JavaScript is the foundation of most websites and web apps you see on the internet. It’s one of the core technologies of the World Wide Web that brings interactivity and dynamism to websites that are built on a static bedrock of HTML.
In fact, JavaScript is and has been the most popular programming language for several successive years now. Twitter, Facebook, Netflix — you name it, JavaScript is used everywhere, and very likely on your own (and clients’) websites too.
And so, understanding JavaScript SEO — a branch of technical SEO that comprises everything you can do to make a JS-heavy website easy to crawl and index, and ultimately rank well in search engines — is vital.
In this quick guide on JavaScript SEO, you’ll learn some actionable best practices to optimize your JavaScript for SEO. But first, let’s understand the impact of JavaScript on SEO and how Google deals with JavaScript.
How does JavaScript impact SEO?
While developers rely on and rave about popular JavaScript frameworks such as Node.js, Vue.js, AngularJS, Ember.js, and React to build highly interactive websites, the SEO folk don’t always share the same enthusiasm.
Why? Essentially because web pages that heavily incorporate JavaScript get indexed slowly (or partially). Developers often tend to overuse JavaScript for adding dynamic page elements where there are better alternative ways to go about it in terms of page load speed and overall performance. They may be trading performance for flashy functionality — which hurts SEO.
In other words, if there’s a lot of dynamic content (such as lazy-loaded images, product reviews, live chat, etc.), bloated theme code, and additional server requests, JS rendering can add seconds to the time it takes for the page to become interactive for visitors — which hurts UX and Core Web Vitals.
So ultimately, JavaScript is great but it can take a toll on your SEO and UX. There are more and more factors that add up to the overall cost of your website’s code, ranging from the CPU limitations on mobile devices lowering your CWV score to unoptimized JavaScript impacting your website’s indexing. Thus, you need to actively work on JavaScript SEO to ensure optimal site performance and indexing.
How does Google process JavaScript?
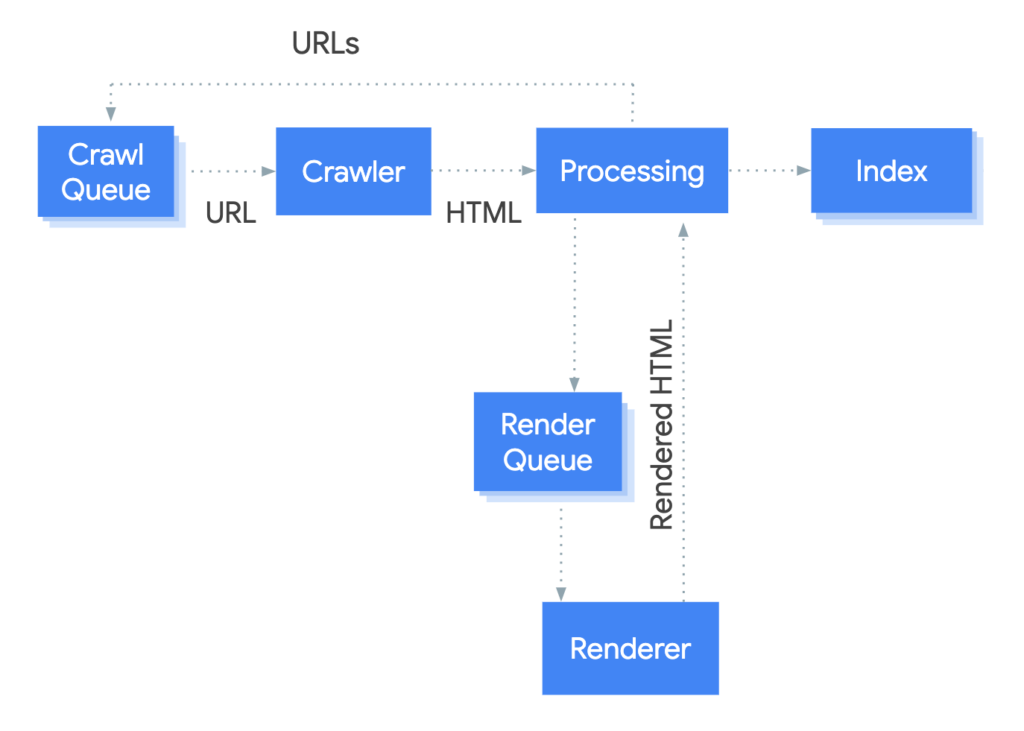
Googlebot processes JavaScript web pages in three phases: crawling, rendering, and indexing. Here’s a simple illustration of this complicated process.
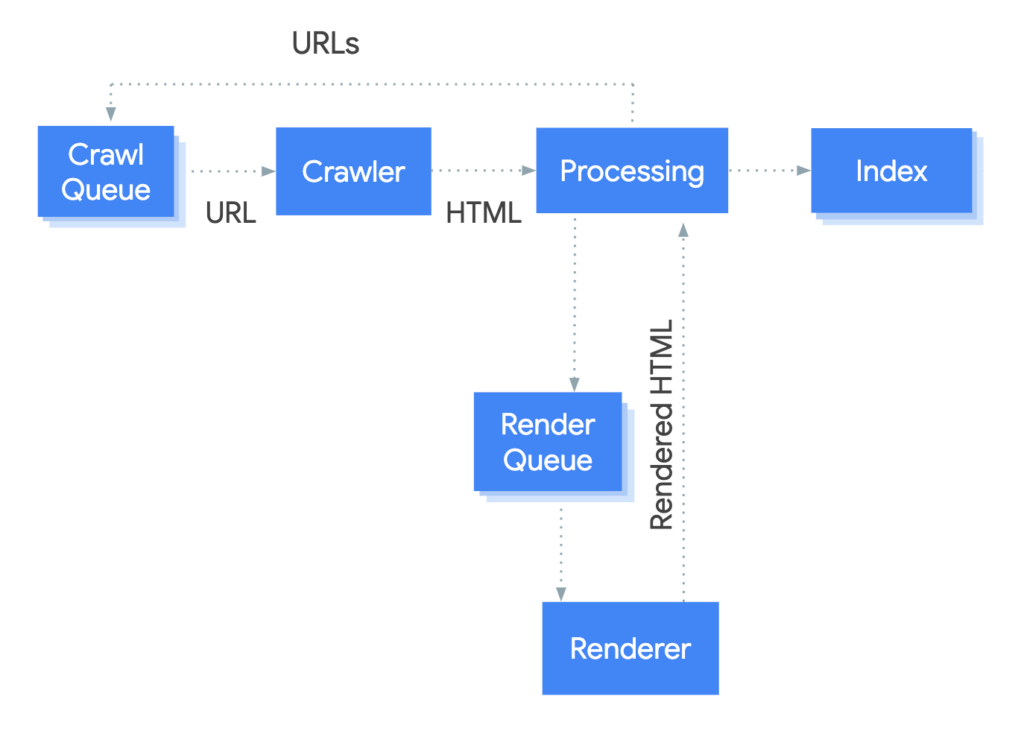
Let’s look into the three key phases in a little more detail.
JavaScript Crawling
Googlebot fetches a URL from the crawl queue by making an HTTP request. The first thing it checks is if you allow crawling in the robots.txt file.
If the file marks the URL as disallowed, then Googlebot skips the URL. It then parses the response for other URLs in the href attribute of HTML links and adds the allowed URLs to the crawl queue.
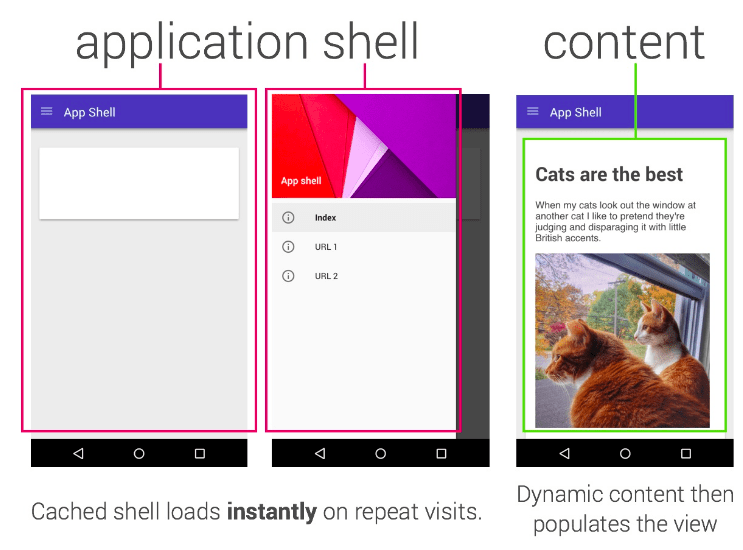
This process works well for server-side rendered pages where the HTML in the HTTP response contains all content. However, JavaScript websites may use the app shell model (see image below) where the initial HTML does not contain the main content and Googlebot has to execute JavaScript before it can see the actual page content that JavaScript generates.
This way, Googlebot crawls the URLs in its crawl queue, page by page.
JavaScript Rendering
Google decides what resources are required to render the main content of the page. In the illustration above, the renderer is where Google renders a page to see what a user sees.
Now, rendering JavaScript at scale is costlier. Huge computing power is required to download, parse, and execute JavaScript in bulk.
And so, Google may defer rendering JavaScript until later. Once Googlebot’s resources allow, a headless Chromium renders the page and executes the JavaScript. Then, Googlebot again parses the rendered HTML for links and queues the URLs it finds for crawling.
The system that handles Google’s rendering process is known as Web Rendering Service (WRS). When the WRS receives URLs, it renders them and sends the rendered HTML back for processing.
There are two types of rendering processes you should be familiar with.
Server-side rendering
Server-side rendering is when the rendering of pages happens on the server before they’re sent to the client (browser or crawler), rather than relying on the client to render them.
This rendering process happens in real-time wherein visitors and crawlers are treated the same. JavaScript code can still be used and is executed after the initial load. In fact, Google recommends server-side rendering as it makes your website faster for users and crawlers because every element is readily available in the initial HTML response.
However, it can be a complex implementation for developers, and the Time to First Byte (TTFB) could be slow because the server has to render web pages on the go.
Client-side rendering
Client-side rendering is the opposite of the above, wherein JavaScript is rendered by the client using the DOM. When the client has to execute the JavaScript, the computing issues outlined above become more prominent when Googlebot attempts to crawl, render, and index content.
So while client-side rendering is popular, search engine bots struggle with it and it’s not ideal for SEO.
A good alternative to server-side rendering and a viable solution for serving a site to users containing JavaScript content generated in the browser but a static version to Googlebot is to deploy dynamic rendering. It essentially means switching between client-side rendered and server-site rendered content for specific user agents.
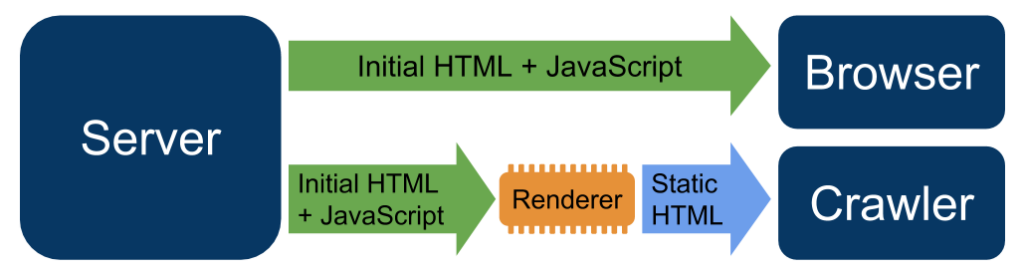
You can implement dynamic rendering by following Google’s guidelines and using tools such as Prerender, Puppeteer, and Rendertron.
Indexing
Finally, Google uses the rendered HTML to index the pages after JavaScript is executed.
Put simply, Google cannot index content until the JavaScript has been rendered, and things get quite complicated when it comes to crawling a JavaScript-based website.
While the delay between crawling and rendering has gone down with recent improvements in Googlebot, there is no guarantee that Google will execute the JavaScript code waiting in its WRS queue, due to reasons such as:
- Blocked in robots.txt
- Timeouts
- Errors
Thus, JavaScript can cause SEO issues when the main content relies on JavaScript but is not rendered by Google, which brings us to the next point…
Why is JavaScript SEO challenging?
While JavaScript isn’t evil for SEO, it clearly does pose some added challenges to achieving top rankings on SERPs. Here are some of the several common SEO pitfalls with JavaScript sites.
Unminified JavaScript and CSS files
As discussed earlier, JavaScript impacts your website’s performance and page load times — a crucial ranking factor for Google. Minification is the process of removing unnecessary lines, comments, and spaces in the page’s code (streamlining the code).
So for sites heavy on JavaScript, you also need to work on minifying the JavaScript (and CSS) code along with other things like deferring non-critical JS until after the main content is rendered in the DOM, inlining critical JS, and serving JS in smaller payloads.
Use of hash in the URLs
Many JavaScript frameworks such as Angular 1 generate URLs with a hash. Such URLs may not be crawled by Googlebot: example.com/#/js-seo/
When you want to make your content visible in search, it’s important to use the more static-looking URLs as Googlebot typically ignores URLs with hash when trying to index the content.
Not checking the internal link structure
Internal links help Googlebot crawl your website more efficiently and highlight the most important pages. A poor internal linking structure and format is always bad for SEO, especially for JavaScript-heavy websites.
Specifically, Google recommends interlinking pages using HTML anchor tags with href attributes instead of JS event handlers because Googlebot may be able to crawl JavaScript links.
How to optimize JavaScript for SEO
Let’s look at some actionable best practices on making your JavaScript site SEO-friendly.
1. Be persistent with your on-page SEO efforts
First things first, focus on the basics and get them right. Because no matter how heavy your JavaScript usage is, your on-page SEO efforts still play a key role in determining your rankings.
This includes things like:
- Unique titles and meta descriptions
- Descriptive alt attributes for images optimized for speed
- Correct URL and internal linking structure
- Keyword-optimized, well-structured, valuable content for visitors
Here’s a great actionable guide to on-page SEO from Ahrefs.
2. Avoid blocking search engines from accessing JS content
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
3. Use relevant HTTP status codes
Googlebot uses HTTP status codes to know if something went wrong when crawling the page.
As a general best practice, use the right status codes for your pages to avoid issues like soft 404. For example, to tell Googlebot if a page shouldn’t be crawled/indexed, use relevant codes, such as a 404 for a page that’s deleted, or a 401 code for pages that require authentication.
4. Fix lazy-loaded content and images
As you know, images can have a huge impact on page performance. To defer the loading of images for when the user scrolls to them below the fold, you can use lazy loading.
However, JavaScript can also affect the crawlability of images that are lazy-loaded. Googlebot supports lazy-loading, but it does not scroll as a human user would. Rather, Googlebot resizes its virtual viewport to be longer when crawling the page’s content. And so, the “scroll” event listener is never triggered and the lazy-loaded content isn’t rendered by the crawler.
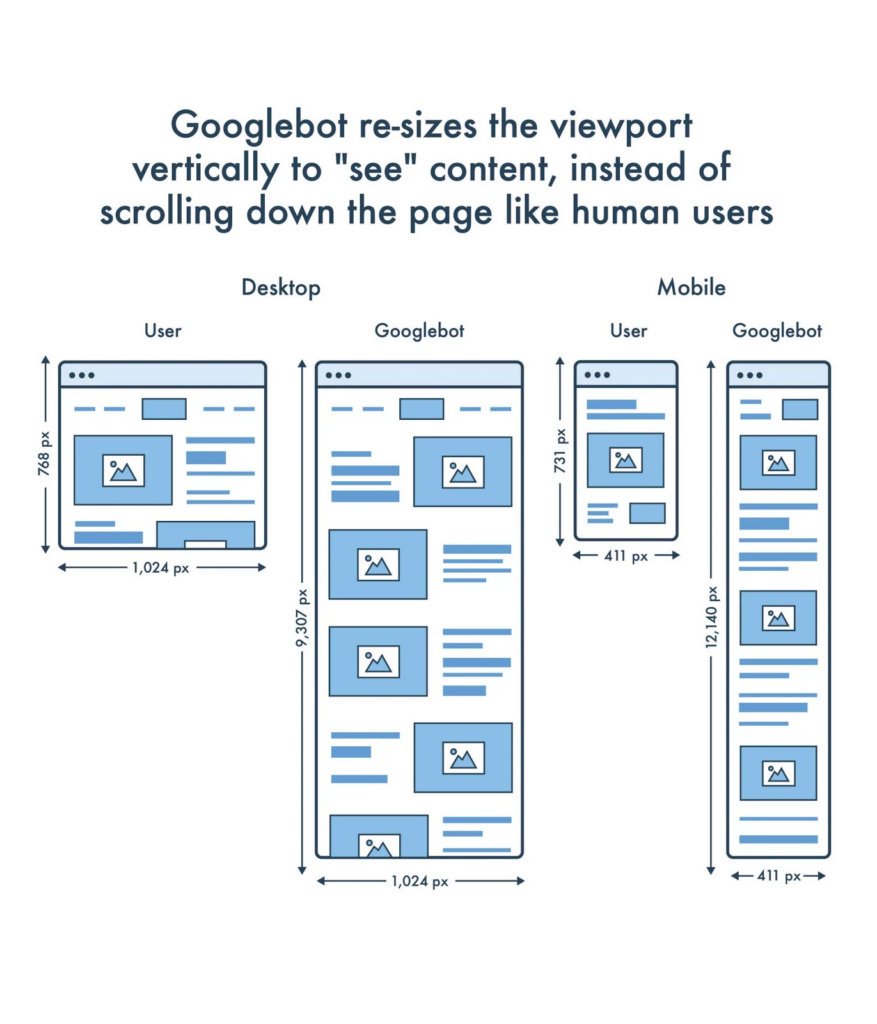
With the introduction of browser-level lazy-loading with the loading attribute, you don’t need to implement lazy-loading using JavaScript anymore. Chromium-powered browsers (Chrome, Edge, and Opera), as well as Firefox, now have native support for the loading attribute.
By lazy-loading content via the loading attribute, search engines can extract the image URLs directly from the HTML and visitors’ browsers know how to lazy-load the image.
5. Avoid soft 404 errors in single-page apps
In the case of client-side rendered and routed single-page applications, using relevant HTTP status codes may not be possible. To avoid soft 404 errors (wherein the server returns a 200 OK status to Googlebot for the invalid “404 not found” page) when using client-side rendering and routing, use one of the following strategies:
- Use a JavaScript redirect to a URL where the server sends a 404 HTTP status code.
- Add a noindex tag to error pages using JavaScript.
6. Use the History API instead of fragments
The History API lets you interact with the browser session history, trigger the browser navigation, and modify the address bar content. A modern JavaScript website or app that doesn’t use the History API, either explicitly or at the framework level, would have a bad user experience since the back and forward buttons break.
Now, Googlebot only considers URLs in the href attribute of HTML for crawling links. So, don’t use fragments to load different page content, rather, use the History API to implement routing between different views of your website. This ensures that link URLs are accessible to Googlebot for crawling.
You can use JavaScript to add meta robots tags to prevent Googlebot from indexing a page (“noindex”) or following links on the page (“nofollow”). When Googlebot encounters noindex in the robots meta tag before running JavaScript, it skips rendering the page and JavaScript execution. So, be careful in using the noindex tag if you do want the page to be indexed,
Also, speaking of robots, accidentally blocking JavaScript and CSS files in your robots.txt file will block Googlebot from crawling these resources and, consequently, rendering and indexing the content properly.
So, make sure to allow these files to be crawled by adding the following code in your robots.txt:
User-Agent: Googlebot
Allow: .js
Allow: .css
8. Use long-lived caching
Long live the cache! Essentially, caching is all about improving load speeds.
To minimize resource consumption and network requests, Googlebot caches CSS and JavaScript aggressively. However, WRS can ignore your cache headers which may lead it to use outdated JavaScript or CSS resources.
You can use file versioning or content fingerprinting (like main.2ba87581f.js) to generate new file names whenever code changes are made so that Googlebot downloads the updated version of the resource for rendering.
9. Use structured data
Using schema markup to display rich results for your products or content pages is a great way to improve your click-through rate and SERP real estate.
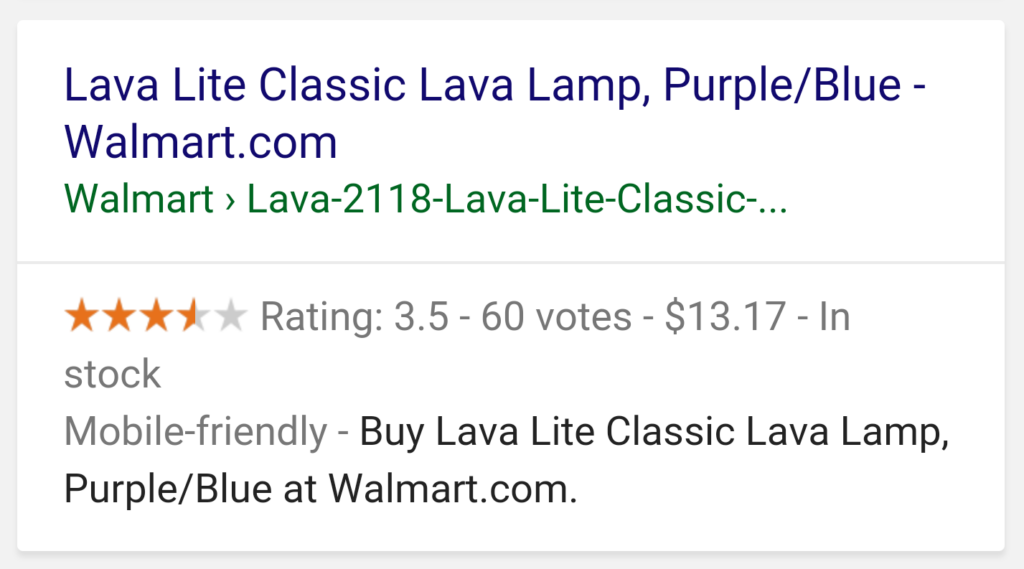
When using structured data on your pages, you can use JavaScript to generate the required JSON-LD and inject it into the page. For this, you can use Google Tag Manager or edit your website’s HTML to include a custom JavaScript snippet.
Either way, use Google’s Rich Results Test tool to test your structured data implementation.
10. Follow best practices for web components
Web components are a set of APIs that let you create custom, reusable, encapsulated HTML tags to use in web pages and apps. They are based on four core specifications: custom elements, shadow DOM, ES Modules, and HTML templates.
While Googlebot supports web components, when it renders a page, it flattens the shadow DOM and light DOM content and can only see content that’s visible in the rendered HTML.
To ensure Googlebot can still see your content after it’s rendered, use the Mobile-Friendly Test tool and review the rendered HTML. If the content isn’t visible in the rendered HTML, Googlebot can’t index it. In such cases, you can use the <slot> element.
11. Design for accessibility
Is your JavaScript website accessible to users with outdated browsers that don’t support JS and people who use screen readers or outdated mobile devices?
Ultimately, SEO is about satisfying users, and not everyone has a fast internet connection or the latest mobile devices.
To make sure your site is easily accessible to all users, test your website’s accessibility by previewing it in your browser with JS turned off. You can also use a text-only web browser like Lynx to identify rich media content that may be hard for Googlebot to render, such as text embedded in images.
12. Use JavaScript SEO tools
Besides the rendering tools (Prerender, Puppeteer, and Rendertron) and Google’s tools (Rich Results Test and Mobile-Friendly Test) mentioned above, there are a few other tools that can help you with your JavaScript SEO and debugging efforts.
You can analyze whether JavaScript content is indexed and what your rendered pages look like using Google Search Console’s URL Inspection Tool.
Know which fragments of your page depend on JavaScript and get a multifaceted look at how a page works without any JavaScript enabled using WWJD.
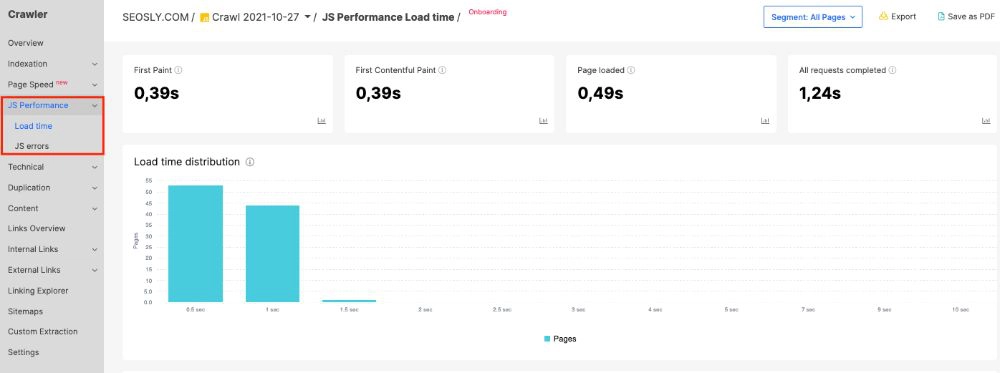
Last but not least, JetOctopus is a great tool to get comprehensive insights into your website’s JavaScript crawling and work on your overall technical SEO. It is an advanced crawler that can view and render JavaScript as Googlebot. In the JS Performance tab, you’ll find insights on JavaScript execution — such as First Paint, First Contentful Paint, and Page load — and the time needed to complete all JavaScript requests along with any JS errors.
Conclusion
Like it or not, JavaScript is here to stay. Your best bet is to understand the intricacies of JS in the context of SEO and adhere to the updated best practices shared by Google in their Google Search Essentials.
Even as Google gets better at indexing JavaScript, you must keep building up your knowledge, use the tools and tips described above, and work with your developers to minimize potential problems in your website’s crawling and indexing.
Next Steps
Here are 3 ways iPullRank can help you combine SEO and content to earn visibility for your business and drive revenue:
- Schedule a 30-Minute Strategy Session: Share your biggest SEO and content challenges so we can put together a custom discovery deck after looking through your digital presence. No one-size-fits-all solutions, only tailored advice to grow your business. Schedule your session now.
- Mitigate SGE’s Potential Impact: How prepared is your SEO strategy for Google’s Search Generative Experience? Get ahead of potential threats and ensure your site remains competitive with our comprehensive SGE Threat Report. Get your report.
- Enhance Your Content Relevancy with Orbitwise: Not sure if your content is mathematically relevant? Use Orbitwise to test and improve your content’s relevancy, ensuring it ranks for your targeted keywords. Test your content today.
Want more? Visit our Resources Page for access to past webinars, exclusive guides, and insightful blogs crafted by our team of experts. Everything you need to keep your business ahead of the curve is right at your fingertips.
Take the next step with iPullRank.







{kind=link}
{kind=link}
{kind=link}