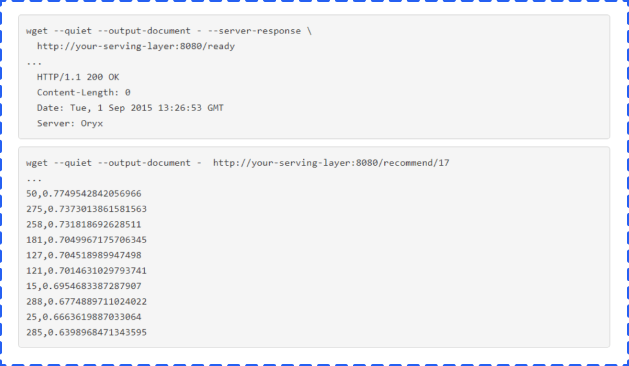
If you’re tailing the particular update topic, you will find these values to be published over the topic. This publication will then be detected by the serving layer later and will provide a return status at the /ready endpoint of 200 OK:
Three primary features of Apache Mahout include the following:
• A basic and extensible coding environment and framework designed for building scalable algorithms
• A wide array of premade algorithms for H2O, Apache Flink, and Scala + Apache Spark
• Samsara, the vector mathematics experimentation setting having R-like syntax that works at scale
Considering that Mahout’s primary algorithms are designed for classification, you can implement clustering as well as batch-based collaborative filtering over Apache Hadoop through the map/reduce paradigm. However, this process does not prevent any contributions over to Hadoop-based implementations. The contributions which operate over one node or over a non-Hadoop cluster become adapted or welcomed. As an example, the “taste” collaborative-filtering influencer part of Mahout was originally a single project and runs stand-alone without the aid of Hadoop.
An algebraic back end-independent optimizer — along with an algebraic Scala DSL to unify in-memory and distributed algebraic operators — makes up the setting. During this time, the available algebraic platforms supported include H2O, Apache Flink, and Apache Spark. MapReduce algorithms have gradually lost support from users.
H2O is an open-source, scalable ML and a predictive analytics system which provides convenience in building ML models over substantial data. H2O also offers effortless productionalization over models used in an enterprise.
This platform’s code is written in Java language. Within H2O, a certain DistributedKey/Value store gets used for approach as well as reference models, objects, data, and other elements over all the machines and nodes.
The algorithms are implemented over H2O’s dispersed Map/Reduce framework. After implementation, you make use of the Java Fork/Join framework to deliver multi-threading. The particular data gets read in parallel and gets distributed all over the cluster and stored inside a memory within compressed columnar format. Additionally, the H2O data parser comes with a built-in intelligence that guesses the schema of a certain incoming data set and offers data ingest support over a number of sources over various formats.
The REST API from H2O provides access to every capability of H2O out of both external programs and scripts out of JSON on HTTP. The H2O web interface, R binding, and Python binding uses REST API.
For developers as well as marketers who are presently in the .net working environment, Accord Framework stands out as a robust open-source alternative when deploying models.
Accord.NET Framework is actually a .NET ML framework combined with image and audio-processing libraries coded in C#. Accord.NET is a comprehensive framework used to create production-grade computer vision, signal processing, statistical applications, and computer audition.
MLlib is one popular ML library consisting of basic learning algorithms as well as utilities that include regression, clustering, collaborative filtering, dimensionality reduction, and classification.
This platform conveniently adapts to Spark’s APIs and works conveniently with NumPy from Python and R libraries. Hadoop data sourcing can also be used on this platform, a function which allows it to work effectively with Hadoop workflows as well.
Flask-RESTful is a lightweight extension to Flask to quickly build REST APIs. It encourages best practices with minimal setup. If you are a Python user, here is a guide to easily build your own REST APIs.
![]()
![]()
Marketers and businesses who want to use Machine Learning beyond the tools previously discussed may require better customization to deploy their specific online models. In addition, marketers as well as business organizations may be able to come up with ways on how their developers can fully use their models which, in this case, may call for other helpful tools.
Oryx is primarily designed to work on Apache Hadoop. For those who are not familiar with Hadoop, this open-source software platform is designed for storing data sets and executing applications over groups of commodity hardware. It can store a substantial amount of data of any kind, provides a high level of processing power, and is capable of handling a virtually limitless amount of tasks or jobs.
Oryx 2 is a product of Lambda Architecture built upon Apache Kafka and Apache Spark; however, Oryx 2 is designed with a specialty in real-time Machine Learning at a large scale. This framework allows for easy creation of applications, but also comes with packaged, end-to-end apps designed for collaborative filtering, regression, clustering, and classification.
Oryx is composed of three tiers: Each tier builds over the one below:
1. The generic Lambda Architecture tier provides serving, batch, and speed layers that are not particular to ML.
2. Specialization over top provides ML simplifications for hyperparameter selecting and other selections.
3. The end-to-end execution of similar standard Machine Learning algorithms gives the application (k-means, random decision forests, or Alternating Least Squares Method for Collaborative Filtering) over the top.
Execute the three layers using:
You don’t have to use these layers over one machine; however, the application can also be possible if the configuration specifies various ports to accommodate the speed and batch layer Spark web user interface along with the port for serving layer API. You can run the serving layer over a number of machines.
Say the batch layer Spark user interface runs on the 4040 port of the machine where you started it — that is, unless this arrangement was altered by a configuration. As a default, the port 8080 will come with a web-based console designed for the serving layer.
A sample GroupLens 100K data set is found in a u.data file. The data set should be converted to CSV:
Provide the input over a serving layer, having a certain local command line tool such as a curl:
In case you are actually tailing the particular input topic, you will find substantial CSV data flow toward the topic:
After a few moments, you will find the batch layer triggering a new computation. This sample configuration will start per five-minute intervals.
The data provided is first delivered to HDFS. The sample configuration has it delivered to the directory hdfs:///user/example/Oryx/data/. Located inside are directories named by a timestamp with each one having a Hadoop part — files equipped with input being SequenceFiles of a text. Despite not being pure text, if you have to print them, you should be able to deliver recognizable data since it is actual text.
Afterward, a model computation will take place. This computation should show results in the form of a number of fresh distributed jobs over the batch layer. The Spark UI will be started over https://your-batch-layer:4040 as provided in the sample configuration.
The model will then be complete and will be considered as a blend of PMML and various supporting data in the subdirectory of hdfs:///user/ example/Oryx/model/. Here’s an example: The model PMML files will be PMML files that contain elements such as the following:
The Y/ and X/ subdirectories that go with it come with feature vectors such as:
If you’re tailing the particular update topic, you will find these values to be published over the topic. This publication will then be detected by the serving layer later and will provide a return status at the /ready endpoint of 200 OK:
Three primary features of Apache Mahout include the following:
• A basic and extensible coding environment and framework designed for building scalable algorithms
• A wide array of premade algorithms for H2O, Apache Flink, and Scala + Apache Spark
• Samsara, the vector mathematics experimentation setting having R-like syntax that works at scale
Considering that Mahout’s primary algorithms are designed for classification, you can implement clustering as well as batch-based collaborative filtering over Apache Hadoop through the map/reduce paradigm. However, this process does not prevent any contributions over to Hadoop-based implementations. The contributions which operate over one node or over a non-Hadoop cluster become adapted or welcomed. As an example, the “taste” collaborative-filtering influencer part of Mahout was originally a single project and runs stand-alone without the aid of Hadoop.
An algebraic back end-independent optimizer — along with an algebraic Scala DSL to unify in-memory and distributed algebraic operators — makes up the setting. During this time, the available algebraic platforms supported include H2O, Apache Flink, and Apache Spark. MapReduce algorithms have gradually lost support from users.
H2O is an open-source, scalable ML and a predictive analytics system which provides convenience in building ML models over substantial data. H2O also offers effortless productionalization over models used in an enterprise.
This platform’s code is written in Java language. Within H2O, a certain DistributedKey/Value store gets used for approach as well as reference models, objects, data, and other elements over all the machines and nodes.
The algorithms are implemented over H2O’s dispersed Map/Reduce framework. After implementation, you make use of the Java Fork/Join framework to deliver multi-threading. The particular data gets read in parallel and gets distributed all over the cluster and stored inside a memory within compressed columnar format. Additionally, the H2O data parser comes with a built-in intelligence that guesses the schema of a certain incoming data set and offers data ingest support over a number of sources over various formats.
The REST API from H2O provides access to every capability of H2O out of both external programs and scripts out of JSON on HTTP. The H2O web interface, R binding, and Python binding uses REST API.
For developers as well as marketers who are presently in the .net working environment, Accord Framework stands out as a robust open-source alternative when deploying models.
Accord.NET Framework is actually a .NET ML framework combined with image and audio-processing libraries coded in C#. Accord.NET is a comprehensive framework used to create production-grade computer vision, signal processing, statistical applications, and computer audition.
MLlib is one popular ML library consisting of basic learning algorithms as well as utilities that include regression, clustering, collaborative filtering, dimensionality reduction, and classification.
This platform conveniently adapts to Spark’s APIs and works conveniently with NumPy from Python and R libraries. Hadoop data sourcing can also be used on this platform, a function which allows it to work effectively with Hadoop workflows as well.
Flask-RESTful is a lightweight extension to Flask to quickly build REST APIs. It encourages best practices with minimal setup. If you are a Python user, here is a guide to easily build your own REST APIs.
![]()
![]()
