
Context is king. Is this already a boring concept? I don’t think so. It’s critical for SEOs and marketers to weave into their professional genetics.
For the longest time—well, at least since Panda and Penguin, and most recently the Helpful Content Updates—Google has told SEOs, content managers, and content creators that content is king.
Two users type the identical query into AI Mode. They get different answers.
Not because of ranking changes, but because the questions the system asked on their behalf were different.
Different context leads to different fan-out leads to different data to compile into a response, which ultimately leads to a highly personalised view of the topic.

The fan-out queries generated for a developer with a code solution-focused search history searching “best productivity tips” will look nothing like those generated for a content marketer, with the same search, if the AI Search system can decipher between the two based on its collected data for the user. Same input, different context, different expansion, different results pool entirely.
AI Search systems use myriad mechanisms to incorporate user context into their responses, making interactions ever more personalized. As any reputable SEO will tell you, this type of personalization of search results has long been the case with traditional search engines—but not to the degree we’re seeing with AI Search. Longer queries, more information shared during interactions, and the very nature of the conversational interface mean these systems capture, store, and utilise more user-specific information than ever before to personalize the responses they give.
All of this operates alongside other mechanisms like fan-out, retrieval, and grounding. Yet arguably, the personalization piece is what no one is talking about—and it’s the piece that will undoubtedly break a ton of traditional SEO and content strategies, making the playbook of yesterday completely obsolete.
Here’s what this means in practice: if the system decides based on memory, context, and conversation that your brand is not relevant to the conversation with this particular user, your brand will not only fail to surface—it will simply not be part of the consideration set. The AI system won’t even ask the questions that would lead to your content, making your brand essentially invisible as an alternative for that user. Needless to say, that’s exactly what relevance engineering, technical branding, and other such newly emerging disciplines are aiming to tackle.
This dynamic might also explain a discrepancy SEOs have been noticing: why do some brands get used in grounding but never cited? I’m here to argue that more than the “chunking” explanation, this has to do with relevance to the user at that moment. The AI search system might use your content to inform its response—specifically those top-of-funnel articles, that in-depth evergreen content, those ultimate guides that are so knowledge-packed and authoritative and well-regarded. Yet it stops there. It determines that your brand is not the best or most relevant offering (think product, service, brand, positioning) to surface to this particular user based on the contextual information it has gathered about them.
As a result, other brands—ones you’ve dismissed as non-competitors due to their company or website size, price point, company revenue, or smaller organic (social or web) presence in the traditional Google-based traffic sense—resurface and capture leads. They do this simply because they communicated their offer in a more focused, structured way, and that offer is exactly what the user needs at this point in their journey.
This represents a fundamental shift in competitive dynamics. AI search systems allow smaller brands to compete with larger ones if their content and offer are communicated in a structured, entity-rich way. They can surface their brands to users for whom they’re highly relevant, bypassing the traditional ranking model based on links, domain authority, and traffic scale. Those signals aren’t irrelevant now—they’re just less decisive than they used to be.
What matters more is being the right answer for this user, based on everything the system knows about them.
In previous resources, we’ve already covered how query fan-out works and how it can skew search intent via semantic expansion. In this article, we’ll talk about how different AI search platforms implement personalized query fan-out—the mechanisms they use, the memory and context signals they incorporate, and what this means for content strategy, all illustrated via experiments and research on the platforms’ architecture and operational settings. The implications run deeper than measurement challenges or attribution headaches. If your content isn’t structured to surface across diverse user contexts, you’ll lose not only rankings and visibility but also your relevance to your audience. You’re being excluded from conversations you don’t even know are happening.
How Traditional Search Engines Personalize Results and Rankings to Individual users
Search engines like Google have long evolved well beyond simple keyword matching. They employ sophisticated algorithms that adapt results to the individual user. They analyze past user behavior, context, and preferences using signals like dwell time, clicks, and browsing history (to name a few) to re-rank what you see based on collected data about a user’s profile. Understanding these mechanisms is essential because AI search systems build on them while fundamentally changing where personalization happens and what information is used to personalize the response people see.
So, let’s review the key semantic signals that underpin the primary ways traditional search engines personalize results. All of these are based on patent filings by Google and other search engines and documented behavior by industry research and reports, summarised from my research for my course on semantic keyword research, where I’ve covered each facet extensively.
Session Context and Sequential Queries
Search engines don’t treat queries as isolated events. They analyze the sequence of interactions within a search session to infer context the user may have omitted.
Query refinement and carry-over context. If you search “what is the capital of France” and follow it with “popular tourist attractions,” Google uses context from the first query to automatically refine the second—you’ll get Paris attractions, not a generic global list.
Session history analysis. The engine tracks whether you’re refining a search or switching topics entirely. Semantically close queries get entered into an “established sequence,” allowing the system to build cumulative understanding of your intent.
Query augmentation. Based on your session behavior, Google triggers specific SERP features—”Related searches,” “People also ask”—to help you discover semantically related terms and refine your path. These aren’t random but personalized to the demonstrated trajectory of your query path and the inferred intent.
Historical User Behavior and Preferences
Google maintains long-term data profiles to re-rank results based on your demonstrated interests and past interactions.
Prioritizing previously clicked sources. Patents indicate that if you’ve previously clicked on specific results or domains for similar queries, Google may boost related items in future searches, assuming alignment with your preferences. For example, if you always click on articles from Forbes, when you search for listicles with a query, containing a term like “best”, then Google will surface results from this domain higher for you than for other people in your group; and they may overtime provide an overall ranking boost for this domain for this type of query.
Demoting redundant results. Conversely, if you’ve already viewed a document during a search session, Google may lower its rank in subsequent searches—assuming the repeat item is no longer useful and you need fresh options.
Autocomplete personalization. Predictive text uses a model based on both frequency and recency, prioritizing words you type frequently or have typed recently. Your autocomplete suggestions adapt to your unique language patterns over time.
Information Gain and Novelty
To prevent you from seeing repetitive content, Google employs Information Gain scoring that personalizes the value of search results based on what you’ve already viewed and the assumed knowledge you already have on this topic. This score is highly personalized to individual users.
Viewed vs. not viewed classification. Google classifies documents into those you’ve viewed and those you haven’t, then analyzes how much new value each document offers.
Scoring novelty. An information gain score measures how much additional useful information a webpage provides beyond what you’ve already seen on the topic. Two users researching the same subject will see different rankings based on their content consumption history.
Personalized ranking. Documents are presented based on these scores, prioritizing pages likely to provide the most new information specific to your knowledge level and session history.
Implicit User Feedback (Interaction Signals)
Search engines rely heavily on what patents refer to implicit user feedback, and that is behavioral data collected during the search process to facilitate engines to understand the relevance of different content pieces to a user and adjust rankings dynamically.
Click data and dwell time. Metrics like click-through rate, dwell time (how long you stay on a page), and long clicks (which are associated with engagement and content satisfaction) assess the quality and relevance of a result for you specifically.
Mouse and scroll patterns. Google tracks mouse hover behavior to predict interest levels, scrolling patterns, and “read interactions” to understand engagement with specific parts of a page.
Pogo-sticking detection. Rapidly returning to search results signals dissatisfaction. This behavior can cause Google to demote that result for you or for similar queries from users who match your profile and search history.
Cohort Analysis (Similar Users)
Personalization isn’t limited to your individual data. Insights are leveraged on user behaviour and scaled to the rankings of groups of similar users to help Google predict content relevance and optimal SERP performance.
Group-based re-ranking. Results can be ordered based on relevance to similar users. If a specific result is popular among users with search patterns, contextual information or demographics matching yours, it may be boosted for you also.
Contextual patterns. The system compares your current query to trends from users in your cohort, adjusting results based on what that group found useful.
Environmental and Device Context
Your physical and technological context significantly shapes results.
Location awareness. Since as early as 2003, Google has used location data to localize results. Queries with physical intent—like “popular attractions” or “restaurants nearby”—prioritize geographically relevant options, or are adjusted based on geographic locations, mentioned in the query sequence.
Device-specific ranking. Google infers different intent based on whether you’re on mobile or desktop. Mobile users scroll differently, tap differently, and often have different urgency. Rankings adapt accordingly.
Temporal context. Time of day influences intent interpretation. Searching “breakfast” at 7am versus 10pm likely signals different needs.
Entity and Knowledge Graph Personalization
Google uses its Knowledge Graph to disambiguate terms and tailor results to entities you’ve previously engaged with.
Personalized knowledge graphs. Patents suggest Google maintains “user-specific knowledge graphs” to support queries and predictions, particularly in voice and mobile searches. Your search history shapes which entity associations the system prioritizes.
Entity disambiguation. If a query references an entity with multiple meanings (e.g. the query “London” could refer to London, in the UK, or London in the US), the system uses your past behavior (e.g. whether you’ve searched for flights to the UK or US recently) and current context (like location, which is highly relevant to a geographic query) to decide which entity panel to display.
To summarise, here are just some of the signals used by traditional search engines to personalize the results you see.
Signal Type | What Google Tracks | How It Affects Rankings |
Session context | Query sequence, refinements, topic switches | Carries context forward, triggers relevant SERP features |
Historical behavior | Past clicks, domain preferences, viewed documents | Boosts familiar sources, demotes already-seen content |
Information gain | Content you’ve consumed on a topic | Prioritizes novelty based on your knowledge level |
Implicit feedback | CTR, dwell time, scroll depth, pogo-sticking | Dynamically adjusts relevance scores |
Cohort signals | Behavior of similar users | Boosts results popular with your demographic/pattern group |
Environmental context | Location, device, time of day | Localizes results, adapts to device-specific behavior |
Entity associations | Your Knowledge Graph interactions | Disambiguates entities based on your history |
All of these mechanisms operate on the ranking of results. Google retrieves a candidate set based on your query, then re-ranks that set based on personalization signals. The query itself—the question being asked—remains stable across users.
This changes with AI Search.
The Shift from Traditional Search to AI Search: From Personalized Rankings to Personalized Queries
Traditional search personalization operates downstream. Google retrieves a candidate set of results based on your query, then re-ranks that set using the signals we just covered. The query itself remains constant across users. A marathon runner and a casual jogger typing “best running shoes” trigger the same retrieval. They just see those results in different order.
AI search systems move personalization upstream into the query generation process itself.
Meaning, when you submit a query to AI Mode, ChatGPT, or Perplexity, the system doesn’t just search for what you typed. It expands your query into dozens of sub-queries through fan-out, retrieves information across those expansions, then synthesizes a response. The key shift is that those fan-out queries (the semantic expansion) are themselves shaped by what the system knows about you.
Going back to our example from the beginning of two users that indicate an intent to prepare for a marathon, and both searching for “best running shoes”.
The runner, located in an urban area, whose search history and context signals indicate years of experience, might trigger this fan-out:
- “marathon running shoes cushioning high mileage”
- “marathon running shoes carbon plate”
- “best road running shoes for experienced runners 2025”
- “lightweight racing flats urban marathon sub-4 hour”
- “running shoes durability concrete asphalt long distance”
- “carbon plate marathon shoes city running performance”
In contrast, if the search is coming from a beginner preparing for their first marathon, located in the outskirts near trails where they’ve been doing their training runs, might trigger something entirely different:
- “marathon training shoes for beginners mixed terrain”
- “trail to road running shoes for new marathoners”
- “cushioned shoes for long distance beginners dirt paths”
- “Long distance running trail training for beginners”
- “durable running shoes for marathon prep unpaved surfaces”
- “Marathon race shoes for unpaved gravel/packed dirt”
Same input query. Same goal—preparing for a marathon. Different contexts. Different questions asked on behalf of each user. Different documents retrieved. Different brands, products, and recommendations synthesized into the response.
The first user might see performance-focused road options like Nike’s Alphafly, Asics Metaspeed, and Saucony Endorphin Pro. The second might see versatile or trail-oriented recommendations from Hoka, Brooks, and Salomon—shoes that handle the mixed terrain of their actual training environment. Neither user specified their experience level, their terrain, or their training context. The system inferres and builds the entire query expansion around those inferences, which it retrieves from past interactions, memory and context.
This is not a subtle distinction. When personalization affects ranking, you’re competing for a position within a stable results set. When personalization affects query generation, you’re competing for inclusion in the query set, and then a citation. Your content might perfectly answer one user’s personalized fan-out and be completely invisible to another’s—not because it ranked poorly, but because the system never asked a question that would surface it.
A brand like Salomon, traditionally seen as a trail running specialist, suddenly competes for marathon-prep queries—but only for users whose context suggests trail-based training. Meanwhile, a road running brand with comprehensive marathon content might never surface for that same user, despite having objectively a higher-reviewed marathon expertise, because the fan-out queries never ventured into pure road running territory.
What does this mean for SEOs, in practice:
- For measurement: You can’t track a “ranking” when there’s no stable query to rank for. Your visibility becomes a distribution across user contexts, not a position.
- For competitive analysis: Brands you’ve dismissed as non-competitors might be capturing users whose personalized fan-outs align with their focused positioning—while your broader content gets retrieved for context but never surfaced as a recommendation.
- For content strategy: Keyword-based optimisation of content becomes insufficient. You need to optimize for the range of questions that different user contexts might generate around your topic. Think persona-based semantic topic clusters.
There are differences in how each AI search platform implements fan-out and how they incorporate user memory and context. Let’s dive into the different platforms’ documentation and related patents.
How Different AI Search Systems Personalize Fan-Out Queries Using Memory and Context
The Technical Foundation: How Context Becomes Query
Before diving into platform specifics, it’s worth laying down the basic machine learning technologies that make fan-outs possible. At the core is the Retrieval-Augmented Generation (RAG) pipeline. When a query is submitted, the system doesn’t pattern-match against an index like traditional search, but instead transforms your query—and everything it knows about the user—into numerical representations called vector embeddings. These embeddings exist in a multidimensional mathematical space where concepts judged to be semantically similar cluster together. Simply put, terms like “running”, “marathon”, and “sprint training” will sit close to each other in this space, even though they share no words.
The retrieval mechanism then transforms your query into an embedding and searches the knowledge base for similar embeddings using semantic vector search. When it finds matches, it retrieves the related content, converts it back to human-readable text, and passes it to the language model for synthesis. Modern systems use hybrid search—combining semantic search with dense vectors and lexical search with sparse vectors—to handle cases where users don’t always use the same language to talk about a topic.
Here’s where personalization enters the picture. Google’s patent User Embedding Models for Personalization reveals how AI Mode incorporates user-specific context embeddings to personalize how queries are interpreted and answered. Your search history, your location, your device, your past interactions—all of these get encoded into embeddings that modify how your query is understood before retrieval even begins.
Another one of Google’s patents, Thematic Search describes how a single query can result in multiple sub-queries based on “sub-themes,” where the system generates narrower themes from responsive documents. Their patent on generating query variants outlines a system that leverages trained generative models to create query variants in real time (the fan-out). And in another filing, they describe their system using large language models to generate synthetic query-document pairs that improve retrieval coverage.
The combined effect of all these systems operating in tandem leads to context shaping the questions asked by the system at the beginning, instead of (as in the case of traditional search) filtering out and ranking the results at the end. The query-fan-out process is not generic but tailored to individual user contexts, driven by search history, interests, past interactions, inferred location, device type, and many more factors. Follow-up questions aren’t the same for everyone. They’re deeply contextual, stochastic, and impossible to predict deterministically, or to track and measure at scale (but more on this later).
This is the problem for marketers: Your content either fits the personalized query expansion for a given user, or it doesn’t exist in their consideration set.
The Spectrum of Inference Depth
On top of this, the unique architecture of models of different AI Search platforms differ. Not all AI search platforms personalize to the same degree. They sit on a spectrum from “only knows what you explicitly tell it” to “infers from your entire digital footprint.”
Understanding where each platform sits on this spectrum matters because it determines how much of your content strategy you can control versus how much depends on user contexts you’ll never see.
Platform | Inference Depth | Primary Data Sources | Fan-Out Visibility |
Perplexity | Shallow | Session context, explicit memories | High (Pro Search shows sub-queries) |
Claude | Moderate | Saved memories, chat history, profile preferences, project instructions | Low-Moderate (shows search query and results, not memory influence) |
ChatGPT | Moderate | Saved memories, chat history patterns, session metadata | Low (query rewriting invisible) |
Gemini | Deep (if enabled) | Gmail, Photos, YouTube, Search history, Workspace | Low (expansion not shown) |
Copilot | Deepest | Full Microsoft 365 Graph—Teams, Outlook, OneDrive, Calendar | Low (grounding in preprocessing) |
The further right you go on this spectrum, the more the system knows about users even when the information is implicit (unsaid, i.e. not mentioned in prompts or searches). Meaning, for platforms like Gemini (once integrated in Workspace) and Copilot, more context is inferred rather than stated.
That said, let’s examine each platform’s approach to memory and personalization.
Perplexity: The Transparent, Session-Based Approach
Perplexity sits at the shallow end of the inference spectrum—and that’s a deliberate architectural choice, not a limitation.
What It Knows About You
Perplexity doesn’t maintain long-term persistent memory like ChatGPT’s saved facts or Gemini’s cross-product grounding. Instead, it uses session memory—temporary retention within the active thread that resets when you start a new chat. You get a clean slate with every new conversation.
That said, Perplexity does store “memories”, which it refers to as preferences, interests, and information you explicitly share that help it give more informed responses. They incorporated an upgraded personalization system that automatically synthesizes information, providing context for relevant tasks without requiring users to manually summarize details. The key word is explicitly. Perplexity only knows what you’ve told it within Perplexity itself. It won’t infer your running habits from your email or your dietary preferences from your photo library. If you haven’t said it, it doesn’t know it.
How It Uses That Knowledge
Rather than treating conversation history as training data, Perplexity retrieves relevant context from your memory store and uses it directly in crafting queries. The system calls on memory and previous searches depending on the question, especially when it determines that context would improve the response for the user.
Let’s illustrate this with an example. If you share in one chat your running goal (e.g. training for a half-marathon), your weekly running habits, and other information.
Experiment: Perplexity context inference from one chat to another, influencing the direction of search
Chat 1, establishing context |

Chat 2, no explicit details mention, information inferred and direction of search decided by the system |
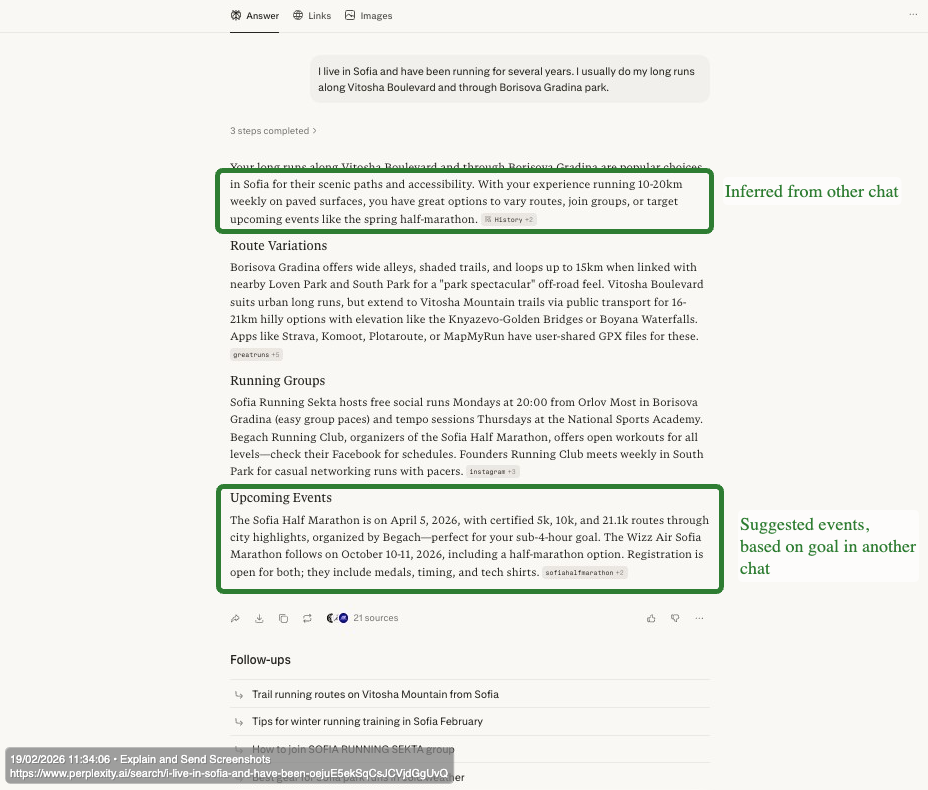
Perplexity’s technical infrastructure reflects this approach. Built on Vespa.ai, it integrates retrieval, ranking, and machine learning inference in a single low-latency pipeline. The system relies heavily on vector searches, representing queries and documents as numerical vectors based on semantic meaning rather than exact keywords. This allows it to compare intent, context, and conceptual similarity across large volumes of live web data.
What This Means for Content Visibility
Perplexity’s transparency is its distinguishing feature. Pro Search shows its query steps visibly, letting you see how your query is being expanded and refined. This makes the personalization and fan-out more observable than any other platform.
For content strategists, this creates both opportunity and constraint. The opportunity: you can actually see what sub-queries are being generated, which means you can reverse-engineer what content gaps exist. The constraint: with limited personalization depth, Perplexity’s expansions tend toward the generic. Two new users to the platform with very different contexts might get similar fan-outs because Perplexity simply doesn’t know enough about either of them to differentiate.
ChatGPT: Explicit Facts Plus Pattern Inference
ChatGPT occupies the middle ground as it remembers what you tell it, and it draws inferences from patterns in your conversations. This creates a more personalized experience than Perplexity without requiring access to your broader digital life.
What It Knows About You
ChatGPT’s memory system is a multi-layered architecture. In order of priority: system instructions, developer instructions, session metadata (ephemeral), user memory (long-term facts), recent conversation summaries, current session messages, and your latest message.
Contrary to what many assume, ChatGPT doesn’t use complex vector databases or RAG over conversation history. It takes a simpler approach: lightweight summaries and explicit facts stored long-term. Session metadata (things like the browsing system, device type, subscription tier, usage model preferred, geo data) gets injected once at the beginning of a conversation. Explicit facts you’ve shared (“I’m training for my first marathon,” “I live near hiking trails,” “I prefer budget options”) persist across sessions.
Memory works in two distinct ways: saved memories that you’ve explicitly asked ChatGPT to remember, and chat history that are automatically-collected insights, gathered from past conversations to improve future ones. Plus and Pro accounts have access to both features; free accounts are limited to saved memories only.
This is an important distinction. Saved memories are things you’ve deliberately told it to retain. Chat history insights are patterns the system has noticed—you frequently ask about Python, you tend to prefer detailed explanations, you often follow up with implementation questions. You didn’t ask it to remember these things. It inferred them.
How It Uses That Knowledge
When Memory with Search is enabled and you submit a query requiring web search, ChatGPT rewrites that query into a search query that leverages relevant information from memories.
OpenAI provides a concrete example in their documentation: for a user that ChatGPT knows from memory is vegan and lives in San Francisco, the query “what are some restaurants near me that I’d like” gets rewritten as “good vegan restaurants, San Francisco.”
So, the user doesn’t need to mention again that they are vegan or that they are located in San Francisco. These are automatically injected in the fan-out based on stored context. The fan-out queries that follow will all carry these constraints, rather than generalised searches.
Applied to our marathon training example: if ChatGPT’s memory contains facts like “training for first marathon,” “runs primarily on trails near home,” and “budget-conscious,” the query “best running shoes” gets expanded with all different related constraints shaping the sub-queries. This means that contrary to traditional search, where the user types three words and gets search results for those, in AI search, the system adds in stored context and searches for different implicit modifiers, inferred from past conversations.
So, let’s visually see what happens when you don’t toggle memory and chat reference.
Experiment: ChatGPT memory persistence—same query before and after session close, with and without memory enabled
What happens when memory is not enabled. |
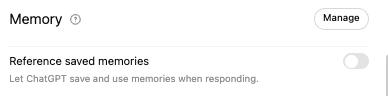
Chat 1 – Establish context |

Chat 2 (in different session) – Establish boundary, no further context shared
System only takes in information like user location, no context data from other chats.

What happens if memory is enabled, and past chats are referenced. |
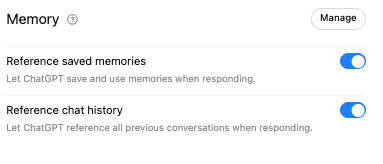
Chat 2 (different session) – This time the system references items from other conversations, even if they are not mentioned in the prompt |

What This Means for Content Visibility
ChatGPT’s moderate inference depth creates a specific challenge: your content surfaces when it matches not just the explicit query, but the constellation of stored facts and inferred patterns that shape the expansion. The more a user interacts with an AI system like ChatGPT or Claude, the more specific its recommendations and more personalized the fan-outs will be. Niche searches that previously were dismissed as ‘zero volume’ when building a strategy can now form a stronger foundation, especially if they are aligned with the ideal customer profile.
A running shoe brand with comprehensive marathon content might still miss users whose ChatGPT memory indicates “budget-conscious” if their content emphasizes premium performance over value. The brand never knew budget was a constraint. The user never mentioned it in this session. But the fan-out queries all included it, and content that didn’t address affordability never entered the retrieval set. This means that user research should now be a key first step in content planning – know exactly why people select your brand; then also knowing the same for competitors if a strategic pivot to a new market is the desired brand trajectory. Specificity in the discussion of features, brand and product attributes, and entity facets becomes an asset rather than a limitation.
Claude: Transparent Architecture, Similar Depth
Claude occupies similar territory to ChatGPT on the inference spectrum—moderate depth, relying on explicit user statements and conversation patterns rather than cross-product inference, yet some architectural choices create meaningful differences.
What It Knows About You
Claude’s memory system uses a file-based approach, storing context in Markdown files rather than complex vector databases. Memory works through several layers: saved memories you’ve explicitly requested, chat history insights the system gathers from conversation patterns, profile preferences you set at the account level, and project-specific instructions that stay contained within individual workspaces.
The key distinction is opt-in design. Unlike ChatGPT where memory defaults to on for paid users, Claude requires explicit activation. This is in alignment with Anthropic’s safety-first philosophy—the AI doesn’t build a profile unless you want it to. You can also search in incognito mode, once this is activated, to exclude chats from resurfacing.

This functionality allows users to view exactly what Claude remembers, and edit it through natural language.
How It Uses That Knowledge
When you submit a query requiring web search, Claude generates a targeted search query that may incorporate your stored context. The system uses Brave Search as its backend—not Google or Bing—which has direct implications for content visibility – if your content is not indexed on Brave, you won’t appear for Claude users. This is really significant as Anthropic’s users are growing faster than ChatGPT or Perplexity’s, and if your audience is technical and primarily using desktop (which is the core for Anthropic), it’s worth appearing there. Your content must be indexed in Brave to appear in Claude’s responses.
Claude can also search your past conversation history to find relevant context for current queries. Ask what you discussed last week, and it will search, retrieve relevant conversations, and weave that context into its response in a new chat. But this is retrieval on demand, not persistent profile-building.
What This Means for Content Visibility
Claude’s transparency is higher than ChatGPT’s but lower than Perplexity’s. When web search triggers, you see the search query generated and the results retrieved—you can observe what Claude found. But you don’t see how your memory or profile preferences shaped that query in the first place. The personalization influence remains partially hidden.
The Brave Search backend creates a distinct optimization path. Research confirms 86.7% overlap between Claude’s cited results and Brave’s top organic results, which is a far higher alignment than ChatGPT shows with Bing or Google. For content strategists, this means Claude visibility is effectively Brave visibility.
Project-based memory separation also matters for enterprise use cases. Claude maintains distinct memories for different projects, creating boundaries that prevent work context from bleeding into personal conversations or vice versa. For organizations managing multiple client engagements or sensitive workstreams, this architectural choice provides compliance-friendly containment that ChatGPT’s unified memory doesn’t offer.
Gemini: Cross-Product Context and the Inference Depth Advantage
Gemini represents a significant jump in inference depth. It can know things about you that you’ve never explicitly stated to any AI system because it has access to your broader Google footprint.
What It Knows About You
Google calls this capability Personal Intelligence, allowing users to securely (I’ll let you be the judge of the accuracy of this claim, given reports of breached Google Calendar data, Gmail summary data, and many more you can discover across forums) connect information from apps like Gmail, Google Photos, YouTube, and Search to make Gemini contextually aware. These permissions allow Gemini to have omni-channel reasoning by retrieving details from documents, emails, photos, web searches, Maps, and more.
The memory structure consolidates everything into one primary artifact: a structured user_context document plus a rolling window of recent messages. Architecturally simpler than ChatGPT’s and Claude’s layered memory approach, but potentially far more comprehensive given the data points from Google services feeding into it. Some researchers have demonstrated that unless the user prompts Gemini to use this, either via Personal Intelligence or otherwise, the system prompt includes a master rule stating “DO NOT USE USER DATA” with information in the user_context block that prohibits this context document being used by default.
Gemini’s has a competitive advantage of being able to store up to one million tokens when Workspace memory is integrated. For enterprise users on Gemini Enterprise, the system builds personal memory by understanding individual needs and work patterns, extracting insights from connected applications like Micrt other content, but against every signal in a user’s Google footprint that might shape what questions get asked.
Going back to our marathon example: a road running brand with excellent marathon content might be invisible to users whose context and preferences reveal trail running habits. The strategic implication: content that explicitly addresses the intersections—”trail running shoes for marathon training” and “transitioning from trails to road for race day”—becomes more valuable. This shifts content engineering from query-based, into semantic overlap between a topic, its forming entities and attributes, and contextual signals that might shape fan-out queries.osoft Outlook and OneDrive.
In practice. A user whose Gmail contains marathon registration confirmations, whose Google Photos includes images from trail runs, whose YouTube history shows beginner running form tutorials, and whose recent Google searches include “how to prevent blisters on long runs” provides Gemini with rich contextual signals—even if they’ve never explicitly told the system anything about their running habits.
Gemini can infer: this person is preparing for a marathon, they train on trails, they’re relatively new to distance running, and they’re dealing with practical training challenges. All from behavioral signals across products, not from explicit statements.
How It Uses That Knowledge
This context flows into query expansion. When that user searches “best running shoes” Gemini’s fan-out can incorporate inferences from across their entire Google footprint:
- Marathon prep signals can lead to queries about durability and long-distance cushioning
- Trail running photos can lead to queries about grip and terrain versatility
- Beginner tutorial history can lead to queries about shoes for new runners, injury prevention
- Injury-related searches can lead to queries about fit, break-in periods, sock compatibility
None of these constraints came from the user’s three-word query. All emerged from cross-product inference.
Google states that Gemini doesn’t train directly on your Gmail inbox or Photos library. It trains on limited information like specific prompts and responses, only after filtering or obfuscating personal data. The inference happens at query time, not training time.
For marketers, this means Gemini’s personalization is permission-gated but extremely deep when enabled. Users who’ve connected their Google services and permitted personalization will experience highly differentiated fan-outs. Users who haven’t will get something closer to Perplexity’s generic expansions.
When it comes to AI Mode, you’ll see when it’s bringing in your personal context—this transparency is built in. With Personal Intelligence enabled, AI Mode can also reference email confirmations, travel bookings, photo memories, past restaurant reservations, and flight details to inform responses. But the practical effect is that the fan-out queries themselves incorporate constraints you never typed, derived from signals across your Google footprint.
Google’s example: searching “things to do in Nashville this weekend with friends, we’re big foodies who like music” ahead of a trip. AI Mode shows restaurants with outdoor seating based on your past bookings and searches, suggests events near where you’re staying based on flight and hotel confirmations from your Gmail.
What This Means for Content Visibility
Gemini’s inference depth creates the starkest version of the visibility challenge outlined in this article. Your content competes not just agains
Copilot: Enterprise-Depth Integration
Copilot represents the deepest inference on the spectrum, or otherwise full personalization capabilities but only for enterprise contexts within the Microsoft 365 ecosystem. Consumer Copilot experiences are more limited.
What It Knows About You
Copilot operates entirely within the Microsoft 365 service boundary, built on Microsoft Graph as its neural network foundation. This is the deepest enterprise integration of any AI search system, with Microsoft 365 users feeding data into Copilot from Outlook, Teams, OneDrive, Sharepoint, and planner tools.
Users interact with Copilot through a sophisticated data flow: preprocessing prompts through “grounding” to add user-specific context from Graph, sending the enriched prompt to the Large Language Model, and storing relevant information when clear intent to remember is detected.
Copilot has two main personalization features:
- Copilot Memory automatically picks up important details from conversations—”I prefer Python for data science,” “Our Q3 deadline is October 15th,” “The Johnson account is our top priority.”
- Custom Instructions let users explicitly tell Copilot how they want it to behave—”Keep my emails concise,” “Always format code with comments,” “Remind me about follow-ups.”
Communication memory creates a unified view across channels. To provide a more personalized experience, Microsoft uses a user’s private communication data connected to Microsoft 365, such as Teams chats, Outlook emails, and transcripts, with this data used solely to make the individual user’s tools more efficient and personalized. Meaning, a Teams chat can help inform the suggested draft for an email.
How It Uses That Knowledge
For enterprise users, this creates the most comprehensive personalization available. When you search for information through Copilot, it doesn’t just know what you’ve explicitly told it. It knows your meeting schedule, your email threads, your document history, your Teams conversations.
Consider a product manager searching “competitive analysis framework.” Copilot’s fan-out might incorporate:
- The specific competitors mentioned in recent email threads
- The analysis format used in documents they’ve created before
- The stakeholders they typically share such analyses with (shaping audience assumptions)
- Deadline pressure based on calendar context (affecting depth vs. speed tradeoffs)
- Previous competitive analyses in their OneDrive (for consistency)
The query “competitive analysis framework” becomes something far more specific: competitive analysis framework for [these competitors] in [this format] for [these stakeholders] by [this deadline] building on [this previous work]. Five words became a deeply contextualized information need.
Data Storage and Compliance
Storage architecture ensures data sovereignty: memory data resides in hidden folders within users’ Exchange Online mailboxes, maintaining the same security and compliance posture as email. For enterprises, this matters as it means that Copilot’s personalization stays within the compliance boundary they’ve already established, and minimises the risk of breaches.
Enhanced personalization is turned on by default but can be controlled by admins. Microsoft uses private communication data solely to make the individual user’s tools more efficient and personalized, not for broader model training, which again is crucial for enterprise use.
What This Means for Content Visibility
For consumer searches, Copilot behaves more like ChatGPT, but for enterprise users within Microsoft 365, visibility depends heavily on how your content relates to their specific work context.
This can be pivotal to B2B content strategies. If you know your audience is using Microsoft 365 and Copilot, generic thought leadership may lose to internal knowledge that Copilot surfaces from their own files.
In this context, content that explicitly bridges external expertise with internal application becomes more valuable than generic explanations. Consider the difference between the titles “Agile Sprint Planning Explained” and “How to Adapt Agile Sprint Planning for Marketing Teams Managing Campaign Launches on a Tight Deadline”. The second piece speaks directly to a user whose Copilot context reveals they work in marketing, have upcoming Black Friday campaign deadlines in their calendar, and have Teams conversations about sprint capacity. When that user searches “sprint planning best practices,” Copilot’s fan-out queries will likely include modifiers like “marketing,” “campaign,” and “non-engineering teams”—because that’s the context it’s working with.
Experiment: Same query across three platforms – Perplexity, ChatGPT, Gemini, showing different responses, inference depth, response architecture, fan-out transparency, and source citing.
Platform |
Example |
Perplexity |
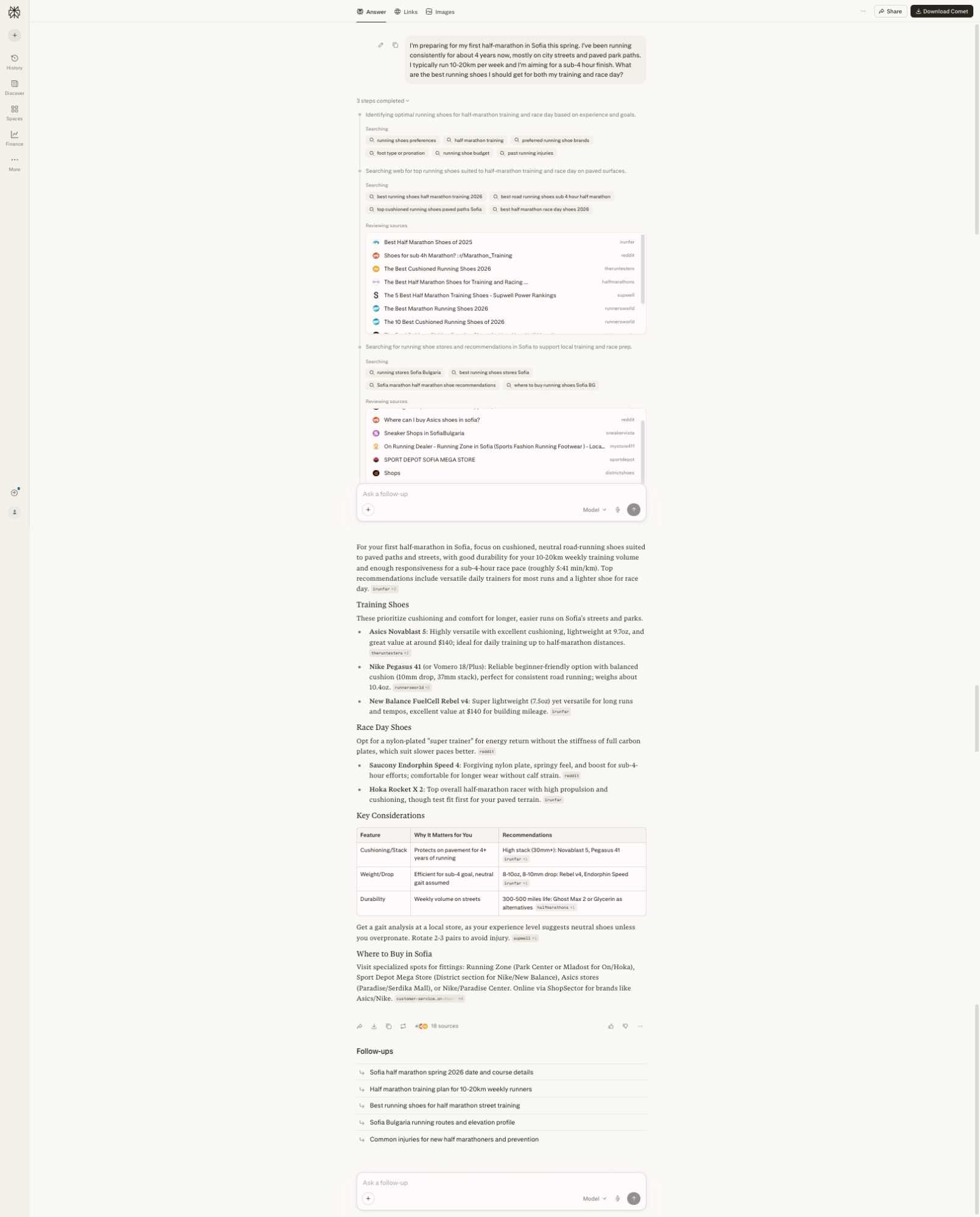
ChatGPT

Gemini
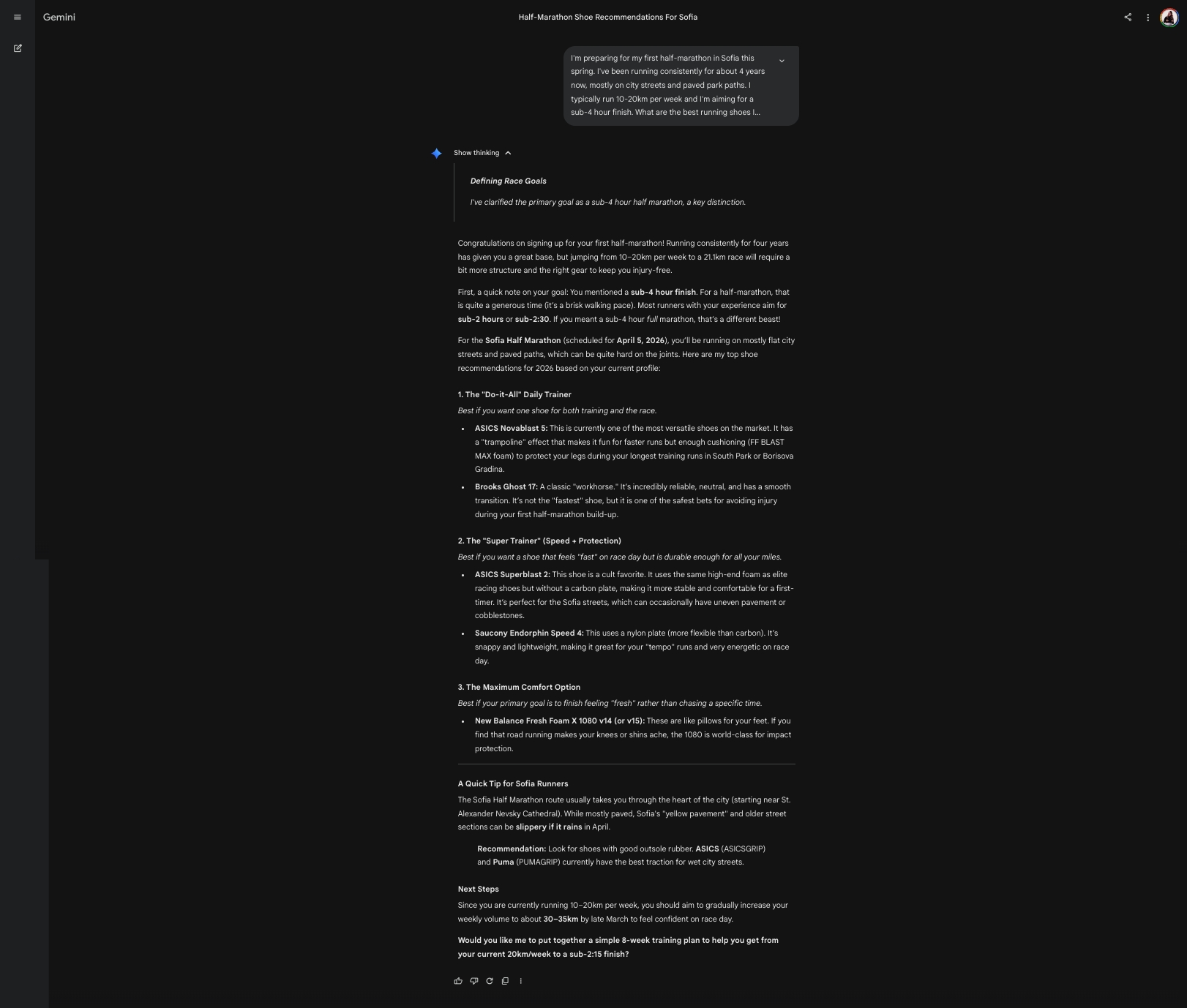
Fan-Out Transparency | High — Shows 3 distinct search steps with visible sub-queries: “running shoes preferences,” “half marathon training,” “preferred running shoe brands,” “foot type or pronation,” “running shoe budget,” “past running injuries,” then “best running shoes half marathon training 2026,” “best road running shoes sub-4 hour half-marathon,” “top cushioned running shoes paved paths Sofia,” followed by local store searches | High – Low in main response, High in Activity panel — Main response shows only “Thought for 1m 1s,” but Activity panel reveals extensive reasoning: “Looking into Sofia’s running shoe options,” query adjustments (without specific fan-out queries, though), troubleshooting product search issues, splitting queries for daily trainers vs race shoes. Shows iterative search refinement process, shows a list of 60+ sources used with links. | Low — “Show thinking” expandable section reveals reasoning (“Defining Race Goals: I’ve clarified the primary goal as a sub-4 hour half marathon”) |
Inference Depth | Moderate — Infers need for cushioned neutral shoes, durability for street running, sub-4 pace requirements; adds local store recommendations in Sofia without being asked | Moderate-High — Infers experience level, corrects the sub-4 hour goal assumption (notes this is generous for half-marathon), suggests training volume increase to 30-35km/week; asks follow-up about easy-run pace and pronation | High — Corrects sub-4 hour assumption (“that is quite a generous time—it’s a brisk walking pace”), infers Sofia Half Marathon date (April 5, 2026), references specific Sofia locations (South Park, Borisova Gradina), notes Sofia’s “yellow pavement” and cobblestones |
Response Architecture | Structured with clear sections: Training Shoes, Race Day Shoes, Key Considerations (table format), Where to Buy in Sofia; includes Follow-ups suggestions | Structured with numbered categories: “Do-it-All” Daily Trainer, “Super Trainer” (Speed + Protection), Maximum Comfort Option; includes decision framework (“How to choose between these three quickly”) | Structured with numbered options but more conversational; includes Quick Tip for Sofia Runners, Next Steps with specific training advice; ends with proactive offer to create 8-week training plan |
Personalization Signals Used | Location (Sofia), experience level (4 years), terrain (city streets/paved paths), weekly mileage (10-20km), goal pace (sub-4); proactively adds local retail options | Location (Sofia), experience level, terrain (road), weekly mileage, goal pace; proactively suggests increasing training volume | Location (Sofia), experience level, terrain, weekly mileage, goal pace; adds race-specific context (actual race date, course details, weather considerations for April) |
Source Citing | Explicit — Lists 18 sources with domain names visible (runrepeat, reddit, therundown, halfmarathons, topwell, runnersworld); sources shown inline with recommendations | Hidden depth — Activity panel shows 60+ sources consulted (realsimple.com, instyle.com, t3.com, brooksrunning.com, and “19 more” across multiple search iterations), but final response surfaces only 2-3 inline citations (e.g., “Brooks Running +1”). Extensive research happens invisibly | None visible — No explicit source citations in the response, no query fan-out process shared anywhere |
Brands Recommended | Training: ASICS Novablast 5, Nike Pegasus 41, New Balance FuelCell Rebel v4; Race Day: Saucony Endorphin Speed 4, Hoka Rocket X 2 | Training: Brooks Ghost 17, ASICS Novablast 5, Hoka Clifton 10; Race: Saucony Endorphin Speed 5, adidas Adizero Adios Pro 3 | Training: ASICS Novablast 5, Brooks Ghost 17; Race: ASICS Superblast 2, Saucony Endorphin Speed 4; Comfort: New Balance Fresh Foam X 1080 v14 |
Local Context Integration | Strong — Dedicates section to “Where to Buy in Sofia” listing specific stores (Running Zone, Sport Depot Mega Store, Nike/Paradise Center) with online alternatives | Moderate — Mentions “Running Zone (Park Center)” and “Nike Store – Paradise Center” for trying on shoes | Strong — References Sofia Half Marathon route (starting near St. Alexander Nevsky Cathedral), notes Sofia’s specific pavement conditions, mentions local parks for training |
Proactive Additions | Follow-up suggestions: Sofia half marathon 2026 date, training plan, best shoes for street training, Sofia running routes, common injuries | Asks clarifying questions: easy-run pace, soft vs. firm feel preference, overpronation history; offers to narrow to exact shoe recommendations | Offers to create 8-week training plan; provides specific weekly volume targets (30-35km by late March); notes weather considerations (slippery if it rains in April) |
Goal Interpretation | Accepts sub-4 hour goal at face value; focuses on durability and responsiveness for that pace | Gently questions goal (“Since your goal pace won’t require an aggressive super-shoe”); recommends forgiving options | Directly corrects goal (“sub-4 hours… is quite a generous time—it’s a brisk walking pace”); suggests sub-2 hours or sub-2:30 as realistic targets |
Here are some of the key observations we can pull, emphasising what we’ve already established on the differences of platform architecture:
- Perplexity provides the most transparent fan-out process—you can see exactly what sub-queries were generated and which sources informed the response. Best for understanding how the AI reached its conclusions.
- ChatGPT offers the most practical decision framework with clear “if you want X, choose Y” guidance. Least transparent about its reasoning process but most actionable in output structure.
- Gemini demonstrates the deepest contextual inference—pulling in the actual race date, specific Sofia locations, and local conditions without being asked. Shows the cross-product context integration potential, though no sources are not cited and the fan-out process is invisible.
- All three platforms inferred the need for road-focused shoes, durability for pavement, and cushioning for the user’s experience level—demonstrating baseline personalization even without deep memory integration.
- Brand overlap is notable: ASICS Novablast 5 and Saucony Endorphin Speed appear across all three platforms, suggesting these genuinely match the query parameters rather than being platform-specific biases.
- All three platforms offer a different direction for future steps, meaning – an entirely different semantic intent drift for the user, if they decide to continue the conversation, depending on which platform they use
The Full Picture: Traditional Search vs. AI Search Personalization
Before moving on to what this means for measurement and strategy, let’s synthesize everything into a single comparative view.
The table below maps each personalization signal type across traditional Google Search and the discussed AI platforms. Pay attention to two things: what data sources each system draws from, and crucially, where in the process that personalization gets applied.
I’ve also broken down in a table including all potential data points that different AI search systems can use for personalization and fan-out queries based on the documents and patents I’ve reviewed: Personalization and Context Data points used by AI Search Systems
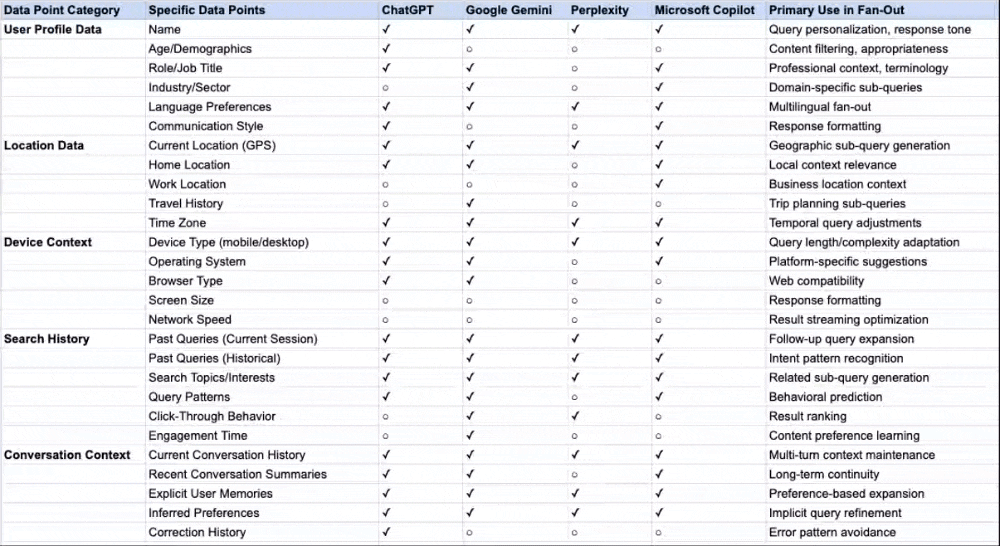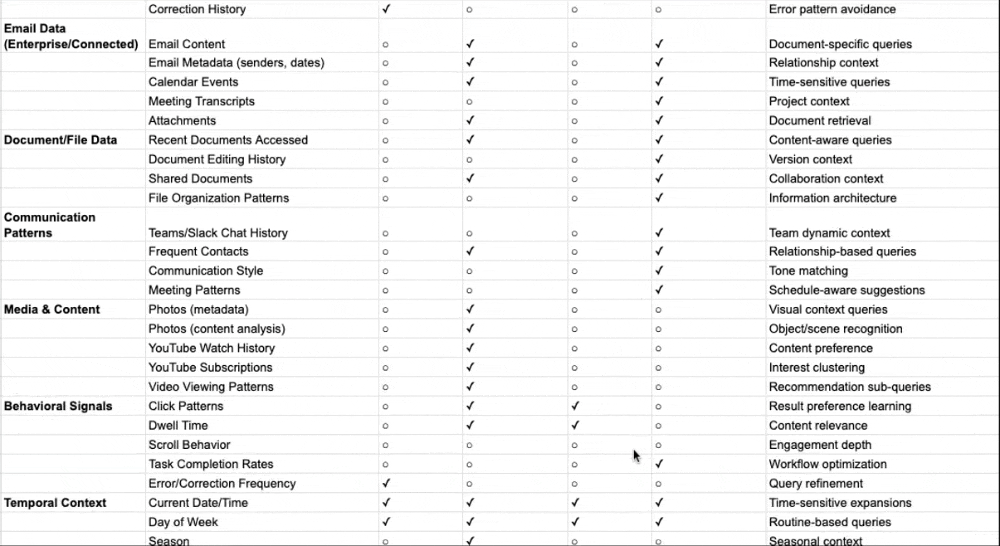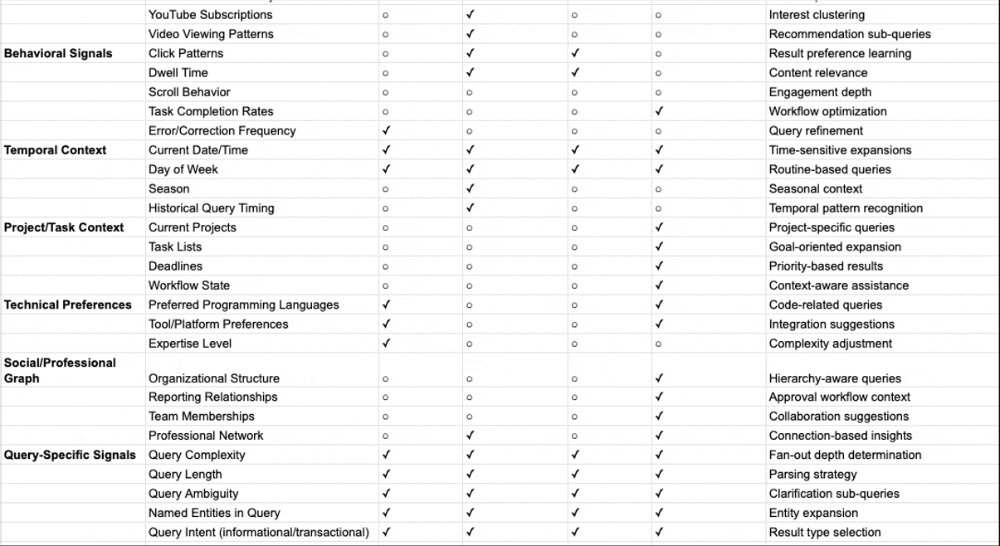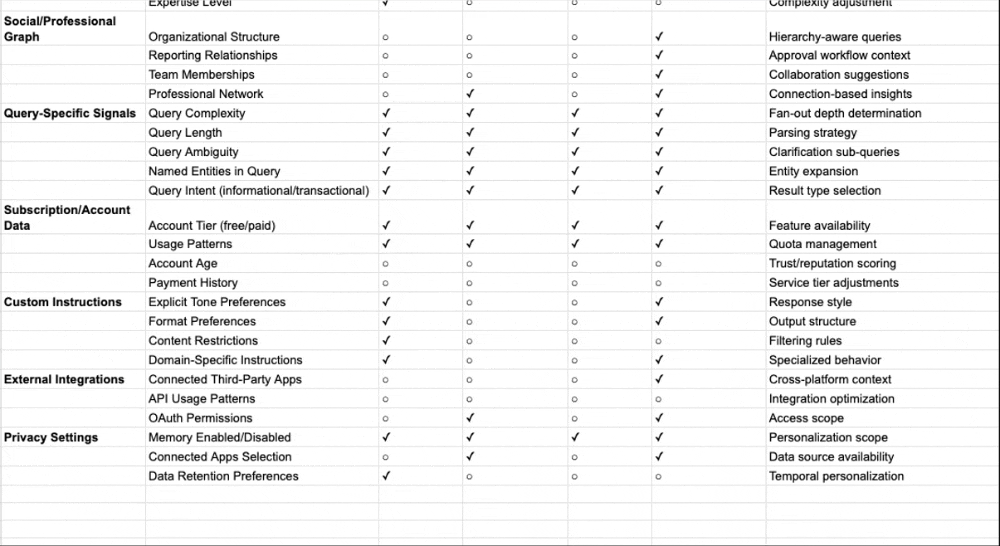
Signal Type | Traditional Google Search | Perplexity | Claude | ChatGPT | Gemini | Copilot |
Where personalization applies | Downstream (re-ranks results) | Upstream (shapes query expansion) | Upstream (shapes search queries) | Upstream (rewrites queries) | Upstream (shapes expansion) | Upstream (grounding in preprocessing) |
Session context | Analyzes query sequence; carries context forward | Session memory only; resets with new chat | Rolling context; project-separated | Session metadata + rolling context | Rolling window of recent messages | Session context enriched via Graph |
Long-term memory | Historical click data; domain preferences | Explicit “memories” only; no persistence | Saved memories + chat history (opt-in) | Saved memories + chat history insights | Structured user_context (opt-in) | Copilot Memory + Custom Instructions |
Behavioral inference | CTR, dwell time, pogo-sticking | None | Patterns from conversation history | Patterns from conversation history | Cross-product (Gmail, Photos, YouTube) | Full M365 activity patterns |
Location signals | IP geolocation | Only if stated | If in profile preferences or memory | Stored if in memory | Google account + device GPS | M365 profile + device |
Third-party integrations | None (Google ecosystem only) | None | None | None | Gmail, Photos, YouTube, Calendar, Workspace | Outlook, Teams, OneDrive, SharePoint |
Search backend | Google index | Own index + web | Brave Search | Bing | Google Search | Bing |
Transparency level | Low | High (shows sub-queries) | Low-Moderate (shows search query/results) | Low (invisible) | Low (invisible) | Low (invisible) |
User control | Limited settings | Session isolation default | View/edit memories; incognito mode; project separation | View/edit/delete memories | Opt-in required; can disconnect apps | Admin-controllable |
Privacy stance | Data used by default | Explicit sharing only | Opt-in memory; safety-first design | Memory on by default (paid); opt-out available | Restricted by default | On by default; M365 compliance boundary |
Three patterns emerge from this comparison that have direct strategic implications.
Pattern 1: The upstream shift is universal across AI platforms.
Every AI search system in this table applies personalization upstream (i.e. during query expansion) rather than downstream during ranking. This is the fundamental difference from traditional search. Google Search takes your query as fixed (with slight phonetic adjustments) and adjusts which results you see. AI search systems adjust what questions are asked before retrieval begins.
This means the competitive frame changes entirely. In traditional SEO, you fought for position within a stable results set. In AI search, you fight for inclusion in a query set that varies by user. Position matters less than presence.
Pattern 2: Inference depth correlates inversely with transparency.
Perplexity offers the shallowest personalization but the highest transparency—you can watch the fan-out happen. Copilot offers the deepest personalization but operates as a black box—grounding happens in preprocessing, and you never see the enriched query that was actually sent to the model.
For marketers, this creates tension and understandably – a ton of confusion on strategy. The platforms where personalization matters most are the platforms where you can observe it least. You’re optimizing for query expansions you’ll never see, shaped by user contexts you can’t access. With enterprise integration of AI search capabilities being the trend, and with personalized AI agents on the rise, this tension will likely continue to grow in future months.
Pattern 3: The data source spectrum determines the context you’re competing against.
At one end, Perplexity only knows what you’ve told it in the current session. At the other end, Copilot and Gemini know your email threads, your calendar, your documents, your internal team conversations and your entire work or personal digital context.
This means even the term relevance has different meanings across platforms, across session context, across devices used, across profiles used to complete the search. On Perplexity, your content competes against other public web content for generic queries. On Copilot, your content competes against the user’s own internal documents and communication history for highly contextualized queries.
What this means for marketers: The Strategic Implications Matrix
Based on these patterns, here’s how the personalization landscape maps to content strategy priorities:
Platform | Personalization Depth | Your Content Competes Against | Strategic Priority |
Perplexity | Shallow (session + explicit) | Other public web content | Comprehensive topic coverage; visible in fan-out |
ChatGPT/ Claude | Moderate (explicit + inferred patterns) | Public web content + user’s stated context | Context-specific content that matches common user profiles |
Gemini/ AI Mode | Deep (cross-product inference) | Public content + inferred user context from Google ecosystem | Content that addresses behavioral signals (not just stated needs) |
Copilot | Deepest (full enterprise graph) | Public content + user’s internal documents and communications | Integration-ready content; bridges external expertise with internal application |
Despite the differences, some fundamentals hold across all platforms:
- Entity clarity matters everywhere. Whether the system uses session memory or enterprise graph integration, it needs to understand what your content is about. Clear and in-depth entity markup, consistent terminology, and structured data help your content get correctly categorized regardless of platform. Those niche, rich schema types will become your best friend for building your enterprise’s knowledge graph, as detailed by Beatrice Gamba in her course on AI search.
- Topical authority compounds. Systems that infer user interests still need to retrieve relevant content to answer queries. Being the authoritative source on a topic increases your chances of surfacing across diverse user contexts because more fan-out paths lead back to you. We have, however, explained that surfacing in the set doesn’t always lead to being cited in the response, so personalization of authoritative content pieces to different context and user personas will become a differentiator.
- Specificity beats generality. Across every platform, the personalization mechanisms reward content that matches specific user contexts over content that tries to be everything to everyone. Your generic “ultimate guide”, which was boasted as the number one content piece in the ‘content is king’ era, will now lose to the focused “guide for [specific user type] in [specific situation]” in the ‘context is king’ era, especially on AI search systems.
Before we wrap up, let’s explore these strategic implications in depth.
Strategic Implications for Content and SEO
The Measurement Problem with Query fan-out
I’ll be honest with my opinion about measurement – query fan out breaks everything about traditional SEO performance tracking. It’s not a huge issue at the moment, as AI search is still not mainstream, but it might be – especially for the gen Zs and Alphas. Not to mention the possibility of new developments in personalized assistants or agents, or new developments in information retrieval.
The stability of traditional measurement and reporting, that whole query-SERP relationship, impression tracking, CTR, and conversion-attribution all leading back to a query a user typed in is now broken in the AI search model. Personalized fan-out, the use of memory and context in such a detailed and rich way by almost all of the platforms in this space makes it obsolete.
Same query, different users now means different fan-out queries, different retrieval sets, different information synthesized into the response. Your content might surface for one user’s expansion and be completely absent from another’s. Not ranked lower—absent. The system never asked a question that would have retrieved it.
What does this do to your metrics?
Impressions become meaningless aggregates. An impression count tells you how many times your content appeared in AI-generated responses. It doesn’t tell you what percentage of relevant queries your content was even eligible for. You might have 10,000 impressions but be invisible to 50,000 users whose personalized fan-outs never included queries your content could answer.
Position tracking becomes impossible. There is no position. There’s no stable results page to rank on. Your content either made it into the synthesized response and got cited or it is used to form the response and it’s not cited, or it doesn’t make it into the consideration pool at all; most of this outcome varies by user context and system memory, but also model training.
CTR and conversion data become distributions, not points. Your content might convert brilliantly for users whose profiles align with your entity and content coverage but become invisible for audiences you’ve not specifically addressed via your content strategy.
Attribution becomes guesswork. When you can’t know which users saw your content (because visibility depends on their personal context), you can’t reliably attribute conversions to specific content pieces or optimization efforts. Did that blog post drive revenue, or did the response frame your product as the best alternative out there. (Yes, AI search narratives can be influenced, but that opens an entirely different avenue of content strategy tactics – third-party mentions, digital PR, video strategy, forum discussions…)
Practically, your content might be performing brilliantly for users whose contexts match your positioning and you might never know it’s failing completely for everyone else. Traditional SEO analytics can’t distinguish between these two realities.
Measurement needs to evolve. Segment your AI-referred traffic by whatever behavioral signals you can access. Look for patterns in who’s finding you—device types, geographic clusters, time-of-day patterns that might indicate user cohorts. Build feedback loops that help you understand which user profiles your content resonates with, and do user research for groups in your target market.
You’re not optimizing for a position anymore. You’re optimizing for coverage across a distribution of possible user contexts that align with your target market.
The Filter Bubble Risk: When Personalization Skews Intent
There’s a darker side to personalized fan-out that we need to address: AI systems can drift from what users ask to what their profiles suggest they want.
I’ve written before about how fan-out can skew search intent through semantic expansion—how the sub-queries an AI system generates might emphasize latent intents the user never explicitly expressed. Personalization amplifies this problem significantly.
Historical bias injection. If your search history indicates interest in budget options, AI systems may constrain your fan-out queries to budget-focused angles, even if in the current session you’re researching a purchase where you’d happily pay more for quality or if your circumstances have changed and you’ve not ‘notified’ the system. The system assumes consistency in your preferences. Your preferences might have changed. You never get to see the premium options because the fan-out queries never asked about them.
Over-personalization erases discovery. One of the underappreciated values of generic search was serendipitous discovery—finding things you didn’t know you were looking for and being met with opposing views. When every query expansion is filtered through your established profile, the system optimizes for confirming what it already knows about you. It deprioritizes surprising you with something outside your established patterns.
Non-technical users don’t see the narrowing happening. This is the most frustrating part for marketers. When it comes to traditional search, users are pre-dispositioned to personalization – they can observe it happening. Local restaurants appear because of their location, news sources are boosted due to their reading history, and disclaimers are often visible in Google Search of why results are ranked in this way. With AI Search, this transparency disappears and users only see the synthesised answer. Sometimes, they don’t even see the sources that form the response. They often don’t have visibility of the query fan outs, fired by the system that shared the information retrieved, nor the particular memory and context data that the system has collected to form its fan-out direction. They can’t see what was excluded. They experience a confidently presented response and assume it represents a comprehensive research.
Especially for those users that are unfamiliar with how generative AI works, this creates filter bubbles they can’t comprehend (due to no provided knowledge about how the technology formed the response), and so they can’t observe or escape their bubble. For brands, this creates visibility gaps that are equally invisible and inescapable unless specific actions are taken to rework content, their branded entity knowledge graphs, and structured data. Your content might be the perfect answer for what a user actually needs—but if their profile suggests they need something else, the fan-out queries never give your content a chance.
The connection to content strategy is this: you can’t assume that comprehensive, authoritative content will surface for everyone researching your topic. Personalization means users are researching different versions of your topic, shaped by their profiles. Your content needs to explicitly address the contexts that might otherwise be assumed away.
How Personalization, Context and Memory will re-shape SEO and Content Strategy for AI Search
Enough about the implications. Let’s talk about what to do.
The strategic response to personalized fan-out isn’t to somehow game the personalization signals—you can’t access them, and you can’t control them. Don’t try to build out a dozen listicles on each facet of your brand, featuring yourself at the top (Lily Ray has explained how that might be a quick way to get yourself flagged for review content violations).
Instead, focus on the fundamentals that will work simultaneously on improving your organic presence on traditional search, your technical foundation (so your site is more easily accessible and preferred by AI search systems and agents alike), and building brand-relevant semantic content architectures robust enough to surface across diverse user contexts, and specific enough to be the best answer when you do surface.
Here’s how that translates to practical priorities.
Semantic SEO Becomes Non-Negotiable
If personalization shapes which entities and concepts appear in fan-out queries, then your content needs to be unambiguously associated with the right entities and concepts, and clearly addressing your target customer personas.
Structured data is no longer a nice-to-have. An enterprise knowledge graph, with bi-directional entity relationships and detailed tagging is the must-have feature for making your content more easily parseable and understood at scale. Making your content, products, and important brand facets speak the language of structure is where the game is at, when it comes to semantics. As not only traditional search engines work with this structure (schema, entities, relationships), but AI Search systems, too (more on this here How AI search systems leverage Entity Recognition).
Start by defining your key people, products, services, topics, organisational, and brand entities. Map out a semantic networking within and outside your organization, covering the important entity attributes and variables. Use schema markup that makes relationships explicit.
Then, when writing content, throw out the playbook that says – write everything on a topic; instead only cover the angles that are relevant for your ideal audience and that are as closely aligned with your proposition. A smaller content library that is focused and in-depth for the primary pain-points of your potential customers has a better chance of citations than a generic ‘ultimate guide’ style piece.
The key point is to be clear about what you offer, who you are, and why that matters for the variety of users that might be interested in your product. The more precisely AI systems can categorize your content, the more fan-out variations it becomes eligible to answer.
Niche Authority Beats Broad Evergreen Content
Here’s a hard truth: the content playbook of yesterday that rewarded top of funnel content and zero-to-hero guides is obsolete in AI search. Personalized fan-out, driven by memory and context rewards specificity. That’s partially why niche YouTube videos and Reddit discussions tend to surface so prominently (well, that and the fact that Google likes to build on monopolistic structures, but I digress).
When the system generates sub-queries like “best trail running shoes for first marathon under $150,” it’s looking for content that addresses that specific intersection. A 10,000-word guide that briefly mentions trail running, briefly mentions marathon training, and briefly mentions budget considerations is less relevant than a 1,500-word piece that deeply addresses exactly that combination. Even more so, when all these entity facets are addressed in a structured way, either on the page (think tables, summaries, etc), or within structured data.
Developing trust and authority in the particular niche where your brand operates matters more than investing in broad content that tries to cover entire categories. Go deep on the specific user contexts you serve best. Be the definitive answer for your target personas rather than a partial answer for everyone. This, of course, means prioritising something that typically is rarely a part of content strategy (but really should have always been the first step) – customer research.
User Research Becomes Even More Critical
If AI systems personalize based on user context, collected through so much data – both implicit and explicitly mentioned, then understanding those contexts is foundational to content strategy.
Persona mapping isn’t an exercise that sits with the brand team anymore. It should spill through the tone of voice, the content strategy, all the way through to technical SEO teams. But moreso, if your goal with content creation is reaching a niche audience with each product, then knowing in detail how they use AI search is another facet of the persona exploration.
So, what does your ideal customer’s AI search profile look like? Do they use Gemini, Claude, ChatGPT, or skip AI search altogether? What step of their purchase journey do they integrate AI search in? What devices are they using? How about the length and type of prompts they type? How much context to they typically share with their preferred system? Is it integrated with their Workspace (relevant to B2B audiences), or not?
Importantly, what can be inferred from their AI footprint to inform the direction in which query fan-outs are generated?
Map the contexts. Identify the signals. Then create content that addresses those specific combinations.
Personalized content systems based on individual persona profiles become more valuable. Not personalized in the sense of dynamic content insertion or programmatic SEO, though this is easier to do now more than ever before, but personalized in the sense of being able to answer distinct questions for distinct user groups with your pages (be it product descriptions, blog posts, case studies, and more). It’s also worth re-emphasising the fact that AI search and traditional rankings are, at least for the time being tied, so aiming for best practices for these items from an SEO perspective will improve the GEO perspective, too, although context can steer the conversation away if it deems your content irrelevant.
Comparison Content That Speaks to Specific Personas
I’m going to say something perhaps a bit outrageous, but let me explain. Comparison articles take on new importance in this landscape—but not the generic “X vs. Y” comparisons, nor the listicles that put your brand at the top in every assessment.
What I think the direction where this is going is: comparison content that explicitly argues why your brand or product is the best choice for a specific user profile, based on the real entity attributes that you win on, and let go of the crown for others where other brands might be better suited. Of course, this still needs to follow the best practices for search systems to avoid penalties.
Not “Nike vs. Hoka for Marathon Training.” Instead: “Why Hoka Works Better Than Nike If You’re Training for Your First Marathon on Trails”, featuring real customer reviews, specific product attributes, and data to highlight the arguments. So, being specific in the discussions about the important entities that make your product the right choice for a particular user is important and proves it through the content itself.
This serves two purposes. First, it increases your chances of surfacing when fan-out queries include those contextual modifiers. Second, it creates co-citations and builds associations with brands within your domain (this can be on your website or in third-party websites), allowing your brand to be introduced as a valid alternative for your target users, when their exact problem is the core of the discussion.
The core point here is not being manipulative or trying to game the system but to insert your brand into discussions where it is relevant, in a way that’s honest. It’s about being genuinely useful to the specific people you can best serve. And doing this in as many domains as possible, keeping those core objectives, as AI search systems diversify their sources, mixing in videos, forum discussions, and social media to form a consensus. Alignment on all channels is the name of the game.
Build for Contextual Intersections
The most actionable framework I can offer is this: stop thinking about keywords and start thinking about contextual intersections.
A keyword is a single dimension: “running shoes.” A contextual intersection is multi-dimensional: “running shoes” + “marathon training” + “trail terrain” + “beginner level” + “budget conscious”
AI search fan-outs generate queries along these intersections. Your content strategy should map the intersections relevant to your business and ensure you have content addressing each one.
This doesn’t mean creating thousands of hyper-specific pages. It means ensuring your content explicitly addresses the contextual modifiers that your target users’ profiles likely contain within the core pages closest to purchase. So, if you’re re-designing your product pages for running shoes, mention the terrain, mention the experience level, the price sensitivity. Provide social proof from a variety of users, who boast different shoe quality facets and uses. Make the intersections explicit in your content so that when fan-out queries include those modifiers, your content is eligible to surface.
Entity Consistency Across the User Journey
Finally, AI systems are building entity associations from your entire content footprint, not just individual pages or pages on your website. On social, on forums, on YouTube. With the recent change of hands of the control on TikTok, perhaps on TikTok, too, soon.
If your brand is associated with “premium performance running gear” in some content and “budget-friendly running options” in other content, AI systems receive mixed signals about who you serve, and they thrive on consensus. When fan-out queries include budget modifiers, the system might deprioritize you because you’re not consistently positioned as a budget option. When queries include premium modifiers, you might surface—but you’ve diluted your authority by also chasing the budget segment.
This also means repositioning your brand to a new audience should be an omni-channel approach, not just changing the copy on a page or two and then wondering why it didn’t work.
Entity consistency matters more than ever. Decide who you are, who you serve, and what contexts you want to own. Then ensure your entire content ecosystem reinforces those associations consistently via knowledge graphs and third-party mentions. You’re optimizing the entity profile that AI systems build about your brand.
What you can and can’t control and Where This Leaves Us
To wrap up, personalized fan-out changes what it means to be “found” in search. Instead of competing for positions on a results page, you’re now competing for inclusion in query sets that vary by user—shaped by contexts you can’t see and signals you can’t control.
You can’t control how AI systems personalize fan-out queries. You can control whether your content is positioned to surface across the range of contexts that matter to your business.
What you can’t control, to name a few:
- How any individual user’s context or memory settings shapes their fan-out queries
- What signals Gemini infers from someone’s Gmail or YouTube history
- What Copilot knows about a user’s work priorities from their Microsoft 365 activity
- Whether your content makes it into a specific user’s personalized query set
- The stochastic, unpredictable nature of query expansion across sessions
You cannot see these signals. You cannot access them. You cannot optimize for a specific user’s profile because you don’t know what that profile contains. Accepting this is step one.
The strategic response is straightforward even if the execution is hard. Here’s what you do control:
- Entity clarity. How precisely AI systems understand what your content is about, who it’s for, and what problems it solves. Structured data, consistent terminology, explicit semantic relationships.
- Topical depth. Whether your content is the definitive resource for your niche or a shallow overview that loses to more focused competitors. Depth on specific contextual intersections beats breadth across generic topics.
- Persona alignment. How well your content maps to the contexts your target users likely carry. You can’t know an individual’s profile, but you can research your audience’s common characteristics and create content that addresses those patterns.
- Content architecture. Whether your content ecosystem covers the range of fan-out queries that might lead to your topic. Multiple focused pieces addressing different user contexts beat one comprehensive piece trying to serve everyone.
- Entity consistency. Whether your entire content footprint reinforces a coherent positioning or sends mixed signals about who you are and who you serve.
- Measurement evolution. How you track performance in a world of probabilistic visibility. Segmentation, cohort analysis, brand mention monitoring, feedback loops that reveal which user contexts your content resonates with.
You control how well your content is positioned to surface across diverse personalized queries. You’re building for a distribution of possible user contexts, not optimizing for a single stable query.
At the start of this article, I argued that in the AI search game, context—not content—is king. Having walked through the mechanisms, let’s review this again.
Context is king for the user. AI Search allows for a personalization of the information retrieval like never before. What it knows about them shapes what questions get asked on their behalf, which shapes what information gets retrieved, which shapes what they ultimately see. Their context determines their reality.
For the brand, the content creator, the SEO—the game is different. You can’t control or even see the user context or their preferences. But you can control how well your content speaks to the contexts that matter for your business.
The brands that will thrive in AI search aren’t the ones with the most content or the highest domain authority or the most backlinks—though none of those things hurt, as they help position you better in traditional SEO, which still is the dominant search mode. The brands that thrive are the ones with the clearest entity positioning, the deepest niche authority, and the most deliberate alignment between their content and their target users’ likely contexts.
This is a fundamental shift from the SEO playbook of the past decade. Less “create comprehensive content and build links.” More “understand exactly who we serve, what contexts they carry, and how to be the definitive answer when those contexts shape the queries.”
The platforms will keep evolving. Google will deepen Gemini’s cross-product inference. OpenAI will likely expand ChatGPT’s memory capabilities and integrate personalization via agents (with the recent acquisition of OpenClaw). Microsoft will tighten Copilot’s enterprise integration. The inference depth spectrum will stretch further in both directions.
The strategic foundation will not change. Invest in audience research, build content that addresses those contexts with specificity, honesty, and authority, and maintain entity clarity so AI systems understand where your content belongs.







