
This being my second time building an SEO Strategy practice from scratch I’ve gotten to put a lot of what I learned from the first go-round into play the right way. Given the inevitable interagency interactions, I’ve gotten the opportunity to endure and see a lot of different agency deliverables and for the most part, I’ve left the experience with the conclusion that the output of keyword research was lacking. Well not just the output, but the inputs and the thinking behind it entirely. And I’m not just pointing the finger at other agencies – I didn’t really know better either.
In most cases, agencies are delivering huge lists of keywords and search volumes and that’s it. If clients are lucky they are getting a prioritized list directly mapped to pages on the site. I see this as a problem for both Paid and Organic Search although I think we can agree that PPC is rarely approached with the same surgical precision as SEO so this type of thinking is typically not on their radar – but it should be. As we build our Paid Search practice we will apply these same practices to account for the audience.
The problem is a list of keywords and search volumes don’t help anyone understand the user behind the search.
From this strategic gap were born the Keyword Portfolio and the SEO Copy Brief, two deliverables that I’d put together at my previous agency and brought over and improved here at iAcquire with the help of my team. Today we’re going to talk about all the work that goes into the Keyword Portfolio and how I believe modern keyword research should be performed and presented.
Standard Keyword Classification is Still Not Enough
At best the industry standard for SEO is to classify your keywords as navigational, transactional or informational. As I’ve said in the past there is too much possibility for ambiguity in keywords to end the analysis or planning there. I think we can agree that there is a wide chasm between informational and transactional keywords and those classifications don’t truly account for the consumer decision journey. Everything seen as information is classified as high funnel and that’s simply not always true especially when transactions are not necessarily a direct on-site action. Also need states may change while reviewing results of the same search.
So to truly understand what the user is looking to accomplish with their search we classify keywords by the personas that are most likely to search for and the need state that user segment is likely to be in. Need state is typically defined by the phase of the Consumer Decision Journey the persona is in. In some cases, we will use a more specific need state, but the easiest CDJ works well. For example, the keyword [how much is ivf] may be relevant to a persona called “Nervous Nancy” who is in the Consideration phase of the in vitro fertilization Consumer Decision Journey. This tells us a substantial amount of information that will dictate Content Strategy rather than telling us what keyword we need to “strategically stuff” into a page.
From the meta description to the ALT tags we account for the brand voice, target audience, and what need they are trying to fulfill with their search. People over robots, yo.
The Process

Before we get to the keyword research phase of the SEO process we go to great lengths to get a firm grasp on our or our client’s business goals. We of course build out your personas with, at the very least, very solid user stories, demographics and psychographics. Many people have different notions as to what a complete persona consists of. I’m not going to argue the values of market segmentation, but the goal is that you end up with a number of clearly differentiated archetypes for your target audience. Whether you’re building affinity maps based on assumptions, using qualitative methods like focus groups and street surveys, or quantitative data stores like Simmons, it doesn’t matter. Just do it.
- Keyword Discovery – From any number of sources you can pull keywords as you normally would. This process isn’t so much about changing where your keywords come from. It’s more about changing how you arrive at whether they are worthwhile and how you can present them in such a way that they are actionable for content strategy and campaign prioritization. Here are the tried and true keyword sources:
- Historical Analytics – Although the keyword intelligence continues to shrink, historical analytics is still the searing pan for keyword discovery. Regardless of the search volume Google is reporting and the CTR studies this is still the best way to know what’s happening and to discover long tail queries that perform. Of course in the era of 100% (not provided), this will become less of an option.
- Google Adwords Keyword Tool Planner – Aside from running tests in Adwords itself and finding out how many impressions are actually happening this is unfortunately your best source for determining how much traffic is available per keyword. Take a deep sigh and go to the Keyword Planner and get what you can.
- UberSuggest – Scraping Google Suggest, UberSuggest is a great tool for identifying long-tail queries and although it is often hard to find that they have search volume in Google’s Keyword Planner, it is often good to gauge whether or not there is interest in a given idea. The guys at Virante have a cool tool called UberGrep for adding the keyword volumes inline on UberSuggest, but it requires an API key from Grepwords.
- Bottlenose – This allows you to identify co-relevant keywords as they are happening in Social Media, much like the methodology I outlined a few years ago with the GoFish tool. Bottlenose is far more robust than my tool and gives you a list of tangential ideas and helps you understand the users behind the vocabulary.
- SEMRush – The tried and true tool for getting your competitors’ keywords as well as search volumes without having to go into Adwords. SEMRush and Grepwords also have APIs that allow you to grab keyword data programmatically.
- Google Trends – Although it doesn’t give you any hard search volume numbers it does allow you to see the trend of interest and drill down into the location-specific trends.
- Yahoo Clues – RIP Yahoo Clues. You were the only free tool that gave actual demographic data per keyword. It would be awesome if Bing made better of use of its keyword data and the demographic data they can pull from Facebook to give us a more robust solution. Hint Hint.
- Experian Hitwise – Hitwise collects searches on the ISP and toolbar level so it’s a great sample-based look at both the keywords and the audiences going to those sites. For our purposes this is the most robust keyword data source and as you might imagine the most cost-prohibitive.
- Data Collection – You’ll need to pull the following data points from your various tools:
- Rankings – You’ll want to know where your client stands currently for these keywords. At iAcquire we’ve inherited the nomenclature of Conductor so we classify rankings into zones. HyperTraffic (1-3), Traffic (4-10), Striking Distance (11-20), Emerging (21-40), Developmental (41-100). Check out Nathan Safran’s post on this topic.
- Search Volume – There are a number of ways to pull this. The wizards at SEOGadget have an Adwords API plugin, but obtaining and maintaining an Adwords API key without having an actual app that fits their criteria is hard to do. I’m also not sure how well this works with all the recent crackdowns that Google has been doing.
- Previous Period Traffic – Whatever previous period of traffic you want to pull whether a month, a quarter or a year. This will be used to compute Share of Voice.
- Landing Page – Landing pages are important for understanding which pages are being targeted incorrectly throughout the site. This is also a good overlap point for our Content Audit deliverable.
- Conversion Rates – The truest show of the value of a keyword is the rate or number of conversions for the previous period. This shows how well a keyword is meeting a given client’s business objectives.
- Keyword Survey – Using SurveyMonkey Audience we put together a survey to get data that allows us to make informed decisions about who exactly in our audience is most likely to use a given keyword for a given reason. We generally pick the number of respondents we want to go after based on what the client believes is a representative sample. It’s hard to predict as you don’t know how many people will fall into each persona bucket, but by leveraging data from Simmons we can predict what percentage of the audience each persona makes up and then put together loose survey projections based on that. The given audience will fit within one demographic range and SM Audience allows us to specify this range. This is a key point where our data from our persona research comes directly into play.
- Survey Design is a science that I don’t claim to have mastered (that’s why we have market research professionals on our team) and as such SurveyMonkey typically requires that users get the all clear from someone over there before they will run such an in-depth survey due to the number of questions we have. They provide a lot of great resources in the way of survey design best practices as well, but the main point I want to drive home in this process is that it’s important to be incredibly judicious about the questions you ask.
- Survey Analysis & Insight Distribution – Ultimately we extrapolate what we learn from the survey across all of the keywords we’ve discovered. If we find that keyword X is more likely to be searched by persona Y and they are in need state Z then similar keywords are likely to follow the same schema. This is the point where the science meets art again. Keyword Portfolios typically have hundreds of keywords so you simply cannot ask about each keyword.
Out-of-the-box, SurveyMonkey Audience gives a lot of great charting options and the ability to cross-tab of data points makes the analysis relatively quick and painless. However, at some point, you are likely going to have to take it to Excel to set up pivot tables to really get down to the persona level on the keywords.
The Deliverable
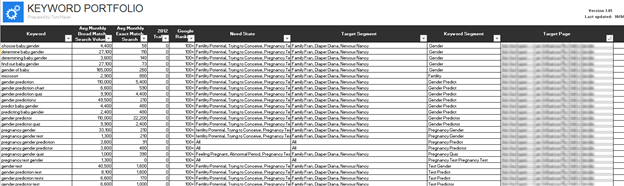
The Keyword Portfolio gives a much more complete picture of the keyword opportunity. Depending on the client’s situation the spreadsheet will have any of the following.
- Keyword
- N-Gram Count
- Avg. Monthly Broad Match Search Volume
- Avg. Monthly Exact Match Search Volume
- Mobile Broad Match Search Volume
- Mobile Exact Match Search Volume
- Previous Period Traffic
- Previous Period Share of Voice
- Previous Period Conversion Rate
- Current Google Ranking
- Target Persona(s)
- Need State(s)
- Keyword Category
- Keyword Sub-Category
- Current Landing Page
- Target Landing Page
- Conversion Rate
- Rank Zone
Most of these fields should be familiar to you except perhaps the following:
- N-Gram Count – An n-gram is a keyphrase comprised of n words. That is to say a phrase with two words is a 2-gram, a phrase with 3 words is a 3-gram, and so on. This is just another way to segment keywords and separate short, middle, and long tail queries in filtering.
- Share of Voice – Keyword Share of Voice is a quick and dirty calculation that speaks to the C-Level. We calculate this by dividing the amount of traffic for the period by the amount of traffic you are likely to get from being in the #1 spot. If you get an SoV that’s over 100% that means you’re in multiple positions or you’re getting a CTR that is higher than the standard.
The end result of the keyword portfolio is a robust spreadsheet that makes it clear where the opportunity is in the context of a brand’s target audience, goals, and competitive landscape.
Keyword Portfolio Use Cases
The main use case of the keyword portfolio is to drive Content Strategy and keep all content creators focused on users rather than robots. Some of the other more specific use cases include identifying keywords:
- landing on the wrong page
- by target audience
- by Rank Zone
- by Need State
- by tail position (head, middle, long)
- by historical conversions
- to prioritize based on campaign effectiveness rather than just search volume
- that need to be consolidated into one page
- that should be split into a new page
The keyword portfolio offers far more robust keyword intelligence for planning and execution than just a list of search volumes. That’s what our clients deserve.
The Caveats
As any Market Research professional will tell you, what people say they do is not necessarily what they actually do and therefore any survey-based data should be validated by true usage data. Naturally, there are several ways to do this:
- Experian Hitwise – The latest iteration of this product integrates with Experian’s Simmons service which means you can get keyword data in context with Mosaic types. Translation: You can get searches vs. personas based on a panel of actual searches. Using this one could potentially skip the step of running surveys completely as you could simply get your insights from the canned surveys that Simmons runs.
- Keyword-Level Demographics – Although 100% not provided is killing the search aspect of this keyword-level methodology, leveraging cohort analytics is the ideal way to validate the market research before conversion happens. While you can use more than one social network Facebook is the most robust demographic and psychographic source.
- Site Profiles – Another method of cohort analytics is leveraging site profiles which is a little easier to make happen than getting people to give you access to their Facebook data. I talk at length about this in a recent Moz post, but look to leverage sources like FullContact and RapLeaf to create invisible profiles and use those to validate personas.
- Conversion Rate Optimization – You could simply look at this a CRO operation and measure the performance impact rather than validating the market research using cohort analysis. After all that’s basically what standard SEO does anyway.
As with any process, my team continues to perfect our approaches based on what we see working best for our clients. We’ve seen some considerable lifts in conversion on clients using this approach.
When Keyword Targeting Goes Wrong
Standard SEO is generally about chasing a keyword with a good amount of search volume that has some relevance to your business. However, when you take your eye off the audience ball long enough things can go very wrong.
Let’s talk about a time when I didn’t practice what I preach.
Kristi Hines, who has been a freelance writer for various blogs including this one for some time now, pitched an idea for a blog post about how to contact Google. I was initially skeptical because I didn’t believe that our target audience was searching for that term, but the available search volume led me to approve the topic in hopes people would naturally link to the post. Naturally, it did in fact generate 186 links from 19 LRDs and ranks #2 for [how to contact google] which would commonly be classified as an informational query. For us however it would be a Familiarity query, but it would not fit any of our target personas thereby making it a completely invalid keyword for us to target. Without getting more data behind the decision I had no idea how disruptive to our goals that ranking for [how to contact google] would be.
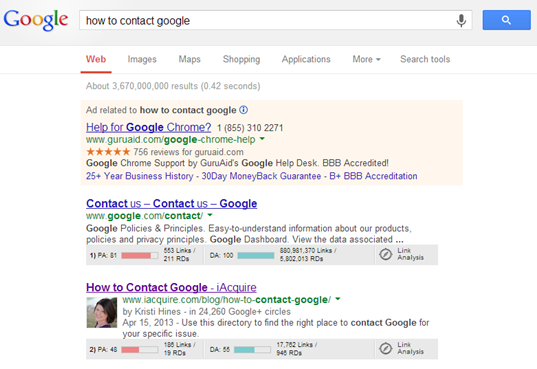
The problem is that [how to contact google] was incredibly unqualified traffic that has resulted in hundreds of people in my IM window that think they have arrived on a Google property. Here’s one of them.
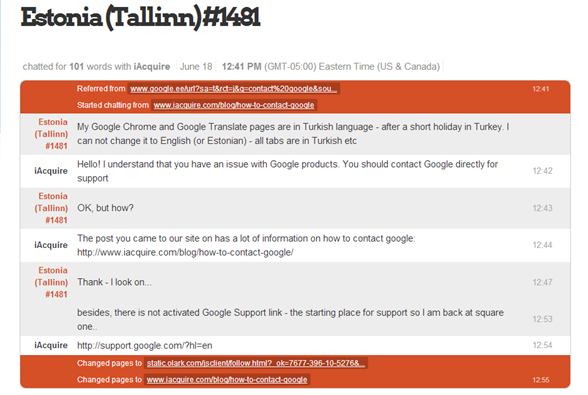
Ultimately, we’ve added this large visual disclaimer to the top of Kristi’s post, but users have still jumped on the Olark live chat to let us know their various gripes with SkyNet Google. Steve Krug is probably pointing and laughing at me right now.
The next step is to either remove or noindex the post, but going through the persona-driven keyword research process would have shown us just how far off that keyword was in a way that couldn’t be explicitly known by just guessing. It also would have saved us a lot of trouble and a lot of distracting instant message conversations.
However when we do focus on our audience and the obvious tenets of SEO we get Search impression increases like this:
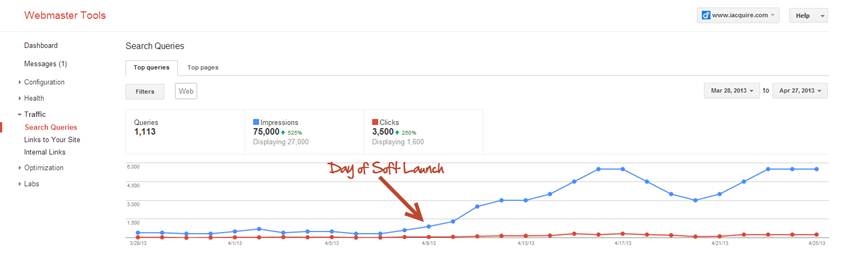
Our Organic traffic conversions (leads) also looked like this:

Use Different Data to Combat (not provided)
It’s unfortunate that Google isn’t going to give us our keyword data back. It’s maddening that they are saying privacy is the reason they’ve obscured it when it’s clearly a way to monopolize Search retargeting and/or turn Google Webmaster Tools into a paid product. At the end of the day, that’s fine, it’s their website they can more or less do what they want. So complaining about it is a waste of time.
The reality of the situation however is that while keywords were always an advantage of Organic Search they are always just a proxy. Keywords have always been positioned as a way to understand the explicit intent of users and now we’re being forced into cohort analysis and implicit intent. That is to say, if you understand the people behind the search and you know what they landed on, you know what messages they are expecting and that is how you optimize in 2014. Your messaging and your user experience are the focus, not just your keywords.
After all, this is the same process the Search Engines are using in the background themselves to better understand their own users (see Google’s affinity segments). I encourage everyone to get in on the action.






