TL;DR
- Review the SERP and the Page Itself
- Turn on Preserve Log in Chrome DevTools
- Switch your user agent to Googlebot
- Go to the page directly and from Google
- Perform a series of cURL requests
With our newfangled SEO tools abstracting away most of the diagnostic work, I’ve come across some folks that don’t know how to diagnose commonplace hacks.
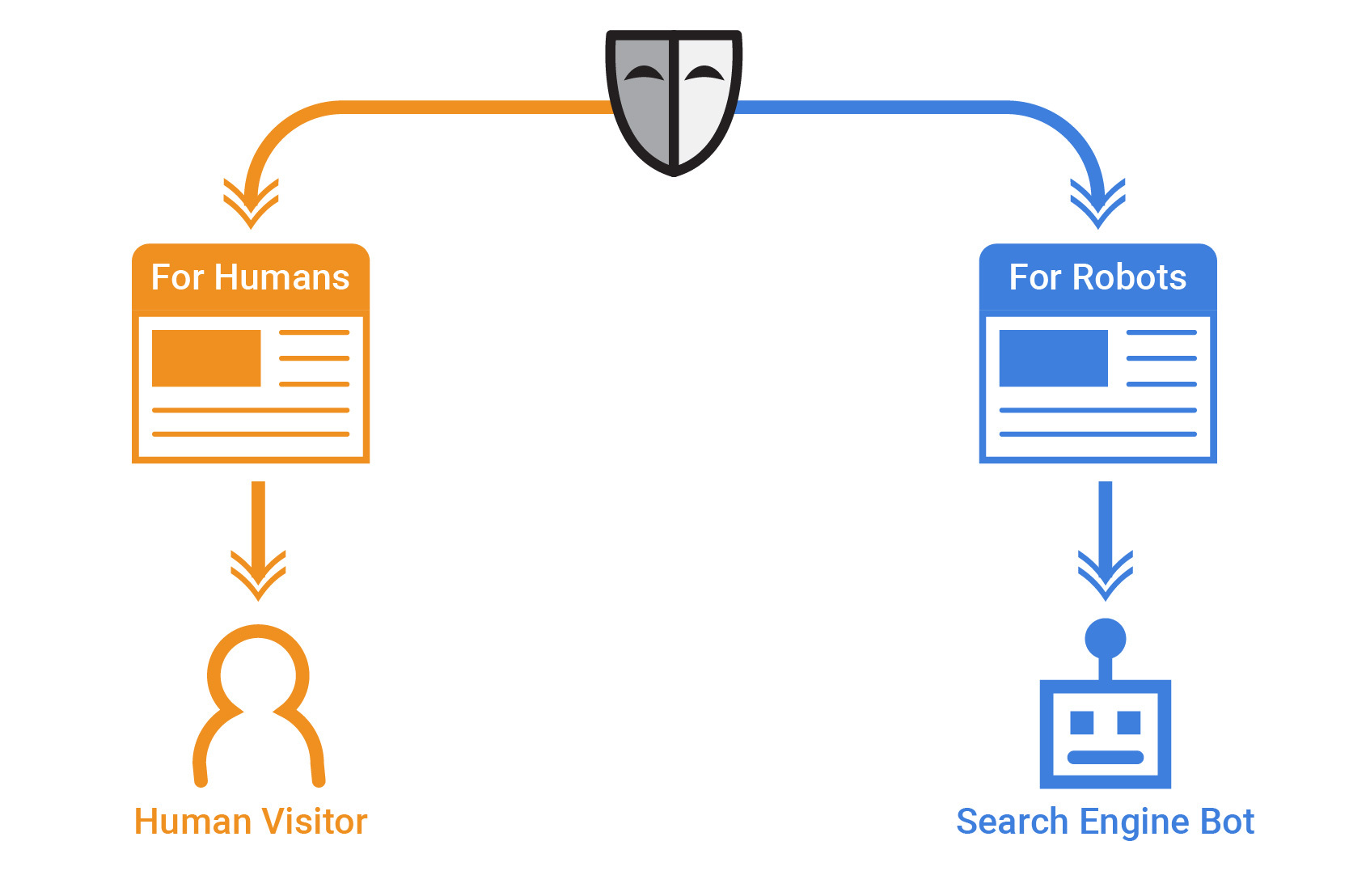
Cloaking is, indeed, a hack. It’s also a hack that still works. I’ve mentioned before that I think it’s hard to truly define cloaking anymore because there are several reasons why a webpage may show something different to Googlebot than to a user.
Google’s definition of cloaking is a bit outdated (hello low production value Matt Cutts video!) in that it mentions Flash. However here is that definition in case you’ve not come across the concept previously:
“Cloaking refers to the practice of presenting different content or URLs to human users and search engines. Cloaking is considered a violation of Google’s Search Essentials because it provides our users with different results than they expected.”
For example, by definition, Dynamic Serving is showing Google one version of the page and the user another. Your server-side rendered (SSR) version of a page often includes way more content than a user initially loads on the client side because a user does not need to look at every component of the page when they first get there. Their interactions with the experience will ultimately help them uncover the content they are after. It’s simply a good design principle to only give them what they need.
You can extrapolate this in at least a couple of ways that could fall somewhere on the cloaking spectrum. So, I imagine that Google has had to relax its stance on cloaking for some time now because there are too many contexts to check to determine if a user is cloaking. For instance, with mobile-first indexing (MFI) enabled across the web, one could potentially have a completely different web page shown on Desktop than on Mobile or for a specific user agent/device/location combination. There are numerous combinations at this point; It would be too computationally expensive for Google to crawl and render all of them.
More recently, Google’s Martin Splitt has indicated that cloaking is more defined by the intent than the act.
Cloaking in the Wild
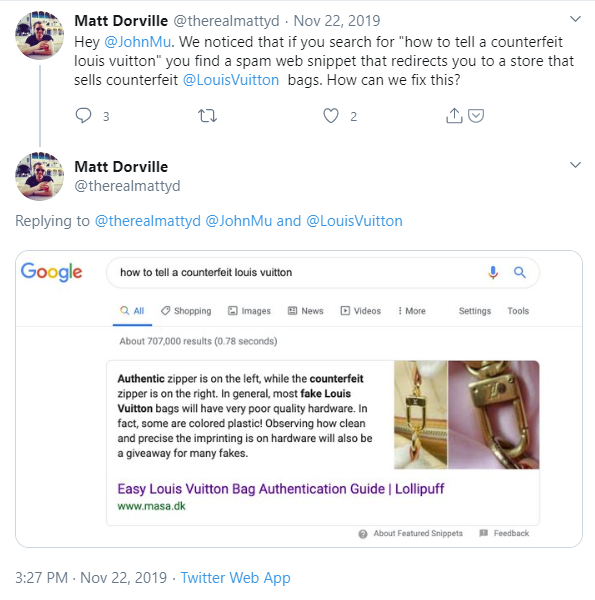
A few months back, Matt Dorville over at 1stDibs tweeted a SERP wherein a featured snippet was triggered for a page that literally did not have the content in the featured snippet on it.
I find puzzles such as this compelling, so I took a few minutes and dove in.
Clicking on the URL from Google, I got redirected to a site that was not at all Masa.dk. Rather, I was redirected to a different site that sells fake Louis Vuitton bags. The content in the featured snippet is nowhere to be found on the page.
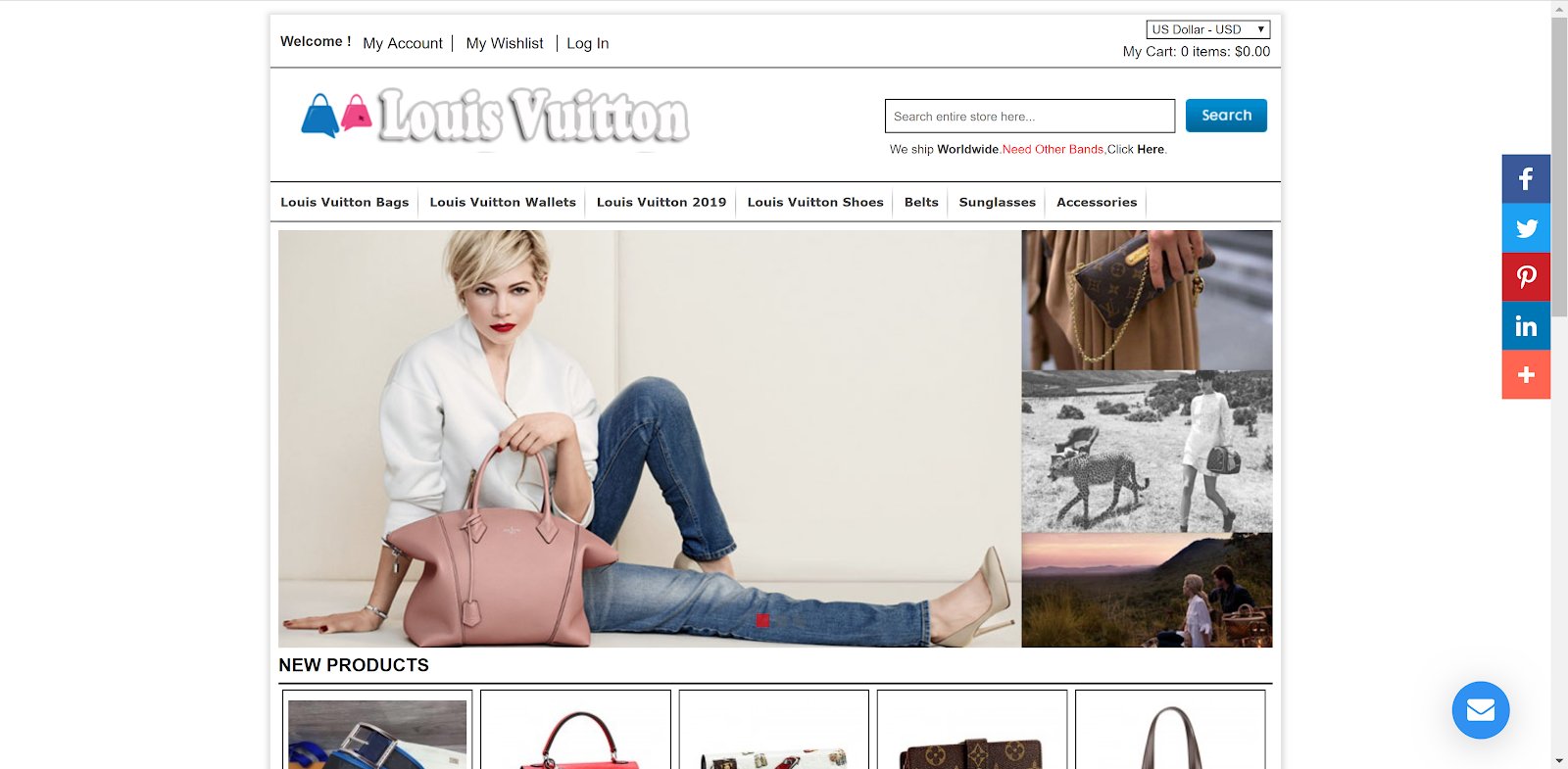
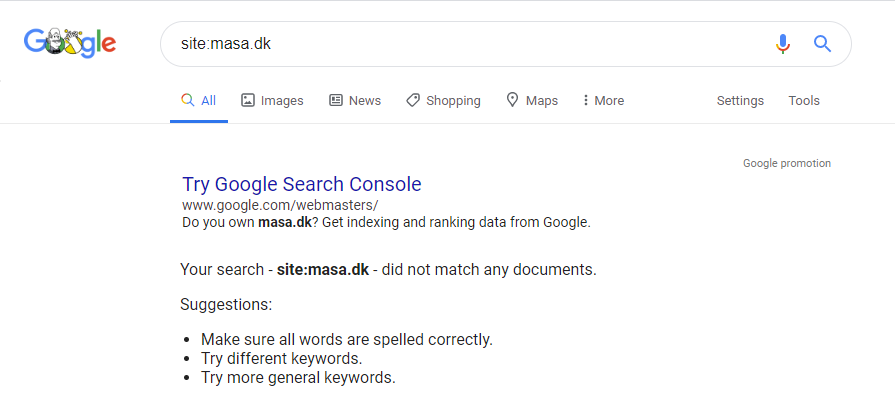
Intrigued, I backtracked and went directly to masa.dk. I was unable to find any content related to Louis Vuitton bags on that domain at all. The site also did not redirect me to the bootleg Louis store. So, there is a high likelihood that the Harrow Symphony Orchestra had no idea that their site was playing out of tune.
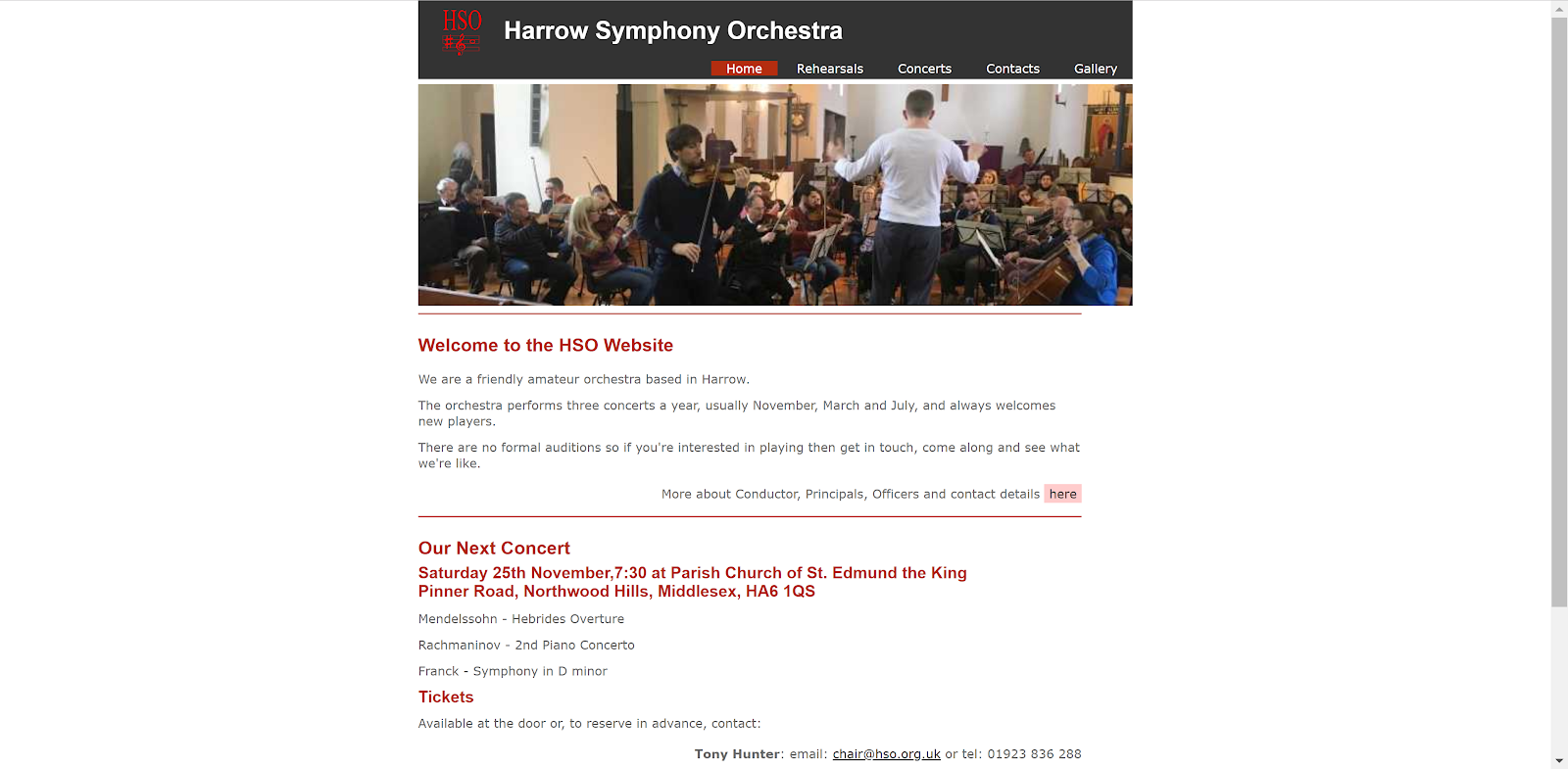
However, if you went to the page as Googlebot, at the time, you’d see some completely different, mostly text-based content.
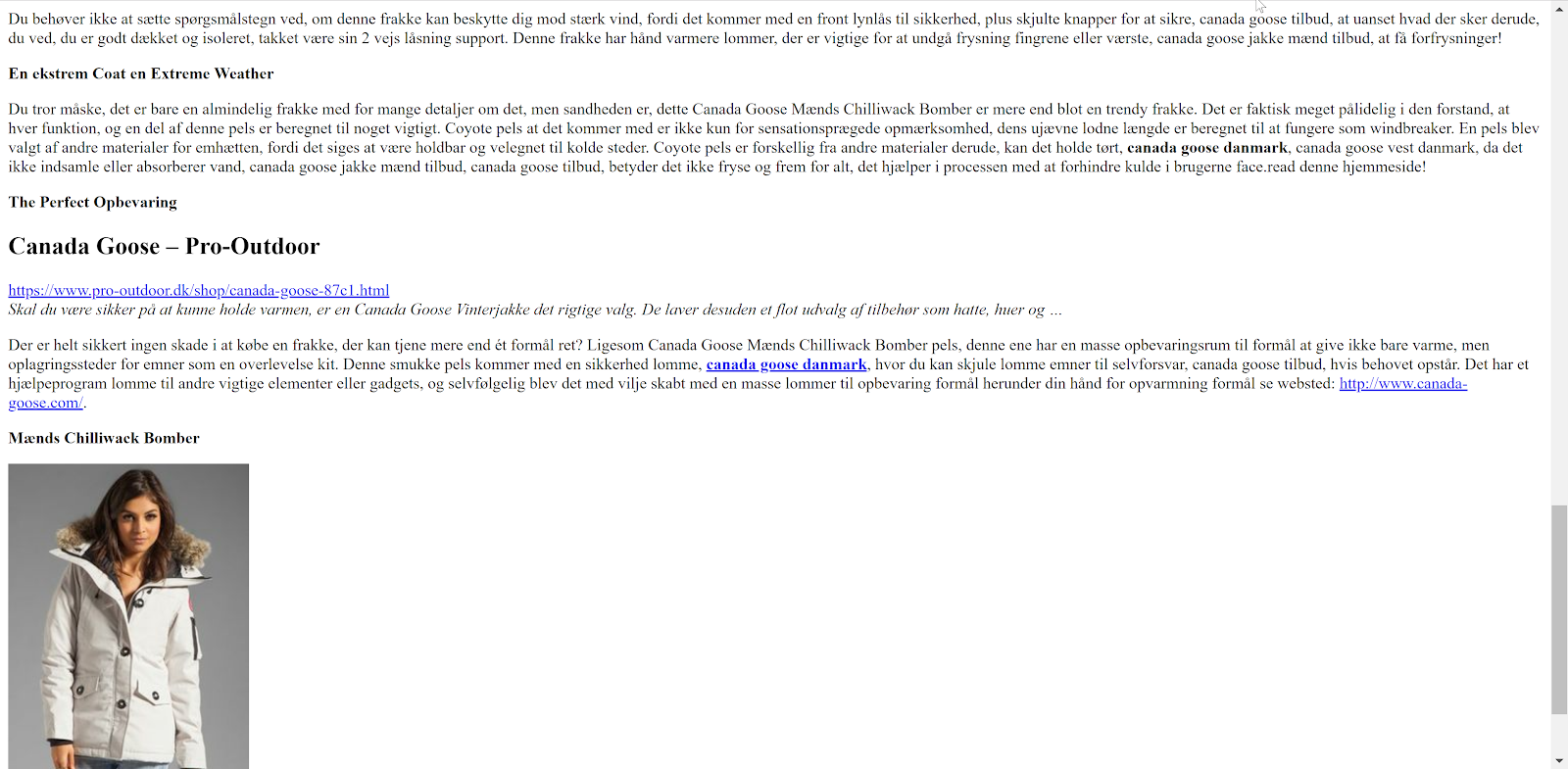
Even so, by the time I caught up with it, that content had nothing to do with the French fashion house either.
Wanting to know more about how it worked, I popped open cURL from my command line and played around with request headers until it was clear that the 302 redirect was triggered by the referer. The only way to see the Canada Goose related content above by having a referrer from Google.com/Search.
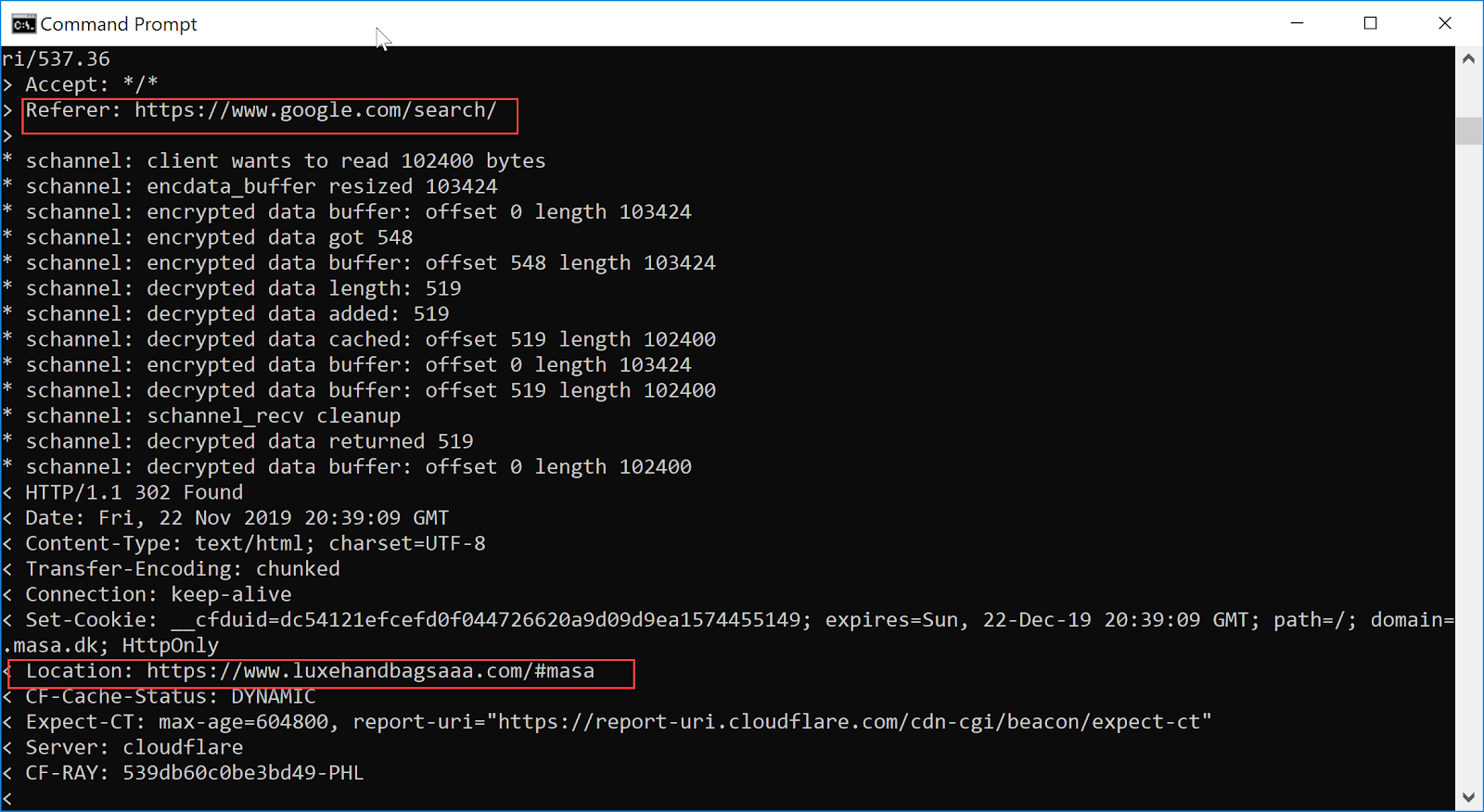
Ultimately, what appears to have happened is the site copied the content from Lollipuff, got it indexed, and then set up a 302 redirect.
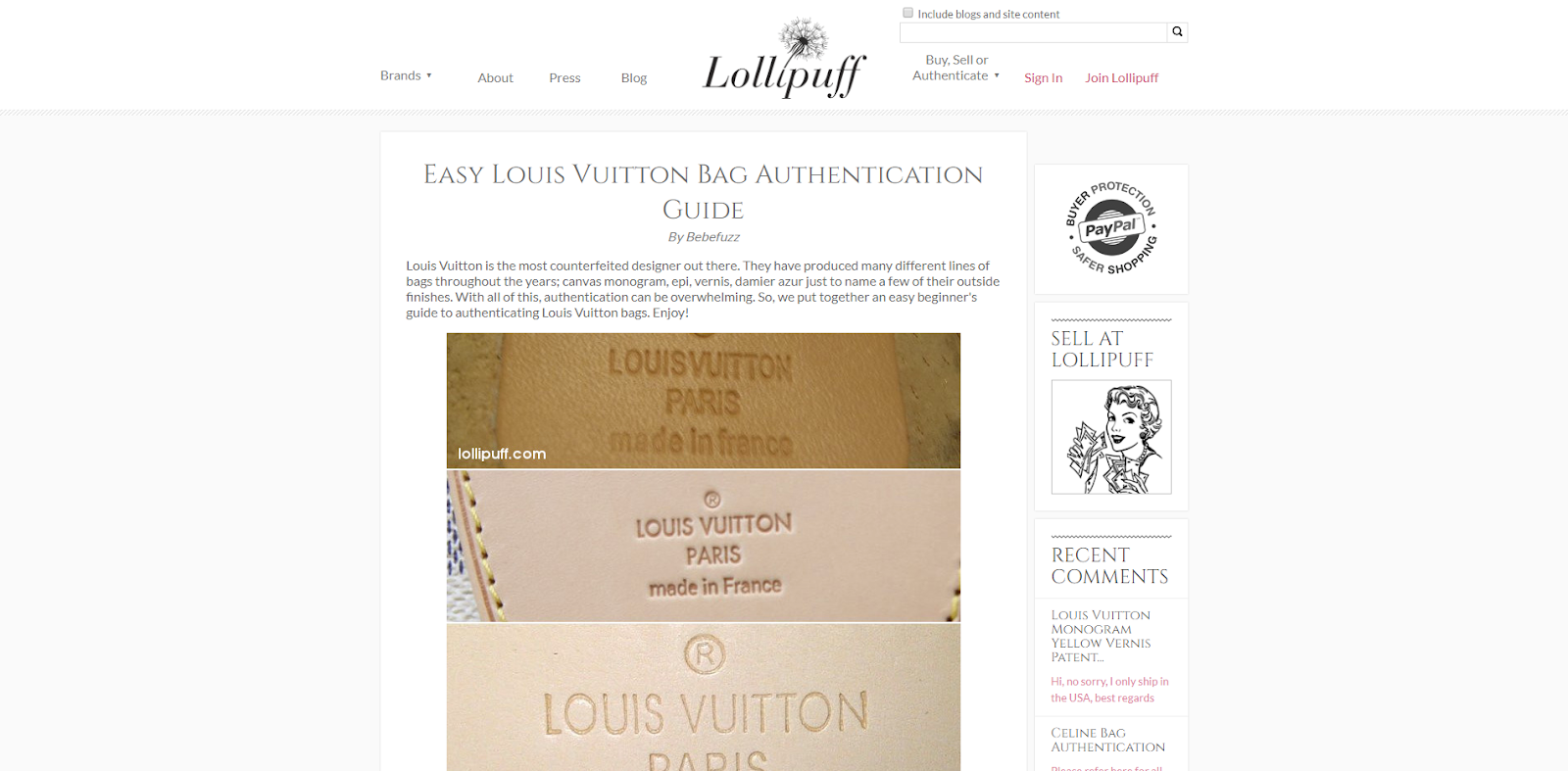
Interestingly enough, that content on Lollipuff.com still currently triggers featured snippets for several keywords around the concept of determining the authenticity of Louis bags.
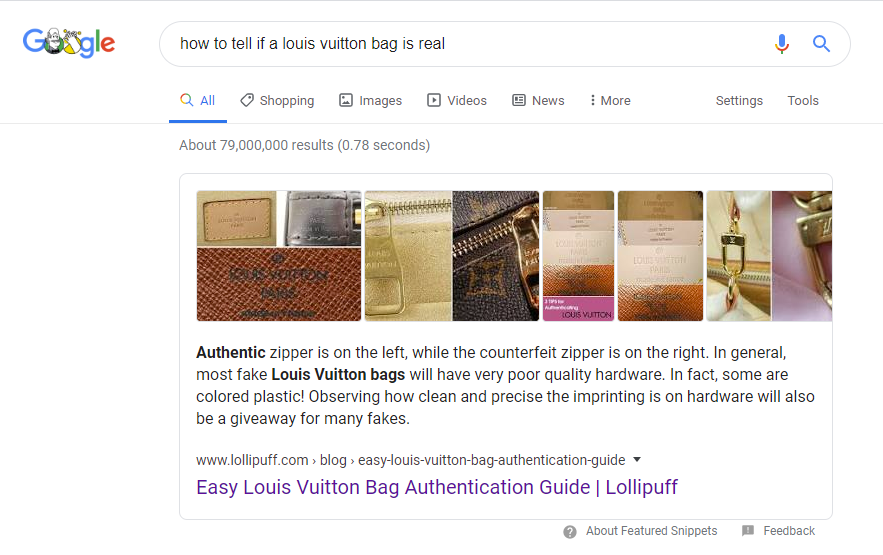
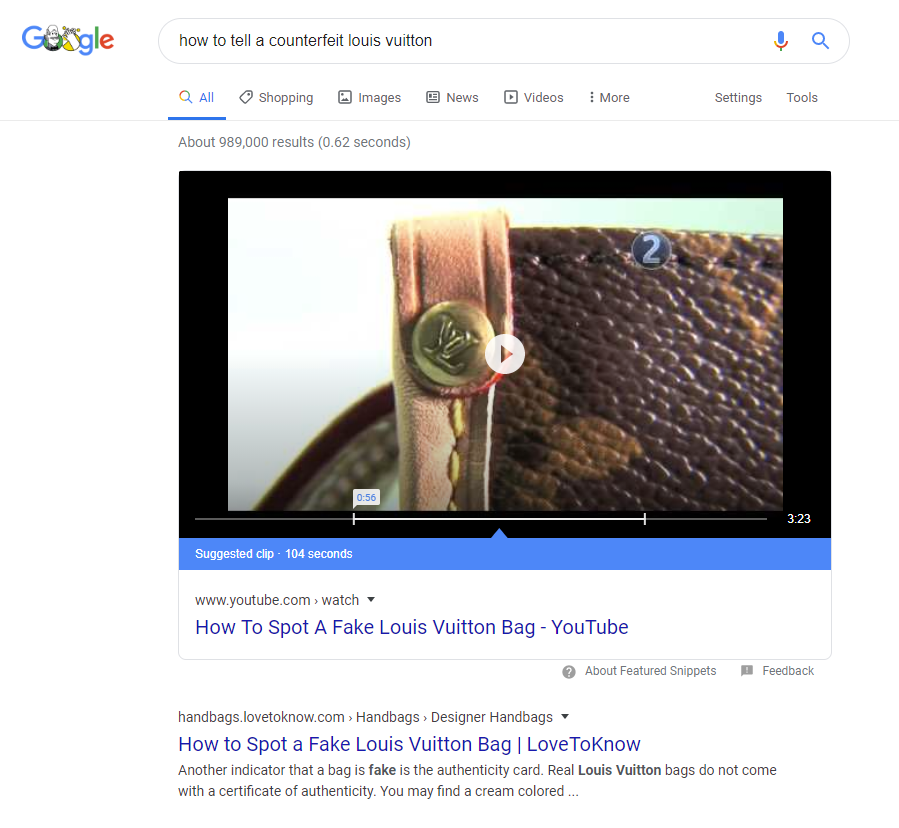
However, for the original query in question, Google has made the switch to a YouTube video.
Unfortunately, it seems that music has stopped entirely for masa.dk. The site is down and there are no longer any pages in Google’s index.
Ways that Websites Cloak
I’m certainly not encouraging anyone to cloak, but for educational purposes, webpages can cloak in several ways. What follows is an incomplete list of things I’ve seen in the wild:
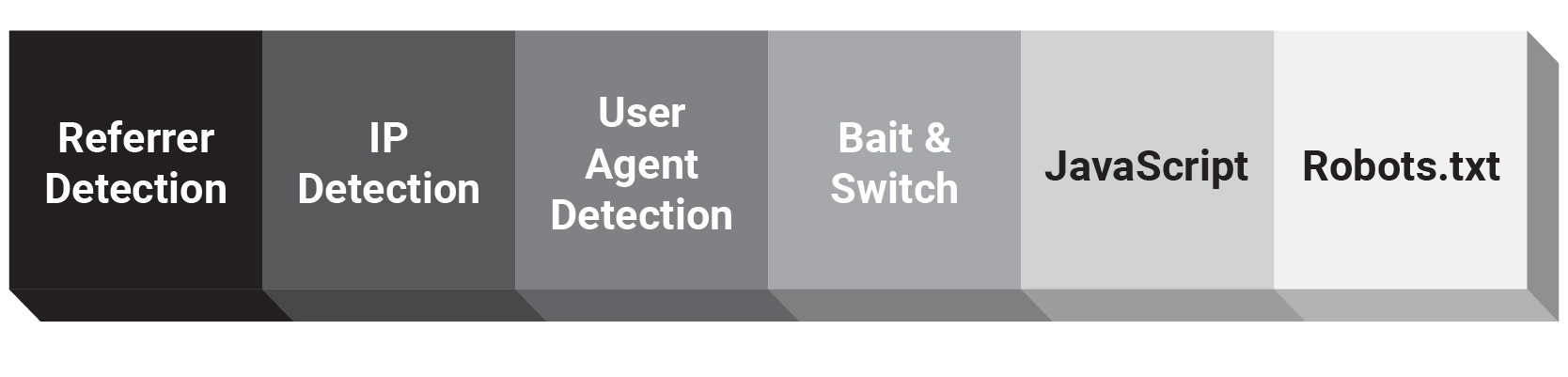
- User Agent Detection – This is perhaps the least sophisticated version of cloaking wherein the page determines whether or not the user agent is Googlebot and returns a different version of the content. This is pretty easy to identify based on manual review.
- IP Detection – Same as user agent detection, except based on the IP address. Since Googlebot’s IPs can be a bit of a moving target, the page may move to perform a reverse DNS lookup and return a different version of the page to Googlebot.
- Referrer Detection – Just as in the cloaking in the example above, the page detects whether or not the user is coming from Google and shows a different experience. This may also be used in context with the other two techniques in hopes of making sure that only Google sees the other version.
- Bait and Switch – The most interesting version of cloaking that I have seen in recent years has to do with driving Googlebot to index a more content-heavy version of the page. Once it’s indexed, the server then returns a 304 Not Modified response and then changes the content experience altogether for the user. Honestly, the first time I saw it, I thought it was genius.
- Robots.txt – If certain resources are required to render content are blocked in robots.txt for Googlebot, they may not see the same content as the user. This is the use case that Martin Splitt addresses in the video above.
- JavaScript – If something loads after the document ready state, Googlebot may not be able to index it as it is seen to the user. Effectively, a page could load content in an open state and delete it after document ready thereby making it indexable, but not actually on the page.
The last two in this list are more of a weaponized version of the problems created by web development that does not account for SEO best practices.
How to Detect Cloaking
If you’re used to turning off JavaScript and CSS to get a deeper understanding of how Googlebot might experience a page then you should just consider adding this to your list of things to do when performing an audit.
- Review the SERP and the Page Itself – How the page comes up in the SERP and what the page ranks for can give you a clue that something is off if you can’t find that content on the page or in its code.
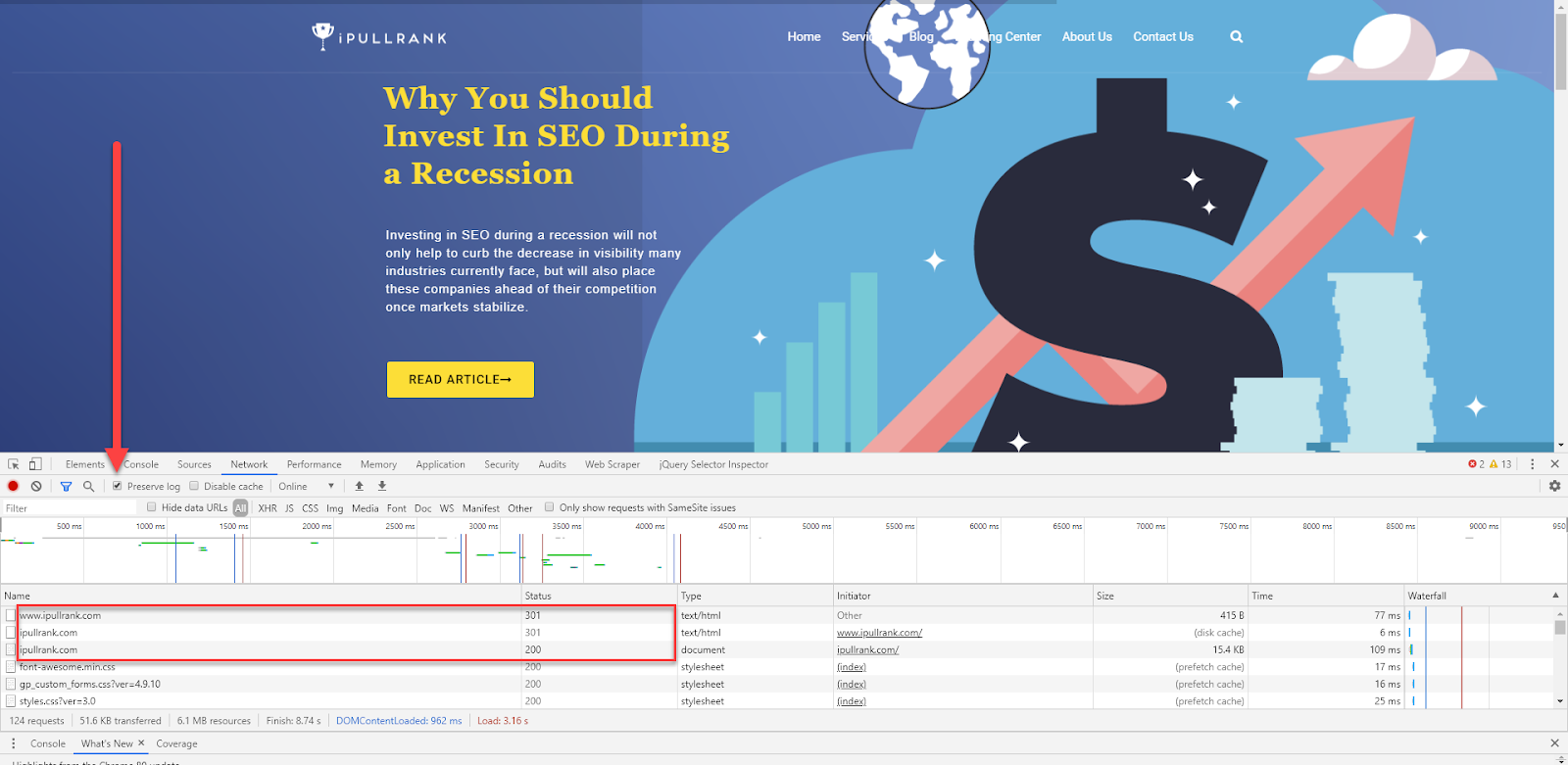
- Turn on Preserve Log in Chrome DevTools – Get in the habit of viewing pages with the Chrome Developer Tools open and on the Network tab. Make sure you keep Preserve Log checked as well. Redirects happen so quickly that it’s often difficult to notice. When you leave Preserve Log on you can see how many redirect hops happened. Otherwise, the log clears itself with each subsequent URL
- Switch your user agent to Googlebot – Looking at the page as Googlebot may change what you see. Change your user agent to “Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)” under Network Conditions in Chrome
- Go to the page directly and from Google – As illustrated above, going to a given URL directly versus being referred from Google.com can change what it serves you. Try a series of paths to entry to ensure consistency.
- Perform a series of cURL requests – There may be any number of things in your browser that a page or server can detect to determine that you’re not actually Googlebot, so you can use cUrl to request pages from the command line. Here’s a series of commands that you may want to run to get raw responses from the server:
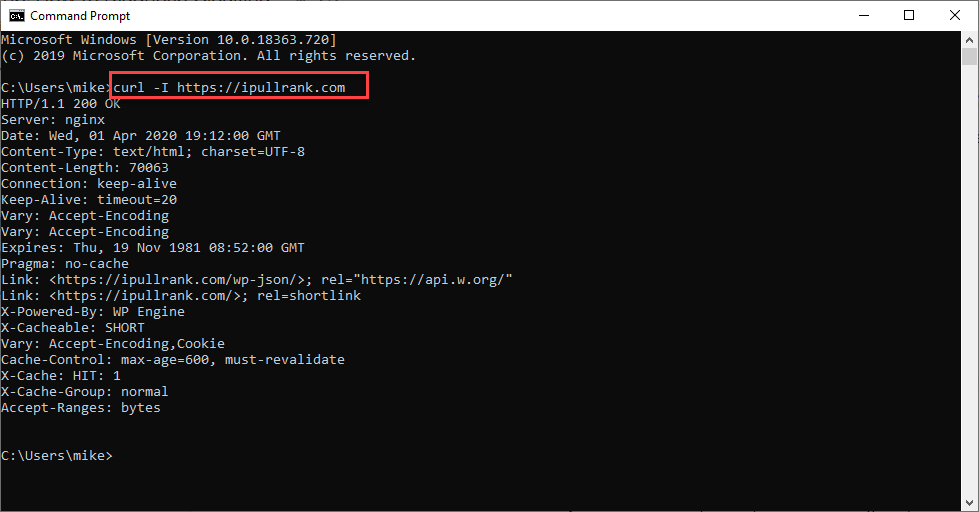
- Get just the headers curl -I https://www.site.com/
- Get the headers and the body of the request curl -i https://www.site.com/
- Crawl with Googlebot User Agent curl -A “Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)” https://www.site.com/
Crawl with referrer curl –referer https://www.google.com/search https://www.site.com/
- Get just the headers curl -I https://www.site.com/
Wrapping Up
Cloaking is still happening in the SERPs. As Matt showed us, it can even make its way into the Featured Snippets. It’s not something you’ll need for every site you work on, but identifying it is a good skill to have in your tool belt when something is awry in the SERPs.

Now over to you, what types of cloaking have you come across and what tools are you using to identify it?