
Searchers rarely type (or think) exactly like your brand content has been written. They misspell brand names, swap words for synonyms, and ask open-ended, messy questions. This trend is even further amplified by the introduction of AI chatbots and AI search agents, which take personalization of the user search prompt to the next level. You can see this firsthand in iPullRank’s AI Mode UX study conducted in August.
What does this mean for SEOs?

The uniqueness of your potential customers’ thoughts, used words and phrases, is now up against the sophistication of the search engine’s information retrieval capabilities when it comes to content discovery. To some things more difficult, you’re marketing at the expense of probabilities.
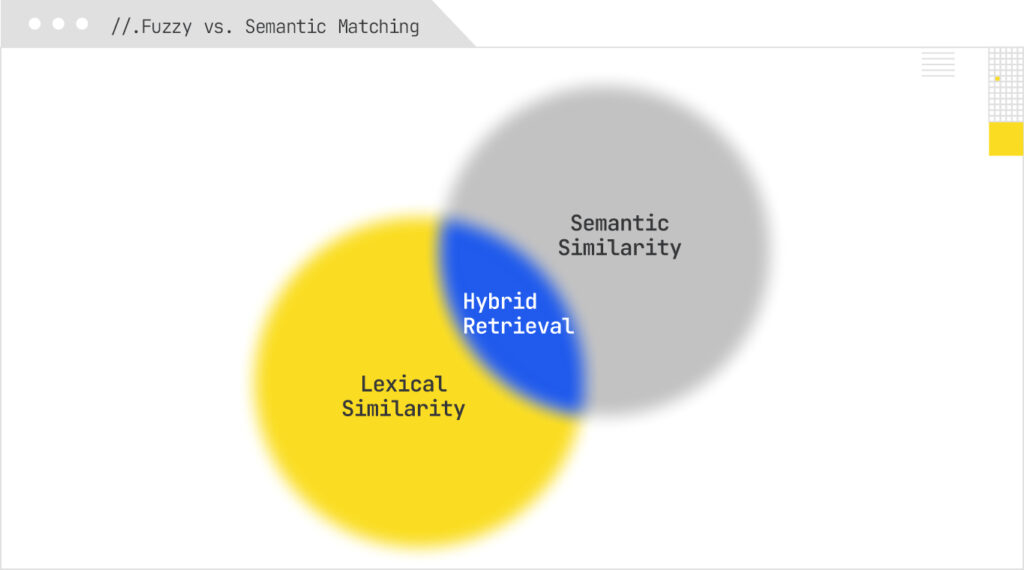
The practical response isn’t to rewrite everything for every phrasing—it’s to teach your retrieval stack to recognize both what a query looks like and what it means. Fuzzy matching catches near-miss strings and variants (typos, transpositions, phonetic lookalikes, and n-gram overlaps). Semantic matching maps language into meaning via embeddings and intent similarity, so paraphrases and long, conversational prompts still land on the right content. When you blend the two, you expand recall without flooding users with noise, and you future-proof visibility as AI agents continue to rewrite, summarize, and personalize queries on the fly.
This article lays out a pragmatic blueprint. We’ll define the main families of fuzzy techniques—exact and distance-based string matching, phonetic and n-gram methods, TF-IDF—and contrast them with semantic (vector) matching. From there, we’ll look at how fuzzy logic powers traditional search in areas like error tolerance, query expansion, voice search, and more. Next, we’ll map those same ideas onto LLM-based search, showing what carries over and what’s new (embedding-driven relevance, reranking, and personalization).
I’ll also share some hands-on quick-start projects that have the potential to improve organic visibility across traditional and AI search engines alike. By the end, you’ll have a clear, testable approach to combine “looks-like” fuzzy signals with “means-like” semantic signals, allowing your content to be discoverable across the messy, personalized, AI-shaped ways people now search.
Fuzzy String Matching - Subtypes, Definitions, Algorithms, and Libraries

Fuzzy matching is a form of string matching: we assess the similarity of two strings against one another. String matching is a machine learning problem dating back to the 1980s. At its core, it measures the “distance” between two strings and converts that distance into a similarity score to classify pairs as equivalent, similar, or distant.
It emerged to solve two big problems: error correction (e.g., spelling mistakes, transpositions, omissions) and information retrieval (finding the best-matching items when inputs are imperfect). In retrieval, we face two risks: returning unwanted items or missing required ones. Fuzzy methods try to balance both.
Now, pause and think about all the SEO/digital marketing situations where human or system errors creep in—and where fuzzy logic helps: redirect mapping, mapping 404s to live URLs, competitor analysis, internal link mapping, and more. Also consider operational data: customer or product databases where manual entry introduces inconsistencies. Fuzzy matching helps deduplicate, consolidate, and correct.
The string similarity problem in fuzzy matching
Similarity is the core problem all fuzzy algorithms tackle. Early work cataloged what actually creates differences between strings that “should” be the same: substitutions (one letter mistaken for another), deletions (omitting a letter), insertions (adding a letter), and transpositions (swapping letters). Algorithms model these errors to compute distance and, from it, similarity.
Crucially, this is why plain string matching is unsuitable for many SEO/marketing tasks that require meaning, not just characters. It’s great for redirect mapping (we assess URLs as strings), but not enough for internal link opportunity identification, where we’re trying to surface pages that benefit users with new information or formats. Classic string matching measures character/word distance; it does not (by itself) capture semantics or context. This lack of semantic or contextual understanding makes them inferior to other approaches (like entity-based mapping) for certain applications, such as internal link opportunity identification.
Fuzzy string matching approaches are classified based on how similarity is calculated. There are five main types:
Type of Matching | Key Difference/Calculation Method | Example Algorithms |
Exact Matching | Direct character-by-character comparison to find the exact pattern. | Boyer-Moore algorithm. |
Distance-based Matching | Focuses on edit distance—the minimum number of edit operations (insertion, deletion, substitution) needed to convert one string into another. | Levenshtein Distance, Jaro Distance, Hamming Distance. |
Phonetic Matching | Captures phonetic similarities, useful where differences exist in pronunciation or spelling but the meaning is the same (e.g., multilingual contexts). | Metaphone, Soundex. |
N-gram Matching | Detects occurrences of fixed sets of pattern arrays (sub-arrays like bigrams or trigrams). Focuses on substring patterns. | N-gram based approach, Bigram Matching, Trigram Matching. |
TF-IDF String Matching | Uses Cosine Similarity with TF-IDF. Analyzes the corpus of words as a whole and weighs tokens higher if they are less common in the corpus (context-sensitive weighting). | TF-IDF with Cosine Similarity. |
Exact Matching
Exact Matching (Direct) as one of the primary methods within the larger context of fuzzy string matching algorithms. It is fundamentally different from other fuzzy methods because its objective is to find perfect identity rather than approximation.
- Typical algorithm: This is a well-known pattern recognition algorithm designed for the exact string matching of many strings against a singular keyword (or, in other words – direct character-by-character comparison), and it is very fast in practice.
- How it works: Check whether the query’s characters appear in a candidate substring, align lengths, and verify character by character. Partial matches advance the window efficiently until an exact match is found. The algorithm seeks the exact pattern contained within the search string. This involves looping through entries, checking for the presence of the characters within the keyword, and ensuring the length of the keyword input matches the entry. If a mismatch occurs, the algorithm searches for the next substring example.
- Strengths: Fast, accurate for exact matches; minimal compute.
- Limitations: Only finds exact matches – no tolerance for typos/variants, making it ineffective for fuzzy or approximate matches.
Distance-based Matching
Distance-based methods compute the minimum number of edit operations needed to turn one string s into another t. Operations typically include substitution, insertion, and deletion (sometimes transposition). The Edit Distance is calculated between two strings (e.g., ‘s’ and ‘t’) as the minimum number of edit operations required to convert the string ‘s’ into the string ‘t’. The program calculates the number of character shifts needed to get from the input keyword to the entry found in the search.
- Typical algorithms: Levenshtein distance, Jaro (and Jaro–Winkler), Hamming distance (for equal-length strings).
- Example: “hard” → “hand” requires one substitution; “hard” → “harder” requires two insertions, so “hard”/“hand” are closer by edit distance than “hard”/“harder.”
- Strengths: Very good for detecting approximate matches. Highly flexible for typos and minor differences in spelling of words.
- Limitations: No semantic understanding – dependence on simple character distance methodology without incorporating semantic similarity; limited when words sound alike but are spelled differently.
Despite its limitations, this type of fuzzy matching has a ton of implementations in SEO, like 404 URL mapping to live URLs, redirect mapping, identifying branded mention variations in search query data, and more.

Phonetic Matching
Phonetic approaches map words to a code approximating pronunciation so that differently spelled words that sound alike collide.
- Typical algorithms: Metaphone (and Double Metaphone). This algorithm excels in performance for handling various errors, including misspellings and letter additions/absences, especially for languages other than English.
- Use cases: Multilingual or noisy data where pronunciation varies; handling homophones and cross-language spellings.
- Strengths: Catches sound-alikes that distance metrics may miss.
Limitations: The main limitation is that it does not consider semantic meaning. It is limited for words that sound alike but are spelled differently (homophones). Language-specific tuning might also be often needed
N-gram Matching
N-gram methods break text into overlapping sequences (characters or words) and compare overlap. N-gram matching aims to detect the occurrences of a fixed set of pattern arrays embedded as sub-arrays in an input array.

- Character n-grams: “elephant” → tri-grams: ele, lep, eph, pha, han, ant.
- Word n-grams (great for SEO workflows): When searching a dataset, the input string (e.g., a keyword) is broken down into fixed sets of words or characters called N-grams. For example, if the input keyword is a seven-word phrase like “what is string matching in machine learning,” it could be split into bigrams (sets of two words, e.g., “what is,” “is string matching,” etc.) or trigrams (sets of three words).
- How scoring works: Entries in your dataset get higher similarity when they contain more of the query’s n-grams.
- Similarity Metric: Jaccard Similarity is an algorithm often used in conjunction with N-gram matching.
- How to get started: scikit-learn or APIs designed for N-gram generation (e.g., NLTK).
- Strengths: Highly efficient for large datasets. Very efficient for quickly extracting data involving large patterns. Scalable. Useful for detecting partial matches, patterns, or key phrases.
- Limitations: Still surface-level; may miss paraphrases with low n-gram overlap. Can be computationally expensive for long strings or high N-gram values.
In SEO n-gram-based matching can be used for keyword clustering, short copy or metadata similarity evaluation, and even detecting plagiarism and finding long-tail SEO phrases.
TF-IDF Matching
TF-IDF String Matching is an approach that introduces complexity and contextual relevance by calculating Cosine Similarity with TF-IDF (Term Frequency–Inverse Document Frequency).
This is a well-established metric for comparing text that has been adapted for flexibility, specifically for matching a query string with values in a singular attribute of a relation.
- What it adds: Goes beyond raw string distance by down-weighting common words and up-weighting distinctive ones across your dataset. TF-IDF fundamentally analyzes the corpus of words as a whole. It weighs each token (word) as more important to the string if it is less common in the corpus.
- How to get started: scikit-learn or gensim Python libraries are examples of tools that can be used for TF-IDF matching.
- Strengths: Well-established, effective for lexically similar but not identical text; simple to implement and tune.
- Limitations: It does not capture semantic similarity. It is slower for high-accuracy configurations. It requires preprocessing.
Hybrid Approaches
In practice, combining methods improves results. For example, mix Levenshtein (to handle misspellings) with Metaphone (to catch sound-alikes) so you cover both typographical and phonetic variation. You can also chain stages: generate candidates with n-grams/TF-IDF, then refine with a distance metric, and finally apply business rules (e.g., thresholds) to balance recall and precision. If one methodology underperforms, iterate toward a hybrid architecture that better fits your data and goals.
The practical implementation of these algorithms is extremely beginner-friendly through readily-accessible Python libraries like FuzzyWuzzy and RapidFuzz, which allow users to choose and stack methods.
How fuzzy matching is used in traditional search engines
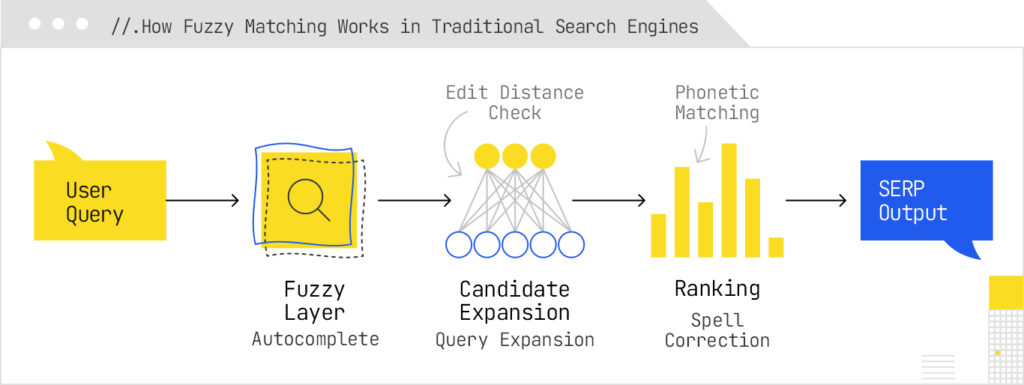
Error handling
Fuzzy matching is the first line of defense against messy input – typos, transpositions, missing characters, mixed scripts. Large engines correct queries by combining edit-distance style candidates with corpus/context signals (“did you mean…”) so users avoid dead ends. Specific techniques include classic spelling correction, tolerant autocomplete, and resilient entity lookup, which all lean on edit-distance, phonetic, and n-gram methods to recover intent and avoid empty SERPs. In more advanced stacks, error tolerance is fused with semantic understanding (e.g., knowledge-graph reasoning) so the system can still retrieve the right entity even when the query is malformed – an approach sometimes described as fault-tolerant semantic search.
On desktop search, Google implements context-weighted spell-checking for queries, while Microsoft dynamically corrects as you type to handle errors. On mobile systems, it automatically detects keyboard type and uses key-proximity and layout–aware rules to re-rank candidate keys that are physically near on a keyboard, improving the precision of the suggested spelling corrections without adding latency.
Broadening search scope
Beyond fixing errors, engines use fuzzy logic to expand or rewrite queries to improve recall. Google’s augmentation query filings describe issuing extra, related sub-queries and merging or re-ranking their results. Engines expand queries with near-matches (inflections, spelling variants, transliterations), and also with history or session context, by adding related terms or time hints. Recent work on personal history–based retrieval shows that vague, “fuzzy” prompts (e.g., “that chess article I read last week”) can be resolved using similarity thresholds and soft time filters, even in voice mode. This is query expansion in action, guided by context rather than just keywords.
Fuzzy matching is also used to improve search results when users have mistyped part of the query in a different script. Search systems might often generate a parallel transliterated or cross-language query variant as a query expansion to boost recall on multilingual queries, where the user has typed a brand or entity name in the wrong script (e.g., Latin vs. Cyrillic)
User experience
Autosuggest is the most visible fuzzy UI layer in search: partial inputs trigger suggestions that may include spelling variants, synonyms, related entities, and direct-to-result shortcuts. Google and Microsoft patents cover predicting completions and surfacing suggested results alongside queries to help users navigate directly.
Information retrieval
Operationally, fuzzy signals are used at the time when candidate queries are generated to boost recall (character/word n-grams, phonetic hashes, edit-distance lookups), then re-weighted in ranking against lexical (BM25/TF-IDF) and semantic features. This layered retrieval reduces miss-rate on long queries and tail entities while preserving precision.
Google’s query augmentation patent filings describe how these expansions create multiple candidate sets, which are then merged and scored by the ranker. This two-phase architecture (first broaden, then score/merge with thresholds) aims to filter out noise in SERPs before surfacing pages in the rankings. Another technique used to avoid flooding results with similar pages that relies in part on fuzzy matching is near-duplicate detection, which is done via techniques like fingerprinting, shingling, or simhash collapse to identify redundant candidates. This allows for query expansions to improve coverage without cluttering the SERP or wasting computation on duplicates.
User context segmentation
People search in many languages and scripts, and the names of products or entities they mention rarely appear in consistent forms. Engines normalize this across these contexts using culture-sensitive fuzzy pipelines: patents describe culture-aware name regularization, different scripts, romanization/transliteration, and cross-language suggestions to map “different looking” but equivalent strings to the same entity.
Voice search optimization
Voice introduces its own fuzziness—automatic speech recognition (ASR) errors, homophones, and vague temporal references (“last week”). Phonetic matching (e.g., Double Metaphone–style coding) and tolerant time windows help bridge the gap between what was heard and what was meant. History-aware systems even apply fuzzy time ranges (“last week” ≈ last ~2 weeks) to align with human memory, especially in voice assistants.
Google’s patents describe turning ASR n-best hypotheses into weighted Boolean queries so retrieval can still succeed even when the transcript is uncertain. There are also fuzzy-logic-derived pipelines in place for when people code-switch (or otherwise talk or search, mixing words from different languages), using transliteration and cross-language suggestions to reduce ASR brittleness and retrieval misses for bilingual users.
Together, these patterns show how traditional search uses fuzzy matching to repair, expand, and contextualize queries – improving robustness, discoverability, and ultimately the user’s path to the right result.
How fuzzy matching is used in LLM-based search

Similarly to how fuzzy matching is used in traditional search engines, LLMs don’t really do fuzzy matching in the traditional sense (edit distance, n-grams, phonetic coding) inside their core generation model. Instead, fuzzy techniques show up in two places around the LLM – the RAG pipeline and via semantic embedding matching for similar strings.
During Prompt Processing: Error Correction and Query Reformulation (Expansion, Synonyms, Paraphrasing, Text-to-Text Transformations)
When the LLM itself interprets your query:
- It tokenizes input. Subword tokenizers (like Byte Pair Encoding) naturally handle misspellings and variants somewhat fuzzily – e.g., “chattbott” is split into known sub-tokens that still relate to “chat” + “bot.”
- It handles typos, mistakes, and other language variants. The model’s pretraining also exposes it to tons of noisy, user-generated text (typos, informal language), so it was introduced to fuzzy tolerance during training.
Some systems explicitly add an LLM-based query rewriting step: the LLM takes a noisy input and rewrites it into a cleaner, canonical query before retrieval. This replaces traditional fuzzy edit-distance spell correction with a neural equivalent.
Many RAG systems include a query rewriting or paraphrasing step before retrieval, one example being the advanced technique Rewrite-Retrieve-Read, which, explained simply, generates a rewritten query, then retrieves data, then feeds to the reader. The goal is to turn the user’s possibly awkwardly-typed or under-specified query into one or more reformulated queries that better match the text in the knowledge base. This can insert synonyms, reorder structure, or break a complex request into simpler sub-queries, or expand it to capture follow-up questions (e.g. Query Fan Out).
However, LLM-based query expansion is not perfect. When the LLM lacks knowledge about the domain or the user’s input is ambiguous, expansion may hurt performance by introducing irrelevant or misleading terms.
For Finding Relevant Candidate Documents and Text Processing: Retrieval Augmented Generation (RAG)
When you use an LLM with retrieval (e.g., in RAG pipelines), you first fetch documents or passages from a database before generation.
Even here, fuzzy matching still plays a role:
- The system implements lexical fuzzy search: Some hybrid systems continue to incorporate edit-distance, n-grams, or phonetic matching in candidate retrieval to tolerate typos, OCR noise, or format errors.
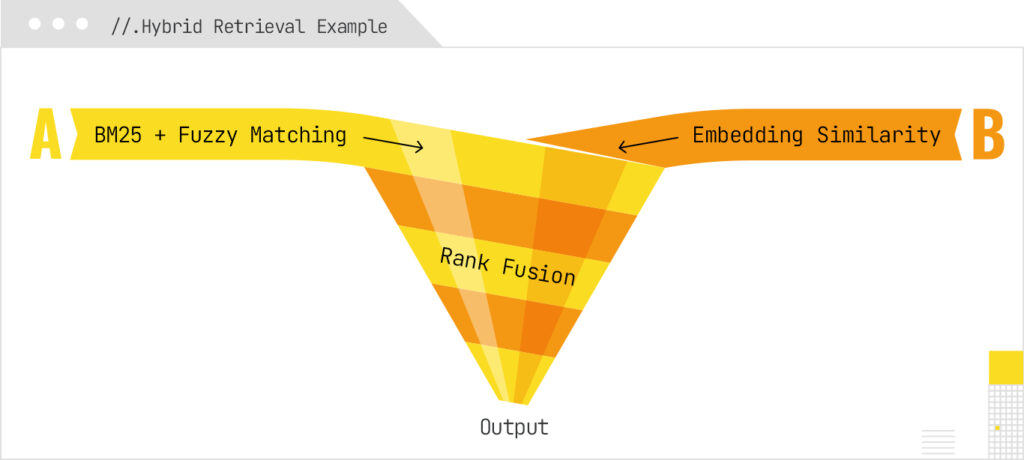
- The system might retrieve documents using a Hybrid approach: A common architecture is:
1. Generate candidates via BM25 and fuzzy string matching (fast, recall-heavy)
2. Generate candidates via vector embeddings (semantic similarity)
3. Merge/rerank them (e.g. via Reciprocal Rank Fusion or weighted fusion)
This layered approach helps the retriever recover answers that would otherwise be missed due to spelling mistakes, synonyms, or paraphrase-level mismatch.
Systems like Perplexity AI explicitly describe combining “hybrid retrieval mechanisms, multi-stage ranking pipelines, distributed indexing, and dynamic parsing” in their architecture, using both lexical and semantic signals. Google’s AI Mode, on the other hand, uses Query fan-out, which benefits from overlapping fuzzy and semantic matching layers for generating the different query variants.
AI Research demonstrates that models combining lexical and distributed (semantic) representations into an architecture (e.g., learned sparse retrieval) outperform either alone.
Inside the Embedding Layer: Embedding-Based Matching (Semantic Fuzzy Matching)
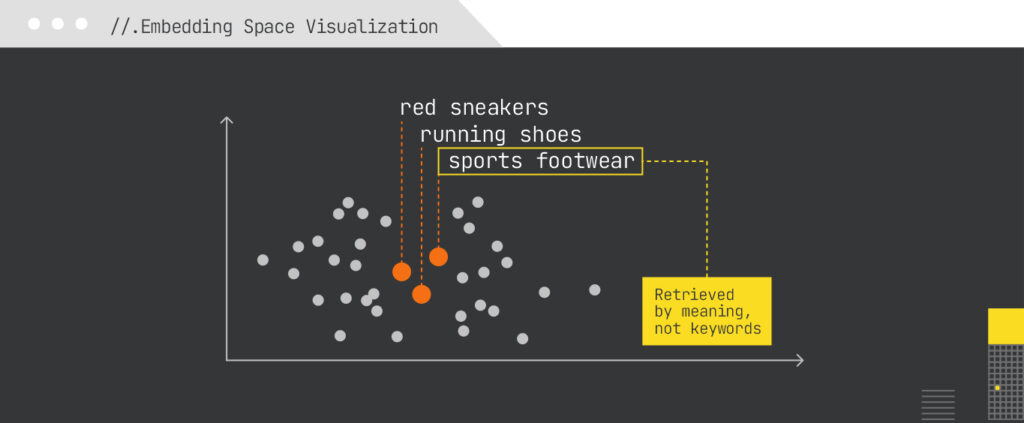
In LLM pipelines, embedding-based matching is the primary fuzzy mechanism of retrieval, enabling content discovery beyond exact keyword overlap.
The core “fuzziness” in modern LLM-based retrieval is based on vector embeddings. Both the query and candidate documents/knowledge chunks are embedded in high-dimensional space; similarity (via cosine distance or other metrics) helps match semantically related content even when literal words differ.
Because embeddings map synonyms, entities with different mention formulations, paraphrases, morphological variants, and contextually similar expressions close together, this acts like a fuzzy matching layer – but at meaning level rather than character-level.
For example, OpenAI’s search patents emphasize that retrieval is shifting from keyword matching to vector-based matching on content chunks.
In Document Selection and Response Generation: Personalization
Personalization is a real axis in LLM pipelines, influencing both retrieval (which passages are surfaced) and generation (how they are used).
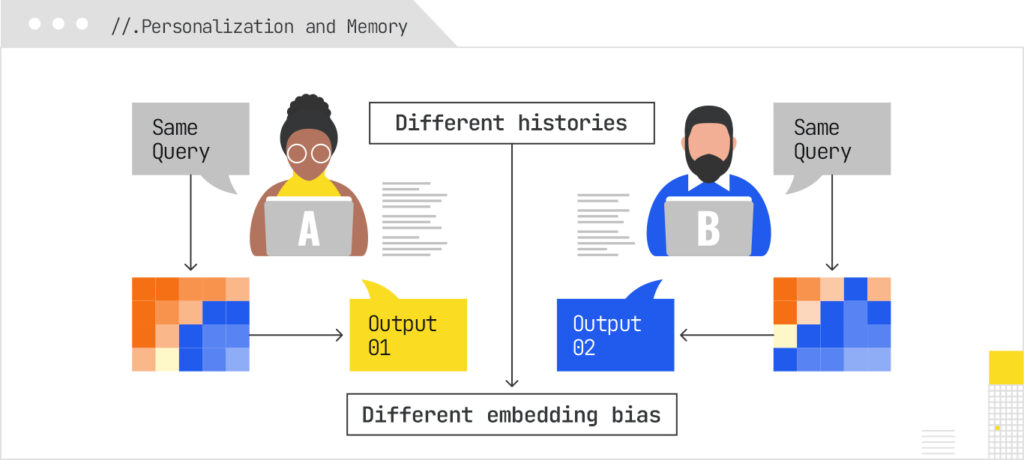
Personalization in LLM-based systems often occurs via user embeddings and memory. In AI Mode, the user’s past queries, preferences, and behavior are embedded and influence which retrieved documents are preferred or how results are weighted. For example, systems may be biased toward content that aligns with the user’s embedding. Note that this is not very different from how traditional search engines utilize individual user context as a preference layer based on past content types that the user engaged with. When in chat-mode, AI search can also incorporate memory or prior dialog context (context memory), so the same query by different users might produce different responses despite the core search intent and question asked being identical.
Aspect | Traditional Search (Google/Bing, IR systems) | LLM-based Pipelines (RAG, embeddings, LLM generation) |
Core technique | Explicit fuzzy algorithms: edit distance (Levenshtein), phonetic codes (Soundex, Metaphone), n-grams, TF-IDF. | No edit-distance or phonetic codes inside the model; instead relies on vector embeddings for semantic similarity. Fuzzy logic introduced during training. |
Error handling | Spell correction, “Did you mean…?”, tolerant autocomplete (typos, transpositions, omissions). | LLMs tokenize noisy inputs into subwords; embeddings smooth over spelling variants. Sometimes add an LLM-based query rewriting step for correction. |
Query expansion | Augment with synonyms, spelling variants, query history; broaden recall with n-grams and expansion rules. | Semantic expansion via embeddings (similar meaning queries cluster in vector space). LLMs can also paraphrase queries before retrieval. |
Candidate retrieval | BM25 and fuzzy match used to generate candidate sets, then ranked by relevance. | Hybrid retrieval: BM25/fuzzy search and vector embeddings, merged with rank fusion (e.g., Reciprocal Rank Fusion). |
Voice & noisy input | Phonetic matching, n-best ASR hypothesis handling. | Embeddings and LLM tolerance for noisy phrasing; LLMs can normalize speech outputs semantically, not just lexically. |
Context sensitivity | Some personalization (query history, language normalization, transliteration). | Embeddings naturally capture paraphrases & cross-lingual similarity; LLMs can also normalize names/entities via rewriting prompts. |
“Fuzzy” nature | Character- or token-level approximation (distance, phonetics). | Semantic fuzziness: embeddings collapse lexical, morphological, and paraphrastic variants into nearby vector space. |
Goal | Ensure users don’t get “zero results” because of spelling errors or lexical mismatch. | Ensure LLM has access to the most semantically relevant passages, even when queries are messy, and then generate a coherent response. |
How to get started with fuzzy matching to improve your organic search visibility (SEO and GEO) - Practical Projects and Quick-starts

Some of the most common pitfalls when optimizing content for discoverability:
- Over-optimizing for one phrasing may reduce embedding cohesion, while too many variants can dilute embedding signals.
- Relying solely on LLM-based paraphrase matching is risky: an LLM-based query expansion showed it can degrade performance for ambiguous or domain-poor inputs.
- Personalization may favor content “close” to a user’s past behavior – new or niche content may need stronger signals to break through.
Strategies
Here are strategies to make your content more discoverable in pipelines combining fuzzy methods and LLMs:
|
Goal / Problem |
Tactic |
Why It Helps in Fuzzy and Semantic Pipelines |
|
Surface in query-rewrite pipelines |
Use multiple phrasings / paraphrases / synonymous expressions within your content (e.g. in FAQs, subheadings) |
If the rewriting step paraphrases user input, having variant phrase forms ensures your content is reachable under those alternate rewrites. |
|
Embed well as retrieval target |
Write clear, self-contained passages (≈ 100–300 words) that can be chunked and embedded independently |
Dense retrieval favors semantically coherent chunks; if your passage is too diffuse, embeddings may mismatch. |
|
Anchor entity / keyword variants |
Use canonical names and aliases, multi-script forms, transliterations, synonym lists (in structured data or in-body) |
Embedding and fuzzy rewrites will map variant forms to your content; this improves recall for users using alternate names or scripts. |
|
Signal context / intent explicitly |
Include context terms, qualifiers, and related keywords in the same passage (“for small businesses,” “in 2025,” etc.) |
Retrieval and rewriting benefit from overlap in secondary keywords to anchor intent, reducing ambiguity. |
|
Personalization alignment |
Create personalized paths (e.g. by persona or vertical) so that your content can match user embeddings better |
If your content matches one persona’s profile closely, it may be favored under retrieval weighting in personalized systems. |
|
Guard against hallucination mismatch |
Ensure that key facts (dates, names, figures) are explicit and unambiguous in content |
The LLM uses retrieved passages to ground its response; if your content is vague, the LLM may hallucinate or misalign. |
|
Measure selection, not just ranking |
Track inclusion in RAG pipelines (was your content retrieved or not), not just SERP rank |
In LLM pipelines, being “retrieved” is step zero — if you are never picked as a candidate, you have no chance to be used. |
Practical Projects
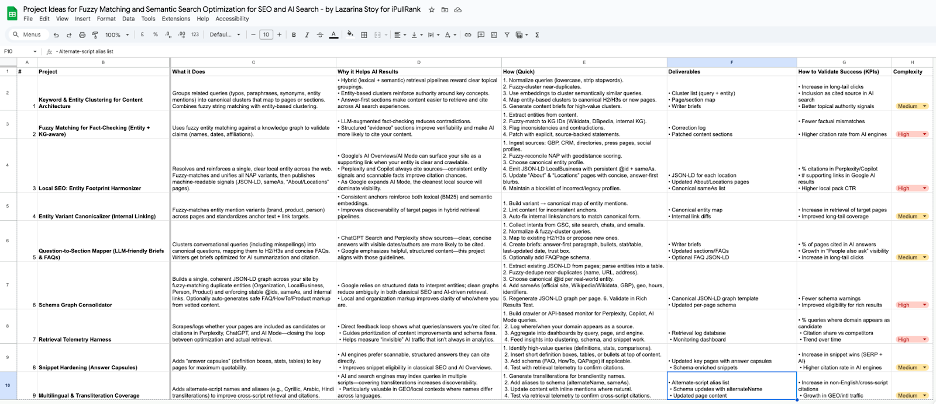
I’ve organized nine practical projects for you to get started with optimizing your content and technical site workflows, for traditional and AI search systems alike.
Here are the top three that you should prioritize, and why:
- Question-to-Section Mapping – AI systems cite passages that are short, self-contained, and unambiguous. Mapping clustered, fuzzy variants of questions to answer-first H2/H3s and tight FAQs makes your content better prepared to be cited. It also aligns perfectly with hybrid retrieval architectures discussed earlier.
- SEO Entity Footprint Unification – For local/topical entities, AI systems need a single, confident referent. Fuzzy-reconciling NAP variants (name/address/phone) and emitting machine-readable signals (JSON-LD LocalBusiness with stable @id, sameAs, hours/geo) makes it easy to ground and safe to cite.
- Schema Graph Consolidator – AI pipelines benefit from clear, machine-navigable entity graphs. A single, deduped JSON-LD graph reduces ambiguity across Organization/LocalBusiness/Person/Product and strengthens cross-page signals that retrieval can trust.
These three projects directly improve the two signals AI systems rely on to cite you:
- Extractable, high-confidence answers: tightly scoped, answer-first sections that an LLM can lift into its output without risk.
- Unambiguous entity grounding: consistent identifiers and machine-readable signals that reduce ambiguity about who you are, where you are, and what you do.
Everything else is also useful, but more of a subset or multiplier once you have a solid base.
See all the suggested projects in this sheet
How can you use Fuzzy Matching?

Fuzzy matching is for candidate generation, not the final decision. Use edit distance, n-grams, or phonetics to repair and expand messy inputs, then let semantic rankers select what matters.
Hybrid retrieval is the default. Engines expand queries both lexically and semantically. Content that aligns with entity attributes, comparisons, and clear facts is more likely to be retrieved and cited.
Build answer-first hubs. Create one authoritative hub per entity. Link supporting pages back with the canonical label and merge duplicates quickly so signals converge.
Expect citation differences. Personalization approaches will continue evolving.
Overall, fuzzy matching is not only a foundational approach but also useful and integrated widely, not only in traditional search but also in AI search retrieval systems. Utilize it as part of your toolkit to better research, plan, and structure content at scale and organize your technical infrastructure to be better understood by LLMs.








