
Large websites are a behemoth to govern. Your enterprise website is governed by many stakeholders. The larger the enterprise, the more complicated the sense of ownership.
Tragically, sometimes the employees who are able to make game-changing enterprise technical SEO decisions don’t understand the first thing about their problems in the first place. Technical SEO issues are common on large websites.
Your enterprise shouldn’t have a problem with technical SEO.
Large sites have been active longer. You have a bigger budget and more people. There’s a significant amount of domain authority; many large sites have relationships with Google (Google favors brands after all) and plenty of clout.
When it comes to organic search, large established brands have an unfair advantage, right?
In some ways, it’s true.
So what’s the problem?
Many established brands aren’t achieving the kind of traction they need to remain competitive in search over the long term. They have legacy tech that’s weighing them down.
Too frequently, large sites run into similar problems and we’re going to tackle them today:
Let’s look at some of the top technical SEO issues these large sites face.
Misusing your crawl budget
Before we dive into this, we need to define our terms. To address the crawl budget challenge, let’s explain it properly.
Your crawl budget refers to the number of pages Googlebot is set to crawl over a set period of time.
According to Google, “Googlebot is the general name for two different types of crawlers: a desktop crawler that simulates a user on desktop, and a mobile crawler that simulates a user on a mobile device.”
Googlebot stops crawling your web pages, packs up, and moves on to a different domain when your crawl budget is used up. Google is the only one who knows about the specific resources they’ve allotted to your site. However, Google relies on specific criteria when allocating the crawl budget for your site.
- Crawl health: Factors like page speed, server response times, compression, etc., are factored into the equation. Google explains why crawl health is such an important criterion: “If the site responds really quickly for a while, the limit goes up, meaning more connections can be used to crawl. If the site slows down or responds with server errors, the limit goes down and Googlebot crawls less.”
- Popularity: According to Google, popular URLs are crawled more often in an effort to keep Google’s index fresh. Google tends to revisit updated pages more often, especially if they’re popular.
- Staleness: This is more about the frequency of your updates. Pages and content that receive regular updates receive regular visits from Googlebot. Google attempts to prevent URLs from becoming stale in their index.
- Links: This includes factors like your internal linking structure (including inbound and outbound links), dead links, redirects, etc.
- Limits set: Google allows website owners to reduce Googlebot’s crawling of their site. Here’s the thing with that; setting higher limits doesn’t automatically mean you’ll receive a bigger crawl budget.
So why is this a challenge?
Google feels too many low-value-add URLs negatively affect your site’s crawling and indexing. They sorted these low-value URLs into a few specific categories:
- Faceted navigation and session identifiers: An example of faceted navigation would include filter by price, size, or color options. An example of session identifiers would be user tracking information stored through URL parameters. These are problematic because it creates different URL combinations, creating an issue with duplicate content.
- On-site duplicate content: Google defines duplicate content as “substantive blocks of content within or across domains that either completely match other content or are appreciably similar.” This comes with some significant downsides, including decreased link popularity, unfavorable rankings, lower clickthrough rates, and poor visibility (due to long tracking or session ID URLs).
- Soft error pages: We’re all aware of 404 errors. Both visitors and search engines are notified that the web page they were looking for does not exist. Soft 404 errors aren’t quite as clear-cut. With a soft 404, visitors see an error page, but search engines see a 200 OK status, giving Google the go-ahead to crawl this page; this is no good.
Soft error pages exhaust your crawl budget; Googlebot spends more time on these low/no value pages and less time on pages that produce value. This leads to poor rankings and a marked decrease in search visibility over time. Typically this is fixed by restoring deleted pages or creating 301 redirects pointing to the page(s) most relevant to your searcher’s query.
- Hacked pages: Google defines these pages as “any content placed on your site without your permission as a result of vulnerabilities in your site’s security.” Google works to keep these pages out of their search results because it diminishes the quality of Google’s SERPs (obviously).
Here’s a detailed breakdown from Google Search Central.
Google focuses much of its attention on the injection of URLs, content, or code.
- Infinite spaces and proxies: According to Google, infinite spaces are pages with a very large number of links, for example, the “Next Page” links that continue forever). These links offer little to no new content. Crawling those URLs means Googlebot uses an unnecessary amount of bandwidth, increasing the odds that Google won’t be able to index your site content completely.
Dynamic URLs, session IDs, additive filtering (see above), dynamic document generation, and broken links all contribute to this problem. Googlebot doesn’t want to index the same content forever. It wants to find new content once, index it, and then check back for updates. Infinite spaces get in the way.
There are several strategies you can take to combat this problem. You can add a no-follow attribute to links that are dynamically generated. Use robots.txt to block Googlebot’s access to problematic URLs; be sure to “specify parameter orders in an allow directive) or use hreflang to identify language variations of content.
- Low quality and spam content: You have nothing to worry about if you’re creating content that follows Google’s E-E-A-T guidelines. If you aren’t, there’s a good chance you may have an issue with low-quality or spam content. Low-quality content fails to meet Google’s E-E-A-T standard; examples include an insecure eCommerce site, content that is not from an authoritative source (e.g., tax advice from a dog grooming website)
Wasting server resources on pages (or issues) like these will pull crawl activity away from pages with value, which may cause a significant delay in Googlebot discovering great content on a site.
The consequences of duplicate content
Duplicate content is cannibalism.
Your web pages compete against themselves for the same rankings and visibility, cannibalizing the value you’d receive from unique content. Each duplicate attracts a very small portion of the traffic and conversions a single authoritative source should receive. The content never reaches its full potential.
Why’s that a problem?
Some traffic is better than none, am I right?
Actually, no.
If a single web page would have received 1,800 visits per day (657K annually), but your duplicates (combined) only receive 500 per day (180K annually), that’s a 114% difference!
Let’s assume you have a 5% conversion rate on both pages.
- 657K visits = 32,850 conversions
- 180K visits = 9,000 conversions
See the problem?
This indicates a revenue leak; a tremendous amount of revenue is lost here, depending on your average order values. From duplicate content alone!
Not good.
Here’s the nefarious part about duplicate content; it happens all of the time. Let’s look at a few of the causes behind duplicate content.
Poor CMS management
It’s common for large organizations to rely on more than one CMS. You may be working with a CMS with native SEO support (or not). You may also be dealing with a CMS that produces duplicate content. For example, several modern CMS give each article a unique database ID that functions as its unique identifier (instead of the URL).
This means a single article can have multiple URLs, creating a problem for search engines that rely on the URL.
URL variations
Inconsistent internal linking often creates issues with duplicate content. This means pages like…
- example.com/page
- www.example.com/page
- www.example.com/page/index.php
… Point people and search engines to the same, exact content.
According to Google, duplicate content is typically non-malicious and can occur as a result of benign events like:
- Printer-only versions of web pages
- The same products in your eCommerce store are displayed or linked to via multiple, unique URLs
- Forums that share regular and stripped-down pages (optimized for mobile)
You can fix it by creating a 301 redirect on your “duplicate” making sure that you direct visitors and search engines to your original page. Additionally, you can use the rel=canonical attribute to outline the pages that are copies and the source you’ve designated as your original.
Using the correct prefix: HTTP vs. HTTPS
Maybe you’re:
- Switching from HTTP to HTTPS
- Moving from a subdomain (i.e., blog.example.com to example.com/blog)
- Changing domains entirely
- Working with several versions of the site (i.e., www.example.com vs. example.com).
- Switching from dev and live environments (i.e., dev.example.com vs. example.com vs. www.example.com).
Whatever your circumstance, you’ll want to address these issues appropriately.
First, designate an original or authoritative source page; consolidate all of the content from your duplicate here. Next, create a 301 redirect on your “duplicate,” pointing to your authoritative source page. This prevents content cannibalization and eliminates internal competition.
What if you need to preserve your duplicates?
Use the rel=canonical attribute to identify your web pages; this allows you to determine the original and the copies, giving Google clear direction on how to rank your web pages.
Content scraping
If you’re running an eCommerce site or in the retailing business, this is a common problem. Let’s say you sell DSLR cameras; if the manufacturer, wholesalers, distributors, and your eCommerce store all have the same product description, that’s (off-site) duplicate content.
The solution is simple. You simply bite the bullet and create unique product descriptions for each product. If you have on-site duplicate content, work to consolidate your content via 301redirects or the rel=canonical attribute.
A disorganized site architecture
Good site architecture is an important must-have for large websites. This is important for two reasons.
- Site architecture distributes link equity (via a flat structure) throughout your site.
- Good site architecture helps Googlebot find and index all pages throughout your site.
What does ‘good’ site architecture look like?
Your site…
- Has a flat structure where people and search engines can reach any page on your site in four clicks or less
- Makes good use of category pages to create hubs
- Has a URL structure that follows your category structure (i.e., example.com/category/subcategory/keyword)
- Uses internal links to link pages and page types together (e.g., navigation pages > category pages > individual pages)
- Use HTML for navigation and internal linking (with keyword-driven anchor text) to distribute link equity
- Add updated sitemaps to improve site “crawlability”
Here’s where this gets difficult.
Your team will need to take a frank look at your site architecture and make some decisions. Is the architecture well organized, or does it need to be completely rebuilt? If it needs to be rebuilt, you’ll need to determine how things should be reorganized and who will be responsible for doing it.
Poor internal linking
Large sites have a distinct advantage.
They have link equity.
Thanks to internal links, a certain amount of value and authority flows from one page to another. Internal linking allows you to spread your ranking power from one page to another.
Here are several factors that determine whether links will pass equity.
- Authority
- Crawlability
- Do-follow vs. no-follow
- HTTP status
- Link location
- Relevance
Why is internal linking important?
Good internal linking establishes an information hierarchy for your site; this helps Google crawl, index, understand, and rank your website. When you feed Googlebot links and descriptive anchor text, you show Google which pages on your site are most important. You give Google clarity on the topics and subtopics you cover.
Internal linking is also essential for users.
They allow users to navigate your website, improving the user experience, engagement, and time on site.
What makes internal linking challenging for large websites?
- Links buried inside plugins or applets
- Links inside un-parseable JavaScript
- Blocked links (due to the meta robots tag and robots.txt)
- Links that are hidden inside forms
- Links buried behind internal search boxes
- Too many links on one page
- I-Frames (or Frames) links
What are some internal linking best practices to follow?
- Use keyword-rich anchor text
- Link strategically to important pages
- Add links from important high-authority pages to new pages/posts you’re trying to rank
- Don’t use the same anchor text for two (or more) pages
- Use descriptive anchor text
- Place links higher on your page
- Keep link structure flat (i.e., three levels)
- Use normal DoFollow links to spread link equity from one page to another
- Use internal links to integrate orphan pages
- Use home page links (strategically) to share link equity with other pages
- Avoid using tools to automate internal link-building
- Create and link to page categories
- Add internal links to old pages
- Use parity audits to create a singular audit
- Monitor your internal links to find and fix broken links
Follow these internal linking best practices to boost SEO performance.
JavaScript SEO rendering errors
Web pages that rely heavily on JavaScript are slowly and partially indexed.
Serge Bezborodov, in his post on JavaScript SEO, outlined the problem. “If there’s a lot of dynamic content (such as lazy-loaded images, product reviews, live chat, etc.), bloated theme code, and additional server requests, JS rendering can add seconds to the time it takes for the page to become interactive for visitors — which hurts UX and Core Web Vitals.”
It gets worse.
Google has made significant improvements to its crawler, but it’s no guarantee that JavaScript-heavy content will be crawled. This is often due to issues outside of Google’s control (e.g., content blocked in robots.txt, timeouts, errors, etc.).
If content depends heavily on JavaScript but isn’t being rendered by Googlebot, you have a problem.
What sort of JavaScript problems create SEO challenges?
- Generating URLs with a hash
- Poor internal link structure (due to JS event handlers)
- Unminified JavaScript and CSS
How can you address these JavaScript challenges?
- Start with Google Page Speed Insights: Use Google’s tool to assess what real users are experiencing when they visit your site.
- Maintain On-page SEO discipline: Make certain on-page factors (e.g., unique titles and meta descriptions, image alt attributes, good internal linking, and keyword-optimized content) are managed well.
- Give Googlebot access to your JavaScript: Make sure you’re not blocking Googlebot from your JavaScript content. You no longer need to hide your JavaScript content from Google (i.e., to preserve your crawl budget).
- Optimize lazy-loading: Googlebot doesn’t scroll as we do; it resizes the page to view your content. If you rely on lazy loading, your content won’t be rendered and viewed by Googlebot. Ensure you optimize your lazy loading code to prevent rendering errors.
- Use robots.txt + JavaScript properly: You don’t want to accidentally prevent Google from indexing your content. If you’re going to use JavaScript to add meta robots tags, tread carefully. Make sure robots.txt allows Googlebot to crawl JS and CSS pages.
- Use caching to improve load speeds: “Use file versioning or content fingerprinting (i.e., main.2ba87581f.js) to generate new file names whenever code changes are made so that Googlebot downloads the updated version of the resource for rendering.”
- Follow web component best practices: Web components are a set of APIs that allows you to create reusable custom elements — with their functionality encapsulated — that you can use in websites and apps. Googlebot supports web components, but it can only see visible content in the rendered HTML. Use Google’s mobile-friendly tool to assess compliance with best practices.
- Build accessible web pages: Your web pages should be visible to those with outdated browsers, screen readers, and those who don’t support JS. Test your web pages using a text-only editor or view your web pages with JS turned off to verify accessibility.
- Use JavaScript analysis tools: Technical SEO tools like JetOctopus provide comprehensive insights into various details (e.g., JavaScript execution, requests, performance, etc.).

These best practices make it easy for Google to crawl, render, and index JavaScript-heavy pages without the added frustration that comes with errors.
A lack of context parity
Do search engines see what your searchers see?
In a previous post, iPullRank Founder Mike King discussed the issues with content parity.
“Uncovering content parity issues mirrors the approach you might take to determine whether or not you have issues with JavaScript SEO. Effectively, you’re trying to figure out what it is that a given webpage is showing to a user that a search engine crawler cannot see because the page may only be showing it in a context that differs from what search engine crawls or indexes with.”
This is the question you’re trying to answer.
But it’s one most sites fail to answer. We analyzed 5.3 million URLs in our research, and we made some surprising discoveries.
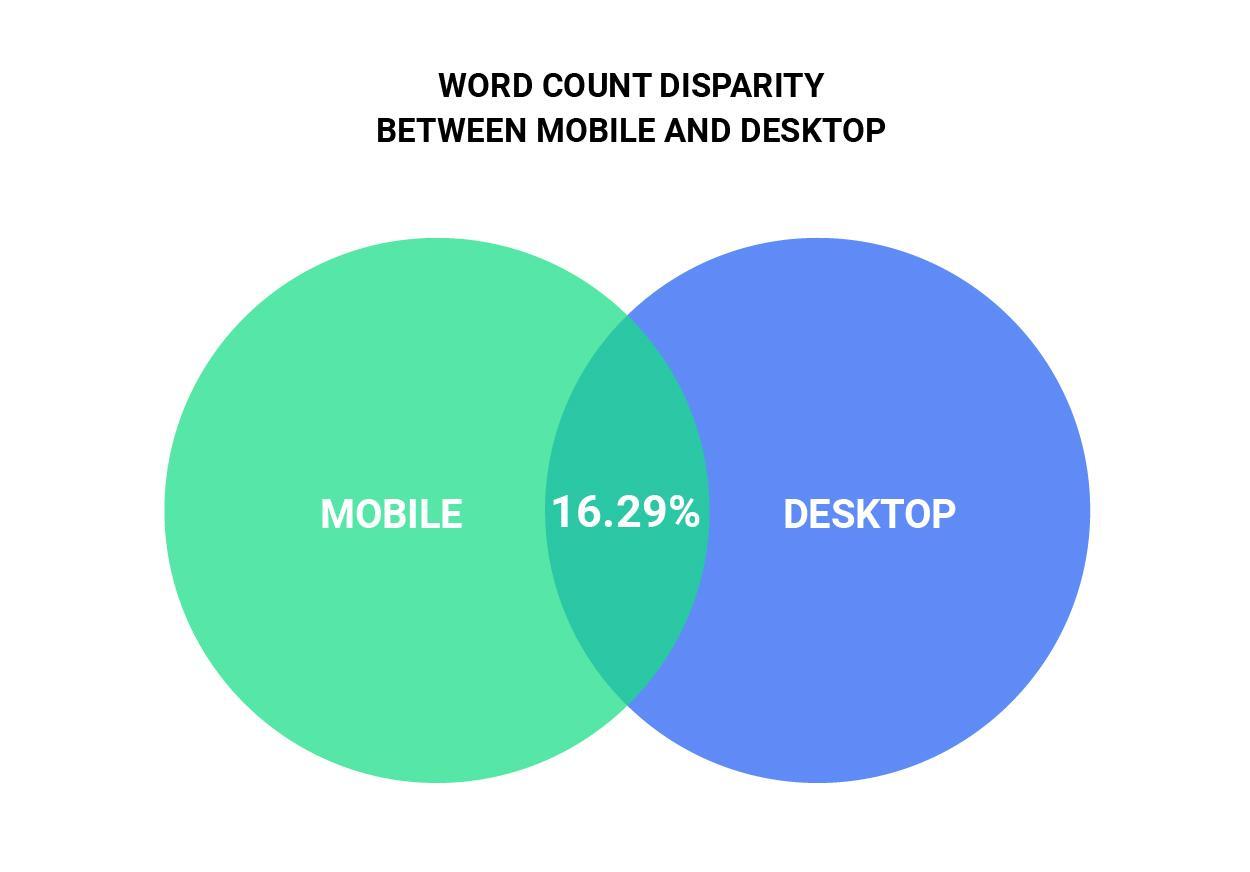
- Only 16.29% of the sites we analyzed had word count parity on both desktop and mobile
- 30.31% of URLs served a different number of internal links for desktop devices than they did for mobile devices
- 2.98% of URLs that are self-canonical on Desktop do not do so on Mobile
You’re looking to see if there are multiple versions of the same page at the same URL.
Why does this matter?
If mobile experiences have less content than desktop, Googlebot sees less of your content. If Google sees less, you receive less visibility.
This is no good.
A singular experience is best for users and search engines, as it provides everyone (users, search engines, you) with a consistent experience. So how do you verify that you’re providing a singular experience?
You conduct a parity audit.
You audit your web pages using a variety of user contexts (perspectives) to get a clear picture of how similar the desktop and mobile versions of your site are.
These contexts are:
- Desktop HTML – The raw HTML version of a web page, delivered from your server to a browser
- Desktop JavaScript – The fully rendered version of a web page, as it is seen in the browser up until the Document Ready state
- Mobile HTML – The raw HTML version of a web page is delivered from your server to a mobile device
- Mobile JavaScript – The fully rendered version of a web page, as it’s typically viewed in the mobile browser up until the Document Ready state
Google also experiences these from the perspective of Googlebot, so you’ll need a non-Googlebot version for each of the four contexts listed above. You can do this manually using tools like Screaming Frog, or you can use Parito, a tool we’ve created, to conduct your parity audit.
Misused and missing structured data
Structured data is on-page markup.
This markup helps search engines understand the information listed on your web pages providing searchers with rich, visual search results. Schema is a shared markup vocabulary that helps search engines match people to the relevant information they want.
Google uses this structured data to create rich snippets, which they define as ” A visually enhanced search result, now known as a “rich result.”
There are more than 30 varieties of Rich Snippets.
These are a few common problems when working with structured data and Schema.org.
- Using more than one language to manage structured data (e.g., JSON-LD, Microdata, or RDF). Here’s a common scenario; developers decide to use JSON-LD, SEOs decide to use Microdata or RDF on the same web page, which is no good. It’s best that everyone working with the same site sticks to the same language.
- HTTP or HTTPS? Which option is best? According to Schema.org, either option is fine, so long as you avoid using “www” as a subdomain.
- We’ve implemented NAP, but we’re not seeing search results. Your page will need to establish authority via external links, local citations, and reviews.
- Marking up text invisible to the user but visible to Googlebot. Google says this is a no-no. “Don’t mark up content that is not visible to readers of the page. For example, if the JSON-LD markup describes a performer, the HTML body must describe that same performer.”
- Your website includes an unsupported content type. Is there a workaround to address this? You could simply do nothing, choose a less specific content type, or use the schema.org extension system to define a new type.
- Is your schema.org markup correct? How can you validate this? You can use Google’s tools to validate rich results. Use the Schema Markup Validator for generic schema validation to test all types of schema.org markup without Google-specific validation.
For more common problems, you can refer to the FAQ at Schema.org.
The disaster of a mismanaged technical website migration
What’s an easy way to lose rankings, visibility, and traffic?
A large website migration.
If you’re dealing with a variety of SEO issues, migrating your website to a new environment may be an excellent way to get a fresh start. But it’s also a great way to lose rankings if it’s mishandled.
Here are a few reasons why enterprises experience a drop in traffic when they migrate their site.
- Missing metadata
- Blocked content (via meta robots robots.txt)
- Canonicalize tag changes
- Page speed/performance issues
- Internal linking issues (i.e., linking to the old site)
- External linking issues (i.e., lost inbound links)
- Google search console accessibility issues
- Redirect issues
- Hosting issues (e.g., country restrictions, firewalls, poor performance)
- Image linking issues (images linking to the old site)
Here’s how you address these technical migration issues.
- Use tools like Screaming Frog to scan your site for errors, broken links, robot.txt, duplicate content, etc.
- Use tools like ExactScience, Google Search Console, and Google Analytics to benchmark existing rankings, traffic, and conversions
- Create (or update) an XML sitemap of your current site
- Validate your XML sitemap with Map Broker
- Create a list of needed fixes (i.e., 301 redirects, broken links)
- Run a context parity audit with Parito
- Don’t allow Googlebot to index your development site content
- Create an XML sitemap and add it to your robots.txt
- Setup/update Bing Webmaster Tools and Google Search Console
- Add tracking codes to each page (e.g., Adobe Analytics, Marketo, Facebook Pixel, etc.), verify installation
- Update analytics conversion goals
- Update paid advertising (search, social, display, etc.) URLs are updated
- Update local citations, social and review profiles, and content
- Use tools like Screaming Frog to scan your new site for errors, broken links, robot.txt, duplicate content, etc.
- Disavow bad links
- Log in to Google Search Console and verify that all of your URLs (and new content) have been indexed
- Update and resubmit the XML sitemap for your new site
- Update and verify your robots.txt
- Check your rankings, traffic, and conversions
- Build new internal links to your pages
- Monitor advertising and marketing channels for a decrease in traffic
- Run parity audits
Website migration is challenging, difficult, and complex. With a careful approach, you’ll have what you need to make the transition safely, with no rankings or traffic loss necessary.
Large websites have these problems with technical Enterprise SEO
These are common enterprise SEO problems, but most of these technical challenges can be fixed.
Many established brands aren’t achieving the kind of traction they need to remain competitive in search over the long term. These technical SEO challenges are avoidable. Your organization can minimize the issues with technical SEO.
Google favors brands; large sites like yours have been active longer. You have a bigger budget, more link equity, and the team you need to solve these technical challenges.
It’s an unfair advantage.
Solving these technical challenges is all about getting the basics right. These challenges boil down to scale; give these challenges the attention they deserve, and you’ll find you can gain a significant amount of value by simply avoiding these problems.








