
LLM-based engines (like Google’s AI Mode, AI Overviews, Perplexity, ChatGPT) now expand queries into dozens of sub-questions, retrieve at the passage level, and assemble answers that are grounded in entities, not keywords. This makes entities and semantic optimizations of content, site, and systems ever more important for achieving better visibility in AI Search systems. Content that’s easy to disambiguate, link, and reuse will earn visibility. You need clearly named entities with stable IDs, concise facts, and unique information gain.
This guide explains how entity recognition (NER), entity linking (EL), and knowledge graphs work together in modern AI search. You’ll get a compact glossary, a process view of how generative search pipelines actually run (from query fan-out to grounded synthesis), and a marketer-friendly playbook for making your content eligible and useful in those reasoning chains. I’ll also touch upon how to operationalize entity-driven optimisation for AI and traditional search, from development to governance to measurement.
The Glossary - Entities, NER vs. Entity Linking, and Role of Knowledge Graphs
Entities are things that exist in the world: concepts, objects, people, locations, organizations, events, and such. Entities exist independently of keywords (or otherwise – the terms that are used to describe them). Unlike keywords, which are specific words or phrases with SEO value, entities reflect recognisable, existing, real-world “things”. For example, “Nike” is an Organization entity, and “Air Force One” is a Product entity, whereas “shop online Nike Jordan Air Force one” is a search query (keyword) with transactional intent.
Each entity has defining properties – attributes, and each attribute can have different variables. For example:
- For the entity ‘Influencer’, an attribute could be ‘Location’ with variables like ‘London’, ‘Paris’, ‘Barcelona’.
- For the entity ‘dog food’, an attribute would be ‘food type’ with variables like ‘kibble’ or ‘canned’
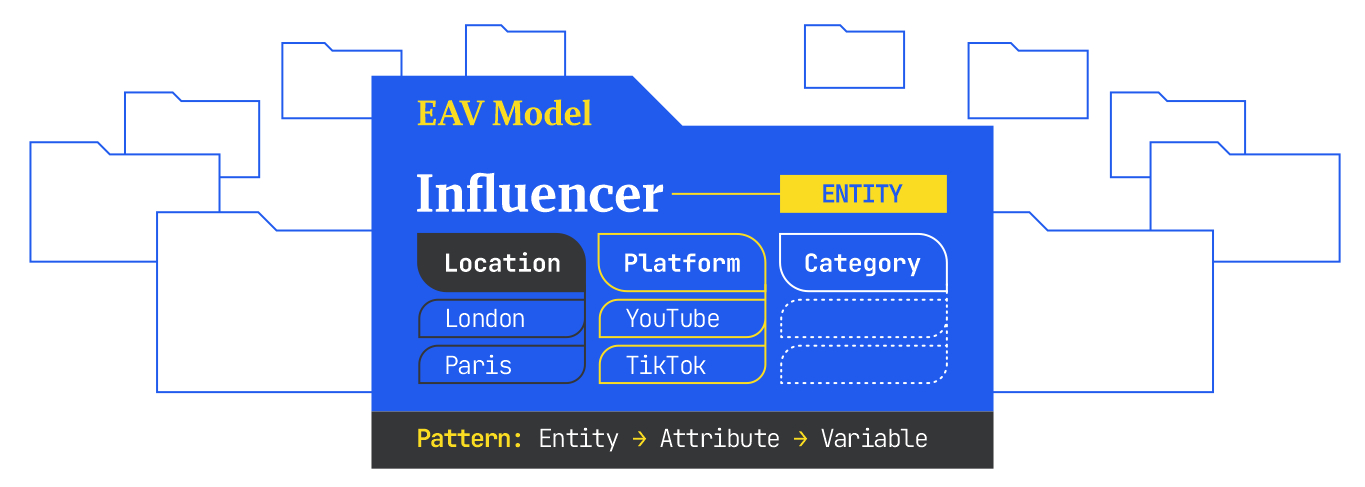
Entities, together with their attributes and variables, are referred to as the EAV model, which is crucial for detailing specific aspects of an entity that users might search for, and often forms the backbone of scalable content strategies like programmatic SEO.
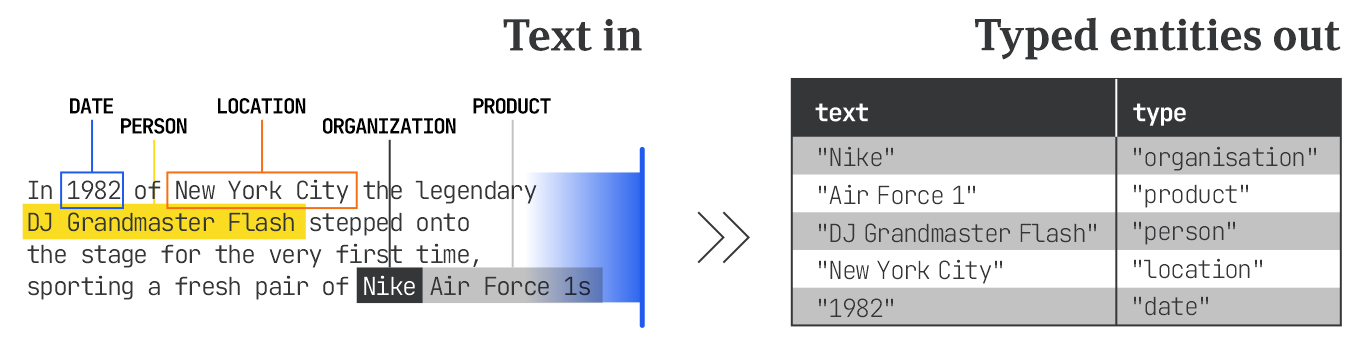
Named Entity Recognition (NER) is the process of extracting named entities from unstructured text. The text is scanned and the software labels terms that align with its database of entities, with broad types like Person, Organization, Product, Location, Date, and so on. Entity recognition as a process turns unstructured copy into structured fragments a program can reason about.
Entity Linking (EL) is the second step in the process, where each entity mention is mapped to a canonical entity ID in the entity recognition model’s knowledge base – think a Wikidata Q-ID (Q312 for Apple Inc.) or a Google Knowledge Graph MID. Entity linking resolves ambiguity (‘Jordan’ the person vs. the country vs. the product), merges synonyms and spelling variants, and ties your content to a shared web of facts. It also enables discovery of approximate (closely-related) entities based on shared entity attributes or variants, or semantic proximity (semantic similarity), derived from contextual embeddings.
The role of canonical entity identifiers is vital for anchoring terms to concepts:
- They help to deduplicate synonyms, aliases, misspellings, or different expressions for the same entity – e.g. ‘NYC,’ ‘New York,’ and ‘New York City’ collapse to one thing.
- They enable disambiguation of entities in different languages – i.e. a single canonical ID would represent one entity, regardless whether it’s mentioned in a text in English, Spanish, or Chinese
- They enable better entity tracking by allowing counts of all mentions, not just exact matches (like in traditional keyword tracking). This can power several SEO visibility shifts like counting entity share of voice based on keyword visibility, or entity sentiment analysis (e.g. how different facets of your brand or product, like customer service or price, are perceived, as opposed to simply analysing and reporting overall review sentiment from customer reviews)
- They can help AI search systems interpret your site. When pages consistently link entities to public IDs (for example, schema.org sameAs/@id, organization identifiers, Wikidata, or product GTIN/MPN), search and LLM features can disambiguate your brand and products, consolidate related pages, and more reliably attribute aspect-level sentiment (e.g., ‘price’ vs. ‘support’). This can improve the likelihood that an LLM summarizes your content accurately, that AI features surface the appropriate page, and that your brand appears consistently across queries and languages—though inclusion or ranking is never guaranteed.
Search experiences powered by LLMs, like Google’s AI Mode, Perplexity or ChatGPT, are designed to understand real-world entities (‘things, not strings’). AI search systems need trustworthy places to validate the entities they identify. Several sources might be used, including:
- Public graphs like Wikidata, Freebase, and DBpedia cover a broad set of concepts.
- Proprietary knowledge graphs maintained by search engines fill gaps and add freshness.
- Vertical taxonomies bring depth in specialized domains, for example, ICD and SNOMED for health, GS1 and product catalogs for commerce, GeoNames for places, and OpenAlex for research.
Under the hood, these systems also use embeddings (vector representations of words/entities) to score how likely a mention matches a candidate, based on the surrounding context provided in the text. Many production NLP APIs (Google Cloud NLP API or Amazon Comprehend) return this type of metadata out of the box (e.g. a Wikipedia URL or Knowledge Graph identifier). This, along with many other reasons, is why you might prefer going with a production-grade, task-specific entity recognition API, as opposed to trying to scale NER within your SEO workflow with an LLM.
How generative AI search engines work (Process Explained)
At a high level, each generative AI search system intakes a query, rewrites or chunks it to improve comprehension and retrieval accuracy, then retrieves information, reranks results with entity awareness, synthesizes a draft with an LLM, and returns a cited, safety-checked answer.
AI Mode Process Deep-dive
- Query Reception and Context Retrieval The process begins with receiving a user’s query, which can be typed, spoken, image-based, or multimodal. The input is processed, based on type, including ML models applied to convert non-text input (e.g. images) to machine-readable formats (e.g. for images – captioning, object detection, or semantically rich embeddings)
- User State Retrieval The system immediately retrieves and aggregates contextual information about the user and their device, forming a “user state”. This includes prior queries, data from previous search result pages (SRPs) and documents (SRDs), contextual user signals (including synced schedules, activity, location, and active applications), as well as stored user attributes and preferences (e.g. dietary restrictions, media preferences). This user state is continuously updated and can be stored as an aggregate embedding.
- Semantic Fingerprinting (User Embeddings): This contextual information is converted into semantically-rich embeddings that represent the user’s “semantic fingerprint”. This allows for modular personalization, meaning two users asking the same query may receive different answers based on their individual profile alignment and semantic relevance
- Synthetic Query Generation (Query Fan-out) Leveraging Large Language Models (LLMs), the system expands the initial query into a multitude of synthetic queries. This query fan-out mechanism allows the search engine to research deeper into content beyond the literal terms of the original query. Some of these might be:
- Alternative formulations: Synthetic queries like follow-up questions, rewritten versions, and “drill-down” queries, created in real-time based on the original query and contextual information.
- Entity-based Reformulations: LLMs crosswalk entity references to broader or narrower equivalents using Knowledge Graph anchors. For example, “SUV” could be expanded to specific models like “Model Y” or “Volkswagen ID.4”. This directly incorporates the role of entities and knowledge graphs in enriching query understanding.
- Intent Diversity and Lexical Variation: The prompt-based query generation emphasizes intent diversity (e.g., comparative, exploratory), lexical variation (synonyms, paraphrasing), and entity-based reformulations.
- Deep Search: Google’s “Deep Search” capability can issue hundreds of these synthetic queries and reason across disparate sources to generate expert-level summaries.
- Document Selection and Custom Corpus Creation The generated synthetic queries are then used by the search system to retrieve relevant documents. The selection of these documents forms a custom corpus, which is responsive to both the original query and the expanded synthetic queries. Ranking for inclusion in generative answers increasingly depends on language model reasoning, rather than solely on static scoring functions like TF-IDF or BM25. Dual encoder models may be used for efficient document retrieval.
- Query Classification and Downstream LLM Selection The system processes the combined data (query, context, synthetic queries, selected documents) to classify the query into specific categories. Examples of these categories include: “needs creative text generation,” “needs creative media generation,” “can benefit from ambient generative summarization,” “can benefit from SRP summarization,” “would benefit from suggested next step query,” “needs clarification,” or “do not interfere”. This entity detection or classification helps stabilize the meaning of ambiguous terms, for example, distinguishing “Jordan sneakers” from “travel Jordan” by recognizing the entity type.
- LLM Orchestration: Based on this classification, specialized “downstream LLMs” are orchestrated by the system for processing, each trained for a particular response type (e.g., a creative text LLM, an ambient generative summarization LLM, a clarification LLM).
- Multi-Stage LLM Processing and Synthesis (Reasoning) Once the custom corpus is assembled, the selected downstream LLMs process the data and generate the final natural language (NL) response
- Reasoning Chains: AI Mode leverages “reasoning chains,” which are structured sequences of intermediate inferences connecting user queries to responses logically. Content needs to be granularly useful and align with each logical inference to be selected for these reasoning steps.
- Grounded Generation: The generation process involves extracting chunks from relevant documents, building structured representations, and synthesizing a coherent answer62. This process includes grounding, recitation, and attribute checking from the source documents themselves to improve factuality and keep names, specs, and relationships straight.
- Multimodal Output: Responses can be multimodal, drawing from text, video, audio, imagery, and dynamic visualizations. The system can transcribe videos, extract claims from podcasts, interpret diagrams, and remix them into new outputs like lists or visual presentations.
- Personalised Summarisation: The NL-based summary is more likely to resonate with the user and omit content they are already familiar with, based on their user state.
- Source Citation and Linkification To ensure accuracy and transparency, relevant portions of the AI-generated natural language summaries are linkified to their source documents. The process of linkification involves comparing the semantic embeddings of the AI-generated text with those of potential source documents to verify verifiability and closeness of content, where sources are benchmarked and excluded from citing if not sufficiently close. Links can be made to sections (passages or sentences) or to entire documents.
- Personalized and Multimodal Output The final output, delivered at the client device, is highly personalized due to the continuous updating of the user state. Responses can be multimodal, including text, images, 3D models, animations, and audio. The system can even omit content the user is already familiar with to make the response more efficient.
Where Semantic Understanding Comes Into Play
In AI search systems, entities, Named Entity Recognition (NER), entity linking, and knowledge graphs play a crucial role in transforming traditional keyword-based retrieval into a more advanced, context-aware, and generative experience.
Stage | Role of Entity Identification | Role of NER (parsing and intent) | Role of Knowledge Graphs (KG) | Role of Entity linking (canonical IDs) | Outputs/artifacts |
Understanding and Expanding Queries | Detect entities in the user query. | Identify topics/subjects/aspects and form a query/context embedding (‘current context vector’). | Use entity relationships and topical proximity to drive query fan-out and generate synthetic queries (leveraging prior/implied queries). | Crosswalk references to broader/narrower equivalents (e.g., ‘SUV’ → ‘Model Y’, ‘ID.4’); normalise synonyms/aliases. | Expanded query set; synthetic queries list; context embedding; initial entity slate (candidate IDs). |
Contextualisation and Personalisation | Recognise entities in signals (prior queries, location, device, behaviour). | Build a persistent user-state embedding; infer intent; suppress content already known. | Map user attributes/interests to nearby KG clusters for personalised expansion/boosting. | Tie user signals to stable IDs (home city, owned products) for consistent personalisation. | User-context embedding/profile; personalisation boosts/filters; optional known-content suppression list. |
Document Retrieval and Synthesis (RAG) | Find entity mentions in docs/passages to form a custom corpus. | Do passage-level matching; embed queries/subqueries/docs/passages; select passages that support reasoning steps; route to downstream LLMs by query class. | Bias retrieval with type constraints and KG proximity; ensure content is entity-rich/KG-aligned. | Normalise variant names so the same entity is retrieved despite surface differences. | Candidate corpus (dense+sparse); passage embeddings and scores; retrieval logs; LLM routing decision. |
Query Parsing and Intent Classification | Surface ambiguous entities (e.g., ‘Jordan’). | Resolve intent via entity typing (person/brand/country) to stabilise meaning early. | Provide type/ontology signals to guide vertical routing. | Commit the resolved mention to the correct canonical ID for downstream use. | Intent class/labels; entity-type tags; target entity ID; routing flags. |
Expansion and Disambiguation | – | Expand aspect terms where implied (features, product lines). | Use KG relations and IDs to broaden/narrow beyond literal wording. | Map synonyms/aliases/brand nicknames to one ID to avoid variant misses. | Expansion set (broader/narrower terms); canonicalisation map (surface → ID); narrowing constraints. |
Retrieval Constraints | Ensure target entity/type appears in candidates. | Filter out off-aspect passages. | Enforce hard/soft filters by entity type and specific IDs (e.g., GTIN/MPN/catalog IDs). | Admit only passages that resolve to the target ID; exclude the rest. | Eligibility mask over candidates; ID/type filter set; whitelist/blacklist by ID (where supported). |
In short, entities, NER, entity linking, and knowledge graphs are integral to AI search systems, allowing them to move beyond simple keyword matching to a sophisticated understanding of meaning, context, and user intent, ultimately delivering more accurate, comprehensive, and personalised results.
Query Reformulation Versus Decomposition
In some cases, instead of rewriting, queries can be decomposed instead. Query chunking is a planning step that decomposes a complex or multi-intent request into minimal, independently retrievable sub-queries, each tied to specific entities, aspects, or tasks. The output is a query plan (sub-queries, constraints, and how to aggregate the answers).
Chunking lets the system retrieve the right evidence for each part of a request and then compose a coherent final answer.
Scenario | Example | Sample chunk plan (sub-queries) | Entity / KG role |
Multi-intent query | ‘Compare Pixel 9 camera to iPhone 16 and suggest accessories for hiking.’ | (1) Retrieve Pixel 9 camera specs & reviews (2) Retrieve iPhone 16 camera specs & reviews (3) Synthesize side-by-side comparison (4) Retrieve hiking-use accessories for the chosen device(s) (5) Aggregate and rank. | Map device names to canonical IDs; align aspects (camera features) to attributes; expand ‘hiking accessories’ via KG relations (cases, straps, power banks). |
Compound task | ‘Summarize this paper and draft an email to the team.’ | (1) Ingest paper (2) Generate structured summary (3) Outline email (purpose, audience, next steps) (4) Draft email using summary (5) Insert references/links. | Link paper to identifiers (DOI, authors); keep entity names/titles consistent; surface key sections as entity-linked facts. |
Conversational refinements | User adds constraints over time (‘under $800,’ ‘near me,’ ‘available this week’). | (1) Start with base results (2) Apply price filter (3) Apply location/stock filter (4) Refresh ranking; repeat as constraints change. | Map constraints to entity attributes (price, location, availability); keep products tied to stable IDs across turns. |
Chunk boundaries often align with the EAV model (entities and their attributes and variables), so splitting by entity/aspect makes retrieval cleaner (each sub-query can require the correct ID/type) and synthesis more precise (aspect-level sentiment and citations stay attached to the right target). In pipeline terms, chunking sits after intake/rewriting, feeds hybrid retrieval, and improves entity-aware re-ranking and grounded LLM synthesis.
In the Gemini API, you can also specify chunk boundaries for semantic retrieval of the analysed text. iPullRank’s Relevance Doctor, on the other hand, allows for a more user-friendly alternative for marketers as it breaks your content (from a URL or pasted text) into passages and scores them for semantic similarity against your target terms. This allows you to see exactly which sections align with your intended target and which are off-topic.
Why entity recognition matters for AI search (or the really, really short 'GEO' manual, as it relates to entities)
Entity recognition (ER) is integral to AI Search: it stabilizes meaning in multimodal, stateful queries; guides query fan-out and chunking; shapes hybrid retrieval and pairwise re-ranking; constrains generation via entity types and attributes; selects citations by semantic match; enforces safety through entity-level policies; and powers results UX (cards/facets/next steps) while feeding analytics that monitor ambiguity and drift.
The more your pages expose clear, linked entities with stable identifiers, the easier it is for this pipeline to retrieve, rerank, and reuse your content. Entity-rich structure boosts disambiguation, improves eligibility in reranking, and gives the LLM grounded facts to quote with confidence.

Here’s the top-level list on what to do:
- Plan: Choose target entities; record canonical IDs.
- Create: Use exact names naturally; include common aliases.
- Disambiguate: Clarify which entity is in the first paragraph.
- Markup: Add schema.org with sameAs to IDs.
- Linking: Internally cluster by entity; cite authoritative sources.
- Assets: Use entity names in titles, H1s, alt text, and filenames.
- Validate: Run an NLP API to extract entities and compare to your targets.
- Maintain: Track mentions and sentiment; refresh pages to keep entity coverage consistent.
You should also check whether your important queries are grounded or not. Here’s a quick process to follow:
- Pull your top queries
- Run NER and entity linking to approximate entities
- Flag those that resolve to canonical IDs (e.g., Wikidata).
- Spot-check SERPs: knowledge panels, entity carousels, or AI overview ‘chips’ imply entity grounding. You can also automate this task for a bulk of your queries with Google’s own Gemini, Grounding with Google Search module or use a tool-based classifier like the OpenAI Grounding Classifier by Dan Petrovic, which tells you whether the response to a query you enter to an LLM will be grounded via external search or not.
- For unlinked queries, add missing aliases, clarify copy, and ensure schema links to the right IDs.
Hands-on: How to get started with entity recognition, entity linking, and knowledge graph exploration
Choose Your API and Project - Go Custom, Integrate Fully
To run an entity recognition process that’s scalable and consistent, and one that can be integrated into all of your SEO workflows – from keyword and content analysis to internal linking – you need a custom-trained task-specific API. Avoid using an LLM for entity analysis, and use a specialised NER API instead.
In repeated experiments I ran, task-specific cloud NLP APIs consistently returned more entities, richer metadata, and reproducible outputs than generative AI chatbots and LLMs. Google Cloud Natural Language (clear winner in total and unique entities) returns entity type, mentions, sentiment, and crucially metadata like Wikipedia URLs and Google Knowledge Graph IDs. AWS Comprehend performs solidly on entities and adds a dedicated Key Phrases module (often surfacing concepts Google catalogs as ‘Other’ entities). IBM Watson NLU contributes relationship graphs and emotion signals alongside entity sentiment. If you insist on using a chatbot, DeepSeek R1 fared best among LLMs tested, but variability and weaker structure remain. LLMs are simply poor fits for production entity pipelines.
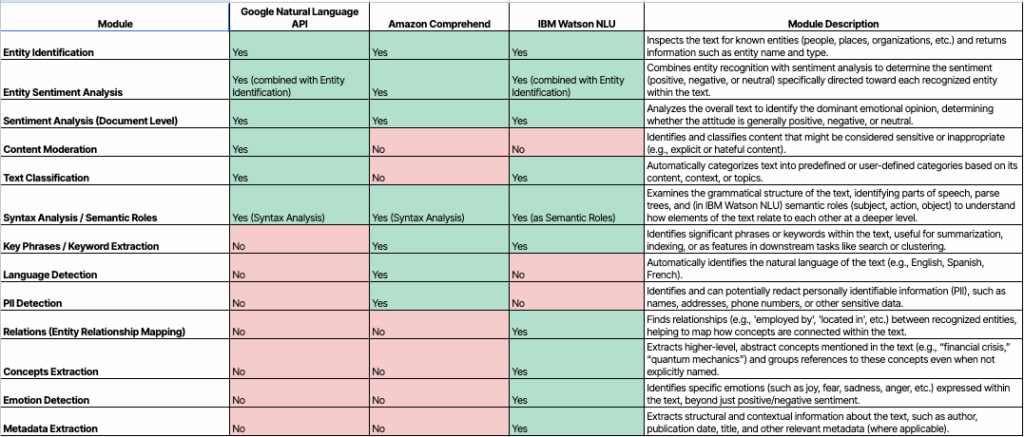
Image is part of the resource pack, shared with students from my Introduction to Machine Learning for SEO Course on the MLforSEO Academy in the Introduction to Entity Extraction and Semantic Analysis Module.
The next step is deciding what content to extract entities from – don’t just think blog posts. Almost any text your brand (or competitor) produces or earns can be mined for entities: product and category pages, help docs, your titles and headings, long-form articles, even YouTube transcripts of your competitors’ videos.
Go wider, too—keyword lists, internal-link inventories, competitor pages, reviews and support tickets, blog and forum comments, PR mentions, backlink anchor text. Think about every touchpoint with your audience. Your customers and potential customers are leaving texts left and right; text prime for entity extraction and mining of little golden nuggets of information.
Some NLP APIs will even let you submit a URL directly, so you can analyze live pages without scraping first. The goal is to map how your brand, products, people, places, and concepts actually appear across your footprint.
Choosing the right entity recognition API is part quality control, part fit. Test on your own pages and language mix. Based on my experiments, some services will treat concepts like ‘machine learning’ as entities, while others would file them under key phrases. Favor APIs that return confidence scores and behave consistently, as what you want are deterministic results that you can reproduce.
At scale, Google Cloud NLP is usually faster and cheaper than prompting a chatbot, and most of the aforementioned entity analysis APIs (AWS, Cloud NLP, Watson NLU) even offer free-tier trials.
At a minimum, make sure the output of your selected entity extraction API includes entity type, mention counts, sentiment, and—most importantly—stable IDs so you can track the same ‘thing’ across documents.
Here is a short summary on how to evaluate entity extraction APIs – look for:
- Coverage in your domain & languages
- Quality: precision/recall, linking accuracy, confidence scores
- Customization: the ability to add new entities, retrain or otherwise – fine-tune the model, ease of maintaining alias tables
- Cost, latency, and throughput
- Output format & stability of IDs
A practical starter workflow of integrating entities into your strategy might look like this:
- Run two complementary extractors (for example, Google Cloud for entities plus AWS for key phrases) to boost entity recall
- Reconcile everything to one canonical ID space (Wikidata is a good default)
- Store common aliases, then enrich with entity sentiment and mention counts to prioritize content updates.
- Keep LLMs for content transformation like writing summaries, title rewrites, Q&A but avoid for the core entity extraction.
Let’s briefly go over a few examples of practical tasks you can do today, on any piece of text content you’d like to extract entities from.
Before you begin:
- Create a Google Cloud account and Set up a Project with Billing enabled
- Enable Knowledge Graph Search API and Natural Language API: In the “APIs & Services” dashboard, search for the APIs name and enable it.
- Create API keys for both and store them safely: Go to “APIs & Services” > “Credentials”. Click “Create Credentials” > “API Key”.
Extract Entities from Content, Discover Related Entities, and Extract Knowledge Graph Information
This section is intentionally brief as everything you need to get started is in the Google Colab. There, you’ll find quick exercises with the Cloud Natural Language API and Knowledge Graph Search API that will enable you to:
- Find entities in your content – Run entity extraction with salience, sentiment score, and magnitude per entity.
- Link entities to the Google Knowledge Graph – Capture each entity’s mid (when available) and enrich it with name, description, types, official URL, image, and a Wikipedia snippet.
- Explore the Knowledge Graph by query or ID – Do a compact lookup or export a fully ‘flattened’ JSON view for deeper analysis.
- Discover related entities for keyword expansion – Given a seed keyword or a CSV of terms, pull the top related entities to broaden research, SEO, and taxonomy building.
MAKE A COPY OF THE CODE NOTEBOOK
To run:
- Paste your keys into the Configuration cell (one key per API; could be the same, if enabled on the same project).
- Upload content.csv with columns id and content.
- Run cells top-to-bottom. (Colab upload/download helpers are built in.)
Coding has never been simpler. What you do with the data is what matters. Let’s explore how these data points can be integrated into your SEO strategy to improve visibility in AI search systems.
The Relevance Engineering Playbook as it Relates to Entities and AI Search Systems
For SEOs and web content publishers, future-proofing strategies and improving content’s appearance in AI search fundamentally requires a shift towards Relevance Engineering, with entity mapping and integration being one of the key pillars for achieving this, but certainly not the only one (think personas, brand relevance mapping, scalable content systems, and organic growth levers, and a ton more, but that’s a topic for another day).
If Google is moving from query-matching to stateful, entity-aware journeys, then the job of SEO shifts from ranking pages to ensuring relevant entities and brand/service/product-important conversations are surfaced in chat, whenever relevant.
AI Mode will fan out a user’s question into dozens of sub-questions, then stitch an answer together at the passage level. The content that wins isn’t the page with the most keywords; it’s the page whose chunks carry clear, disambiguated entities and verifiable facts, plus content with unique viewpoints and the strongest information gain score for the user’s search query and their previous knowledge on the topic.
Entities — the people, products, places, and concepts your business touches — become the operating system for how you plan, publish, link, and measure content. As explained in depth in Chapter 14 of iPullRank’s AI Search Manual, entity attribution is one of the key ways to surface your content in generative search engines. Ensure the important and relevant entities for your audience are clearly linked to the Knowledge Graph and appropriately cited throughout your content (with sensible variations).
Below is a practical, team-friendly playbook for integrating entities into your strategy. You’ll see “Projects” sprinkled throughout – these are lightweight tools and processes a marketing/SEO team can run without heavy engineering. They’re examples of how to get the job done, not the only way.
Content Strategy
Engineer content with clearly named, knowledge-graph-aligned entities by:
- Producing Fan-Out Compatible Content: To align with the diverse subqueries generated by the query fan-out process, content must include clearly named entities that map to the Knowledge Graph. This involves explicitly identifying and defining key concepts, individuals, locations, and products relevant to your topic. Related queries often surface via entity relationships and taxonomies, so plan for those as part of your content strategy to capture broader intents.
- Leveraging Knowledge Graphs: AI Mode has different canvases, depending on the user context, journey stage, and query intent, but some, like Shopping or Deep Search, likely leverage Google’s Knowledge Graph, Shopping Graph, and other related ontologies. By defining entities and their relationships, you help Google’s AI disambiguate information and connect your content to its broader understanding of the world, and surface your brand wherever relevant to the user.
Different systems ground answers differently: Google links from AI Overviews; Bing’s Deep Search expands and disambiguates with GPT-4; Perplexity cites by default, and Pro Search shows its steps; ChatGPT adds sources in a sidebar.
Ensure your content is written in a semantically complete way at a passage level. LLMs pull passages, not pages. To make you content RAG-ready (retrieval-augmented generation), you can:
- Improve the content’s paragraph structure, where each paragraph begins with the entity’s canonical name and verifiable facts about it. Despite the importance of that opening line and entity reference, it does not guarantee ranking unless your content brings unique perspectives and angles into the conversation. This is measured by many mechanisms, one of which is the information gain score.
You can achieve this by reiterating important entity attributes whenever you’re discussing your core article entities, but also by integrating different content formats like tables or lists. Expanding the content sections with relevant information about your core entities, their attributes, and how they relate to your target personas will go a long way in AI Search discovery.
Behind the scenes, store those chunks with light metadata — the entity IDs, language, and a few key attributes. You’re not gaming anything; you’re making your own search (and any future agent) dramatically better at finding the right sentence when a fan-out sub-query hits.
- Create passages that are semantically complete in isolation by making atomic assertions, meaning it can answer or contextualise a specific subquery on its own, clearly defining the entities it discusses. This improves its retrievability and usefulness in AI’s reasoning processes, as LLMs currently retrieve and reason at the passage level, not just the entire page.
- Write clearly and be specific about what each passage is trying to achieve, especially when it comes to product comparisons, trade-offs (benefits and limitations to different user groups), definitions, and specs. Name your sources and avoid vague, unsupported claims.
Project: Entity Brief Generator (Content Planner)
- What it is: A one-page creative brief per entity that proposes headings, attributes to cover, FAQs, related entities to mention, internal links, and citation candidates.
- What you’ll see: For “AP-200 Air Purifier,” the brief recommends sections like Specs, Filters & Maintenance, AP-200 vs AP-300, Who It’s For/Not For, and a short claims table with sources.
- What to do with it: Give it to writers and designers as the starting point for a hub or spoke.
- Why it helps: Produces entity-first content that LLMs can confidently ground and reuse.
Example (content micro-pattern):
“AP-200 Air Purifier” — A compact HEPA-13 purifier designed for rooms up to 250 sq ft. Verified CADR: 160 CFM. Filter model: AP-F13 (6–8 months). Compared with AP-300 (larger rooms, higher CADR). Best for renters and home offices; not ideal for open-plan spaces. Sources: Test lab report (May 2025), internal QA log.
Technical and Structured Data
Use structured data to say, unambiguously, ‘this passage refers to this thing.’ This is the technical way of anchoring your brand’s ‘product narratives in specific, repeated, and semantically rich entities’, as Dixon Jones highlights in this beauty case study on AI Search visibility optimisation. The goal here being to show up comprehensively in model outputs.
Add schema markup that defines entities, their properties, and how they relate. Think in semantic triples (subject–predicate–object) so facts are reusable by search systems and agents.
Schema isn’t decorative. Use precise types (e.g., Product, Organization, Place, MedicalEntity, CreativeWork) and anchor them with persistent @ids. Keep a simple registry of who owns which JSON-LD block; run CI tests that fail the build on invalid markup or ID reuse.
A minimal pattern looks like this:
<xmp>{
"@context": "https://schema.org",
"@type": "Product",
"@id": "https://example.com/id/product/ap-200",
"name": "AP-200 Air Purifier",
"brand": { "@type": "Organization", "@id": "https://example.com/id/org/exampleco" },
"sameAs": ["https://www.wikidata.org/wiki/Q..."]
}</xmp>
Short, typed, and anchored to a stable @id. That’s enough for retrievers to align passages with a knowledge graph.
Pair JSON-LD with semantic HTML so LLMs can segment content reliably. Use structural elements (<article>, <section>, <header>, <main>), a clear heading hierarchy (one <h1> per page; <h2>/<h3> that mirror your outline), and data-friendly tags like <time datetime>, <data value>, <figure>/<figcaption>. Tables should include <thead>, <tbody>, and header scopes; comparisons and definitions belong in lists (<ol>/<ul> or <dl>/<dt>/<dd>). For media, use descriptive alt and file names that match the entity label and variant. All of this helps AI systems extract the right passage and attach it to the right thing.
Project: Schema.org Entity Auditor & sameAs Consistency Checker.
- What it is: A lightweight site-wide pass that verifies types, required fields, stable @ids, and approved sameAs links.
- What you’ll see: A friendly “fix list” by URL and an entity-type dashboard (e.g., Products: 94% valid; 0 ID conflicts).
- What to do with it: Treat critical failures as blockers before publishing.
- Why it helps: Clean, consistent entity markup makes your pages more groundable and “linkable” in LLM reasoning and entity cards.
Platforms that default to citations (Perplexity, Copilot Search, ChatGPT search) directly reward stable @ids, explicit claims, and linkable sources.
Entity Hubs and Internal Linking
Topical authority still matters, but in an AI context, it looks like entity hubs. Give each priority entity a hub that states what it is, how it compares, and where the numbers come from. Around the hub, build supports that mirror common reasoning steps like comparisons, troubleshooting, buyer’s guides, how-tos. This is not fundamentally different from the hub-and-spoke strategy, though the focus here should be on semantic discovery (as opposed to word-based) and alignment with brand-important personas.
Two simple rules keep clusters healthy:
- Link intentionally. The hub introduces the entity and routes readers (and crawlers) to the right spoke. Spokes acknowledge the hub as the source of truth. Use the canonical entity label in anchors for quiet but powerful disambiguation.
- Merge fast, duplicate slow. If two pages argue about the same ID, you’re introducing confusion and reason for the model to remove you from its reasoning chain. Same core principles of cannibalization avoidance from SEO apply to AI Search (or GEO), where if there exists intent cannibalisation, i.e. two pages competing for the same user intent, they should be merged.
Multimodal (Video, Audio, Social)
If AI experiences summarize across formats, keep the entity story consistent everywhere. Transcripts should name the same entities your articles do. Captions aren’t meaningless either, treat them as short, structured summaries with the right labels. For images and product shots, include the exact model or variant in the file name and align alt text with the hub’s ID. The same labels, repeated across text, audio, and visuals, become a durable signal.
LLMs consistently cite YouTube videos (it’s the third most-cited source, according to data from the Visual Capitalist) and other multimodal content, and even within the YouTube search and video pages, there are numerous featured snippets that pull entity data, when that is appropriately highlighted within the title, description, captions, transcripts and other elements – so, doing this would pay off not only in terms of search visibility but also in terms of in-platform discoverability.
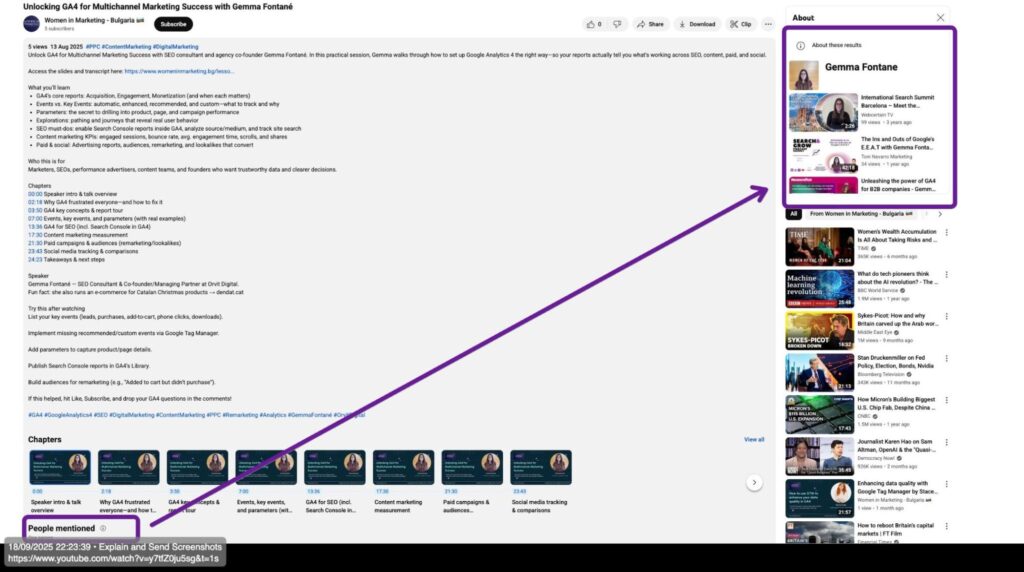
Google supports video-based questions in AI Overviews, while ChatGPT search adds category modules and linked sources, which is yet another reason to keep entity labels consistent across formats.
Mindset & Team Ops for Canonical Entity Management
Every strong entity strategy starts with an unglamorous spreadsheet. List the ‘things’ you care about—brands, models, categories, people, locations—and give each a permanent canonical ID (your own @id, plus authoritative sameAs where it exists). That ID never gets recycled, even if names change.
Aim for canonical entity governance.
- What it is: A lightweight system that gives every ‘thing’ a permanent @id, assigns shared ownership, and sets simple merge/split rules. This should include the invoice mentions, attributes, and all other relevant entity information you have in your content production pipeline (personas, comparisons, competitors, etc).
- Why you need it: It stops near-entities that fracture signals; engineering can ship JSON-LD with confidence; analytics can report performance by entity, not just URL. It also keeps hreflang and on-site search coherent across locales.
- How to run it: Name owners per cluster (Editorial, SEO, Engineering). Define when a variant becomes its own entity. Enforce ID permanence with a basic changelog of renames and merges. Automate the boring parts—alert on unknown entities in search logs, block releases on schema failures or ID reuse, and check sameAs links weekly.
- How to handle multilingual: Treat IDs like VINs: one per thing across locales. Translate labels and maintain an alias list, but don’t fork identities.
Project: Ambiguity Watchlist & Disambiguation Playbook.
- What it is: A weekly radar for terms that can map to multiple entities (brand vs product, place vs organization, etc.).
- What you’ll see: A short watchlist plus recommended fixes: disambiguation pages, glossary entries, copy tweaks, schema hints (about, knowsAbout, areaServed, geo).
- What to do with it: Prioritize by business impact; ship small fixes fast; track before/after CTR on affected queries.
- Why it helps: Reduces wrong matches in AI answers and improves click-through on ambiguous terms.
Relevance Engineering and Measurement
Relevance engineering is the work of helping content survive query fan-out and the reasoning steps agents take to answer questions. Move beyond keywords and tune for how models actually retrieve and compose answers.
Start by mapping the tasks your audience tries to complete. For each task, check whether your passages cover the sub-queries a model will generate (definitions, comparisons, trade-offs, steps, sources). Where you find gaps, add a short, verifiable passage rather than a long new page.
Make it operational:
- Build a passage index: chunks start with the canonical entity name and a few checkable facts, wired to a stable @id.
- Generate passage-level embeddings and test against synthetic fan-out queries to see where recall drops. Use our free tool Qforia for generating synthetic queries to test against.
- Simulate reasoning chains for common journeys (e.g., ‘Is X right for Y?’ → ‘What are the trade-offs?’ → ‘What do I do next?’). Patch the steps where your content falls out.
- Track results by behavioral persona (e.g., logged-in vs. logged-out, new vs. returning, pre- vs. post-purchase but also based on demographic and contextual signals, so personalization doesn’t hide blind spots.
- Decompose important claims into atomic assertions (triples) with sources and tie them back to the entity @id. That makes facts easier to reuse and verify.
If entities are your content OS, your performance measurement dashboards should use the same language. Start with three questions: Are we covering the right things? Is the markup safe to reuse? Is value accruing to the entities we care about?
Track success by surface: AI Overview inclusion and linked citations (Google), answer-box citations (Copilot/Brave/Perplexity), and source sidebar presence (ChatGPT search).
Keep the dashboard small and blunt by tracking by entity, not just URL.
Core metrics to add to your SEO performance tracking | |||
Metric | How to Track | Why Track it | Reporting Cadence |
Entity coverage | % of priority entities with a credible hub + ≥3 supporting pieces. | Proves you’re not thin where it matters. | Weekly |
Schema validity | CI pass rate for JSON-LD; count of ID conflicts (target: zero). | Proves machines can safely reuse your facts | On every release |
Performance by entity | impressions, CTR, conversions/assisted conversions grouped by entity. | Shows outcomes accrue to things, not pages. | Weekly |
Ambiguity rate | % of mentions with ≥2 plausible entities on a labeled sample. | Signals whether text disambiguates cleanly. | Weekly |
Agility | time-to-publish on emerging entities (detection to entity hub live to entity supports live). | Shows whether you can capitalize on new demand. | Monthly |
Don’t forget to keep track of emerging entities from your site search and user logs, AI tracking tools, and industry news, trends, and developments.
Project: GSC → Entity Coverage & Opportunity Finder.
- What it is: A simple way to connect your search demand to your entity canon.
- What you’ll see:
- A coverage score—what share of clicks ties to mapped entities.
- An opportunity list—high-impression entities with weak or missing hubs/schema.
- Suggested actions—new/expanded hub, internal links, required schema fields.
- What to do with it: Turn insights into tickets; fix the highest-impact gaps first.
- Why it helps: Directly reveals where entity work will lift visibility in AI overviews and answer engines.
Project: Entity-Grounded Prompt & Snippet Sandbox.
- What it is: A safe place to test how entity clarity changes what LLMs surface and cite.
- What you’ll see: Side-by-side answers for a small set of high-value queries—baseline vs. versions that inject canonical names/IDs and citations. A simple “grounding score” and “what changed” notes.
- What to do with it: Use results to tweak copy and schema on your live pages (e.g., add the canonical label earlier, tighten a claim, include a source).
- Why it helps: Shows stakeholders—using your own topics—how entity precision improves answer usefulness and citation likelihood.
Entity Governance
Good governance of this system will prevent you drifting away from your core topics and diluting your authority.
Ship alerts for three things:
- Unknown entities appearing in logs,
- Unusual spikes on known entities,
- Schema regressions that should block a release.
In the CMS, build a lightweight sidebar to save your team hours, which surfaces the canonical entity for each article; suggests internal links to the hub and nearest spokes; and provides a ready-to-paste JSON-LD stub with the correct @id.
On-site search should respect the same canon, with filters and facets by entity type and autocomplete powered by your alias dictionary. This type of system enables users and crawlers to encounter one coherent map of your brand and product entity world.
Weekly maintenance can stay boring: sync aliases and attributes from your product/knowledge systems; verify that sameAs links still resolve; rerun schema tests in CI; log merges/splits in the entity changelog.
Once the canon exists, familiar projects get sharper. Programmatic pages can key off entity attributes instead of keyword permutations. E-commerce facets like brand, material, and compatibility become honest filters over entities, enabling ‘works with’ graphs. Local SEO cleans up when Place and Organization entities carry consistent NAP and authoritative sameAs. E-E-A-T becomes tangible when authors and organizations are first-class entities with verifiable profiles. Even recommendations improve when ‘related entities’ are derived from observed co-occurrence in your reporting.
Cadence | Checklist |
Before publish |
|
Weekly |
|
Per release |
|
Monthly |
|
To truly adopt an engineering mindset when it comes to entities in AI search systems, build an operating cadence to support LLMs and reasoning agents to understand your content better. Putting this into practice is an ongoing effort with multiple steps, and will undoubtedly require additional tools beyond the standard SEO toolkit. Mike covers this in his article on AI Mode and the Future of Search.
Why Clear Entities, Not Word Count of Keywords, Decide Visibility
- LLMs retrieve passages, not pages. Write semantically complete chunks that start with the canonical entity name and a couple of checkable facts.
- Entities are your content OS. Treat people, products, places, and concepts as first-class objects you plan, publish, link, and report against. Use stable @ids and sensible sameAs.
- Fan-out is real. Queries are expanded and decomposed into sub-tasks; content that maps cleanly to entity attributes and comparisons is more likely to be selected.
- Markup isn’t decorative. Precise schema (with persistent IDs) + semantic HTML makes your facts reusable for grounding and entity cards—gate releases on critical schema errors.
- Build entity hubs, then link with intent. One source-of-truth hub per priority entity; spokes acknowledge the hub with the canonical label; merge cannibalizing pages quickly.
- Keep the story consistent across formats. Titles, captions, transcripts, file names, and alt text should reinforce the same entities and variants.
- Measure by entity. Track entity coverage, schema validity, performance by entity, ambiguity rate, and agility—keep dashboards small and blunt.
- Run lightweight projects, not moonshots. Create supporting apps in the CMS, SOPs for writing, tagging, tracking, and more.
- Govern the canon. One ID per thing across locales; maintain aliases; log merges/splits; alert on unknown entities, spikes, and schema regressions.
- Information gain beats word count. Disambiguated entities + verifiable claims + unique perspective give models a reason to use—and cite—your passages.
When your site is built around clear entities, persistent IDs, factual chunks, and basic governance, you’re not just easier to crawl; you’re easier to reason with. That’s the real ranking factor in a world of synthetic queries, AI-generated search results, and mentions with the value of backlinks, earned at the passage level.






