MACHINE LEARNING FOR MARKETERS
A Comprehensive Guide to Machine Learning

A Comprehensive Guide to Machine Learning

Now that we’ve taken the time to outline exactly how you can use and build chatbots, let’s take a look at specific third-party options that let you get started with machine learning regardless of your technical prowess.
Google Colaboratory (Google Colab for short) is a free, browser-based notebook that allows you to write and execute Python. If you are familiar with other Google applications, like Google Doc and Google Sheet, you will have no problem with Google Colab.
The reasons for using Google Colab are:
• Zero configuration required
• Free access to GPUs and TPUs
• Easy sharing
Open your Google Drive, and then click the upper left button to open the dropdown menu.
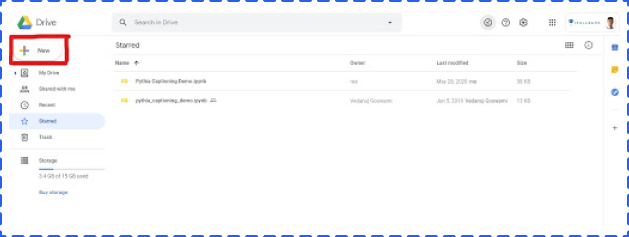
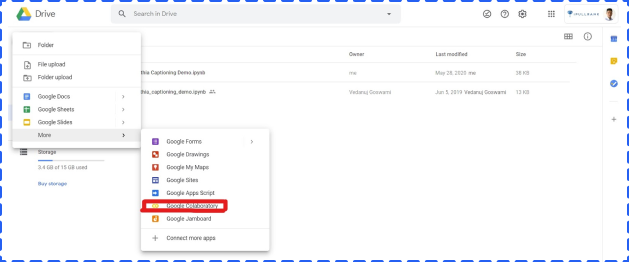
Choose More, and then click Google Colaboratory in the sub dropdown menu to create a new Google Colab notebook.
After opening a new Colab notebook, you are pretty much done. WithColab, you don’t need to install Python or any programming notebooks, like Jupyter Notebook. Another advantage is that most commonly used libraries, like Pandas and Matplotlib, are already installed.so you can us it directly instead of dealing with installation.
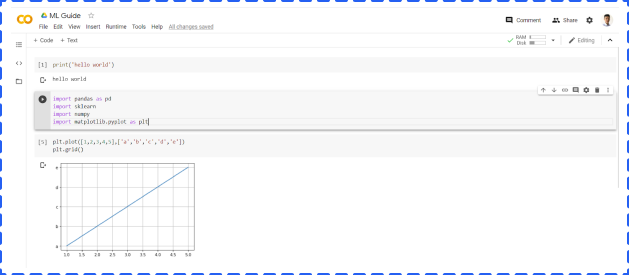
In addition, Google Colab provides free GPU access (1 K80 core) to everyone, but TPU requires an additional charge. When you deal with a huge project, GPU and TPU can significantly reduce the running time.
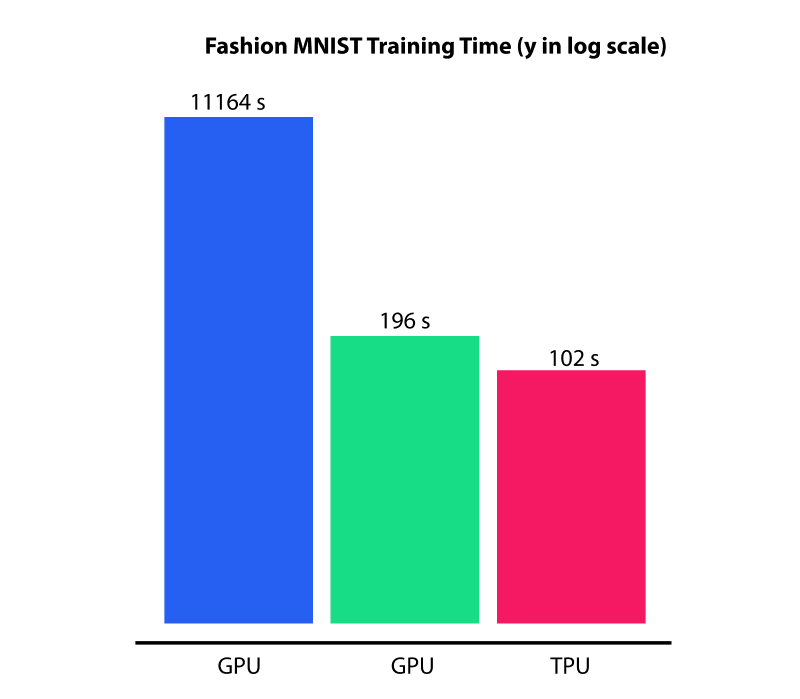
To use GPU, clicking Runtime -> Change runtime type -> Choose GPU -> Save.
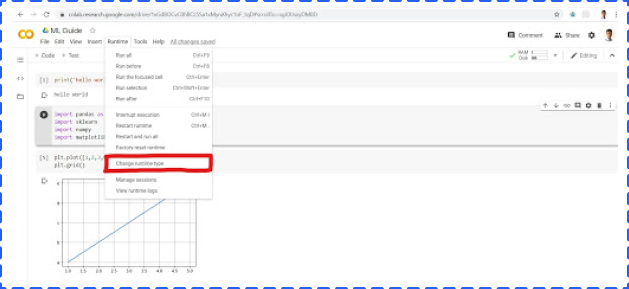
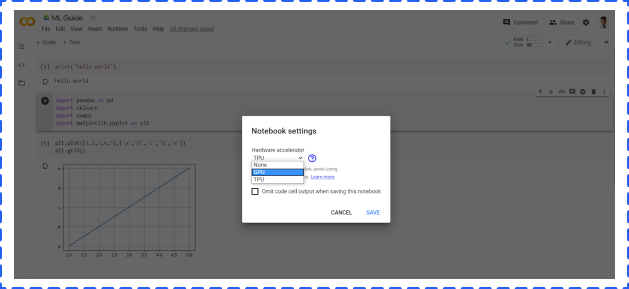
Jupyter Notebook is an open-source web application that allows you to write Python code for data cleaning and transformation, numerical simulation, statistical modeling, data visualization, Machine Learning, and much more.
For new users, it is general and easy to use Anaconda to install both Python and the Jupyter notebook. Anaconda includes not only Python and Jupyter notebook but also a lot of packages commonly used in data science and Machine Learning.
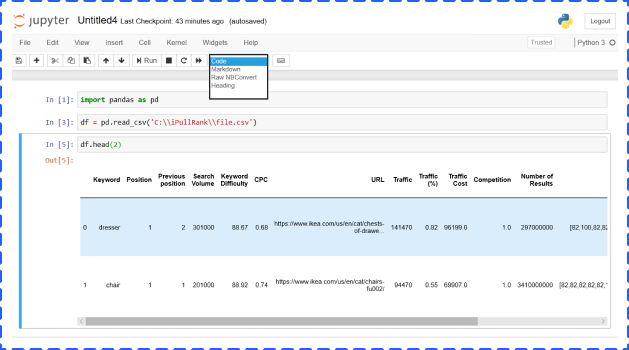
Once the Anaconda is opened, you will see different applications including Jupyter Notebook. But in this article, we are going to focus on the Jupyter Notebook. You will get the below screen:
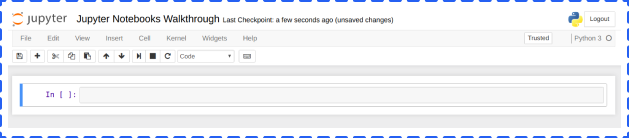
You can import libraries, like pandas and numpy, reading files in different formats (csv, json etc.), building Machine Learning models, and generating various charts in the cell.
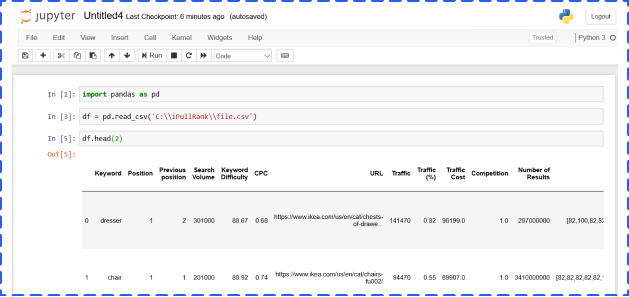
The cell has four options, and you could choose from the dropdown menu:
• Code – It is where you type and run code
• Markdown – It is where you could type and show text. In general, people use it to add conclusions, comments, etc.
• Raw NBConvert – It is a command line tool to convert your notebook into another format (like HTML)
• Heading – This is where you add Headings to separate sections and make your notebook organized. You can add a “#” in Markdown cell to create headings as well
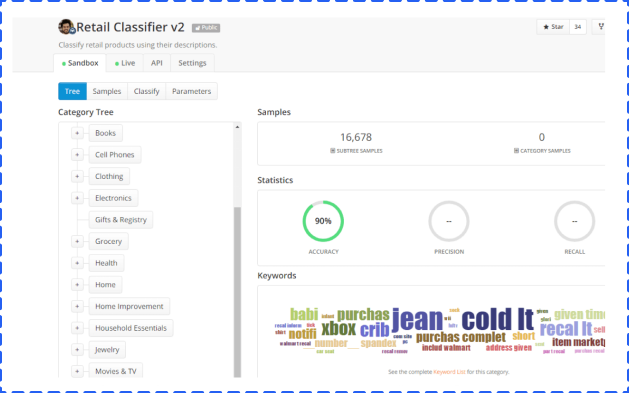
MonkeyLearn, a Machine Learning API that uses machines to understand human language, offers a solution to create and test Machine Learning algorithms to solve problems such as sentiment analysis and topic detection. You’ll find pre-created modules in the application, but you can also create your own customized modules.
The modules represent three components: classification, extraction, and pipelines.
These modules take text and return labels organized in a hierarchy. Let’s take a look at its pre-built retail classifier.
The algorithm for classification was taught over time by having “samples” added to the system. To see the classification in action, you can classify “Text” or a “File.” We entered a description of a fishing rod and reel combo to test the functionality.
Results come back in a JSON format, but they’re still readable by people with a base level of development understanding.
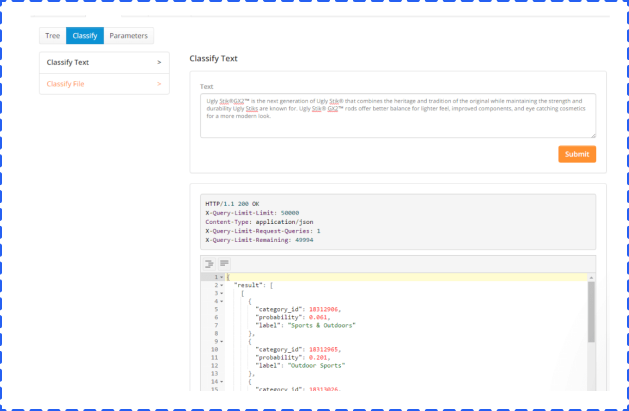
Results come back in a JSON format, but they’re still readable by people with a base level of development understanding.

As you can see, Fishing Rod & Reel Combos was the category with the highest probability.
You can’t create a customized text extractor today, but you can train prebuilt modules. The extractors allow you to extract keywords, useful data, and entities. We’ll look below at the useful data extractor.
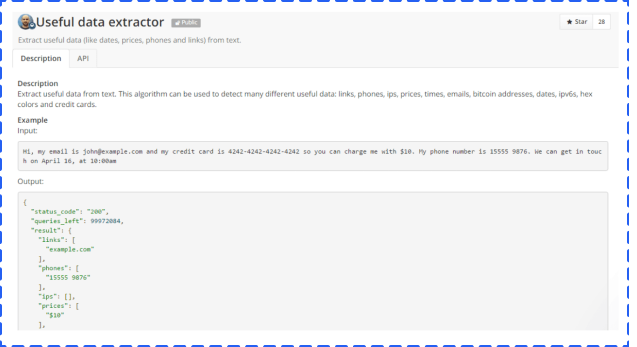
This tool allows people to easily extract valuable information from a block of text and store it. This type of functionality could be used to help customer service representatives manage potential issues that arise through email or social media. Post-sentiment analysis for this module could grab the information needed and store it on a customer data level.
The pipeline modules allow you to combine other modules into one workflow. For example, given a text, you can create a pipeline that performs the following functions:
• First, it does language detection.
• Second, if the language is English, then it does sentiment analysis in English.
• Third, if the sentiment is negative, it extracts valuable data.
With pipelines, you can declare the different processing steps made to the text and create logic to combine the partial results.
The advantage of using a pipeline is that you can do multiple process with only one HTTP request.
This option is more technical in that you need to use JSON to tie together other modules you’ve already built into a workflow process. Alternatively, you can turn to a useful tool called Zapier, a way to make various apps connect with one another. When you allow these apps to connect, you can save yourself valuable time by automating repetitive, tedious tasks. For example, with Zapier, you can unite a Trigger (“a new email”) with a specific action (“create a contact”) to execute an action in one app when something occurs in another app.
Currently, there is a Text Analysis by MonkeyLearn Plugin for Google Sheets to help you finish various text related tasks easily, like sentiment analysis and email extraction. Below are three simple steps to install and run the analysis.
Open a Google Sheet -> click Add-ones -> get add-ones -> search Text Analysis by MonkeyLearn -> install
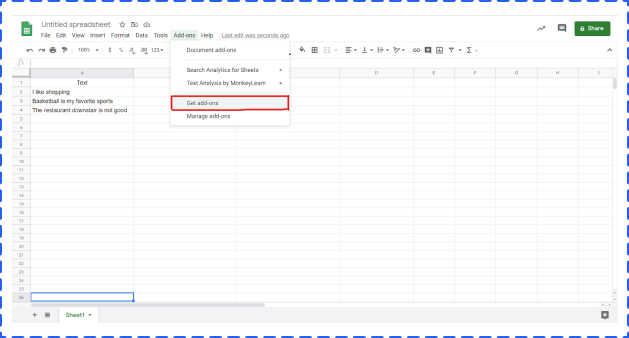
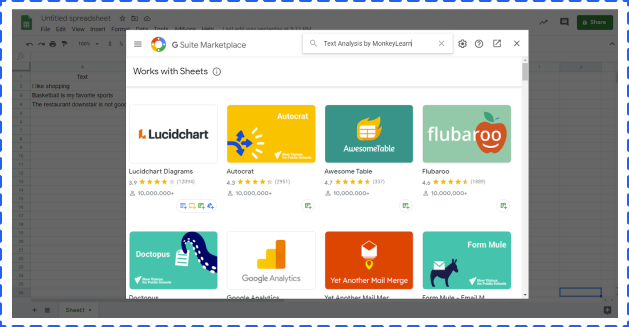
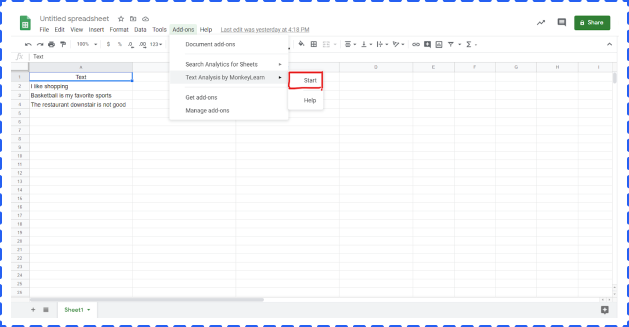
Click Add-ones -> choose Text Analysis by MonkeyLearn -> click start. But at this point, you can not really start. The next step is to create a MonkeyLearn account and set an API.
Click Change key -> paste your API Key -> click Set
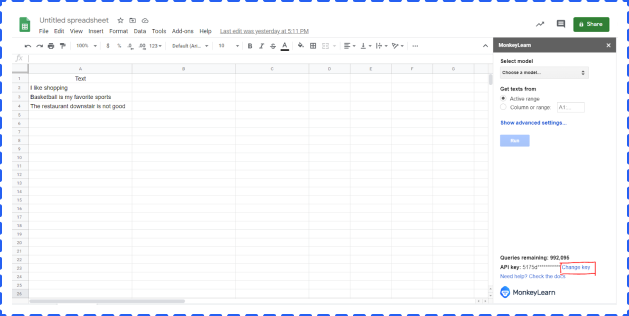
Select cell range -> choose a model from the dropdown list -> click Run. The result will show in the right column by default.
Amazon launched its Machine Learning as a service product in 2015, and while the product isn’t as intuitive to use as some other third-party applications, it’s a fantastic supervised learning option for predictions. This system uses a logistic regression model, mapping variables between 1 and 0. Additionally, Amazon can also handle multiclass classifications. Multiclass classification models can do the following:
• Automate the effort of predicting object classification based on one of more than two classes
• Create a scalable way to account for classes and objects that are continually evolving
You’re going to work with data stored in an Amazon S3 location, so you need to become familiar with uploading data through the Amazon Management Console. You’ll get an S3 URL once you’ve uploaded your data; however, you should be aware that the S3 Browser is slightly more intuitive than the Amazon Management Console.
The data set can hold as many attributes as you want. An attribute in this model works as a classifier. Regardless of which attributes you include in your dataset, you must include the attribute y. This is the training data for your model and will later be the attribute you’re looking to predict.
Since we’re using a logistic regression model, we want to choose questions where the answers have only two choices (yes and no or true and false). For your training data, you can represent these two choices with 1s and 0s. For multiclass classifications, you’ll use as many identifiers as you need to represent as many classes as you have set up for classifying your data.
Go into your Machine Learning console and choose the standard setup under “Get started …”
On the next page, you’ll need to enter the data set location that you entered in the previous step. Next, you go through a number of steps where you verify the data, allow Amazon Machine Learning to infer the schema, and select the y as the target attribute for predictions.
The default model for the ML model is the option that Amazon creates based on its understanding of your schema and your predictive attribute. However, you can customize the recipe yourself. If you’re getting started with Machine Learning, it would be best to experiment with the default models and get an understanding of the system first before you venture into recipe creation.
Once you’ve created the model, Amazon will tell you if your data and recipe combined are good enough to use. Amazon computes an Area Under a Curve (AUC) Metric that expresses the quality performance of your Machine Learning model. The closer the AUC for a Machine Learning model comes to 1, the better the quality of the performance.
Amazon lets you know in real-world language whether the data is good or bad.
You can now use the score threshold to fine-tune your ML model performance. You can use this score to target the most true or false items predicted based on likelihood.
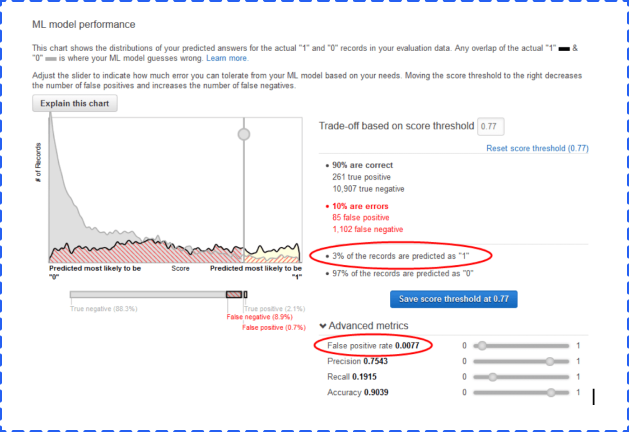
Now you’re ready to generate predictions.
You can generate a real-time prediction to test the model. Here, you simply enter the attributes for one record and see what the prediction for the record returns.
You’re also able to do batch predictions. For this process, you’ll need to upload the data you intend to analyze to S3 and choose Batch Predictions in the Machine Learning menu. You’ll then be asked to enter the S3 URL, verify the data, and name your batch prediction. The process will then run for you.
To view your data, go back to Batch Predictions in the Amazon Machine Learning menu.

A list of predictions will appear, and you choose the batch prediction you ran.
You want to note the Output S3 URL. Go to the Amazon S3 console, navigate to that referenced URL’s location, and find the results folder. The results are in a compressed .gzip file. You can download the file, open it, and analyze the results.
The data has two columns. One is for best answer, which delivers a true or false 0 or 1 based on the score threshold you set. The other column has the raw score of the record.
The application for this type of service is fairly open, and that flexibility is what makes this option such an interesting one for marketers.
One option is to glean more from your marketing campaigns. You can take the data from your analytics and create attributes for users that entered through your campaigns as they worked their way through the funnel. As you launch new campaigns, you can measure success in early days by running a model that compares your data to the performance of previous campaigns. You could also set up these models for different levels of your funnel to tell your salespeople about records that they need to focus on at each level. This arrangement is referred to as lead scoring. When applied to machine learning, you essentially “train” a machine to recognize individuals in a marketing database that have the potential to become future customers. The machine assigns predictive lead scores to identify the likelihood that each individual account will convert to a sale or a customer.
Google Cloud AI & Machine Learning Products is a comprehensive and trusted platform of innovative machine learning products and services, consisting of AI Hub, AI building blocks, and AI Platform. For those people who plan to develop and run a machine learning project, Google Cloud AI Platform is a good option.
AI Platform is a code-based data science development environment that empowers machine learning developers and data scientists to quickly take their projects from ideation to deployment. One of the biggest advantages to using AI Platform is that it covers each step in the machine learning development cycle.
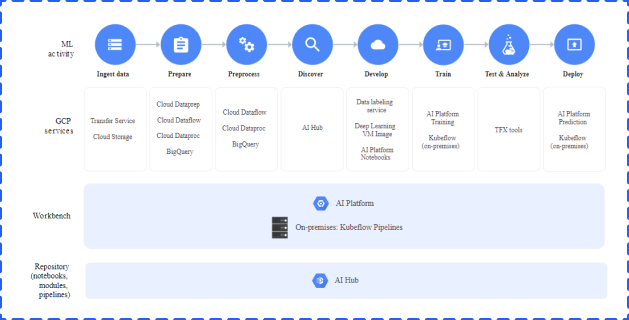
Source: https://cloud.google.com/ai-platform
During the preparation stage, you can use BigQuey and Google Cloud Storage to store your data.
You can use AI Platform Notebooks to build your machine learning applications. You can also use AI Platform Training and Prediction services to train your models and deploy them.
Google Cloud Platform Console and Kubeflow Pipelines can help you manage your models, experiments, and end-to-end workflows. In addition, you can use Kubeflow Pipelines to build reusable end-to-end ML pipelines.
Google Cloud Prediction API provides a RESTful API to build machine learning models. You can build spam detection, sentiment analysis, and recommendation systems based on the models.
This system is similar to Amazon’s Machine Learning option, except it involves a much more advanced knowledge of basic coding skill to get up and running. However, you’ll find an option for those of us that have less refined experience creating machine learning recipes from syntax.
Google Cloud Prediction API has a Google Sheets option called Smart Autofill.
Just like our other processes, the first step starts with data. You pull in the data based on important attributes for your campaign. Unlike the process we did with Amazon, you actually want to combine your training data and data you want to predict in the same sheet.
From the data you enter, you choose the columns that have data you want to use in predicting your results, as well as the column you plan to fill with predictions.
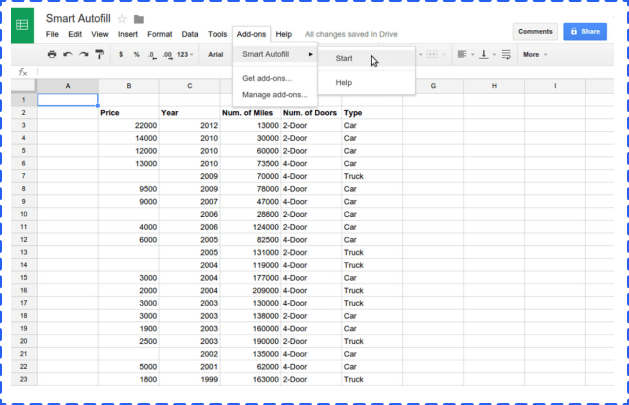
Next, you select the column that has the data you want to predict.
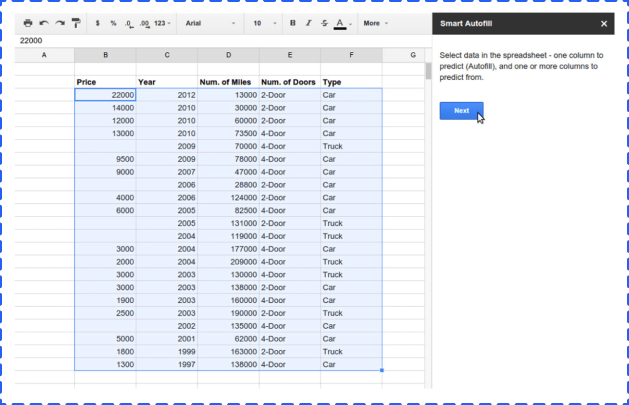
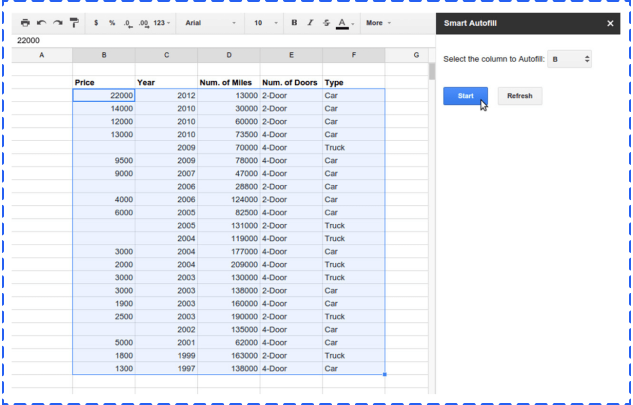
When you’re done, you can view the estimated error and accuracy of your data. You can work with values that are not simply true or false statements, and the add-on function will report the possible amount of error.
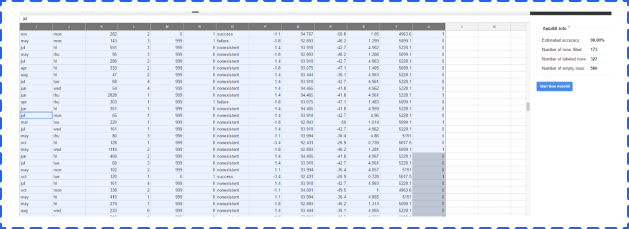
We ran the Auto Smartfill add-on on the data from the Amazon Machine Learning test. The test worked, but we noticed a couple of items.
• As with traditional Google Sheets operations, the add-on has a hard time dealing with data at a very large scale. We had to parse down the record count to get it to work.
• It takes some time to get the results you need.
However, the results you get are very good.
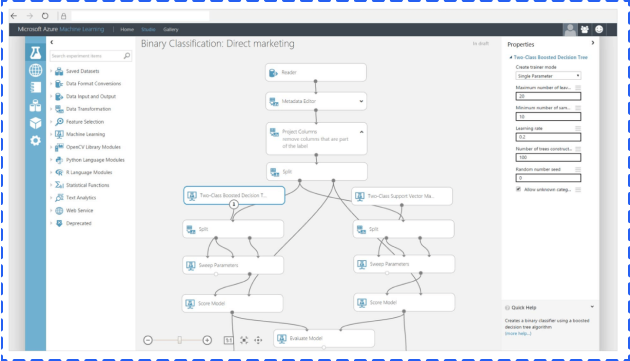
Microsoft has launched ML Studio as a part of its Azure tool set.
ML Studio is interesting because you can work in a drag-and-drop interface to build your workflows.
While this arrangement makes the setup look extremely user-friendly, the robust nature of ML Studio is not something anyone can dive into. Each of the interconnected units in ML Studio is a layer of the machine learning process. This layering includes data, algorithms, scoring models, and more. Each of those components is capable of being managed through R or Python.
As you dig in, you realize that Microsoft Azure ML Studio is a powerful tool created with data scientists in mind. This feature makes it a good option if you’re growing a data science team, but it’s less friendly for a new user to the system.
One interesting note is that you’ll discover pre-built solutions available in the Azure marketplace that might make this option more palatable for those with technical experience.
While the above options allow for an entire world of flexibility and creativity for your machine learning needs, some of us only need tools that work today for very specific issues. Luckily, machine learning-based software solutions are on the rise in the adtech space, and solutions exist for you to sign up today and put machine learning to work for you.
BigML is a consumable, programmable, and scalable Machine Learning platform provides a selection of Machine Learning algorithms to solve various tasks, like Classification, Regression, and Time Series Analysis, by applying a single, standardized framework. The mission of BigML is to make Machine Learning easy, beautiful and understandable for everybody.
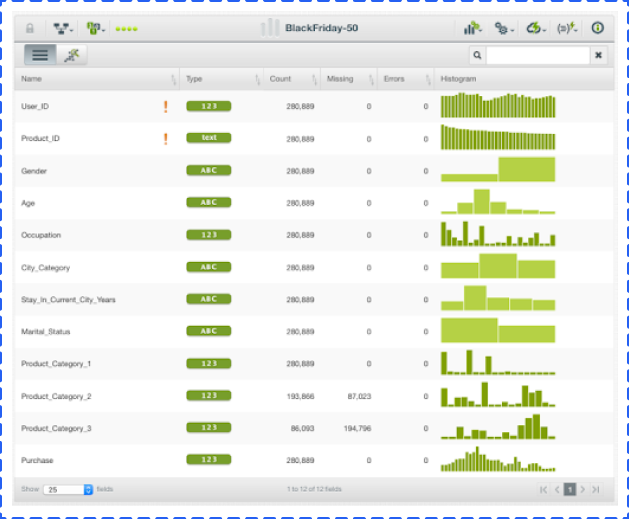
Below is a list of useful features:
1. Allowing you to load data from plenty of places, including Cloud storage platforms, direct URLs, and local CSV files.
2. Helping you detect outliers and pattern anomalies to save time and money, even before hitting your model.
3. A large number of free datasets and models for you to play with.
Atomic Reach is an out-of-the-box solution that helps marketers know what to do with their content to get the most value out of their content marketing. This tool helps you create the content, share it, engage with data in real time to make on-the-spot changes to strategy, and see trending topics that you can use to create timely content.
The creation module measures 22 attributes of the content you’re creating in real time. These attributes include readability level, length, emotions and more. The Atomic Reach Writer lets you train your Machine Learning by assigning different attribute levels as an “audience.” You generate content for that audience, and the system lets you know where you score.
Rarelogic has created an email marketing optimization solution that works with Shopify and BigCommerce. The company’s main offering is predictive email recommendations. You can create and use preset Mailouts based on visitor segmentations:
Before we close the door on the topic of tools and ways that marketers can get working with machine learning today, we wanted to touch on some open-source platforms that exist and are worth investigating.
Keras is an open-source neural network library written in Python. It’s capable of running on top of three open-source machine learning software libraries, DeepLearning4j, TensorFlow, and Theano. The library has many implementations of commonly used neural network building blocks including layers, objectives, and optimizers.
KNIME is a software to create and productionize data science by simple drag and drop process.
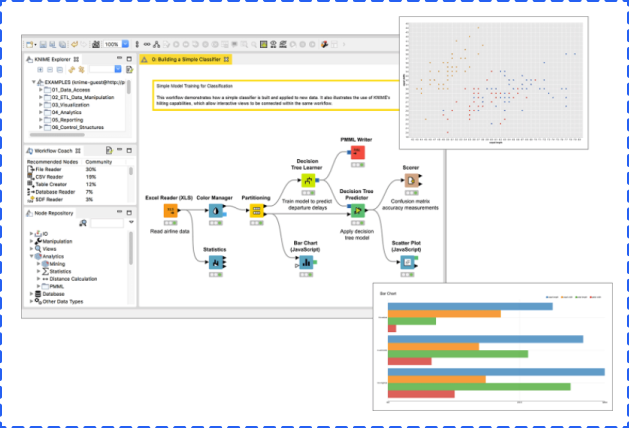
KNIME Analytics Platform is a free, open-source platform for data-driven innovation which is good for individual use. It allows you to load data from any source, like Microsoft SQL and Salesforce, process data, leverage plenty of Machine Learning and AI models, share insights, and even build data science workflows.
KNIME Server is for enterprise. Besides features that KNIME Analytics Platform contains, it also allows you to share best practices across teams and the company, automatically schedule workflows, scale workflow execution, deploy analytical applications, manage and monitor operations, and more.
KNIME (Konstanz Information Miner) is an open-source data analytics, reporting, and integration platform that has components of machine learning included in its modular data pipelining. KNIME integrates with various open-source projects to help with machine learning functionality, such as Weka and R Project.
![]()
![]()
Now that we’ve taken the time to outline exactly how you can use and build chatbots, let’s take a look at specific third-party options that let you get started with machine learning regardless of your technical prowess.
Google Colaboratory (Google Colab for short) is a free, browser-based notebook that allows you to write and execute Python. If you are familiar with other Google applications, like Google Doc and Google Sheet, you will have no problem with Google Colab.
The reasons for using Google Colab are:
• Zero configuration required
• Free access to GPUs and TPUs
• Easy sharing
Open your Google Drive, and then click the upper left button to open the dropdown menu.
Choose More, and then click Google Colaboratory in the sub dropdown menu to create a new Google Colab notebook.
After opening a new Colab notebook, you are pretty much done. WithColab, you don’t need to install Python or any programming notebooks, like Jupyter Notebook. Another advantage is that most commonly used libraries, like Pandas and Matplotlib, are already installed.so you can us it directly instead of dealing with installation.
In addition, Google Colab provides free GPU access (1 K80 core) to everyone, but TPU requires an additional charge. When you deal with a huge project, GPU and TPU can significantly reduce the running time.
To use GPU, clicking Runtime -> Change runtime type -> Choose GPU -> Save.
Jupyter Notebook is an open-source web application that allows you to write Python code for data cleaning and transformation, numerical simulation, statistical modeling, data visualization, Machine Learning, and much more.
For new users, it is general and easy to use Anaconda to install both Python and the Jupyter notebook. Anaconda includes not only Python and Jupyter notebook but also a lot of packages commonly used in data science and Machine Learning.
Once the Anaconda is opened, you will see different applications including Jupyter Notebook. But in this article, we are going to focus on the Jupyter Notebook. You will get the below screen:
You can import libraries, like pandas and numpy, reading files in different formats (csv, json etc.), building Machine Learning models, and generating various charts in the cell.
The cell has four options, and you could choose from the dropdown menu:
• Code – It is where you type and run code
• Markdown – It is where you could type and show text. In general, people use it to add conclusions, comments, etc.
• Raw NBConvert – It is a command line tool to convert your notebook into another format (like HTML)
• Heading – This is where you add Headings to separate sections and make your notebook organized. You can add a “#” in Markdown cell to create headings as well
MonkeyLearn, a Machine Learning API that uses machines to understand human language, offers a solution to create and test Machine Learning algorithms to solve problems such as sentiment analysis and topic detection. You’ll find pre-created modules in the application, but you can also create your own customized modules.
The modules represent three components: classification, extraction, and pipelines.
These modules take text and return labels organized in a hierarchy. Let’s take a look at its pre-built retail classifier.
The algorithm for classification was taught over time by having “samples” added to the system. To see the classification in action, you can classify “Text” or a “File.” We entered a description of a fishing rod and reel combo to test the functionality.
Results come back in a JSON format, but they’re still readable by people with a base level of development understanding.
Results come back in a JSON format, but they’re still readable by people with a base level of development understanding.
As you can see, Fishing Rod & Reel Combos was the category with the highest probability.
You can’t create a customized text extractor today, but you can train prebuilt modules. The extractors allow you to extract keywords, useful data, and entities. We’ll look below at the useful data extractor.
This tool allows people to easily extract valuable information from a block of text and store it. This type of functionality could be used to help customer service representatives manage potential issues that arise through email or social media. Post-sentiment analysis for this module could grab the information needed and store it on a customer data level.
The pipeline modules allow you to combine other modules into one workflow. For example, given a text, you can create a pipeline that performs the following functions:
• First, it does language detection.
• Second, if the language is English, then it does sentiment analysis in English.
• Third, if the sentiment is negative, it extracts valuable data.
With pipelines, you can declare the different processing steps made to the text and create logic to combine the partial results.
The advantage of using a pipeline is that you can do multiple process with only one HTTP request.
This option is more technical in that you need to use JSON to tie together other modules you’ve already built into a workflow process. Alternatively, you can turn to a useful tool called Zapier, a way to make various apps connect with one another. When you allow these apps to connect, you can save yourself valuable time by automating repetitive, tedious tasks. For example, with Zapier, you can unite a Trigger (“a new email”) with a specific action (“create a contact”) to execute an action in one app when something occurs in another app.
Currently, there is a Text Analysis by MonkeyLearn Plugin for Google Sheets to help you finish various text related tasks easily, like sentiment analysis and email extraction. Below are three simple steps to install and run the analysis.
Open a Google Sheet -> click Add-ones -> get add-ones -> search Text Analysis by MonkeyLearn -> install
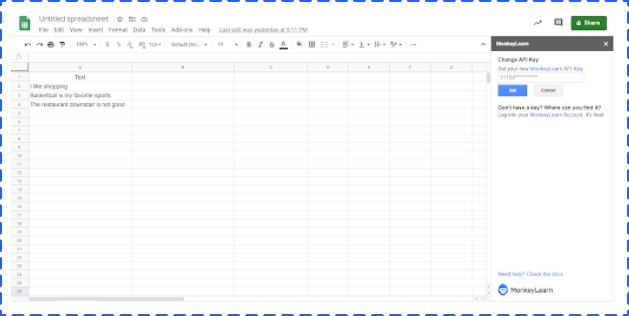
Click Add-ones -> choose Text Analysis by MonkeyLearn -> click start. But at this point, you can not really start. The next step is to create a MonkeyLearn account and set an API.
Click Change key -> paste your API Key -> click Set
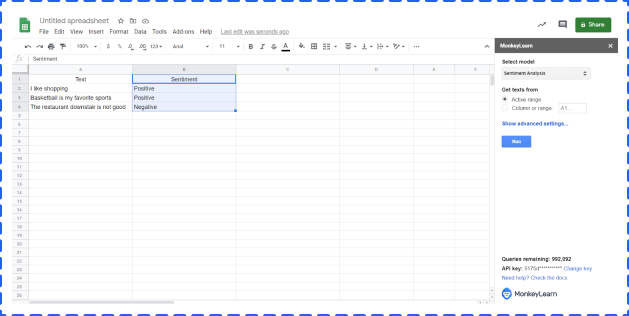
Select cell range -> choose a model from the dropdown list -> click Run. The result will show in the right column by default.
Amazon launched its Machine Learning as a service product in 2015, and while the product isn’t as intuitive to use as some other third-party applications, it’s a fantastic supervised learning option for predictions. This system uses a logistic regression model, mapping variables between 1 and 0. Additionally, Amazon can also handle multiclass classifications. Multiclass classification models can do the following:
• Automate the effort of predicting object classification based on one of more than two classes
• Create a scalable way to account for classes and objects that are continually evolving
You’re going to work with data stored in an Amazon S3 location, so you need to become familiar with uploading data through the Amazon Management Console. You’ll get an S3 URL once you’ve uploaded your data; however, you should be aware that the S3 Browser is slightly more intuitive than the Amazon Management Console.
The data set can hold as many attributes as you want. An attribute in this model works as a classifier. Regardless of which attributes you include in your dataset, you must include the attribute y. This is the training data for your model and will later be the attribute you’re looking to predict.
Since we’re using a logistic regression model, we want to choose questions where the answers have only two choices (yes and no or true and false). For your training data, you can represent these two choices with 1s and 0s. For multiclass classifications, you’ll use as many identifiers as you need to represent as many classes as you have set up for classifying your data.
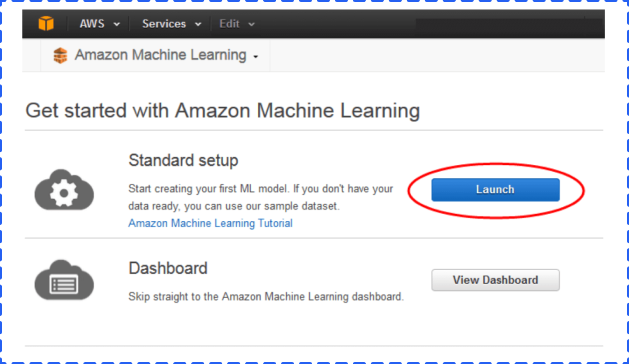
Go into your Machine Learning console and choose the standard setup under “Get started …”
On the next page, you’ll need to enter the data set location that you entered in the previous step. Next, you go through a number of steps where you verify the data, allow Amazon Machine Learning to infer the schema, and select the y as the target attribute for predictions.
The default model for the ML model is the option that Amazon creates based on its understanding of your schema and your predictive attribute. However, you can customize the recipe yourself. If you’re getting started with Machine Learning, it would be best to experiment with the default models and get an understanding of the system first before you venture into recipe creation.
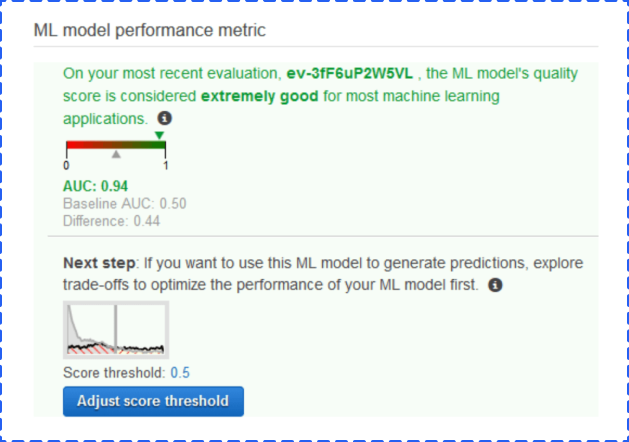
Once you’ve created the model, Amazon will tell you if your data and recipe combined are good enough to use. Amazon computes an Area Under a Curve (AUC) Metric that expresses the quality performance of your Machine Learning model. The closer the AUC for a Machine Learning model comes to 1, the better the quality of the performance.
Amazon lets you know in real-world language whether the data is good or bad.
You can now use the score threshold to fine-tune your ML model performance. You can use this score to target the most true or false items predicted based on likelihood.
Now you’re ready to generate predictions.
You can generate a real-time prediction to test the model. Here, you simply enter the attributes for one record and see what the prediction for the record returns.
You’re also able to do batch predictions. For this process, you’ll need to upload the data you intend to analyze to S3 and choose Batch Predictions in the Machine Learning menu. You’ll then be asked to enter the S3 URL, verify the data, and name your batch prediction. The process will then run for you.
To view your data, go back to Batch Predictions in the Amazon Machine Learning menu.
A list of predictions will appear, and you choose the batch prediction you ran.
You want to note the Output S3 URL. Go to the Amazon S3 console, navigate to that referenced URL’s location, and find the results folder. The results are in a compressed .gzip file. You can download the file, open it, and analyze the results.
The data has two columns. One is for best answer, which delivers a true or false 0 or 1 based on the score threshold you set. The other column has the raw score of the record.
The application for this type of service is fairly open, and that flexibility is what makes this option such an interesting one for marketers.
One option is to glean more from your marketing campaigns. You can take the data from your analytics and create attributes for users that entered through your campaigns as they worked their way through the funnel. As you launch new campaigns, you can measure success in early days by running a model that compares your data to the performance of previous campaigns. You could also set up these models for different levels of your funnel to tell your salespeople about records that they need to focus on at each level. This arrangement is referred to as lead scoring. When applied to machine learning, you essentially “train” a machine to recognize individuals in a marketing database that have the potential to become future customers. The machine assigns predictive lead scores to identify the likelihood that each individual account will convert to a sale or a customer.
Google Cloud AI & Machine Learning Products is a comprehensive and trusted platform of innovative machine learning products and services, consisting of AI Hub, AI building blocks, and AI Platform. For those people who plan to develop and run a machine learning project, Google Cloud AI Platform is a good option.
AI Platform is a code-based data science development environment that empowers machine learning developers and data scientists to quickly take their projects from ideation to deployment. One of the biggest advantages to using AI Platform is that it covers each step in the machine learning development cycle.
Source: https://cloud.google.com/ai-platform
During the preparation stage, you can use BigQuey and Google Cloud Storage to store your data.
You can use AI Platform Notebooks to build your machine learning applications. You can also use AI Platform Training and Prediction services to train your models and deploy them.
Google Cloud Platform Console and Kubeflow Pipelines can help you manage your models, experiments, and end-to-end workflows. In addition, you can use Kubeflow Pipelines to build reusable end-to-end ML pipelines.
Google Cloud Prediction API provides a RESTful API to build machine learning models. You can build spam detection, sentiment analysis, and recommendation systems based on the models.
This system is similar to Amazon’s Machine Learning option, except it involves a much more advanced knowledge of basic coding skill to get up and running. However, you’ll find an option for those of us that have less refined experience creating machine learning recipes from syntax.
Google Cloud Prediction API has a Google Sheets option called Smart Autofill.
Just like our other processes, the first step starts with data. You pull in the data based on important attributes for your campaign. Unlike the process we did with Amazon, you actually want to combine your training data and data you want to predict in the same sheet.
From the data you enter, you choose the columns that have data you want to use in predicting your results, as well as the column you plan to fill with predictions.
Next, you select the column that has the data you want to predict.
When you’re done, you can view the estimated error and accuracy of your data. You can work with values that are not simply true or false statements, and the add-on function will report the possible amount of error.
We ran the Auto Smartfill add-on on the data from the Amazon Machine Learning test. The test worked, but we noticed a couple of items.
• As with traditional Google Sheets operations, the add-on has a hard time dealing with data at a very large scale. We had to parse down the record count to get it to work.
• It takes some time to get the results you need.
However, the results you get are very good.
Microsoft has launched ML Studio as a part of its Azure tool set.
ML Studio is interesting because you can work in a drag-and-drop interface to build your workflows.
While this arrangement makes the setup look extremely user-friendly, the robust nature of ML Studio is not something anyone can dive into. Each of the interconnected units in ML Studio is a layer of the machine learning process. This layering includes data, algorithms, scoring models, and more. Each of those components is capable of being managed through R or Python.
As you dig in, you realize that Microsoft Azure ML Studio is a powerful tool created with data scientists in mind. This feature makes it a good option if you’re growing a data science team, but it’s less friendly for a new user to the system.
One interesting note is that you’ll discover pre-built solutions available in the Azure marketplace that might make this option more palatable for those with technical experience.
While the above options allow for an entire world of flexibility and creativity for your machine learning needs, some of us only need tools that work today for very specific issues. Luckily, machine learning-based software solutions are on the rise in the adtech space, and solutions exist for you to sign up today and put machine learning to work for you.
BigML is a consumable, programmable, and scalable Machine Learning platform provides a selection of Machine Learning algorithms to solve various tasks, like Classification, Regression, and Time Series Analysis, by applying a single, standardized framework. The mission of BigML is to make Machine Learning easy, beautiful and understandable for everybody.
Below is a list of useful features:
1. Allowing you to load data from plenty of places, including Cloud storage platforms, direct URLs, and local CSV files.
2. Helping you detect outliers and pattern anomalies to save time and money, even before hitting your model.
3. A large number of free datasets and models for you to play with.
Atomic Reach is an out-of-the-box solution that helps marketers know what to do with their content to get the most value out of their content marketing. This tool helps you create the content, share it, engage with data in real time to make on-the-spot changes to strategy, and see trending topics that you can use to create timely content.
The creation module measures 22 attributes of the content you’re creating in real time. These attributes include readability level, length, emotions and more. The Atomic Reach Writer lets you train your Machine Learning by assigning different attribute levels as an “audience.” You generate content for that audience, and the system lets you know where you score.
Rarelogic has created an email marketing optimization solution that works with Shopify and BigCommerce. The company’s main offering is predictive email recommendations. You can create and use preset Mailouts based on visitor segmentations:
Before we close the door on the topic of tools and ways that marketers can get working with machine learning today, we wanted to touch on some open-source platforms that exist and are worth investigating.
Keras is an open-source neural network library written in Python. It’s capable of running on top of three open-source machine learning software libraries, DeepLearning4j, TensorFlow, and Theano. The library has many implementations of commonly used neural network building blocks including layers, objectives, and optimizers.
KNIME is a software to create and productionize data science by simple drag and drop process.
KNIME Analytics Platform is a free, open-source platform for data-driven innovation which is good for individual use. It allows you to load data from any source, like Microsoft SQL and Salesforce, process data, leverage plenty of Machine Learning and AI models, share insights, and even build data science workflows.
KNIME Server is for enterprise. Besides features that KNIME Analytics Platform contains, it also allows you to share best practices across teams and the company, automatically schedule workflows, scale workflow execution, deploy analytical applications, manage and monitor operations, and more.
KNIME (Konstanz Information Miner) is an open-source data analytics, reporting, and integration platform that has components of machine learning included in its modular data pipelining. KNIME integrates with various open-source projects to help with machine learning functionality, such as Weka and R Project.
![]()
![]()
