
Audience needs remain the same in the age of AI Search: well-written, engaging content that answers their questions and helps solve their problem will reign supreme.
Let’s discuss how we blend the age-old with the new age.
Great content begins with a solid foundation of strategy and ideation. What you create is a function of why–why is this topic important? What problem does it represent? How can we develop it so it meets the needs of users and search engines?
That last question is where GEO Content Strategy and Production begins. Leveraging tools like Qforia you can build out a comprehensive Keyword Matrix with a full inventory of all related queries on a topic. This matrix serves as the foundation for what subjects and related queries are necessary to include in your content. Once you have this data, you can begin the content production process.
Qforia can also show you other related queries, what type of question the query is asking, and what type of content would be best to answer the query (table, interactive tool, guide, etc.).
After this, it’s useful to explore the SERPs and LLM results to see what content is already out there or where there are gaps. Using the suggestions from Qforia, you can audit your current content and see what’s missing, what can be improved, or what can be pruned. Then you can go on to create an omnimedia content plan to ensure visibility everywhere online, not just the SERP, including LLMs, YouTube, Reddit, social media, and elsewhere.
As we’ve discussed, one of the most important steps toward visibility in AI Search is ensuring that your content is both accessible and relevant. If your content can’t be found, it won’t be surfaced, and that’s true whether the user is typing a query into Google Search or being served an AI-generated summary.
To accomplish this, make sure the following technical elements are in place:
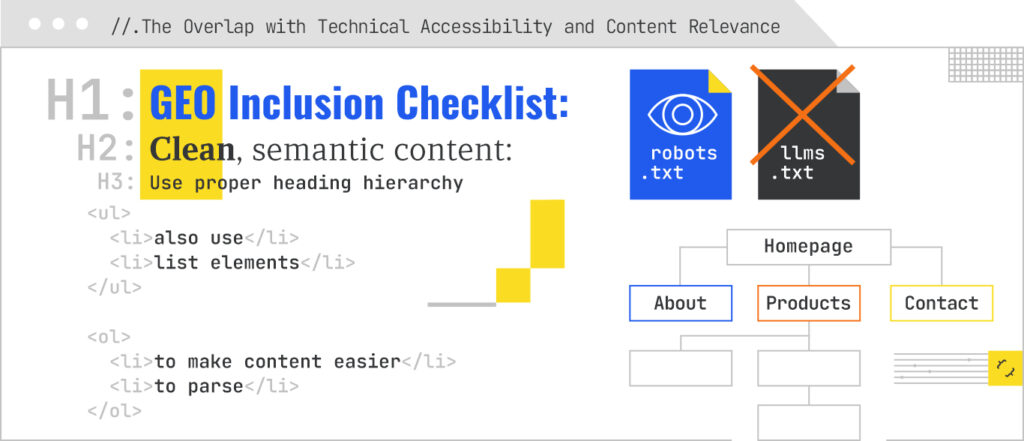
There are also some content-focused recommendations:
It’s not all technical tips and tricks, though. The best way to ensure visibility in LLMs is to make content that resonates. In an era when the internet is overflowing with content, yours must be scroll-stopping.
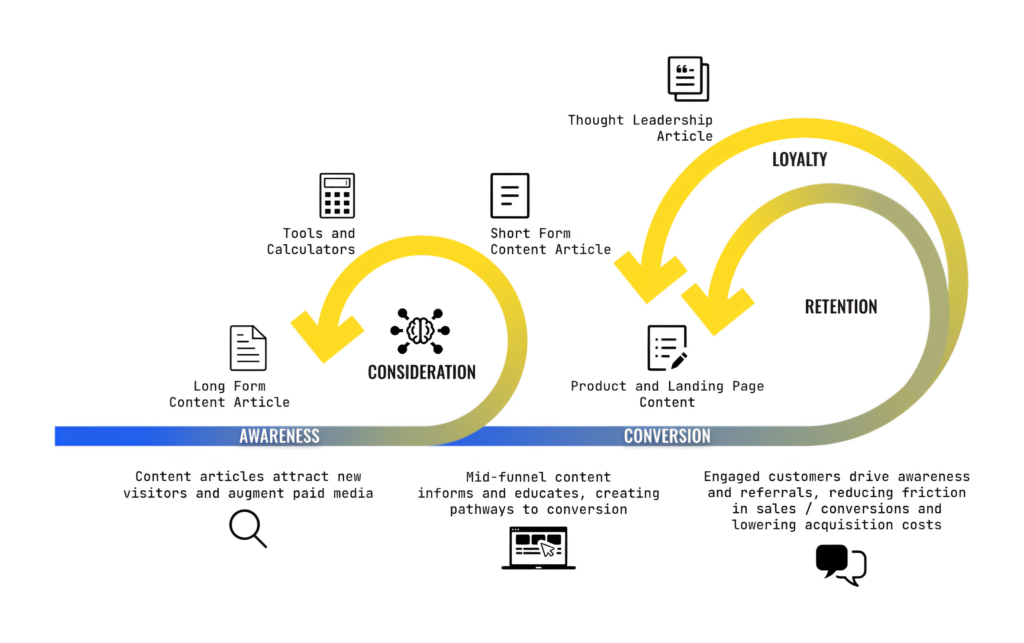
Add the R.E.A.L. tenets to your content strategy:
Making your content technically accessible, semantically clear, and relevant gives you the best chance of being included in AI-generated answers.
Ensuring that your content is focused on the entity/topic you intend means including all of the necessary and related entities to strengthen its meaning.
For example, if you were developing a piece of content on “Wi-Fi Service in Richmond,” there would be several entities to include in your content to improve its correlation with the main topic. Some of those entities might be:
While not every one of these entities would make it into the “Wi-Fi Service in Richmond” context, it is helpful to understand all the types of information that are associated and correlated with the main topic.

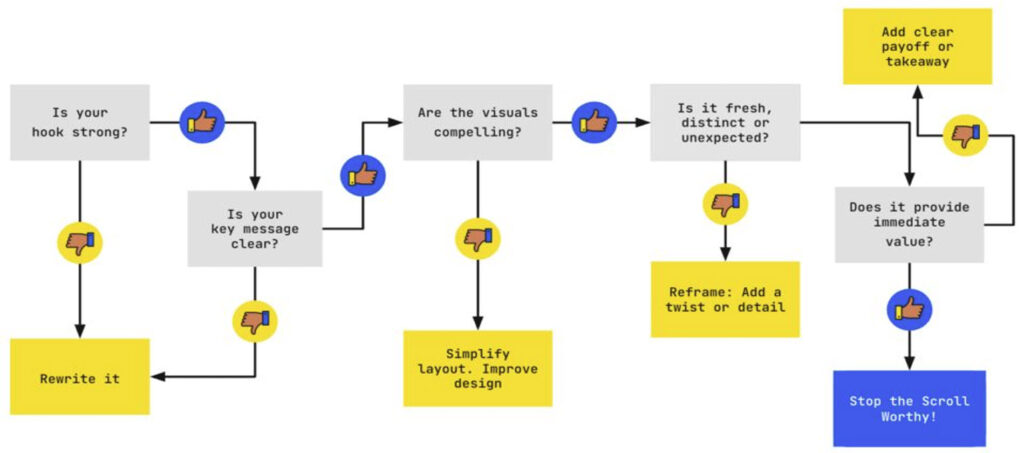
Here’s a quick flowchart to assess your content before it goes live:
In summary, as you start exploring more ways to improve operational efficiency with AI-driven solutions, be sure to align yourself with the three laws of generative AI content:
In the next chapter, we’ll go through how to measure the success of this content and what new measurement methods we can use.
The appendix includes everything you need to operationalize the ideas in this manual, downloadable tools, reporting templates, and prompt recipes for GEO testing. You’ll also find a glossary that breaks down technical terms and concepts to keep your team aligned. Use this section as your implementation hub.
//.eBook

The AI Search Manual is your operating manual for being seen in the next iteration of Organic Search where answers are generated, not linked.
Prefer to read in chunks? We’ll send the AI Search Manual as an email series—complete with extra commentary, fresh examples, and early access to new tools. Stay sharp and stay ahead, one email at a time.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering AI Search and content marketing agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $5B+ in organic search results for our clients.
We’ll break it up and send it straight to your inbox along with all of the great insights, real-world examples, and early access to new tools we’re testing. It’s the easiest way to keep up without blocking off your whole afternoon.





