
With AI technology threatening the time-space continuum of organic search, SEOs are on the verge of an existential crisis.
Should we panic?
Yes and no.
Appearing in a static Large Language Model (LLM), like ChatGPT-3.5, might be valuable for brand visibility, but it won’t send traffic to your website.
Instead, this post will focus on how to feature in Google’s AI Overviews ( previously SGE), which not only boosts visibility but also drives traffic to your site through source links. While our primary focus is on AI Overviews, the principles discussed are applicable across various platforms, including Microsoft’s Copilot, Bard, Perplexity, and Claude.
Internet-connected platforms enhance LLM output by retrieving current, relevant content from search engine indices. This process is called Retrieval Augmented Generation (RAG).
I won’t go into extensive details as to how it works, but in essence, it’s combining the power of the LLM with a selection of highly relevant content from the internet that allows the chatbot to produce a more up-to-date and factually accurate output.
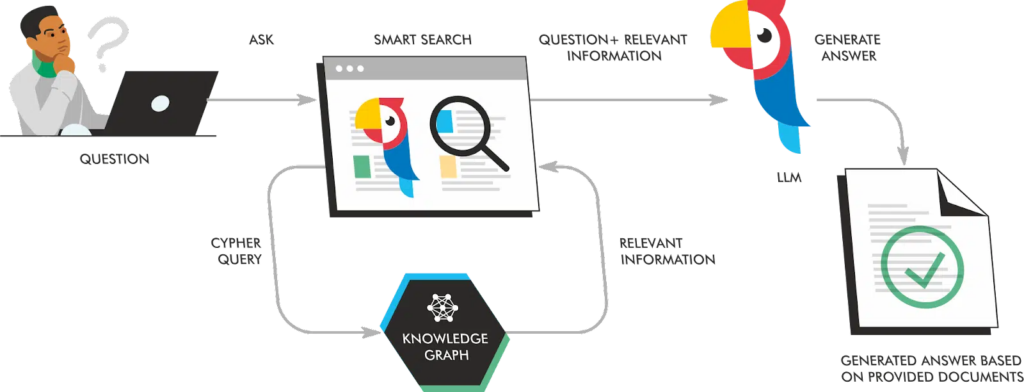
For a comprehensive explanation of RAG read: How Search Generative Experience works and why retrieval-augmented generation is our future
Generative-AI-powered search engines (RAG LLMs) are essentially a moving target for content creators. The complexity of SEO just became even more challenging. They use context from someone’s previous searches, may offer varied outputs over time, and currently, there is limited reporting available from these platforms.
To optimize your content for RAG LLMs, you need to reverse engineer the existing generative content for the keywords that you want to target.
To do that, you need to document your progress and results, develop a comprehensive keyword list, an approach to analyzing generative content effectively, and a content optimization and refinement process.
Can you optimize for RAG LLMs?
Optimizing for AI Overviews is akin to targeting featured snippets, though with more variables and less predictability. Success hinges on matching the format and relevance of the existing top-performing content.
The relevance of the content is not ambiguous. It’s quantitatively based on mathematical formulas. Tools like Orbitwise, MarketMuse, SurferSEO, and MarketBrew’s AI Overviews Visualiser tool can help you assess the relevance of your content for a targeted keyword.
RAG LLM outputs are based on probabilities, meaning your primary challenge in appearing in AI Overviews for a targeted query lies in understanding and adapting to these probabilistic models.
The fundamental function of RAG is the pretty predictable retrieval aspect. Your primary objective is to have a chunk of your content that is most relevant to the query.
What do you need to know?
- How big is the chunk used for the output?
- How relevant is your chunk versus the chunk from your competing pages?
Another major consideration:
The more saturated the topic or vague the query, the more volatility we’ll see in the results day to day.
If you find a very specific query that your indexed content answers, chances are, you already appear in the AI Overviews output:
AI Overview searches often fluctuate with different sources and formats daily. While producing relevant content, it does not currently align with traditional SEO factors like authority backlinks or user behavior.
For instance, when searching ‘best movies of all time‘, I encountered a result quoting an anonymous Redditor, demonstrating the unpredictable nature of AI Overviews’ source selection. Hardly, an example of reliable trustworthiness.
Even SGE is over-indexing on Reddit. 😂
— Garrett Sussman ☕️🔎 (@garrettsussman) January 29, 2024
"According to a Reddit user, it has an average ranking of 5.5, which is "solidly in its own tier".
Yup...seems worthy of the query 'best movies all time.' pic.twitter.com/HPOyTo5DAy
A study on AI Overviews by Authoritas (despite the small sample size of 1000 queries) showed that 93.8% of citations were not in the top 10 organic results.
This directly contradicted the study performed by Mike King months earlier across 90K queries, which showed links were most likely sourced from organic positions 1,2, and 9.
The reason we shouldn’t discount the Authoritas study stems from the rapid improvement of AI Overviews.
We should also anticipate more changes going forward as Google incorporates its most recent AI model – Gemini.
Optimizing for AI Overviews requires a process of informed experimentation.
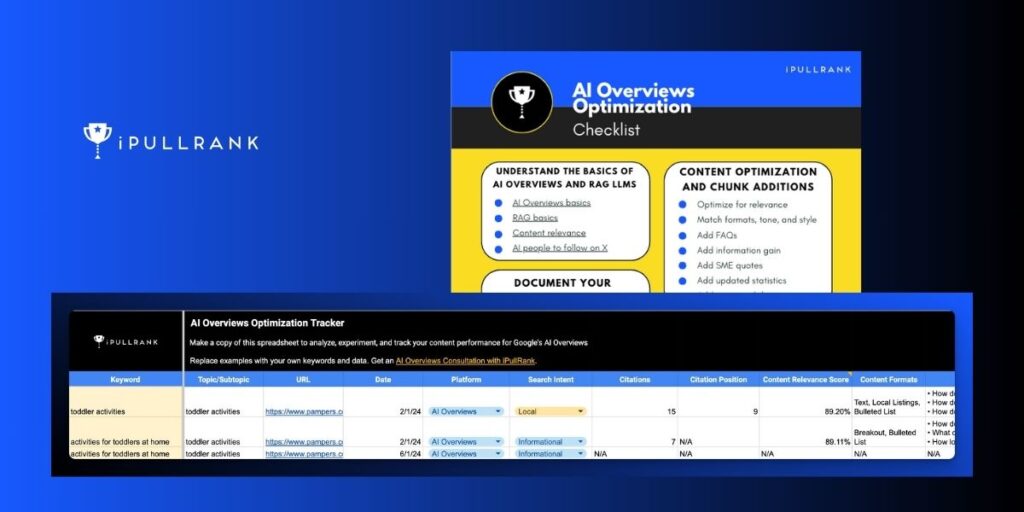
Documenting your experiments and tracking your performance comes next.
UPDATE: AI Overviews is changing constantly. On May 14th, 2024, Google rebranded SGE as AI Overviews at their annual Google I/O event.
Additionally, Since starting this article, the cisation carousel has completely disappeared from the snapshot for me. Is that going to be the final output? To be determined. But it highlights the evolving nature of versions of this experiment.

Document your Generative AI Search Engine experiments
The fundamental truth about RAG LLMs and generative AI is that they’re always changing. They’re machine learners that depend on a dynamic index of content depending on the search engine.
Google will access a different indexed internet than Bing.
While there’s some semblance of stability, content drops in and out of the index daily. LLM output is based on probabilities. Platforms like AI Overviews are likely to incorporate more personalized factors like searcher location into the output, though imperfect.
It’s a fool’s errand to expect the same result for every person every day.
Our goal should be to increase the likelihood that our content is sourced for a set of searches across our targeted topics and subtopics.
That caveat can inform our documentation, strategy, and experimentation.
When we track the performance of our content in RAG-powered platforms, we’ll want to keep track of the following data points:
- Target Keyword
- Target URL
- Topic/Subtopic
- Platform
- Search Intent
- Starting Date
- Number of Citations/Products/Listings
- Citation/Products/Listings Ranking (dependent on the UI of your platform)
- Content Relevance Score
- Content Formats
- Number of Fraggles Per Result
- Follow Up / Related Searches
- Notes on content update experiments
It would help to also create a secondary table to track query improvements across dates. You’d be able to annotate those updates with content improvements.
You can make a copy and use this AI Overviews Performance Tracker spreadsheet that I’ve created for you.
With your spreadsheet in hand, you can start mapping out your keyword topic clusters.
Create a map of search journey keywords
Searches on chatbots quickly become longer and more nuanced due to the natural language interactions with the platforms.
Your goal is subtopic coverage across variations of long-tail searchers.
Before engaging in keyword research, you may already have an existing keyword portfolio in place. For this process, select a specific topic or subtopic cluster of existing content that you want to focus on.
But keep in mind that traditional keyword research exists as a guide for RAG LLMs. You need to supplement it with market research and audience insights, people-also-asked queries, and follow-up searches from your targeted platform.
Your keyword list should start with an entry point in your audience’s search journey. That might be sourced from content already on your site or you may want to create content specifically designed for your AI Overviews tests.
Once you’ve settled on your initial keyword, you can develop your audience-driven keyword list. Our search process is rarely linear, search queries for chatbots are exponential, and your focus should begin with the most valuable and high-volume beginning query.
Imagine you’re the content marketing lead for an online children’s education center. You sell courses, books, and educational tools. Your core audience consists of parents and educators.
For anyone who has rambunctious toddlers running around, coming up with activities is exhausting. Thankfully, you already have a great blog post that has a list of potential toddler activities. That’s a great starting query for our exercise.
toddler activities
Traditional keyword research: Relevance and volume-driven
SEO keyword tools can help us quickly generate a ton of relevant searches backed by keyword volume. Keyword research tools lack transparency in their data sources. Your mileage may vary.
But the following tools have become relatively dependable in the industry:
- Google Keyword Planner (the most reliable source)
- Ahrefs
- Semrush
- Moz
- Keywords Everywhere
- Keyword Insights
First, we’ll jump over to Ahrefs and use the keyword explorer for our keyword – toddler activities:
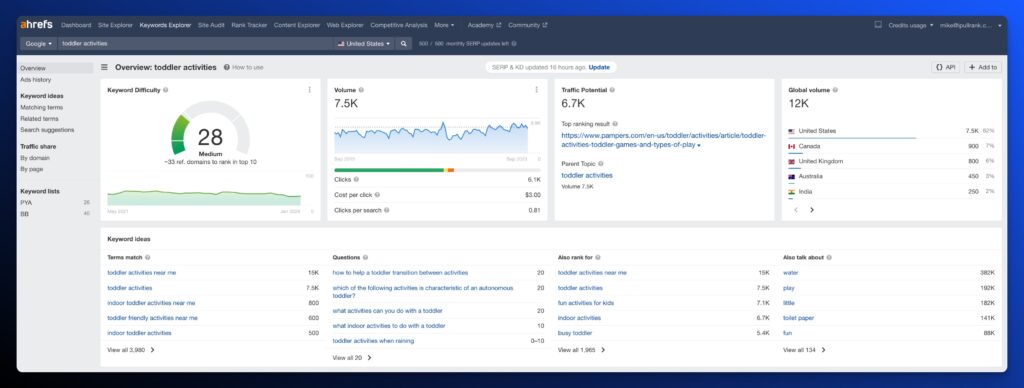
Turns out to be a great starting point. We see about 7.5K monthly searches and a medium keyword difficulty. For term match, we do see local intent queries, so we’ll want to keep that in mind when we look at the SERP.
Now we can start to build our list of keywords that expand from this search journey.
First stop:
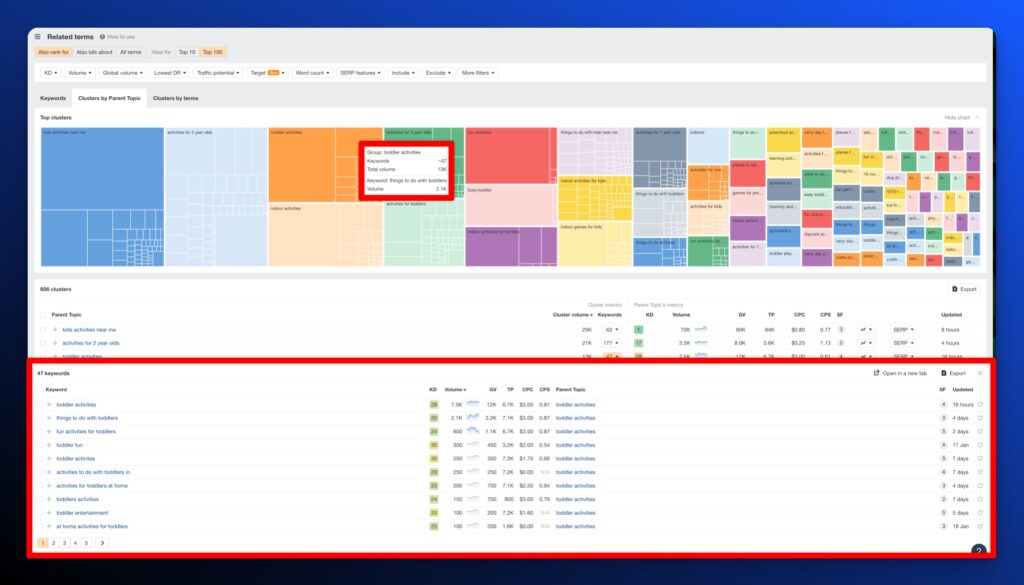
Looking solid! 47 keywords around my topic. While that’s a great starting point, we want to go next level and source directly from Google for related queries.
People Also Ask
Google provides a rich snippet for most queries called People Also Ask.
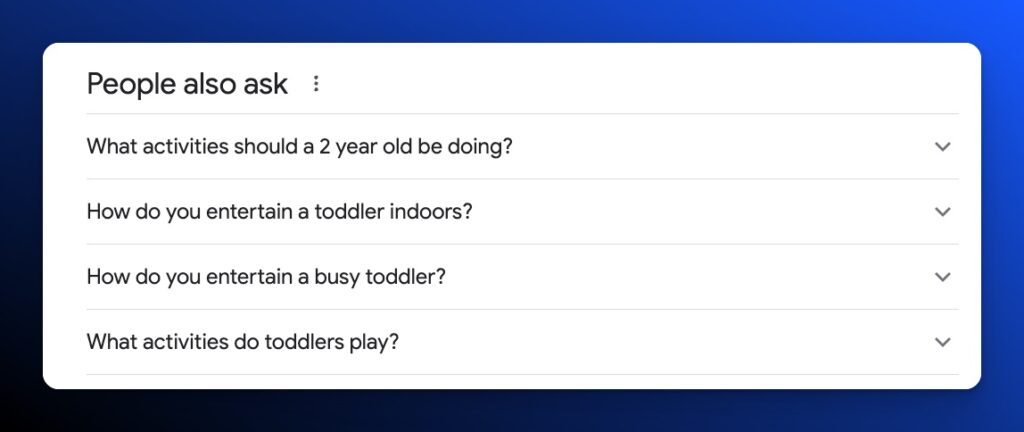
There’s a dynamite tool that can collect the searches that appear. Guess what it’s called? AlsoAsked.
Respect to simple, brilliant marketing. You can get a visualization 3 levels deep and on the paid plan, you can export a CSV of the keywords.
Let’s pop in our target keyword and see what we get.
43 more relevant keywords. The cool thing with AlsoAsked is that you get more of the natural language queries that a normal person might ask in an organic conversation.
Follow Up Keywords
Each LLM platform has its preferred method of introducing related searches. Similar to AI Overviews, follow-ups aren’t static either. You could collect searches for a few days or weeks to build out your list. Look at the slight differences between AI Overviews, Copilot, and Perplexity.
AI Overviews Follow Ups
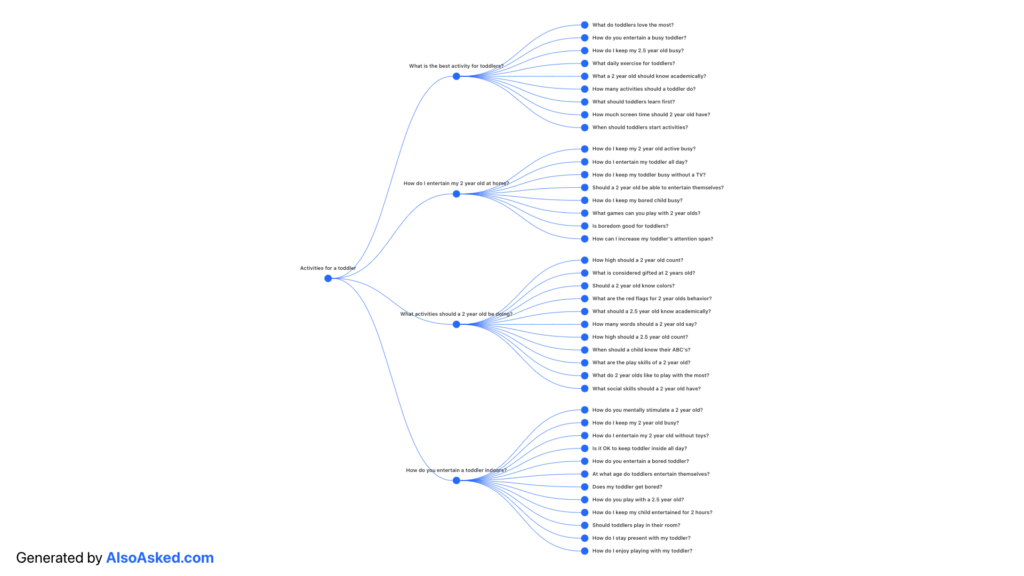
Bing Related Queries

Perplexity Related Questions
With these platforms, you can see how quickly you can develop a massive portfolio of keywords. Choosing a topic and subset of keywords that are mapped directly to your business goals (revenue, conversions, and traffic) will be the most important use of your time and resources.
Before moving on to analyzing the content generated for your keywords, add your list of keywords to your spreadsheet.
Analyze the output from your RAG LLM platform
Getting your content in the generative text for your targeted query is part logic and part art. Without purely depending on trial and error, you can design a rubric that you can use to evaluate the content, identify patterns, and stitch together for your content updates, creation, and optimization.
First, familiarize yourself with the expected generative output of your targeted platform.
Google’s AI Overviews – the AI snapshot comes in three flavors depending on search intent.
Informational snapshots can include paragraphs, breakout text sections, bulleted lists, images, videos, citations, and mentions (drop-down source links for text).

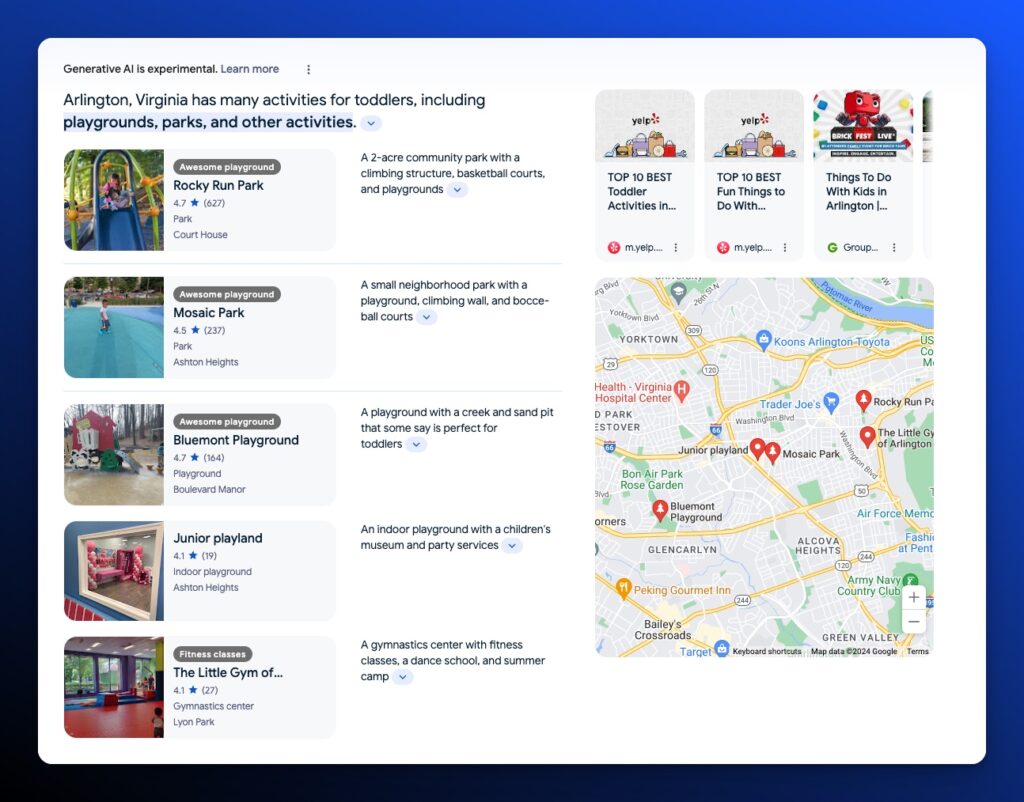
Local snapshots can include everything in an informational snapshot plus a map and Google Business Profile Listings.
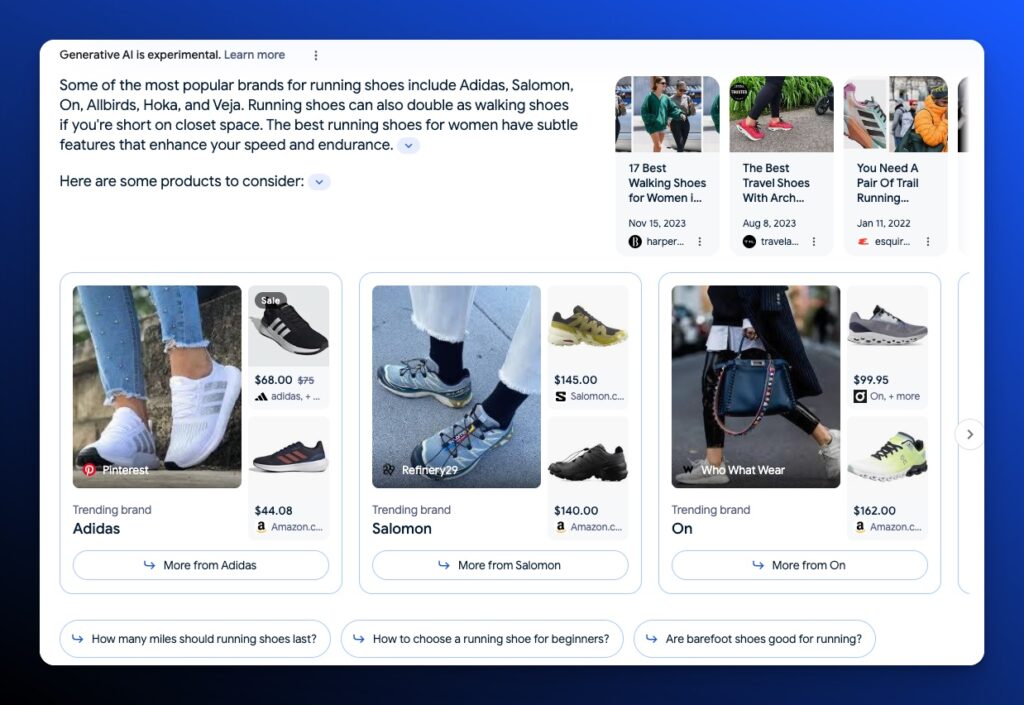
Shopping snapshots can include everything in an informational snapshot plus product listings, product cards, and product packs.
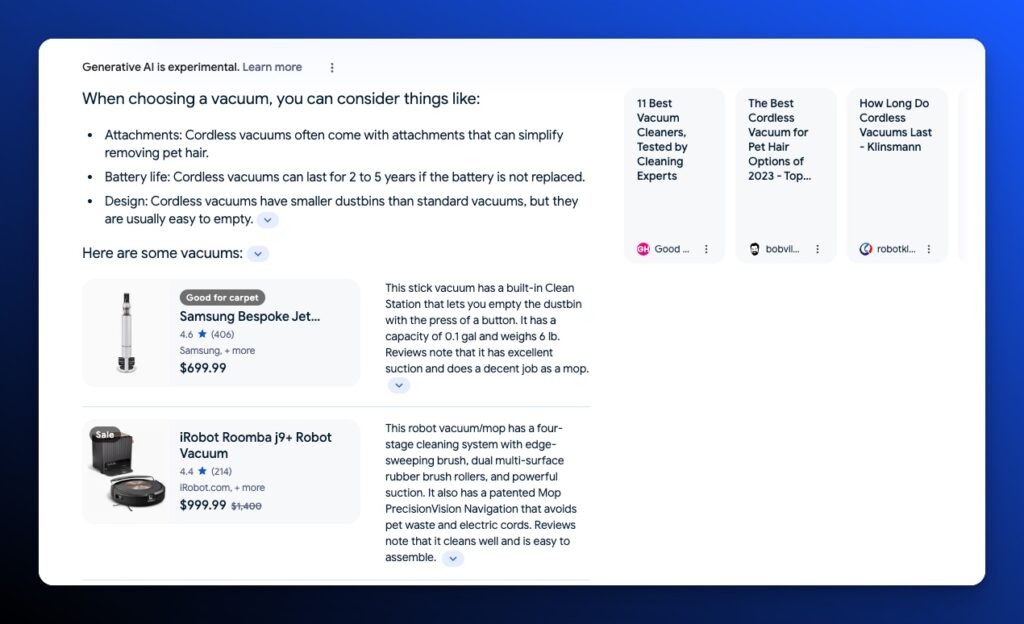
Revisiting our toddler activity keyword list, let’s look at one of the informational keywords for analysis:
activities for toddlers at home
To highlight the dynamic changes of AI Overviews. Within a few hours, the output remained the same. But across 3 days, we already see a change in output.
1/26/24

1/29/24
Search intent: Informational
Content Types:
- Breakout Text – the order has changed
- Bulleted Lists – one of the lists no longer exists
- Image (that expands to an image search)
Citations: 9 -> 8
Mentions: 3 -> 2
The changes are subtle, but highlight that tracking over time is a worthwhile effort.
Analyze the types of websites that are sourced in the GenAI output
We know that AI Overviews is sourcing content based on the relevance of the content. What’s fascinating about the cited content is that it’s not automatically information from the highest-ranking pages. We can’t pinpoint the exact factors that are used to select content for the generative text.
iPullRank Founder, Michael King identified that AI Overviews sometimes creates generative output based on individual passages called Fraggles (coined by Cindy Krum). Fraggles include the actual text used by the platform’s RAG mechanisms in the linked URL. That text is used to generate the AI output.
Here’s an AI Overviews result for “Taylor Swift” and the Fraggle from Investopedia that it uses:
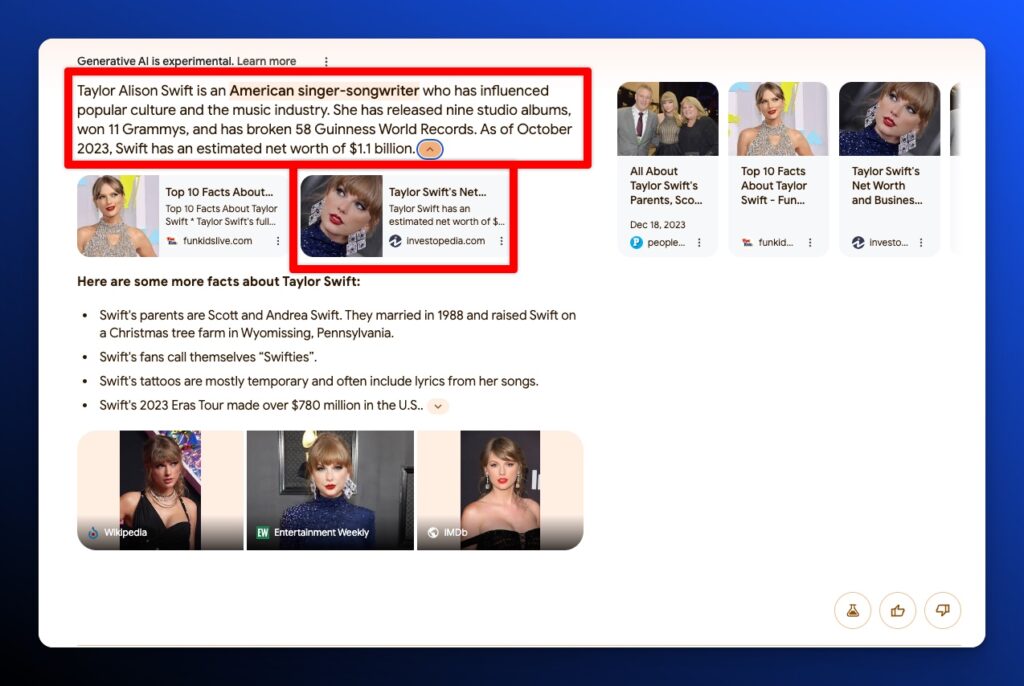

Reverse engineering those Fraggles and improving on the relevancy, simplicity, and clarity of the content are the best ways to earn your place in the AI Overviews and replace the Fraggle incumbent.
To analyze these Fraggles based on the mathematical values they hold using vector embeddings (see Mike’s article on content relevance), we can use MarketBrew’s free AI Overviews Visualizer tool which analyzes the relevance of the page to the targeted keyword in the context of AI Overviews.
Why did Market Brew founder Scott Stouffer and his team build the AI Overviews Visualizer?
“As a search engineer spanning over 20 years, what I am seeing is that AI Overviews is ushering in the 4th version of semantic algorithms. First, we had TF-IDF, then we had keywords, then it was entities, and now we have embeddings. It was an inevitable progression. During the entity movement, for a long time, Stanford NLP tried really hard to push NLP as the primary way to define and use structure within the latest semantic algorithms, but embeddings implicitly include the structure along with so many additional relationships.
For example, if you embed the HTML tags with the content, you actually bring along all of the styling/heading vectors without having to analyze any of them. The only issue with embeddings is that it’s hard to visualize what is happening, and that’s why Market Brew launched the AI Overviews Visualizer.”
The AI Overviews Visualizer works by comprehending the intricacies of embedding-based searches and how your content reacts to different searches, the free AI Overviews (Search Generative Experience) Visualizer aims to bring users closer to understanding AI Overviews optimization strategies.

Let’s try it for the example above:

You can see that the chunk has a high similarity (relevance) score of 82%. While it’s not the highest chunk in the article, it must hit a certain threshold for AI Overviews to include it in the snapshot. At the time, the combination of the general relevance of the article and the specific Fraggle chunk earned it inclusion in the AI Overviews output.
So returning to our example, let’s identify the citations, where they exist in the top 100 results, and whether they are a fraggle or general content.
The citations from our example on the 26th are:
- 10 Chinese New Year Montessori-Inspired Tray Activities for Toddlers (Not in Top 100 – Fraggle – Similar Score – 82%)
- 15 Secrets to Entertaining a Toddler at Home (Not in Top 100 – Headings)
- 15 Water Play Activities for Toddlers (Not in Top 100 – Fraggle)
- How to keep an active toddler occupied indoors (Not in Top 100 – Fraggle)
- Ball Painting: Sensory Process Art for Kids (Not in Top 100 – Fraggle)
- How To Occupy An Extremely Active Toddler At Home? (Not in Top 100 – Fraggle)
- 12 Fun Halloween Activities for Kids You Can Do at Home (Not in Top 100 – Fraggle)
- 9 Sensory Activities for Curious Babies and Toddlers (Not in Top 100 – Fraggle)
In this one anecdotal example, none of the results appeared in the top 100 organic rankings. This highlights an opportunity for sites that want to leapfrog the top 10 results, but also a frustration that quality, relevant results do not automatically appear in the AI Overviews output.
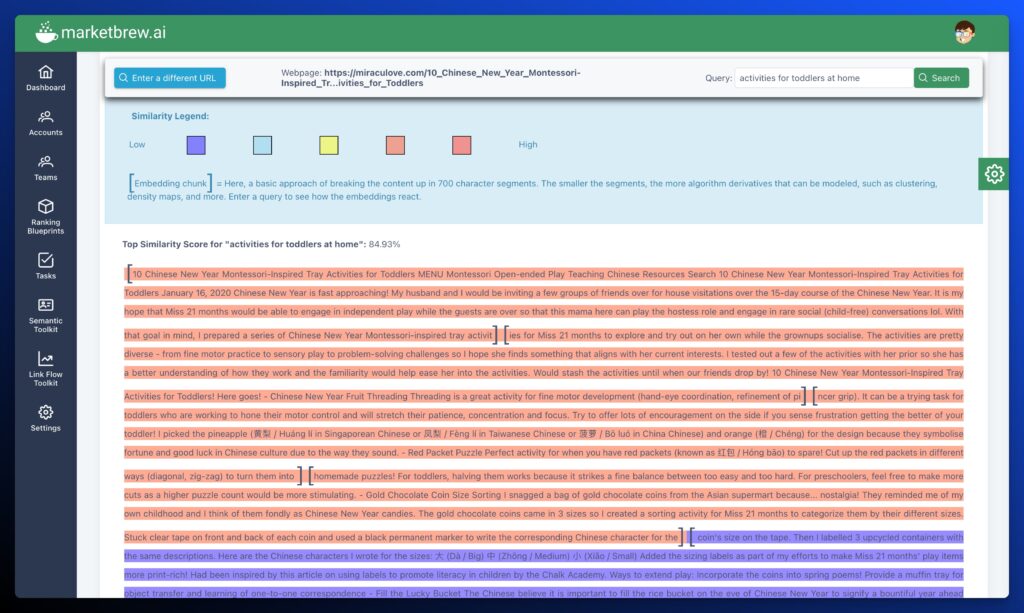
1. 10 Chinese New Year Montessori-Inspired Tray Activities for Toddlers
- Ranking: Not in Top 100
- Publish Date: 1-16-2020
- Fraggle: Yes
- Relevance Score: 82%
- Content Type: Breakout

Now let’s look at how MarketBrew’s free AI Overviews Visualizer tool analyzes the relevance to the AI Overviews output:
2. 15 Secrets to Entertaining a Toddler at Home
- Ranking: Not in Top 100
- Publish Date: 5-10-2021
- Fraggle: No (Headers)
- Relevance Score: 87%
- Content Type: Bulleted List
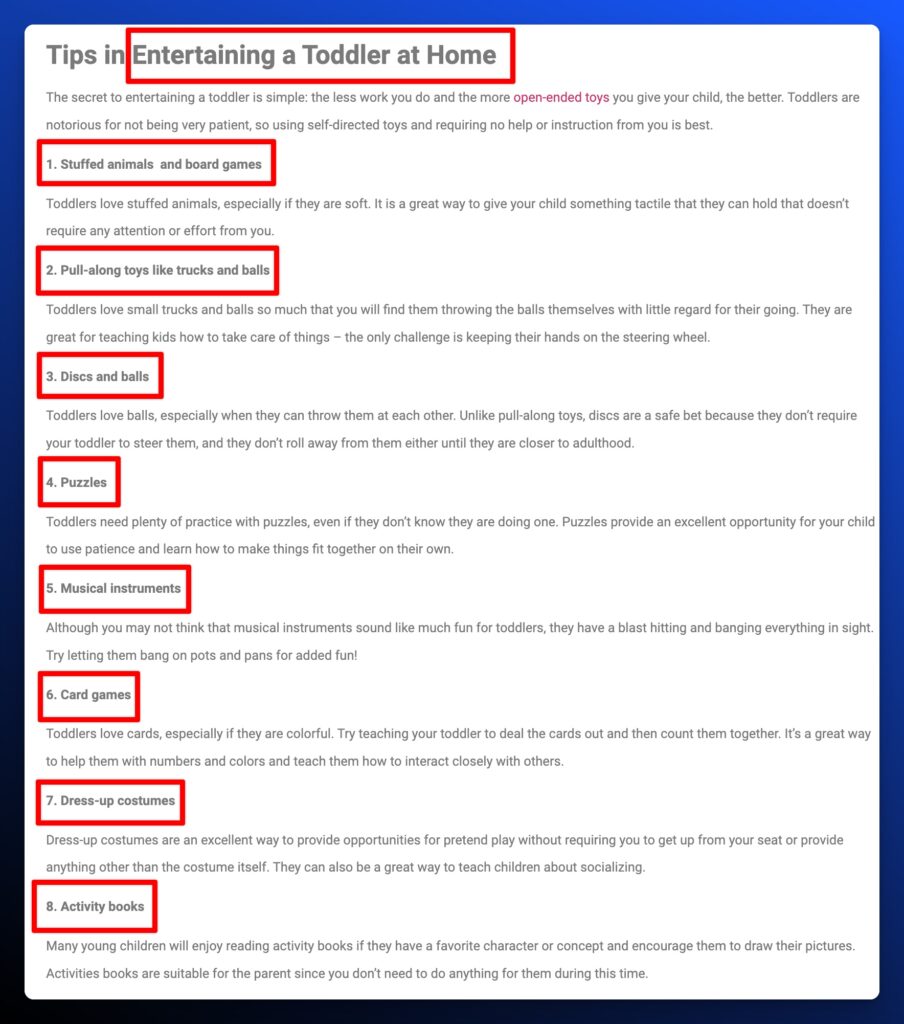

Analysis: The content in this chunk to generate the bulleted list was a series of headings similar to what you’d expect from a normal featured snippet.
3. 15 Water Play Activities for Toddlers
- Ranking: Not in Top 100
- Publish Date: 6-15-2021
- Fraggle: Yes
- Relevance Score: 69%
- Content Type: Breakout Content


Analysis: It surprised me that this isn’t even the top similarity score chunk from the content.
4. How to keep an active toddler occupied indoors
- Ranking: Not in Top 100
- Publish Date: 3-27-2020
- Fraggle: Yes
- Relevance Score: 78%
- Content Type: Breakout Content


Analysis: Again, not the top similarity score chunk from the content.
5. Ball Painting: Sensory Process Art for Kids
- Ranking: Not in Top 100
- Publish Date: 6-16-2022
- Fraggle: Yes
- Relevance Score: 85%
- Content Type: Breakout Content

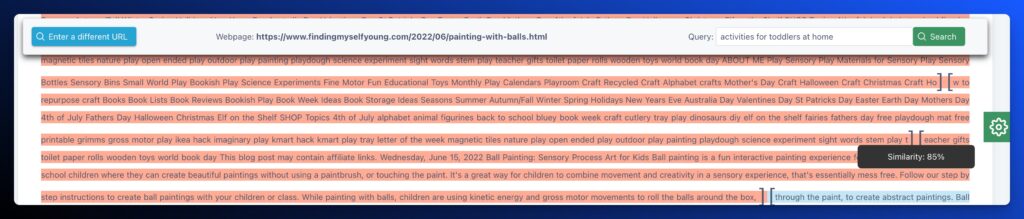
Analysis: It makes you begin to wonder what other factors beyond similarity score are at play here.
6. How To Occupy An Extremely Active Toddler At Home?
- Ranking: Not in Top 100
- Publish Date: Unknown
- Fraggle: Yes
- Relevance Score: 68%
- Content Type: Breakout Content


Analysis: This article had 4 different broken images across the content.
7. 12 Fun Halloween Activities for Kids You Can Do at Home
- Ranking: Not in Top 100
- Publish Date: 6-16-2022
- Fraggle: Yes
- Relevance Score: 80%
- Content Type: Breakout Content


8. 9 Sensory Activities for Curious Babies and Toddlers
- Ranking: Not in Top 100
- Publish Date: Unknown
- Fraggle: Yes
- Relevance Score: 86%
- Content Type: Breakout Content

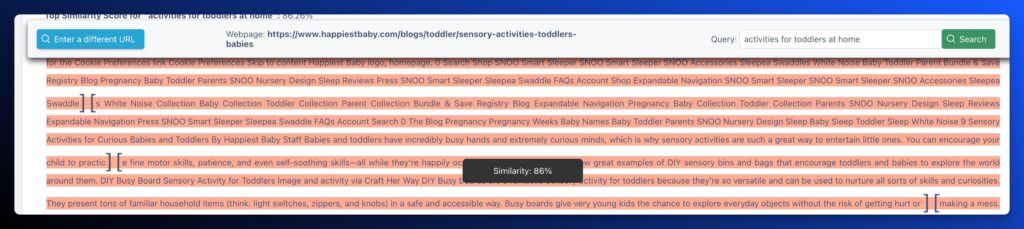
What’s fascinating about these fraggles are that they don’t come from many popular brands. They’re not the most original or unique suggestions. Some of them include exact matches of words from the keyword, but for the most part, they are topically relevant. The UX of the websites they’re sourced from have poor designs and are sometimes littered with ads. The content is old. The content is sometimes buried within the article, not immediately at the top of the page.
And when we use the free relevance score tool Orbitwise to look at the top AI Overviews result from miraculove.com, it has a lower relevance score (68) compared to 2 of the top 3 organically ranked articles that are not included in the AI Overviews result: busytoddler.com (72) and pampers.com (78)

When we look at the highest Fraggle ‘chunk’ from the Pampers article, it hits an 89% similarity score, but the content is not ‘unique’ compared to all of the other content out there. Arts and Crafts feel generic compared to the other ideas.

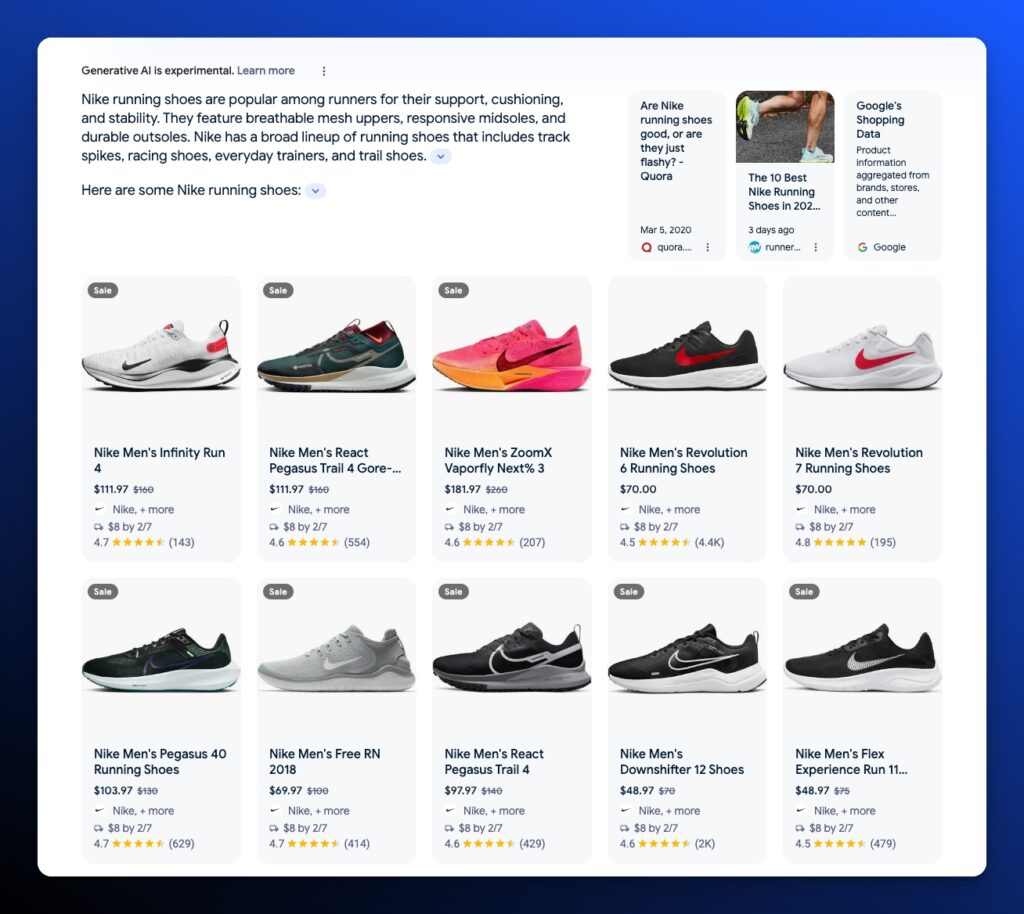
Optimizing Products in AI Overviews
eCommerce queries have a much bigger impact on business value than informational queries for many brands. It’s not exclusive to eCommerce brands. Affiliate marketing for media publishers can still be a source of revenue.
So what do you need to consider for a commercial query in AI Overviews?
When a shopping result is triggered on AI Overviews, the AI snapshot will provide those direct product listings in the form of the pack, grid, or individual listing.
Each of the listings has a direct citation. Typically it’s either an affiliate-incentivized listicle with a series or product or it’s taken directly from Google’s Shopping graph.
Product Listing Example Sourced from an Article and the Google Shopping Graph
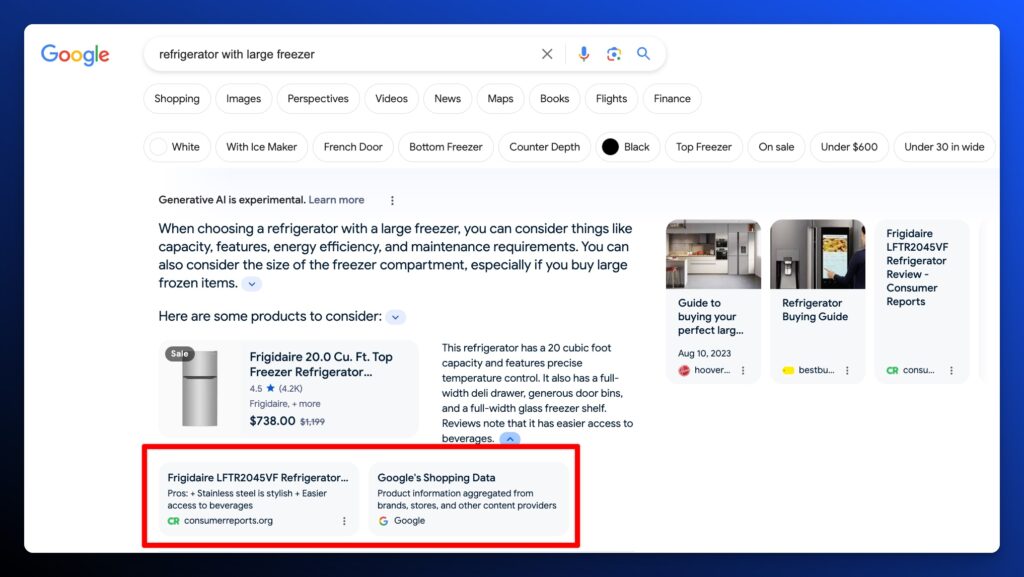
Product Listings sourced only from the Google Shopping Graph

In February 2023, Google published a blog post explaining how the Google Shopping Graph would work to serve customers.
The Shopping Graph is an “ML-powered, real-time data set of the world’s products and sellers. It stores billions of global product listings (more on that next), plus specific information about those products — like availability, reviews from other shoppers, pros and cons, materials, colors and sizes.”
It’s so much more than the specs on the products. Whenever you click on a product listing in AI Overviews, you can see the extensive information and content that informs the result.
The future of eCommerce still exists as a content ecosystem. Affiliate content still matters for AI Overviews. Whether niche publishers produce the same type of content is negotiable. It’s probable that affiliate commission from content might drop dramatically. But when one content producer drops, another may take its place. We could also see a bigger move to video affiliate content that monetizes on other channels of search. Maybe RAG LLMs will more effectively incorporate video content in the future. Right now, written content and product listings dominate AI Overviews commercial query results.
Going back to our example, it’s clear why the first product was listed based on the description from the sourced product review website.
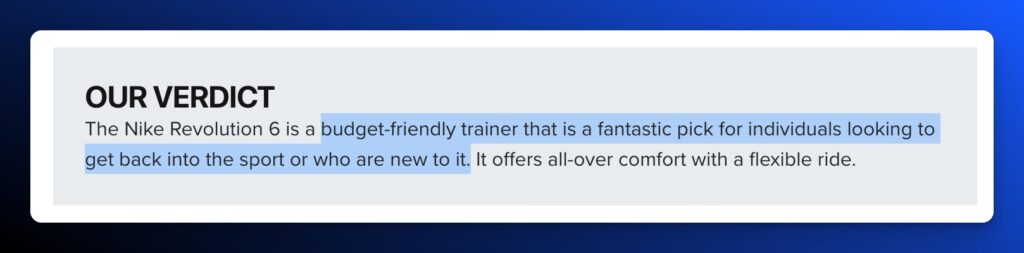
The blurb directly speaks to the query.
“A budget-friendly trainer that is a fantastic pick for individuals looking to get back into the sport or who are new to it.”
Translation: affordable running shoes for beginners.
Content relevance clearly matters in product listings for AI Overviews.
Beyond the obvious content relevance factors, the rankings of listings in AI Overviews does not directly map to the listings in Google’s Shopping Tab grid.
Here’s the AI Overviews Grid:
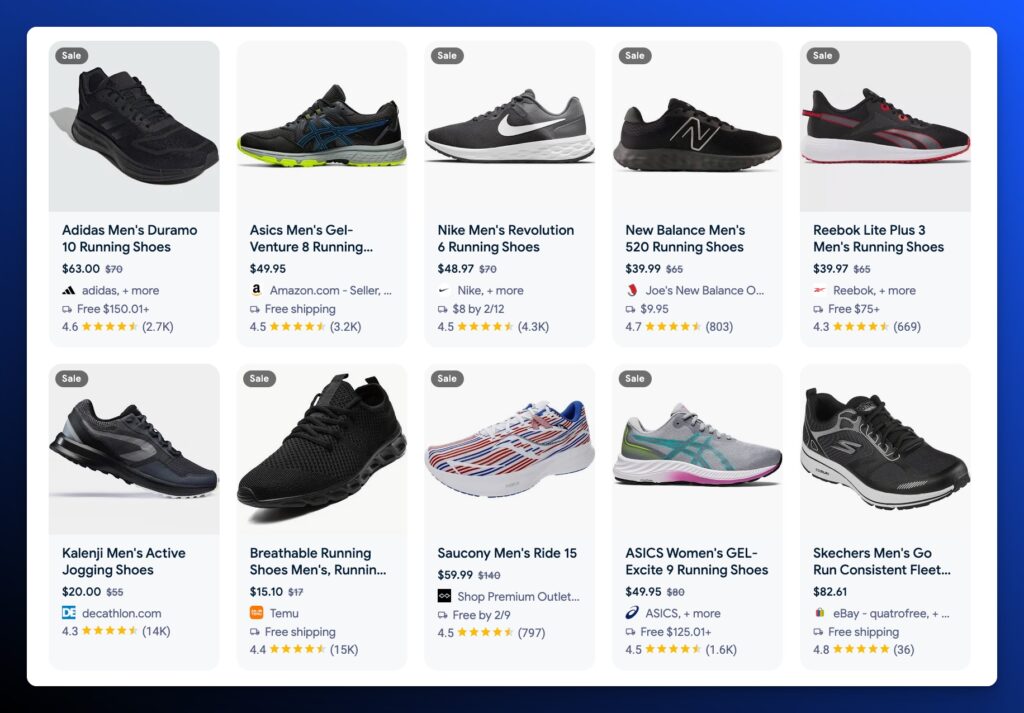
Here’s the shopping tab grid for the same query:

It’s a completely different list of products. SEO Consultant Brodie Clark recently published a comprehensive list of factors that determine why certain products rank in organic search product carousels and grids.
His top factors include:
- Valid items and eligibility
- Exact product match
- An extensive set of information provided
- Maintained various product titles
- Sourced product reviews
- A distinct, competitive edge
These recommendations support many best practices around organic search best practices for eCommerce.
Your products need to be properly implemented in the Shopping Graph. You need social proof. You need as much info as possible for a buyer to make an informed decision. It all leads to a good search experience (Google’s ultimate goal).
It logically makes sense from the product panel and the explicit mention of products pulled from the Shopping Graph that you should approach your product visibility the same way for RAG LLMs.
Tactics To Incorporate Based on Recent Studies
Content relevance has proven to be a core factor for inclusion in generative output. But what other proactive steps can we take to increase the likelihood that our content is preferable as a citation or brand mention in RAG LLMs?
In addition to the analysis of large data sets, SEOs, data scientists, and AI engineers are beginning to conduct academic experiments that test theories.
A group of researchers conducted an experiment that proposes the concept of Generative Engine Optimization (GEO).

The academics set performance benchmarks, tested content formats and types, and analyzed the results in comparison to existing LLMs.
They identified a few techniques that could offer an advantage for SEOs targeting RAG LLMs.

These models still operate as a black box without clear reasons as to what content contributes to the output. It’s logical to conclude that current SEO principles supporting quality content would improve your chances of appearing in the results.
Data and authority signals would help produce stronger fact-based results that support the goals of the creators of these models. The output needs to be useful and trustworthy. Statistics, citations, and authoritative language help serve that purpose.
While there’s yet to be conclusive evidence that other techniques provide a definitive advantage, it makes sense that other elements that support the output goals of these models would eventually be rewarded.
Here are a few specific tactics that your team should consider.
Improve Your Written Content Chunks (The Featured Snippet Approach)
Much has been written about writing content that targets featured snippets. Intentionally improve the clarity, usefulness, and authority of specific chunks of your writing that serve a specific intent for your targeted query.
Accurate, concise, and structured responses elevate your chance of being highlighted and likely improve visibility.
Add FAQs Chunks
Frequently Asked Questions (FAQs) are a standardized format that specifically mirrors that chunk format that matters for RAG LLMs. FAQs address common user queries and offer direct, valuable information. This approach not only enhances user experience but also aligns with search engines’ preference for content that directly answers specific questions. As RAG LLM searches become more specific and detailed, FAQs become more valuable.
Information Gain
Integrating high-value, information not readily available elsewhere into your content can give you an edge. This concept, known as information gain, involves providing unique insights or data, making your content more valuable and likely to be ranked higher by LLM-driven search algorithms. Expert insights can be an excellent source for this unique information. These chunks can be especially valuable for informational queries.
Quotes from Subject Matter Experts (SMEs)
Speaking of expertise, adding directly attributed quotes from subject matter experts lends credibility and authority to your content. Expert insights offer depth and perspective, boosting the quality of your information. This enhances trustworthiness, a factor that’s increasingly important in search engine algorithms.
Relevant and Fresh Statistics
Incorporate recent and relevant statistics. It keeps your content current and fact-based. Updated stats ensure your content remains informative and relevant, which is critical for maintaining high search rankings and user engagement.
Structured Data (JSON, HTML Structure, On-Page SEO, Technical SEO)
Implement structured data, such as JSON-LD, and optimize HTML structures to improve how search engines understand and index your content. On-page and technical SEO, including aspects like rendering and crawling, are fundamental for ensuring your content is accessible and understandable to search engines. The same goes for RAG LLMs.
Structured data continues to grow in importance for search engines, yet only a slight majority of websites implement it:
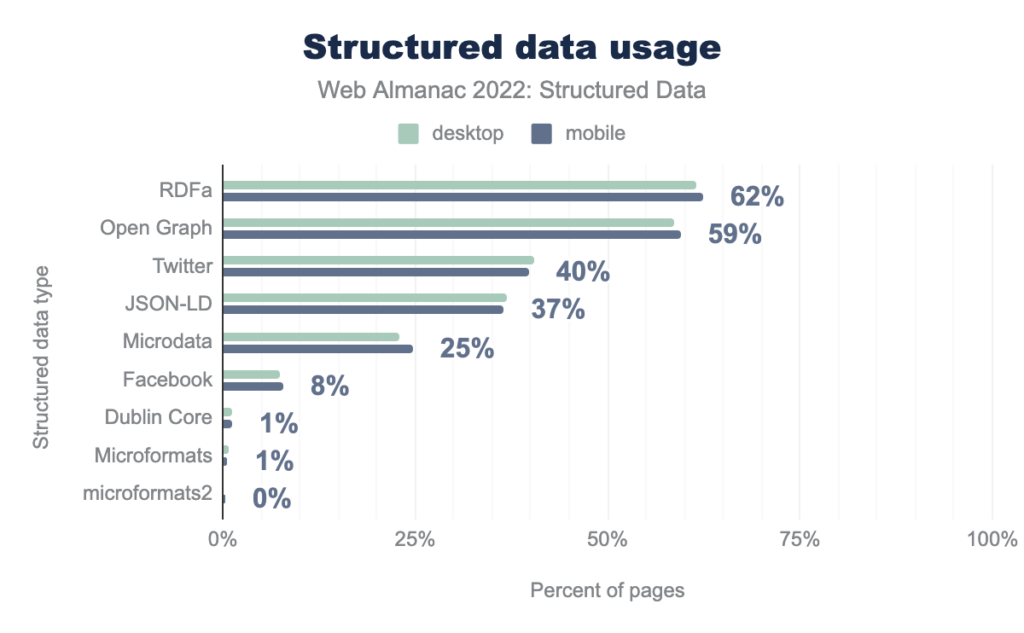
Source: https://almanac.httparchive.org/en/2022/structured-data#a-year-in-review
As LLMs depend more on Knowledge Graphs to understand attributes of websites, brands, and people, your ability to provide ‘relationship clues’ with semantically structured data can emerge as a major competitive advantage.
Shopping Graph (eCommerce)
Speaking of advantageous graphs, for eCommerce brands, integrating with Google’s Shopping Graph allows real-time inventory and pricing updates, enhancing product visibility. This tool connects your products directly with potential buyers, optimizing for transactional search queries.
As we mentioned above, AI Overviews pulls heavily from the Google Shopping Graph for commercial queries. Anything that includes products in the shopping snapshot would benefit from comprehensive and up-to-date shopping graph data.
Testing and Experimenting with AI Overview Content Placement
What about in real time? Can we actually put any of this into play and see our content appear in the AI snapshot?
For these experiments, we’re going to attempt to adjust the similarity score (cosine similarity) for our target keyword. We will add new content chunks that match the search intent of keyword, add value, and have a higher similarity score than the incumbents using the AI Overview Visualizer.
We’ll then check in on the keywords daily with the hope that we see our content sourced in the snapshot.
While we do not expect the results to be sustainable (you may search for the same query on your browser and not see our citation appear), we believe we can scientifically reverse-engineer our content and leverage RAG processes to improve our AI Overviews visibility.
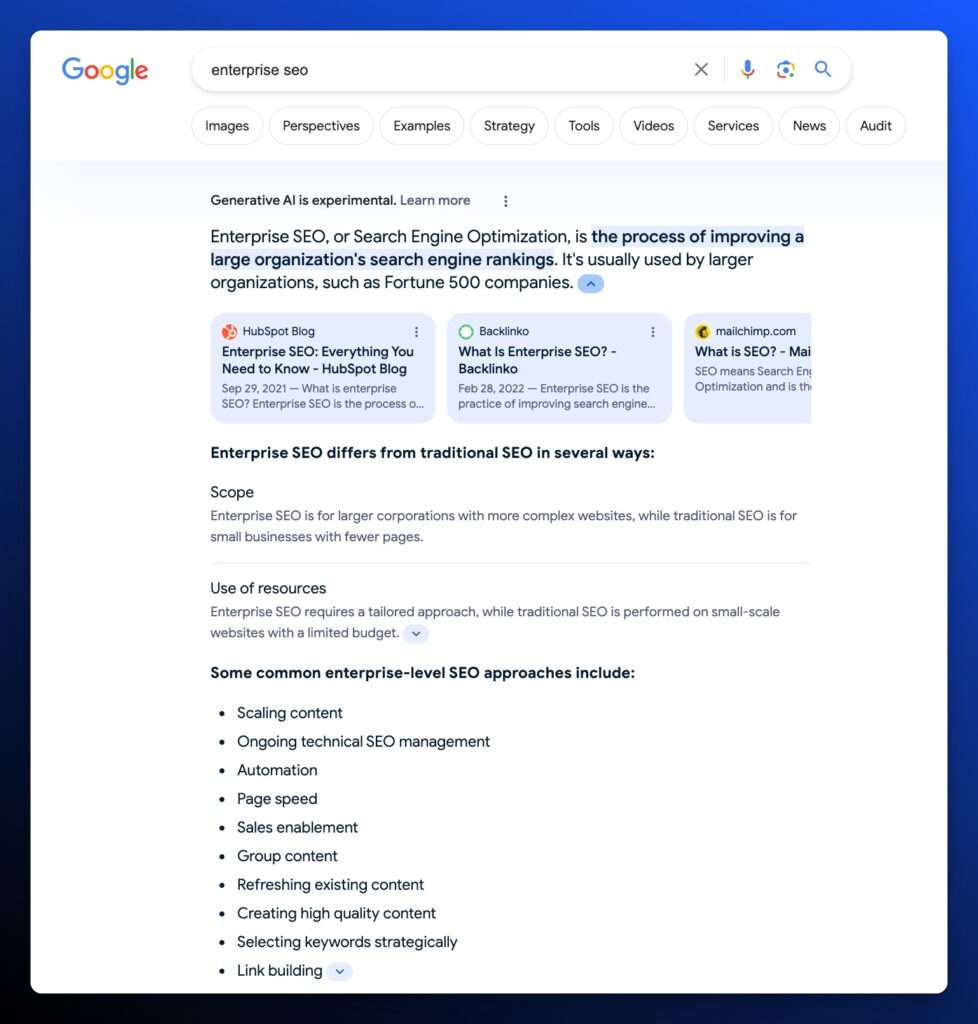
Experiment 1: Keyword - Enterprise SEO
For this experiment, our website is ranking 46th. Despite falling down the SERPs, we might have an opportunity to capture placement in AI Overviews by improving the similarity score of our competing content chunks.

The top output includes 4 chunks that rank at 1 (HubSpot), 3 (Backlinko), 5 (SearchEngine Journal), and not in the top 100 (LinkedIn Guest Post). So we can earn a space in that top-definition output.
Here are the 4 competing definitions, their contributing content chunks, and the similarity scores.
Enterprise SEO: Everything You Need to Know - HubSpot - (Similarity Score 87%)


Enterprise SEO - Backlinko (Similarity Score 73%)


Enterprise SEO Guide: Strategies, Tools, & More - Search Engine Journal (Similarity Score 82%)


Enterprise SEO vs. Traditional SEO: What's the difference?- LinkedIn (Similarity Score 88%)


Enterprise Services for Growing Organizations - iPullRank (Similarity Score 66%)


Analyzing the definitions that were pulled into the generated AI Overviews output that defines Enterprise SEO using the AI Overviews Visualizer, iPullRank clearly doesn’t match the similarity score when comparing chunks.
So our first step is to write a better definition that has a score that matches the existing contributors.
Enterprise SEO is a strategic approach to search engine optimization tailored for large organizations or websites. For enterprises with larger websites and vast volumes of content, it addresses complexities in optimizing technical aspects, crafting strategic content, and ensuring scalability to align with broader corporate goals. This practice emphasizes collaboration across departments, leveraging data for decision-making, and managing compliance to drive long-term search engine success.
We published an updated definition with a competitive similarity score of 86% on February 1st, 2024, we’ll see if this can earn us placement.

Experiment Outcome: February 5th, 2024
Our updated snippet has not appeared in the AI Overviews snapshot for Enterprise SEO.
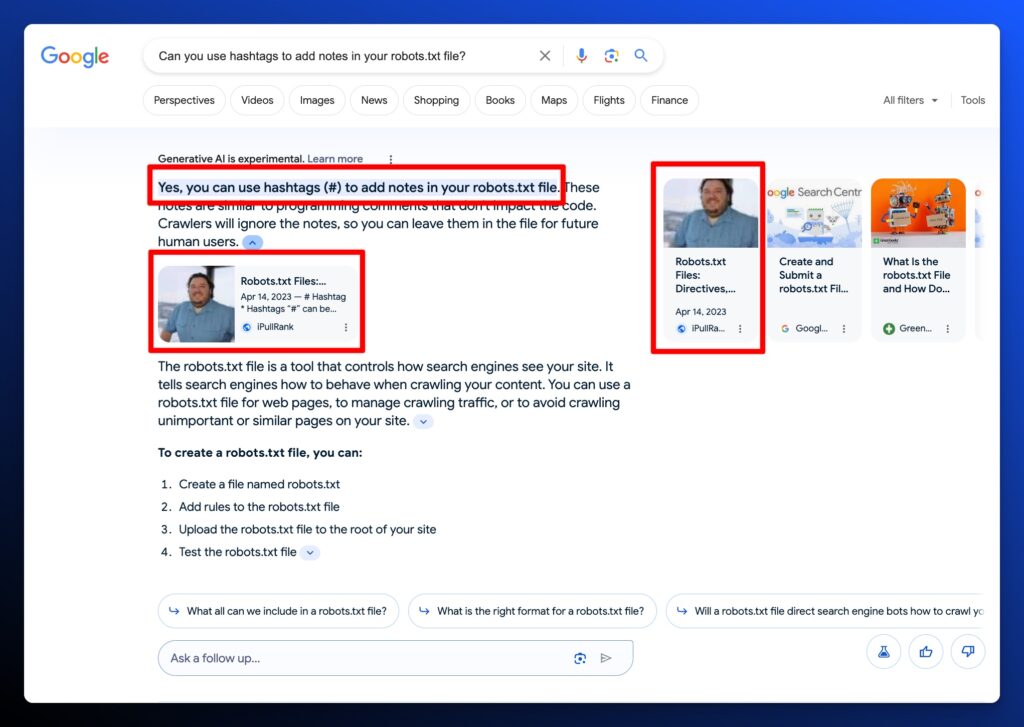
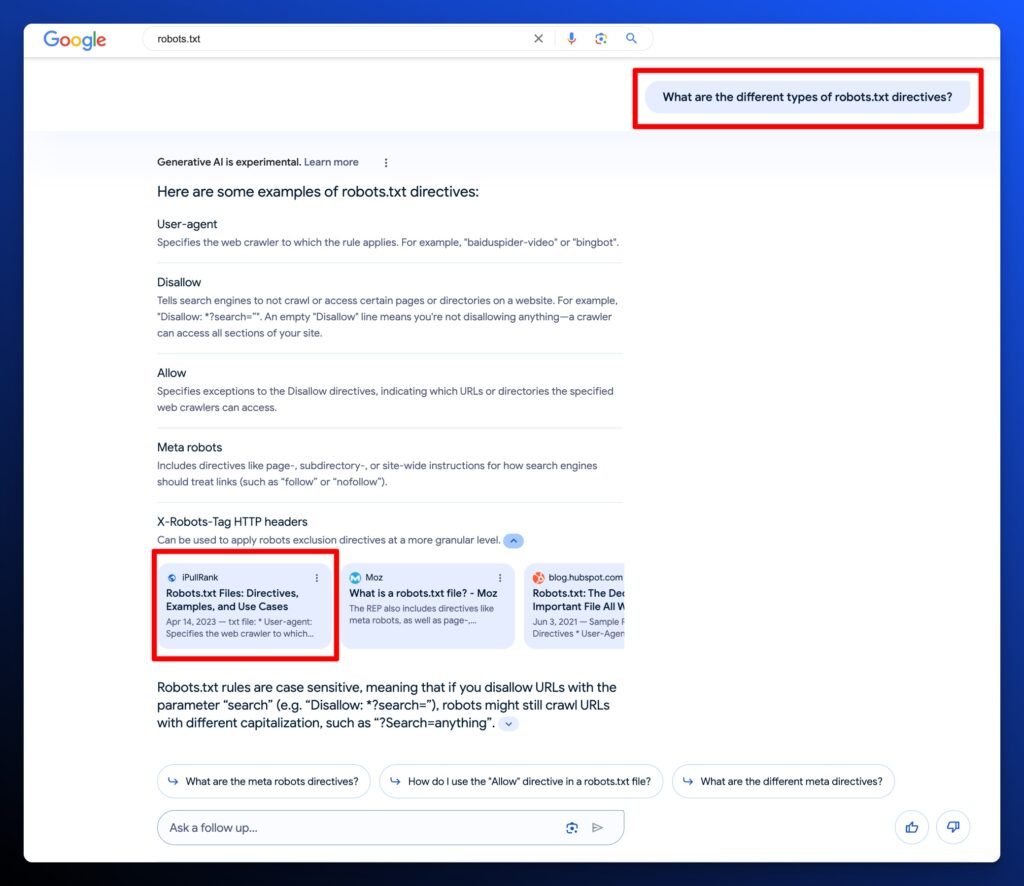
Experiment 2: Keyword - Robots.txt
For the next experiment, we’re going to try to win a placements by creating a bulleted list that might be important enough and have a strong enough similarity score that it would be included.
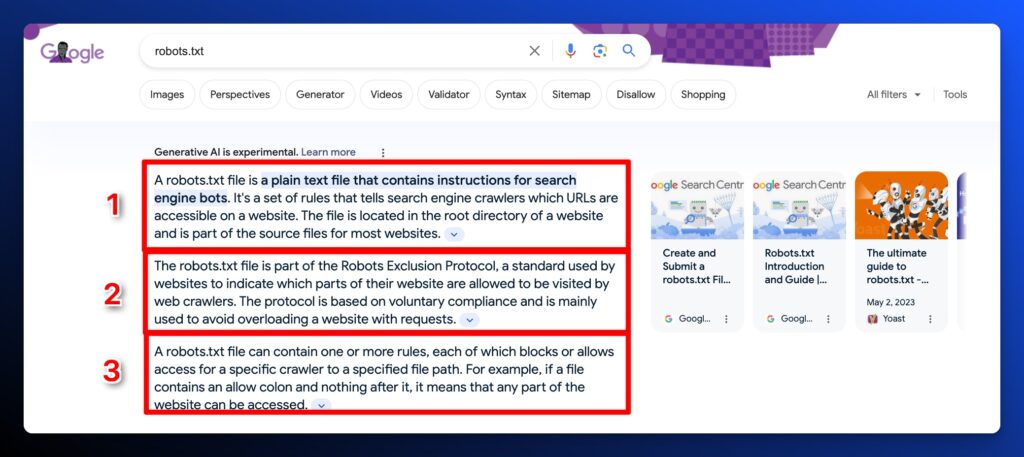
Here’s a bulleted list we’ve added to the page.
“Things that are commonly included in a robots.txt file:
- User-agent: Specifies the web crawler to which the rule applies. A * can be used to apply the rules to all web crawlers.
- Disallow: Indicates which URLs or directories the specified web crawlers are not allowed to access.
- Allow: Specifies exceptions to the Disallow directives, indicating which URLs or directories the specified web crawlers can access. This is particularly useful for allowing access to a specific file within a disallowed directory.
- Sitemap: Provides the URL to the website’s sitemap, which helps crawlers find and index content more efficiently.
- Crawl-delay: Sets the number of seconds a crawler should wait between making requests to the server. This can help manage server load.
- Noindex: Directs crawlers not to index specific URLs. However, it’s important to note that the Noindex directive in a robots.txt file is not officially supported by all search engines, and using meta tags on the page itself is a more reliable method.”
We published an updated definition with a competitive similarity score of 82% on February 1st, 2024.

Experiment Outcome: February 5th, 2024
Our updated snippet has not appeared in the originally targeted AI Overviews snapshot for Robots.txt, but it did show up for the Follow Up search “What are the different types of robots.txt directives?”
Experiment 3: Keyword - Media Organization Examples
For this final experiment, our article is ranked number 1 for the query Media Organization Examples, but we’re not appearing in the AI Overviews breakout.
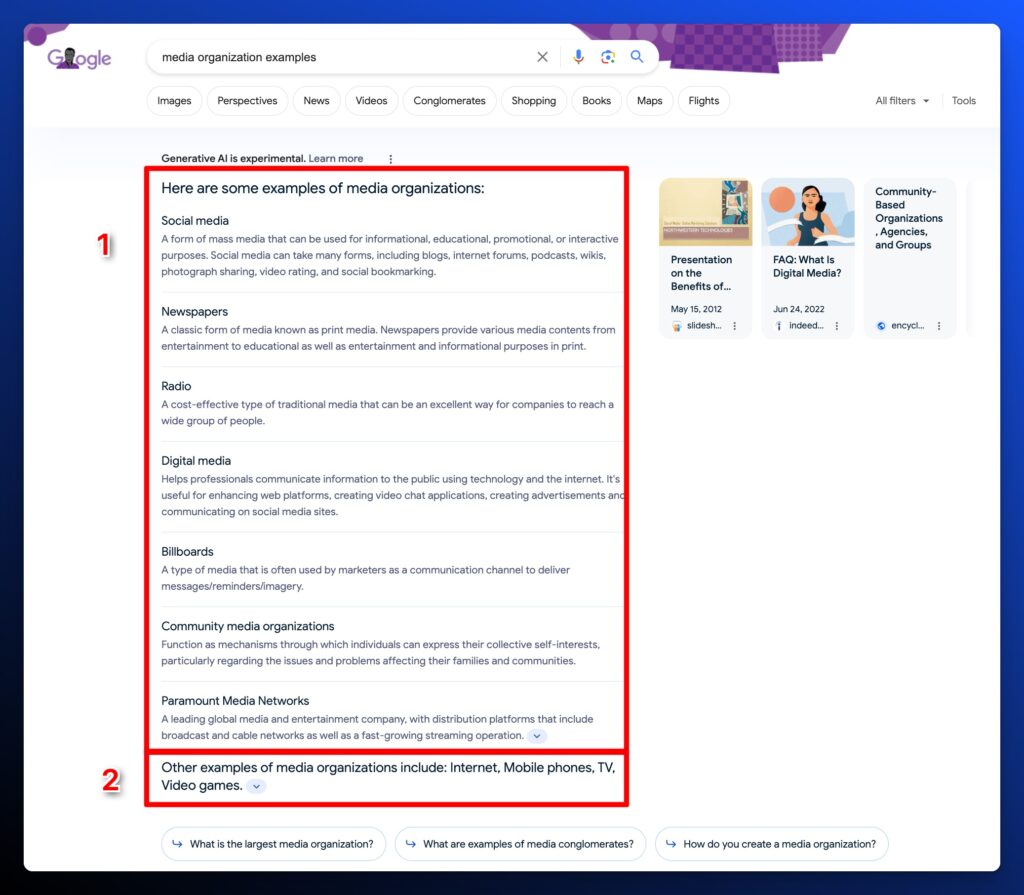
What’s odd about this AI Overviews output is that the content doesn’t make any sense.
How is Social Media or Billboards a type of media organization? In this case, AI Overviews selects the wrong entity type for ‘media organization.’
Our content has a list of specific examples, but not generalized examples. So the expectation here is that we can create a short list of generalized examples, add specifics to them, and see if that will earn us placement.
“Here are some examples of media organizations:
- News Media: Entities dedicated to the timely reporting of events and issues across a broad spectrum of topics.
- Trade Publications: Magazines and websites aimed at professionals in specific industries, offering news, updates, and insights pertinent to their trade.
- Niche Media: Platforms catering to specialized interests or audiences, offering content tailored to specific hobbies, professions, or demographic groups.
- Sports Media: Outlets focused on sports news, commentary, and analysis, covering everything from local teams to international competitions.
- Broadcast Media: Includes television and radio networks and stations that deliver content ranging from news and entertainment to educational programming.”
We published an updated definition with a competitive similarity score of 85% on February 1st, 2024.

Experiment Outcome: February 5th, 2024
Our updated snippet appears in its own section! We have successfully improved the similarity score and matched the content type to appear in the AI Overviews snapshot.
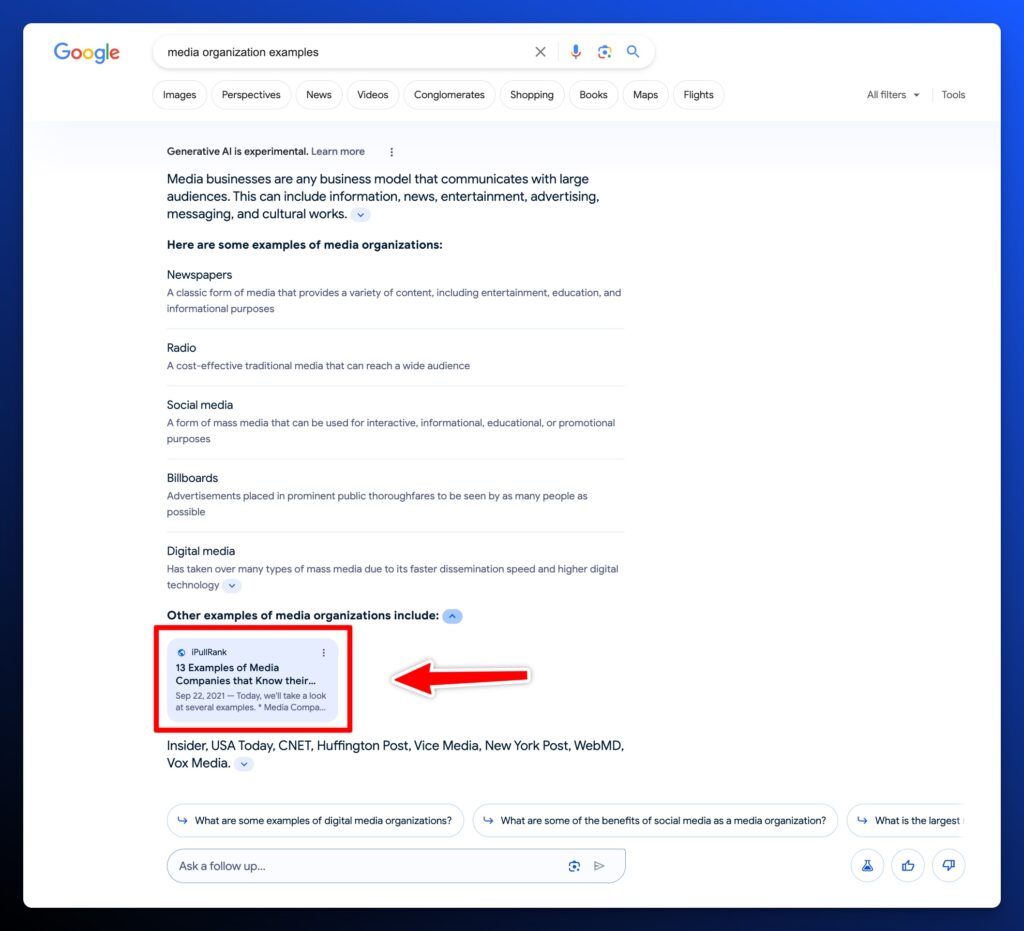
Whether this citation stays in this result remains to be seen, but it’s achievable like a featured snippet. This process can inform your SEO content strategy going forward for AI Overviews.
Evaluate your article against the targeted keyword for cosine similarity, update it to match the content format output, monitor and track progress.
RAG LLM Optimization: Uncharted Waters, Hard to Track, Essential to Consider
Being prescriptive on RAG LLM optimization isn’t irresponsible. It’s a smart way to future-proof your digital presence because it depends on the fundamental SEO and content quality concepts that we stand by. You see talking heads argue and discuss the ethics and commercial risks of AI-powered chatbots. It’s easy to ignore the developments of search and online visibility and fight to protect your IPs by any means necessary. That’s the wrong move.
Recently, the New York Times submitted a massive lawsuit against OpenAI for copyright infringement. Guess who is currently hiring AI engineers for generative AI journalism initiatives?
It’s a BlockBuster moment for many brands. Nobody is arguing that it’s fair or easy. But creating high-quality content, reevaluating your business models, and allowing your brand to participate in and even dominate the conversations is an important choice and roadmap moving forward.
Next Steps
Here are three ways iPullRank can help you combine SEO and content to earn visibility for your business and drive revenue:
- Schedule a 30-Minute Strategy Session: Share your biggest SEO and content challenges so we can put together a custom discovery deck after looking through your digital presence. No one-size-fits-all solutions, only tailored advice to grow your business. Schedule your consultation session now.
- Get Our Newsletter: AI is reshaping search. The Rank Report gives you signal through the noise, so your brand doesn’t just keep up, it leads. Subscribe to the Rank Report.
- Enhance Your Content’s Relevance with Relevance Doctor: Not sure if your content is mathematically relevant? Use Relevance Doctor to test and improve your content’s relevancy, ensuring it ranks for your targeted keywords. Test your content relevance today.
Want more? Visit our blog for access to past webinars, exclusive guides, and insightful blogs crafted by our team of experts.







