
Type the same question into Google’s AI Overview today and tomorrow, and you may not see the same citations. Run “best project management tools” through ChatGPT twice in the same week, and the sources it chooses could look completely unrelated.
I tried it myself. The same query was run twice (on different days) and the results came back distinct, exactly as you’d expect.

This kind of fluctuation reflects how modern AI search works, where systems don’t retrieve a single fixed list of results but generate answers by making a sequence of probabilistic choices, which means variability is built in from the start.
For most of search’s history, things felt much more predictable. You typed in a query and got a familiar list of blue links that hardly changed from one day to the next. Sure, an algorithm tweak or a new competitor might shuffle the order a bit, but the overall lineup stayed steady.
Local searches were an exception though, since Google has long personalised those for obvious geographic reasons, and there was some expansion through synonyms and related queries, though never to the extent we see today.
Even so, these adjustments were limited, which meant rankings remained stable enough that marketers could build whole playbooks on that consistency, focusing on how Google ranked pages and adjusting their content to match those signals.
But that foundation is now giving way. AI search systems introduce an architecture built on probability at every stage. They fan out queries into multiple variations, retrieve documents based on embeddings rather than simple keyword matches, and choose passages for citation according to statistical weighting. The outcome is a response that can look different each time, even when the prompt appears identical.
The scale of this disruption is already visible: Ahrefs studied 15,000 long-tail queries and found that only 12% of the links cited by ChatGPT, Gemini, and Copilot overlapped with Google’s top 10 results for the same prompts. 4 out of 5 citations pointed to pages that had no ranking presence at all for the target query.
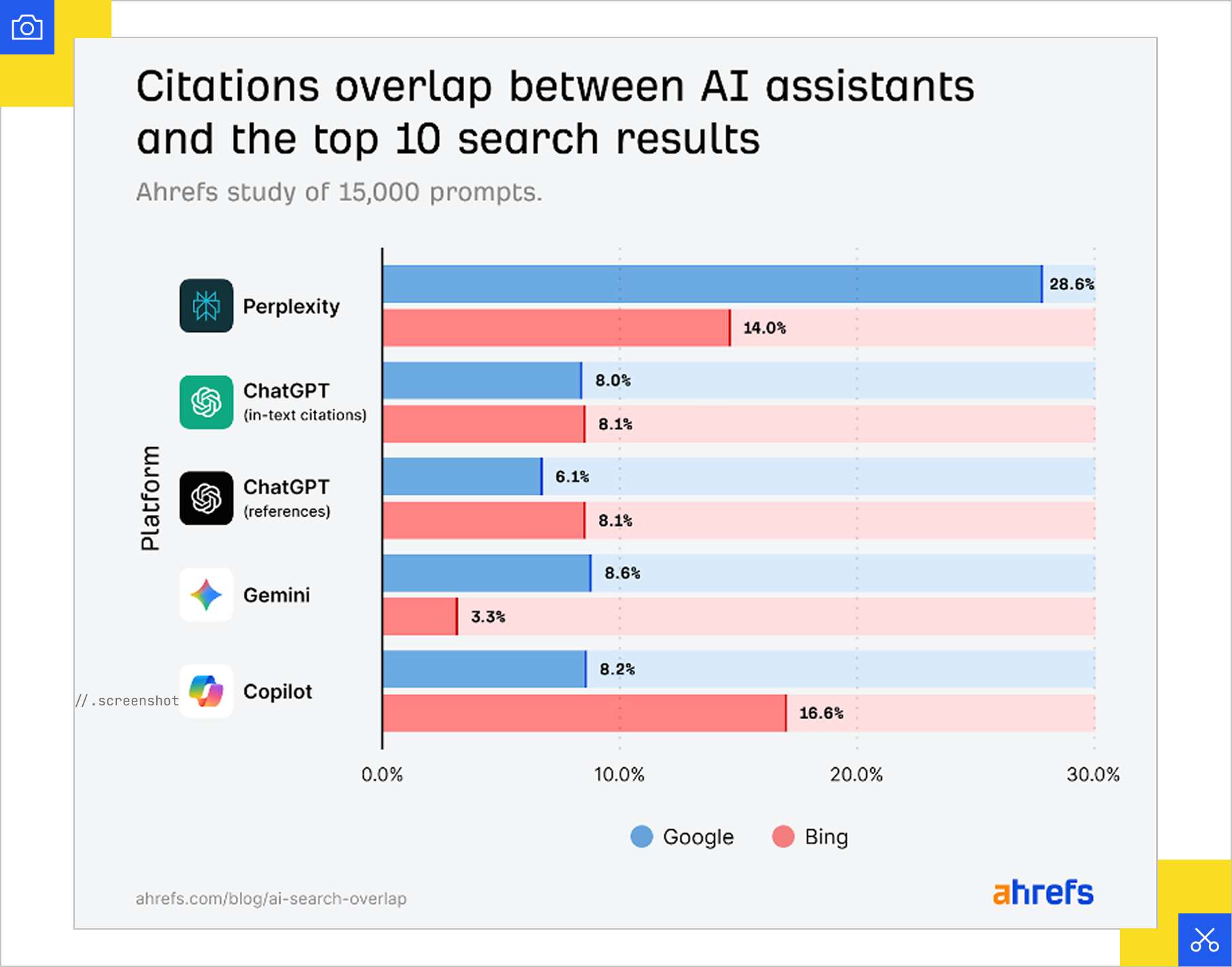
The implication of this is that visibility is no longer tied to a predictable position on a search results page. Being a top performer in organic search doesn’t necessarily translate to inclusion in LLM citations, rather what matters is increasing the probability of being chosen across a wide range of retrieval paths.
Optimizing in this environment requires thinking in terms of likelihoods rather than guarantees (essentially reframing the challenge as one of probability in SEO) and engineering relevance at the passage level rather than focusing solely on metrics like domain or page authority.
But alas, the challenge is compounded by the opacity of these systems. Traditional SEO offered a clear window into performance through rank tracking and SERP analysis. Practitioners could interpret how specific changes to content or links affected visibility. In machine learning, this is called interpretability, which is the ability to trace outcomes back to understandable factors. In contrast, AI search functions as a black box, where inclusion can flicker on and off with no obvious explanation.
To navigate it, marketers have to understand how probability governs retrieval and citation, and how to design content that performs reliably in systems built on this spoken-about variability.
From Deterministic to Probabilistic Search Systems
Search once operated in a way that felt almost mechanical. Search engines like Google functioned as elaborate filing systems, where typing a query triggered the algorithm to score pages against familiar criteria such as:
- Keyword relevance
- Link authority
- Engagement signals (click-through rates, dwell time)
- Content freshness
- Page speed and performance
- Site structure and crawlability
These metrics were analyzed before producing a ranked list. The same search from the same location would usually return the same results in the same order.
Out of that stability, an entire industry took shape. SEO professionals learned to audit websites, study ranking factors, and implement improvements that reliably influenced visibility. The rules were never published in full, but they were stable enough to observe, experiment with, and build playbooks around.
However, we now find ourselves in a time where AI search replaces these deterministic rules with layers of probability. Instead of asking which single page best matches a query, systems like Gemini or ChatGPT break the prompt into multiple synthetic variations (a process known as query fan-out, which we’ll return to later), retrieve documents through embeddings, and assemble an answer by selecting and weighting passages. Every stage introduces uncertainty, which means the outcome is never fixed.
AI Mode is a clear example of this. As Mike King noted in his widely read AI Mode piece,
“Google’s AI Mode incorporates reasoning, personal context, and later may incorporate aspects of DeepSearch. These are all mechanisms that we don’t and likely won’t have visibility into that make search probabilistic.”
Unlike earlier systems that ranked whole pages, AI search works at the passage level. Retrieved documents are broken down into smaller chunks, and the model decides which fragments to stitch together into a response.
This shift from page-level ranking to passage-level synthesis produces volatility by design. Where older systems offered a consistent lineup of blue links, generative search builds fluid responses that may draw on different passages and sources with every run.
Context adds even more variation. In the past, personalization was limited, often little more than a nudge based on location or search history. Today, AI systems consider a far richer set of signals; think user embeddings, inferred intent, device context, etc. Two people typing the same question may see different answers and different citations, not as an error, but as the product of a system designed to adapt outputs to context in real time.
Google's Gemini and Query Fan-Out
One of the clearest windows into how Google’s AI search works comes from the concept of Query Fan-Out. What does that mean? Instead of treating a single user question as the only query to answer, the system explodes it into a network of related searches that get processed at the same time.
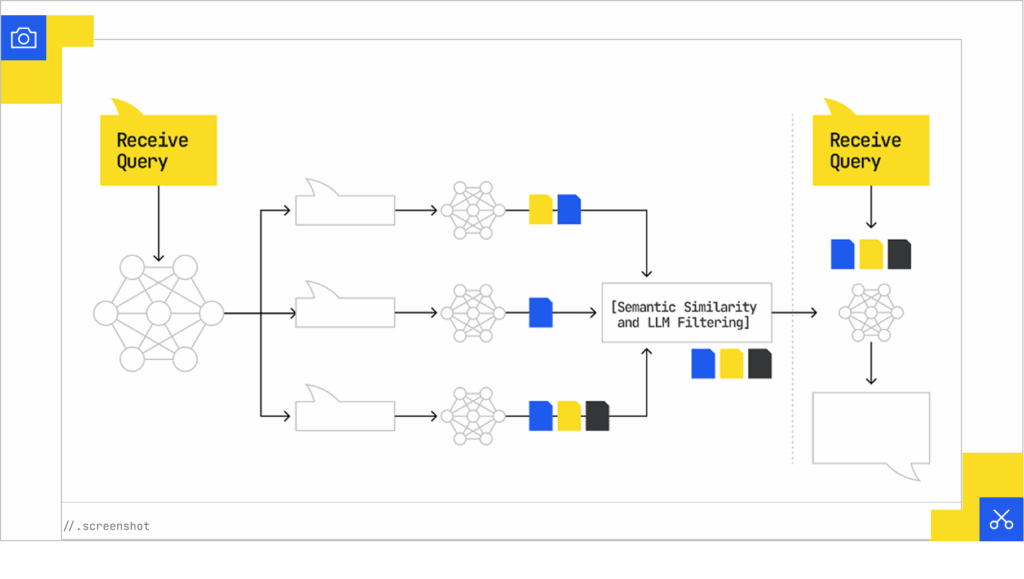
Patent documents reveal how this happens. In Search with Stateful Chat, Google describes how the system generates synthetic queries based on conversational context and user state, creating additional search variations that run alongside the original query. Another patent, Systems and Methods For Prompt-Based Query Generation for Diverse Retrieval, shows how Large Language Models (LLMs) can generate diverse query variations, providing the technical foundation for creating multiple search interpretations.
We’ll explore these patents and related work in more detail below, but the key point here is that query fan-out makes search results inherently variable from the very start.
In an interview with Search Engine Land, Mike King puts it like this:
“They have this idea that they call query fan-out where effectively they’re doing query expansion based on what the user put in and they’re doing it in a way where they’re just handing it, the query off to Gemini 2.5 Pro…and it’s then returning a bunch of queries and also different data points from the Knowledge Graph…and then it’s performing all these searches in the background and then it’s pulling chunks from those pages and then feeding to Gemini to then generate what the response is going to be in AI Mode”
In practice, this means a single query triggers a whole network of related searches running in parallel, each pulling back passages that may feed into the final response.
Take the example of a search for “sustainable packaging solutions for e-commerce.” Gemini might generate queries such as:
- Biodegradable shipping materials
- Carbon-neutral packaging suppliers
- Cost comparison of eco-friendly options
- Consumer preferences for sustainable packaging
- Regulatory requirements for packaging waste
- Case studies of sustainable packaging adoption
Each of those synthetic queries launches its own retrieval process. Instead of simple keyword matching, Gemini uses dense retrieval based on embeddings to surface documents that align semantically with the intent of each subquery. From there, passages are scored and ranked, with probabilistic methods determining which ones feed into the final answer.
Google itself has confirmed this architecture. At Google I/O 2025, Google’s VP and Head of Search, Elizabeth Reid explained that AI Mode “uses our query fan-out technique, breaking down your question into subtopics and issuing a multitude of queries simultaneously on your behalf.”
This explains why ranking highly for a single head term no longer guarantees visibility. A page that ranks first for “sustainable packaging solutions” might not appear for any of the synthetic queries the system actually uses. Meanwhile, a page ranking lower for the main term but performing well across multiple sub-queries has many more opportunities to be selected for the final response.
In effect, query fan-out builds on the process of latent intent projection, mapping a query into related meanings and expanding it into neighboring concepts. The retrieved passages from those expansions form a temporary custom corpus, and because every selection is probabilistic, the retrieval paths remain non-deterministic.
As a result, the competition is no longer just for “the ranking,” but for being part of the constellation of content the system may draw from when it breaks a user’s question in many possible ways
How Large Language Models Generate Answers Probabilistically
Once the fan-out and retrieval steps are complete, another layer of uncertainty takes over. The system has gathered passages from across the web, but it still has to weave them into a coherent response. Unlike traditional search, which simply displayed ranked results, AI search composes new text in real time.
The method is called autoregressive generation. At each step, the model predicts the next word in the sequence by scoring every option in its vocabulary. The top candidates form a pool, and one is selected to continue the sentence. That choice then shapes the next round of predictions, and the cycle repeats until the answer is complete.
The outcome is shaped by sampling strategies that deliberately inject variation:
- Greedy search: Greedy search is the simplest decoding method. The model always selects the single most probable next word. It’s fast and predictable, but it tends to generate bland or repetitive text because it never explores alternatives.
- Beam search: Beam search keeps track of several of the most likely sequences at once. At each step, it explores multiple candidate continuations and picks the sequence with the highest overall score.
- Top-k sampling: The model narrows the field to the k most probable words and randomly selects from within that set, weighted by probability. Even a word with strong odds can be skipped if the random draw favors another candidate.
- Nucleus sampling (top-p): Nucleus sampling takes a different approach. Instead of fixing k, it gathers tokens until their combined probability passes a threshold p. The pool can be small when the model is confident, or larger when it’s uncertain.
- Temperature control: A tuning parameter that adjusts how adventurous the model is. Higher temperatures increase diversity in word choice, while lower temperatures favor safe, predictable continuations.
These mechanisms explain why identical queries can yield different answers, even when the system retrieves the same supporting material. The decoding step itself introduces variation in emphasis, phrasing, and sometimes even which sources get cited.
Retrieval-Augmented Generation (RAG) and Passage Selection
At the heart of generative search is Retrieval-Augmented Generation, often shortened to RAG. It works in two steps: first, the system retrieves potentially relevant material, and then it generates a response from that material. This pipeline explains much of the volatility users now see in AI search.
That process unfolds in several stages:
Dense retrieval surfaces unexpected sources
Instead of scanning entire pages, RAG breaks content into smaller passages and converts them into vector embeddings. Queries are mapped into the same space, and the system retrieves passages that are semantically close, even if they share no words with the original query. This is why AI Overviews can cite pages that do not rank for the keyword at all (See Ahrefs study on this).
Reranking makes answers unstable
Once candidate passages are retrieved, the model does not use all of them. It might pull in 20 to 50 snippets and then apply probabilistic reranking. Similarity scores, authority signals, and freshness affect the outcome, but the final set is chosen statistically rather than through fixed scoring rules. Two equally strong passages may compete, and which one makes it into the final synthesis can vary from run to run.
Citations create attribution errors
This reranking process also explains why citations often feel inconsistent. The model might paraphrase a passage from one site but credit another that says roughly the same thing.
Sometimes it leans on syndicated copies rather than the original.
Case in point: A study by Tow Center for Digital Journalism found that AI search engines frequently misattribute or misrepresent citations, with over 60% of test cases containing errors. In some instances, systems pointed to syndicated versions of articles instead of the original publisher, or cited links that did not clearly contain the quoted material.
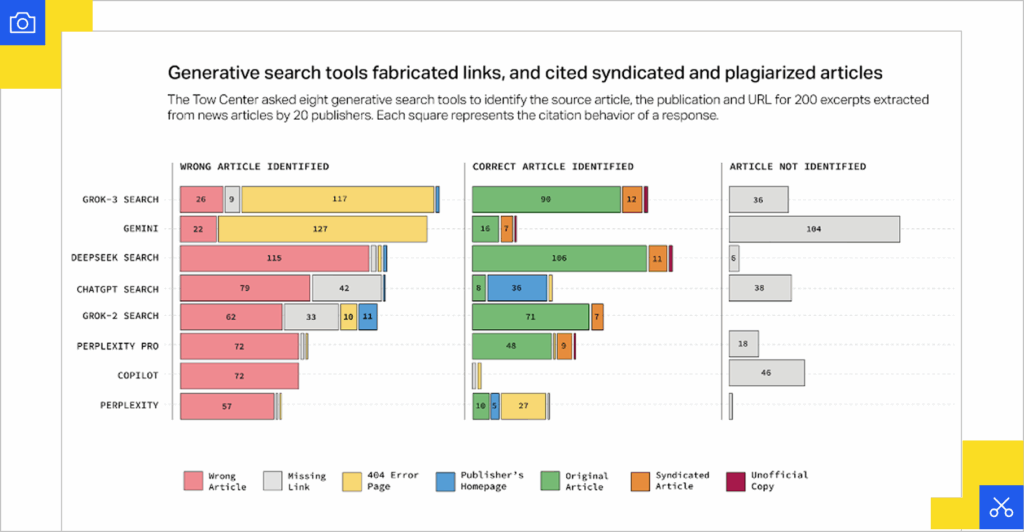
These flaws make clear that what rises to the surface in AI search is not a stable reflection of ranking, but the shifting output of a probabilistic pipeline.
For practitioners, that means getting indexed is no longer enough. Content must be written and structured so that individual passages are semantically retrievable, strong enough to win during reranking, and clear enough to be cited consistently across multiple runs of the same query.
Patents That Reveal the Probabilistic Engine
Public filings give the clearest look at how Google can expand a query, classify it, compare passages, and decide what to cite. Read together, they show a search pipeline driven by statistical choices rather than fixed rules.
Search with Stateful Chat (US20240289407A1)
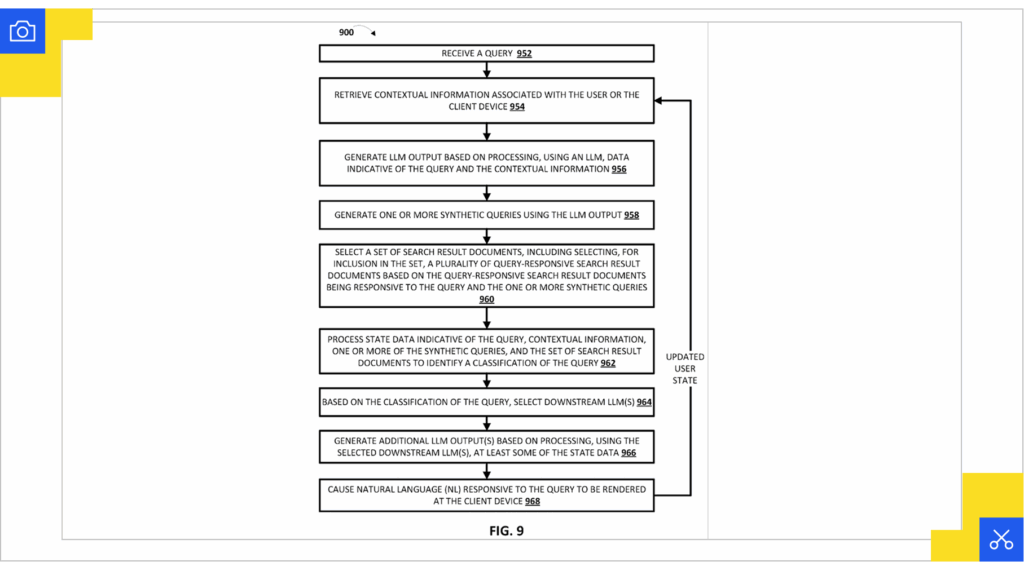
This application describes a natural language response system that maintains user state across search sessions, including prior queries, search result documents, user engagement data, and contextual information. When processing a query, the system generates one or more synthetic queries using LLM output to expand beyond the original user input, then selects search result documents based on both the original and synthetic queries to create what the patent calls query-responsive search result documents.
The system processes state data to identify a classification of the query, which determines which downstream LLMs handle response generation (essentially routing different query types to specialized models). This creates a stateful chat experience where the same query can produce different synthetic expansions and document selections based on accumulated user context. The entire pipeline runs on learned models making decisions at each step, creating what the patent calls a generative companion that adapts responses dynamically.
Systems and Methods for Prompt-based Query Generation for Diverse Retrieval (WO2024064249A1)
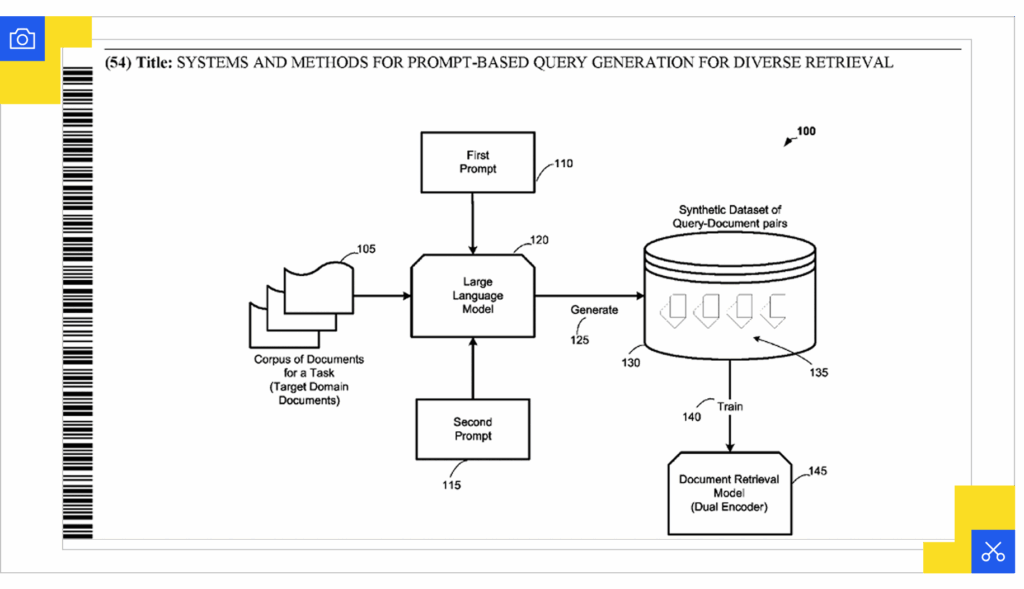
Here the focus is on creating training data through synthetic queries. A large language model is prompted with documents from a corpus and asked to generate multiple phrasings that a user might type to find that content. The system uses just 2-8 example query-document pairs as prompts, then generates up to 8 synthetic queries per document using sampling with a temperature parameter of 0.7.
These synthetic query-document pairs undergo round-trip filtering, where generated queries must successfully retrieve their source documents, to remove low-quality examples. The filtered pairs are then used to train dual encoder retrieval systems so they can recognize relevance even when user queries look very different from the source text.
The patent highlights how this method, called PROMPTAGATOR, expands semantic coverage without the need for extensive human-labeled datasets. The system outperforms retrieval models trained on hundreds of thousands of human annotations by leveraging the diverse synthetic training data that results from the probabilistic LLM generation process.
Dynamic selection from among multiple candidate generative models with differing computational efficiencies (US20240311405A1)
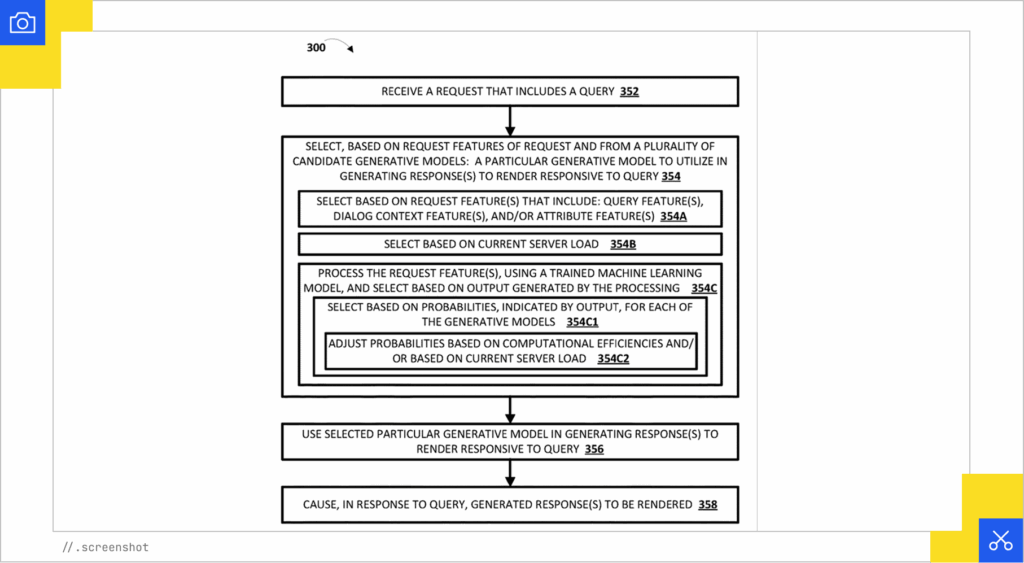
Rather than always relying on a single model, this system chooses among multiple generative models at inference time. The routing decision depends on features such as the text and embeddings of the query, the ongoing conversation state, user or device attributes, and even real-time server load.
A learned classifier weighs these factors to decide which model will generate the answer. That means the same query might be handled by a larger, more capable model in one context and a smaller, faster model in another. Because the choice itself is probabilistic, outcomes can differ across sessions, with variation not only in retrieval and citation but in the generator producing the response.
Generative Summaries for Search Results (US11769017B1)
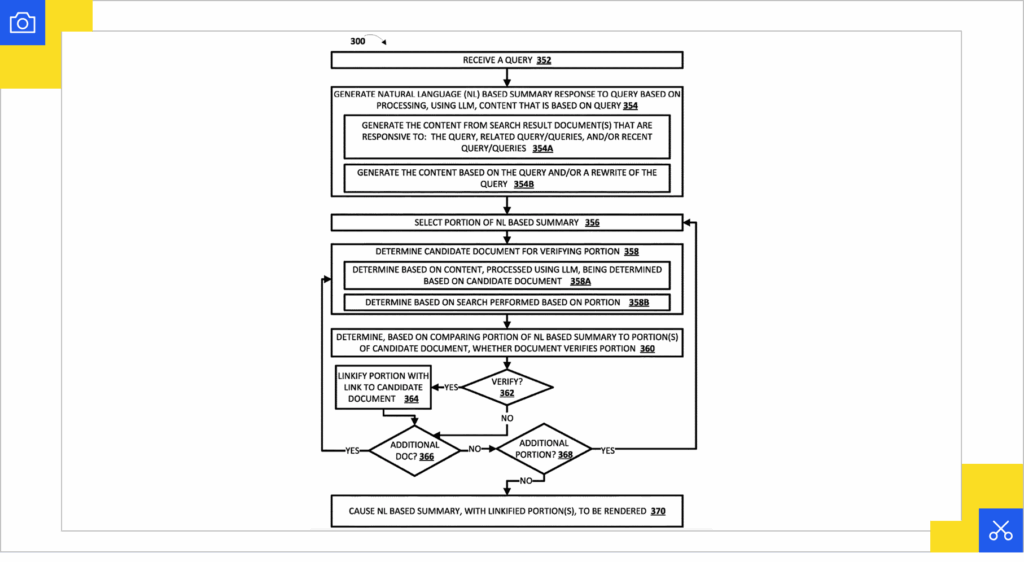
The filing explains how search responses can be enriched with large language model–generated summaries. Instead of only listing links, the system composes a natural-language overview that integrates supporting documents, attaches citations, and may include annotations such as confidence levels.
Importantly, these summaries are not fixed. They adapt dynamically based on additional context beyond the original query. This includes content from related queries, recent user searches, and implied queries generated from profile data. When users interact with results by clicking links, the system generates revised summaries using updated prompts that reflect familiarity with the accessed content.
A verification step compares segments of the generated summary against candidate documents to determine which sources best support each claim. The same factual content might be attributed to different supporting links depending on how the verification algorithms weight the evidence across generation runs.
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
The final step in the pipeline (ranking) also shifts into probabilistic territory. Traditional ranking depended on fixed scoring functions, but PRP reframes it as a series of relative comparisons. Given a query and two candidate passages, the model is asked which one is more relevant.
These pairwise judgments are aggregated through methods like all-pairs comparison, sorting, or sliding-window approaches to produce a full ranking. Results demonstrate that smaller open-source models using this approach can compete with much larger commercial systems. Since each comparison involves probabilistic outputs, the same documents may rank differently across runs, but the pairwise method proves more robust than approaches requiring complete list generation or calibrated scoring.
What do these patents tell us?
Viewed together, these patents sketch out a search system that behaves more like a decision network than a static index. A single query can branch into many reformulations, each pulling in its own set of materials. Different models may be tapped depending on context, and the system can rewrite its own responses as new cues arrive.
The outcome is never locked in place: the information shown to a user is the product of layered choices, each influenced by prior activity, system conditions, and statistical weighting. For marketers and SEO professionals, the key point is that influence now comes from increasing the odds of being included in those branching pathways rather than holding a stable slot on a results page.
Probability-Driven Selection: Impact on Citations and Visibility
In the classic SEO model, ranking implied visibility: if a page was in the top spot, it was seen, and if it was seen, it had a chance to drive traffic.
Patents such as the ones described above show that these steps are now split into separate, probability-driven processes. A page may be retrieved, its passages may shape the generated text, yet another source may end up being cited in the final output.
Retrieval is uncertain because systems expand queries into synthetic variations, score passages in vector space, and rerank them with outcomes that can change from run to run.
Traditional rank tracking cannot capture this dynamic. Counting positions assumes stability, but in probabilistic search the real measure of visibility is frequency and persistence.
As Duane Forrester explained in his piece “12 new KPIs for the generative AI search era”, practitioners will need to track metrics such as:
- Attribution rate in AI outputs: how often your brand or site is named as a source in generated answers.
- AI citation count: the number of times your content is referenced across AI outputs.
- Retrieval confidence score: the likelihood that your chunk is selected in the model’s retrieval step.
- LLM answer coverage: how many distinct prompts or questions your content helps answer.
- Zero-click surface presence: how often your content appears in AI summaries or interfaces without a click.
Practical SEO Strategies for a Probabilistic, Generative Search Era
If everything in the pipeline is uncertain, from how queries expand to which passages get cited, then optimization is about stacking the odds in your favor.
The question is not “how do I rank once and stay there,” but “how do I make my content retrievable, competitive, and credible across dozens of shifting retrieval paths?”
Optimize for semantic coverage
Search systems expand queries into synthetic variations, each probing a different angle. To intersect with them, content has to stretch beyond one phrasing. Covering terminology, entities, synonyms, and related contexts raises the chance of alignment. This is also where latent intent comes in: the questions behind the query that are never stated outright. Anticipating those hidden angles ensures your content shows up even when the system rephrases the ask in unexpected ways.
Structure for passage-level retrieval
Dense retrievers look at fragments, not whole pages. Strong passages present a claim, evidence, and context in a way that stands alone. That structure not only improves retrievability, it also supports the reasoning steps a model has to take as it assembles an answer. A passage that clearly fits into one of those steps is more likely to be chosen and cited.
Anticipate multiple intents and modalities
Query expansion rarely stops at one interpretation. Some variations probe definitions, others costs, comparisons, or examples. Covering these adjacent angles increases your odds of connecting with at least one. But intent is not only textual. AI systems now pull from images and video as well. Adding multimodal content broadens your coverage, giving the system more hooks to include your material in different answer formats.
Signal authority and track outcomes
Generative systems judge credibility by what they can verify directly. Authorship, citations, and supporting data should be explicit and machine-readable. But authority signals alone are not enough. Practitioners also need to build new GEO tracking and experimentation into their workflows, since rank tracking no longer captures visibility in this environment.
Bring stakeholders into the shift
As much as optimizing for probabilistic systems is a tactical change, it’s also an organizational one. Stakeholders must recognize that volatility is a feature, not a flaw, and that success depends on adopting new KPIs while rethinking how teams are structured. GEO cannot be bolted onto yesterday’s SEO model; it requires rethinking roles, skills, and responsibilities.
The Future of Search in a Probabilistic World
The instability of AI search also creates openings. Pages that never ranked in Google’s top ten can suddenly surface in generative answers, while long-standing rankings may not carry the same weight. In this environment, visibility becomes a matter of probability, not position.
For those who adapt, the upside is enormous. Content built for retrieval, comparison, and citation can win attention far beyond what static rankings allowed. GEO gives marketers the tools to turn volatility into competitive advantage.







