
Want a different perspective? These links open AI Search platforms with a prompt to explore this topic, how it works in AI Search, and how iPullRank approaches it.
*These buttons will open a third-party AI Search platform and submit a pre-written prompt. Results are generated by the platform and may vary.
Generative AI search systems are not monolithic. While they share common architectural elements — embedding-based retrieval, reranking layers, and LLM synthesis — each platform implements them differently, with varying trade-offs in speed, transparency, and result quality. For GEO practitioners, understanding these architectural distinctions is critical: Specific optimization levers that move the needle in Google AI Mode might be irrelevant in Perplexity AI, for instance, and vice versa.
This chapter unpacks the inner workings of leading AI Search systems. We’ll look at their retrieval pipelines, indexing strategies, synthesis layers, and interface choices, and then draw out what each means for optimizing your content’s visibility and inclusion.
At the heart of most AI search platforms is retrieval-augmented generation. RAG addresses the fundamental weaknesses of LLMs: hallucinations and knowledge cutoffs. By grounding generation in fresh, externally retrieved data, these systems can deliver answers that are both fluent and factual.
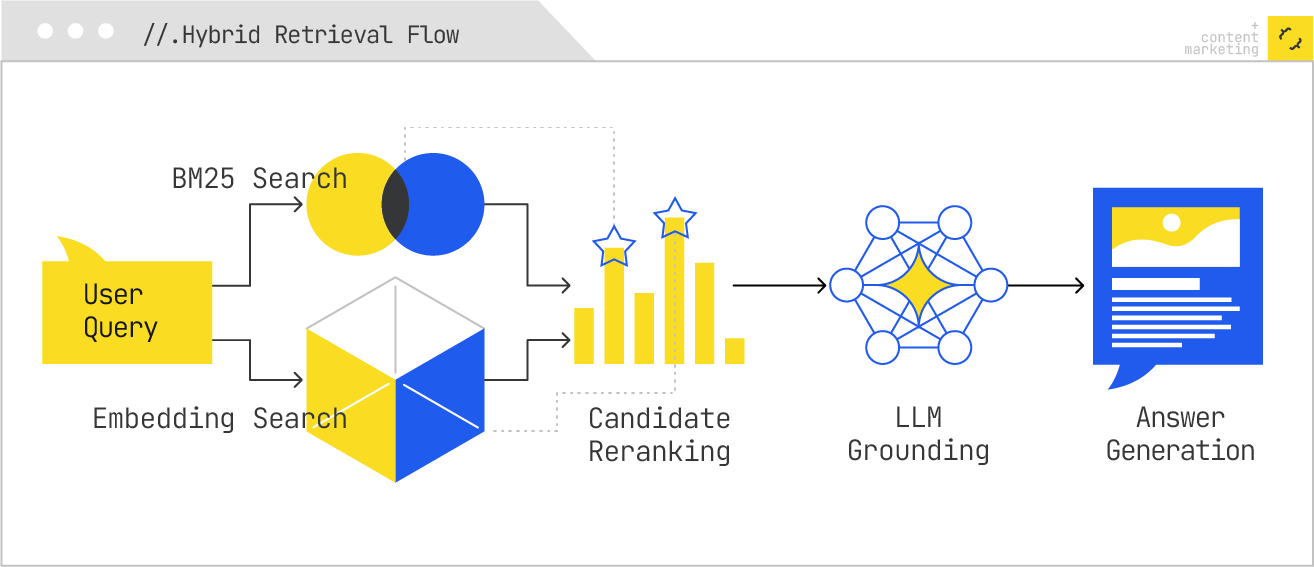
In a RAG pipeline, the user’s query is first encoded into an embedding vector (or vectors, if the system uses a multivector model). The system then searches an index of precomputed content embeddings — which may represent web pages, videos, documents, or multimodal data — to retrieve the most relevant candidates. These candidates are then often reranked using a more computationally expensive cross-encoder, which jointly processes the query and candidate to produce a refined relevance score. Finally, the top-ranked results are fed into an LLM as grounding context for answer synthesis.
What makes RAG powerful is that it turns the LLM into a “just-in-time” reasoner, operating on information retrieved seconds ago, rather than months or years ago when the model was last trained. This has massive implications for GEO: If your content is not both retrievable (through strong embeddings and metadata) and easily digestible by the LLM (through clear structure and extractable facts), you’ll be invisible in the synthesis stage.
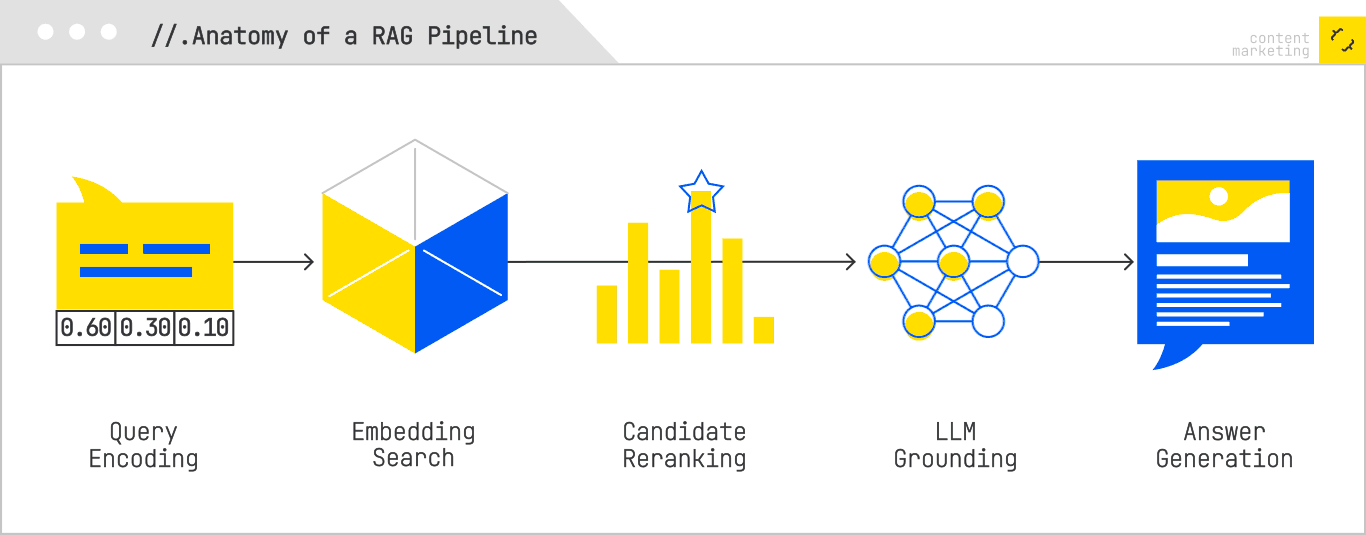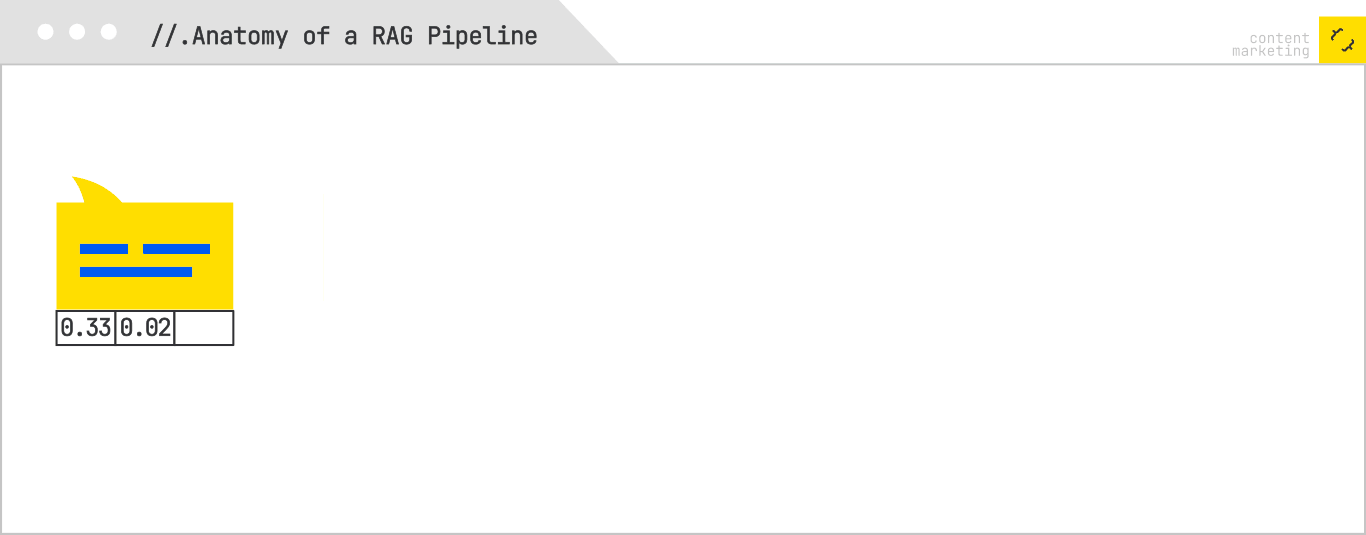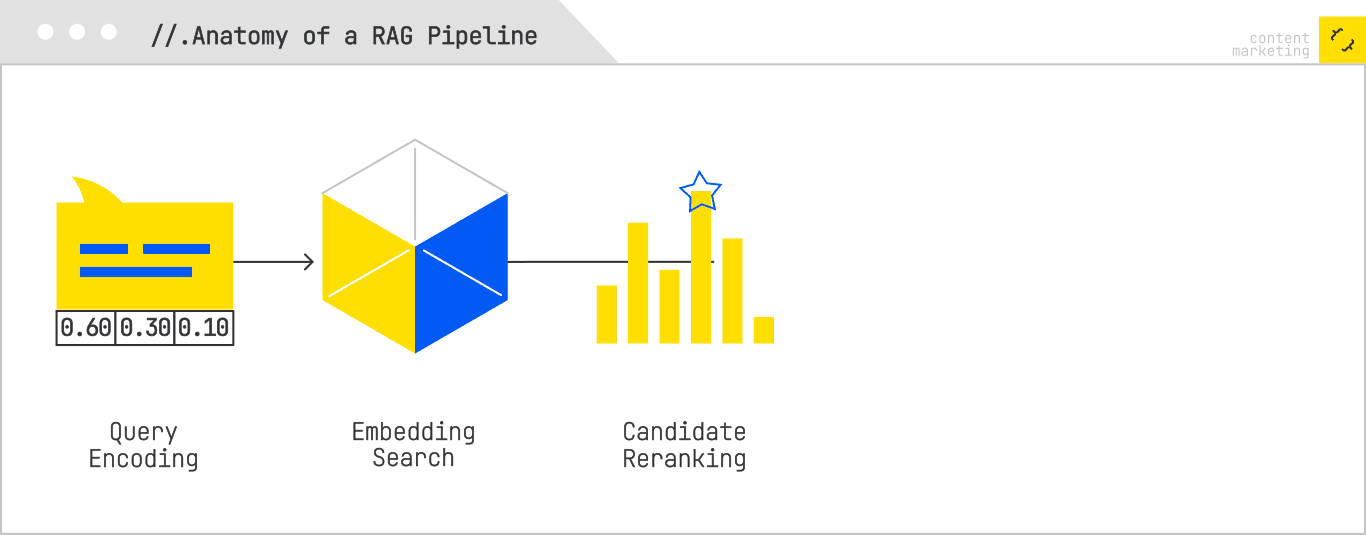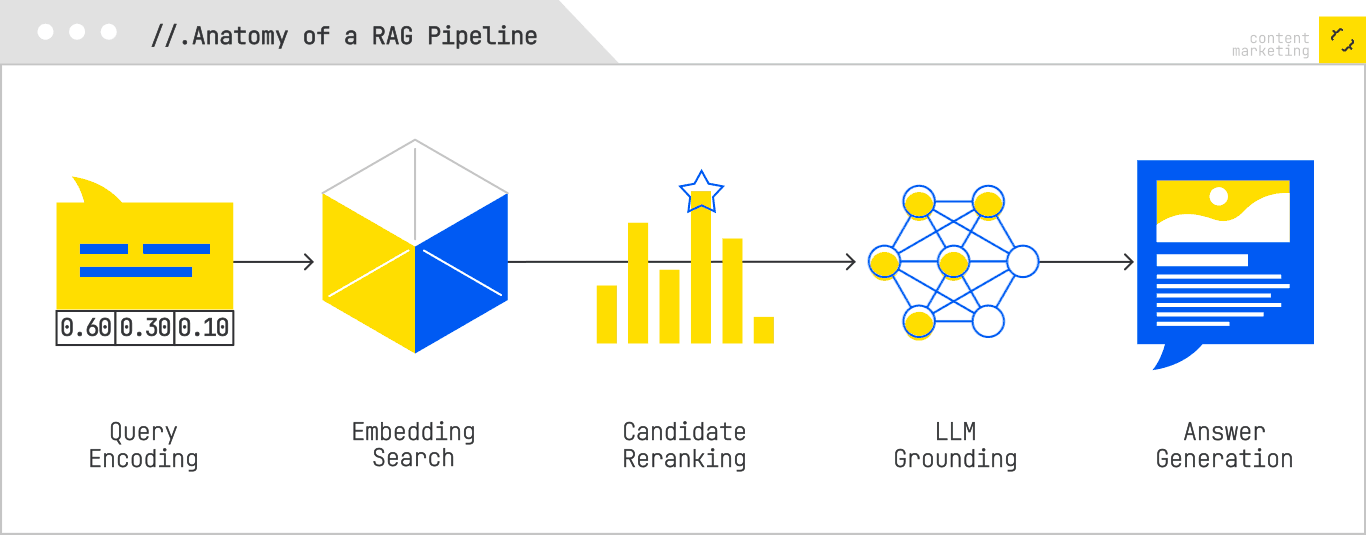
Embedding-based indexing replaces the inverted index of classical search with a vector database. Every document is represented by one or more dense vectors that capture its meaning in a high-dimensional space. This allows the system to retrieve semantically related content even when there is zero keyword overlap with the query.
Indexing for AI Search is often multimodal. Text passages, images, audio clips, and even tables may be embedded separately, then linked under a shared document ID. An image from your site could be retrieved directly as evidence for a generative answer, even if the text on the page is less competitive.
For GEO, embedding-based indexing demands that content be optimized for semantic coverage. That means using natural language that clearly expresses the concepts you want to be retrieved for, adding descriptive alt text and captions to images, and ensuring transcriptions and metadata for non-text content are rich and accurate.

Despite the power of embeddings, most AI search platforms use hybrid retrieval pipelines. Lexical search still excels at precision for exact matches, especially for rare terms, product codes, and names. Semantic retrieval excels at recall for conceptually related content. Combining the two — and then reranking with a contextual model — delivers the best of both worlds.
Such a hybrid system might first run a BM25 (lexical) search over the inverted index and a nearest-neighbor (semantic) search over the embedding index. It would then merge the result sets, normalize the scores, and pass the combined pool through a reranker. In practice, this increases the odds that both exact-match and semantically related content are considered for synthesis.
From a GEO perspective, hybrid retrieval means you can’t abandon classic SEO practices. Keyword optimization still matters for lexical recall, while semantic optimization determines whether you’re present in the embedding index.
Google’s AI Search surfaces are built on a tight integration between its LLM stack (customized Gemini models) and its mature search infrastructure that has been refined over two decades.
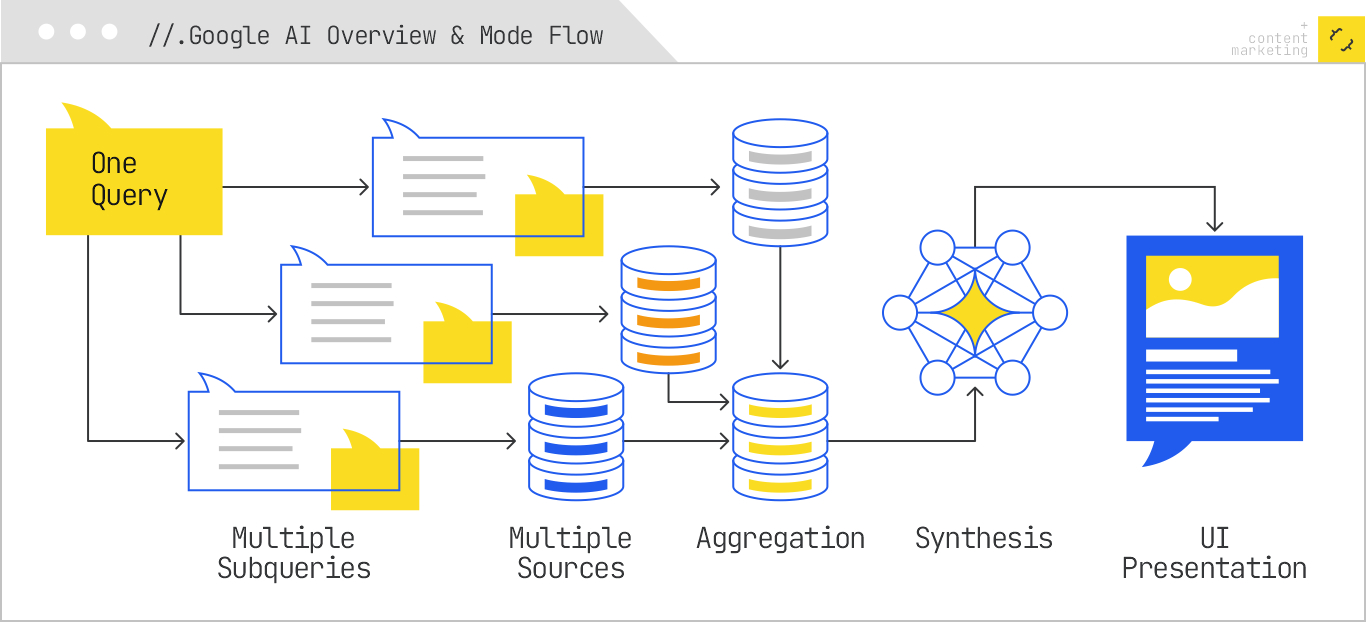
When you issue a query, the system performs a query fan-out, exploding your input into multiple subqueries targeting different intent dimensions. These subqueries run in parallel against various data sources — the web index, Knowledge Graph, YouTube transcripts, Google Shopping feeds, and more.
Results from these subqueries are aggregated, deduplicated, and ranked. The top candidates are then fed into a Gemini-based LLM, which synthesizes a concise overview. AI Overviews display this at the top of a traditional SERP with inline citations.
AI Mode, by contrast, is a fully conversational environment, designed for multi-turn reasoning and exploratory queries. It can persist context across turns and dynamically fetch more evidence mid-conversation.
The GEO implication is clear: Content needs to be optimized not just for standard web ranking but for multi-intent retrieval. The more dimensions of a query your content can satisfy, the more likely it will be included in synthesis.
Google’s AI Overviews and AI Mode are not separate products bolted onto search. They are tightly integrated, retrieval-augmented layers built directly into Google’s search stack. While the surface UX is new, the underlying components reuse, and in some cases extend, the same infrastructure Google has been refining since the earliest days of universal search.
Based on observed behavior, patents, and Google’s own disclosures, we can model the process in five major stages: query understanding, query fan-out, retrieval from multiple data sources, aggregation and filtering, and LLM synthesis.
When a user submits a query in AI Mode or triggers an Overview, the first step is semantic parsing. This likely involves both classic tokenization and modern Transformer-based embeddings to produce multiple representations of the query:
This phase also detects language, applies spell correction, and identifies whether the query warrants an AI Overview. Google has admitted that not all queries are eligible. High-stakes (often referred to as Your Money or Your Life, or YMYL) queries and queries with sparse authoritative coverage may be excluded or handled more conservatively.
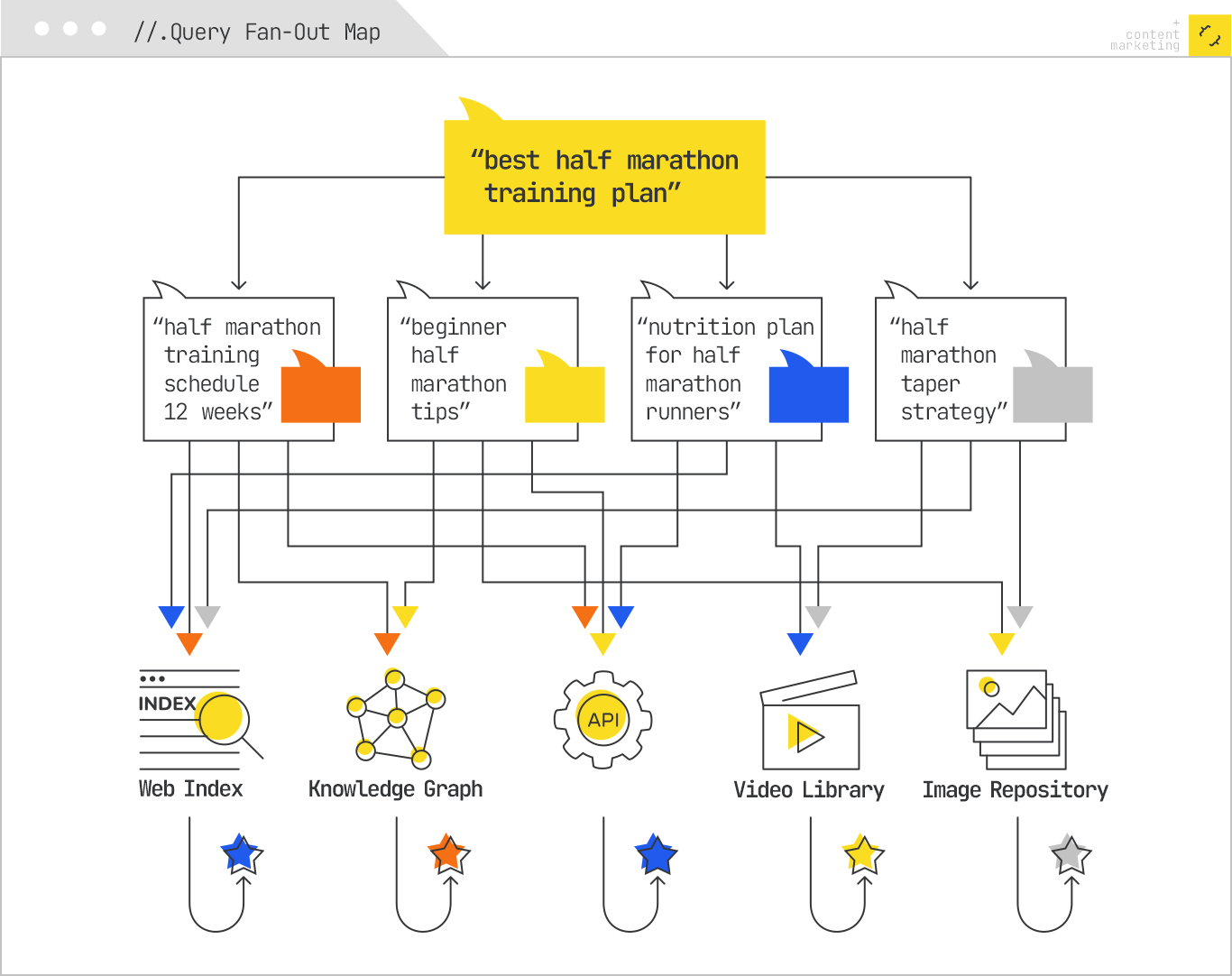
If the query qualifies, Google generates multiple subqueries to cover latent intents and fill information gaps.
For example, the query “best half-marathon training plan” might fan out into:
These subqueries run in parallel across different source systems:
The fan-out ensures broader recall than a single query could achieve.
Each subquery is routed to the appropriate retrieval stack. For the web index, this may mean running BM25 against the inverted index in parallel with approximate nearest neighbor (ANN) search over Google’s internal embedding space. In vector search, Google likely uses multivector document representations, meaning each document is split into multiple semantic segments, each with its own embedding, for higher retrieval accuracy.
For non-web sources, retrieval methods vary. The Knowledge Graph is a structured database of entity nodes and edges; retrieval here is graph traversal rather than vector search. YouTube transcripts and images are stored in their own multimodal embedding spaces, often linked to Knowledge Graph entities for cross-modal recall.
Once each subquery returns its results, Google merges them into a single candidate pool. Deduplication removes near-identical passages or URLs.
Filtering then applies both quality and safety constraints:
Snippet selection is heavily influenced by extractability and clarity. If the system can’t pull a self-contained, high-quality passage, the page is less likely to be cited.
The final candidate set — often dozens of passages from multiple sources — is passed into a Gemini-based LLM as grounding context. The LLM then synthesizes a cohesive answer, deciding where to insert citations. Citations can appear inline, in sidebars, or as “more sources” links, depending on the UI surface.
AI Overviews aim for brevity and clarity, so synthesis is constrained. Think of them as a single-shot generation pass with a fixed token budget. AI Mode, by contrast, is conversational and persistent. It can run additional retrieval cycles mid-session, incorporate follow-up questions, and adjust the synthesis style on the fly.
From a GEO standpoint, the path to inclusion is:

Base ChatGPT models do not maintain their own web index. They are trained on a massive static corpus, but pull URLs from indices and request them in real time. ChatGPT generates search queries, sending them to Bing’s API, and retrieves a short list of URLs. It then fetches the full content of selected URLs at runtime and processes them directly for synthesis.
This architecture means that inclusion depends entirely on real-time retrievability. If your site is blocked by robots.txt, slow to load, hidden behind client-side rendering, or semantically opaque, it will not be used in a synthesis pipeline.
Classic SEO dominates here; the strategy is ensuring accessibility and clarity: Make pages technically crawlable, lightweight, and semantically transparent so that on-the-fly fetches yield clean, parseable text.

Bing’s Copilot is the closest thing to a classical search engine wearing a generative suit. Unlike Perplexity’s API-first, on-demand approach or Google’s highly fused Gemini + Search stack, Copilot inherits Microsoft’s full-fledged Bing ranking infrastructure and then layers GPT-class synthesis on top. The consequence is a pipeline where traditional SEO signals still matter a lot, because they determine which candidates ever make it to the grounding set, while extractability and clarity determine whether those candidates become citations in the final conversational response.
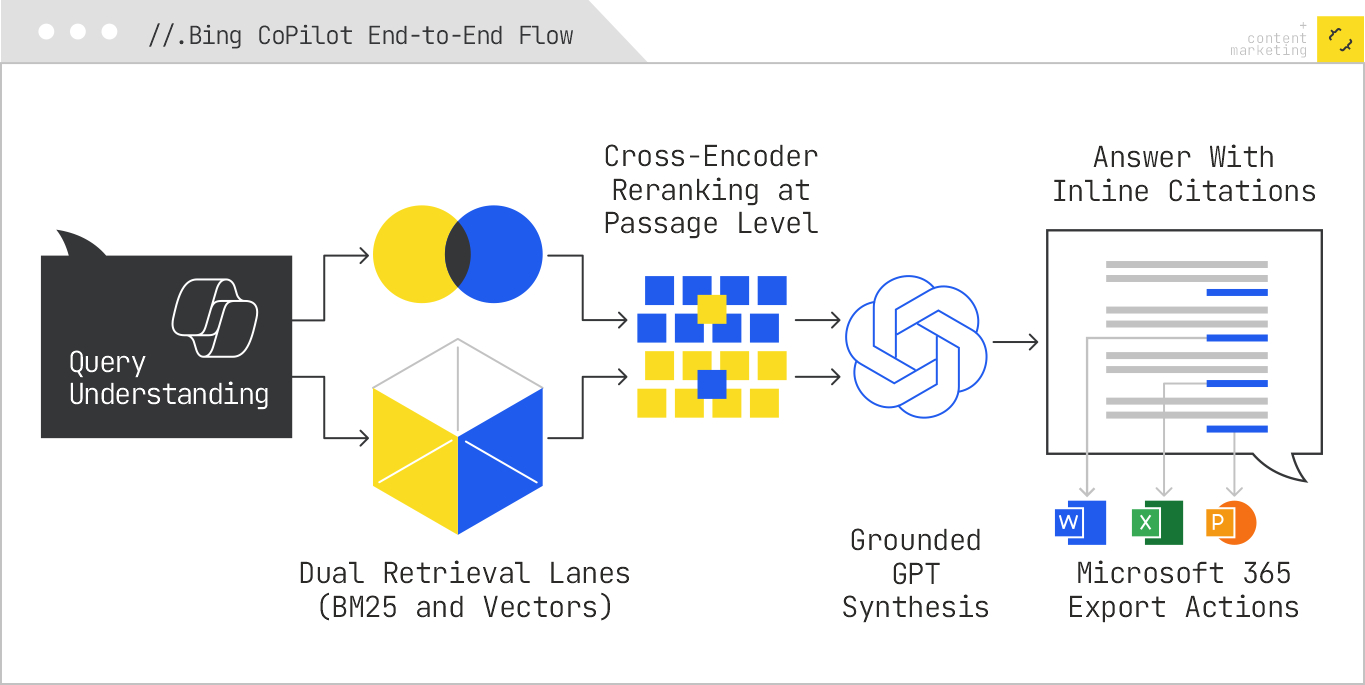
Copilot’s flow can be modeled in five stages: query understanding, hybrid retrieval, contextual reranking, LLM grounding and synthesis, and presentation with citations and actions. Around that core loop sits a Microsoft 365 integration surface that lets answers spill directly into productivity contexts like Word, Excel, and Teams.
When a user prompts Copilot, the system performs parallel interpretations of the input. A lexical representation is created for classic retrieval, a dense embedding representation is produced for semantic search, and entity linking identifies its knowledge-graph nodes for disambiguation. Copilot also assigns a task profile to the query: Is the user asking for a factual summary, a how-to, a comparison, a recommendation, or a calculation? That task classification influences which verticals or specialized services Bing hits next. For example, commerce queries may trigger stronger weight on Shopping feeds, while local intent pushes more signal to Places and Maps entities. This first step looks conservative compared with Google’s expansive fan-out, but it is opinionated: Bing leans on the maturity of its ranker to prune early rather than explode the space.
Bing’s retrieval is a true hybrid. A BM25-style run over the inverted index returns high-precision, exact-match candidates — especially valuable for rare strings, product SKUs, and named entities. In parallel, a nearest-neighbor search over Bing’s dense vector indexes retrieves semantically related passages that may not share surface terms with the query. The system merges these pools, normalizes their scores, and enforces freshness and site-quality constraints. Critically, Bing’s web index is deep and already quality-filtered, so what reaches the pool tends to be stable, crawlable, and canonicalized. That’s why classic SEO hygiene — crawlability, canonical signals, clean HTML, speed — still pays off disproportionately with Copilot compared with API-only engines.
From a GEO perspective, this is where you earn your first ticket. If you aren’t competitive on either lexical or semantic retrieval, you don’t make the cut. Pages that marry keyword clarity with strong topical embeddings have the best odds of landing in the candidate set across many query phrasings.
The merged pool then passes to a cross-encoder reranker that’s been tuned for passage-level relevance. Instead of scoring whole pages, Bing increasingly focuses on passages that can answer a discrete facet of the query. The reranker jointly encodes the query and each passage to assign a context-aware score, which captures nuance that simple vector similarity misses. At this stage, Bing also performs deduplication and diversity control, so that near-identical passages from mirror sites or syndication partners don’t crowd out unique sources.
Two quiet but decisive filters apply here. First, extractability: Passages with clear scope, lists, tables, and definition-style phrasing are easier to ground in synthesis, so they survive. Second, authority: Site-level and entity-level trust signals influence tiebreaks. If two passages say the same thing, the one from the more reputable domain or author typically wins. This is why E-E-A-T–style signals, while not exposed as a single metric, still shape which sources Copilot shows.
The top passages are bundled as grounding context for a GPT-class model. Copilot’s prompts instruct the model to synthesize concisely, attribute claims, and avoid speculation beyond the provided evidence. Unlike a free-form chat model, Copilot’s generator is tightly coupled to what was retrieved; its job is to compose rather than to invent. If the answer requires breadth, the system can issue incremental retrieval mid-generation to pull missing facets, though in practice you see this most during multi-turn conversations where follow-ups expand scope.
Grounding strategy matters for GEO. If your passage is scoped, contains the claim in crisp language, and references dates, versions, or conditions, it is easier to quote or paraphrase safely. If the model needs three passages to triangulate what your one chunk could have stated plainly, you’re at a disadvantage.
Copilot’s UI presents the synthesized response with prominent citations — usually inline superscripts linked to source cards or listed below the answer. Because the pipeline privileges passage-level grounding, citations tend to be tight: a handful of sources, rather than a sprawling bibliography. On follow-up turns, sources can change as the conversation pivots and new retrieval runs fire.
What distinguishes Copilot is the action layer across Microsoft 365. A travel recommendation can be exported to a Word doc template, a list can be turned into an Excel table, or a summary can be shared in Teams with the citations intact.
For GEO, this means content that is easily repurposed — tables, checklists, CSV-friendly structures — has leverage beyond the initial answer, because it flows into downstream user tasks where citations are visible and sticky.
If you rank in blue links but fail to show as a Copilot citation, the usual culprits are structural, not topical. Client-side rendering that delays core content, heavy interstitials that confuse extraction, ambiguous scope with no conditions or dates, or long narratives that bury the lead all reduce passage quality. Thin author pages and weak entity markup can also hurt in close calls versus equally relevant passages from sites with cleaner E-E-A-T signals.
Remember the sequence:
You need to survive all four.
Think classic SEO plus chunk engineering.
Also, optimize for post-answer utility. Provide downloadable tables, CSVs, and copy-ready modules that map naturally to Word/Excel. This increases the odds that users will click your citation to get the reusable artifact.
Perplexity AI operates with an intentional clarity that sets it apart from other generative search platforms. Unlike AI Overviews and Copilot, which interleave synthesis and source attribution in ways that can obscure the retrieval process, Perplexity foregrounds its citations. Sources are displayed prominently, often before the generated answer itself, allowing observers to see precisely what pages informed its synthesis. This transparency makes it not only a powerful answer engine for users, but also an unusually open laboratory for GEO practitioners seeking to understand what content earns visibility.
In fact, the term “generative engine optimization” comes from a paper for which researchers used Perplexity to run experiments on what influences responses from conversational AI platforms.
At a functional level, Perplexity conducts real-time searches when a query is issued, often pulling from both Google and Bing indexes. From there, it evaluates candidates against a blend of lexical and semantic relevance, topical authority, and answer extractability. A recent analysis of 59 distinct factors influencing Perplexity’s ranking behavior reveals a retrieval system that rewards more than just relevance; it rewards clarity, contextual alignment, and machine readability.
One clear pattern is the prioritization of direct-answer formatting. Pages that explicitly restate the query, often in a subheading or opening sentence, and then follow it with a concise, high-information-density answer are disproportionately represented in citation sets. For example, a question like “What is the difference between GPT-4 and GPT-5?” is more likely to pull from a page that contains that exact phrase as a heading, followed immediately by a short paragraph that defines the distinction without extraneous detail. This mirrors snippet optimization in traditional SEO — but the stakes are higher here, because Perplexity’s output integrates those passages directly into generated text.
The factor research also indicates that entity prominence and linking play an outsize role. Perplexity seems to favor passages where key entities (people, companies, products, places) are both clearly named and contextually linked to other relevant concepts. This could be through structured data (schema.org markup), explicit parenthetical explanations, or appositive phrases. For GEO, this suggests that entity linking is not just a knowledge-graph play—it’s a retrieval play in generative AI search.
Authority remains important, but the analysis suggests that Perplexity’s interpretation of authority is multidimensional. Beyond domain-level backlink metrics, the system appears sensitive to perceived expertise signals. Author bylines, credentials, and detailed “About” or author-bio sections contribute to this, as does alignment with reputable sources in the same citation set. When Perplexity synthesizes an answer, it often draws from multiple domains; inclusion alongside high-credibility peers elevates the perceived trustworthiness of your brand.
Another intriguing finding is that visual content, particularly inline images that illustrate the answer, can correlate with higher citation rates. This may not be due to a direct image-relevance algorithm, but rather because well-structured content that includes explanatory visuals tends to align with other citation-worthy attributes, such as formatting clarity and comprehensive coverage. In practice, an article explaining a technical concept with a labeled diagram is more likely to be cited than a text-only equivalent, even if the textual explanation is equally strong.
The platform also seems to reward semantic breadth without dilution. Pages that naturally incorporate related terms and concepts covering multiple facets of a query without drifting off-topic are more likely to surface. This speaks to the importance of comprehensive topical coverage within a single page, as opposed to spreading information thinly across multiple URLs.
For GEO practitioners, the transparency of Perplexity’s citation process is an opportunity to close the feedback loop in near-real time. If your content is not cited, you can observe what pages were, identify their structural and semantic advantages, and adjust accordingly. Conversely, when you are cited, you can dissect which factors you satisfied — whether it was precise query alignment, rich entity linking, authoritative context, or visual support — and replicate those patterns across other target queries.
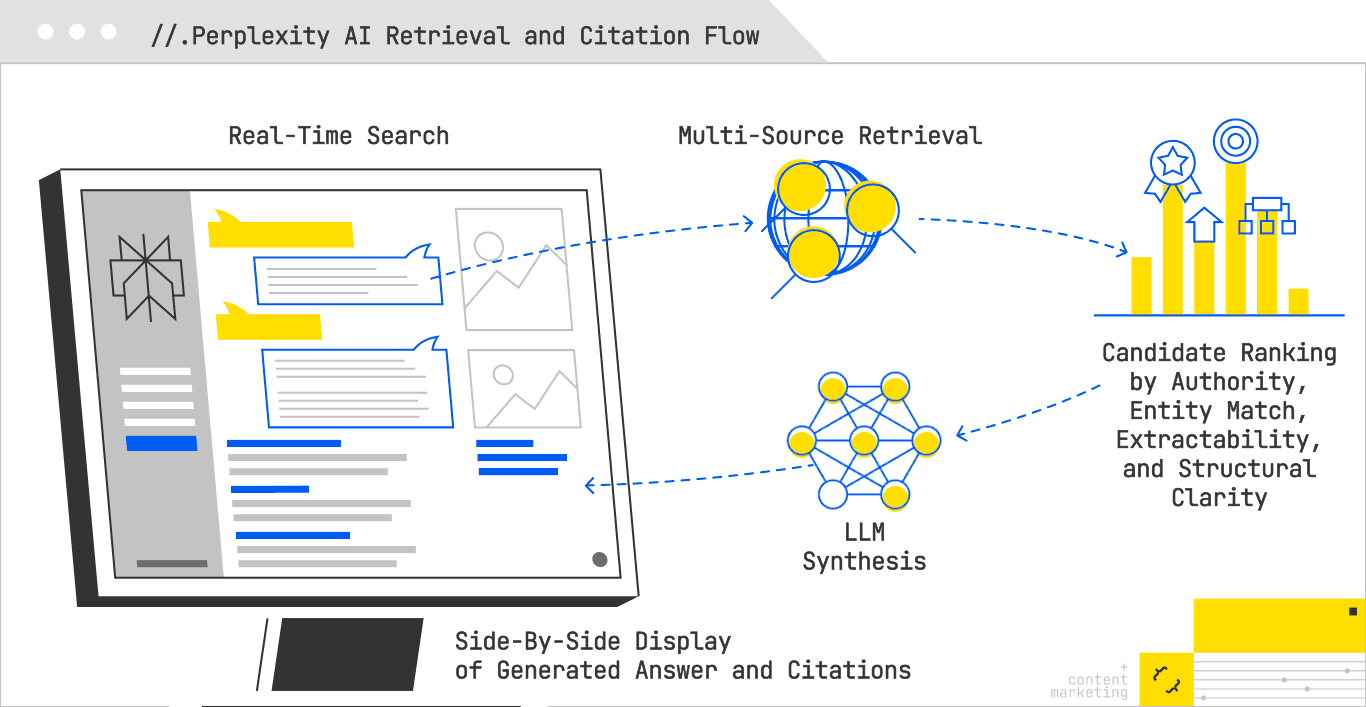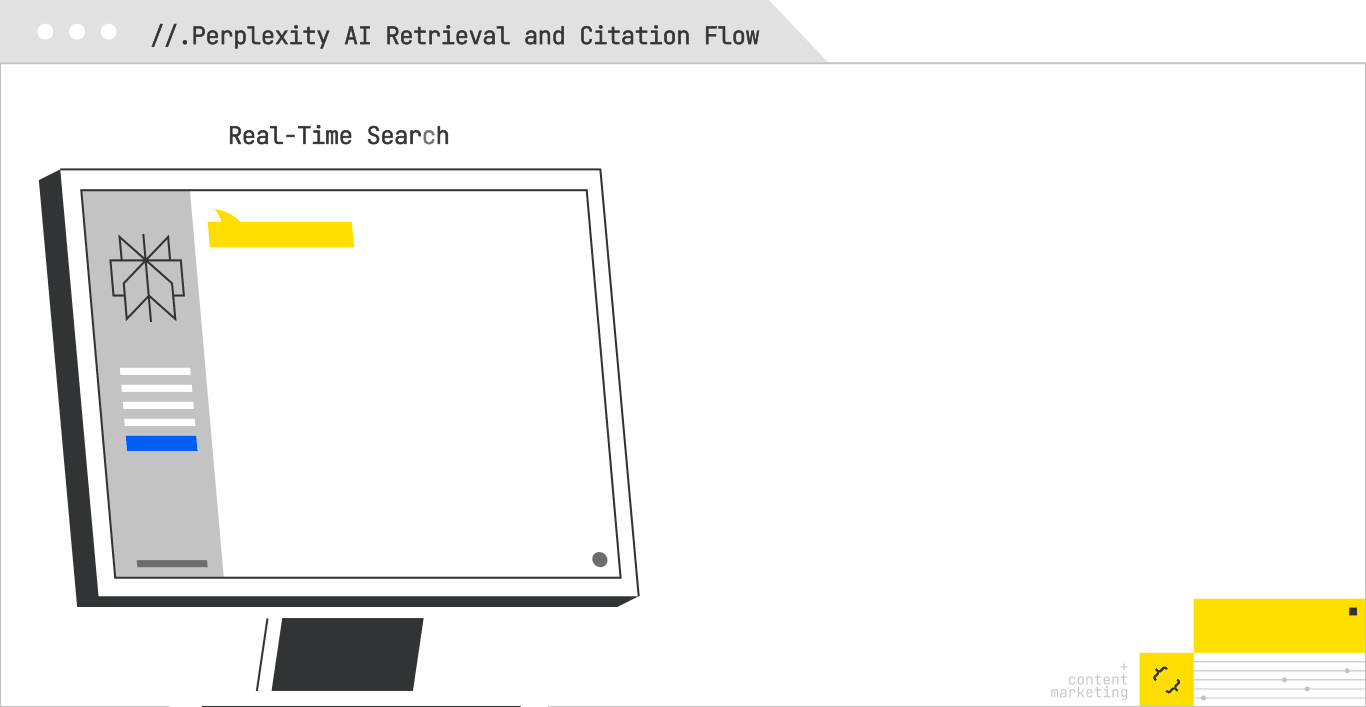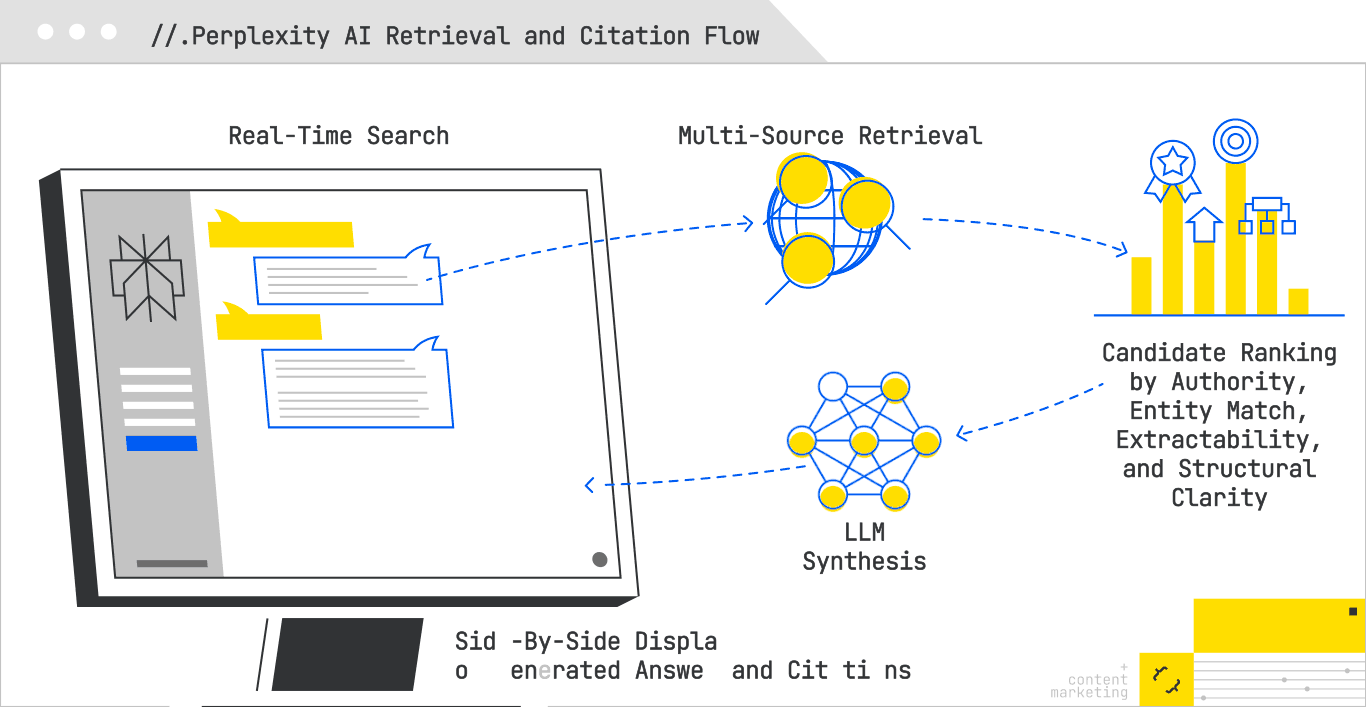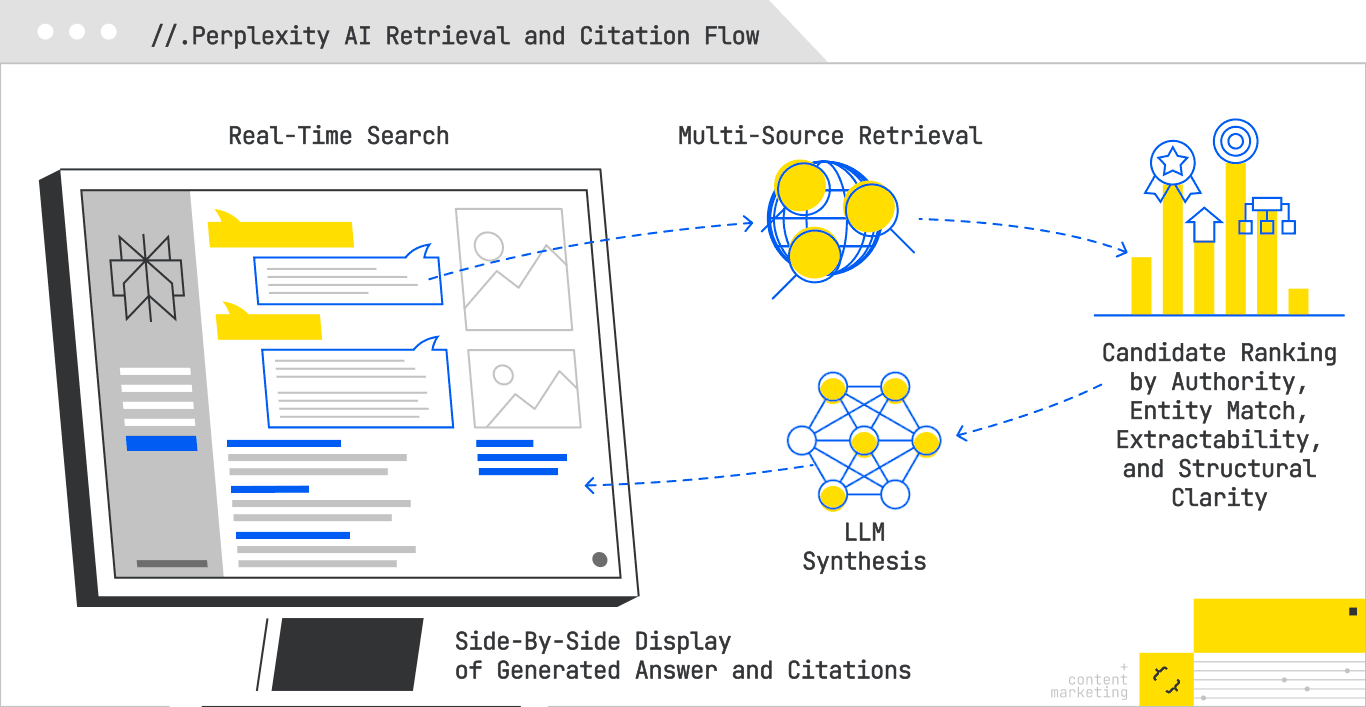
In the broader GEO landscape, Perplexity may be the most measurable of the AI search engines. Its openness removes a layer of guesswork that hampers optimization in other environments, making it an ideal testbed for strategies that can then be ported—albeit with less visibility—into opaque systems like Google’s AI Mode.
For all its transparency, Perplexity is not a passive index. It is an active, selective retriever that rewards content precision, structural clarity, and semantic trust. Optimizing for it means thinking about your pages less as static documents, and more as modular answer units designed to be lifted, cited, and recombined into an AI-synthesized narrative.
This layered structure gives Perplexity multiple extractable options depending on the synthesis need.
Perplexity may never drive the same traffic volume as Google, but it serves as a truth table for generative search visibility. In its transparency, you can see the contours of how retrieval, ranking, and synthesis are converging across the AI search ecosystem. Optimizing here is about training your content to excel in the next generation of search, where answers are built, not listed.
As we’ve seen, while each AI Search surface shares the same broad retrieval-to-synthesis blueprint, the levers that determine whether your content is retrieved, grounded, and cited vary dramatically between platforms. So optimizing without understanding these differences is like trying to rank in Google using only YouTube tactics: You might get lucky, but you’re playing the wrong game.
The common thread is that retrievability is the price of admission, extractability is the ticket to grounding, and trust signals seal the deal for citation. The sequence is universal, but the weighting of each factor depends entirely on the platform’s architecture and philosophy.
The quick-reference table below distills these platform-specific optimization priorities:
Platform | Retrieval Model | Index Type | Primary GEO Levers | Citation Behavior | Common Exclusion Reasons |
Google AI Overviews & AI Mode | Query fan-out to multiple subqueries (lexical + vector + entity) | Full Google web index + KG + vertical indexes | Coverage of multiple latent intents, clean snippet extractability, topical authority, entity-level E-E-A-T | Inline links, sidebar cards, “more sources” | Content fails fan-out subqueries, unclear passage boundaries, low trust signals |
Bing’s CoPilot | Dual-lane retrieval (BM25 + dense vectors) with passage-level cross-encoder rerank | Full Bing web index | Win lexical and semantic lanes, liftable passages, entity schema, freshness signals | Inline superscripts linked to source cards | Client-side rendering delays, buried leads, weak entity markup |
Perplexity AI | Multi-engine API calls (Google/Bing), merged results, selective URL fetch | No native index; real-time external APIs | Crawlability for real-time fetch, concise self-contained passages, fast server response | Source list before answer + inline for claims | robots.txt blocking, slow load, heavy JS rendering core content |
ChatGPT w/ Browsing | LLM search-query generation, Bing search API calls, specific URL fetching | No persistent index | Surface query-wording match, instant accessibility, semantically explicit titles/headings | Inline or end citations, sometimes partial | Doesn’t request your URL, fails to parse due to blocked/slow fetch |
We’ve now pulled apart the wiring of the leading AI Search platforms and seen just how differently they balance retrieval, grounding, and synthesis. We’ve also learned that the gates you have to pass through, from retrievability to extractability to trust, are consistent in concept but wildly inconsistent in execution.
If there’s one common denominator across every architecture, though, it’s this: The first move is never just “your query.” From Google’s expansive fan-out to Bing’s dual-lane retrieval to Perplexity’s precision reformulations to ChatGPT’s opportunistic search prompts, all these systems begin by transforming what the user types into a set of related queries. And those expansions and rewrites aren’t random: They’re engineered to mine latent intent — the unspoken needs behind the explicit words — and then route those intents to the right data sources.
This is where the game shifts from “Can I rank for a keyword?” to “Can I position myself for an entire intent space?”
In the next chapter, we’re going to break down the mechanics of query fan-out, latent-intent mining, and source aggregation in the generative search pipeline. We’ll explore how a single input can splinter into dozens of targeted retrieval paths, how those paths cover both lexical and semantic ground, and how the results are filtered before a single sentence is generated.
If Chapter 7 showed us the anatomy of the body, Chapter 8 is where we will examine the circulatory system: the flows of queries and content that feed the generative brain.
If your brand isn’t being retrieved, synthesized, and cited in AI Overviews, AI Mode, ChatGPT, or Perplexity, you’re missing from the decisions that matter. Relevance Engineering structures content for clarity, optimizes for retrieval, and measures real impact. Content Resonance turns that visibility into lasting connection.
Schedule a call with iPullRank to own the conversations that drive your market.
The appendix includes everything you need to operationalize the ideas in this manual, downloadable tools, reporting templates, and prompt recipes for GEO testing. You’ll also find a glossary that breaks down technical terms and concepts to keep your team aligned. Use this section as your implementation hub.
//.eBook

The AI Search Manual is your operating manual for being seen in the next iteration of Organic Search where answers are generated, not linked.
Prefer to read in chunks? We’ll send the AI Search Manual as an email series—complete with extra commentary, fresh examples, and early access to new tools. Stay sharp and stay ahead, one email at a time.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.
We’ll break it up and send it straight to your inbox along with all of the great insights, real-world examples, and early access to new tools we’re testing. It’s the easiest way to keep up without blocking off your whole afternoon.





