

Have you ever worked on a site with a million pages?
At that scale, Googlebot doesn’t always crawl every page, let alone index them.
- Broken links.
- Slow response times.
- Low crawl frequency.
With such quantity, you need a way to analyze website performance and catch technical issues before your organic search traffic takes a hit.
Log file analysis is a not-so-secret and critical, though sometimes underutilized, element of an SEO strategy. With the growing complexity of the web and increased competition online, it is an even more important tactic than ever to gain data-backed insights into how your website is performing.
So what is log file analysis and why does it matter for SEO?
Your web servers record and measure the crawl behavior of search engines. These logs can reveal issues and opportunities that impact the way that Google sees your site. In other words, monitoring and analyzing log files lets you see your website how Google sees it.
SEOs analyze those logs to determine how efficiently Google interacts with your website. Proper log analysis can highlight and inform optimizations and fixes to better guide search engines to your most important and strategic pages. As a result, you maximize traffic, revenue, and the overall impact of organic search.
In the words of Dana Tan, Director of SEO at Under Armour:
“Getting server logs takes the conjecture out of SEO and it’s 100% scientific. It’s data. You can’t argue with cold, hard data. And that really makes SEO a science instead of guesswork.”
Where are server log files stored and how can you access them?
In many cases, just getting access to the server logs themselves is the hardest part. Access to your server logs depends on your server and hosting setup – and you most likely will need to engage with the DevOps or Engineering team to get the appropriate permissions. In most scenarios, traffic is delivered through a Content Delivery Network (CDN) such as Akamai, Cloudflare, or Fastly, and can be delivered to an AWS S3 bucket or database.
The anatomy of a clean log line
Before delving into your CDN, let’s take a look at a clean log line for a crawl from Googlebot:
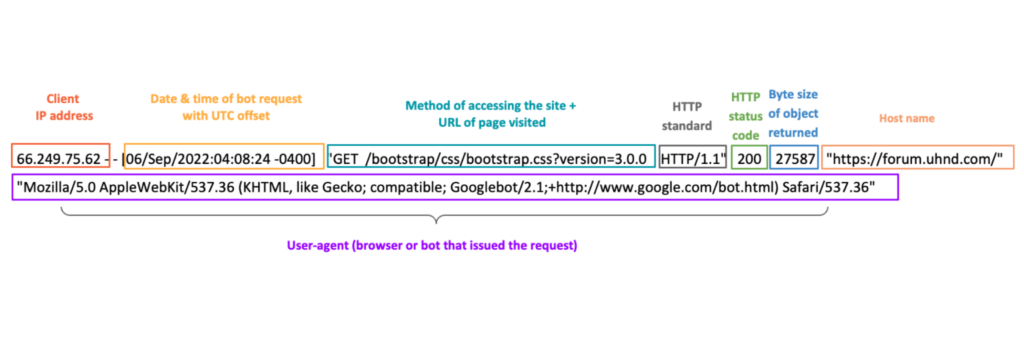
Although log data is usually simple in format, it’s important to realize the common hurdles that arise when attempting to retrieve and convert the data into “readable” metrics. Too often, SEOs end up with a lot of manual work, unstable files, missed data, or inaccurate analyses.
- Log files for a large website can quickly add up to gigabytes of data, becoming quite cumbersome. This data is often too large for desktop analysis tools, so you will need to have the files compressed and then decompressed when retrieving the data.
- Some log files may require multiple downloads in a single day.
- Log files need to be parsed to extract the specific data that is useful for SEO, and then transcribed into SEO terms such as crawl volume, visit volume, unique URLs, and more.
Instead of trying to manage log files yourself or manually parse through millions of cells worth of data, you can have your log files automatically fed into a usable interface made specifically for SEOs. In our case, it’s into the Botify LogAnalyzer within the Botify Analytics suite.
Botify can ingest a subset of the SEO-relevant data from the web server log files based on direct delivery from the CDNs, parse that data, and do so programmatically and on a recurring basis.
By handling log files in this manner, you are also ensuring the highest level of security.
When ingesting the logs, Botify uses the IP address from your log files to validate the user agent to avoid inflating data with spoofing, while leveraging the referrer data to provide visit insights.
Botify never processes personal data. If a personal IP address is not removed by the client and surfaces in the server log files, Botify permanently removes all of this information before processing any log files. Botify is GDPR and SOC2 compliant, providing the highest standard of data privacy and security for brands.
Reading a log file analysis report: what could you uncover?
Quite a lot, actually! Log file analysis allows you to:
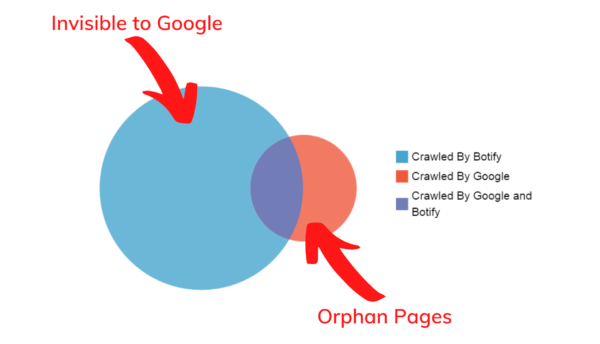
- See if Google is spending time on unimportant pages, like duplicate content or orphan pages.
- Evaluate crawls by segments and analyze search engine behavior on specific sections of your website.
- Understand the distribution of bad status codes and server errors such as 3XX, 4XX, or 5XXs that may impact Google’s ability to properly and efficiently crawl your website and discover content.
- Compare crawl volume to unique URLs crawled and learn of any new URLs that weren’t in a previous crawl.
- Know how frequently Googlebot is crawling your website, helping you chart the relationship between crawl frequency, crawl budget, and traffic fluctuations and determine if the frequency is aligned with your publishing schedule.
Below are some valuable visuals from Botify’s LogAnalyzer. Within Botify’s tool, specifically, you have the flexibility of viewing data such as crawl volume or unique number of URLs for the entire website – or based on specific site segments, customizable within the platform.
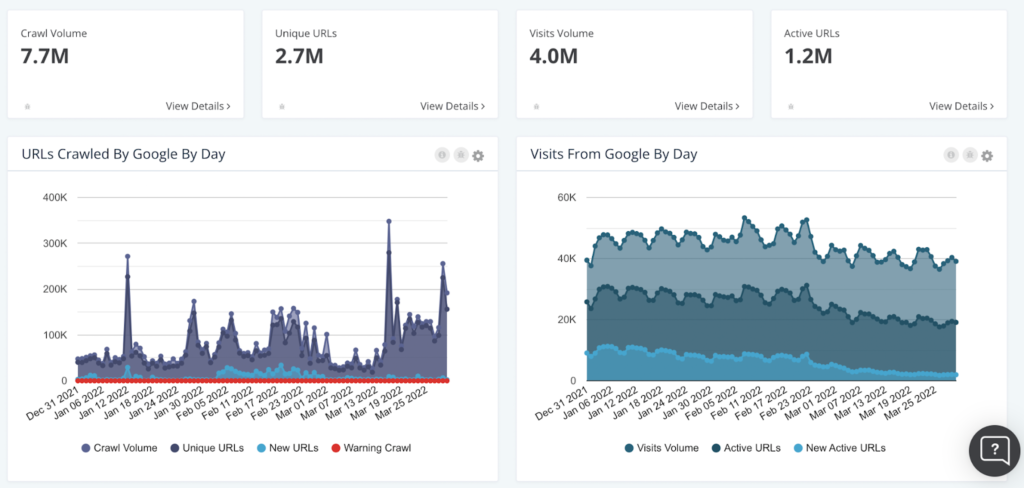
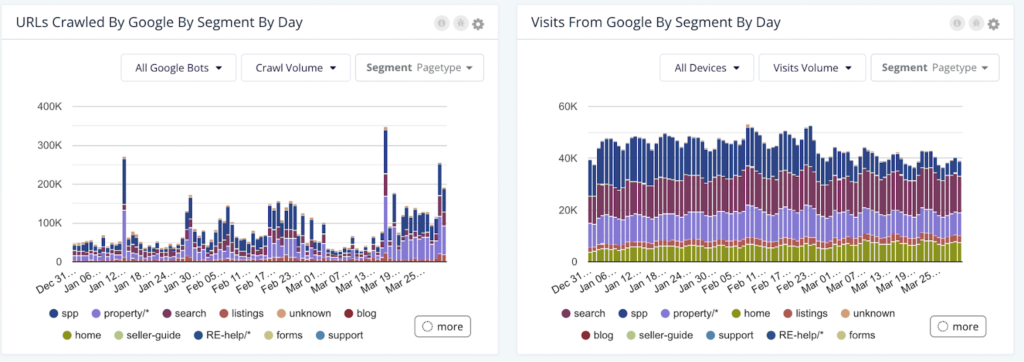
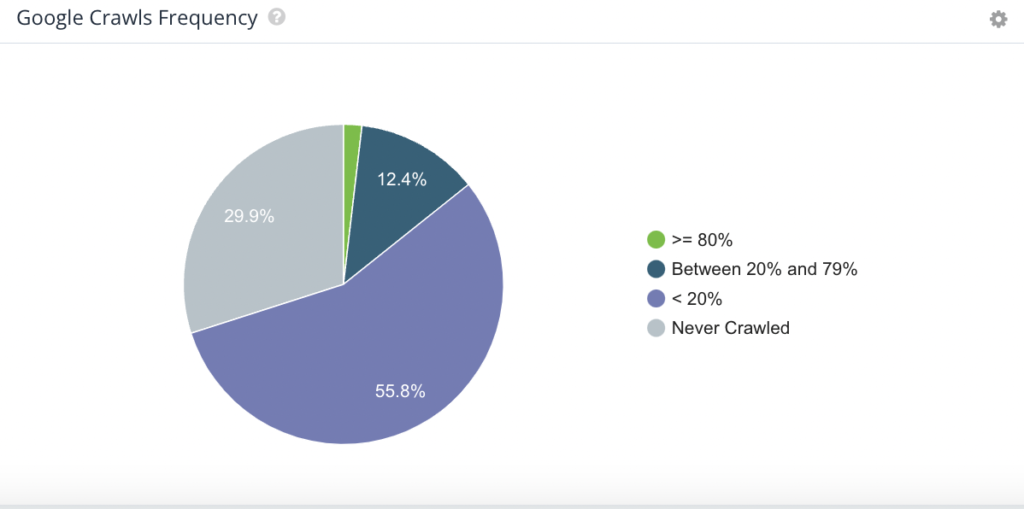
For example, if you’re managing an ecommerce website that sells sportswear, apparel, athletic gear, and accessories, you can isolate portions of the website for analysis, whether by category, i.e. sneakers, by content type, i.e. tennis, or by gender, i.e. women. Alternatively, if managing a news site, you may choose to segment the website based on content type, i.e. articles, or sections i.e. international news. This not only allows for easier sharing of data across teams, but also helps to pinpoint where issues may be on the website. This becomes incredibly useful when there are specific events such as a product launch or major news event.
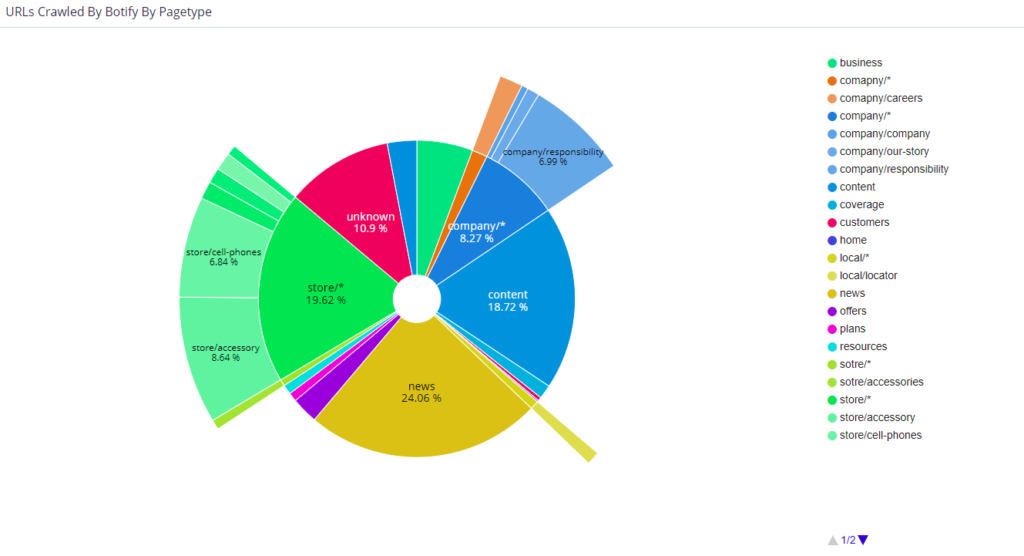
In fact, one of Botify’s publisher customers experienced a short-term boost in traffic followed by a steep decline in traffic. A recent news event was responsible for the boost, and when they isolated their pages by content, they were able to see that their evergreen content was suffering. The only way to identify the problem was by splitting both types of content through segmentation.
It’s also important to monitor which pages are being crawled frequently in order to gauge if search engine bots are coming back to your website often enough and finding new content when they do return. If you notice that they are coming back to pages that remain largely unchanged, this can be a waste of crawl budget that would be better used on pages with fresh content.
Monitoring 304s and static resources
Within LogAnalyzer, you can see all of your pages that return a 304 status code. This status code signals to a web crawler that it has not been modified and should be cached, helping lower the crawl frequency to these pages and freeing up crawl budget to be allocated to other pages. Reviewing 304s is also a useful tactic for site audits to determine if your server is telling search engines that pages that have, in fact, been updated, have not been.
Similarly, you can monitor the frequency at which search engine bots are crawling static resources such as JavaScript files, fonts, CSS files, and more – but also the number of resources they are spending to render this content. This not only affects crawl budget, but also render budget.
Render budget looks at how many pages a search engine bot is able to fully execute and the resources it takes to do so as compared to a simple HTML page. If 40+% of your crawls are going towards these types of resources, you may potentially have a render budget issue, which would impact how much content Google will crawl and ultimately render in a given timeframe.
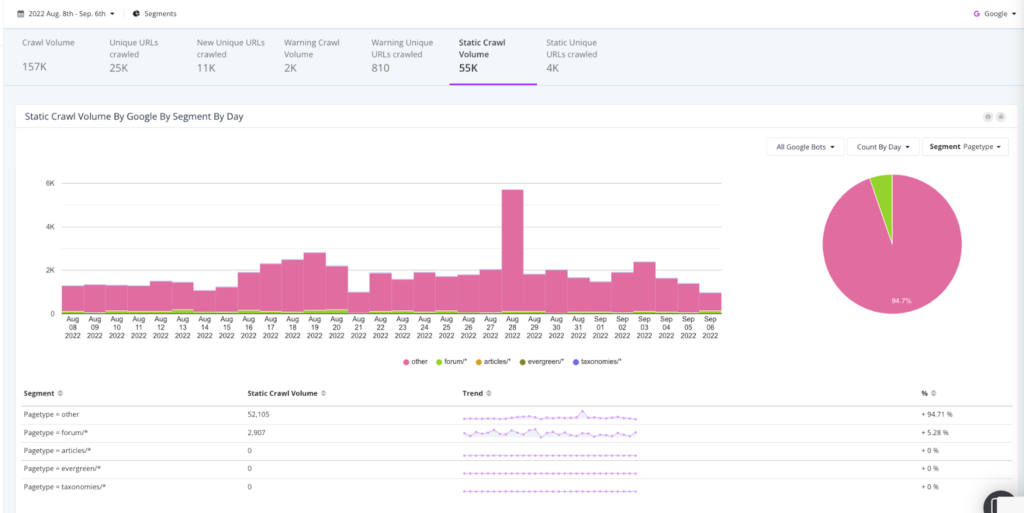
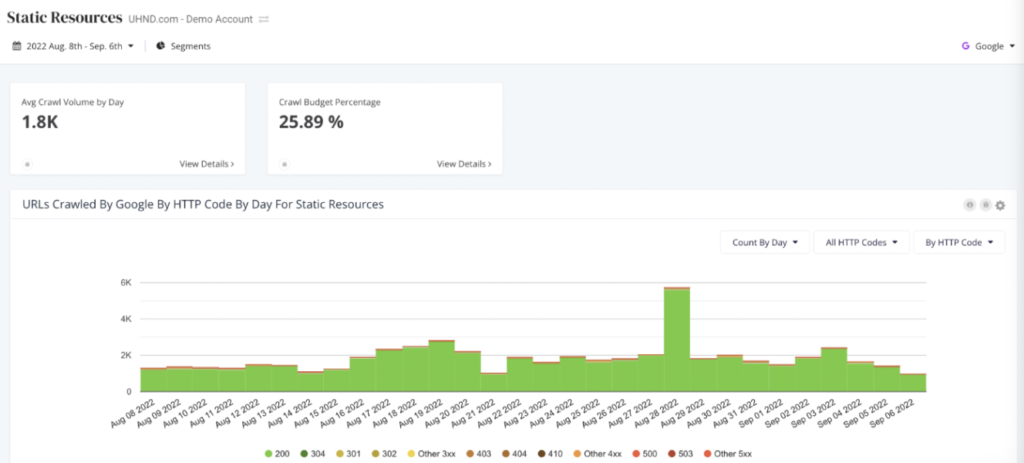
Log file analysis reports can uncover a wealth of information about the discoverability and performance of your website and should help guide your SEO priorities. And, with so many people changing various portions of the website, it’s an excellent diagnostic tool to pinpoint anomalies and mitigate disasters – one that should be utilized regularly.
But as you know, SEO professionals are often asked to do a lot with a little. Working with a trusted agency partner like iPullRank, who has the technical SEO acumen to utilize a sophisticated platform like Botify, the experience to run the breadth and depth of analyses necessary to keep up, and the expertise to help turn analysis into action, maximizes the value of your overall investment in organic search.
How to diagnose which pages are not being crawled by Google
Google might not be crawling your entire site. You need to discover which pages aren’t being crawled and why.
Every time Googlebot crawls your site, your team may have deployed something that prevents the spider from picking up on your content. You need recurring monitoring in place to alert you of those page drops every time they happen.
With Botify’s SiteCrawler, you can overlay log and crawl data and simplify the challenge of finding those gaps.
One of the most popular charts within the Botify platform, within the Search Engine section of SiteCrawler, is a simple Venn diagram comparing what was crawled by Botify only, crawled by both Botify and Google, and crawled by Google only. This gives an easy visual of what your website crawl coverage is, with the ability to drill down further and compare characteristics across URLs or sets of URLs, across crawls.
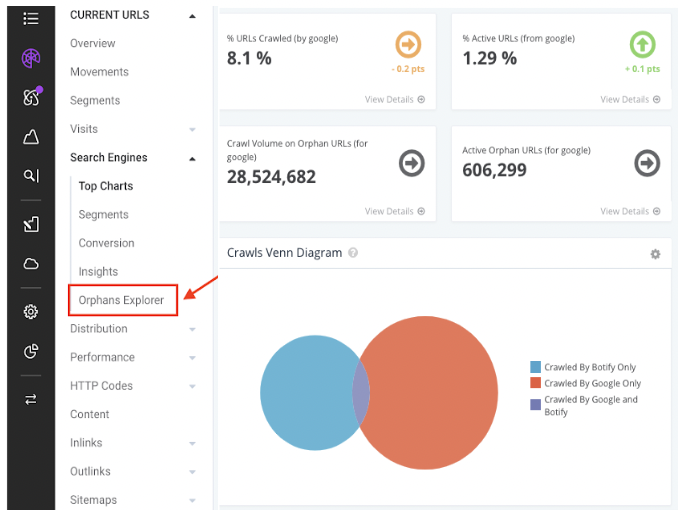
Within Site Crawler, you can also find additional insights surrounding:
Inlinks, redirects, and sitemap maintenance
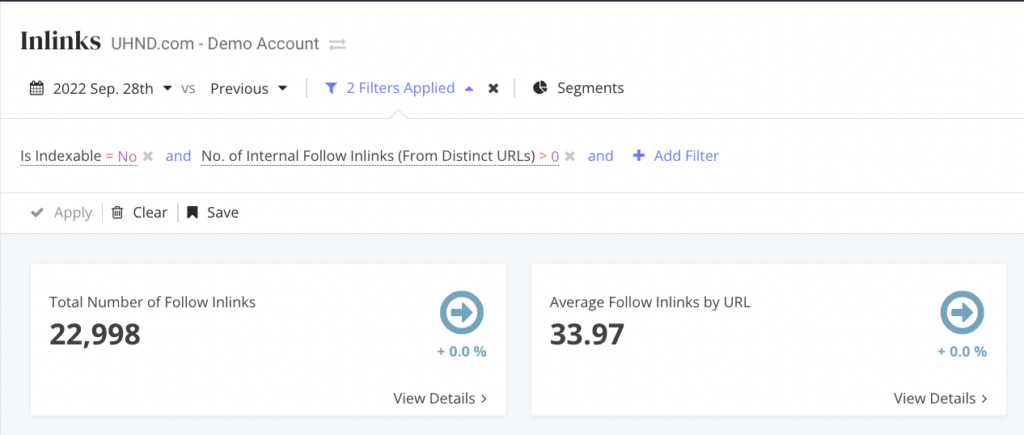
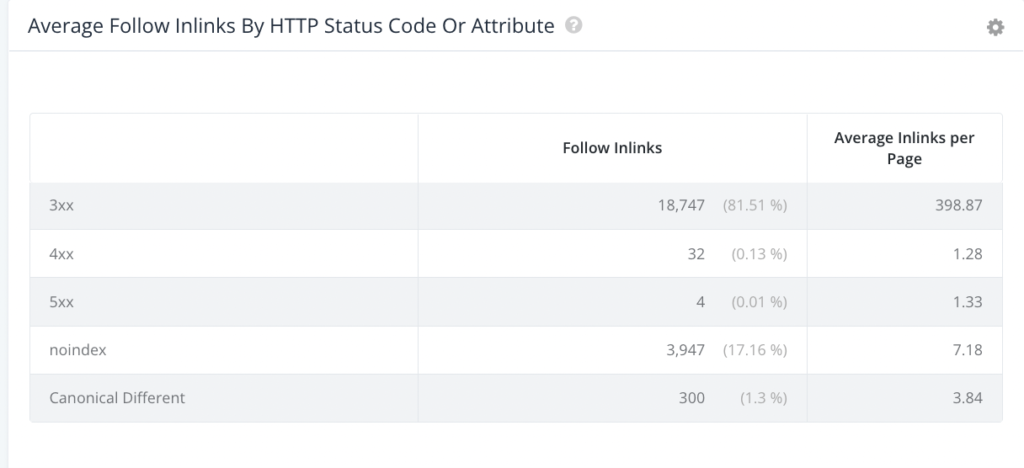
Problem: If you have inlinks to 4XX or 3XX pages, redirects to 4XX pages, or 3XX or 4XX in sitemaps, you can be wasting crawl budget, as well as creating a poor user experience for both search engines and users.
- Inlinks to 4XX or 3XX or Redirects to 4XX: Sending search engines to pages that don’t exist, or a page where they are then redirected once again, wastes crawl budget and disrupts the experience of finding relevant content on your site.
- Solution: Within the Inlinks subsection in SiteCrawler, set a filter to view your URLs by status code, quickly understand the volume of URLs impacted, drill into them specifically, and work with your team to remove or replace.
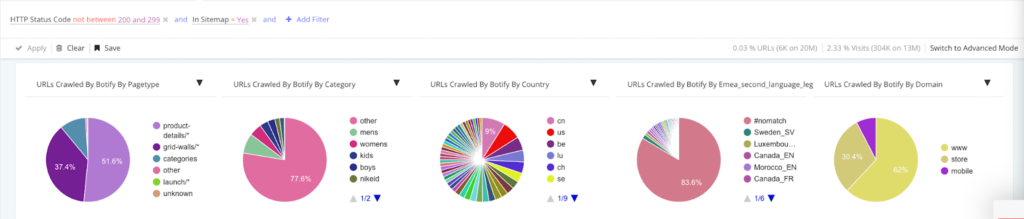
- 3XX or 4XX in sitemaps: sitemaps should only contain clean URLs, i.e. those with a 200 status code. If search engines see URLs with 3XX or 4XX, they will start to lose trust in your sitemaps and no longer reference it as a signal for indexing.
- Solution: Within SiteCrawler, visit the Sitemaps section and filter your URLs based on status code (or by showing all but 2XX status codes). You can see the breakdown based on your website’s page type, category, country, domain, and more, and see a list of each URL and the specific status code. From there, you can prioritize removing them, and for 3XX, replacing them with the destination URLs.
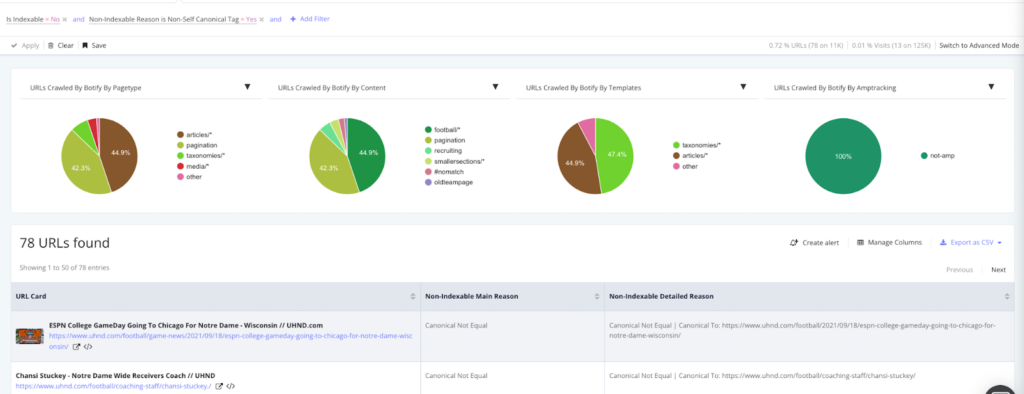
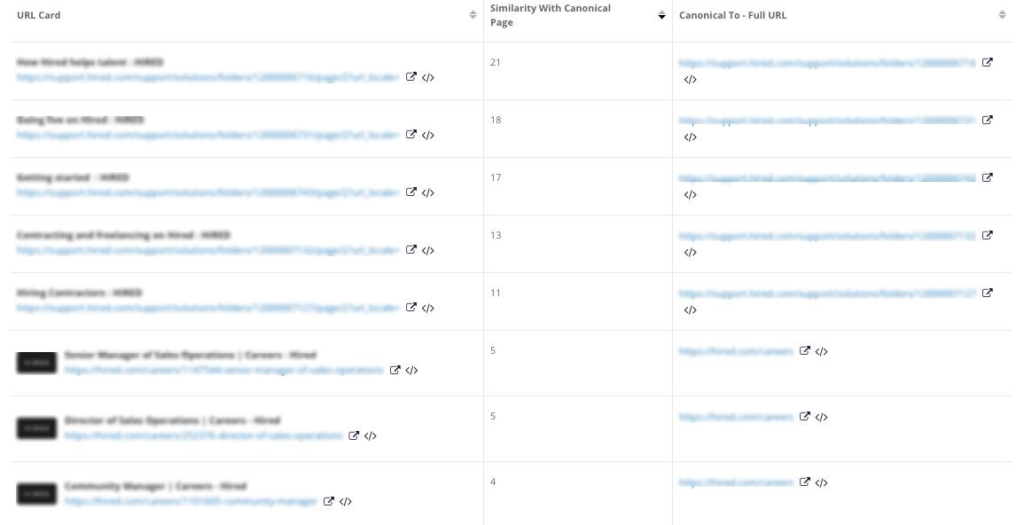
Non-self-referencing canonicals
Problem: URLs may get linked with parameters and UTM tags leading Google to pick up that URL as the canonical version and multiple versions of the same page getting indexed separately. So a self-referencing canonical lets you specify which URL you want to have recognized as the canonical URL.
Solution: Checking canonicals one by one is nearly impossible. Botify checks for common canonicalization mistakes and has reports that give you visibility into whether or not your canonical tags are following best practices. The platform shows you everything from content similarity between a page and its canonical to pages that canonical to a URL with errors.
Depth of content
Problem: If strategic pages are buried too deep within a website, search engines may not discover them, in turn not index them and eliminate the chance of traffic from organic search. Search engines may also not return and try to find them often enough, impacting crawl frequency.
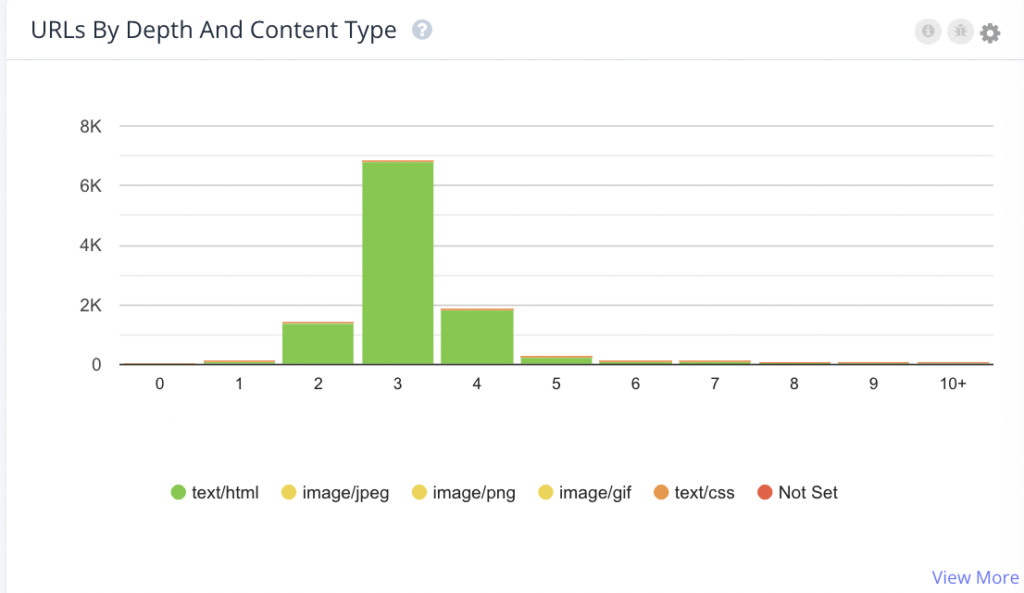
Solution: Look at how many pages search engines are finding in a given crawl, and how many have a page depth of three or more. Typically, if a page needs more than three clicks to be reached, it will perform poorly, and excessive page depth can be a threat to your SEO.
In order to mitigate page depth issues, consider your pagination, limit navigation filters, and move or remove tracking parameters.
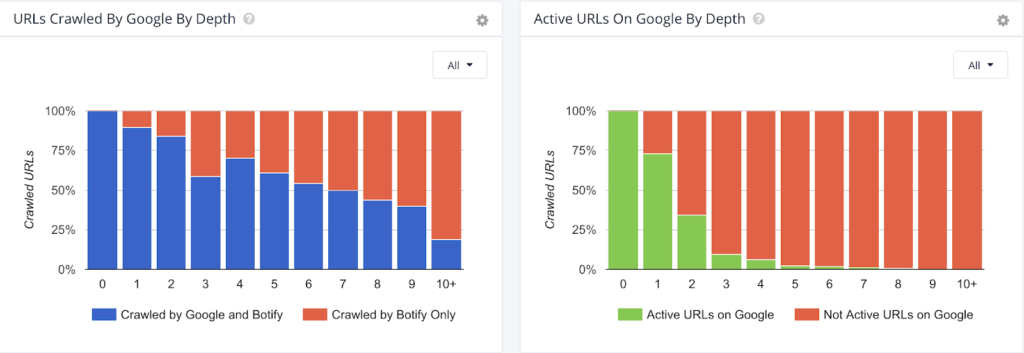
URL response time
Problem: If the response time of your URLs is too slow, typically over two seconds, there’s the possibility that Googlebot will not crawl them. If they’re not crawled, they won’t be indexed, eliminating their ability to drive traffic. A page that loads in 500ms or less is considered extremely fast in the eyes of Google.
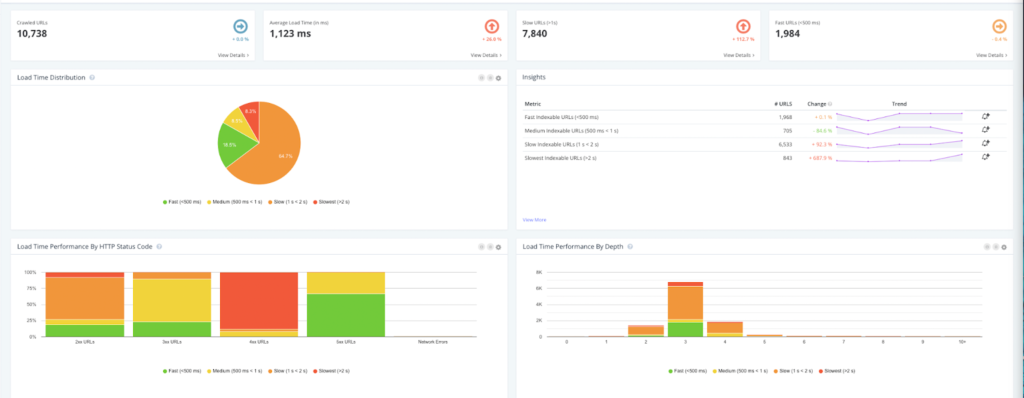
Solution: Use Botify’s SiteCrawler to find your URLs that are indexable, but are loading too slowly and compare it to what is actually being crawled, indexed, and rendered fully, as elements on the page might be the cause of the slow response time.
The ability to integrate crawl and log data in a single platform for easy comparison is also a key distinction between Botify and some of the other log file tools. Botify unifies this crawl and log data with keyword data and website analytics for the most comprehensive analysis of your website. Logflare or Screaming Frog’s Log Analyser, for example, are more manual, less automated, and not efficiently integrated with other data sets, posing risks for inaccuracy and missed opportunities. Furthermore, using machine-based storage instead of cloud-based storage makes it more difficult to share data and views with key stakeholders.
Finding the right partners
With lean teams, the constantly changing digital and SEO landscape, and heightened consumer expectations, brands need to minimize the busy work and develop an organic search strategy that combines the best of technology and expertise. iPullRank up levels the strategy of many enterprise brands utilizing Botify’s technology – and can do the same for you.
Learn more about Botify’s LogAnalyzer and for a complete log file audit, contact iPullRank.

- Log File Analysis: A Must-Have for SEO Pros - September 29, 2022





Leave a Comment