
Here we are going to show you how to generate quality and useful meta descriptions using advanced text summarization methods in natural language generation (NLG) with Python code.
The methods in the article work well for pages with rich content, like news page blog pages.
What are meta descriptions?
The meta description is an HTML attribute that provides a brief summary of a web page. Although meta descriptions have already been removed from Google’s ranking algorithms for web search back in 2009, it is still an important factor for a page’s CTR (click-through rate), and that click behavior can positively reinforce a page’s ranking. Therefore, it is worth it for companies to keep paying attention to meta descriptions.
What is text summarization?
Text summarization is one of the NLG (natural language generation) techniques. The goal of text summarization is to produce a concise summary while preserving key information and overall meaning.
There are two types of text summarization, abstractive and extractive summarization.
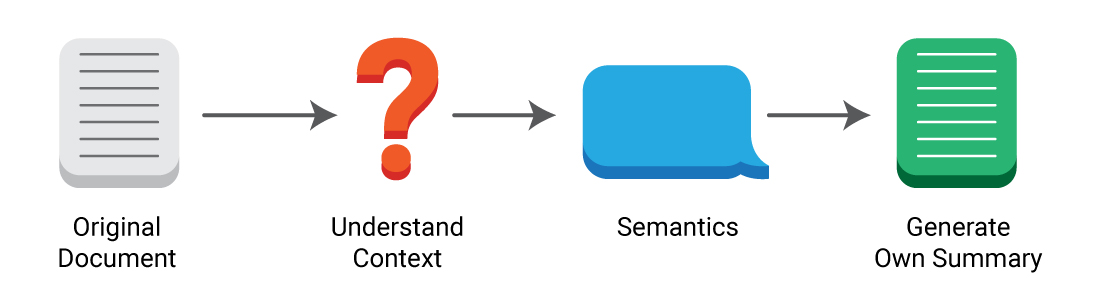
1. The abstractive summarization method generates a summary based on the semantic understanding of original documents, therefore, not all words in the summary appear in original documents. The process is similar to the way humans read an article and then summarize it in their own words.
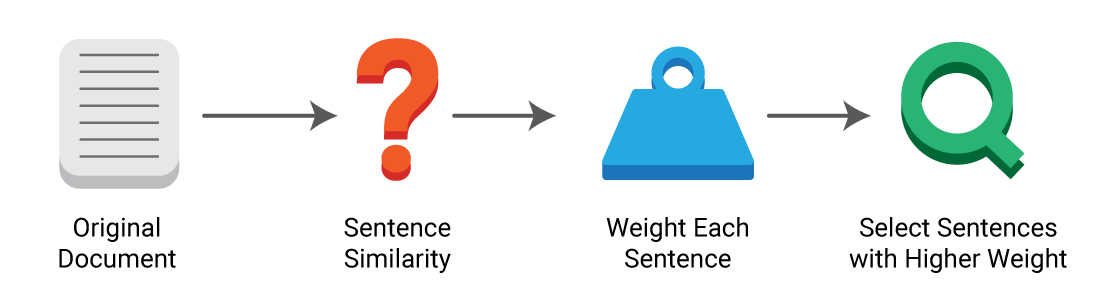
2. The extractive summarization method selects certain sentences that contain the most important information to summarize articles. Effectively, extracting those sentences to construct the summary. In this case, no original copy is generated.
You might be curious about how this method identifies important sentences. While there are various algorithms to define weights and rank each sentence, they are all based on similarities among the sentences.
As we can see, the algorithm between the two methods is different; and compared to the extractive method, abstractive summarization needs a deeper understanding of the text which requires a much more complex algorithm. In addition, for a company that has a clear voice and tone, abstractive summarization is not a good choice as it is not able to keep it.
Therefore, you will see that extractive summarization is more broadly used as it requires simpler code, can keep the same voice and tone, and needs less manual revamp.
Text summarization methods in Python
Hugging Face Transformers
The Transformers library is a state-of-the-art natural language library with deep interoperability between TensorFlow 2.0 and PyTorch. It contains many popular architectures (BERT, GPT-2, XLM, DistilBert, etc.) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 30 pre-trained models, some in more than 100 languages.
In the Transformers library, you can easily use different models by using pipelines. These pipelines represent different tasks, like Sentiment Analysis, Feature Extraction, and Question Answering.
Now, let’s see how easy it is to summarize using Transformers pipelines.
1. Install the Transformers library in a Google Colab notebook.
!pip install transformers
2. Import the Transformers library, and add the summarization pipeline. This pipeline contains various models that have been fine-tuned, including ‘bart-large-cnn’, ‘t5-small’, ‘t5-base’, ‘t5-large’, ‘t5-3b’, and ‘t5-11b’. The default is the BART model.
from transformers import pipeline
summarizer = pipeline('summarization')
3. Load your documents.
import pandas as pd
file_name='test.txt'
text = pd.read_csv((file_name), sep='\t', header=None,
encoding='utf-8').iloc[0,0]
Below is the content we used.
“How Often Should I Add New Content? The best way to find an answer to your question is to consider your audience. If you have content worth engaging with daily, provide new content daily. If you are creating new content just to create new content, chances are it won’t be worth the investment. Google doesn’t just consider freshness, it considers a host of other important signals and factors to determine ranking. Just because it’s new, doesn’t mean it’s relevant. Deciding on the frequency for your content will largely depend on your audience, your brand, your product, and how often you have content of value to provide. Let’s put it this way. In 2020, WordPress users post 70 million new posts every month. According to a Botify Study, 94% of blog posts get no links. So why focus on quantity when, clearly, content is a quality game. Frequency does affect how often your site gets crawled, according to Google’s Caffeine Update. If you update your site once a year, Google’s not going to waste its crawl budget crawling your site daily. If you update regularly, it makes sense to crawl your website regularly. The more regularly you get crawled, the more opportunity you have to rank, and the more impact updates and changes will have on your ranking.”
4. Import the pipeline, and run the model. I specified the summary should have more than 10 characters and at most 250.
# use bart in pytorch
generated_text = summarizer(text, min_length=10, max_length=250)
generated_text[0]['summary_text']
Below is the summary generated.
“In 2020, WordPress users post 70 million new posts every month. Google doesn’t just consider freshness, it considers a host of other important signals and factors to determine ranking. Frequency does affect how often your site gets crawled, according to Google’s Caffeine Update.”
You might be surprised at the quality of the result, but I recommend a summary using a different model as there is no best model. Besides the BART model, T5 is another state-of-the-art text model.
t5_summarizer = pipeline('summarization', model='t5-large',
tokenizer='t5-large')
t5_generated_text = t5_summarizer(text, min_length=10, max_length=250)
Below is the summary generated by the T5 model.
“if you have content worth engaging with daily, provide new content daily. in 2020, WordPress users post 70 million new posts every month. the more regularly you get crawled, the more opportunity you have to rank.”
As you can see, this summary is still impressive.
TextRank
TextRank is a general-purpose, graph-based ranking algorithm for NLP, which measures the similarity between two sentences using cosine similarity and ranks sentences using the algorithm of PageRank.
TextRank is also an unsupervised learning approach that you don’t need to build and train a model prior to starting using it.
Before starting our code, it is helpful to understand cosine similarity. Cosine similarity is a measure of similarity by calculating the cosine of the angle between vectors. Since sentences will be represented by a bunch of vectors, we can use cosine similarity to find the similarity.
Let’s start the code.
1. Import necessary libraries
import pandas as pd
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from spacy.lang.en import English
from spacy.tokenizer import Tokenizer
from nltk.cluster.util import cosine_distance
import numpy as np
import networkx as nx
2. Read your document, and transform it to a list of all sentences
def read_article(filename):
file = pd.read_csv(filename, sep='\t', header=None,encoding='utf-8')
filedata = file.iloc[0,0]
sentences = filedata.split('.')
sentences = sentences[:len(sentences)-1]
return sentences
3. Processing sentences, calculate similarity, and generate a similarity matrix
nlp = spacy.load('en_core_web_lg')
nlp.max_length = 1500000
We used the spaCy library to process sentences, like removing punctuation and stop words. spaCy is a free open-source library for advanced natural language processing. Compared with most natural language libraries, including NLTK, spaCy not only offers access to larger word vectors, but also provides faster and more accurate syntactic analysis.
spaCy offers models with different sizes. In order to generate a better performance, we loaded a large-size pre-trained model.
def sentence_similarity(sent1, sent2):
tokens1 = nlp(sent1)
sent1 = [word.lemma_ for word in tokens1 if (word.is_punct==False)&(word.is_stop==False)&(word.is_alpha)&(len(word.orth_)>1)]
tokens2 = nlp(sent2)
sent2 = [word.lemma_ for word in tokens2 if (word.is_punct==False)&(word.is_stop==False)&(word.is_alpha)&(len(word.orth_)>1)]
all_words = list(set(sent1 + sent2))
vector1 = [0] * len(all_words)
vector2 = [0] * len(all_words)
# build the vector for the first and second sentences
for w in sent1:
vector1[all_words.index(w)] += 1
for w in sent2:
vector2[all_words.index(w)] += 1
return 1 - cosine_distance(vector1, vector2)
This function is to calculate the cosine similarity between two sentences.
def build_similarity_matrix(sentences):
# Create an empty similarity matrix
similarity_matrix = np.zeros((len(sentences), len(sentences)))
for idx1 in range(len(sentences)):
for idx2 in range(len(sentences)):
if idx1 != idx2: #if both are not same sentences
similarity_matrix[idx1][idx2] = sentence_similarity(sentences[idx1], sentences[idx2])
return similarity_matrix
By embedding the previous function into this one, we are building a matrix to store similarity among sentences.
4. Generate summary
def generate_summary(filename, num_of_sentences=5):
summarize_text = []
sentences = read_article(filename)
# Generate Similary Martix
sentence_similarity_martix = build_similarity_matrix(sentences)
# Rank sentences
sentence_similarity_graph = nx.from_numpy_array(sentence_similarity_martix)
scores = nx.pagerank(sentence_similarity_graph)
# Sort the rank and pick top sentences
ranked_sentence = sorted(((scores[i],s) for i,s in enumerate(sentences)), reverse=True)
for i in range(num_of_sentences):
summarize_text.append(ranked_sentence[i][1])
summarize = '. '.join(summarize_text)
print(summarize)
Before generating a summary, there is one last step, ranking sentences. Here we borrow the algorithm of PageRank. As we all know, PageRank is an algorithm used by Google Search to rank web pages in their search engine results.
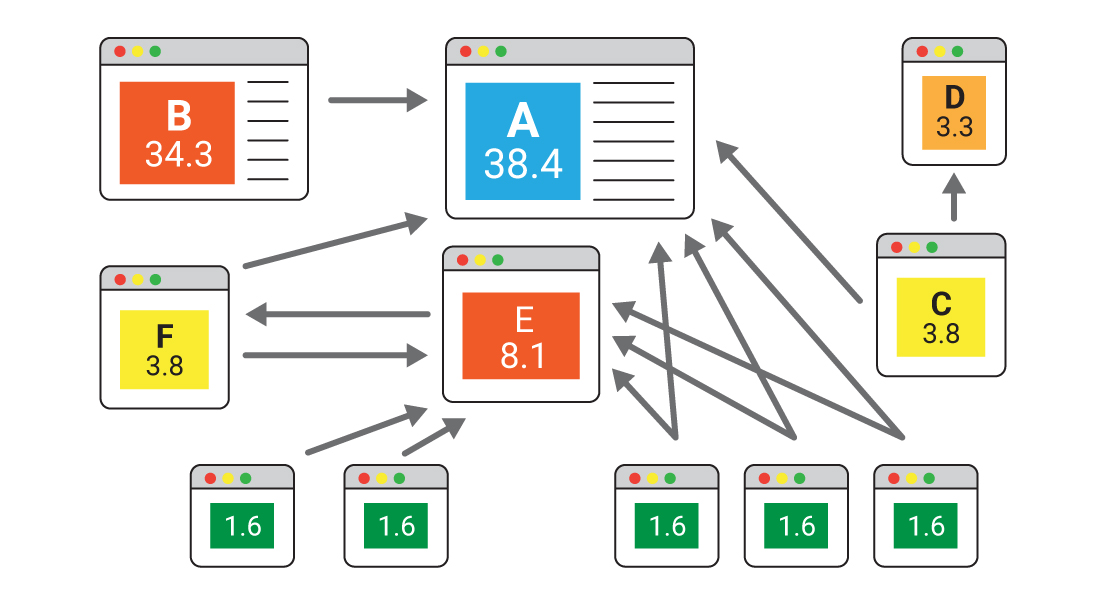
PageRank consists of two basic but important components, nodes and value of links. Each node represents a web page, and the value of links is determined based on page importance. For TextRank, notes are sentences, and the value of links is the similarity between two sentences.
To calculate the weight for each sentence and rank them, we used a cool library, called NetworkX, which helps us first transform the similarity matrix to a graph, and then compute a weight for each sentence in the graph based on the structure and similarity of the links.
5. Check the result
We used the same content, and below is the summary generated.
“If you have content worth engaging with daily, provide new content daily. If you are creating new content just to create new content, chances are it won’t be worth the investment. If you update your site once a year, Google’s not going to waste its crawl budget crawling your site daily. Frequency does affect how often your site gets crawled, according to Google’s Caffeine Update”
As you can see, the result is not bad. And you can customize the number of sentences as well.
Hope the above two methods can help you generate accurate and useful summaries. If you are interested in text summarization, there are a lot of more-advanced text summarization techniques that are worth playing around with.
- Extractive Text Summarization using Neural Networks
- Using Latent Semantic Analysis in Text Summarization and Summary Evaluation
- Text Summarization using Deep Learning
- Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting
Learn More from iPullRank
If you’d like to learn more about the techniques used by our staff here at iPullRank, check out our blog and sign up for our newsletter. If you need more hands-on expertise, you can reach out to one of our Account Executives to learn more about how we can help improve your company’s marketing efforts.








