
Two and a half years ago, I wrote an article for Search Engine Land about how retrieval-augmented generation (RAG) was the future of search. That piece argued that RAG was not Google’s reactive answer to ChatGPT. It was the architecture they had been building since the REALM paper in August 2020. SGE (now AI Overviews) was the production manifestation. Everything that has happened since has confirmed it.
The single-shot RAG pipeline I described in that article, query → retriever → top-k chunks → LLM → answer with citations, is already the past. Every major AI search platform has moved on. Google AI Mode, ChatGPT Search, Perplexity Pro Search, Claude with Computer Use, Gemini Deep Research, even the Microsoft Copilot Researcher and Analyst agents, they all run a different architecture now. They plan. They route between tools. They retrieve, read, then retrieve again. They grade their own first drafts and decide whether to go back for more. The retrieve-once-then-generate pattern that defined the first wave is obsolete.
This is agentic RAG, and it is now the default.
If your GEO program is still optimized for single-shot retrieval, you are optimizing for a system that no longer exists. Worse: in agentic RAG, you cannot see the gatekeepers rejecting you. You only see whether you ended up in the final answer. The traditional reverse-engineering playbook (rank checking, citation counting, even prompt-by-prompt sampling) only sees the last stage of a multi-stage pipeline. Everything that happens upstream is a black box.
By the time you get to the bottom of this page you will have a working mental model of agentic RAG, the patent evidence that Google has productized this architecture, what each major platform is actually doing, the six concrete shifts it forces in content engineering, and a reproducible audit you can run against your own brand this week. You will also have the strongest opinion I have published all year: the only honest way forward is model distillation.
What the SEL article got right and what's changed
The October 2023 thesis still holds. Passage-level retrieval is the unit of relevance. Knowledge graphs are symbiotic with LLMs, not a checkbox you tick once and forget. Static IR scores are obsolete. The job of a search system is to lower Delphic costs, the cost a user pays to get to an answer, and Google’s organizing principle has always been that traffic is a necessary evil, not a goal. That part of the argument needs no revision.
What has changed is the shape of the retrieval pipeline.
In 2023, RAG was a linear assembly line. A query came in, an embedding model encoded it, a vector index returned the top-k passages, those passages were stuffed into the LLM’s context window, and the model generated an answer. Citation tracking was straightforward because the citation set was the retrieval set. If your content was in the top-k, you had a chance. If it wasn’t, you didn’t. This is the framework I described in that piece, and it was accurate at the time.
But things have changed.
The pipelines now have four properties that the linear architecture lacks: planning, tool use, multi-hop iteration, and reflection. The implication is that retrieval is not a single event anymore. A single user query triggers somewhere between five and twenty internal sub-retrievals. The agent orchestrates them, evaluates the intermediate results, and only synthesizes a final answer once it has decided the evidence base is sufficient.
This is the upgrade my piece foreshadowed but did not name.
Why naive RAG broke

Retrieval quality determines output quality and naive RAG has four failure modes that yielded lower quality results.
- Classic, single-pass RAG cannot serve compound questions – A prompt like {How does a 1031 exchange interact with a SEP IRA for an LLC owner under 50?} needs five retrievals, not one. A single embedding query against a vector index will land on documents about 1031 exchanges or SEP IRAs, and the synthesis will be incoherent because the model is forced to bridge two retrievals it never made.
- Classic RAG can’t recover from a bad first pull – If the initial retrieval misses the canonical source because the embedding distance was off, or because the chunk boundaries split the relevant passage in half, or because a more aggressive piece of competing content scored higher on a query the user did not literally ask then the model has nothing to lean on except its parametric knowledge. That’s when hallucinations cascade.
- Classic RAG didn’t route between retrieval tools – Vector search is the right answer for some sub-questions and exactly wrong for others. “What is today’s mortgage rate?” needs a structured-data API call, not a passage search. “What does the IRS say about Section 179?” needs an authoritative-source filter, not similarity. “Calculate the depreciation schedule on a $50,000 vehicle placed in service in March” needs a code interpreter or a calculator tool. A single retriever cannot make those choices.
- Classic RAG can’t grade its own work – Once the answer is generated, naive RAG ships it. There is no critic. No second pass. No “wait, this contradicts the source I cited two paragraphs up.” If the model gets it wrong, the user sees the wrong answer.
These four failure modes are why every serious deployment moved to a different architecture. Each one has a corresponding fix, and the fixes together are agentic RAG.
What "agentic" means in agentic RAG
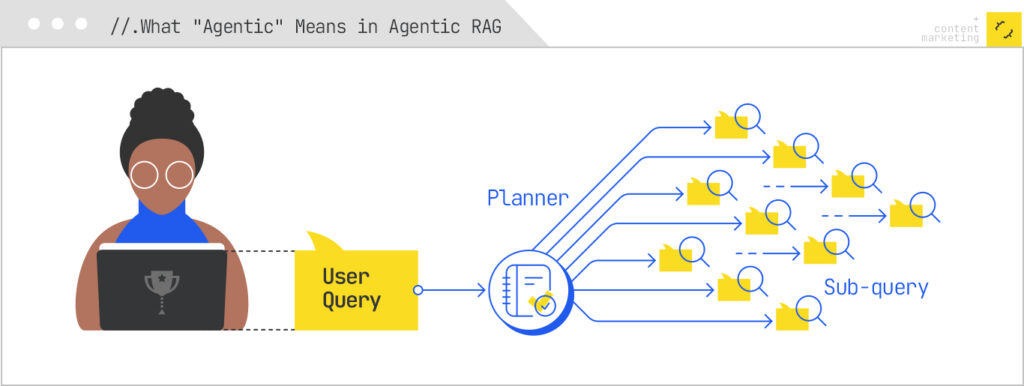
The word “agentic” gets used loosely. Let’s nail it down structurally. There are four properties that turn RAG into agentic RAG, and a system needs all four to deserve the label.
- Planning. Before any retrieval happens, the system decomposes the user query into a research plan. Sub-queries get generated, tools get pre-selected, retrieval order gets determined. In the AI Mode piece I called this “a latent multi-query event” when discussing query fan out.
Agentic RAG goes a step further: the system does not just fan out, it plans the fan-out. The foundational paper is ReAct (Yao et al., 2022), which framed the move directly: “we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans… while actions allow it to interface with external sources, such as knowledge bases or environments.”
That interleaving is the planner. The production version is in every frontier model now, plus the planner-executor patterns that LangGraph and LlamaIndex have made standard. - Tool use, also called function calling. Retrieval is one tool among many. The agent can choose to query a vector index, hit a BM25 index, hit a structured-data API, run code, browse a live web page, call an MCP server, or call another agent. Each tool has a schema, and the agent picks the right one for the right sub-query.
Toolformer (Schick et al., 2023) made the case bluntly: “language models can teach themselves to use external tools via simple APIs and achieve the best of both worlds… a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.” That sentence is the spec for every router we’ll discuss later. - Iteration, sometimes called multi-hop retrieval. The agent retrieves, reads what came back, and then retrieves again based on what it learned. Bridge entities or the entities the first retrieval surfaced that the second retrieval needs to investigate, become first-class behavior, not edge cases.
IRCoT (Trivedi et al., 2022) defined the loop as “interleaving retrieval with steps (sentences) in a chain of thought, guiding the retrieval with CoT and in turn using retrieved results to improve CoT.” The same paper reported retrieval improvements of up to 21 points on multi-hop QA datasets when the loop was applied. - Reflection, also called self-critique. After drafting an answer, the agent grades it. Sufficiency, contradiction, freshness, source diversity. If the critic flags a problem, the agent goes back and retrieves more.
Self-RAG (Asai et al., 2023) is the most-cited paper in this lineage and the cleanest articulation: “a new framework called Self-Reflective Retrieval-Augmented Generation that enhances a language model’s quality and factuality through retrieval and self-reflection… the framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using reflection tokens.”
CRAG, Reflexion, and Self-Refine extend the same pattern in different directions, but the core mechanism is right there.
Anthropic’s December 2024 essay “Building effective agents” defines the same four properties under cleaner terminology, and one of its lines belongs in every GEO deck this year: “Agents are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.” With so much confusion around what an agent is or what agentic means, let’s use that as the working definition. Ultimately, the terminology varies by vendor; the four properties do not.
A picture is worth more than the definition list above. Imagine the classic RAG architecture as a single arrow pointing right: query enters one end, answer comes out the other. Now imagine agentic RAG as a loop with five labeled stops — planner, router, retrieval tools, critic, synthesizer — and bidirectional arrows that allow the agent to revisit any stop until the critic signs off. That loop is what your content has to survive.

The agentic RAG reference architecture

Let’s walk through the canonical components, because you cannot reverse-engineer a system you cannot draw.
- Planner / orchestrator – Reads the user query, generates a research plan. Same LLM as the rest of the system, run with a planner-specific prompt. Outputs a list of sub-queries and a tool assignment for each.
- Router – Decides which retrieval tool fits each sub-query. Vector search? Lexical? A hybrid retriever? A live web fetch? A SQL query against a structured database? A function call into a calculator? An MCP server exposing a domain-specific API? An agent-to-agent call? The router is the most underrated component in the entire stack because it determines whether your content even gets a chance to be retrieved. If your domain has a tool surface and you do not expose one, the router skips you.
- Retrieval tools – Each tool is its own subsystem. Vector retrievers run cosine similarity over dense embeddings. Lexical retrievers run BM25 or rank-modified TF-IDF. Structured tools call APIs and return rows. Code interpreters execute scripts. Web browsers fetch live URLs. The agent treats them all uniformly: input goes in, evidence comes out.
- Memory – There are typically two layers of memory. Short-term scratchpad for the current research thread. This includes things like what sub-queries have run, what evidence has come back, what the critic has flagged. Then there’s long-term memory for user
- Critic / reflection module – Judges sufficiency and quality of the draft answer. This is sometimes a separate model, but often the same model with a critic-specific prompt. The Reflection module decides whether to ship or to re-query. The critic is the gatekeeper that nobody talks about, and it is the gatekeeper that drops the most content from final answers

- Synthesize – Composes the final answer with inline citations, often after a final pairwise re-rank against the surviving candidates.
A clarification before we move on. Most production systems are not literal multi-agent constellations. They are a single LLM running tight loops with different prompts at each stage, plus tool calling. Do not conflate “agentic” with “multi-agent.”
Multi-agent setups exist. Anthropic’s research stack uses them, and so does Microsoft’s Researcher / Analyst pair, but the dominant production pattern is single-LLM, multi-prompt, multi-tool. When the marketing team tells you their AI is “multi-agent,” nine times out of ten what they mean is “we have a planner prompt and a critic prompt.”
Patent evidence: how Google is actually doing agentic RAG
Google has been quietly building toward this architecture for years, and the patent record maps almost cleanly onto the four-property definition from §3. Five Google LLC patents do the heavy lifting. Read them in this order and you can watch the agentic loop assemble in IP filings, one component at a time.
- Planning — query decomposition and fan-out. US11663201B2 — Generating Query Variants Using a Trained Generative Model was filed in April 2018 and issued in May 2023. It describes systems that use a trained generative model to produce query variants at runtime from a single submitted query. The patent enumerates eight variant types — equivalent, follow-up, generalization, canonicalization, language-translation, entailment, specification, and clarification queries — and explicitly handles “tail” queries with low submission frequency. This is the planner. When AI Mode receives one query and decomposes it into five-to-twenty sub-queries, the mechanic the patent describes is what is running. The companion filing, WO2024064249A1 — Systems and Methods for Prompt-Based Query Generation for Diverse Retrieval, is the Google Research version of the same idea. “Promptagator” which uses few-shot LLM prompting to generate synthetic queries for training dual-encoder retrievers across diverse domains. Plan-then-fan-out, productized.
- Tool use — routing among retrieval sources. US20240362093A1 — Query Response Using a Custom Corpus, assigned to Google LLC and published October 31, 2024, is the cleanest router patent in the stack. The system has the LLM process a user query and generate API calls to external applications, each of which has access to a respective custom corpus. The external applications return documents, which the LLM uses as context for generation. Tool selection. API calls. Multiple corpora. The behavior every frontier vendor now ships under the label “function calling” was filed by Google in this patent.
- Memory — stateful, multi-turn orchestration. US20240289407A1 — Search with Stateful Chat, assigned to Google LLC in March 2024, describes augmenting traditional search with a “generative companion” that maintains and updates user context across multiple chat turns. The patent explicitly handles synthetic query generation tailored to that ongoing state. This is the long-term memory layer of the architecture in §4 — the same layer that ChatGPT calls Memory and Gemini calls Saved Info. Google patented the mechanic before any of them shipped a UI for it.
- Reflection — pairwise ranking inside the loop. US20250124067A1 — Method for Text Ranking with Pairwise Ranking Prompting, assigned to Google LLC in October 2024, is the patent I covered in How AI Mode Works. The system ranks passages by having an LLM perform pairwise comparisons — “of these two passages, which is better for this query?” — and aggregates the comparisons into a final ranked list. This is relative, model-mediated, probabilistic ranking, and it is the inner loop that runs inside the agent’s reflection and synthesis stages. Your content is not competing in isolation. It is being compared head-to-head against every other surviving candidate, by an LLM that reads both passages and picks a winner.

- Synthesis — generative answers grounded in retrieved evidence. US11769017B1 — Generative Summaries for Search Results was filed in March 2023 and issued by September of the same year. The patent describes generating natural-language summaries of search results using LLMs, with explicit provisions for processing additional content to mitigate inaccuracies and improve summary quality. Industry analysts have correctly identified this as the patent foundation underneath SGE and the AI Overviews product. The “process additional content to mitigate inaccuracies” language is reflection in early form — the synthesizer is checking its own work before shipping the answer.
Five patents. One planner mechanic. One router mechanic. One memory mechanic. One reflection mechanic. One synthesis mechanic. Lay them on top of the four-property definition and it’s clear that Google has filed IP on every component of the agentic loop. The agentic stack is not a startup-vendor framing borrowed from the open-source agent ecosystem. It is a production architecture that Google has been building toward in its patent filings since 2018.
The other major platforms do not have the same patent footprint, but they have the same architecture. Patents are evidence, not boundaries. The fact that Google has chosen to file IP on these specific subsystems tells you which subsystems they consider strategic and which subsystems your content has to win at if you want to be cited in AI Mode.
How each major platform actually uses agentic RAG
Different platforms emphasize different pieces of the loop. The platform-by-platform read matters because the same content can win in one system and lose in another based on which gatekeeper does the heaviest lifting.
- Google AI Mode – The most aggressive agentic implementation in production. Planner-driven fan-out. Multi-pass retrieval into Search. Pairwise re-ranking per US20250124067A1. A reflection module that drops sources that fail the critic. The visible “expansion” UI shows you a fraction of the sub-queries, but the actual fan-out is wider. This is the platform where breadth and pairwise survivability matter most.
- Google AI Overviews – A lighter agentic pattern. Shorter loops. Less iteration than AI Mode. AIO is closer to classic fan-out than full agentic RAG, but the trajectory is clear, every AIO update adds more reflection and more router intelligence.
- ChatGPT Search and Deep Research – Deep Research is the cleanest user-facing demonstration of the pattern. It literally exposes its planning, sub-queries, and reflection in the visible UI. You watch the agent decompose your question, route to tools, and grade its own progress. Standard ChatGPT Search runs a smaller version of the same pipeline without the visible plan. If you want to study agentic RAG empirically, run ten queries through Deep Research and read the trace.
- Perplexity Pro Search and Deep Research – Agentic from the start. Multi-step retrieval, source diversification by design, draft critique. Perplexity tends to be the most generous about source attribution, which makes it the best canary for whether your content is making it into intermediate retrievals.
- Claude with Computer Use, Projects, and Skills – Tool use as a first-class primitive. Claude features long-running multi-step tasks where retrieval is interleaved with action. The system can read a page, decide to fetch a different page, decide to run code, decide to query an API, all inside the same task. Claude is overrepresented in enterprise deployments where the action layer matters as much as the retrieval layer.
- Gemini Deep Research – Explicit research-plan-then-execute loop. Multi-source aggregation. Draft critique. The visible plan in Gemini Deep Research is a useful diagnostic. If your content does not show up in any of the planned sub-queries, you are not just losing the citation, you are losing the consideration set.
- Grok DeepSearch – An emerging real-time agentic pattern leaning on X data. The retrieval surface is fundamentally different in that it uses fresh social signals over a structured public corpus, but the loop architecture is the same.
- Microsoft Copilot Researcher and Analyst agents – Enterprise agentic RAG over SharePoint, Microsoft Graph, and the open web. The Researcher and Analyst pair is closer to a true multi-agent setup than the others on this list. Two specialized agents, each with their own tool stack, coordinating on a single research goal.
Here is the comparison across the eight major platforms. Iteration depth is rated on a five-point scale from minimal (single-pass with light reranking) to deep (10+ sub-queries with multiple critic loops). Visibility ratings reflect what is exposed in the user-facing UI as of mid-2026.
Platform | Planner visibility | Router strategy | Iteration depth | Reflection visibility | Citation surfacing |
Google AI Mode | Partial (expansion view shows some sub-queries) | Internal Search index + structured data tools + Knowledge Graph | Deep (5–20 sub-queries) | Hidden (pairwise rerank + critic both internal) | Inline links, often per-claim |
Google AI Overviews | Hidden | Search index, lighter than AI Mode | Medium (3–8 sub-queries) | Hidden | Inline links, less granular |
ChatGPT Search | Hidden | Bing index + first-party tools | Medium | Hidden | Inline links, sometimes a sources panel |
ChatGPT Deep Research | Fully exposed (live plan + sub-queries + reasoning) | Bing index + browse + code interpreter | Deep (often 20+ sub-queries) | Partially exposed (you see the agent reflect mid-task) | Numbered references with full source list |
Perplexity Pro Search | Partial (sub-question list rendered) | Multi-source web + structured tools | Medium-to-deep | Hidden but generous on sourcing | Inline numbered links, full source panel |
Perplexity Deep Research | Fully exposed | Multi-source web + browse + structured tools | Deep | Partially exposed | Inline + comprehensive source panel |
Claude (Computer Use, Projects, Skills) | Hidden | Tool use as first-class primitive (search, code, browse, MCP) | Variable, can be very deep | Hidden | Inline citations when tools return them |
Gemini Deep Research | Fully exposed (research plan rendered before execution) | Google Search + structured tools | Deep | Partially exposed | Inline + structured source list |
Grok DeepSearch | Partial | X data + open web | Medium | Hidden | Inline links, X-weighted |
Microsoft Copilot Researcher / Analyst | Partial (multi-agent traces in some surfaces) | SharePoint + Microsoft Graph + open web | Deep | Partially exposed | Inline citations, enterprise-doc weighted |
The honest summary: every major AI search system is now agentic. The differences are about which gatekeepers they expose and which ones they hide. None of them expose all five. The Deep Research surfaces — across ChatGPT, Gemini, and Perplexity Pro — are the most useful diagnostics you have for studying agentic-RAG behavior in production, because they show the planner and partial reflection in the UI. The non-Deep surfaces are what most users actually run, and those hide nearly everything.
What this changes for Relevance Engineering
You know I’m not going to leave you without anything actionable. Here are the six concrete shifts that follow from everything above.
- You have to win across many sub-retrievals, not one. A single “good ranking” page is no longer enough. Agentic systems decompose your topic into five to twenty sub-queries and retrieve against each one independently. Coverage breadth and topical depth are not nice-to-haves anymore, they are structural requirements. Pages that exist as standalone pillars without depth in the surrounding subtopic graph get cited once, maybe, and then dropped from the consideration set on the next sub-query. Pages that anchor a dense, well-linked topical neighborhood get cited five times in the same answer.
- Atomic, scoped passages beat monolithic articles and now they have to win pairwise. Each agent sub-query retrieves chunks, not pages. Then those chunks get pairwise-ranked against competing chunks from competing sources, by an LLM that reads both. The line I used in the AI Mode piece holds: your passages have to survive pairwise scrutiny. That means you need self-contained logic, named entities up front, explicit scope conditions (“for businesses with under 500 employees”). You also need evidence density, tables, and lists that an LLM can quote without ambiguity. Anything that requires a human to scroll up two paragraphs for context will lose pairwise to a passage that does not.
- Bridge entities determine multi-hop inclusion. When the agent’s first retrieval lands on Entity A, the second retrieval is about A’s relationships. If your content is the canonical bridge between A and B, you get cited in answers where the user never typed your brand. This is the most underexploited GEO surface in the industry today. I’ll talk more about it in another article.

- Reflection cycles reward source diversity and contradiction-handling. When the critic grades the draft, it looks for corroboration and contradiction. Content that explicitly addresses counterarguments, edge cases, and “when this doesn’t apply” survives reflection passes that strip out one-sided sources. Salesy content with no acknowledgment of failure modes is a tell to the critic that the source is biased, and biased sources get filtered.
- Tool-callable content is a new content type. Calculators. Structured-data endpoints. APIs. Comparison engines. When a tool exists, the router calls the tool instead of citing prose. If you are in a domain where a tool is more useful than an article like mortgage rates, drug interactions, tax brackets, product specs, ETF performance, fund characteristics, you should build the tool and expose it through an MCP server, an API, and structured data. The brands that ignore this and keep writing 2,500-word “ultimate guide” articles will be replaced in the answer by a function call.
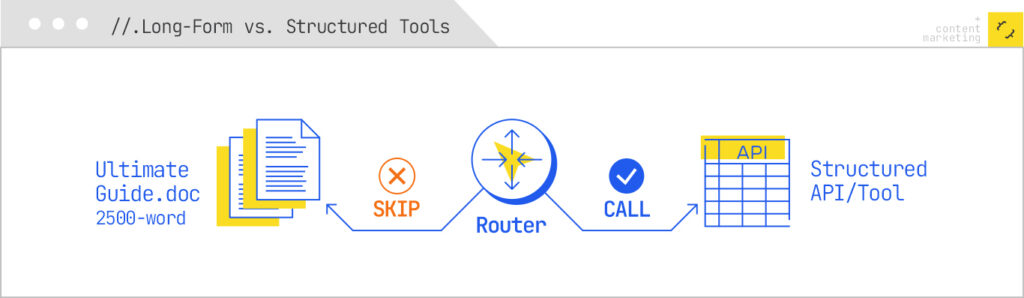
- Freshness is a reflection-stage gate. The critic checks freshness explicitly. dateModified in your schema. Version numbers in body copy. Explicit “as of [date]” framing in the prose. None of this is cosmetic. All of it directly affects whether your content survives the reflection pass when the agent is grading source quality. Stale content gets dropped at the critic, even if it won the pairwise re-rank, because the critic decides it cannot trust it.
The unifying point under all six: classic SEO content engineering optimized for one moment of judgment — the SERP. Agentic RAG content engineering has to win at five different moments for every subquery in the fan-out: planner, router, retrieval, pairwise, critic. That is roughly an order of magnitude more surface area, and the brands that build for it will see citation gravity that compounds.
The opacity problem — and why distillation is the smart way forward
Here is the part nobody else is willing to write yet, because saying it out loud has uncomfortable implications for the entire GEO measurement category.
In single-shot RAG, you could at least observe inputs and outputs. Your page either showed up in the retrieval set or it didn’t. You could reverse-engineer the retriever by sampling enough queries. You could correlate content changes with citation changes. The system was a black box, but it was a black box with measurable inputs and measurable outputs.
In agentic RAG, every gatekeeper between the user query and the final answer is opaque.
You don’t know which sub-queries the planner generated. You don’t know which tool the router picked for each sub-query. You don’t know which corpus was searched, which passages were returned, or which competitor passages your content lost to in the pairwise re-rank. You don’t know what the critic flagged. You don’t know which sources the critic dropped before synthesis. You only know whether you ended up in the final answer.
The implication is uncomfortable. Traditional reverse-engineering — “rank checking,” “citation tracking,” even prompt-by-prompt sampling at scale only sees the final stage. Every citation tracker watches what shows up in the published answer. They are all measuring the survivors of a five-stage filter without observing the filter. You are optimizing against a black box behind a black box behind a black box.
The honest path forward is model distillation.
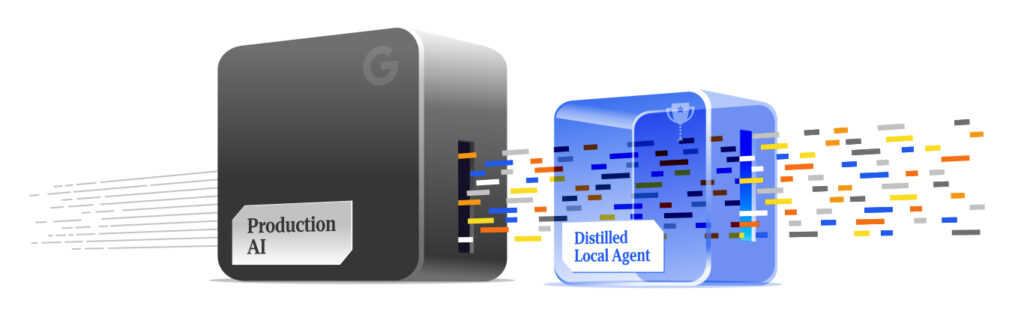
Distillation, in plain English: training a smaller, observable model to imitate the behavior of a larger, opaque one. You cannot see inside Google’s planner, but you can stand up your own planner-router-critic stack on inputs and observed outputs, calibrate it against the citations you actually see in production, and use that as the diagnostic harness. When your local agent’s planner generates ten sub-queries that closely match the visible Deep Research plan for the same prompt, you have a calibrated proxy for the upstream gatekeepers in production systems. The proxy is not the production system, but it is observable, and observable beats invisible.
What this looks like in practice for a GEO program:
Stand up a local reference agent on Google Gemma 4 — the 31B Dense variant for the planner and critic loops where reasoning fidelity matters, or the 26B A4B MoE variant when latency and cost dominate. Pair it with LangGraph or LlamaIndex for the agent framework, a hosted embedding model, and a small custom index over the open web for your topic. There is a thematic point worth making out loud here: Google ships the open-weights model that powers the local distillation harness used to reverse-engineer Google’s own production stack. That is not a coincidence. That is a category opening up that the smart agencies and software companies will own.
Feed the harness the prompts you care about ranking for. Observe its planner output. Log every sub-query the router generates. Capture the retrieval candidates at each stage. Score the pairwise comparisons. Read the critic’s notes. Where your local agent’s behavior matches the production system’s visible behavior like the Deep Research plan, the Perplexity sub-question list, the AI Mode expansion then you have a calibrated harness. Where it diverges, you have a calibration target. When your content fails to make it past the router or the critic in your distilled local agent, that is a strong signal it is failing in production.
This is preferable to the current dominant playbook of “spam more prompts at ChatGPT and count citations” for one reason: distillation gives you a causal story for why content fails at each stage. Citation counting only gives you a correlational story for what survived. When a client asks “why are we losing to Competitor X in AI Mode,” the answer “your passages keep losing pairwise comparisons in the calculator-ratio sub-query” is defensible. The answer “our citation count went down 12 percent this month” is not.
The candid caveat: distillation is not free. It requires engineering investment, an evaluation harness, and continuous calibration against production-system behavior. The agencies and in-house GEO teams that build this capability now will have a measurement moat that compounds. The ones that wait will be running the same dashboard their competitors are running and wondering why their reports cannot answer the questions executives are asking.
You cannot optimize what you cannot observe. Reverse-engineering the production black box is a dead end. Distilling your own version of it is the only path to durable GEO performance.
What this changes for measurement
The measurement category is going to fragment, and the brands that pick the right side of the fragmentation will have a significant advantage for the next two years.
Citation counts under-report your real footprint by a factor of three to ten in agentic systems. If you appear in four of twelve sub-retrievals but get cited once in the final answer, classic citation tracking misses 75 percent of your actual impact. Worse, it misses the why. You can have a citation rate that looks healthy and a sub-query coverage rate that is collapsing, and a year from now the collapse shows up in citations and you have no warning.
The new metric layer needs:
- Sub-query coverage — what percentage of the agent’s planned fan-out includes at least one of your sources.
- Retrieval-to-citation ratio — for sub-queries where your content is in the retrieval set, how often does it survive to citation.
- Reflection survival rate — for content that makes the synthesis pool, how often does the critic drop it.
- Bridge-entity centrality — whether your content is positioned as the canonical link between key entities in your topical graph.
- Tool-call inclusion — whether the router is calling your endpoints when a tool fits the sub-query.
- Distillation stage-failure rate — from the local agent, where in the loop your content most often gets dropped.

Existing tools watch the survivors of a five-stage filter. The next generation of GEO measurement infrastructure will sit underneath them and watch the filter itself, partly through the visible UI of Deep Research and AI Mode, and partly through a distilled local agent that fills in everything the production systems hide.
A reproducible test you can run this week
You know I always want to leave you with something actionable. So, I’ve got two things you can do to make improvements on your AI Search performance. The first requires no engineering. The second is engineering-light, single-engineer effort.
Part A — The Observable Agentic RAG Audit.
The first one is a workbook for you to collect data and see how you are being interpreted by agentic RAG systems. Here are the steps:
- Pick five high-value queries. Pick the ones where citation actually moves your business. The queries your sales team wishes you ranked for, the queries that drive demos, the queries that show up in customer support tickets. I understand that these are difficult to measure, so use your traditional search queries as a proxy if you need to.
- Run each query through ChatGPT Deep Research, Gemini Deep Research, and Perplexity Pro with research mode enabled.
- Capture the visible research plan for each. Deep Research and Perplexity show this directly; AI Mode partially exposes it through the expansion view.
- Log every sub-query the agent issues. Save them in a spreadsheet, one row per sub-query, three columns for the three platforms.
- For each sub-query, run it as a standalone search and check whether your content appears in the top retrieval set. If yes, mark hit. If no, mark miss.
- Compare your sub-query coverage to your final-citation rate on the original five queries. The gap is your reflection-loss problem or the places where your content makes it into retrieval and then loses pairwise or fails the critic.
- For every sub-query you miss entirely, classify why: no content on the topic, content too broad, poor chunking, missing schema, missing tool surface, freshness gap. The classification is the input to your content roadmap for the next quarter.
This will give you a sense of where you’re falling out of the pipeline and what improvements you need to make to your content.
Part B — The Distillation Audit.
This approach is more technical. Part A told you what the production agents publicly admitted. Part B tells you what they didn’t. The planner sub-queries you couldn’t read, the reranker verdicts you couldn’t see, the specific stage where your content fell out.
I built the harness so you wouldn’t have to: https://github.com/iPullRank-dev/agentic-rag-audit. It’s a local, observable version of the agentic-RAG loop the production systems run with the same five-node shape (planner, router, retriever, synthesizer with pairwise reranker, critic with reflection) on Google Gemma 4 via Ollama, with SerpAPI seeds, Scrapling fetching, Trafilatura extraction, and an opt-in LangExtract chunker. Strictly speaking it’s structural distillation, not model distillation. The point is diagnostic — observable end-to-end.
- Install. Python 3.10+, Ollama running on a workstation GPU (8GB+ VRAM is fine), a SerpAPI key, your brand domain.
<xmp> git clone https://github.com/ipullrank/agentic-rag-distillation.git
cd agentic-rag-distillation
pip install -r requirements.txt
ollama pull gemma4:e2b
cp .env.example .env # fill in SERPAPI_KEY and BRAND_DOMAIN
</xmp>
- Run the same five queries from Part A. One at a time:
<xmp> python -m examples.run_audit \
--query "your query here" \
--brand-domain "yourbrand.com" \
--trace-out traces/Q1.json
</xmp>
It’ll take roughly 90–120 seconds per query. You get eight diagnostic sections in your terminal — plan & routing, retrieval funnel, pairwise verdicts, brand journey, critic verdict, pipeline timing, final answer, citations — plus a trace JSON and a log file.
Here’s an example terminal output:

- Read the brand journey. This is the section you came for. For each of your URLs that was surfaced, it shows which sub-queries found it, what the chunker actually extracted, whether it made the reranker pool, the head-to-head verdicts that named it, and whether it ended up cited. When your content falls out, you see your URL’s actual opening passage side-by-side with the URLs that did make the pool with targeted recommendations based on the observable diff (opening sentence, query-term overlap, passage density).
- Roll up the metrics across the query set. After running all five Part A queries:
<xmp> python -m examples.view_program \
--trace-dir traces/ \
--brand-domain "yourbrand.com"
</xmp>
You’ll get six metrics: sub-query coverage, retrieval-to-citation ratio, reflection survival rate, tool-call inclusion, and stage-failure rate by stage. Here’s an example:

The stage-failure rate is what drives the content roadmap. Failing at retrieval is one kind of work — traditional SEO for the specific sub-queries the planner is generating. Failing at the reranker is another — passage-level content density and directness. Failing at synthesis selection is a third — unique-signal coverage. Each demands different work.
- Calibrate against Part A. Capture each production Deep Research plan as YAML (template at examples/production-template.yaml) and diff:
<xmp> python -m examples.compare_to_production \
--local traces/Q1.json \
--production traces/production/chatgpt-Q1.yaml
</xmp>
Where the two converge, you have a calibrated harness. Where they diverge sharply, your planner prompt or your seed-page provider needs work. Re-calibrate quarterly or after any major prompt change.
Note: The local agent isn’t the production system. Gemma 4 E2B is the smallest variant; reranker quality and critic decisions improve materially with E4B (one-line model swap in .env). The retriever depends on SerpAPI, so brand visibility upstream is still a hard prerequisite. Pairwise verdicts on small models are directional, not authoritative. You should read the actual reasoning in section 3 of each run to judge confidence.
What this gives you that Part A can’t: the specific stage where your content falls out, your URL’s actual extracted passage compared to the winners, the reranker’s stated reasoning when you lost a head-to-head, and the specific sub-queries your topic neighborhood doesn’t yet cover. That’s the diagnostic baseline you turn into a content roadmap.
Finally, as with any open source code I share, we likely have an internal version that is more robust. You should look at this as a starting point, build your own solutions on top, and share them back with the community.
Get the audit pack and let's talk
Classic SEO playbooks are obsolete. Single-shot RAG playbooks are obsolete. The brands that win in 2026 and beyond will run agentic-RAG-aware content engineering on top of distilled measurement infrastructure, and they will lock in citation gravity that compounds for years. The brands that don’t will spend the next two years arguing about why it’s just SEO and watching their citation count keeps going down.
Download the Part A Audit Sheet and, if you’re more technical clone (and contribute to) the Part B distillation starter repo. If you want to skip building the harness yourself and put a Relevance Engineering team to work on your brand, you know how to find us. And if you have not already, check out the AI Search Manual for the longer-form reference for much of what we’ve discussed in this article.
The retrieval-once playbook is over. The agentic loop is the new default. It’s time to build and analyze for it if we want to be serious about driving results.






