

Google, if you’re reading this, it’s too late. 😉
Ok. Cracks knuckles. Let’s get right to the Google algorithm leak.
Internal documentation for Google Search’s Content Warehouse API has been discovered. Google’s internal microservices appear to mirror what Google Cloud Platform offers and the internal version of documentation for the deprecated Document AI Warehouse was accidentally published publicly to a code repository for the client library. The documentation for this code was also captured by an external automated documentation service.
Based on the change history, this code repository mistake was fixed on May 7th, but the automated documentation is still live. In efforts to limit potential liability, I won’t link to it here, but because all the code in that repository was published under the Apache 2.0 license, anyone that came across it was granted a broad set of rights, including the ability to use, modify, and distribute it anyway.
I have reviewed the API reference docs and contextualized them with some other previous Google leaks and the DOJ antitrust testimony. I’m combining that with the extensive patent and whitepaper research done for my upcoming book, The Science of SEO. While there is no detail about Google’s scoring functions in the documentation I’ve reviewed, there is a wealth of information about data stored for content, links, and user interactions. There are also varying degrees of descriptions (ranging from disappointingly sparse to surprisingly revealing) of the features being manipulated and stored.
You’d be tempted to broadly call these “ranking factors,” but that would be imprecise. Many, even most, of them are ranking factors, but many are not. What I’ll do here is contextualize some of the most interesting ranking systems and features (at least, those I was able to find in the first few hours of reviewing this massive leak) based on my extensive research and things that Google has told/lied to us about over the years.
“Lied” is harsh, but it’s the only accurate word to use here. While I don’t necessarily fault Google’s public representatives for protecting their proprietary information, I do take issue with their efforts to actively discredit people in the marketing, tech, and journalism worlds who have presented reproducible discoveries. My advice to future Googlers speaking on these topics: Sometimes it’s better to simply say “we can’t talk about that.” Your credibility matters, and when leaks like this and testimony like the DOJ trial come out, it becomes impossible to trust your future statements.
- Read Mike’s follow-up on Search Engine Land: How SEO moves forward with the Google Content Warehouse API leak
Caveats for the Google Algorithm Leak
I think we all know people will work to discredit my findings and analysis from this leak. Some will question why it matters and say “but we already knew that.” So, let’s get the caveats out of the way before we get to the good stuff.
- Limited Time and Context – With the holiday weekend, I’ve only been able to spend about 12 hours or so in deep concentration on all this. I’m incredibly thankful to some anonymous parties that were super helpful in sharing their insights with me to help me get up to speed quickly. Also, similar to the Yandex leak I covered last year, I do not have a complete picture. Where we had source code to parse through and none of the thinking behind it for Yandex, in this case we have some of the thinking behind thousands of features and modules, but no source code. You’ll have to forgive me for sharing this in a less structured way than I will in a few weeks after I’ve sat with the material longer.
- No Scoring Functions – We do not know how features are weighted in the various downstream scoring functions. We don’t know if everything available is being used. We do know some features are deprecated. Unless explicitly indicated, we don’t know how things are being used. We don’t know where everything happens in the pipeline. We have a series of named ranking systems that loosely align with how Google has explained them, how SEOs have observed rankings in the wild, and how patent applications and IR literature explains. Ultimately, thanks to this leak, we now have a clearer picture of what is being considered that can inform what we focus on vs. ignore in SEO moving forward.
- Likely the First of Several Posts – This post will be my initial stab of what I’ve reviewed. I may publish subsequent posts as I continue to dig into the details. I suspect this article will lead to the SEO community racing to parse through these docs and we will, collectively, be discovering and recontextualizing things for months to come.
- This Appears to Be Current Information – As best I can tell, this leak represents the current, active architecture of Google Search Content Storage as of March of 2024. (Cue a Google PR person saying I’m wrong. Actually let’s just skip the song and dance, y’all). Based on the commit history, the related code was pushed on on Mar 27, 2024 and not removed until May 7, 2024.
- Correlation is not causation – Ok, this one doesn’t really apply here, but I just wanted to make sure I covered all the bases.
There are 14K Ranking Features and More in the Google Leak Docs
There are 2,596 modules represented in the API documentation with 14,014 attributes (features) that look like this:

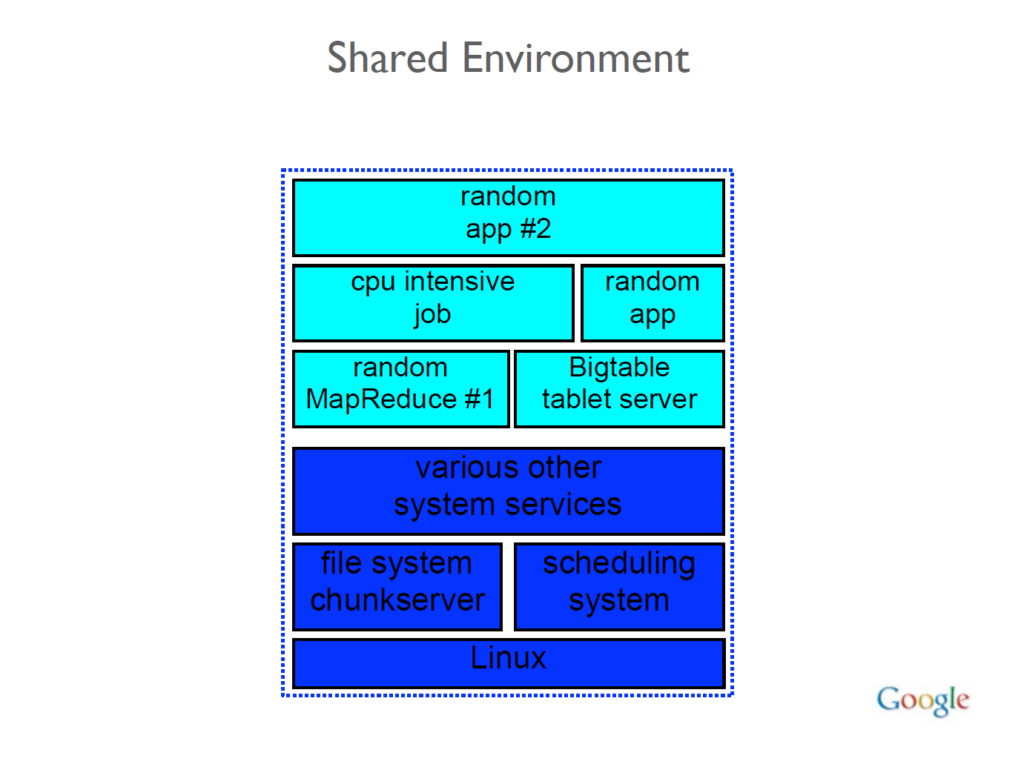
The modules are related to components of YouTube, Assistant, Books, video search, links, web documents, crawl infrastructure, an internal calendar system, and the People API. Just like Yandex, Google’s systems operate on a monolithic repository (or “monorepo”) and the machines operate in a shared environment. This means that all the code is stored in one place and any machine on the network can be a part of any of Google’s systems.
The leaked documentation outlines each module of the API and breaks them down into summaries, types, functions, and attributes. Most of what we’re looking at are the property definitions for various protocol buffers (or protobufs) that get accessed across the ranking systems to generate SERPs (Search Engine Result Pages – what Google shows searchers after they perform a query).
Unfortunately, many of the summaries reference Go links, which are URLs on Google’s corporate intranet, that offer additional details for different aspects of the system. Without the right Google credentials to login and view these pages (which would almost certainly require being a current Googler on the Search team), we are left to our own devices to interpret.
The API Docs Reveal Some Notable Google Lies
Google spokespeople have gone out their way to misdirect and mislead us on a variety of aspects of how their systems operate in an effort to control how we behave as SEOs. I won’t go as far as calling it “social engineering” because of the loaded history of that term. Let’s instead go with… “gaslighting.” Google’s public statements probably aren’t intentional efforts to lie, but rather to deceive potential spammers (and many legitimate SEOs as well) to throw us off the scent of how to impact search results.
Below, I present assertions from Google employees alongside facts from the documentation with limited commentary so you can judge for yourself.
“We Don’t Have Anything Like Domain Authority”
Google spokespeople have said numerous times that they don’t use “domain authority.” I’ve always assumed that this was a lie by omission and obfuscation.
By saying they don’t use domain authority, they could be saying they specifically don’t use Moz’s metric called “Domain Authority” (obviously 🙄). They could also be saying they don’t measure the authority or importance for a specific subject matter (or domain) as it relates to a website. This confusion-by-way-of-semantics allows them to never directly answer the question as to whether they calculate or use sitewide authority metrics.
Gary Ilyes, an analyst on the Google Search Team who focuses on publishing information to help website creators, has repeated this assertion numerous times.
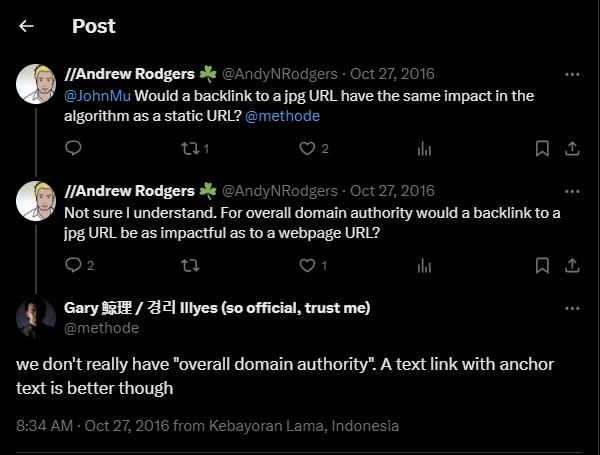
And Gary’s not alone. John Mueller, a “search advocate who coordinates Google search relations” declared in this video “we don’t have website authority score.”
In reality, as part of the Compressed Quality Signals that are stored on a per document basis, Google has a feature they compute called “siteAuthority.”
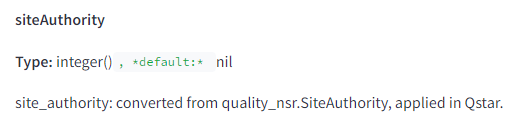
We do not know specifically how this measure is computed or used in the downstream scoring functions, but we now know definitively that it exists and is used in the Q* ranking system. Turns out Google does indeed have an overall domain authority. Cue Googlers claiming “we have it, but we don’t use it,” or “you don’t understand what that means,” or… wait, I said “limited commentary” didn’t I? Moving on.
“We Don’t Use Clicks for Rankings”
Let’s put this one to bed for good.
Testimony from Pandu Nayak in the DOJ Antitrust Trial recently revealed the existence of the Glue and NavBoost ranking systems. NavBoost is a system that employs click-driven measures to boost, demote, or otherwise reinforce a ranking in Web Search. Nayak indicated that Navboost has been around since around 2005 and historically used a rolling 18 months of click data. The system was recently updated to use a rolling 13 months of data and focuses on web search results, while a system called Glue is associated with other universal search results. But, even before that reveal, we had several patents (including 2007’s Time Based Ranking patent) which specifically indicates how click logs can be used to change results.
We also know that clicks as a measurement of success is a best practice in information retrieval. We know that Google has shifted towards machine learning driven algorithms and ML requires response variables to refine its performance. Despite this staggering evidence there is still confusion in the SEO community due to the misdirection of Google’s spokespeople and the embarrassingly complicit publication of articles across the search marketing world that uncritically repeat Google’s public statements.
Gary Ilyes has addressed this click measuring issue many times. In one instance he reinforced what Google Search engineer Paul Haahr shared in his 2016 SMX West talk about live experiments, saying that “using clicks directly in rankings would be a mistake.”

Later still, he famously used his platform to disparage Rand Fishkin (founder/CEO of Moz, and a longtime SEO practitioner) saying that “dwell time, CTR, whatever Fishkin’s new theory is, those are generally made up crap.”
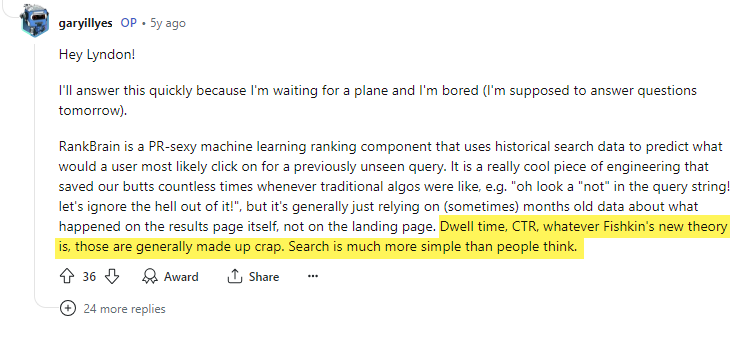
In reality, Navboost has a specific module entirely focused on click signals.
The summary of that module defines it as “click and impression signals for Craps,” one of the ranking systems. As we see below, bad clicks, good clicks, last longest clicks, unsquashed clicks, and unsquashed last longest clicks are all considered as metrics. According to Google’s “Scoring local search results based on location prominence” patent, “Squashing is a function that prevents one large signal from dominating the others.” In other words, the systems are normalizing the click data to ensure there is no runaway manipulation based on the click signal. Googlers argue that systems in patents and whitepapers are not necessarily what are in production, but NavBoost would be a nonsensical thing to build and include were it not a critical part of Google’s information retrieval systems.

Many of these same click-based measurements are also found in another module related to indexing signals. One of the measures is the date of the “last good click” to a given document. This suggests that content decay (or traffic loss over time) is also a function of a ranking page not driving the expected amount of clicks for its SERP position.
Additionally, the documentation represents users as voters and their clicks are stored as their votes. The system counts the number of bad clicks and segments the data by country and device.
They also store which result had the longest click during the session. So, it’s not enough to just perform the search and click the result, users need to also spend a significant amount of time on the page. Long clicks are a measure of the success of a search session just like dwell time, but there is no specific feature called “dwell time” in this documentation. Nevertheless, long clicks are effectively measures of the same thing, contradicting Google’s statements on the matter.
Various sources have indicated that NavBoost is “already one of Google’s strongest ranking signals”. The leaked documentation specifies “Navboost” by name 84 times with five modules featuring Navboost in the title. There is also evidence that they contemplate its scoring on the subdomain, root domain, and URL level which inherently indicates they treat different levels of a site differently. I won’t go into the subdomain vs. sudirectory argument, but later we’ll discuss how the data from the system has also informed the Panda algorithm.
So, yes, Google does not mention “CTR” or “dwell time” by those exact words in this documentation, but the spirit of what Rand proved: clicks on search results and measures of a successful search session, are included. The evidence is fairly definitive, there can be little doubt that Google uses clicks and post-click behavior as part of its ranking algorithms.
“There is no Sandbox”
Google spokespeople have been adamant that there is no sandbox that websites are segregated to based on age or lack of trust signals. In a now deleted tweet, John Muller responded to a question about how long it takes to be eligible to rank indicating that “There is no sandbox.”
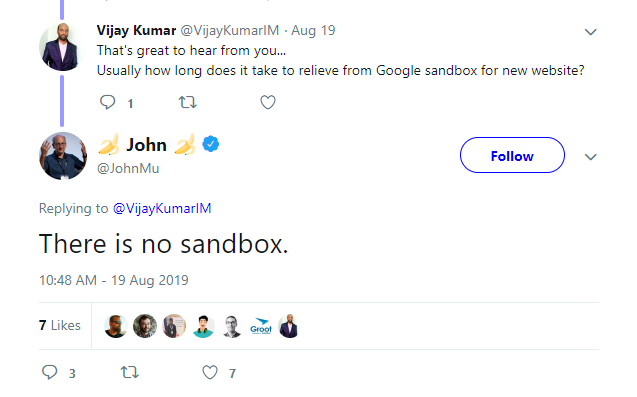
In the PerDocData module, the documentation indicates an attribute called hostAge that is used specifically “to sandbox fresh spam in serving time.”
Turns out there is a sandbox after all. Who knew? Oh yeah, Rand knew.
“We don’t use anything from Chrome for Ranking”
Matt Cutts has previously been quoted as saying that Google does not use Chrome data as part of organic search. More recently John Mueller reinforced this idea.

One of the modules related to page quality scores features a site-level measure of views from Chrome. Another module that seems to be related to the generation of sitelinks has a Chrome-related attribute as well.
![The image is a slide titled "Realtime Boost Signal" with a link to (go/realtime-boost). The content of the slide includes information on the sources and uses of real-time boost signals, as well as graphs illustrating query trends. Here are the details: Title: Realtime Boost Signal (go/realtime-boost) Spikes and Correlations on Content Creation Location (S2), Entities, Salient Terms, NGrams... Sources: Freshdocs-instant Chrome Visits (soon) (highlighted in yellow) Instant Navboost (soon) Not restricted by Twitter contract Run in Query Rewriter: Can be used anywhere: Freshbox, Stream... Graphs: Top Right Graph: Titled "Twitter Hemlock Query Trend" with a red line indicating "Noise level (median + 1IQR)" and a spike indicated by an arrow labeled "Spike." Bottom Right Graph: Titled "Query [Dilma]" with the caption "Spike 5 mins after impeachment process announced." It shows a spike in the score time series for the term "Dilma." At the bottom, the slide has a note saying "No birds were hurt in the making of Realtime Boost signal," and the Google logo is displayed in the bottom left corner.](https://ipullrank.com/wp-content/uploads/2024/05/image16-1024x576.png)
A leaked internal presentation from May of 2016 on the RealTime Boost system also indicates that Chrome data was coming to search. I mean, you get the point.
Google spokespeople are well-meaning, but can we trust them?
The quick answer is not when you get too close to the secret sauce.
I harbor no ill will against the folks I’ve cited here. I’m sure they all do their best to provide support and value to the community within the bounds that are allowed. However, these documents make it clear that we should continue to take what they say as one input and our community should continue to experiment to see what works.
The Architecture of Google’s Ranking Systems
Conceptually, you may think of “the Google algorithm” as one thing, a giant equation with a series of weighted ranking factors. In reality, it’s a series of microservices where many features are preprocessed and made available at runtime to compose the SERP. Based on the different systems referenced in the documentation, there may be over a hundred different ranking systems. Assuming these are not all the systems, perhaps each of the separate systems represents a “ranking signal” and maybe that’s how Google gets to the 200 ranking signals they often talk about.
In Jeff Dean’s “Building Software Systems at Google and Lessons Learned” talk, he mentioned that earlier iterations of Google sent each query to 1000 machines to process and respond in sub-250 milliseconds. He also diagrammed an earlier version of the system architecture abstraction. This diagram illustrates that Super Root is the brain of Google Search that sends queries out and stitches everything together at the end.
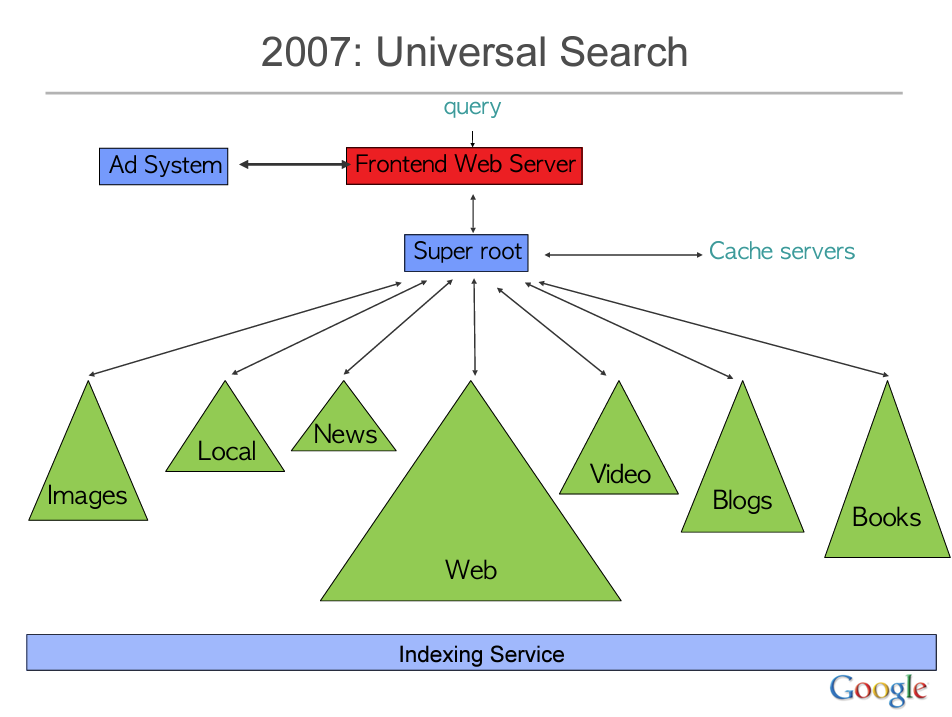
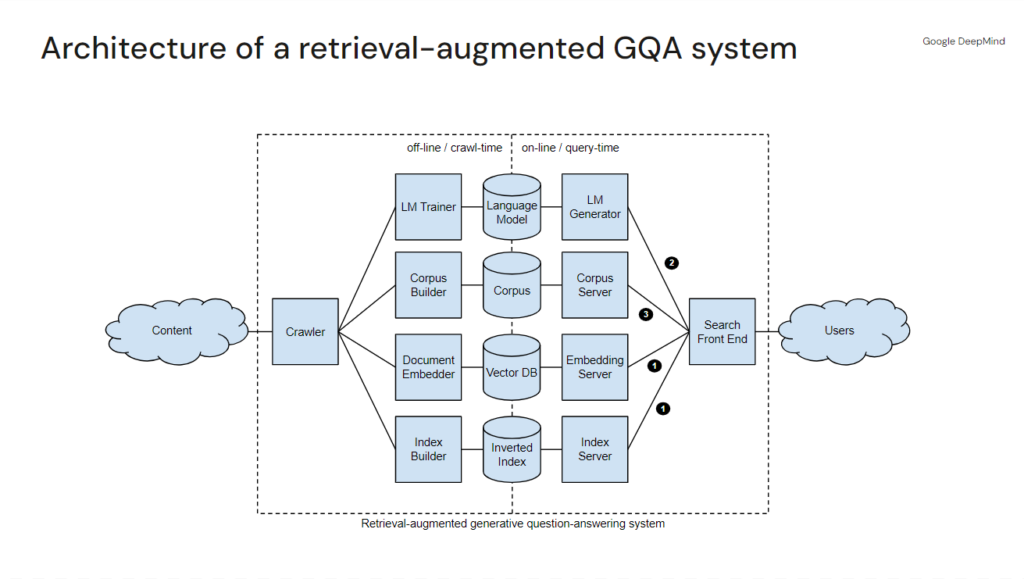
Distinguished Research engineer Marc Najork, in his recent Generative Information Retrieval presentation showcased an abstracted model of Google Search with its RAG system (aka Search Generative Experience/AI Overviews). This diagram illustrates a series of different data stores and servers that process the various layers of a result.
Google whistleblower, Zach Vorhies, leaked this slide which showcases the relationships of different systems within Google by their internal names. Several of these are referenced in the documentation.
![The image is a diagram titled "a sample of ML across the company" and shows how machine learning (ML) is integrated into various Google and Alphabet products. The diagram illustrates connections between different ML teams and products, with circle size proportional to the number of connections. Title: a sample of ML across the company Subtitle: Machine learning is core to a wide range of Google products and Alphabet companies. Components: ML Teams (green circles): Sibyl Drishti Brain Laser SAFT Alphabet companies (red circles): [X] Chauffeur Life Sciences Google products (yellow circles): Nest Search Indexing Android Speech Geo Play Music, Movies, Books, Games Image Search G+ GDN Context Ads YouTube Search Translate Email Inbox Play Apps Product Ads GMob Mobile Ads Google TV Security Google Now WebAnswers Genie Connections: Lines connect various ML teams to multiple Google products and Alphabet companies, indicating collaboration or integration of machine learning technologies. For example, the "Brain" ML team connects to numerous products such as Nest, Search Indexing, Android Speech, Geo, YouTube, and Translate, among others. The "Laser" team connects to products like Google TV, Security, Google Now, and Play Apps. Legend: Green circles: ML team Red circles: Alphabet companies Yellow circles: Google products Circle size is proportional to the number of connections Logo and Disclaimer: Google logo at the bottom left corner "Confidential & Proprietary" note at the bottom right corner This diagram visually represents the extensive integration of machine learning across various products and services within Google and its parent company Alphabet.](https://ipullrank.com/wp-content/uploads/2024/05/image19-1.png)
Using these three high-level models, we can start to think about how some of these components play together. From what I can glean from the documentation, it appears this API lives on top of Google’s Spanner. Spanner is an architecture that basically allows for infinite scalability of content storage and compute while treating a series of globally networked computers as one.
Admittedly, it’s somewhat difficult to piece the relationship between everything together from just the documentation, but Paul Haahr’s resume provides some valuable insight as to what some of the named ranking systems do. I’ll highlight the ones I know by name and segment them into their function.
Crawling
- Trawler – The web crawling system. It features a crawl queue, maintains crawl rates, and understands how often pages change.
Indexing
- Alexandria – The core indexing system.
- SegIndexer – System that places tiers documents into tiers within the index.
- TeraGoogle – Secondary indexing system for documents that live on disk long term.
Rendering
- HtmlrenderWebkitHeadless – Rendering system for JavaScript pages. Oddly this is named after Webkit rather than Chromium. There is mention of Chromium in the docs, so It’s likely that Google originally used WebKit and made the switch once Headless Chrome arrived.
Processing
- LinkExtractor – Extracts links from pages.
- WebMirror – System for managing canonicalization and duplication.
Ranking
- Mustang – The primary scoring, ranking, and serving system
- Ascorer – The primary rankings algorithm that ranks pages prior to any re-ranking adjustments.
- NavBoost – Re-ranking system based on click logs of user behavior.
- FreshnessTwiddler – Re-ranking system for documents based on freshness.
- WebChooserScorer – Defines feature names used in snippet scoring.
Serving
- Google Web Server – GWS is the server that the frontend of Google interacts with. It receives the payloads of data to display to the user.
- SuperRoot – This is the brain of Google Search that sends messages to Google’s servers to and managges the post-processing system for re-ranking and presentation of results.
- SnippetBrain – The system that generates snippets for results.
- Glue – The system for pulling together universal results using user behavior.
- Cookbook – System for generating signals. There is indication that values are created at runtime.
As I said, there are many more systems outlined in these docs, but it’s not entirely clear what they do. For instance, SAFT and Drishti from the above diagram are also represented in these documents, but their functions are unclear.
What are Twiddlers?
There is limited information online about Twiddlers in general, so I think it’s worth explaining them here so we can better contextualize the various Boost systems that we encounter in the docs.
Twiddlers are re-ranking functions that run after the primary Ascorer search algorithm. They operate similar to how filters and actions work in WordPress where what is displayed is adjusted right before being presented to the user. Twiddlers can adjust the information retrieval score of a document or change the ranking of a document. A lot of the live experiments and the named systems we know about are implemented this way. As this Xoogler demonstrates, they are quite important across a variety of Google systems:
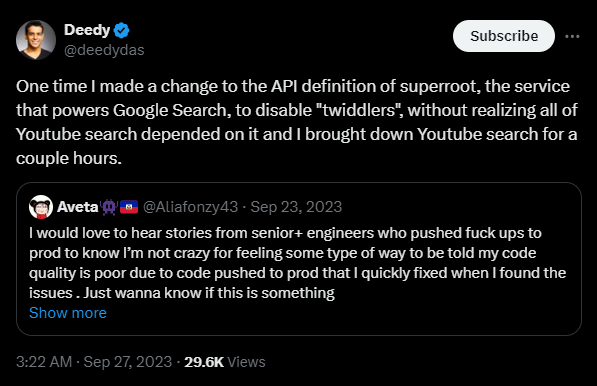
Twiddlers can offer category constraints, meaning diversity can be promoted by specifically limiting the type of results. For instance the author may decide to only allow 3 blog posts in a given SERP. This can clarify when ranking is a lost cause based on your page format.
When Google says something like Panda was not a part of the core algorithm this likely means it’s launched as a Twiddler as a reranking boost or demotion calculation and then later moved into the primary scoring function. Think of it as similar to the difference between server side and client side rendering
Presumably, any of the functions with a Boost suffix operate using the Twiddler framework. Here are some of the Boosts identified in the docs:
- NavBoost
- QualityBoost
- RealTimeBoost
- WebImageBoost
By their naming conventions, they are all pretty self-explanatory.
There’s also an internal document about Twiddlers I’ve reviewed that speaks to this in more detail, but this post sounds like the author saw the same doc that I did.
Key revelations that may impact how you do SEO
Let’s get to what you really came for. What is Google doing that we did not know or that we were unsure of and how can it impact my SEO efforts?
Quick note before we go further. It’s always my goal to expose the SEO industry to novel concepts. It is not my goal to give you a prescription on how to use it for your specific use case. If that’s what you want, you should hire iPullRank for your SEO. Otherwise, there is always more than enough for you to extrapolate from and develop your own use cases.
How Panda Works
When Panda rolled out there was a lot of confusion. Is it machine learning? Does it use user signals? Why do we need an update or a refresh to recover? Is it sitewide? Why did I lose traffic for a certain subdirectory?
Panda was released under Amit Singhal’s direction. Singhal was decidedly against machine learning due to its limited observability. In fact, there are a series of patents focusing on site quality for Panda, but the one I want to focus on is the non-descript “Ranking search results.” The patent clarifies that Panda is far simpler than what we thought. It was a largely about building a scoring modifier based on distributed signals related to user behavior and external links. That modifier can be applied on a domain level, subdomain, or subdirectory level.
“The system generates a modification factor for the group of resources from the count of independent links and the count of reference queries (step 306). For example, the modification factor can be a ratio of the number of independent links for the group to the number of reference queries for the group. That is, the modification factor (M) can be expressed as:
M=IL/RQ,
where IL is the number of independent links counted for the group of resources and RQ is the number of reference queries counted for the group of resources.”
The independent links are basically what we think of as linking root domains, but the reference queries are a bit more involved. Here’s how they are defined in the patent:
“A reference query for a particular group of resources can be a previously submitted search query that has been categorized as referring to a resource in the particular group of resources. Categorizing a particular previously submitted search query as referring to a resource in the particular group of resources can include: determining that the particular previously submitted search query includes one or more terms that have been determined to refer to the resource in the particular group of resources.”
Now that we have access to this documentation, it’s clear that reference queries are queries from NavBoost.

This suggests that Panda refreshes were simply updates to the rolling window of queries similar to how Core Web Vitals calculations function. It could also mean that updates to the link graph were not processed in real-time for Panda.
Not to beat a dead horse, but another Panda patent, Site quality score, also contemplates a score that is a ratio between the reference queries and user selections or clicks.
The bottom line here is that you need to drive more successful clicks using a broader set of queries and earn more link diversity if you want to continue to rank. Conceptually, it makes sense because a very strong piece of content will do that. A focus on driving more qualified traffic to a better user experience will send signals to Google that your page deserves to rank. You should focus on the same to recover from the Helpful Content Update.
Authors are an explicit feature
Much has been written about E-E-A-T. Many SEOs are non-believers because of how nebulous it is to score expertise and authority. I’ve also previously highlighted how little author markup is actually on the web. Prior to learning about vector embeddings, I did not believe authorship was a viable enough signal at web scale.
Nonetheless, Google does explicitly stores the authors associated with a document as text:
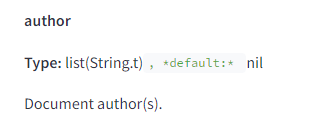
They also look to determine if an entity on the page is also the author of the page.
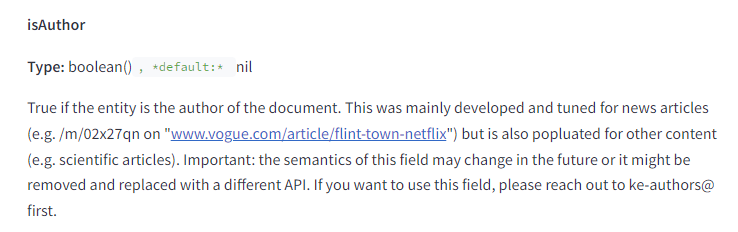
This combined with the in-depth mapping of entities and embeddings showcased in these documents, it’s pretty clear that there is some comprehensive measurement of authors.
Demotions
There are a series of algorithmic demotions discussed in the documentation. The descriptions are limited, but they are worth mentioning. We’ve already discussed Panda, but the remaining demotions I’ve come across are:
- Anchor Mismatch – When the link does not match the target site it’s linking to, the link is demoted on the calculations. As I’ve said before, Google is looking for relevance on both sides of a link.
- SERP Demotion – A signal indicating demotion based on factors observed from the SERP, suggesting potential user dissatisfaction with the page as likely measured by clicks.
- Nav Demotion – Presumably, this is a demotion applied to pages exhibiting poor navigation practices or user experience issues.
- Exact Match Domains Demotion – In late 2012, Matt Cutts announced that exact match domains would not get as much value as they did historically. There is a specific feature for their demotion.
- Product Review Demotion – There’s no specific information on this, but it’s listed as a demotion and probably related to 2023’s recent product reviews update.
- Location demotions – There is an indication that “global” pages and “super global” pages can be demoted. This suggests that Google attempts to associate pages with a location and rank them accordingly.
- Porn demotions – This one is pretty obvious.
- Other link demotions – We’ll discuss in the next section.
All these potential demotions can inform a strategy, but it boils down to making stellar content with strong user experience and building a brand, if we’re being honest.
Links Still Seem to be Pretty Important
I have not seen any evidence to refute recent claims that links are considered less important. Again, that is likely to be handled in the scoring functions themselves rather than how the information is stored. That said, there has been great care to extract and engineer features to deeply understand the link graph.
Indexing Tier Impacts Link Value
A metric called sourceType that shows a loose relationship between the where a page is indexed and how valuable it is. For quick background, Google’s index is stratified into tiers where the most important, regularly updated, and accessed content is stored in flash memory. Less important content is stored on solid state drives, and irregularly updated content is stored on standard hard drives.

Effectively, this is saying the higher the tier, the more valuable the link. Pages that are considered “fresh” are also considered high quality. Suffice it to say, you want your links to come from pages that either fresh or are otherwise featured in the top tier. This partially explains why getting rankings from highly ranking pages and from news pages yields better ranking performance. Look at that, I just made digital PR cool again!
Link Spam Velocity Signals
There is a whole series of metrics about the identification of spikes in spam anchor text. Noting the phraseAnchorSpamDays feature, Google effectively has the ability to measure link velocity of spam.
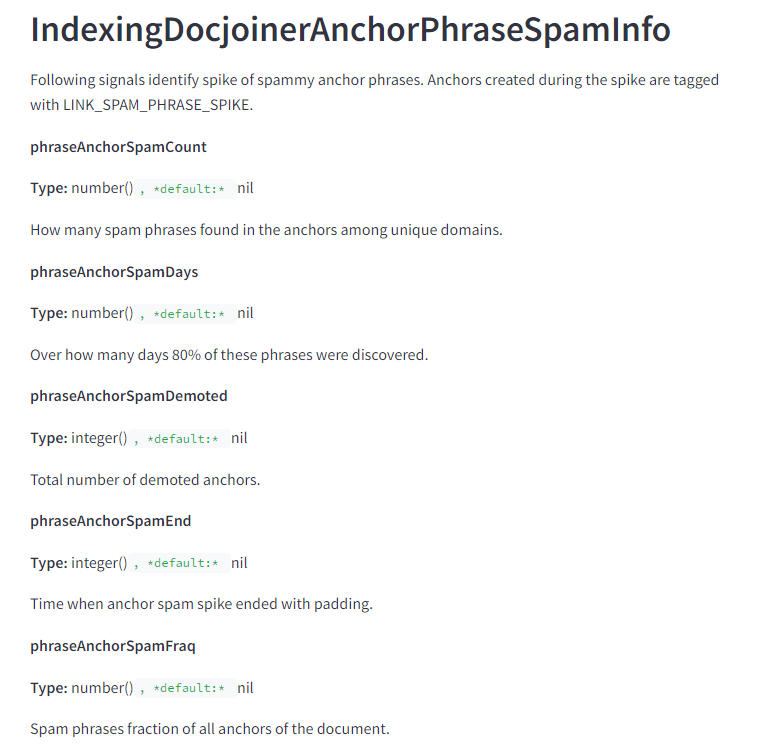
This could easily be used to identify when a site is spamming and to nullify a negative SEO attack. For those that are skeptical about the latter, Google can use this data to compare a baseline of link discovery against a current trend and simply not count those links in either direction.
Google only uses the last 20 changes for a given URL when analyzing links
I’ve previously discussed how Google’s file system is capable of storing versions of pages over time similar to the Wayback Machine. My understanding of this is that Google keeps what it has indexed forever. This is one of the reasons you can’t simply redirect a page to an irrelevant target and expect the link equity to flow.
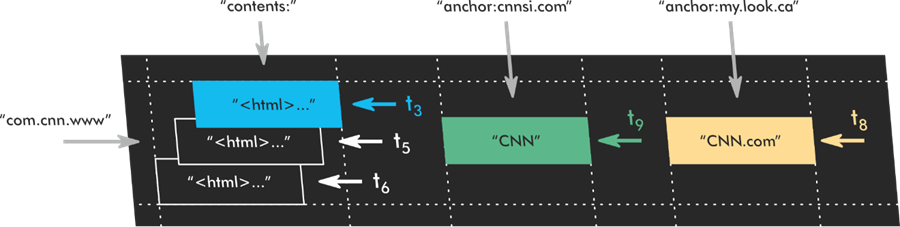
The docs reinforce this idea implying that they keep all the changes they’ve ever seen for the page.
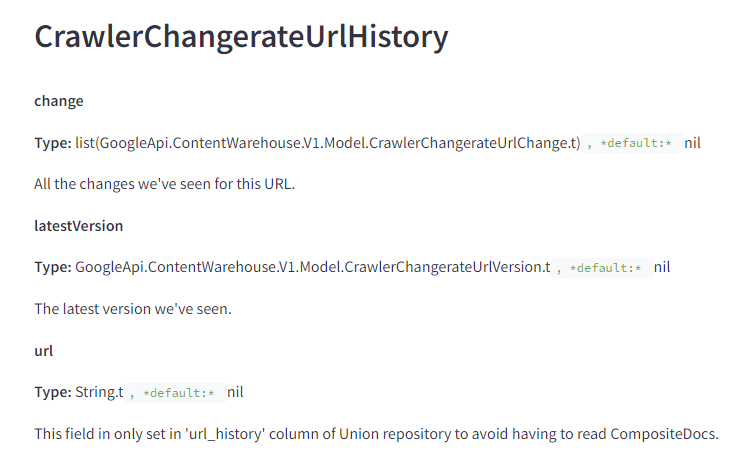
When they do surface data for comparison by retrieving DocInfo, they only consider the 20 latest versions of the page.
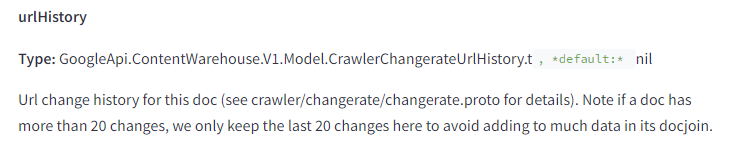
This should give you a sense of how many times you need to change pages and have them indexed to get a “clean slate” in Google.
Homepage PageRank is considered for all pages
Every document has its homepage PageRank (the Nearest Seed version) associated with it. This likely used as a proxy for new pages until they capture their own PageRank.

It is likely that this and siteAuthority are used as proxies for new pages until they have their own PageRank calculated.
Homepage Trust
Google is decides how to value a link based on how much they trust the homepage.

As always, you should be focusing on quality and relevance of your links instead of volume.
Font Size of Terms and Links Matters
When I first started doing SEO in 2006 one of the things we did was bold and underline text or make certain passages bigger to make them appear more important. In the past 5 years I’ve seen people say that is still worth doing. I was skeptical, but now I see that Google is tracking the average weighted font size of terms in documents.

They are doing the same for the anchor text of links.

Penguin Drops Internal Links
Within many of the anchor related modules the idea of “local” means the same site. This droppedLocalAnchorCount suggests that some internal links are not counted.
I Did Not See a Single Mention of Disavow
While disavow data could be stored elsewhere, it is not specifically in this API. I find that specifically because the quality raters data is directly accessible here. This suggests that the disavow data is decoupled from the core ranking systems.
My long term assumption has been that disavow has been a crowd sourced feature engineering effort to train Google’s spam classifiers. The data not being “online” suggests that this may be true.
I could keep going on links and talk about features like IndyRank, PageRankNS, and so on, but suffice it to say Google has link analysis very dialed in and much of what they are doing is not approximated by our link indices. It is a very good time to reconsider your link building programs based on everything you’ve just read.
Documents Get Truncated
Google counts the number of tokens and the ratio of total words in the body to the number of unique tokens. The docs indicate that there is a maximum number of tokens that can be considered for a document specifically in the Mustang system thereby reinforcing that authors should continue to put their most important content early.

Short Content is Scored for Originality
The OriginalContentScore suggests that short content is scored for its originality. This is probably why thin content is not always a function of length.

Conversely, there is also a keyword stuffing score.
Page Titles Are Still Measured Against Queries
The documentation indicates that there is a titlematchScore. The description suggests that how well the page title matches the query is still something that Google actively gives value to.

Placing your target keywords first is still the move.
There Are No Character Counting Measures
To his credit, Gary Ilyes has said that SEOs made up the whole optimal character count for metadata. There is no metric in this dataset that counts the length of page titles or snippets. The only character counting measure I found in the documentation is the snippetPrefixCharCount which appears to be set to determine what can be used as part of the snippet.

This reinforces what we’ve seen tested many times, lengthy page titles are suboptimal for driving clicks, but they are fine for driving rankings.
Dates are Very Important
Google is very focused on fresh results and the documents illustrate its numerous attempts to associate dates with pages.
- bylineDate – This is the explicitly set date on the page.
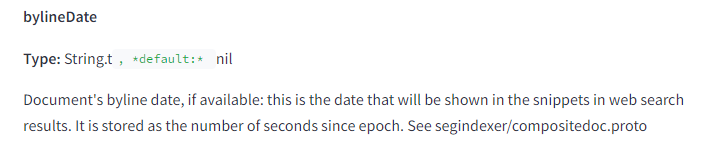
- syntacticDate – This is an extracted date from the URL or in the title.

- semanticDate – This is date derived from the content of the page.

Your best here is specifying a date and being consistent with it across structured data, page titles, XML sitemaps. Putting dates in your URL that conflict with the dates in other places on the page will likely yield lower content performance.
Domain Registration Info is Stored About the Pages
It’s been a long-running conspiracy theory that Google’s status as a registrar feeds the algorithm. We can upgrade to a conspiracy fact. They store the latest registration information on a composite document level.
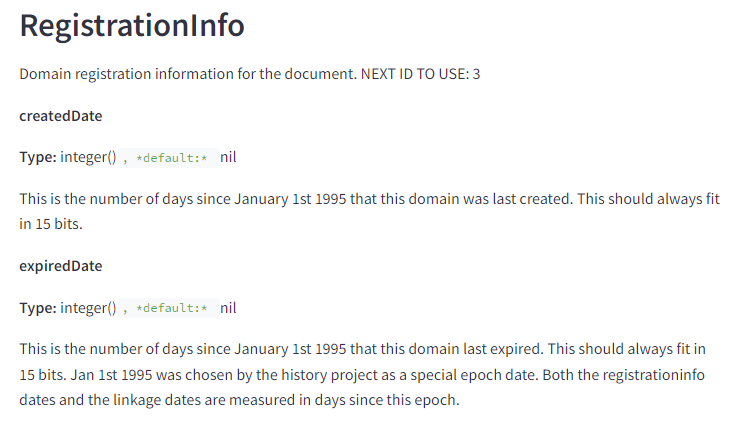
As previously discussed, this is likely used to inform sandboxing of new content. It may also be used to sandbox a previously registered domain that has changed ownership. I suspect the weight on this has been recently turned up with the introduction of the expired domain abuse spam policy.
Video Focused Sites are Treated Differently
If more than 50% of pages on the site have video on them, the site is considered video-focused and will be treated differently.

Your Money Your Life is specifically scored
The documentation indicates that Google has classifiers that generate scores for YMYL Health and for YMYL News.
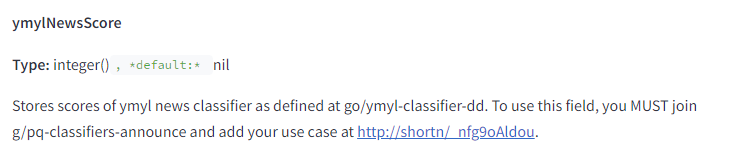
They also make a prediction for “fringe queries” or those that have not been seen before to determine if they are YMYL or not.
![The image displays a section from a technical documentation page. It includes the following elements and text: encodedChardXlqYmylPrediction Type: integer(), default: nil An encoding of the Chard XLQ-YMYL prediction in [0,1].](https://ipullrank.com/wp-content/uploads/2024/05/image35.png)
Finally, YMYL is cored on the chunk level which suggests that whole system is based on embeddings.
There are Gold Standard Documents
There is no indication of what this means, but the description mentions “human-labeled documents” versus “automatically labeled annotations.” I wonder if this is a function of quality ratings, but Google says quality ratings don’t impact rankings. So, we may never know. 🤔

Site Embeddings Are Used to Measure How On Topic a Page is
I’ll talk about embeddings in more detail in a subsequent post, but is worth noting that Google is specifically vectorizing pages and sites and comparing the page embeddings to the site embeddings to see how off-topic the page is.
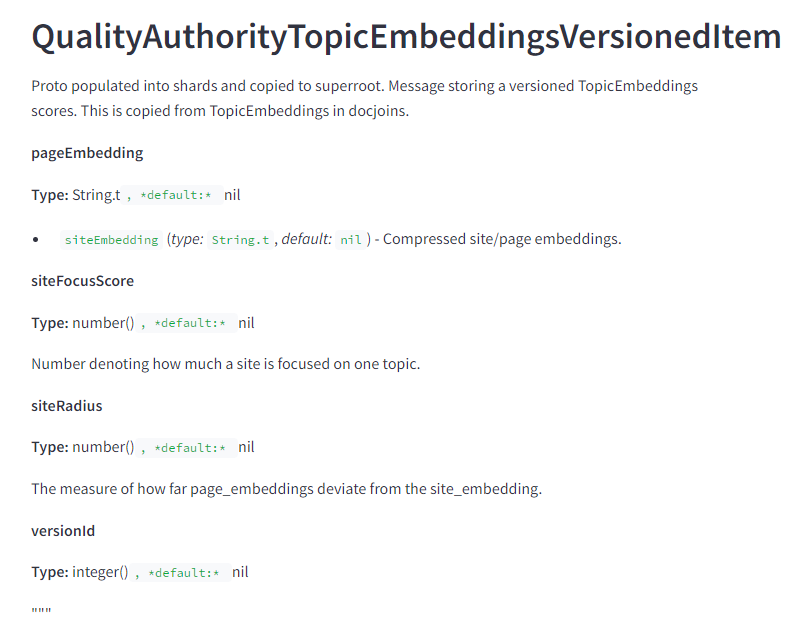
The siteFocusScore captures how much the site sticks to a single topic. The site radius captures how far the page goes outside of the core topic based on the site2vec vectors generated for the site.
Google May Be Torching Small Sites on Purpose
Google has a specific flag that indicates is a site is a “small personal site.” There’s no definition of such sites, but based on everything we know, it would not be difficult for them to add a Twiddler that boosted such sites or one that demoted them.

Considering the backlash and the small businesses that have been torched by the Helpful Content Update, it’s a wonder that they use this feature to do something about it.
My Open Questions
I could keep going, and I will, but it’s time for an intermission. In the meantime, I suspect it is inevitable that others will be all over this leak deriving their own conclusions. At the moment, I have a few open questions that I would love for us to all to consider.
Is the Helpful Content Update known as Baby Panda?
There are two references to something called “baby panda” in the Compressed Quality Signals. Baby Panda is a Twiddler which is a bolt on adjustment after initial ranking.
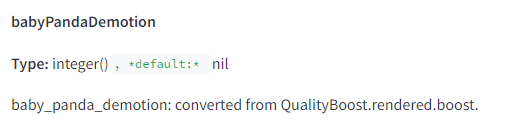
There is a mention of it working on top of Panda, but no other information in the docs.

I think we are generally in agreement that the Helpful Content Update has many of the same behaviors of Panda. If it’s built on top of a system using reference queries, links, and clicks those are the things you’ll need to focus on after you improve your content.
Does NSR mean Neural Semantic Retrieval?
There are a ton of references to modules and attributes with NSR as part of the naming convention. Many of these are related to site chunks and embeddings. Google has previously discussed “Neural Matching” as a big focus for improvements. My educated guess is that NSR stands for Neural Semantic Retrieval and these are all features related to semantic search. However, in some instances they mention next to a “site rank.”
I’d love for some rebellious Googler to head to go/NSR and just send me a “you’re right” from an anonymous email address or something.
Actionables
Like I said, I don’t have any prescriptions for you. I do have some strategic advice though.
- Send Rand Fishkin an Apology – Since my “Everything Google Lied to Us About” keynote at PubCon, I have been on a campaign to clear Rand’s name as it relates to NavBoost. Rand did a thankless job of trying to help our industry elevate for years. He caught a lot of flack for it on the Google side and on the SEO side. Sometimes he didn’t get things right, but his heart was always in the right place and he put forth strong efforts to make what we do respected and just better. Specifically, he was not wrong about the conclusions from his click experiments, his repeated attempts to show the existence of a Google Sandbox, his case studies showing Google ranks subdomains differently, and his long-belittled belief that Google employs sitewide, authority-style signals. You also have him to thank for this analysis as he was the one to share the documentation with me. Now is a good time for a lot of y’all to show him love on Threads.
- Make Great Content and Promote it Well – I’m joking, but I’m also serious. Google has continued to give that advice and we balk at it as not actionable. For some SEOs it’s just beyond their control. After reviewing these features that give Google its advantages, it is quite obvious that making better content and promoting it to audiences that it resonates with will yield the best impact on those measures. Measures of link and content features will certainly get you quite far, but if you really want to win in Google long term, you’re going to have to make things that continue to deserve to rank.
- Bring Back Correlation Studies – We now have a much better understanding of many of the features that Google is using to build rankings. Through a combination of clickstream data and feature extraction, we can replicate more than we could previously. I think it’s time to bring back vertical-specific correlation studies.
- Test and Learn – You should have seen enough visibility and traffic charts with Y-axes to know you can’t trust anything you read or hear in SEO. This leak is another indication that you should be taking in the inputs and experimenting with them to see what will work for your website. It’s not enough to look at anecdotal reviews of things and assume that’s how Google works. If your organization does not have an experimentation plan for SEO, now is a good time to start one.
We know what we're doing
An important thing we can all take away from this is: SEOs know what they are doing. After years of being told we’re wrong it’s good to see behind the curtain and find out we have been right all along. And, while there are interesting nuances of how Google works in these documents there is nothing that is going to make dramatically change course in how I strategically do SEO.
For those that dig in, these documents will primarily serve to validate what seasoned SEOs have long advocated. Understand your audience, identify what they want, make the best thing possible that aligns with that, make it technically accessible, and promote it until it ranks.
To everyone in SEO that has been unsure of what they are doing, keep testing, keep learning, and keep growing businesses. Google can’t do what they do without us.
Download the Rankings Features
Welp, someone is going to download and organize all the features into a spreadsheet for you. It might as well be me. We only have a month left in the quarter and I want to get our MQLs up anyway. 😆
Grab your copy of the rankings features list.
We’re Just Getting Started
What I’ve always loved about SEO is that it is a constantly evolving puzzle. And while helping brands make billions of dollars from our efforts is fun, there is something very satisfying about feeding my curiosity with all the sleuthing related to picking apart how Google works. It has been a great joy to finally get to see behind the curtain.
That’s all I’ve got for now, but let me know what you find! Anyone that wants to share something with me can reach out. I’m pretty easy to find!
Next Steps
Here are 3 ways iPullRank can help you combine SEO and content to earn visibility for your business and drive revenue:
- Schedule a 30-Minute Strategy Session: Share your biggest SEO and content challenges so we can put together a custom discovery deck after looking through your digital presence. No one-size-fits-all solutions, only tailored advice to grow your business. Schedule your consultation session now.
- Mitigate the AI Overviews’ Potential Impact: How prepared is your SEO strategy for Google’s AI Overviews? Get ahead of potential threats and ensure your site remains competitive with our comprehensive AI Overviews Threat Report. Get your AI Overviews report.
- Enhance Your Content Relevancy with Orbitwise: Not sure if your content is mathematically relevant? Use Orbitwise to test and improve your content’s relevancy, ensuring it ranks for your targeted keywords. Test your content relevance today.
Want more? Visit our Resources Page for access to past webinars, exclusive guides, and insightful blogs crafted by our team of experts.






Leave a Comment