
Since ChatGPT launched in November 2022, we’ve witnessed a surge in AI-generated content flooding the internet. Right now, it’s estimated that over 17% of Google search results contain AI-generated content.
According to Ahrefs, 86.5% of top-ranking pages include some form of AI assistance, leaving only 13.5% as fully human-written. By next year, projections suggest 90% of all content will be AI-generated, and Google appears to neither reward nor penalize AI-generated pages at this time.
The problem is that AI is wrong 60% of the time, according to a March 2025 Columbia Journalism study. Hallucination is still a big problem. Despite this, people still frequently use AI to write. This leaves the web susceptible to an onslaught of low-quality, high-volume content called “AI slop” that could prevent your business from being visible to prospective customers and clients.
“If we’re all generating content based on the same training data, based on the same results that are out there, at what point are you no longer providing any value?” iPullRank’s Senior Director of SEO and Data Analytics Zach Chahalis asked.
Search Engine Optimization (SEO) ensured your site was discovered, but these days, Generative Engine Optimization (GEO) ensures your site is understood.
This blog will walk you through the strategic frameworks we’ve developed at the intersection of traditional SEO and AI-first optimization. You’ll learn how generative systems evaluate content across multiple dimensions, from scope clarity and authority corroboration to freshness signals and safety filters.
We’ll also explore how to audit your content through the lens of vector embeddings, how to use your server logs as a window into AI knowledge, and why an omnimedia content strategy is vital.
AI Search Requires Multi-Dimensional Approaches
Generative search is not a single ranking contest for a single query. It is a multi-stage filtering process in which your content competes at dozens of points in a branching, multimodal retrieval plan. The fan-out indicates the system is looking for breadth as well as depth, and the synthesis step assesses your content on relevance, extractability, and readiness.

“Essentially, we need to be looking at building and developing a multimodal content strategy that supports the retrieval plan and the fan-out queries of where your customers are, and the types of content that are expected for the different queries.”
- Zach Chahalis
Routing Profiles
You need to match the routing profile of what exists, so your content needs to be in the expected form, or it might be overlooked during retrieval. Consider these tips:
- Ensure multi-modal parity (text, structured data, transcripts, etc.).
- Place content where the routing logic looks (e.g., API-friendly formats, transcripts for procedural content).
- Align content with routing profiles to increase retrieval across fan-out branches.
If you worked in the finance industry, routing would send rate queries to financial data APIs, minimum deposit requirements to bank product pages, insurance explanations to government or educational sources, and comparison logic to personal finance editorial sites. Each of those is a different source type, with a different retrieval method and cost profile.
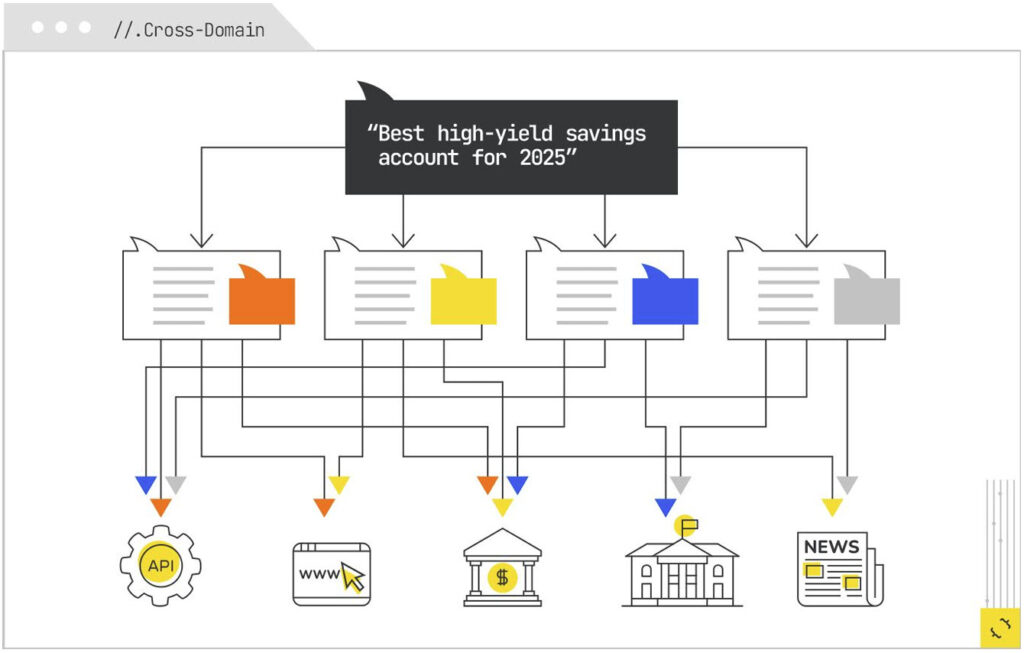
Selection for Synthesis
Selection is not only about relevance to the sub-query. It is also about the suitability of a chunk to be lifted, recombined, and integrated without introducing factual errors, formatting issues, or incoherence.
In effect, the system is ranking not entire pages but atomic units of information, and the scoring
criteria are tuned to synthesis needs rather than to click-through behavior.
Synthesis requires looking at:
- Extractability
- Evidence density
- Scope clarity
- Authority
- Freshness
- Safety

Let’s break them all down.
Extractability
If a chunk cannot be cleanly separated from its surrounding context without losing meaning, it is less valuable to the synthesis process. This is why content that is scoped and labeled clearly tends to survive selection.

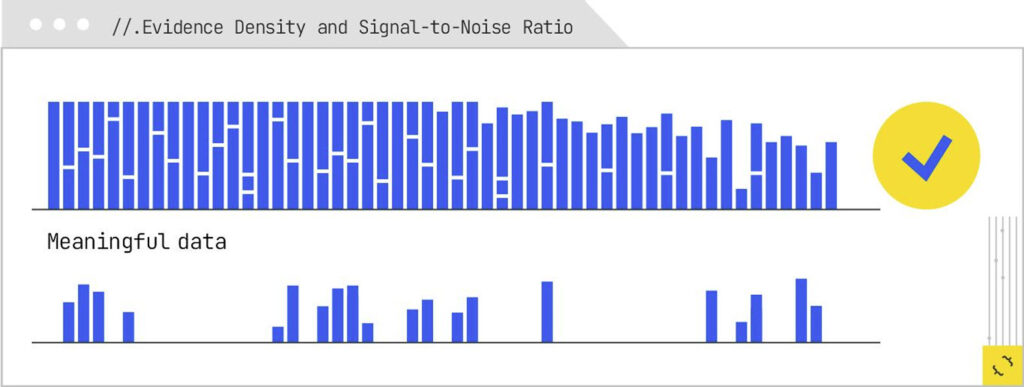
Evidence Density and Signal-to-Noise Ratio
Once extractability is established, the system looks at evidence density or the proportion of meaningful, verifiable information to total tokens. A dense paragraph that gives a clear statement, followed by an immediate citation or supporting data, is more valuable than a
lengthy, anecdote-heavy section that buries the facts in storytelling.
The system wants to find verifiable information and select the most valuable information.
“They want to surface information that’s been validated and authoritatively placed in your platform in your data,” Zach said.
Scope Clarity and Applicability
Generative systems are sensitive to scope because they’re trying to assemble an answer that’s not misleading. If a chunk does not make clear the conditions under which it is true, it is harder to place it correctly in the final answer.
It needs to be organized in a way that’s clear, detailed, and verifiable.

Authority and Corroboration
The system also weighs the source’s credibility and the degree to which other retrieved chunks corroborate the information.
“Authority is not just limited to your domain-level trust, but applies at the author or publisher level, further emphasizing the value of things like EEAT and structured data, authorship, entity definition, etc.”
- Zach Chahalis
Corroboration is a subtle but important factor. If three independent, credible sources agree on a specific mileage progression, that progression is more likely to survive selection. Outlier claims may still make it in if they are well-sourced, but the system will often prefer information that has multiple points of agreement.
Freshness and Stability
Recency is another filter, especially for topics where the facts can change. A chunk that is clearly dated and shows evidence of recent review is more attractive to the model than one with no temporal markers.
This study from Siege Media says that content that shows it’s been updated or reviewed recently (within the last 6 months to 2 years) is considered much more valuable to LLMs.
Harm and Safety Filters
Selection often applies harm and safety filters. These filters can be domain-specific, drawing on both explicit policies and learned patterns from training data.
Our advice is to avoid discussing sensitive topics or just be very careful with how this type of content is structured. Instead, focus on helpful and respectful content.

Tips for Making Extractable Content
High-quality content can be excluded from synthesis if it isn’t easily extractable. Interactive designs that aren’t crawlable or long-form narratives that bury key facts risk being skipped in favor of denser, more accessible material.
You need to engineer content for the selection funnel, which requires rethinking how you structure your content. A single long page may need to be designed as a series of clearly marked, self-contained modules, each of which could stand alone if lifted into a generative answer. It also means pairing each chunk with whatever metadata, markup, and alternative formats will make it easier for a retrieval system to recognize and use.
When organizing your content on a page, write for synthesis. To ensure your content performs well in modern retrieval systems, it’s essential to structure it in a way that is both machine-readable and human-friendly. Embedding models rely on clean, well-defined “chunks” or semantic units of information to generate precise and relevant results.
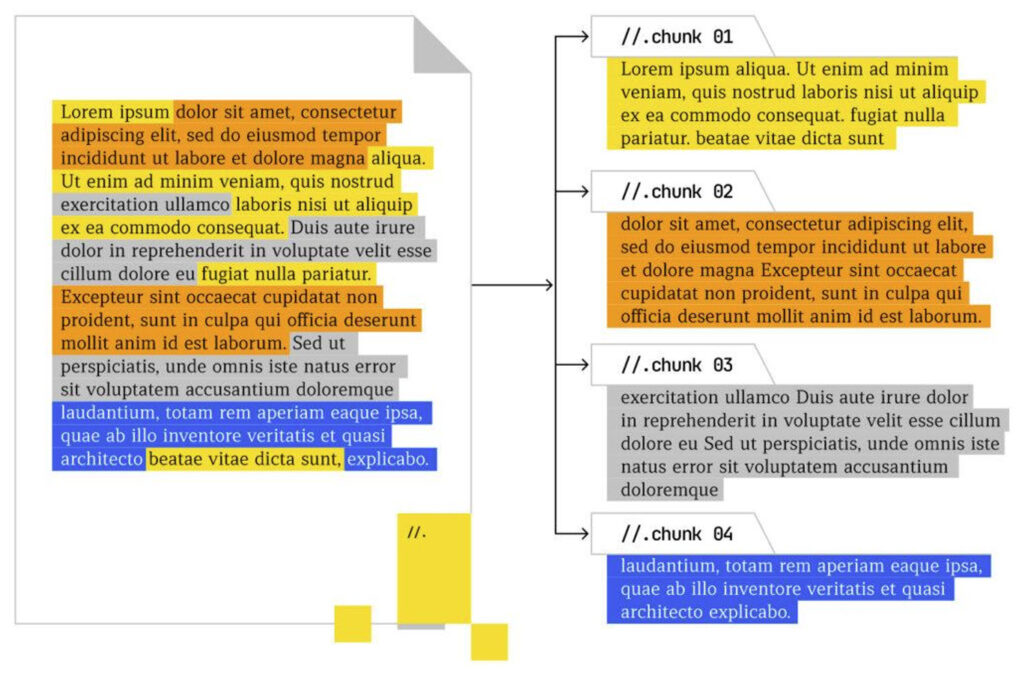
Headings and subheadings should be clear, and passages should answer queries directly and succinctly. The combination of query/passage is defined as a semantic unit, and these units are used to power AI search.
And by the way, iPullRank has a free tool called Relevance Doctor to help you with this.
Our Strategic Approach: Relevance Engineering
Relevance Engineering is the process of adjusting content so it’s selected and cited by AI systems. While traditional SEO focuses on ranking full pages, this approach targets the individual passages and concepts that AI uses to construct responses.
Our strategic approach for driving visibility in AI search includes:
- A content audit for AI readability and extractability
- Semantic and latent intent research
- Content structuring and augmentation for AI
- Testing and iteration with AI simulation
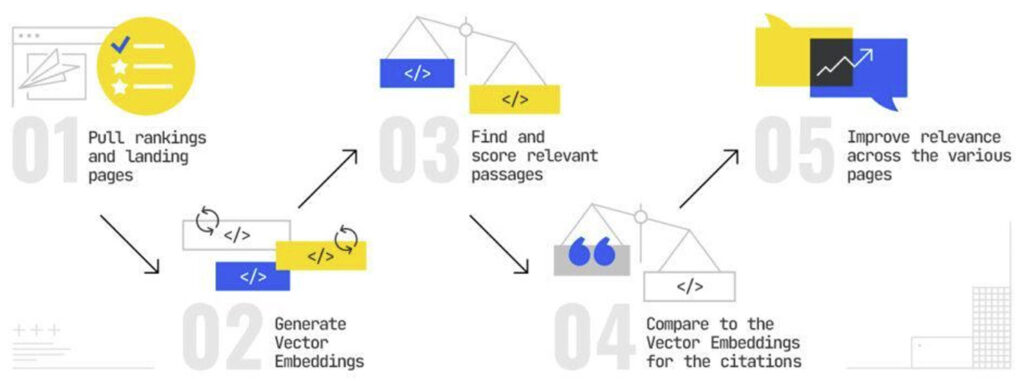
In our tactical implementation, we use these five steps to understand gaps in content:
- Pull rankings and landing pages (use Search Console or your favorite Rank Tracking tool)
- Generate vector embeddings
- Find and score relevant passages (Use Relevance Doctor)
- Compare to the vector embeddings for the citations
- Improve relevance across the various pages
To identify content gaps, our team extrapolates synthetic queries using our proprietary (and free) Qforia tool. This tool now also helps determine the expected types of content per term.
You can also reverse intersect the citations yourself to figure out fan-out queries (we’ve used FetchSERP and SERP API for this).
Log File Analysis
Performing an analysis of your log files can help you understand AI crawlers and bots better.
“Logs really and truly are your visibility into the AI knowledge ingestion pipeline,” Zach said. “They reveal exactly what those systems are doing when they come into your site.”
Your website server logs can show:
- Which AI bots visit
- How often they visit
- How deep they crawl
- Which pages they never reach
- Where they fail to render pages
When looking through your logs, focus on:
- Crawl Frequency – Are AI bots returning regularly?
- Crawl Depth – Are they exploring your site structure correctly? (Ex. Ecommerce: Homepage->Category->Sub-Category->Product Detail Page)
- Render Completeness – Do bots bail before JavaScript loads meaningful content? If your content is built dynamically via JavaScript, AI crawlers may never “see” key sections, especially those rendered asynchronously or hidden behind user interactions.
- Coverage Gaps – Which URLs are never seen by AI bots?
- Status Patterns – Do bots encounter 3XX/4XX/5XX URLs or long response times, reducing embeddings?
Optimizing for Agentic Search
As search tools integrate AI agents more often, it’s important to keep them in mind when optimizing for search. The key pillars for optimizing for agentic search are things we’ve already discussed and are familiar with, but they’re still important:
- Have structured, unambiguous entities.
- Leverage predictable markup and templates so agents can extract and compare data reliably.
- Use actionable endpoints such as booking paths, pricing data, availability, contact APIs, etc.
- Have explainable content such as comparisons, pros/cons, ideal scenarios, summaries, etc.
- Use RAG-Friendly chunked content with clean sections, tables, structured lists and definitional paragraphs.
- Leverage edge rendering so AI crawlers don’t time out or get a partial picture.
“Just think about any context where you have first-person data that could be valuable to the end user,” said iPullRank’s Director of Marketing, Garrett Sussman.
Machine Context Protocol (MCP) and Application Programming Interfaces (APIs) are the future of agentic optimization.
MCP allows agents to securely access your APIs, product/service data, inventory, pricing, availability, and more. Agentic systems will prefer websites with toolable, machine-readable endpoints over raw scraped HTML, so APIs and MCP will become the canonical source that agents trust and act on, making your business a first-party data provider to AI systems.
For marketers, this will need to be a major conversation for your business (and one that we can help you with).
Omnimedia Content Strategy
An omnimedia strategy requires us to think beyond text and align with the expected content formats and locations to drive visibility.

For queries involving troubleshooting, product comparisons, lived experiences, or niche use cases, AI systems often prioritize user-generated content (UGC) and forum discussions.
“The generative models value this type of content a lot more because it’s looking for that authentic, diverse, and situational insight that you can’t necessarily find on your marketing content pages,” Zach said.
Also, focus on using entity-rich, embedding-friendly language. Write with clearly defined entities, use consistent terminology, and include modifiers and descriptors to help differentiate similar entities (i.e., qualifiers like size, function, location, and purpose).

Other things to consider:
- LLMs can and do use structured data as part of RAG pipelines.
- Semantic triples (subject-predicate-object) can help search engines understand context better by identifying entities, establishing connections, and building a web of interconnected concepts.
- Unique content or proprietary data increases the likelihood that your page is retrieved and cited as authoritative in RAG pipelines.
- Clearly defined, straightforward sentences reduce embedding noise and retrieval errors.
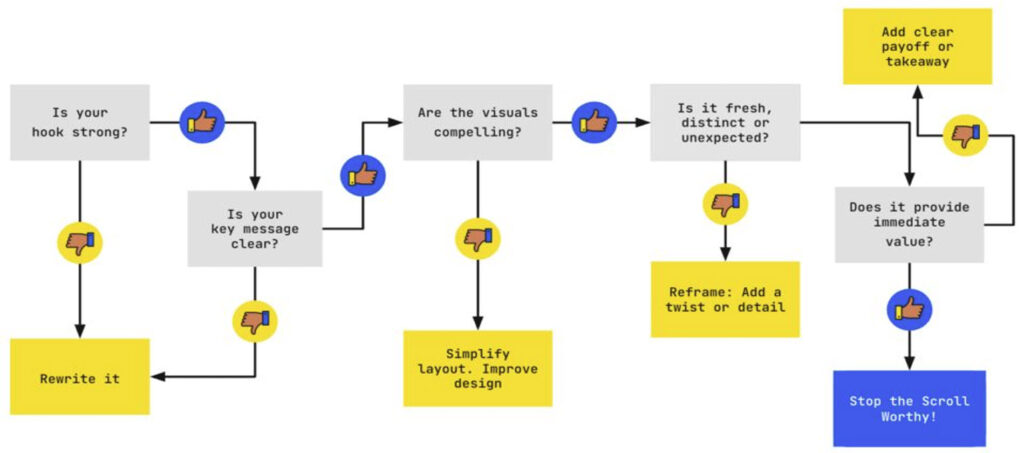
This content assessment flow chart can help gauge whether your content is worthy of stopping the scroll:
Preparing Your Business for an AI Future
When 90% of content is AI-generated, successful businesses will be engineering content that AI systems can actually use. That means building for extractability, structuring for synthesis, and ensuring your first-party data is accessible through the channels that agentic systems trust.
The good news is that many of the principles we’ve covered aren’t entirely new. Authority, freshness, clarity, and structured data have always mattered. What’s changed is how these signals are evaluated.
If you’re feeling overwhelmed by the scope of these changes, you’re not alone. The intersection of content strategy, technical SEO, and AI optimization requires new tools, new workflows, and new expertise.
At iPullRank, we’ve built frameworks and tools specifically to help businesses navigate this transition. Whether you need help auditing your content for AI readiness, analyzing your log files for crawler behavior, or developing an omnimedia strategy that works across modalities, we’re here to help. Reach out to learn how we can help future-proof your content.
And check out the other 2 articles in this series based on our webinars with Sitebulb:








