
When SEOs discuss the differences between classic search and AI Search, the most significant nuance overlooked is the impact of query fan-out.
Query fan-out is the map of every related question an AI system generates or infers from a single user query. It shows the full range of angles, subtopics, and follow-up intents the model considers relevant.
That spread determines how much of your content is pulled into answers across AI Overviews, AI Mode, ChatGPT, Gemini, and Perplexity. If you understand the fan-out, you know what content you need to support, fix, or build to stay visible.
Query fan-out plays a critical role in modern search architectures, particularly in frameworks like Retrieval-Augmented Generation (RAG), where it directly supports grounding synthesized information and anchoring responses to verifiable sources.
You’ll see seasoned SEOs argue that the mechanisms of query fan-out exist in the processing systems of traditional search systems. That’s true. Query augmentation, search intent analysis, consideration of user and session context, and user history and user content preferences and behavior for personalization have all leveraged the technique. But query fan-out technology goes a step further by expanding a single query into multiple subqueries.
This, alongside the reasoning and text processing and transformation capabilities of LLMs, allows AI Search systems to mimic research on a given topic and consolidate information from multiple documents into a single response.
Understanding the mechanism behind how AI Search platforms expand queries with fan-out is important for multiple reasons:
- Query fan-out represents the most significant shift in search since mobile-first indexing
Query fan-out signals a profound evolution in search technology and demands that professionals reimagine their optimization strategies entirely – from deterministic to probabilistic ranking means shifting from traditional visibility optimizations to relevance engineering, driven by entities, context, and semantics.
- Query fan-out powers modern AI search’s contextual capabilities
Modern AI Search systems depend on query fan-out to deliver dynamic, context-aware experiences. Similar mechanisms for query fan-out in Google’s AI Search platforms (Gemini, AI Overviews, AI Mode) are implemented in other AI Search systems (Copilot, ChatGPT, Perplexity), enabling search systems to synthesize comprehensive, personalized responses grounded in multiple evidence sources, something keyword matching alone cannot achieve.
- Query decomposition strengthens factual accuracy but demands atomic, entity-rich content architecture
Query fan-out decomposes complex queries into dozens of semantically distinct subqueries, each targeting a specific facet of user intent. It’s built for conversational search and search efficiency.This multi-vector retrieval strategy forces LLMs to pull evidence from multiple passages and documents rather than relying on a single high-ranking page, resulting in a fundamental break from keyword-based ranking.
As a result, LLMs ground claims in multiple sources, which also assists in reducing hallucination risk. On the flip side, this also means your content wins only if individual passages (as opposed to entire pages) contain atomic facts anchored to canonical entities with verifiable sources, and if they are relevant to the questions that potential users might be asking to find businesses like yours via AI Search systems.
Generic, thematic content no longer converts to visibility in search. Your passages must be granularly useful and independently retrievable, which is why traditional keyword-based content clustering and broad topic coverage might fail as a strategy for AI Search.
- Contextual query variation and over-personalization: why semantic infrastructure replaces keyword optimization
Follow-up questions generated by fan-out vary stochastically across users, and can be influenced by factors like past search history, device, location, preferences, and prior queries. It’s important to note that traditional search systems (like Google Search’s algorithm) also do this.The difference here is that AI Search systems over-personalize results and work with longer user queries. On average, according to our AI Search research with SimilarWeb, the queries submitted to AI Search systems are about 70-80 words, compared to only 3-4 on Google.
This contextual personalization is so dynamic that traditional SEO tools designed for static keyword-to-page matching cannot predict, measure, or optimize for it. Over-personalization means the same query generates different answers for different users, reducing your predictability and the ability to measure success through traditional impression tracking. Your content may rank differently (or not at all) for the same person on different days.
To compete in AI Search, marketing teams must build a robust semantic foundation, an ontological core that allows LLMs to reason across your entities, attributes, and relationships regardless of how the query is decomposed. This shift is not optional: systems that optimize for individual keywords will fragment across personalized query variants, while systems built on semantic infrastructure remain coherent and retrievable across all decompositions.
- Citation-based visibility might eventually rival links, though AI search today remains a fraction of total traffic
Today, AI Search systems a small but growing fraction of search traffic, which is still far below traditional organic results. That said, the strategic shift toward citation-based visibility is urgent precisely because of how it can compound: if AI Search matures (big if, considering underlying industry factors and technology limitations) and captures 20%, 30%, or more of query volume, citation metrics will become as material to business outcomes as backlinks and CTR.In that future state, being mentioned and cited in AI responses across reasoning chains, answer synthesized, and entity cards might be considered the equivalent of no-follow links in traditional search: a visibility signal that drives brand awareness, trust, and indirect conversion.
In the analysis below, we will take a facet of this discussion – how AI Search platforms expand user search queries with the fan-out technology, and consider how this over-personalization can skew search intent, and what this means for SEOs and marketing professionals wanting to improve visibility on AI Search platforms.
Want the NSFW version? Check out Mike King’s recent presentation at Tech SEO Connect (get the deck).
I will touch upon the fan-out-like implementations of not only Google, but other AI Search systems, too; and offer practical suggestions for aligning your existing content strategy to this approach.
How Query Fan-Out Works
Let’s quickly recap the query fan-out mechanism and related patents. Notably, Google’s query fan-out mechanism is described in detail in the patent titled Thematic Search, where short, expansive, descriptive search subqueries (query fan-outs) are referred to as themes.
It can be used in a wide range of UX implementations:

This patent describes the process of generating fan-out queries, selecting and extracting passage-based information from relevant documents, and generating summaries for AI Overviews and, in part, AI Mode and Google’s Deep Research
How Queries Are Deconstructed and Expanded
Query fan-out expands a single user query into multiple, more specific subqueries, based on identified themes. Rather than treating a search request as an isolated request, the system decomposes it through several mechanisms.
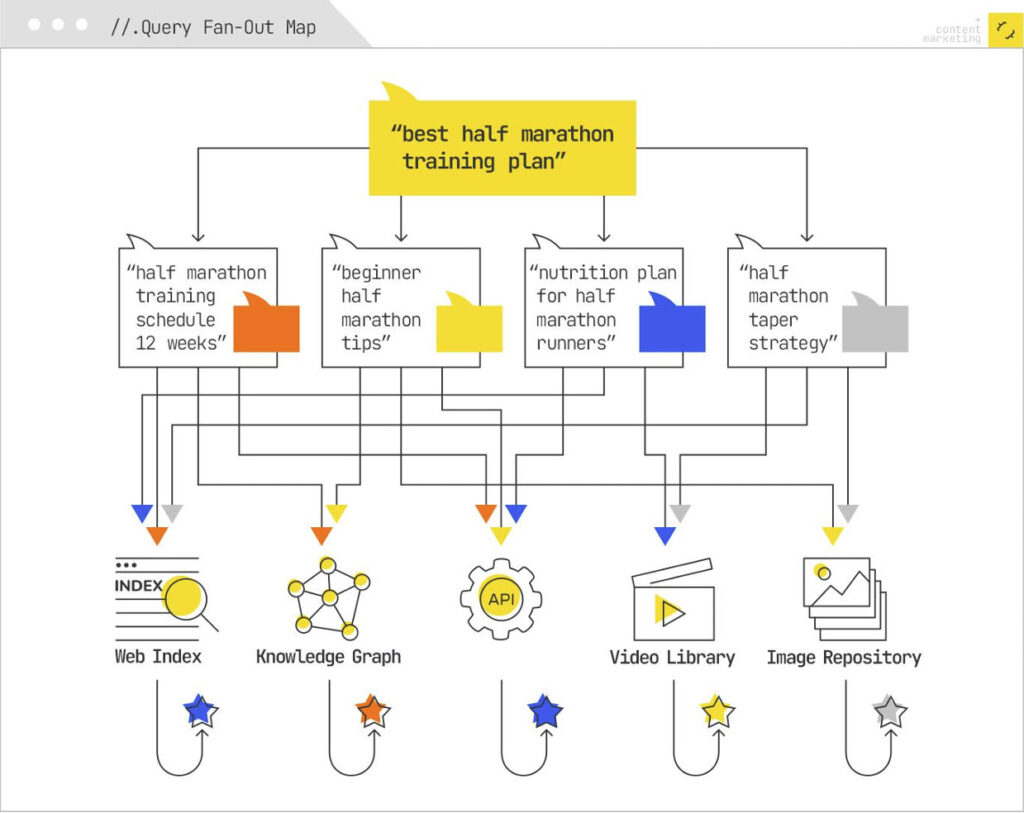
The system decomposes the user’s question into subtopics and facets, then simultaneously executes multiple queries on their behalf across these different angles.
NLP algorithms analyze each query to determine user intent, assess complexity, and route to the appropriate response type.
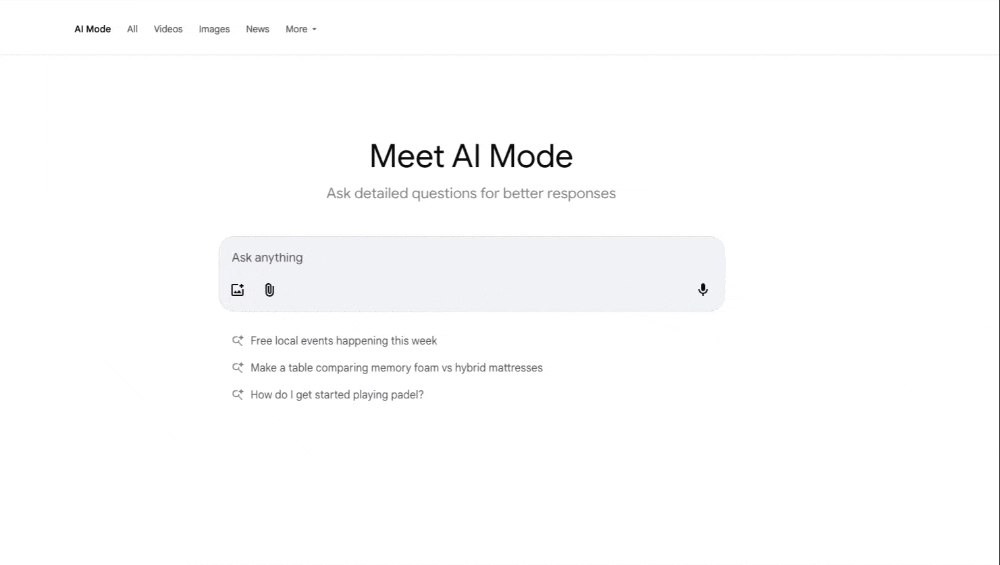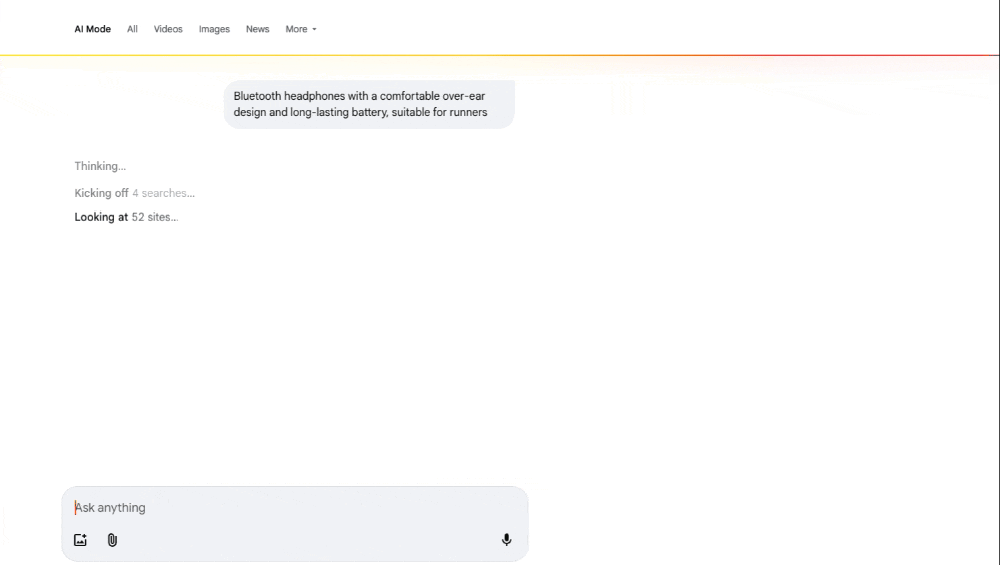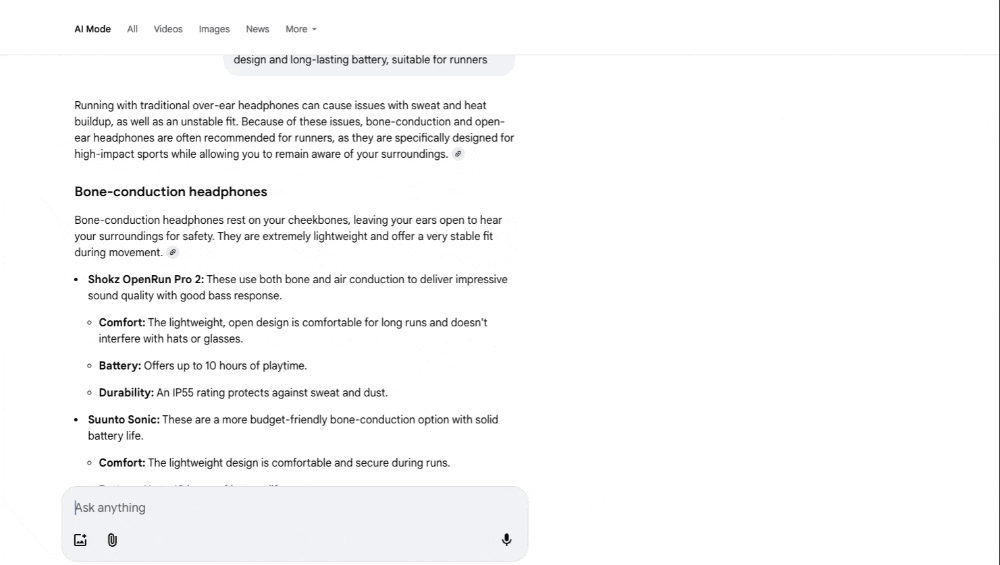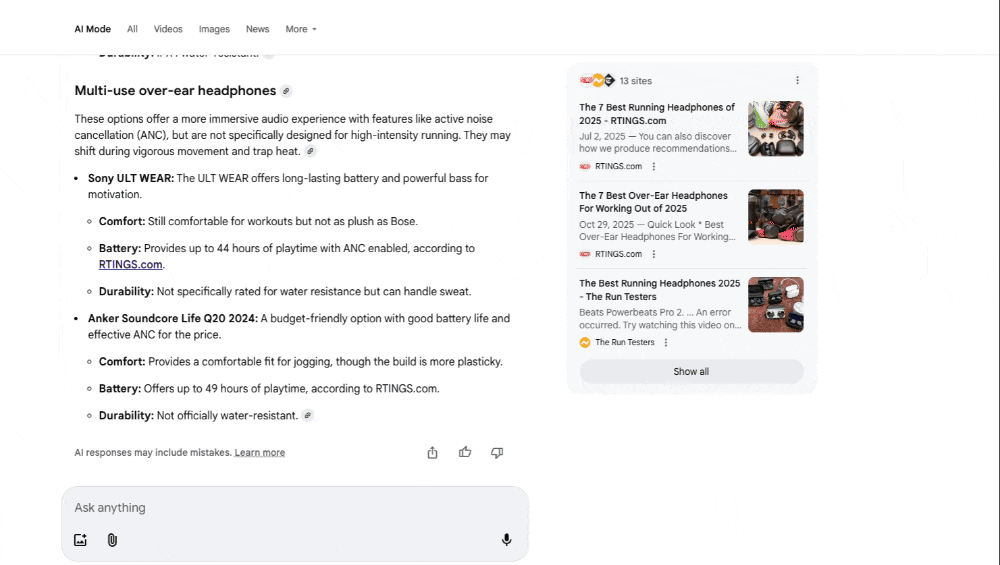
Context-rich, complex queries requiring multi-criteria decision-making or source synthesis, for example, “Bluetooth headphones with a comfortable over-ear design and long-lasting battery, suitable for runners” will trigger extensive fan-out.
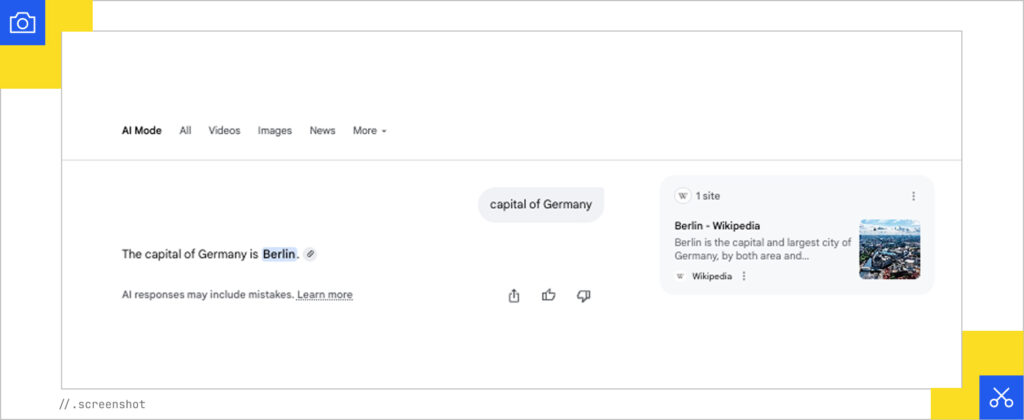
Simple factual queries, such as “capital of Germany,” receive minimal decomposition and do not trigger fan-out.
Quick side note – how would a traditional search system approach these queries?
Google’s approach relies heavily on semantic understanding, similar to the fan-out system’s reaction to query complexity.
For the simple factual query, “capital of Berlin,” Google will identify “Germany” as an entity, and capital as an attribute, and utilize its Knowledge Graph (KG), which organizes and connects real-world entities and their relationships. Because this query typically seeks a single definitive fact (a “Know Simple” query), the result would be displayed immediately in the SERP via a Knowledge Panel, which shows a combination of relevant, factual information about the entity, enhancing the user experience.
In contrast, for the complex query, “Bluetooth headphones with a comfortable over-ear design and long-lasting battery, suitable for runners” will trigger a more intensive semantic analysis.
Google shifts to an entity-centric understanding (think Entity SEO), recognizing:
- The core entity ‘headphones’ and associated brands
- Semantically-related topical clusters, like ‘for runners’ versus ‘for working out’ or ‘for fitness fans’
- multiple specific attributes mentioned in the query, alongside their mention variants (‘Bluetooth’ versus ‘wireless’, ‘comfortable’ versus ‘don’t hurt’ versus ‘sweatproof’, ‘long-lasting battery’ versus ‘10+/ 6+ hours battery life’)
- the general intent (commercial investigation), triggering articles like listicles, and comparison videos, as well as featuring discussion forums prominently

The system will use the Knowledge Graph to retrieve related entities and attributes. It might initiate query augmentation or refinements to enrich the search by adding related terms or concepts to the original query (e.g., suggesting specific models or comparisons based on user interactions).
Mechanisms for detecting query refinement help Google interpret the progression and modifications of subsequent searches within a session to accurately deliver results aligned with the user’s nuanced intent (i.e., anticipating the next step in the journey by endorsing specific product-entity searches or deepening the investigation with different facets of the original search query).
The key difference is that simple factual queries optimize for speed and accuracy via structured data. Complex queries optimize for comprehensiveness via parallel exploration and entity-driven synthesis.
Query fan-out retrieves information from sources different than those ranked in the top positions of traditional search, and AI Search systems don’t cite all the sources that they base their responses on (that were retrieved during the fan-out process and used for response generation).
More on this in iPullRank’s AI Search Manual. The system executes subqueries in parallel across the live web, knowledge graphs, and specialized databases such as shopping graphs.
Role in Modern AI Systems (RAG and Grounding)
Query fan-out powers the comprehensive, synthesized answers that define modern AI Search interfaces like Google’s AI Overviews and AI Mode, but a similar mechanism exists for platforms like ChatGPT, Perplexity, and Copilot.
Within Retrieval-Augmented Generation (RAG) frameworks, query fan-out strengthens the retrieval component. Parallel subquery execution gathers a richer set of relevant passages from different documents, providing LLMs with the contextual information needed to synthesize detailed, accurate answers.
Query fan-out also supports LLM’s grounding capabilities by connecting responses to verifiable, real-world information. Multiple subqueries retrieve semantically rich, citation-worthy passages that anchor different aspects of the response to factual sources, reducing the risk of hallucination.
Personalization and Dynamic Execution
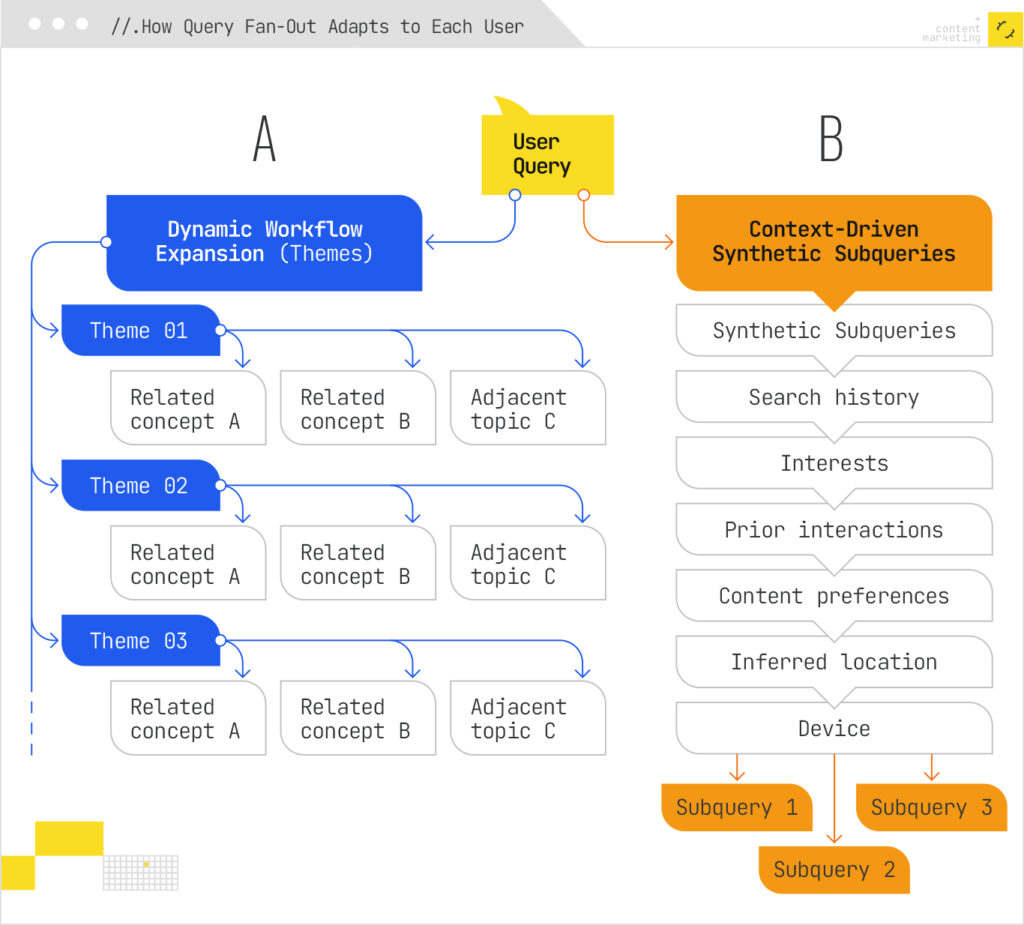
Query fan-out adapts to individual users through two mechanisms:
- The system generates queries dynamically throughout iterative workflows, exploring multiple related concepts and areas of inquiry (themes) in parallel rather than executing a predetermined query set.
- The synthetic subqueries the system generates (similar to traditional search systems) would consider factors such as individual user context based on search history, interests, prior interactions (content preferences), inferred location, and device.
Both of these aspects can skew search intent, but more on this in a moment.
Query fan-out shifts the way that information is retrieved from single-search, document-based, to a multi-search, paragraph-based. The mechanism activates an entire network of highly contextualized searches executed in parallel, ultimately transforming complex requests into comprehensive, synthesized, and verifiable answers.
Core Technologies Powering Query Fan-Out
Modern AI Search systems rely on a multi-stage, layered architecture to decompose and expand queries. It’s multiple iterative ML systems working together, each performing a specific task, together doing the work. The four primary technical mechanisms enabling this process are:
- Foundational AI and Modeling: Generative LLMs (including specialized models trained on real query-document pairs) and sequence-to-sequence models like T5 and GPT that produce synthetic queries at scale, enabling the system to generate plausible queries for documents that lack labeled training data.
- Dynamic and Contextual Query Generation: NLP-driven query analysis that determines complexity and routes to appropriate response types, combined with personalization via user attributes (location, task context, demographics, search history, temporal signals, calendar data) and generation of eight distinct query variant types tailored to individual users and contexts.
- Iterative Processing and Control Architecture: Control models (also called Critics) that manage iterative refinement loops using reinforcement learning signals, where an Actor (generative model) generates variants and the Critic evaluates result quality, determining whether to continue iteration or terminate based on quality thresholds, iteration limits, or diminishing returns.
- Retrieval and Synthesis Mechanisms: Parallel retrieval-augmented generation (RAG) that executes decomposed queries simultaneously across the live web, knowledge graphs, and specialized databases, combined with semantic chunking (fixed-size, recursive, or layout-aware) to ground responses in verifiable passages and thematic search clustering that generates summary descriptions and organizes results into theme-based drill-down queries
How LLMs Drive Query Generation
Large Language Models sit at the center of query fan-out. Rather than relying on simple keyword addition or predefined rules, LLMs actively generate new query variants that capture meaning beyond the surface words. They are utilized to generate diverse, context-aware, and semantically rich query variations.
The system trains specialized generative models on real query-document pairs. These models learn patterns about which questions a given document might answer, then use those patterns to generate synthetic queries. This approach works because it fills a real gap that traditional search systems are yet to address – the need for flexible consideration of longer, unique queries with a ton of explicit user context shared. The query fan-out system uses trained generative neural network models capable of actively producing new query variants for any input, even queries never seen before.
A critical component is the use of synthetic queries, which are artificially generated queries designed to simulate real user search queries. The system is trained to generate eight distinct types of query variants, broadening the scope of the search:
▪ Equivalent Query (alternative phrasing for the same question).
▪ Follow-up Query (logical next questions).
▪ Generalization Query (broader versions).
▪ Specification Query (more detailed versions).
▪ Canonicalization Query (standardized phrasing).
▪ Language Translation Query (for multilingual content retrieval).
▪ Entailment Query (implied or logically following questions).
▪ Clarification Query (questions presented back to the user to confirm intent).
This diversity matters because a single document might not match the user’s exact phrasing, but it could answer a generalized version of their question or a more specific variant they didn’t think to ask.
Personalization Through Query Tokens and Attributes
When a user submits a query, NLP analysis determines complexity and intent, aimed at identifying the type of response needed. The system then personalizes query generation using user and environmental attributes.

Key inputs for generating variants include the original query tokens, type values (indicators specifying the kind of variant needed), and various attributes such as:
- User Attributes: Location, current task (e.g., cooking, research), demographics/professional background, and past search behavior patterns.
- Temporal Attributes: Current time of day, day of the week, or proximity to holidays.
- Task Prediction Signals: Stored calendar entries, recent communications, and currently open applications.
Rather than treating personalization as a final polish, it’s baked into the query generation itself. The generative model uses these signals as inputs, meaning different users get genuinely different subquery expansions from the same initial question.
Iterative Refinement Through Control Models
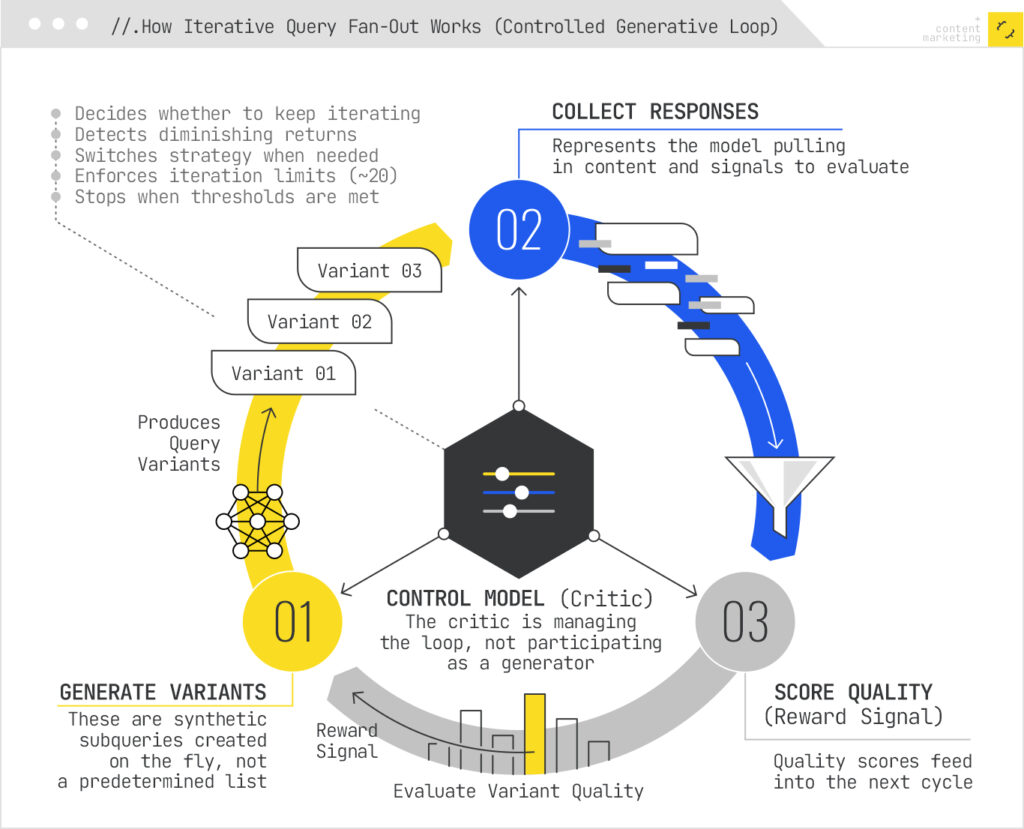
Query fan-out doesn’t happen in one pass. An iterative loop generates variants, collects responses, and decides whether to continue or stop. Search queries are generated dynamically throughout an iterative workflow, such as in the Deep Researcher with Test-Time Diffusion (TTD-DR) framework. A separate neural network called the Control Model (or Critic) manages this loop. It acts like a quality gate, deciding when the accumulated results are good enough, when the system is reaching diminishing returns, or when it should try a different angle.
The control model uses reinforcement learning signals. Each generated variant produces results; the quality of those results feeds back as a reward signal to the generative model. This creates a feedback loop where the system learns which types of variants are most useful for answering different question types. The loop terminates when quality thresholds are met, iteration limits are reached (typically around 20 iterations), or quality improvements flatten out.
Retrieving and Grounding Across Multiple Sources
Query fan-out significantly enhances the retrieval component of Retrieval-Augmented Generation (RAG). The system fires them simultaneously across the live web, knowledge graphs, specialized databases, and other sources. Parallel execution is critical. If the system processed subqueries sequentially, response time would explode. Instead, it gets a richer portfolio of evidence in roughly the same time as a traditional sequential search. This expanded, parallel retrieval gathers a richer set of documents/passages, providing ample contextual information for the language model to synthesize a detailed answer.
Grounding pulls from these diverse sources by retrieving semantically rich passages that anchor specific claims. Rather than surfacing entire pages, the system identifies the specific chunks that support different aspects of the answer. Content chunking strategies (fixed-size, recursive, or layout-aware) help the system parse documents into meaningful pieces. This is why your content structure matters: a well-organised and written document is easier for retrieval models to ground claims against.
Thematic Search operates alongside this process. After gathering initial results, the system generates summary descriptions for document passages, then clusters those summaries into themes. If a user selects a theme, the system dynamically generates a narrower drill-down query combining the original query with the selected theme. This creates a conversational loop where users can refine results by exploring thematic branches.
Which AI Search Platforms Use a Fan-Out Mechanism?
Query fan-out isn’t unique to one platform. Most modern AI search systems use it, though they talk about it differently and implement it with varying transparency.
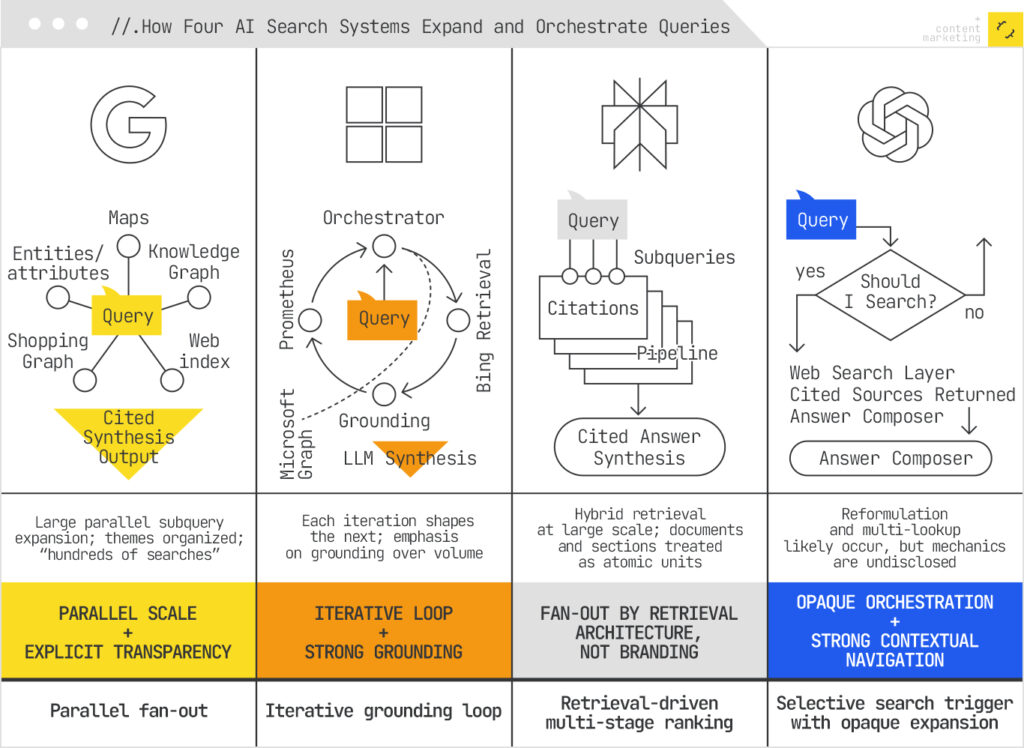
- Google uses Query Fan-Out Explicitly in AI Mode, Deep Search, and some AI Overview experiences
The system decomposes your query into many themed subqueries, fires them in parallel across the web and Google’s internal graphs (Knowledge Graph, Shopping Graph, Maps), then synthesizes a cited response. Google has named this mechanism publicly and documented it in patents (1, 2, 3) describing synthetic query generation within stateful chat sessions and LLM-driven query generation for broader coverage.
The key distinguishing feature from other AI search systems is scale and transparency. Google talks openly about firing “hundreds of searches” (bye-bye, sustainability pledge) and organizing results by theme, which aligns with the explicit, large-scale parallel approach.
- Microsoft’s Copilot uses Bing’s Orchestrator to route your query through an internal pipeline, via an Iterative and Graph-Grounded process
Rather than a single parallel burst, Orchestrator generates internal queries iteratively, grounds results in Bing’s index and knowledge systems, then passes the grounded data to the LLM synthesis layer (called Prometheus). Simply put, this means each result informs the next, creating a grounding loop rather than a pure parallel burst. For enterprise use, this pattern extends to Microsoft Graph, where Copilot can ground queries against your organizational data before synthesizing answers. Azure AI Foundry “Grounding with Bing Search” shows the same pattern for agents (search fan-out then ground/compose).
The difference from Google’s approach: Microsoft focuses on iteration and data grounding over massive parallel subquery generation.
- Perplexity’s answer engine performs hybrid retrieval with multi-stage ranking on a swarm of queries
Perplexity issues multiple searches internally and synthesizes them with citations. Perplexity’s architecture processes 200 million queries daily, achieving 358ms median latency across a multi-stage ranking pipeline backed by 200+ billion indexed URLs. If you use Perplexity, you see multiple subqueries firing in the UI. But Perplexity doesn’t call this query fan-out.
They describe the Search API architecture as hybrid retrieval combined with distributed indexing and multi-stage ranking. Perplexity prioritizes this retrieval approach and fine-grained content understanding, as it enables them to treat documents and sections as atomic retrieval units to supply LLMs with only the most relevant text spans.
The behavior is clearly a fan-out/fan-in pipeline, as previously noted in Mike’s teardown analysis of AI search architectures, but the company positions it as a retrieval architecture decision rather than a named query expansion technique.
- ChatGPT includes a Search mode that decides when to hit the web, returns cited sources, and composes answers.
ChatGPT’s Search behavior strongly suggests query reformulation and multiple lookups, but OpenAI hasn’t published details about orchestration, subquery generation, or the number of parallel searches. OpenAI has been less transparent about the mechanics than competitors, only documenting decision-to-search and source-cited synthesis only; details like number or shape of subqueries made are undisclosed. ChatGPT’s Atlas uses conversational search with contextual understanding of the current page, enabling rapid pivot without explicit query expansion.
Click the table below to view it expanded in a new window:
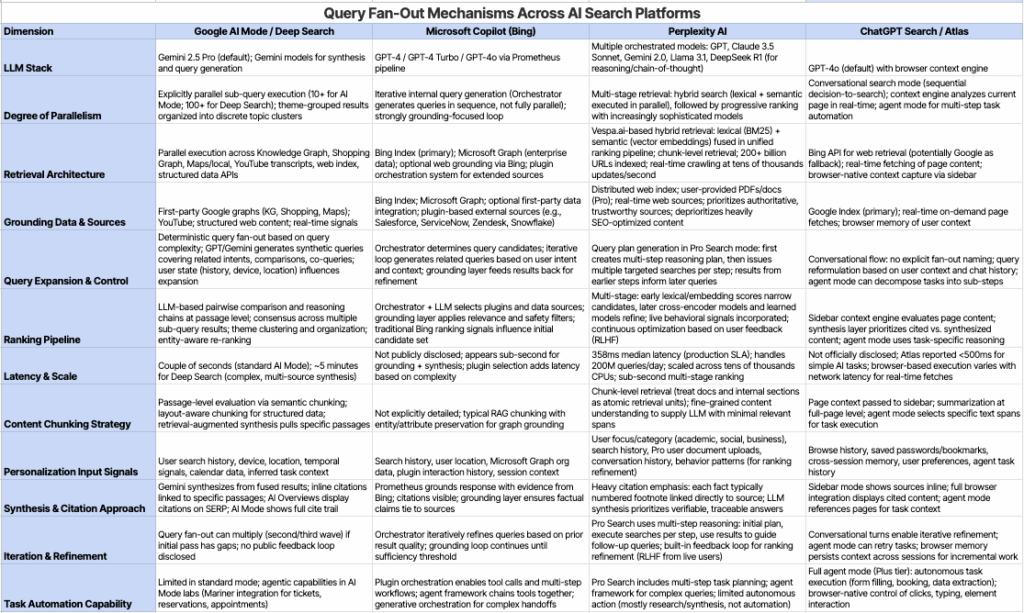
Despite the different framing, all four platforms decompose queries into multiple subqueries and synthesize the results. All platforms (similarly to traditional search engines) personalize based on search history and location. Microsoft extends personalization to Microsoft Graph org data and enterprise contexts. OpenAI’s Atlas adds cross-session browser memory and browsing history for persistent personalization.
For SEOs and content strategists, this matters because it means your content needs to be discoverable not just by the literal query but by the constellation of related, themed, and contextual subqueries that any of these systems might generate. The specific platform differences are less important than understanding that decomposition itself is the game.
How the Query Fan-Out Mechanism Can Skew Intent
Despite the query fan-out being a multi-faceted process, designed to precisely pinpoint and address intents and user needs with varying complexity, some of its mechanisms can, in fact, skew intent.
While its primary goal is to retrieve the maximum number of relevant documents regardless of vocabulary limitations, the mechanisms it uses, particularly deep personalization features and dynamic generation of related topics, inherently possess the capacity to interpret and potentially skew or broaden the initial intent of the user-generated query.
Let’s explore.
Generative Dynamic Query Expansion Can Skew Intent Through Semantic Drift
Large Language Models (LLMs) are used for generative query expansion to produce diverse, context-aware, and semantically rich query variations. The system can generate eight distinct types of variants, including:
- Follow-up Queries (logical next questions)
- Generalization Queries (broader versions)
- Specification Queries (more detailed versions)
- Entailment Queries (logically implied questions)
This expansion, by design, explores adjacent and implicit concepts, leading the search results away from the narrow focus of the initial query.
When the system projects latent intent, it embeds the original query into a high-dimensional vector space and identifies neighboring concepts based on proximity. Historical query co-occurrence data, clickstream patterns, and knowledge graph linkages inform these neighbors. This mechanism introduces drift risk. The system traverses semantic relationships that may feel adjacent to the user’s original intent but stray from it.
In traditional search, these expansions are also made to inform featured snippets like People also Ask, People also search for, or People Search Next. The key difference here is that in AI Search systems, the bias is introduced by the generative AI, which combines the data to produce its final response. While in traditional Google Search, the results are presented, and the user is left to decide whether to explore these adjacent intent avenues, in AI search, this decision is made for the user; the queries are fired, and the responses to adjacent queries are woven into the system’s response.
In some contexts, this may feel like a positive thing, like a step in removing the commercial investigative aspect from the user journey, thus shortening the path to purchase (like in the example I shared at the start of the article).
In other contexts, like in the context of travel or trip planning, this exact change leads to an erasure of authentic experiences of travellers shared in blogs or vlogs, replacing them with a concatenated list of top picks.
Query fan-out systems often integrate with mechanisms like Thematic Search, which generate themes from the content of responsive documents rather than relying solely on the query itself. When a theme is selected, the system generates a new, narrower search query by combining the original query with the selected theme. This iterative process, designed for drilling down from a broad query, replaces the user’s original query with a synthetic, topic-specific query (“moving to Denver” + “neighborhoods”).
These synthetic query variants might fire and remain pre-loaded until clicked, or they might be directly included in the response. These mechanisms might be designed to anticipate the next step of the search journey, but they might overwhelm or nudge the user onto a different search path altogether.
Two-point transformation and Latent Signals can result in Hybrid or Misinformed Responses
This is compounded by the machine learning architecture itself. Latent intent signals are captured by encoding user interactions with retrieved results, but existing methods treat query reformulation as a two-point transformation, neglecting the intermediate transitions that characterize users’ ongoing refinement of intent. The system infers intent from past behavior, not from what the user is asking now.
Here are example signals captured:
- Historical embeddings: “This user has searched for marathon content 47 times in the past 3 months, so they’re a distance runner”
- Click patterns: “They clicked on high-performance shoe reviews, so they value speed/weight”
- Interaction history: “They spent 8 minutes on a page about marathon nutrition, so that’s a strong signal”
These signals are static. They’re encoded once into user embeddings and reused across multiple queries within a session. The system doesn’t re-evaluate the user’s current request; it filters the current query through the lens of historical intent.

At the core of this issue is the distinction between:
- Latent intent (what the system infers from patterns): “This is a marathon-focused distance runner”
- Explicit intent (what the user is actually asking right now): “I’m injured and need rehabilitation options”
When the system only captures endpoints, it conflates the two. It assumes today’s query is just another variation of yesterday’s need, rather than recognizing a fundamental shift.
For example, the system sees Monday’s query (“marathon shoes”) and Friday’s query (“low-impact cardio”) and treats them as variations of the same user intent, rather than recognizing an actual intent shift caused by an intervening event (injury).
If the system uses two-point transformation, it may:
- It shows results for both marathon shoes AND low-impact cardio, creating a confusing hybrid answer
- It misses that the user is currently injured and needs rehabilitation-focused content
- It over-weights the “marathon training” signal from their history, not recognizing it’s now outdated
- It doesn’t surface injury recovery content prominently, even though that’s their current need
As a result, the user sees generic “running + recovery” results when they actually need “post-running-injury rehabilitation programs + non-running cardio options.”
Deep Personalization, Contextual Bias and Filter Bubbles
A key characteristic of query fan-out in modern AI Search is its deep personalization, where subqueries are tailored to the individual user’s context.
The system generates variants not just based on the original query tokens, but heavily influenced by Attributes (additional contextual information). These attributes include User Attributes (past search behavior patterns, professional background, interests), Temporal Attributes, and Task Prediction Signals (stored calendar entries, recent communications).
Put otherwise, personalization mechanisms inject historical bias into query expansion. This creates a compounding problem: the system doesn’t just answer the user’s query; it reinterprets the query through the lens of past behavior.
LLMs can skew phrasing of certain topics based on users’ characteristics, content preferences, and browsing data, including political leanings, showing more positive information about entities aligned with the user while omitting negative information about opposing entities. The same phenomenon applies to topical bias. A user with a search history dominated by one perspective will have their follow-up queries shaped toward that perspective, even if they’re searching for balanced information.
Filter bubbles describe situations where individuals are exposed to a narrow range of opinions and perspectives that reinforce their existing beliefs and biases.
AI Search Systems create the mechanism for an environment that leads to polarisation and biasing of options, due to a lack of confrontation with opinions and narratives different from ours. Systems like ChatGPT are inherently agreeable, leading many people who have intense relationships with the technology astray into what is now being referred to as AI-induced psychosis.
The real damage is that the user doesn’t perceive the narrowing. They assume the system is answering their explicit query, unaware that subqueries have been rewritten to match their historical patterns.
Takeaways: What This Means for SEO and Marketing Professionals Wanting to Improve Visibility on AI Search Platforms
While query fan-out is a sophisticated mechanism used in AI search, some of the inherent systems can lead to issues like intent drift. The transformations and deep personalization features may at times be helpful; at other times they may skew intent, or create a filter bubble, in which you don’t see a more complete picture of the information available on a given issue. Users lose visibility into what they’re not seeing, and the system has no external signal besides the contextual signals and the user prompt to correct course when it drifts, failing to stray vulnerable conversations away safely.
The mechanism has inherent vulnerabilities that can work against both users and publishers. Understanding these vulnerabilities is critical because they directly affect whether your content gets discovered and cited in AI-generated answers. So, to wrap up, let’s address the question of what this all means for marketers.
The Measurement Problem: Personalization Breaks Attribution
Early-day SEO relied on a single, stable metric – keyword rankings. We’ve later transitioned to tracking SERP snippets visibility, too, then came AI Overviews, and now – AI search systems and query fan-out breaks this model entirely.
The same query now expands differently for different users. A budget-conscious user searching for “electric vehicle charging” triggers subqueries around cost analysis, installation pricing, and affordability programs. An environmentally-focused user gets subqueries emphasizing carbon impact and renewable energy integration. A tech enthusiast gets infrastructure specs and charging speed comparisons. None of these users wrote different queries. The system personalized the expansion based on historical behavior.
Side note: This also happens, albeit to a lesser degree, in the way Google personalises featured snippets and content rankings to avoid showing the same user the same content twice, if they failed to click on it before in the same search sequence, path or session; or to make the appearance of a snippet like People Also Asked highly contextualised to the user profile of the searcher. I explore this in depth in this course.
You might rank first in one personalized expansion and not appear at all in another. Your visibility is no longer a single position you can track. It’s a distribution across dozens of personalized query variations, each with different retrieval sets and ranking orders.
Most SEO tools still measure success through keywords and rankings. That framework is now obsolete for AI search. Your content might be highly visible in one user’s personalized answer and completely.
The Intent Skew Problem: Right Content, Wrong Context
The bigger threat isn’t measurement. It’s that personalization can steer the system toward the user’s historical profile rather than their current, stated need.
When a user’s query doesn’t clearly signal a break from their historical pattern, the system continues inferring intent from past behavior. The intermediate transitions we discussed earlier get ignored. The system treats the current query as a variation within a stable intent, not as a signal that intent has shifted.
This creates a specific failure mode: The system might be discovering and recommending high-quality content that’s relevant to someone like that user, but not to that user right now. This can make trends of metrics like CTR from AI search appear more erratic, without a company ever making any changes to their strategy.
The Divergence Problem: When Iteration Expands Too Far
Some AI systems don’t just execute a single set of parallel subqueries, but use iterative expansion. The system retrieves initial results, extracts enrichment terms (entities, concepts, related keywords) from those results, and uses those terms to generate the next wave of queries.
On paper this sounds smart. If your first search finds documents about “EV charging,” you can extract related concepts like “battery technology,” “grid integration,” “renewable energy,” and “charging standards” from those documents. You use those extracted terms to generate follow-up queries, retrieving an even more comprehensive set.
But here’s the risk: The enrichment terms extracted from the first set of results may include concepts tangentially related to the user’s actual question, not directly relevant to it. You start with “charging infrastructure” and extract “supply chain resilience,” which leads to queries about manufacturing. Now you’re retrieving documents about battery production in China, which is technically related but increasingly distant from what the user asked about.
If this iterative expansion continues long enough without converging back toward the original intent, the system ends up retrieving more and more marginal documents. Later-stage queries drift so far from the user’s initial focus that the retrieved documents reflect the system’s exploratory path, not the user’s original question.
Some systems recognize divergence risk and set stopping criteria. They stop expanding if the ratio of novel (new) documents to repeated documents grows too high, signaling that iteration is yielding diminishing returns or divergence. But many systems continue until they hit arbitrary limits like “maximum 20 iterations,” by which point they may have drifted significantly.
What This Means for Your Content Strategy
These three problems compound. Personalization + iterative expansion + intermediate-transition blindness creates an environment where discoverability is unstable.
- You can’t rely on ranking for specific queries. The query itself expands and personalizes dynamically. Instead, you need to think about your content’s semantic coherence and retrievability across multiple expansion paths.
- You need to address intent transitions explicitly. Create content that acknowledges when users move from one need to another. If you’re writing about electric vehicles, don’t just cover performance specs. Cover the progression: research phase, decision phase, installation phase, long-term ownership. Users in different phases generate different queries, and your content should meet them at each point.
- Your content should be atomic and extractable. When the system uses enrichment terms from retrieved documents to generate follow-up queries, you want those terms to come from your content and lead to your pages, not to tangential competitors. Use clear semantic structure: define key concepts explicitly, link related ideas, use schema markup to disambiguate entities. This increases the odds that extraction from your content yields useful enrichment terms rather than semantic drift.
- Measurement needs to shift from rankings to citations and reasoning inclusion. Stop asking “What’s my rank?” Start asking “Am I being cited in AI-generated answers? How about in reasoning chains? For which entities and attributes? Why is content used as a source and not cited?” These metrics are harder to track with traditional tools, but they’re the only metrics that matter when ranking disappears.
- Build topical authority that spans user journey stages. Don’t just optimize for the final purchase or decision query. Create content for research, comparison, troubleshooting, and transition moments. When users move from “learning about X” to “implementing X” to “maintaining X,” your content should move with them. This reduces the odds that iteration and personalization will drag them toward competitors.
Query fan-out was designed to solve traditional search’s problems: single-query limitations, limited intent understanding, one-size-fits-all results. But in solving those problems, it introduced new ones: measurement opacity, filter bubbles, and divergent iteration.
You can’t control these systems. What you can control is how your content is structured and what it addresses. Make your content clear, atomic, and journey-aware. Build authority not just for individual keywords but for the transitions and connections between user needs. Track visibility through citations and entity mentions, not rankings.







