
Let’s be honest. The words “content audit” rarely spark joy. Especially when you’re staring down a legacy blog archive with thousands of articles accumulated over years. Traditional content pruning often feels like a necessary evil. It’s time-consuming, subjective, and heavily reliant on SEO metrics that don’t always tell the full story about strategic alignment.
You know the drill: pull traffic data, check rankings, glance at backlinks, maybe skim a few posts, and make your best guess. But how do you really know if that low-traffic article from 2018 is truly irrelevant, or just poorly positioned but semantically aligned with a core business priority? How do you scale this judgment across 1,000+ pages without losing your mind or your entire quarter?
At iPullRank, we faced this exact challenge. We needed a more intelligent, scalable, and strategically grounded way to audit and prune large content libraries. Our solution? Combining the power of AI-driven semantic relevance analysis with essential SEO and content metadata. This article walks you through a Relevance Engineering framework we developed. This isn’t just cleanup; it’s about sharpening your site’s overall semantic signal, the identity that search engines increasingly recognize, by cutting through the noise of irrelevant content.
Read Francine's Relevance Engineering primer
Key Takeaway:
We used Relevance Engineering to quantify strategic alignment across 1,000+ blog posts, cut 500+ underperformers, and lift sitewide semantic relevance by 2–3% — without guessing.
The Problem: Why Legacy Content Pruning Techniques Fall Short at Scale
So, why ditch the tried-and-true processes? Because frankly, for large sites, it’s often neither tried nor true enough. It crumbles under its own weight.
Anyone who’s spent weeks drowning in spreadsheets, manually mapping keywords, and trying to eyeball relevance across 800 blog posts knows the first issue: manual slogs just don’t scale.
It’s a resource black hole. You either burn out your team, rush the job, or sample so lightly you miss critical insights. The sheer volume makes comprehensive, thoughtful analysis almost impossible.
Then there’s the data trap. Relying solely on traffic, rankings, or even conversions can tell an incomplete story. Sure, that post from 2019 might get decent organic traffic, but is it attracting the right audience? Does it align with your current product positioning or ideal customer profile? Or is it just ranking for some tangential query, pulling in looky-loos who bounce immediately?
Search and organic visibility in general is changing (just ask Mike). Traffic doesn’t always equal value, and performance data alone overlooks strategic alignment. It also struggles to identify consolidation opportunities.
Worst of all is the subjectivity quagmire. What is “relevant,” really? Without an objective yardstick, it often comes down to gut feel, internal politics (“But the VP of Sales liked that post!”), or inconsistent judgment calls between team members or over time.
You end up with debates based on opinion, not data, about whether a piece truly supports core business topics. Trying to maintain consistency across thousands of articles this way? Good luck.
We needed a better way. Something faster, more objective, and capable of assessing meaning alongside performance.
Our Solution: Objective Relevance Scoring with Embeddings and SEO Reality
Faced with the scaling and subjectivity problems, we knew we needed a system that could blend semantic understanding with real-world performance data. The objective was clear: systematically identify content that genuinely aligns with the company’s core expertise and business goals, flag the rest for pruning or revision, and do it efficiently across a massive library.
Our approach hinges on a hybrid model. We don’t just use AI embeddings, and we don’t just look at SEO stats. We fuse them together. Here’s the gist:
- Ground Truth in Strategy: First, we defined the core topic areas the business actually cares about, directly linked to their products and target audience needs. Think of these as the strategic pillars for content.
- Quantify Meaning with Embeddings: We used AI to generate numerical representations (embeddings) for:
- Each core topic area (by creating a “topic centroid” from relevant keywords).
- The overall business relevance (embedding a concise statement of strategic focus).
- Every single blog article (combining title and main body content).
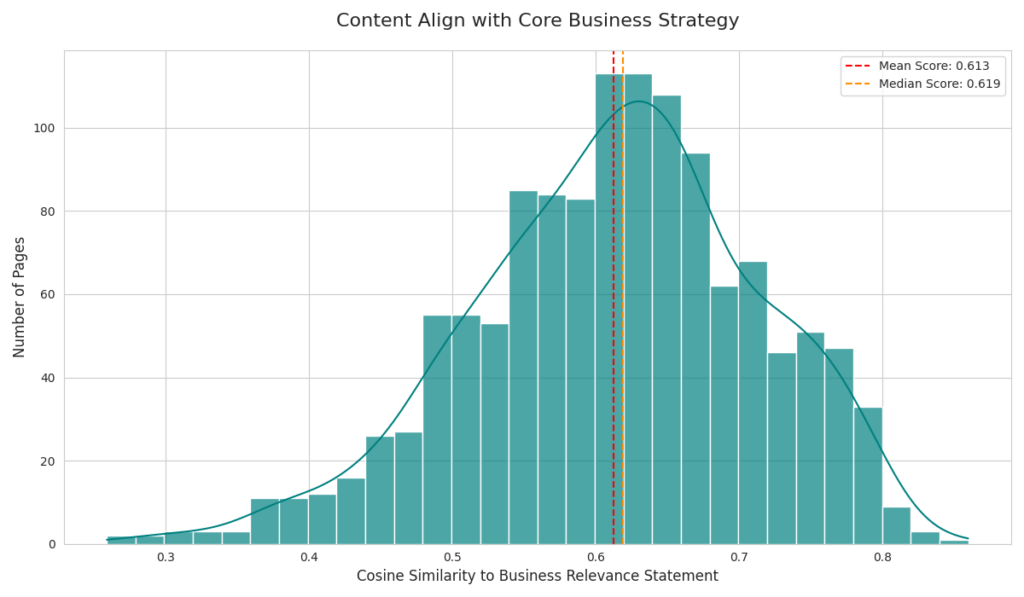
- Measure Alignment with Cosine Similarity: We then mathematically calculated the semantic “closeness” (cosine similarity) between each article’s embedding and the embeddings representing our core topics and business relevance. This gave us objective relevance scores for every post against every strategic pillar.
- Layer in Performance Reality: Relevance scores alone aren’t enough. We integrated key SEO performance metrics (like recent clicks from GSC) and crucial content metadata (publish and last updated dates).
- Make Data-Driven Decisions: Finally, we combined the semantic relevance scores, SEO data, and content age into a decision framework (our Kill / Keep / Review model) to categorize each piece of content logically and consistently.
This approach gives us a multi-dimensional view of each article’s value. With a quick glance, you could view an article’s semantic fit, its actual performance, and its freshness. This allows for much smarter, more defensible decisions at scale.
The Step-by-Step Workflow: How We Did It
All right, if you’ve made it this far, you’re ready to get into the weeds. Before diving into the individual steps, here’s a quick look at the toolkit we used for this project. Nothing too exotic, but having the right tools for crawling, data processing, embedding generation, and analysis is crucial.
To start, here are the tools we use and how we use them:
- Screaming Frog SEO Spider
For crawling the blog and extracting URLs, titles, and main article content via custom XPath. - Ollama (with mxbai-embed-large model)
Running a local embedding model gave us control and kept costs down for generating semantic embeddings at scale. You could substitute this with API-based models (OpenAI, Cohere, Voyage, etc.). - Python (Pandas, NumPy, Scikit-learn)
The workhorse for cleaning text, generating embeddings in batches, calculating cosine similarity, and merging various data sources. - Google Sheets
For final analysis, filtering, applying the decision framework, and tracking manual reviews. - GA4/Google Search Console
Source for essential SEO performance data (clicks, impressions, potential conversions).
With that out of the way, here’s how we executed each phase.
Read Mike’s deep dive on using vector embeddings with Screaming Frog
Step 1: Define Strategic Focus (The North Star)
You can’t measure relevance if you don’t know what you’re measuring against. This first step is critical and grounds the entire analysis in business reality, not just keyword vanity metrics.
- Why do this: To ensure the audit aligns with current product/service offerings, target markets, and strategic content goals. This prevents pruning content that is valuable, just not yet performing, and ensures the remaining content strongly supports the business.
- How we did it: We worked with the client to solidify their core solution areas. For this B2B SaaS provider, it boiled down to distinct categories based on their unique sales plays like ‘Media Management’. For each area, we developed representative keyword portfolios reflecting user intent and product capabilities. Crucially, we also drafted a concise business relevance statement (a short paragraph capturing the ideal focus and target audience for their content efforts going forward). This statement becomes its own benchmark later.
One of the first misalignments we spotted after this exercise? A whole series of posts about remote working tips and digital nomad life — timely during early COVID, but no longer aligned with the client’s current positioning in enterprise cloud infrastructure.
Step 2: Generate Topic & Business Relevance Centroids (Representing Meaning)
With the strategic pillars defined, we needed to translate them into a format the machines could understand: embeddings. The goal was to create a single, representative vector for each core topic cluster and for the overall business relevance.
- Why do this: These ‘centroid’ embeddings act as quantitative benchmarks for semantic relevance. Calculating similarity against these is far more objective than a human guessing “how relevant” a post is.
- How we did it: Using our chosen embedding model (Ollama with mxbai-embed-large, run locally for control and cost), we didn’t just embed the topic name. Instead:
- We generated an embedding for each individual keyword within a topic’s portfolio (from Step 1).
- We then calculated the average of all keyword embeddings within that cluster. This averaged vector became the topic centroid – a robust mathematical representation of the topic’s semantic space.
- We also generated a single embedding for the business relevance statement drafted in Step 1.
- (Tooling Note: Running a model locally, like with Ollama, is great for large jobs where API costs could skyrocket or where data privacy is paramount. API options are faster to set up if those aren’t concerns.)
Step 3: Generate Article Embeddings (Representing Each Post)
Now, we create a semantic vector for every single article in the library.
- Why do this: To represent the meaning of each article numerically, allowing for mathematical comparison against our topic centroids.
- How we did it: We ran the extracted content through some basic Python cleaning routines (removing excess whitespace, stray HTML tags missed by the crawl). Then, for each article, we added the Title text and the cleaned main body content and generated a single embedding using the same model (mxbai-embed-large) for consistency. These individual article embeddings were stored efficiently, typically in a NumPy array paired with their corresponding URLs.
Step 4: Calculate Similarity Scores (Measuring Alignment)
This is where the magic happens, comparing the meaning of each article to the meaning of our target topics.
- Why do this: To get an objective, numerical score quantifying how semantically aligned each article is with each core topic cluster and the overall business relevance statement.
- How we did it: Using Scikit-learn in Python, we calculated the cosine similarity between each article’s embedding (from Step 4) and each of the topic centroid embeddings (plus the business relevance embedding, all from Step 2). Cosine similarity is ideal here as it measures the orientation (i.e., topical direction) rather than magnitude of the vectors.
The output was essentially a matrix, added to our spreadsheet, showing each URL alongside columns like ‘Media Management Similarity‘, and ‘Business Relevance Similarity‘, with scores ranging from -1 to 1 (closer to 1 means more similar). For example, a blog post about free iPhone 4 wallpapers showed a very low cosine similarity score across every core topic — even though it had once performed decently in organic search. This quantifiable disconnect helped us move beyond “it once got traffic” and make a stronger case for pruning.
Step 5: Layer SEO Performance & Metadata (Adding Context)
Semantic relevance is powerful, but it lives in the real world. An article might be perfectly relevant but get zero traffic, or be ancient and outdated.
- Why do this: To provide the necessary business and performance context to the relevance scores. Pruning shouldn’t happen in a vacuum.
- How we did it: We pulled standard SEO metrics, primarily trailing 3-6 months of organic clicks from Google Search Console (using a recent window avoids rewarding historical performance that’s since decayed). We also pulled Publish Date and Last Modified Date from the CMS or crawl data. This performance and freshness data was then joined to our main spreadsheet containing the URLs and similarity scores. We now had a master file for analysis.
Step 6: Apply the Decision Framework (Making Informed Choices)
Mama, we made it. With all the data assembled, it was time to make the calls.
- Why do this: To translate the combined data points into clear, actionable categories for each article, guiding the pruning and optimization efforts.
- How we did it: We established data thresholds to categorize each article. This wasn’t purely algorithmic; it involved setting rules and then reviewing the output.
- KILL: Candidates typically had low similarity scores across all core topics, low recent GSC clicks, and were old (e.g., > 5 years with no significant updates). These offer little strategic or performance value.
- KEEP: Articles generally qualified if they had high similarity to at least one core topic OR had strong recent SEO performance, even if relevance was moderate. These are either strategically sound or proven performers.
- REVIEW/REVISE: This crucial category caught articles that were relevant but perhaps outdated, underperforming despite relevance, or highly similar to other posts (potential consolidation targets, like those >0.90 similarity). These need human judgment.
- Understandably, this process still included manual review. The automated categorization flagged candidates, but strategists reviewed edge cases, confirmed decisions, and identified specific actions (e.g., “redirect,” “update and repromote,” “consolidate into new pillar page”). High-relevance articles flagged for review due to age or performance became top priorities for content refresh efforts.
Okay, deep breath. That was the methodology. Now, let’s see if all that computational elbow grease actually moved the needle.
The Results: A Leaner, More Relevant Blog
So, did all that data wrangling and vector crunching pay off? For our client, the answer was a clear yes. The methodology provided the objective evidence needed to make significant, strategically sound changes.
Here’s a snapshot of the outcomes:
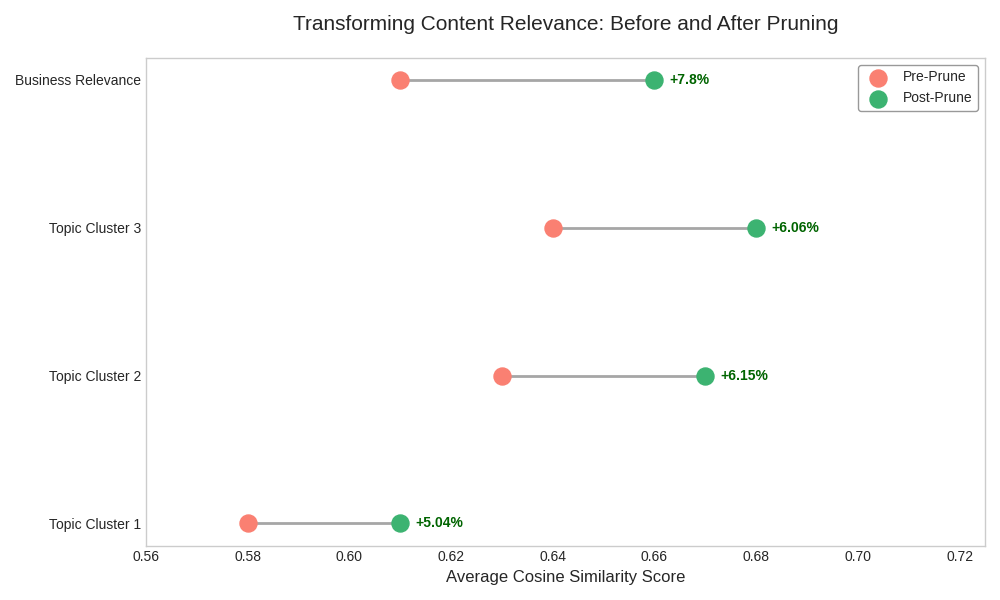
Quantifiable Lift in Overall Relevance: This was the headline metric. We went beyond individual page scores and actually measured the blog’s collective semantic alignment. By creating a single representative embedding for the entire blog’s content (think of it as a ‘mega embedding’) both before and after pruning, we could calculate the change in cosine similarity against the core business relevance target.
The result? A site-wide relevance lift of 2-3%. For a large, established content library, improving the overall semantic signal by that much is definitely nothing to sneeze at. It’s a direct measure of increased focus.
Significant Pruning Achieved: The analysis identified substantial deadweight. Based on the combined relevance, performance, and freshness scores, we flagged approximately 45% of the content library for pruning or consolidation. This meant strategically removing or redirecting over 500 articles that no longer served a purpose.
Foundation for Future Authority: The result is a more focused, coherent, and authoritative blog, better positioned to perform in search, resonate with the target audience, and drive meaningful business results. It established a cleaner baseline for future content development and topic cluster expansion.
This wasn’t about hitting a deletion target; it was about using a combination of semantic understanding and performance data to surgically refine the content library for maximum strategic impact.
How You Can Apply This Framework (And Why You Should)
This methodology isn’t just a one-off project; it’s a robust framework adaptable to several common strategic needs. Its real advantage lies in bringing objectivity and scalability to relevance assessment, moving beyond gut feelings and manual slogs. By integrating semantic analysis with concrete SEO data and content metadata, you get a holistic view of content value, ensuring decisions align with both search demand and business priorities.

Key Takeaways: Smarter Pruning, Stronger Strategy
Ultimately, tackling a sprawling content library requires more than just traffic analysis and gut instinct.
The core idea here is that AI-powered embeddings offer a genuinely scalable and objective way to measure semantic relevance, moving beyond subjective interpretations of what fits your strategy. However, relevance alone isn’t the full picture. True strategic content management emerges when you fuse that semantic understanding with concrete SEO performance data and content freshness, creating a holistic view of each asset’s real value and potential. Remember, this isn’t merely about deleting old pages; it’s about strategically focusing your content portfolio to sharpen your site’s overall thematic signal, making it clearer to both search engines and your target audience what you stand for.
Adopting this kind of data-driven, multi-faceted framework provides a defensible and far more effective approach to content audits and ongoing governance, especially when dealing with the complexities of large, legacy websites.







