
Want a different perspective? These links open AI Search platforms with a prompt to explore this topic, how it works in AI Search, and how iPullRank approaches it.
*These buttons will open a third-party AI Search platform and submit a pre-written prompt. Results are generated by the platform and may vary.
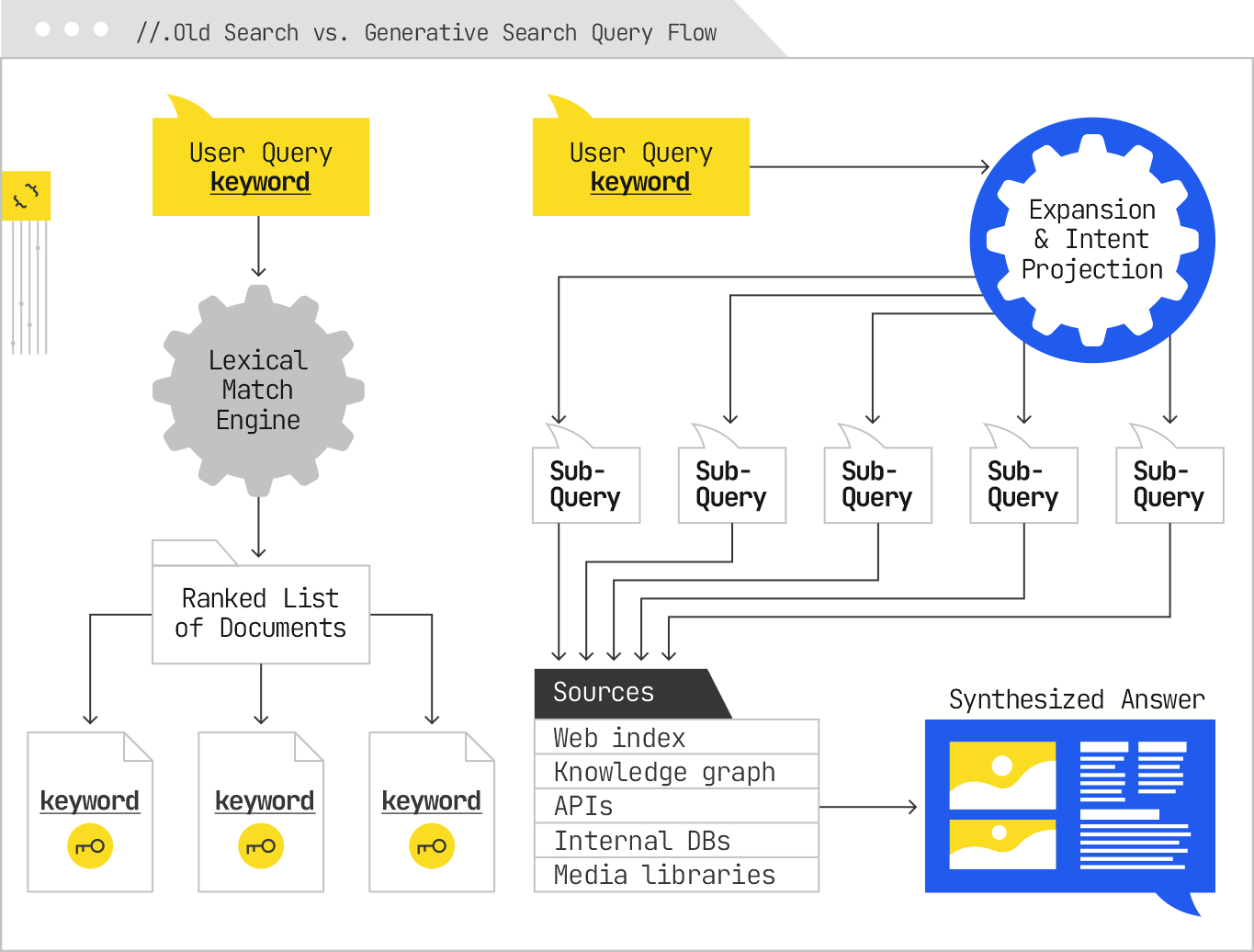
When search was powered by deterministic ranking systems, the query was the gravitational center of the entire experience. A person typed a phrase, and the search engine did its best to match those exact words to terms in its inverted index. Documents that matched more terms, in more significant places, scored higher. The query was static from input to output, and its role was straightforward: It was the sole lens through which the index was viewed.
This architecture was keyword-first and document-second, and everything you did in SEO reflected that relationship. You picked a set of queries worth ranking for, then optimized your pages to align with them, and the whole game was making those documents the most relevant and authoritative match for that string.
Generative search has made that approach obsolete. In this new retrieval-and-synthesis pipeline, the query someone types is not the query the system uses to gather information. Instead, the initial input is treated as a high-level prompt, a clue that sets off a much broader exploration of related questions and possible user needs. The system decomposes the query, rewrites it in multiple forms, generates speculative follow-ups, and routes each variant to different sources. What comes back is not a single ranked list but a set of candidate content chunks, which the system reranks, filters, and compiles to inform a synthesized answer.
The impact of this change cannot be overstated. It means that matching the literal words of a user’s query is no longer enough to guarantee retrieval, let alone inclusion in the final answer. The real competition is now at the subquery level. Your content needs to be relevant not just to the original phrasing, but to a constellation of related and adjacent intents the system might generate in its expansion phase.
Let’s return to a user search for “best half-marathon training plan for beginners.” In the old paradigm, that exact string, or close lexical variants, would be what the engine used to score documents. In the generative paradigm, that single query becomes the seed for a tree of expansions:
The system is not looking for a single perfect match anymore. It is building a portfolio of evidence to construct an answer, and the original query is just one small part of that portfolio.
What’s more, with ChatGPT’s update to the 5.2 model, it now generates longer-tail queries and performs minimal fan-outs. This means marketers need to know exactly what customers want and provide that content for them. With fewer fan-outs being generated, you need to have all of that content covered, or you won’t get cited.
The journey from the user’s initial words to the system’s full set of retrieval instructions begins with query expansion. This is the stage where the system broadens the scope of what it is looking for, aiming to cover both the explicit and implicit needs behind the request.
Expansion is not new. Early search engines used synonym lists and stemming to capture variants, but the modern version is qualitatively different. Powered by LLMs, embeddings, and real-world behavioral data, it is capable of generating expansions that go well beyond surface-level variation.
Let’s stay with our anchor query: “best half-marathon training plan for beginners.”
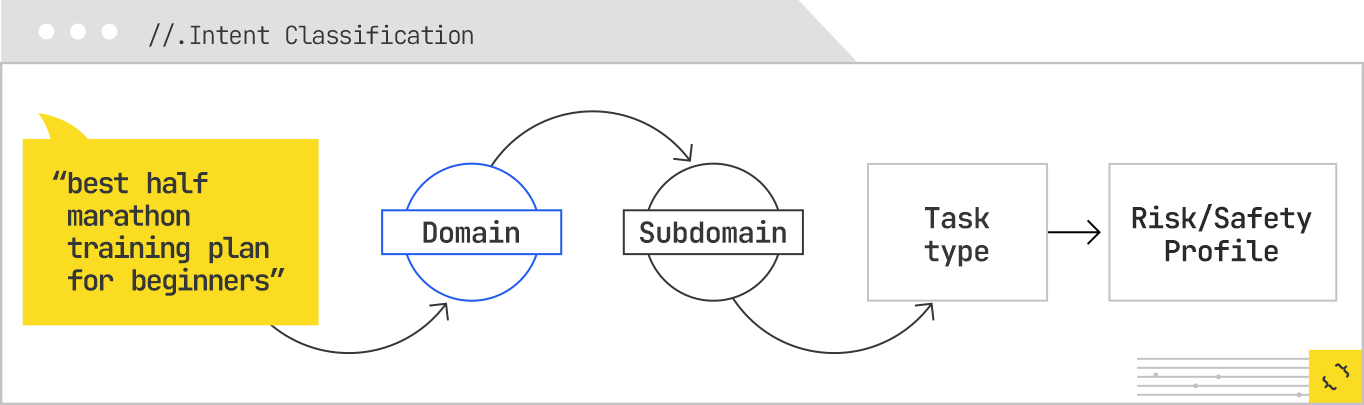
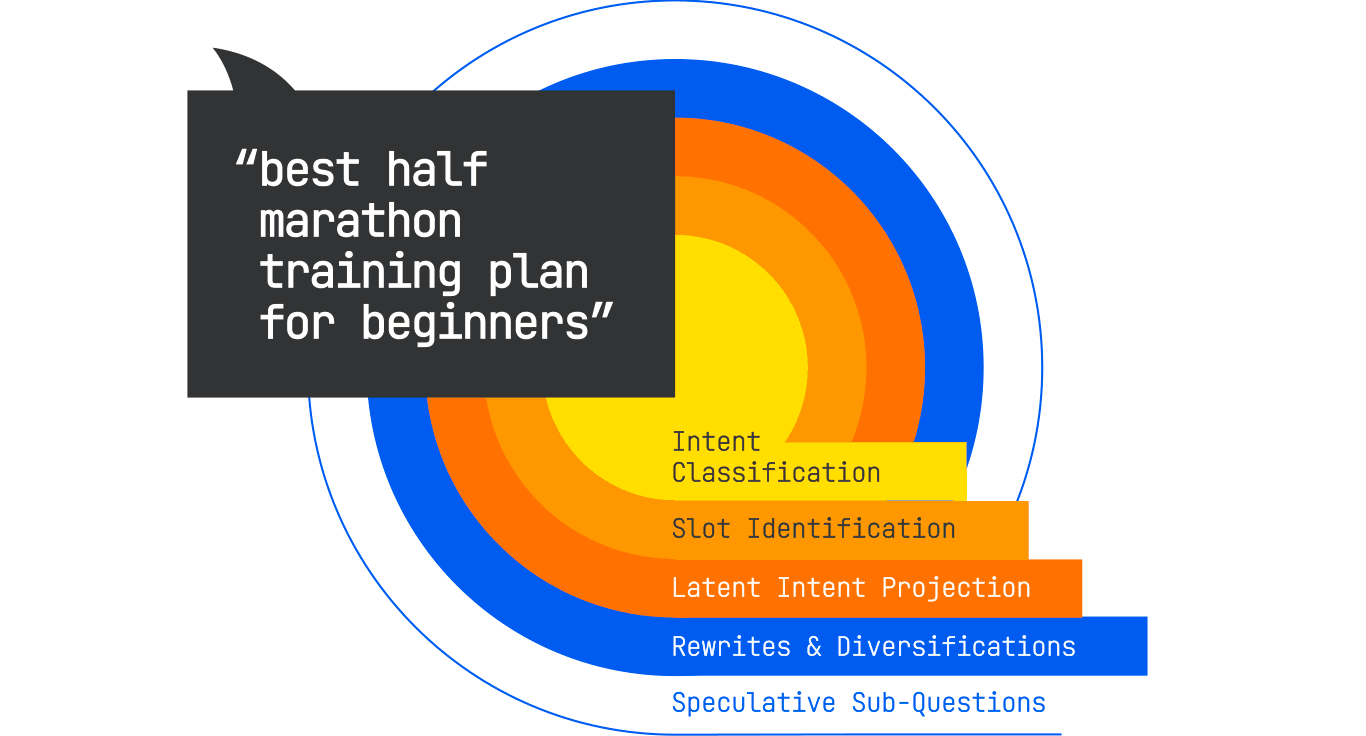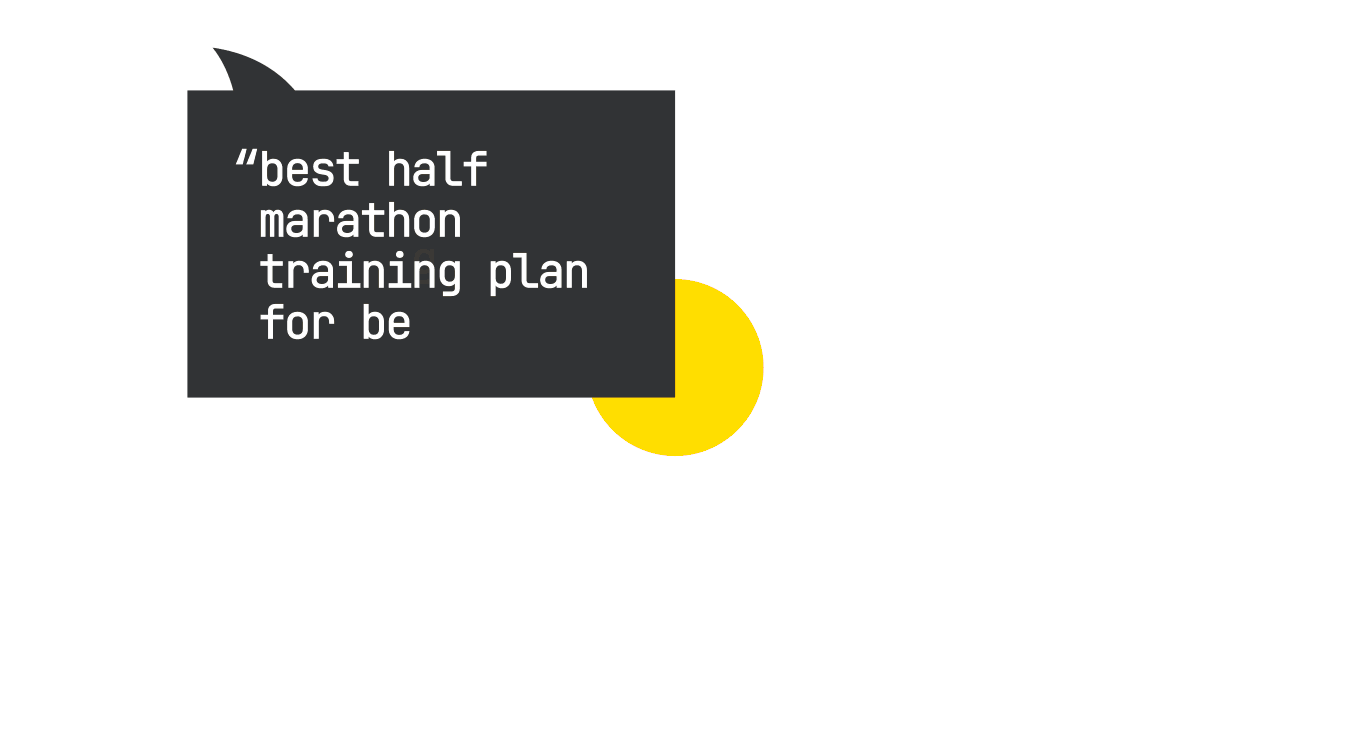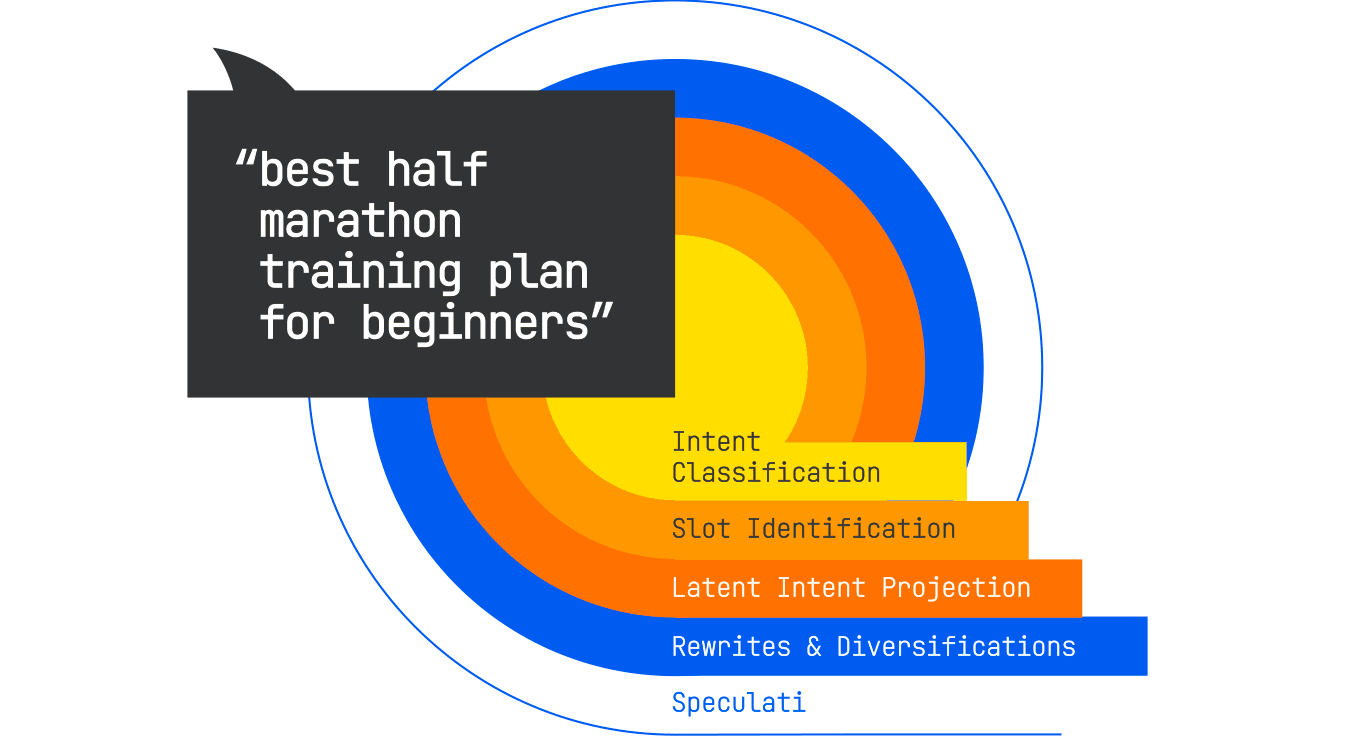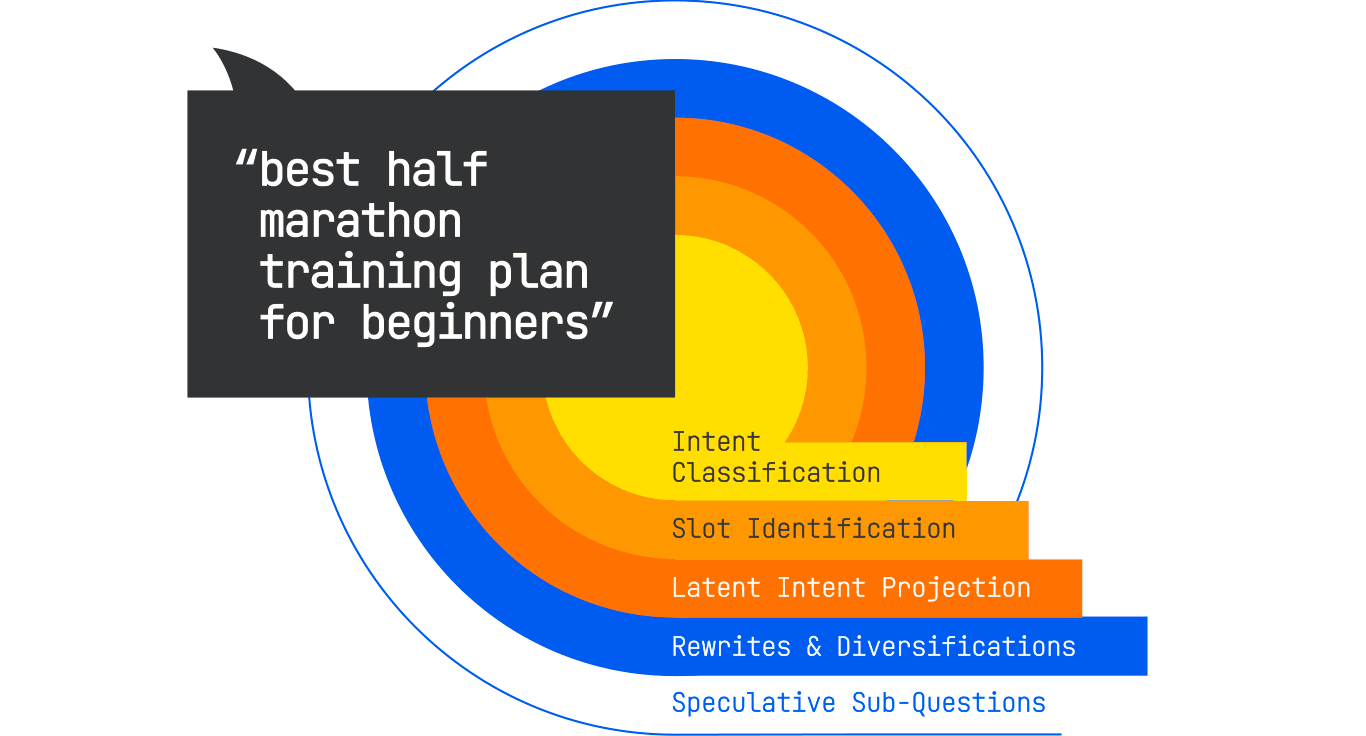
The first step is intent classification, which informs everything that follows by setting constraints on the types of sources and content formats that will be considered: The system determines that this is an informational query in the sports-and-fitness domain, specifically in the running subdomain. The task type is identified as “plan/guide,” with an embedded comparative element (since “best” implies evaluation). The risk profile of this content is low, but there is a safety component, in the form of injury-prevention advice.

Next is slot identification. Slots are variables the system expects to fill in order to produce a useful answer. Some of them are explicit. For example, “half-marathon” sets the distance, while “beginners” sets the audience. Others are implicit; here, the system may want to know the available training time frame, as well as the runner’s current fitness level, age group, and goal (finish vs. personal record). These slots may not all be populated immediately, but knowing they exist allows the system to search for content that can fill them.
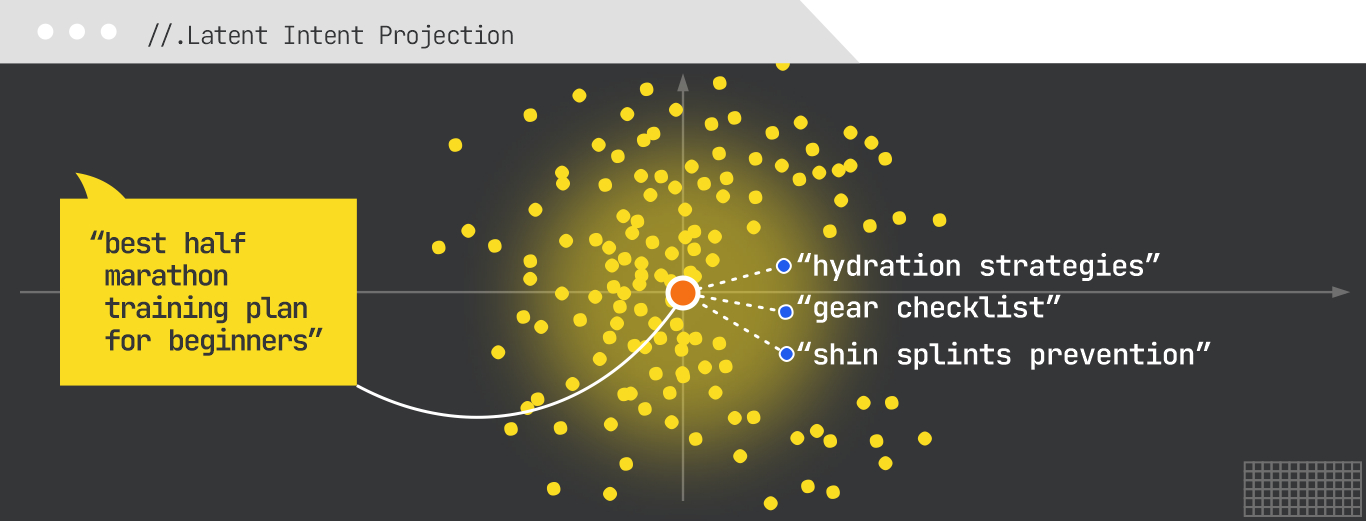
Once the slots are mapped, the system moves into latent-intent projection. This is where the original query is embedded into a high-dimensional vector space, and the model identifies neighboring concepts based on proximity. For this query, those neighbors might include:
These concepts are not random; they are informed by historical query co-occurrence data, clickstream patterns, and knowledge-graph linkages.
For example, the knowledge graph may connect “half-marathon” to entities like “13.1 miles,” “popular race events,” “training plans by distance,” and “nutrition for endurance events.” Traversing these connections gives the system new angles to pursue. If “half-marathon” connects to “training plans” and “injury prevention,” those nodes can become seeds for their own expansions.
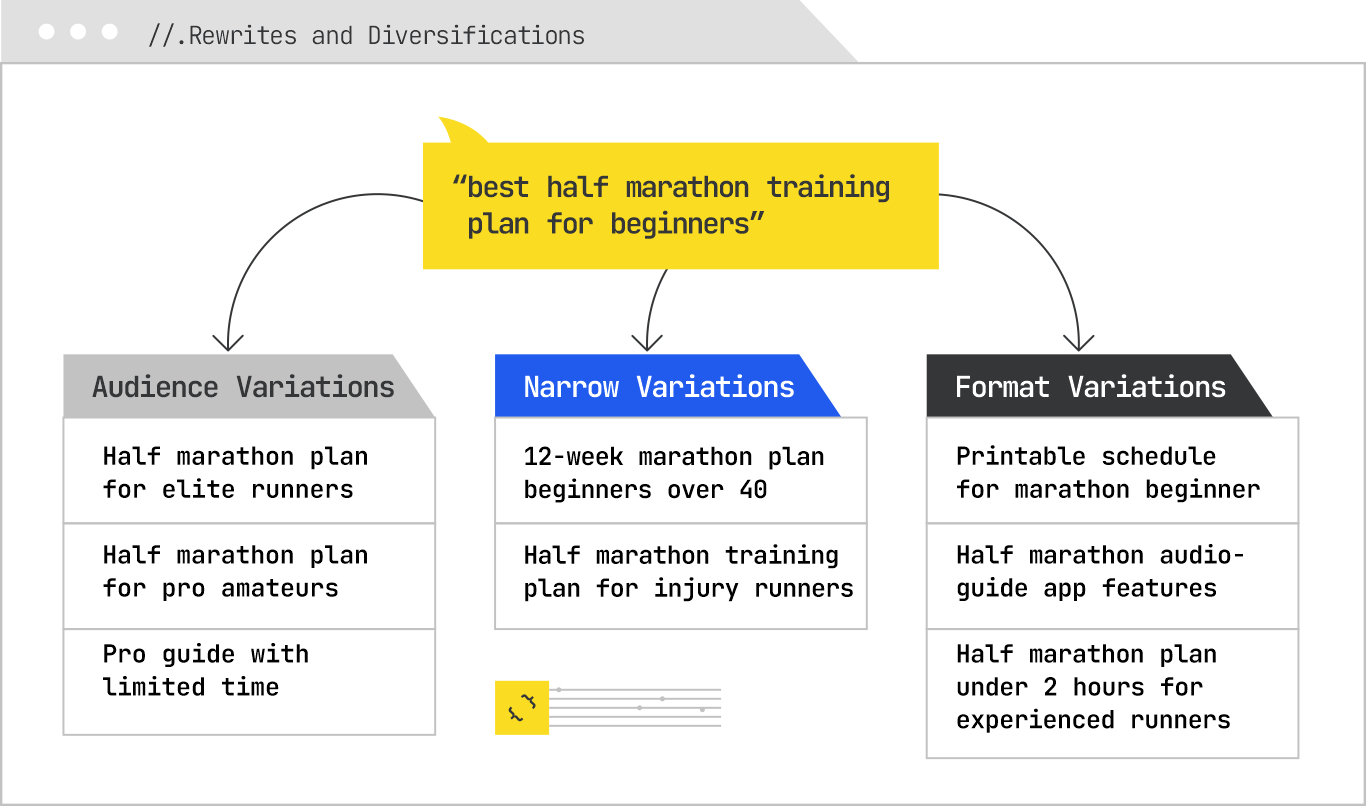
The system then generates rewrites and diversifications of the original query. These might include narrowing variations (“12-week half-marathon plan for beginners over 40”) and format variations (“printable beginner half-marathon schedule”). Each rewrite is designed to maximize the chance of finding a relevant content chunk that may not match the original phrasing.
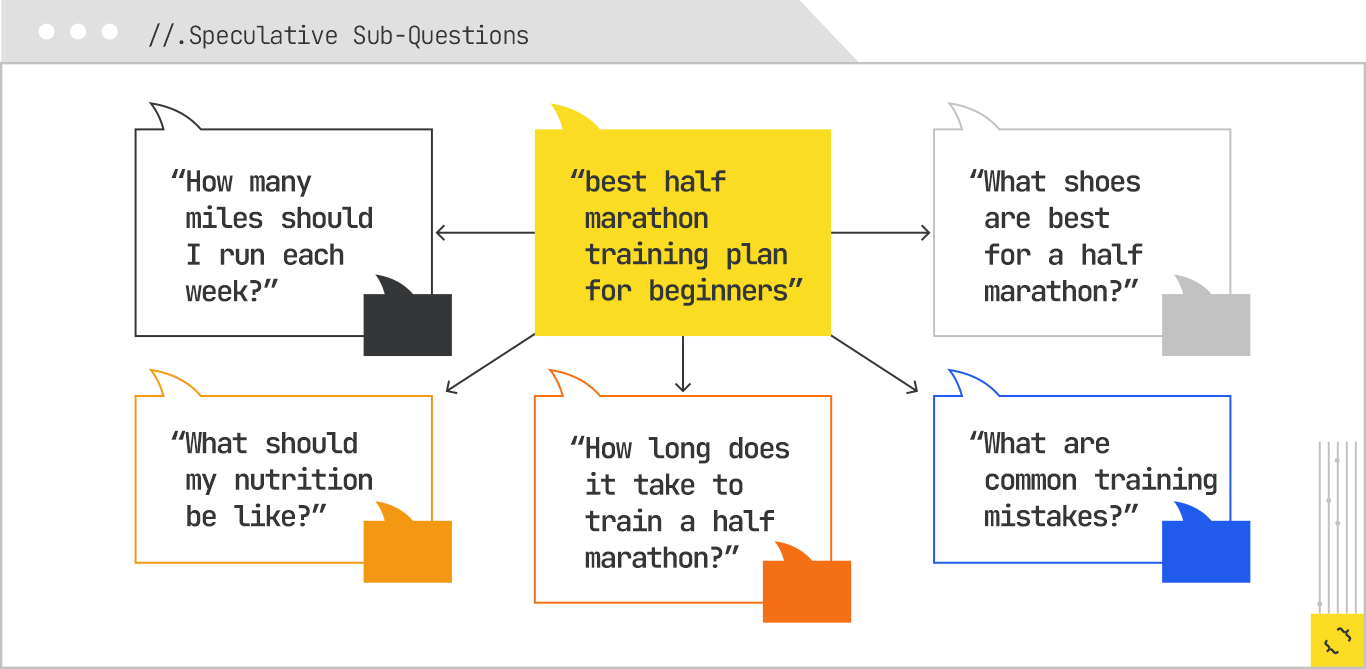
Finally, the model adds speculative sub-questions, based on patterns from similar sessions. A user who asks for a training plan will often later ask, “What shoes are best for half-marathon training?” or “How many miles should I run each week?” Including these in the retrieval plan preemptively allows the system to gather the material it will likely need for synthesis.
By the end of the expansion stage, the system may have generated a dozen or more subqueries, each covering a slightly different aspect of the problem space. Together, they form a much richer representation of the user’s intent than the original query alone.
For GEO, the consequence is clear: If you only produce content for the exact query, you are competing for only one branch of the fan-out tree. To become a regular part of generative answers, you need to be present in many branches. That means building intent-complete hubs that not only answer the core question, but also address the most common and valuable expansions the system is likely to generate. It also means thinking about your topics in terms of slot coverage, making sure that the variables the model may want to fill are represented in your content in ways that are extractable and unambiguous.
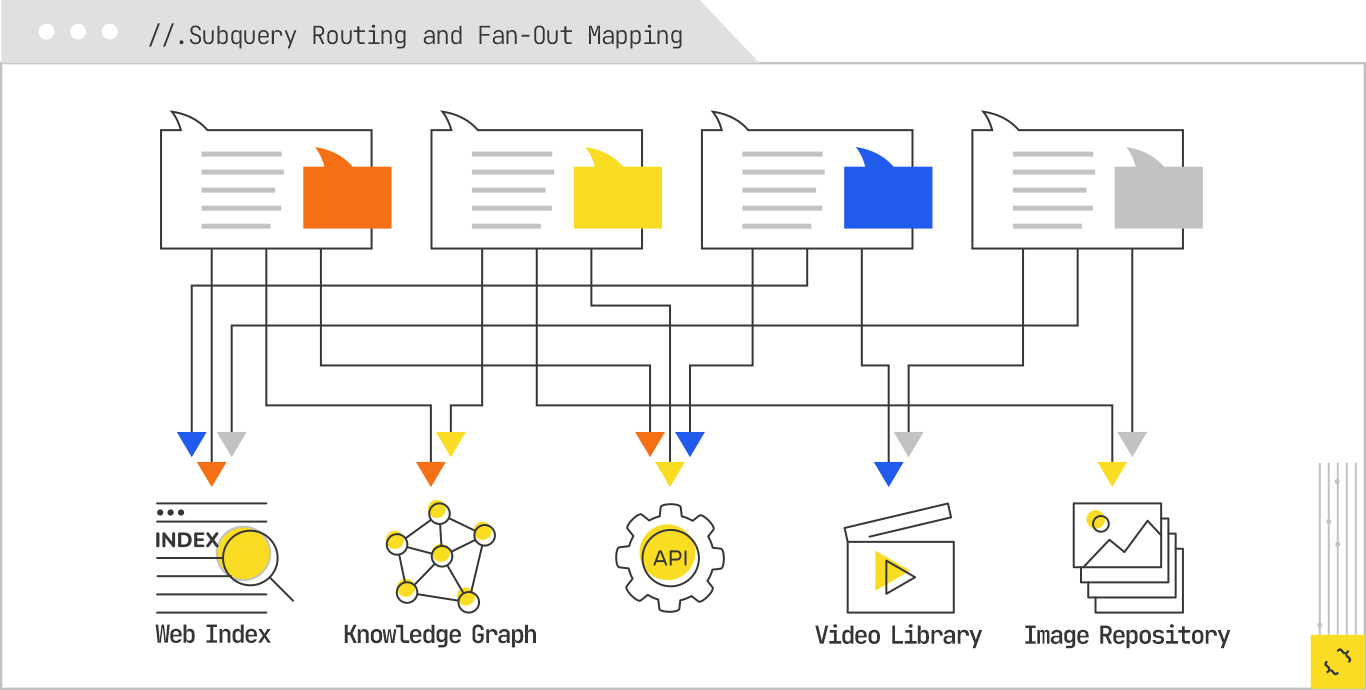
Once the expansion phase has produced a portfolio of subqueries, the system’s job shifts from what to look for to where to look for it. This is the routing stage, and it is where the fan-out map becomes operational. Each subquery is now a small task in its own right, and the system must decide what source or sources can best satisfy it, what modality is most appropriate for the answer, and what retrieval strategy will be used to get it.
Routing is where the architecture of modern generative search really starts to diverge from what SEOs are used to. In traditional search, every query went to the same place: the web index. That index might have been augmented with a news vertical, an images vertical, or a local-business database, but the logic was still relatively shallow. The query was matched lexically, scored against a single type of index, and results were presented in rank order. In a generative system, the routing step is a much more active decision-making process, one that treats different sources as different sensors in the information-gathering apparatus.
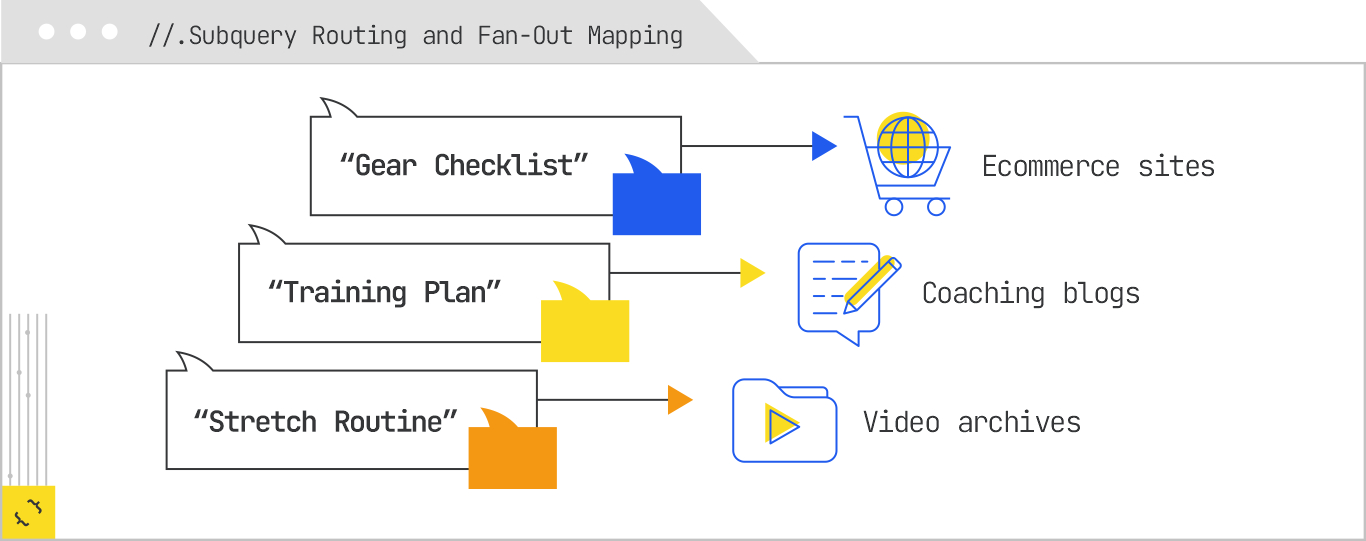
Returning to our half-marathon example, the expansion stage may have produced subqueries like:
Each of these subqueries has different informational characteristics. The training plan is likely best represented as text or a table. The gear checklist could be a table or a structured list, potentially with product images. The stretch routine might be best served by video, but the system may choose to retrieve transcripts first because they are faster to parse. The mileage question might target a structured knowledge base where coaching plans are already indexed in a machine-readable format. The nutrition guide might be routed toward vetted health content, and possibly subject to stricter source filtering.
In routing, the system maintains an internal mapping of what source types are most appropriate for different query classes. A “plan” might map to long-form text and structured schedules; a “checklist” might map to listicles and product tables; a “routine” might map to video; a “definition” might map to knowledge bases.
Query Class | Preferred Source Types | Preferred Formats/ Modalities |
Plan | Coaching blogs, training websites, expert-authored pages | Long-form text, structured schedules, tables |
Checklist | Ecommerce sites, product review sites, affiliate blogs | Listicles, bullet lists, product-comparison tables |
Routine | Instructional platforms, fitness apps, YouTube channels | Video (with transcripts), step-by-step guides |
Definition | Knowledge bases, encyclopedias, government or academic sources | Concise explanatory text, structured definitions |
These mappings are informed by both the model’s training and the system’s performance data — if past retrievals from a certain source type have led to better synthesis outcomes for a given class of query, that source type will be favored.
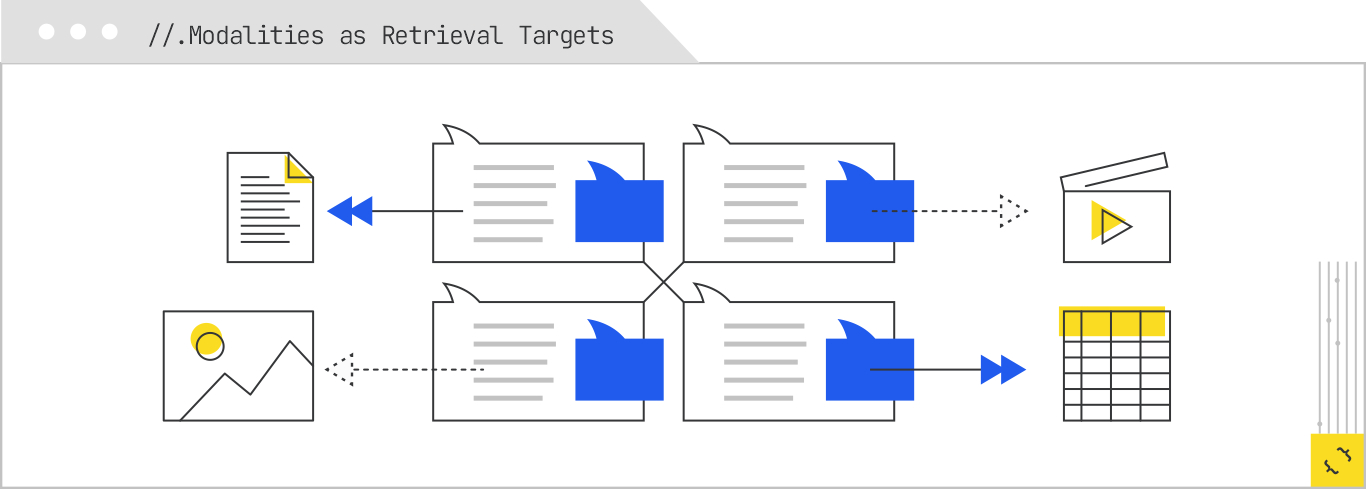
In this stage, modality is treated as part of the retrieval specification, not just a property of the returned document. If the system decides that “stretch routine for runners” should be answered with video, it will prioritize video repositories, video-optimized indexes, or even first-party instructional archives. However, it will often prefer to start with transcripts or closed captions, because these allow it to work with the information in text form while retaining the ability to reference or link to the original video.
This modality-aware routing means that a piece of content you created purely as a video might never be considered if it lacks a transcript (although Google’s systems auto-generate these). Likewise, a data-heavy table buried in a PDF might be skipped if the PDF is hard to parse or locked behind a paywall. The routing logic is looking for the most efficient and reliable way to extract the needed information, which often means favoring formats that are easy to chunk and embed.
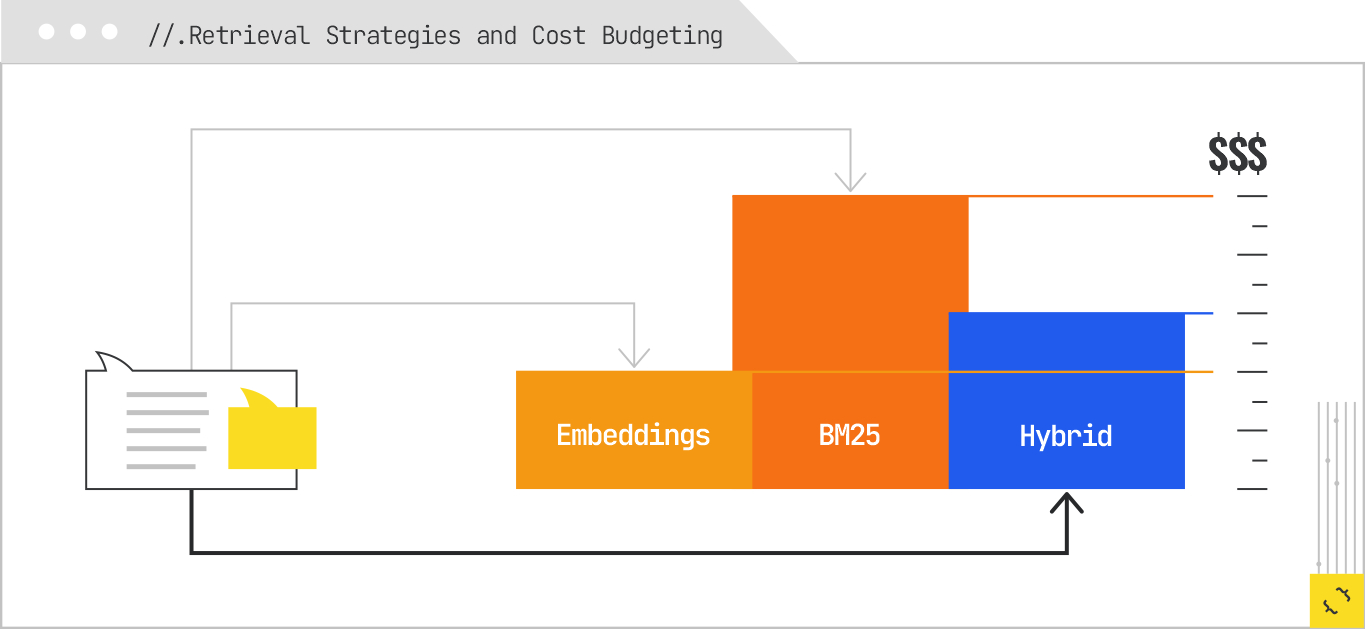
But routing is not only about matching queries to sources; it is also about deciding how to retrieve. Some subqueries are best served by sparse retrieval methods like BM25, which excel at matching rare, specific terms. Others benefit from dense retrieval using embeddings, which can capture semantic similarity even when the wording is very different. Hybrid retrieval strategies combine both approaches, ranking the union of results to capture the strengths of each.
There is also a cost dimension to routing. Each retrieval call — whether to an API, a vector database, or a web crawler — consumes resources. The system may therefore budget its retrieval calls based on the perceived importance of the subquery to the final answer. High-priority subqueries might get multiple retrieval passes from different sources; lower-priority ones might get a single pass from the most likely source. This is especially relevant in commercial verticals, where retrieval costs can add up quickly if the system is pulling from multiple paid APIs.
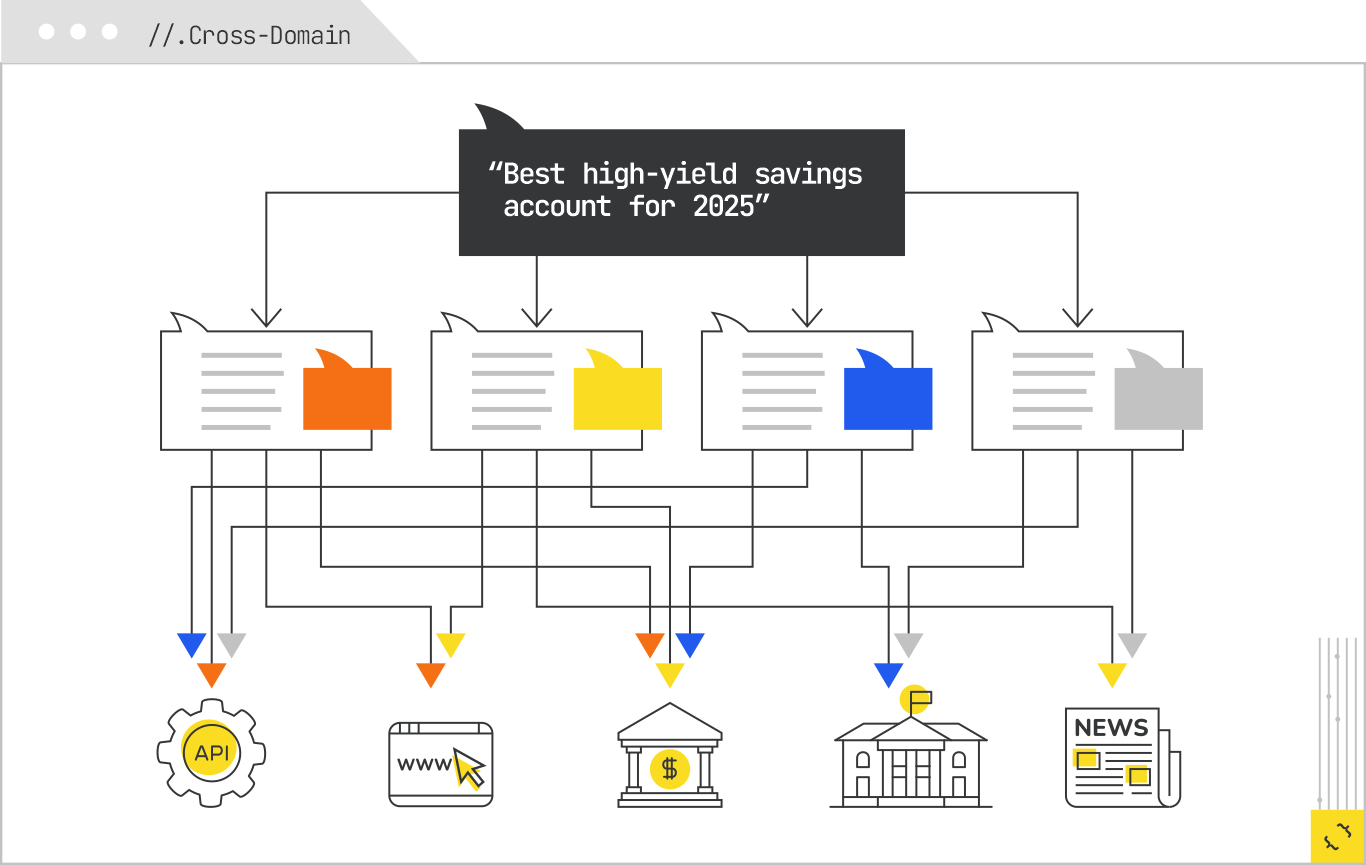
Consider a different seed query: “best high-yield savings account for 2025.” The expansion might produce subqueries like:
Routing here would send rate queries to financial-data APIs, minimum deposit requirements to bank product pages, insurance explanations to government or educational sources, and comparison logic to personal-finance editorial sites. Each of these is a different source type, with a different retrieval method and cost profile.
From a GEO perspective, routing is the step where a lot of opportunities are either created or lost. If your content does not match the modality the system expects for a given subquery, it may never be retrieved in the first place. This is why multimodal parity matters: If you publish a training plan, it should exist as narrative text, a structured table, a downloadable file, and ideally a short video with a transcript. This way, no matter which modality the system decides to target for that subquery, you have a relevant representation ready.
It also means thinking about where your content lives. If the routing logic is biased toward structured data from APIs for certain subqueries, consider exposing parts of your content in API-friendly formats. If the system prefers transcripts for procedural content, make sure your videos have high-quality, time-stamped transcripts. The more your content aligns with the routing profile, the more likely it is to be retrieved across multiple branches of the fan-out.
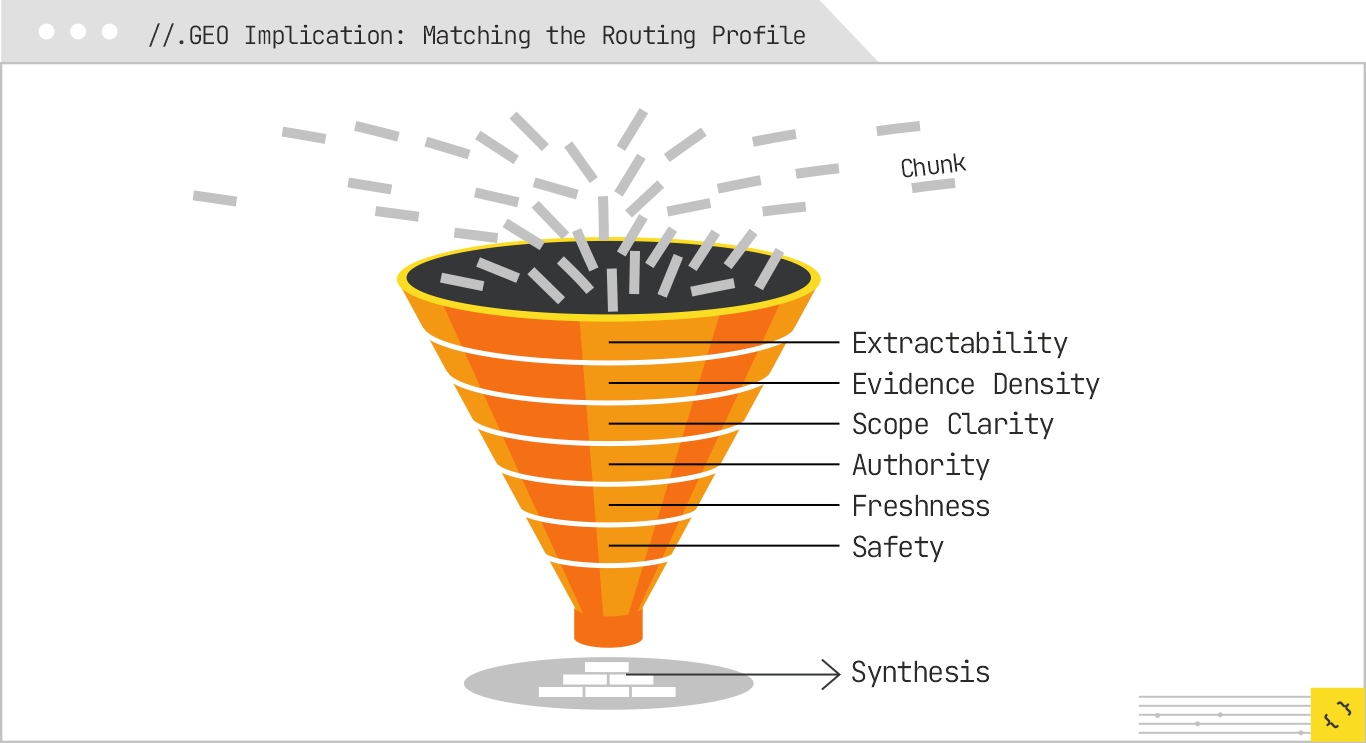
By the time the system finishes subquery routing and retrieval, it is holding far more content than it can possibly integrate into an answer. The fan-out has gathered material from multiple sources and modalities, and now the funnel narrows. The selection stage is where the system decides which pieces of retrieved content will be passed forward to the synthesis layer.
This is a very different problem from web ranking in the classic sense. In the old model, you might have a top ten, and the winner sat in position one. In the generative model, dozens or even hundreds of candidates can be relevant, but only a handful are both useful and usable for answer generation.
Selection is not only about relevance to the subquery. It is also about the suitability of a chunk to be lifted, recombined, and integrated without introducing factual errors, formatting issues, or incoherence. In effect, the system is ranking not entire pages but atomic units of information, and the scoring criteria are tuned to synthesis needs rather than click-through behavior.

The first major filter is extractability. If a chunk cannot be cleanly separated from its surrounding context without losing meaning, it is less valuable to the synthesis process. This is why content that is scoped and labeled clearly tends to survive selection best. In our half-marathon example, a training schedule presented as a table with headers for “Week,” “Miles,” and “Notes” is immediately usable. The same schedule described narratively in a long paragraph forces the model to parse and reconstruct the structure, which increases the risk of errors.
This is also why procedural steps, definitions, and fact lists that are explicitly marked in the HTML with headings, list tags, and semantic markup tend to perform better in selection. They give the model clean boundaries for chunking and make it easier to understand what the unit is about without reading the entire page.
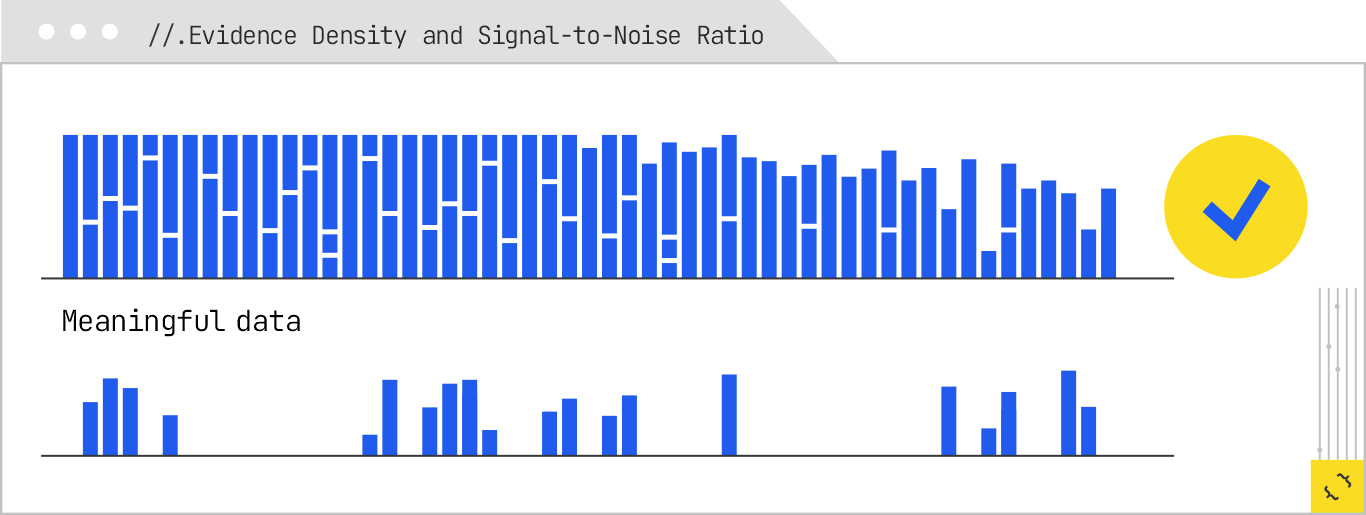
Once extractability is established, the system looks at evidence density, or the proportion of meaningful, verifiable information to total tokens. A dense paragraph that gives a clear statement, followed by an immediate citation or supporting data, is more valuable than a lengthy, anecdote-heavy section that buries the facts in storytelling.
In our example, a concise section that reads, “Most beginners should train three to four days per week, with long runs increasing by one mile each week, according to the American College of Sports Medicine,” is high-density. It offers a specific recommendation, includes progression details, and cites a credible source. By contrast, a 400–word reminiscence about how the author trained for their first race, with the key details scattered throughout, has low density and is more likely to be dropped. In other words, you can skip your grandma’s life story and just give me the bulleted recipe!

Generative systems are sensitive to scope because they are trying to assemble an answer that is not misleading. If a chunk does not make clear the conditions under which it is true, it is harder to place it correctly in the final answer. Statements like “This plan assumes you can currently run three miles without stopping” are extremely useful, because they define applicability. Without that, a model risks recommending the plan to someone who cannot meet that baseline, which could be a safety issue.
Scope clarity is particularly important in YMYL (Your Money or Your Life) domains. Consider a finance example: For the subquery “minimum deposit for Marcus savings account,” a page that says “No minimum deposit” but does not specify the date or account type may be excluded in favor of one that says, “As of February 2025, Marcus by Goldman Sachs has no minimum deposit for its high-yield savings account.” The latter is scoped in both time and product type, reducing the risk of outdated or overgeneralized information.

The system also weighs the credibility of the source and the degree to which the information is corroborated by other retrieved chunks. Authority in this context is not limited to domain-level trust; it can apply at the author or publisher level. A training plan written by a certified coach or a nutrition guide authored by a registered dietitian carries more weight than an anonymous blog post.
Corroboration is a subtle but important factor. If three independent, credible sources agree on a specific mileage progression, that progression is more likely to survive selection. Outlier claims may still make it in if they are well-sourced, but the system will often prefer information that has multiple points of agreement.

Recency is another filter, especially for topics where the facts can change. In our example, the basic principles of half-marathon training may be stable, but event-specific advice, gear recommendations, and nutrition guidelines might change over time. A chunk that is clearly dated and shows evidence of recent review is more attractive to the model than one with no temporal markers. In finance, freshness is even more critical. Interest rates, fees, and account terms can change monthly or even more frequently, so outdated chunks are quickly discarded.

Finally, selection often applies harm and safety filters. This can mean removing chunks that recommend unsafe practices for beginners, such as increasing long-run mileage by more than 10 percent per week, or financial advice that could be considered speculative or misleading. These filters can be domain-specific, drawing on both explicit policies and learned patterns from training data.
One of the most frustrating realities for content creators is that material that is high-quality and relevant can nonetheless be excluded from synthesis. This often happens because the format or presentation does not align with extractability needs. A beautifully designed interactive that contains a wealth of information may be invisible if its data is not exposed in a crawlable, parseable way. Long-form content that frontloads narrative and pushes key facts far down the page risks being skipped simply because the model finds denser, easier-to-use material earlier in its retrieval set.
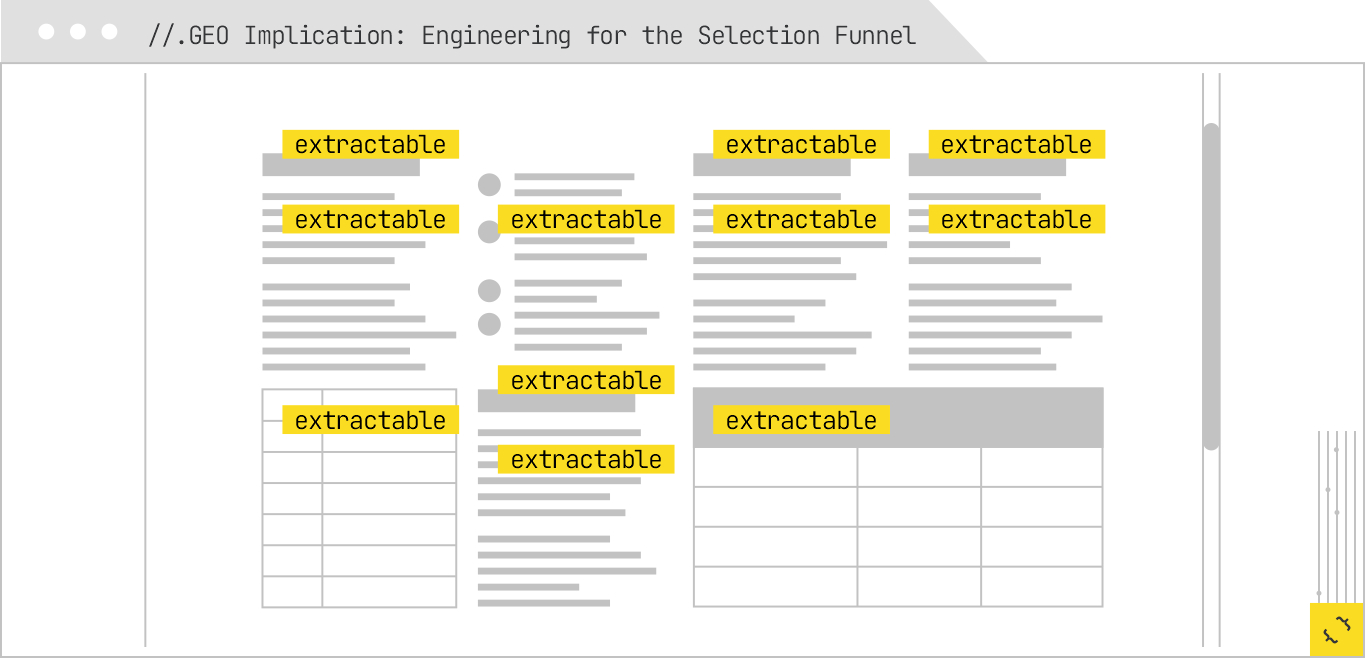
For GEO, the lesson from the selection stage is that optimization must happen at the chunk level, not just at the page or site level. Each key piece of information should be:
In practice, this means rethinking how you structure your content. A single long page may need to be designed as a series of clearly marked, self-contained modules, each of which could stand alone if lifted into a generative answer. It also means pairing each chunk with whatever metadata, markup, and alternative formats will make it easier for a retrieval system to recognize and use.
When your content survives this stage, the synthesis layer can pull it, trust it, and fit it into a larger narrative without having to rework it. And in a generative search world, that readiness is what determines whether your work actually appears in the answer the user sees.
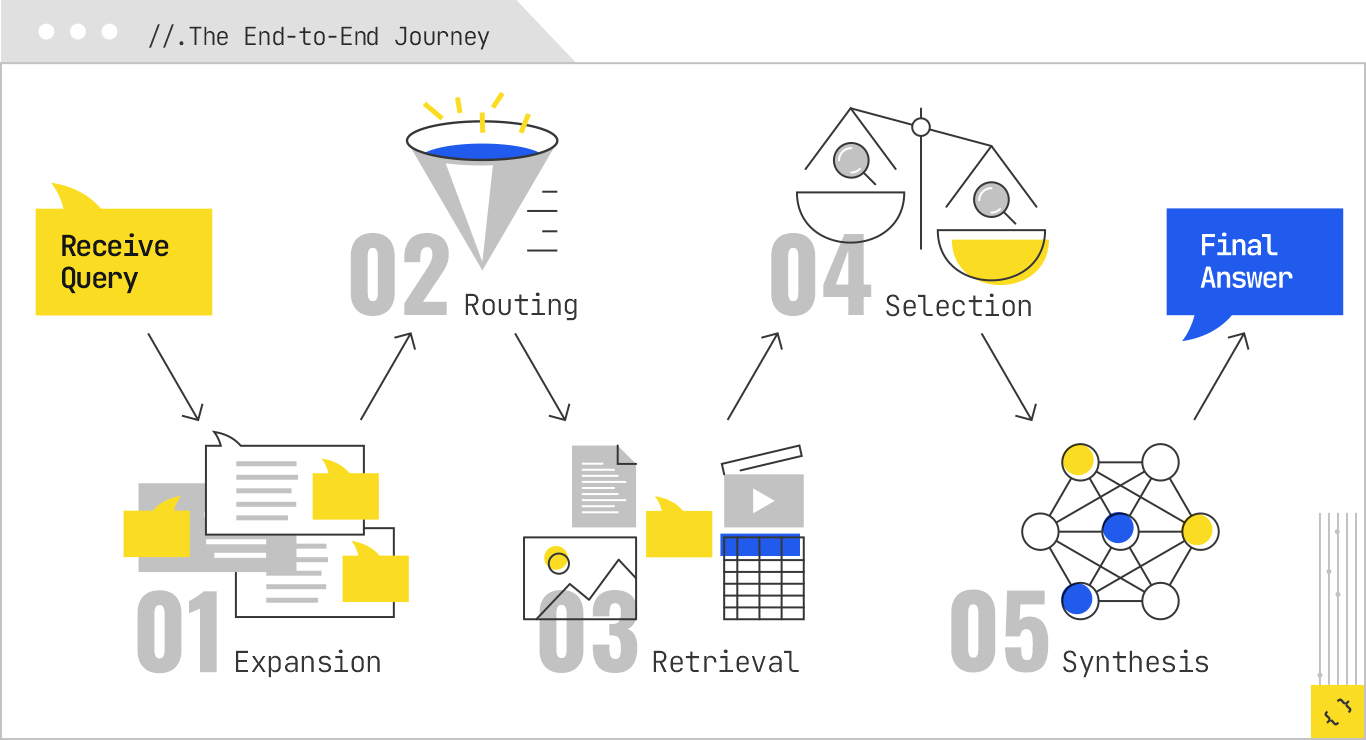
To see how query fan-out, subquery routing, and selection work together, it helps to walk one example through the entire pipeline, from user input to the final generated answer. Let’s return to our anchor query: “best half-marathon training plan for beginners.”
The process begins the moment the user submits the query. In the expansion phase, the system classifies the domain and task type, identifies slots like time frame and runner profile, and projects latent intents such as gear recommendations, injury prevention, and nutrition advice. It rewrites the query into more specific and alternative forms, like “16-week half-marathon training schedule for first-time runners” or “half-marathon run-walk plan,” and generates speculative follow-ups, like “How many miles per week should a beginner run for half-marathon training?” By the end of this phase, the original query has become a network of 15 to 20 subqueries, each targeting a specific facet of the user’s needs.
In the routing phase, each of these subqueries is matched to the most appropriate source and modality. The training-plan subquery is sent to web indexes with a preference for text and tables. The gear-checklist subquery targets ecommerce product pages and sports-retailer guides, ideally in table or list formats. The stretch-routine subquery points toward video repositories, but the system prefers to pull transcripts for fast parsing. Mileage-progression questions hit structured knowledge bases populated with coaching data, while nutrition guides are routed to vetted health and sports-medicine sources. All this creates a fan-out map where each branch of the original query leads to one or more sources, each with its own retrieval strategy.
In the selection phase, the results from all these retrievals are scored for extractability, evidence density, scope clarity, authority, freshness, and corroboration. A 16-week plan laid out in a clean table survives; a narrative description buried deep in a long blog post does not. A gear checklist that specifies weight, weather suitability, and price in a table is kept; a photo carousel with no alt text is dropped. An injury-prevention tip that cites a sports-medicine authority passes the filter; an unsourced opinion is excluded. By the end of selection, the hundreds of retrieved chunks are narrowed to a dozen high-quality, ready-to-use units of information.
The synthesis layer then assembles these chunks into a coherent answer: an introductory paragraph on what to expect from a beginner’s half-marathon plan, a table of weekly mileage progression, a bulleted list of essential gear, a short paragraph on injury-prevention strategies, and an embedded image or two of stretching techniques. Each piece of that answer has been through three rounds of filtering, and each came from a different branch of the fan-out tree. The final output is richer than any single document could have provided, but it is also heavily shaped by the system’s decisions at each stage.
What’s important to recognize here is how many opportunities there were for your content to be included and how many opportunities there were for it to be excluded. If you only had the training plan and nothing else, you might have been represented once in the final answer. But if you had also created the gear checklist, the injury-prevention tips, the nutrition guide, and the stretch routines (in formats the routing system prefers), you could have been represented in four or five places within the same answer.
In sum, generative search is not a single ranking contest for a single query. It is a multistage filtering process in which your content competes at dozens of points in a branching, multimodal retrieval plan. The fan-out means the system is looking for breadth as well as depth, and the synthesis step means it is judging your content on extractability and readiness, not just relevance.
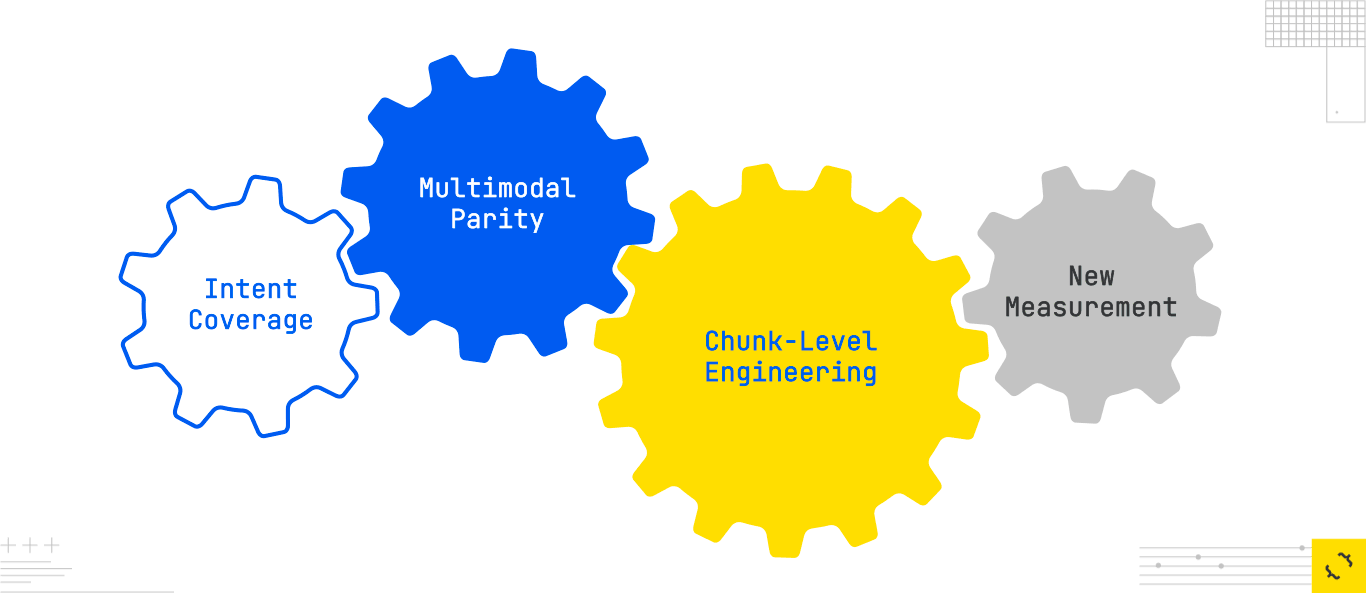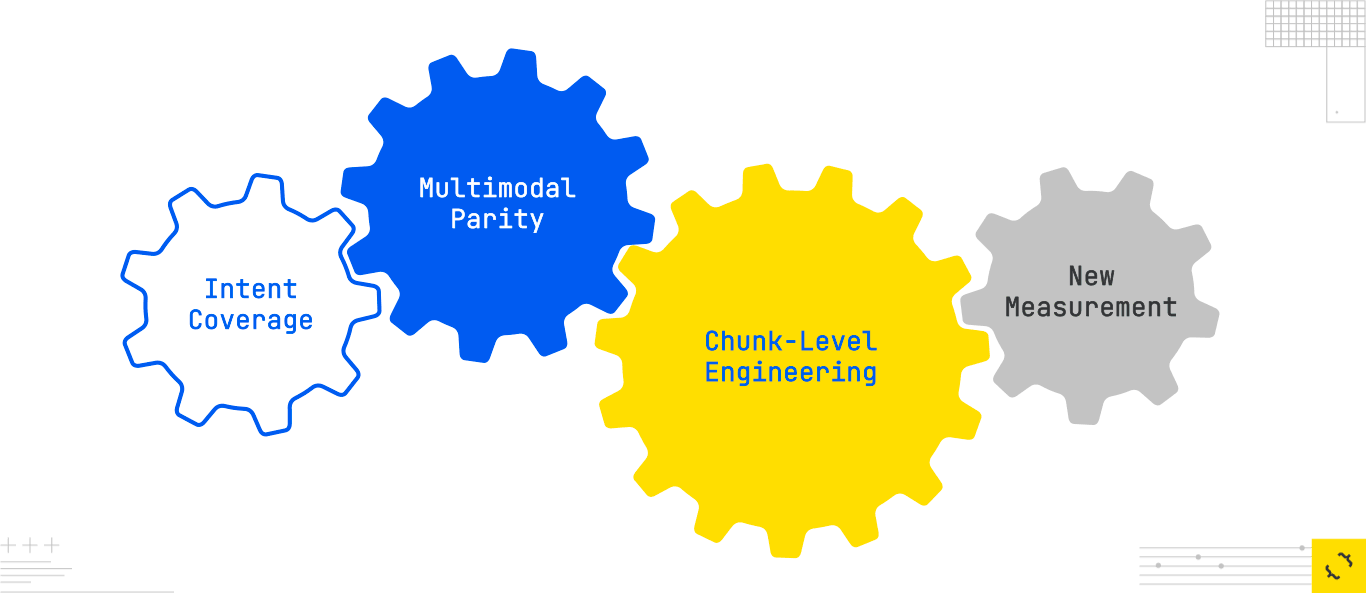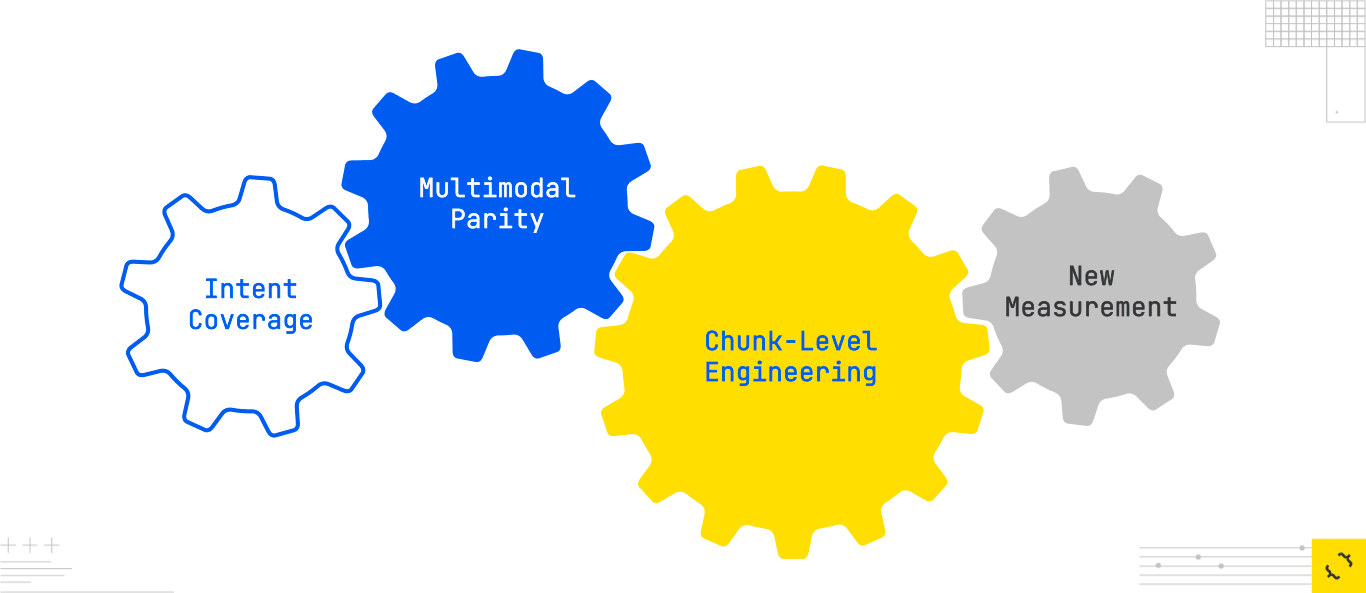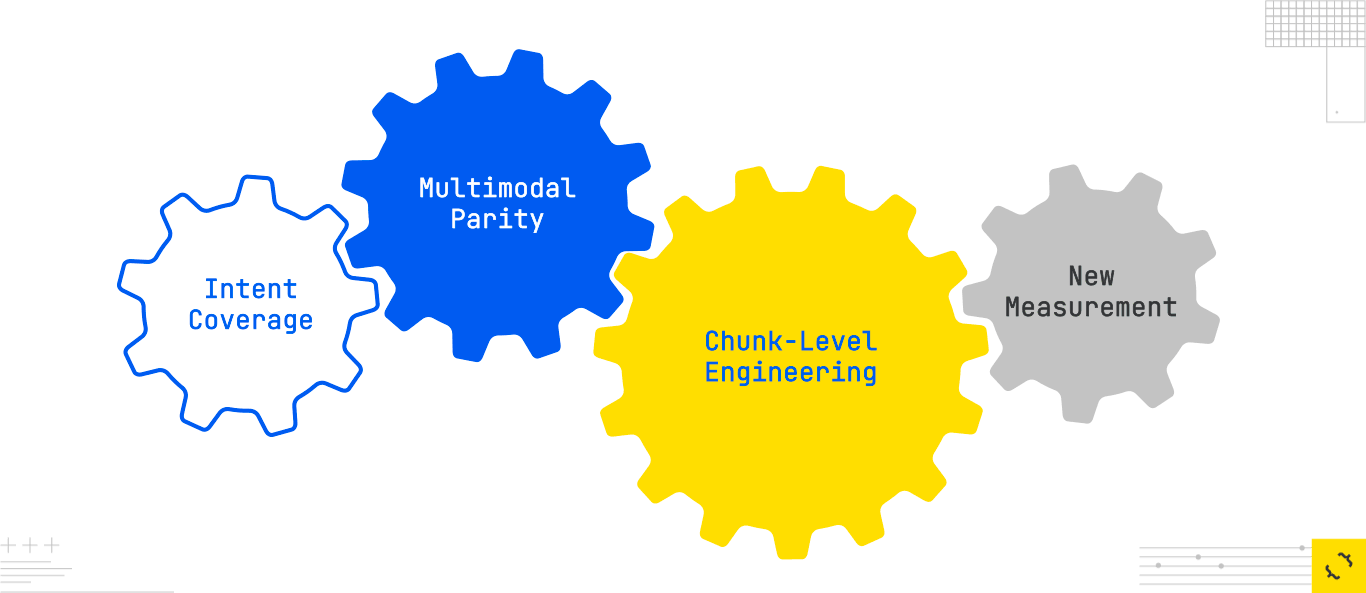
From a GEO perspective, this changes the game in four important ways.
First, intent coverage replaces keyword coverage as the primary unit of competition. You can no longer afford to optimize a page for one query and call it done. You must anticipate the expansions the system will generate, and you must build content that addresses them directly. This is why topic hubs, slot-complete content, and adjacent-intent coverage matter. They ensure that when the model explodes a query into multiple branches, your site has an offering for each branch.
Second, multimodal parity becomes table stakes. Because routing decisions are modality-aware, having your information available in text, tables, images, videos, transcripts, and structured data gives you more entry points into the retrieval process. If the system decides a subquery should be answered with a table and you only have prose, you’re invisible to that branch of the fan-out.
Third, chunk-level Relevance Engineering is as important as page-level optimization. Selection happens at the chunk level, and the system will only use material that is extractable, dense with evidence, scoped, authoritative, and fresh. This incentivizes designing each information unit (a step list, a definition, a comparison table) to successfully stand alone if lifted out of context. It means labeling, structuring, and versioning that unit so the model knows exactly what it is and when it applies.
Finally, measurement needs to evolve. Traditional SEO metrics like rankings and CTR don’t capture performance in a generative context. You need to measure subquery recall (how many branches of the fan-out you appear in), atomic coverage (the percentage of your content that meets extractability criteria), evidence density (the signal-to-noise ratio in your chunks), and citation stability (how often you’re selected in regeneration cycles). These are the input metrics that tell you whether you are truly winning in a GEO environment.
The shift to generative search is a shift from competing for a single keyword to competing for every relevant moment in a dynamic, multibranch retrieval plan. The winners will be the sites that think like data providers as much as publishers, designing content for integration into answers rather than just for stand-alone consumption. The systems are going to keep getting better at expansion, routing, and synthesis. Your job is to make sure that at every step of that process, there is a chunk of your content that fits perfectly into the slot the model is trying to fill.
If your brand isn’t being retrieved, synthesized, and cited in AI Overviews, AI Mode, ChatGPT, or Perplexity, you’re missing from the decisions that matter. Relevance Engineering structures content for clarity, optimizes for retrieval, and measures real impact. Content Resonance turns that visibility into lasting connection.
Schedule a call with iPullRank to own the conversations that drive your market.
The appendix includes everything you need to operationalize the ideas in this manual, downloadable tools, reporting templates, and prompt recipes for GEO testing. You’ll also find a glossary that breaks down technical terms and concepts to keep your team aligned. Use this section as your implementation hub.
//.eBook

The AI Search Manual is your operating manual for being seen in the next iteration of Organic Search where answers are generated, not linked.
Prefer to read in chunks? We’ll send the AI Search Manual as an email series—complete with extra commentary, fresh examples, and early access to new tools. Stay sharp and stay ahead, one email at a time.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.
We’ll break it up and send it straight to your inbox along with all of the great insights, real-world examples, and early access to new tools we’re testing. It’s the easiest way to keep up without blocking off your whole afternoon.





