

Writing my book “The Science of SEO” has been incredibly eye-opening as I’ve dug deep into the minutia of how search engines work.
Fundamentally, SEO is an abstraction layer wherein we manipulate inputs (site architecture, content, and links) for a search engine to get specific outputs (rankings and traffic). At that abstraction layer, we talk about aspects of those inputs as being qualitative (good vs bad) and quantitative (PR 7 vs LCP 2.5), but a search engine is a mathematical environment, so even a qualitative feature must be quantified through a quantitative proxy.
For example, the Panda update is said to have looked at page quality and the utility of content for users and we were presented with qualitative direction on how to create better content that yields user satisfaction. However, according to the “Ranking search results” patent filed by Navneet Panda and Vladimir Ofitserov, Panda constructed a “group-specific modification factor” as a post-retrieval multiplier to augment the ranking of pages. That score was a ratio of “reference queries” to “independent links” or, in other words, the number of inbound linking root domains pointing to that page, subdirectory, or domain divided by the number of queries that directly referenced the page, subdirectory or, domain. The “Site quality score”, and “Scoring site quality” patents, further expand on this idea and introduced “user selections” (clicks and dwell time) to improve the calculation. None of these are qualitative measures of page quality. Rather, they are all measures of quantitative user behaviors that act as proxies for a scalable determination of quality based on user feedback.
It makes sense that, if a piece of content is high quality, a lot of people will link to it, a lot of people will search for it by name or URL, and a lot of people will spend a lot of time reading it.
Now, relevance is only one of many measures used in a ranking scoring function, however, it’s perhaps one of the most important query-dependent factors that inform what pages enter the consideration set.
So, how might a search engine determine relevance?
Search Engines Operate on the Vector Space Model
While there is an array of retrieval models out there, every major web search engine you’ve ever used operates on Gerard Salton’s vector space model. In this model, both the user’s query and the resulting documents are converted into a series of vectors and plotted in high dimensional space. Those document vectors that are the closest to the query vector are considered the most relevant results.
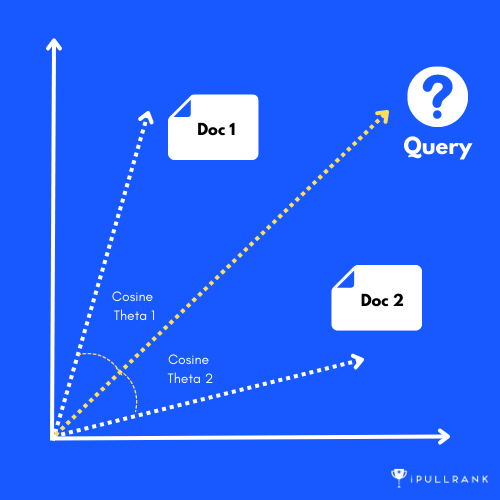
Queries and documents being converted to vectors is an indication that we’re talking about mathematical operations. Specifically, we’re talking about Linear Algebra and the measure of relevance is Cosine Similarity.
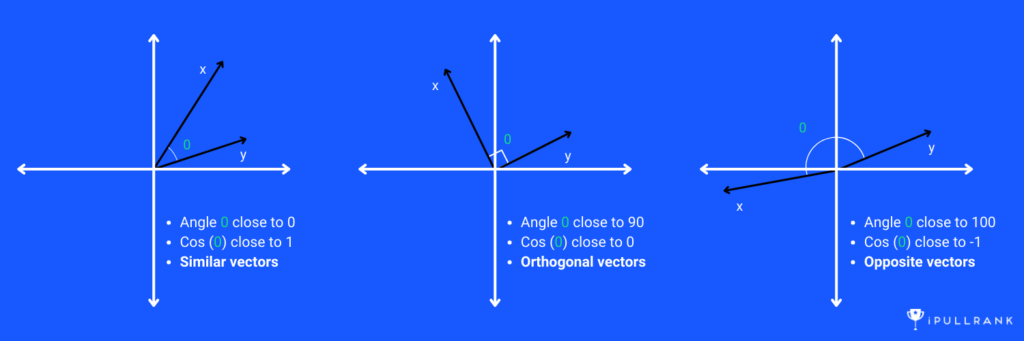
Cosine Similarity measures the cosine of the angle between two vectors, and it ranges from -1 to 1. A result of 1 indicates that the vectors are identical, 0 indicates that the vectors are orthogonal (i.e., have no similarity), and -1 indicates that the vectors are diametrically opposed (i.e. have an opposite relationship).
This is where a big disconnect lies in how we discuss relevance in the SEO community.
Often we eyeball pages and declare that we have the more relevant page than our competitors and are puzzled as to why are we not ranking better. To further confuse things, everyone’s heuristic about this is different. Some people feel that because an expert wrote it, or their page is more visually readable, or because it’s better designed it’s more relevant. While all of these measures may impact the vectorization of the page, they are all qualitative measures of something other than relevance. Complicating matters, some people believe because a page is longer, it’s more relevant. This is partially why the question about content is usually, how long should it be?
Word Vectors
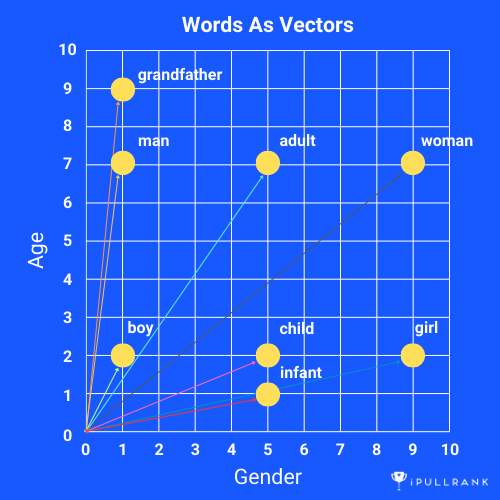
In the vector space model, we are converting words into vectors, which in its simplest form are numerical representations of words in a high-dimensional space. Each dimension corresponds to a unique feature or aspect of the word’s meaning. Word vectors capture the statistical properties of words, such as their frequency and co-occurrence with other words in a corpus (or index).
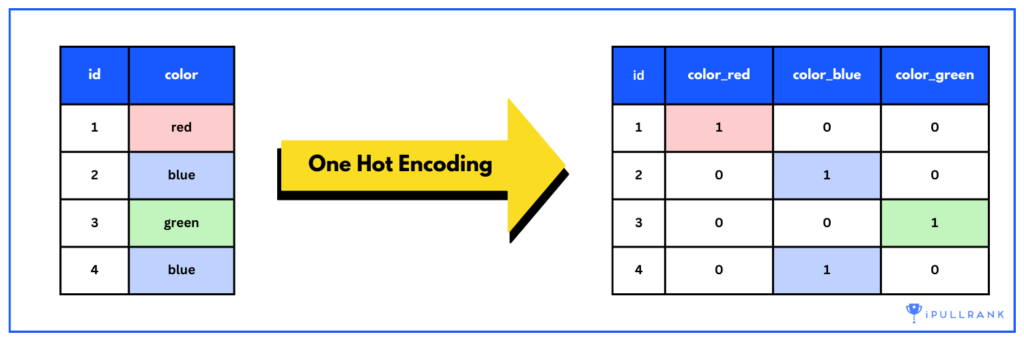
There are several techniques used to generate word vectors, including one-hot encoding, TF-IDF, and neural network-based models. One-hot encoding is a basic approach that assigns a unique vector to each word in a corpus or vocabulary. Each dimension of the vector is set to 0, except for the dimension that corresponds to the word, which is set to 1.
Bag of Words and TF-IDF
In a web search engine, the bag of words model represents a page as a collection of individual words or “tokens” and their respective frequencies. If some of this language is beginning to sound like things you’re learning about ChatGPT, stay tuned, you’ll see why in a second.
In this model, we create a “bag” of words, where the order and context of the words are ignored. For example, if we have the sentence “The dog started to run after the cat, but the cat jumped over the fence”, the bag of words representation would be {dog: 1, start: 1, run: 1, cat: 2, jump: 1, fence:1} one-hot encoded as illustrated below.
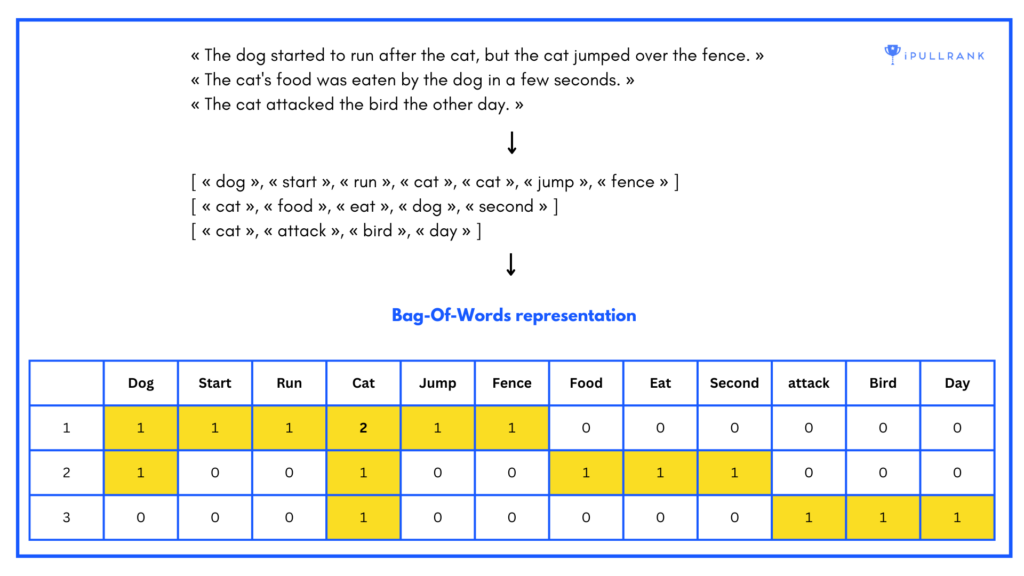
In the example, we have three sentences and each column represents the stems of the words (it’s “start” not “started”) in the vocabulary. Each cell represents the term frequency of that word in the sentence. When plotting in multidimensional space, each row could represent a vector based on the vocabulary of the document.
The limitation of the bag of words model is that it treats all words equally, regardless of their importance or relevance to the document. To offset that, the information retrieval world devised term frequency-inverse document frequency (TF-IDF).
TF-IDF, on the other hand, takes into account the importance of each word in a given document or corpus of documents. It assigns higher weights to words that appear frequently in a particular document or corpus, but less frequently in other documents or corpora.
While the OGs talked about and used it for a long time, over the past five years, the SEO community (myself included), got very loud about the TF-IDF concept. Using the idea of co-occurrence, many of us have been optimizing our content to account for those missing co-occurring terms.
Technically, this isn’t wrong, it’s just rudimentary now that Google has a stronger focus on semantic search rather than lexical search.
There are many SEO tools out there that compare a given page to those that are ranking in the SERPs and tell you the co-occurring keywords that your page is missing. Yes, this will directly impact what Google is measuring semantically, but the TF-IDF model is not a direct reflection of how they are determining relevance for rankings at this point.
Word Embeddings
The terms “word embeddings” and “word vectors” are often used interchangeably in the context of NLP. However, there is a subtle difference between the two concepts.
Word embeddings are a specific type of word vector representation that is designed to capture the semantic and syntactic meaning of words. Word embeddings are a series of floating point values generated using neural network-based models, such as Word2Vec, GloVe, and BERT that are trained on large amounts of text data. These models assign each word a unique vector representation that captures its meaning in high-dimensional space. This is the concept that underlies how the GPT family of language models works. In fact, OpenAI offers embeddings as a service in their APIs.
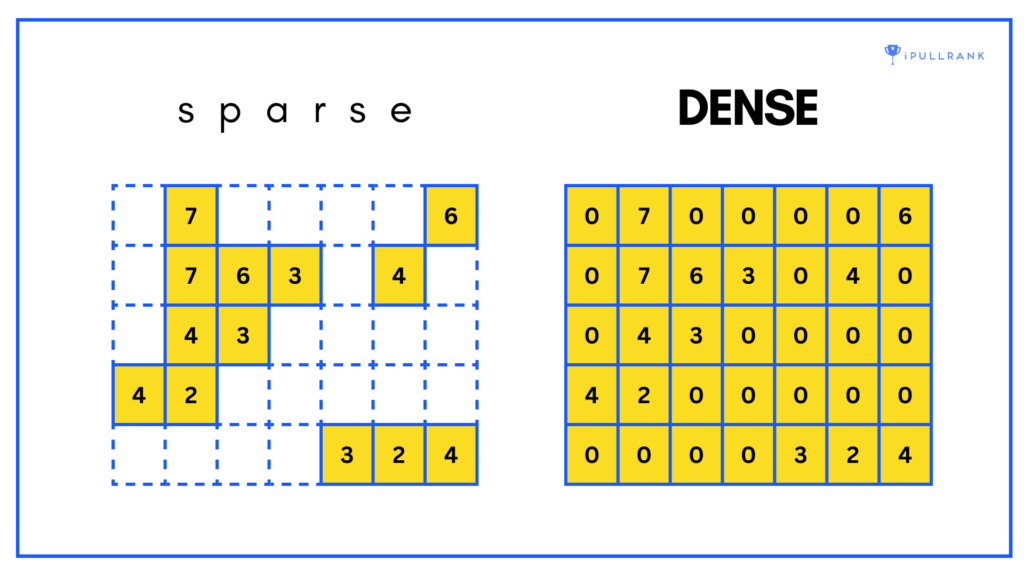
Sparse and dense embeddings are two ways of representing words or sentences as embeddings.
Sparse embeddings operate like a dictionary where each word is assigned a unique index, and the embedding for a word is a vector of mostly zeros with a few non-zero values at the index corresponding to that word. This type of embedding is very memory-efficient because most values are zero, but it doesn’t capture the nuances of language very well.
Dense embeddings operate as a mapping where each word or sentence is represented by a continuous vector of numbers, with each number representing a different aspect of the word or sentence. This type of embedding is more memory-intensive, but it captures the context and relationships within the language.
A good analogy for sparse and dense embeddings is a photo versus a painting. A photo captures a moment in time with precise detail, but it may not convey the depth and emotion of the subject. You don’t see the emotion in the brush strokes that the painter or the multiple dimensions of the scene. Whereas a painting is a representation of the subject that is more abstract, but it can convey more nuanced emotions and details that are not captured in a photo.
Dense embeddings unlock a lot of features and functionality in search that were far more difficult under the lexical system. If you remember when Google mentioned passage indexing a few years back, this is the idea of what they call aspect embeddings where the relevance of features of a page can be reviewed and scored when performing different retrieval operations. This is why Google’s featured snippets have gotten so much better and they are able to highlight down to the specific sentence.
Word2Vec (or the moment Google left SEO behind)
It’s worth taking a step back to show how we got here. In January 2013, Tomas Mikolov, Kai Chen, Greg Corrado, and Jeff Dean shared their “Efficient Estimation of Word Representations in Vector Space” which gave the NLP world the then-novel neural network architecture known as Word2Vec.
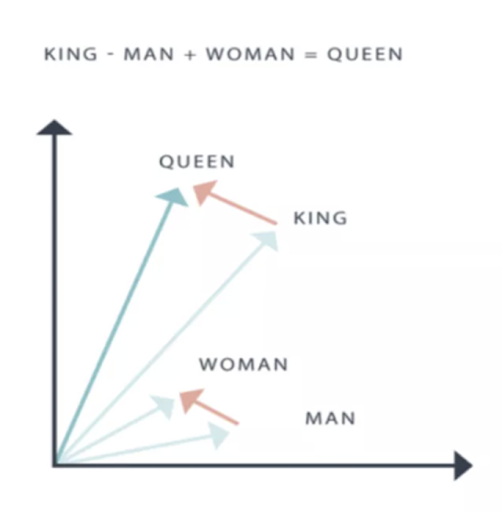
In that paper, they highlighted that, with the embeddings they generated using Word2Vec, one can do simple mathematical calculations to encode and uncover semantic relationships. Famously, they showcased how subtracting the vector for the word “man” from the vector for for the word “king” and adding the vector for the word “woman” yielded a vector that was closest to the word “queen.”
These mathematical operations held across many word relationships. In the examples below we see this for verb tenses and the relationships between countries and their capitals in high dimensional space.
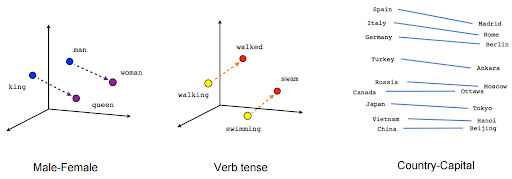
Word2Vec was a significant leap forward, it had a key shortcoming in its ability to understand context and meaning accurately. One of the primary reasons for this is that Word2Vec uses a technique called a “skip-gram” to predict the surrounding words of a target word based on its position in a sentence. This technique assumes that the meaning of a word is determined by the words that surround it, without taking into account the broader context of the sentence or document.
Despite this shortcoming, this is where Google began to move from the lexical model and really unlocked the semantic model thereby leaving the SEO community in the dust. It’s quite shocking that our SEO tools have still been just counting words all this time when such a leap forward has been available open source for 10 years.
Now let’s talk about BERT.
BERT
Google’s Bidirectional Encoder Representations from Transformers (BERT) is a pre-trained NLP model that revolutionized the field. BERT is based on the Transformer architecture, a type of neural network that is particularly well-suited for sequence-to-sequence tasks such as machine translation and text summarization.
What sets BERT apart from previous NLP models is its ability to generate dense vector representations of words and sentences. Unlike earlier models that used comparatively sparse word vectors, BERT is able to capture the meaning and context of a sentence in a dense, continuous vector space. This allows the model to better understand the nuances of language and provide more accurate results for tasks such as search, text classification, sentiment analysis, and question answering.
BERT was trained on a massive corpus of text data, including web pages, books, and news articles. During training, the model learned to predict missing words in a sentence, based on the words that came before and after the missing word. This task, known as masked language modeling, allowed the model to learn the relationships between words and their context in a sentence.
BERT also introduced another technique called next sentence prediction, which helps the model to understand the relationship between two consecutive sentences. This is particularly useful for tasks such as question answering and natural language inference.
Google Search was one of the first applications to benefit from BERT’s improved performance. In 2019, Google announced that it had implemented BERT in its search algorithms, allowing the search engine to better understand the meaning behind search queries and provide more relevant results. BERT’s ability to generate dense vector representations of words and sentences allowed Google Search to better understand the nuances of language and provide more accurate results for long-tail queries, which are often more conversational and complex.
The Universal Sentence Encoder
Google’s Universal Sentence Encoder (paper) is a language model that is capable of encoding a sentence or piece of text into a dense embeddings. These embeddings can be used for the same various tasks that we discussed with BERT.
In fact, I don’t know that I need to go into any more technical detail. Just know that it can be used to generate valuable embeddings for semantic search and it’s open source.
Introducing Orbitwise
Knowing that Google is using dense embeddings for so many aspects of its ranking systems, I’ve gotten frustrated with how SEO tools are still trapped in the lexical dark ages. So, we’ve built a free tool called Orbitwise (orbit + bitwise) to calculate relevance using the vector space model and Google’s Universal Sentence Encoder.
At this point, Google has an array of language models to choose from, so there’s no telling which one is actually in production in Search. However, since we’ll never have exactly what Google has for any SEO use case, we should all agree that SEO tools are about precision, not accuracy. That is to say, even if we’re not using the same language model as Google the relative calculations between pages should be similar.
Let’s jump into an example to show it works.
The [enterprise seo] example
Just like any other marketer, I feel our enterprise SEO landing page is more relevant than the pages that rank above it and definitely better than the page that ranks #1. Like you, my position is mostly a feeling that I have after power-skimming their headings rather than actually reading the copy.

When we think through the lens content versus links, the question is what do we do now to improve our position? Optimize the content or build more links? This is exactly the time to fire up Orbitwise.
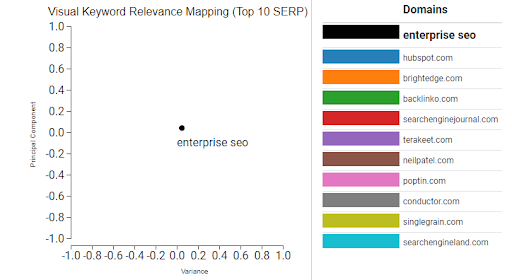
Orbitwise takes your query and converts it into a 512-dimension embedding to use for comparison against the embeddings that are generated for the documents. The tool then performs cosine similarity between the query and each document to determine relatedness. We also calculate a percentage of similarity and reduce the dimensionality of the embeddings and place them in 2D space for a simplistic visualization.
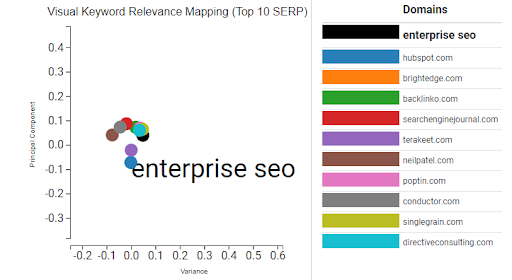
The dots are often clustered quite closely, so it’s best to use your mouse wheel to zoom in and understand the distance because a small difference means a lot to the calculation.
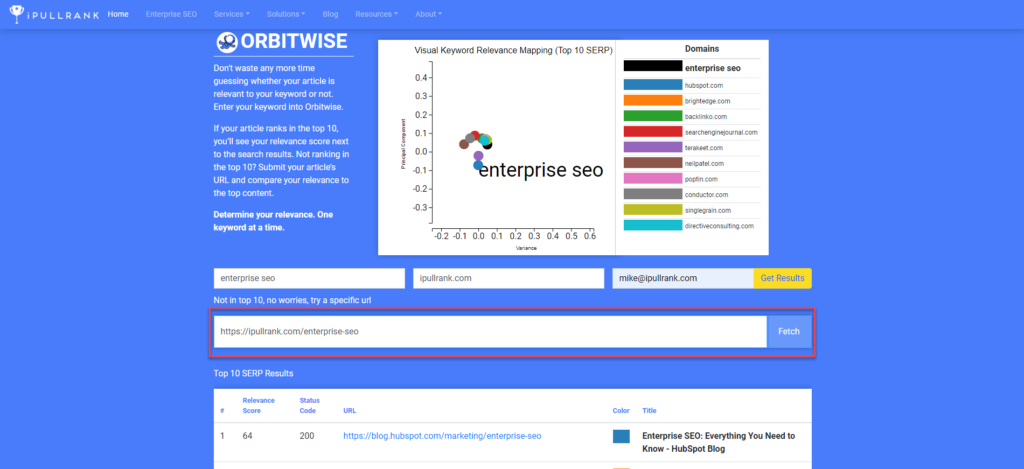
Since my page does not rank in the top 10, I need to pull it separately by entering it in the input box below. Once I’ve done that, my page is added to the chart and the table.
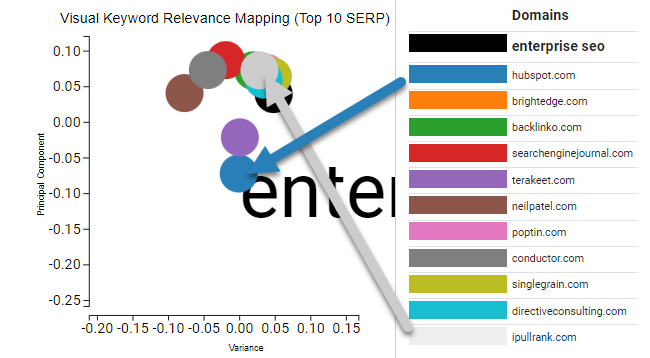
Zooming in clarifies that my page has very high relevance with the query since it’s overlapping the black dot whereas the number one ranking page has much lower relevance.
Interpreting the results
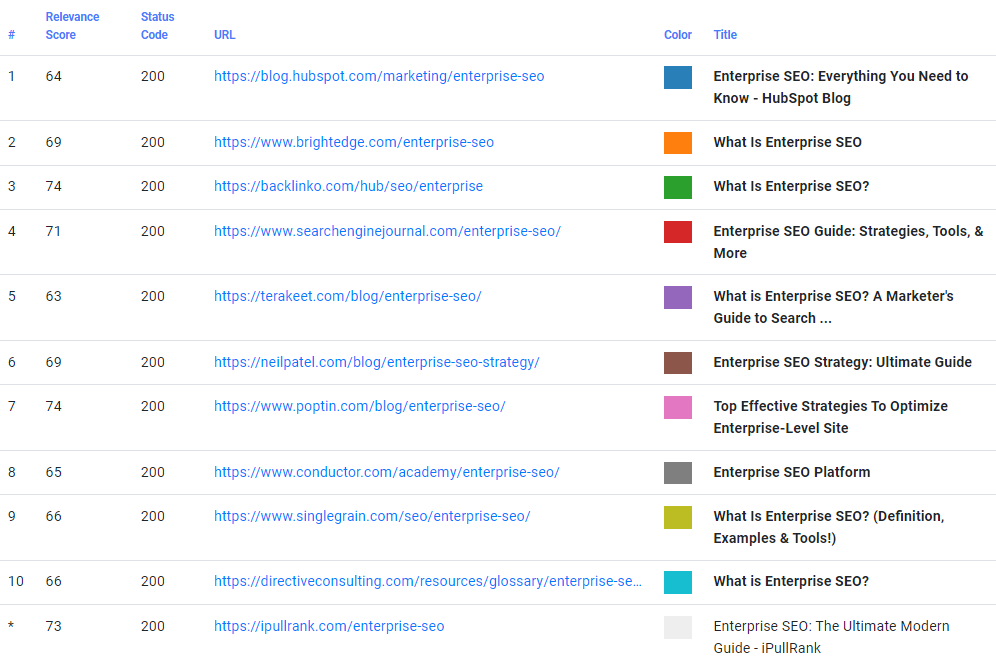
Now we have our results. In the column on the left, we have a percentage of relevance between the URL and the query. Comparing my landing page to the number one result makes it immediately clear that my page’s issue is not relevance since they have 64 and we have 73.
Looking at these in the context of link data from Ahrefs helps me definitively know that the problem here isn’t relevance or content optimization, but authority. So, go ahead and link to our enterprise SEO page, whenever y’all are ready. 😁
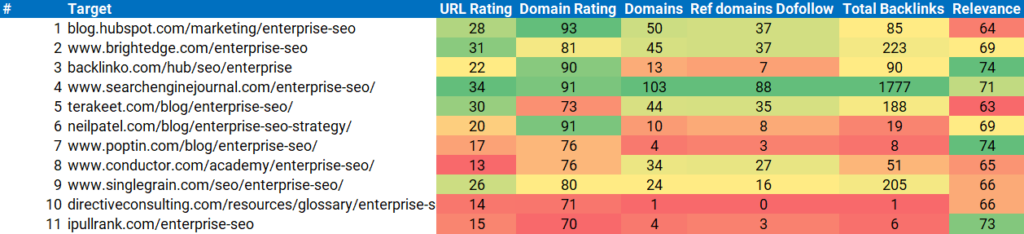
Surely, I may have assumed it was an authority issue before even looking, but it’s much better to have a definitive answer so I can know how to prioritize our efforts.
Wrapping Up
Learning more about the technical aspects of how Google works makes it very clear that SEO software has some catching up to do. It’s my hope that tools like Orbitwise showcase how SEO tools can be improved by leveraging some of the same open-source technologies that have come out of the Google Research teams.
In the meantime, feel free to give Orbitwise a spin as you’re working through your own questions of relevance. Let me know how it’s working for you in the comments below.
Next Steps
Here are 3 ways iPullRank can help you combine SEO and content to earn visibility for your business and drive revenue:
- Schedule a 30-Minute Strategy Session: Share your biggest SEO and content challenges so we can put together a custom discovery deck after looking through your digital presence. No one-size-fits-all solutions, only tailored advice to grow your business. Schedule your consultation session now.
- Mitigate the AI Overviews’ Potential Impact: How prepared is your SEO strategy for Google’s AI Overviews? Get ahead of potential threats and ensure your site remains competitive with our comprehensive AI Overviews Threat Report. Get your AI Overviews report.
- Enhance Your Content Relevancy with Orbitwise: Not sure if your content is mathematically relevant? Use Orbitwise to test and improve your content’s relevancy, ensuring it ranks for your targeted keywords. Test your content relevance today.
Want more? Visit our Resources Page for access to past webinars, exclusive guides, and insightful blogs crafted by our team of experts.






Leave a Comment