
In traditional SEO, optimization work has always been reactive to the realities of a live system. Google pushes an update, rankings shift, we interpret the movement through ranking data, and we adjust. But the GEO paradigm demands a more proactive stance. The search systems we’re optimizing for are no longer static indexes queried via a fixed lexical interface. They are multi-stage reasoning systems with hidden retrieval layers, generative models, and filtering mechanisms. If we want to reliably influence these systems, we need to stop treating them as black boxes and start building simulators.
Simulation in GEO is not just an academic exercise. It is a practical, iterative process for probing how an AI-driven search environment sees, interprets, and ultimately chooses to present your content. The methods range from LLM-based scoring pipelines to synthetic query generation, retrieval testing, and even prompt-driven hallucination analysis. The objective is simple: Replicate enough of the retrieval and reasoning stages that you can meaningfully test hypotheses before shipping content into the wild.
Why Simulation Matters in GEO
The stakes are higher now. In a purely lexical search environment, you could infer retrieval logic from keyword patterns, backlinks, and document structure. In GEO, you’re working with vector spaces, transformer encoders, entity-linking algorithms, and retrieval-augmented generation orchestration layers. Every stage introduces potential nonlinearities, so small changes in content can produce outsize effects, or no effect at all, depending on where the bottleneck lies.
Simulation offers two key advantages.
- It lets you isolate variables. If you can feed synthetic queries into a controlled retrieval model and observe which passages surface, you can decouple retrieval influence from generative-synthesis quirks. (This is effectively what was done with Perplexity in the original Generative Engine Optimization paper.)
- It shortens the feedback loop. Rather than waiting for a production AI system to refresh its indexes or re-embed your pages, you can pre-test adjustments against a local or cloud-hosted model and iterate in hours instead of weeks.
Forward-Looking Opportunity: As AI search platforms mature, we are likely to see more frequent architectural changes to their retrieval layers. We can expect new embedding models, updated entity-linking heuristics, and modified context-window sizes. A robust simulation environment will not only help adapt to these shifts, it could become a core competitive moat: The better your internal model of a given AI Search surface, the faster you can exploit new ranking levers.
Building a Local Retrieval Simulation App with LlamaIndex
One of the most powerful ways to understand how your content performs in a RAG setup is to build your own lightweight simulation environment. This lets you feed in a query and a page (or just its text) and see exactly which chunks the retriever selects to answer the question.
We’ll walk through building a Google Colab or local Python app that uses:
- Trafilatura, for HTML-to-text extraction from URLs
- LlamaIndex, for chunking, indexing, and retrieval simulation
- FetchSERP, for getting real AI Overview/AI Mode rankings for comparison
The tool will output:
- Retrieved-chunks list — The exact text blocks your simulated retriever would pass to the LLM.
- Overlap analysis — How those chunks compare to live AI Search citations.
- Diagnostic chart — A simple visualization of chunk relevance scores.
Here’s how we’ll do it.
Step 1: Install Dependencies
Get your Python environment ready with LlamaIndex, Trafilatura, FetchSERP, and Gemini embeddings.
pip install -U llama-index google-generativeai trafilatura python-dotenv
We’re using:
- trafilatura to pull clean text from a URL
- llama-index as our retrieval framework
- fetchserp to call the FetchSERP API for live AI Overview/AI Mode data
Step 2: Set Up Your API Keys
Authenticate with FetchSERP, Gemini, and any LLM provider so your workflow can run end-to-end.
You’ll need:
- FetchSERP API key from https://fetchserp.com
- GEMINI API key for embeddings and LLM queries in LlamaIndex
Create a .env file to store your API credentials:
GOOGLE_API_KEY=your_google_api_key_here
FETCHSERP_API_KEY=your_fetchserp_key_here
Step 3: Extract the Content
Pull clean, structured text from a target URL using Trafilatura for optimal indexing.
import os
from dotenv import load_dotenv
import requests
import trafilatura
from llama_index.core import Document, VectorStoreIndex, Settings
from llama_index.embeddings.gemini import GeminiEmbedding
# from llama_index.llms.gemini import Gemini # optional if you want to generate with Gemini
load_dotenv()
# --- Configure embeddings (Gemini) ---
Settings.embed_model = GeminiEmbedding(
model_name="models/gemini-embedding-001",
api_key=os.getenv("GOOGLE_API_KEY")
)
# Optional: configure Gemini LLM for synthesis (not required for retrieval-only sims)
# Settings.llm = Gemini(model="models/gemini-2.5-pro", api_key=os.getenv("GOOGLE_API_KEY"))
FETCHSERP_API_KEY = os.getenv("FETCHSERP_API_KEY")
# --- Content extraction (Trafilatura) ---
def extract_text_from_url(url: str) -> str:
downloaded = trafilatura.fetch_url(url)
if not downloaded:
raise ValueError(f"Could not fetch URL: {url}")
text = trafilatura.extract(downloaded, include_comments=False, include_tables=True)
if not text:
raise ValueError(f"Could not extract readable text from: {url}")
return text
If the user doesn’t have a URL, you can accept raw pasted copy instead.
Step 4: Index with LlamaIndex
Embed and store your content chunks using Gemini’s gemini-embedding-001 model for precise retrieval.
# --- Index building with LlamaIndex (Gemini embeddings) ---
def build_index_from_text(text: str) -> VectorStoreIndex:
docs = [Document(text)]
index = VectorStoreIndex.from_documents(docs)
return index
This builds an embedding index from your content. LlamaIndex automatically chunks the text and stores embeddings for retrieval.
Step 5: Simulate Retrieval
Run a query through your local index to see which chunks a retriever would surface.
# --- Retrieval simulation ---
def simulate_retrieval(index: VectorStoreIndex, query: str, top_k: int = 5):
retriever = index.as_retriever(similarity_top_k=top_k)
results = retriever.retrieve(query)
# returns list of (chunk_text, score)
return [(r.node.text, getattr(r, "score", None)) for r in results]
This returns the top 5 chunks that would be fed into the LLM for a RAG answer.
Step 6: Get Real AI Search Data for Comparison
Use FetchSERP to pull AI Overview or AI Mode citations for your query.
# --- FetchSERP: get AI Overview / Mode citations for comparison ---
def fetch_ai_overview(query: str, country: str = "us"):
# Adjust to your FetchSERP endpoint & params; this mirrors the earlier example usage
url = "https://api.fetchserp.com/search"
params = {
"q": query,
"search_engine": "google.com",
"ai_overview": "true",
"gl": country
}
headers = {"x-api-key": FETCHSERP_API_KEY}
r = requests.get(url, params=params, headers=headers, timeout=60)
r.raise_for_status()
return r.json()
def extract_citation_urls(fetchserp_json) -> list:
# Adapt the parsing to your actual payload shape
# Example path: data.ai_overview.citations -> [{url, title, site_name}, ...]
ai = fetchserp_json.get("ai_overview") or {}
cits = ai.get("citations") or []
urls = [c.get("url") for c in cits if c.get("url")]
return urls
From the FetchSERP response, you can extract citation URLs from the AI Overview or AI Mode section.
Step 7: Display & Compare
Visualize the overlap (or gap) between your simulated retrieval results and live AI Search output.
# --- Overlap (very naive string containment; you can expand to domain matching, etc.) ---
def compare_chunks_with_live(citation_urls: list, local_chunks: list):
matches = []
for url in citation_urls:
uhost = url.lower()
for chunk, score in local_chunks:
if uhost in (chunk or "").lower():
matches.append((url, chunk, score))
return matches
Step 8: Run the Full Workflow
Execute the complete pipeline from extraction to comparison in one automated run.
if __name__ == "__main__":
query = "best ultralight tents for backpacking"
url = "https://www.example.com/ultralight-tent-guide"
# 1) Local simulation with Gemini embeddings
text = extract_text_from_url(url)
index = build_index_from_text(text)
retrieved = simulate_retrieval(index, query, top_k=5)
print("\n=== Retrieved Chunks (Gemini embeddings) ===")
for i, (chunk, score) in enumerate(retrieved, 1):
print(f"\n[{i}] score={score if score is not None else 'n/a'}")
print(chunk[:600].strip(), "…")
# 2) Live AI Overviews via FetchSERP for comparison
try:
live = fetch_ai_overview(query)
live_urls = extract_citation_urls(live)
print("\n=== Live AI Overview Citations ===")
for u in live_urls:
print("-", u)
# 3) Naive overlap check
overlaps = compare_chunks_with_live(live_urls, retrieved)
print("\n=== Overlap (urls that appear within retrieved chunks) ===")
if not overlaps:
print("No direct overlaps found (expected; retrieved chunks are your page).")
else:
for u, ch, sc in overlaps:
print(f"- {u} | score={sc}")
except Exception as e:
print("\n[Warn] Could not fetch or parse live AI Overview data:", e)
Why This Matters for GEO
With this setup in place, you gain clear visibility into how a simulated vector search interacts with your content. You can pinpoint exactly which sections or chunks of your page are being retrieved, making it easier to understand how your content would perform in a retrieval-based system.
By comparing these simulated retrieval results with live AI Search citations, you can identify gaps in coverage where key passages are not surfacing. This insight allows you to target your optimizations toward improving representation in those missing areas. Additionally, the system enables rapid iteration: You can make content edits, rerun the retrieval process, and immediately see if the desired chunks rank higher in the simulated output.
Looking ahead, this framework has room for powerful extensions. For example, you could incorporate synthetic query fan-out, allowing you to generate and test retrieval for multiple query variations in bulk. This would give you a richer map of how different search intents interact with your content. Another valuable enhancement would be to aggregate chunk-level scores across your entire site into a “retrieval readiness” heat map, helping you prioritize optimization work at scale. Finally, integrating hallucination-testing prompts against retrieved chunks would let you evaluate not just whether your content is being pulled, but also whether AI systems are accurately representing it in generated answers. Together, these capabilities would transform the app from a single-query diagnostic tool into a robust GEO simulation-and-monitoring environment.
LLM-Based Content Scoring: Reading Your Pages Like a Retriever
One of the most direct simulation techniques is to use LLMs to evaluate your own content as though they were the retrieval-and-ranking layer of an AI Search system. The key here is not to ask the LLM for subjective feedback (“Does this content look good?”) but to give it specific scoring criteria that align with how retrieval models operate.
In practice, this means breaking down content scoring into dimensions like:
- AI Readability: Can the content be cleanly segmented into extractable answer units? Are headings aligned with discrete subtopics? Are key facts front-loaded in paragraphs?
- Extractability: If you prompt the model with a question, can it locate and return the relevant passage without hallucination or rephrasing drift?
- Semantic Richness: Does the passage contain a high density of relevant entities, synonyms, and co-occurring terms that reinforce topical alignment?
A well-constructed LLM scoring pipeline might feed the model a passage along with a target query, and ask it to assign a retrieval likelihood score on a 0-to-10 scale. You could then aggregate these scores across your site to produce a heat map of “retrieval readiness.”
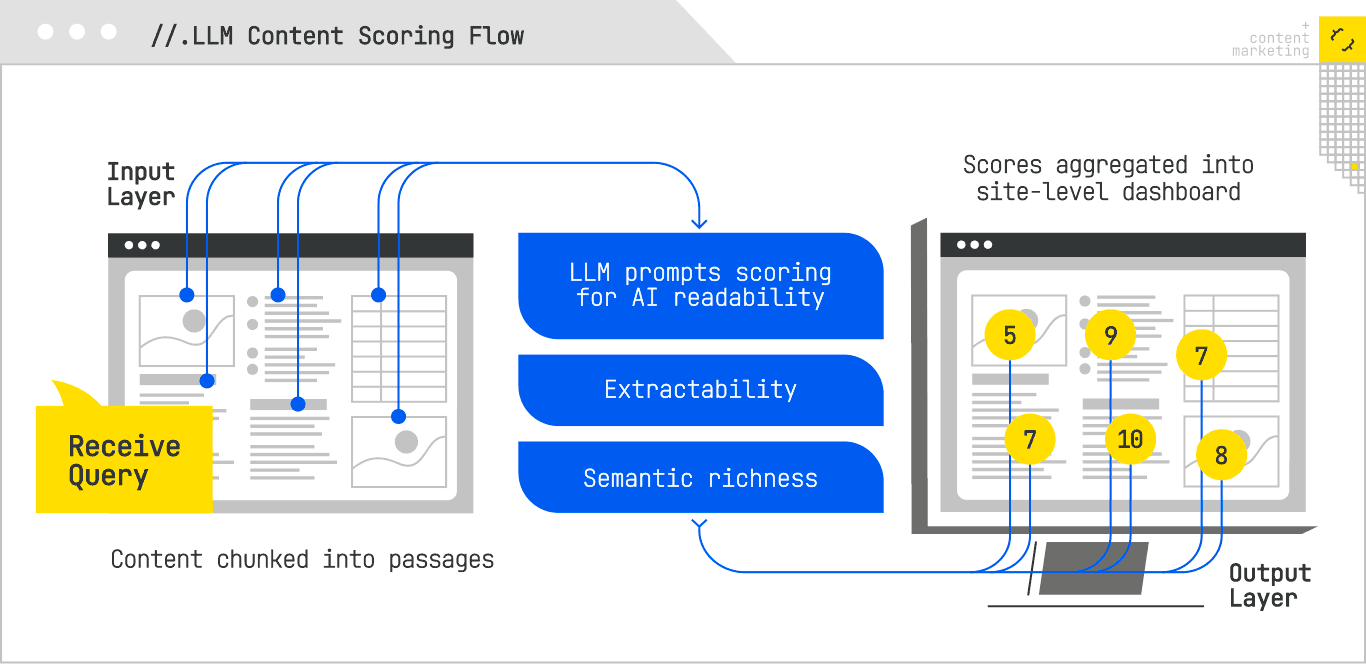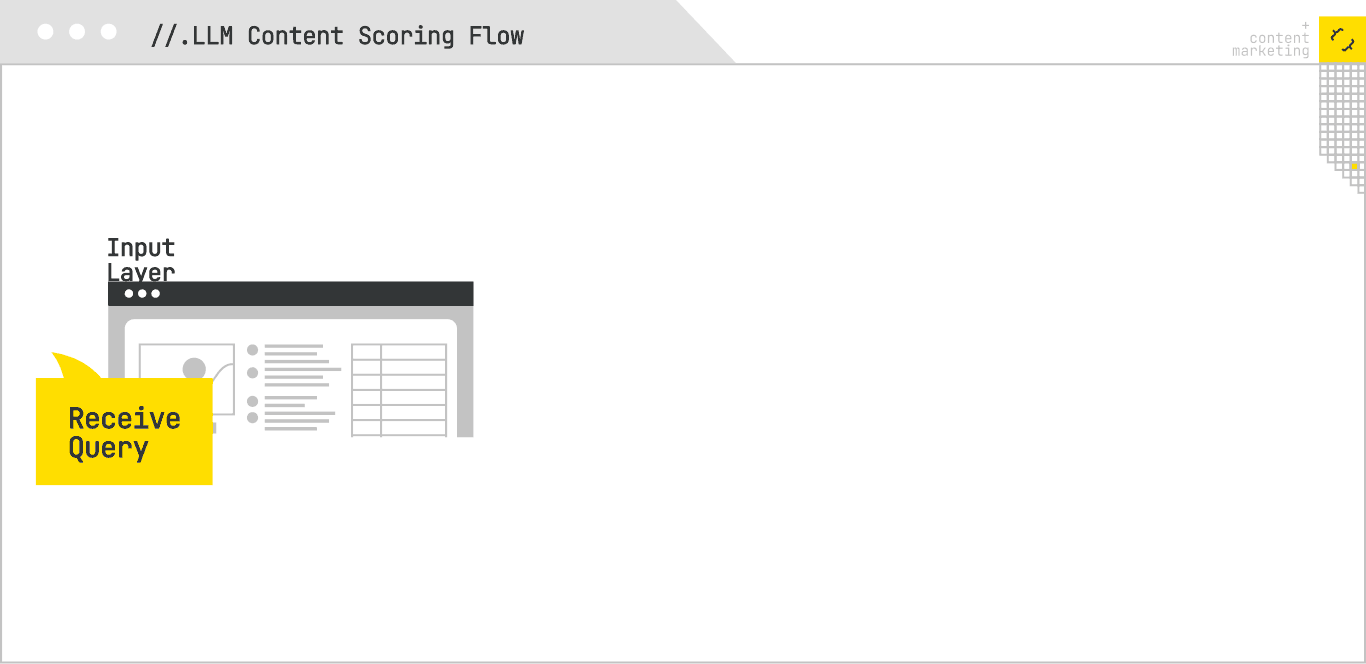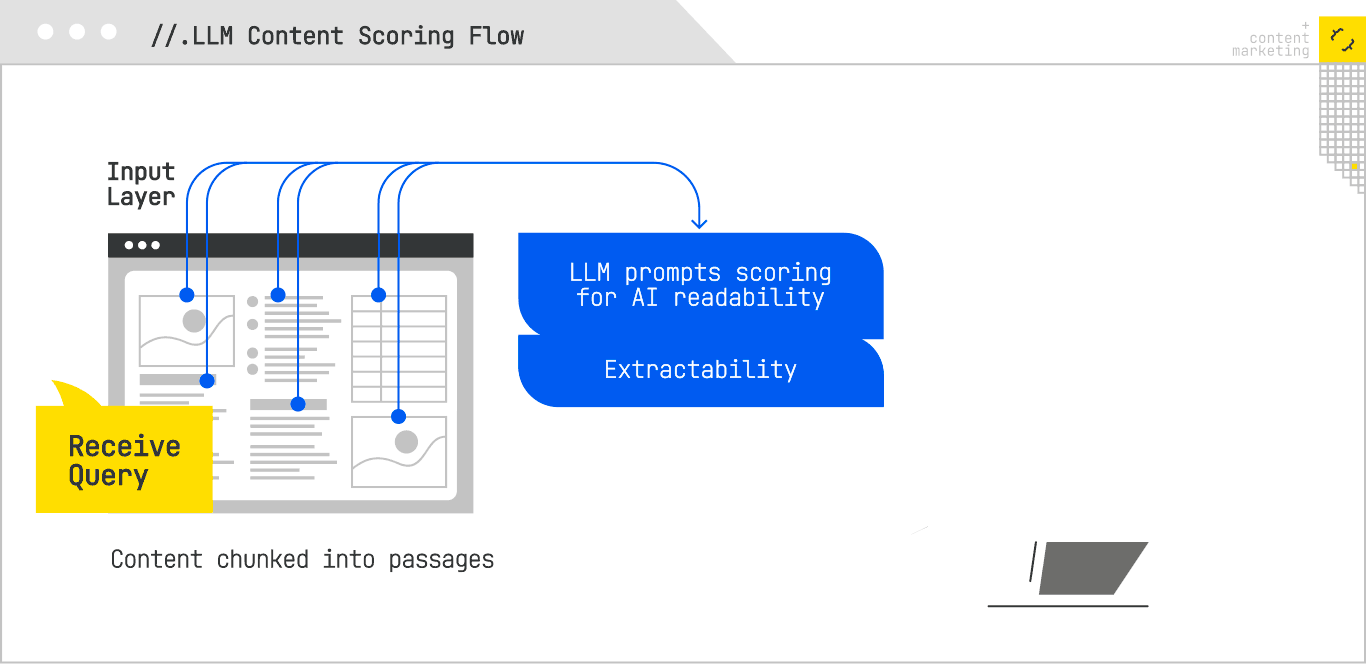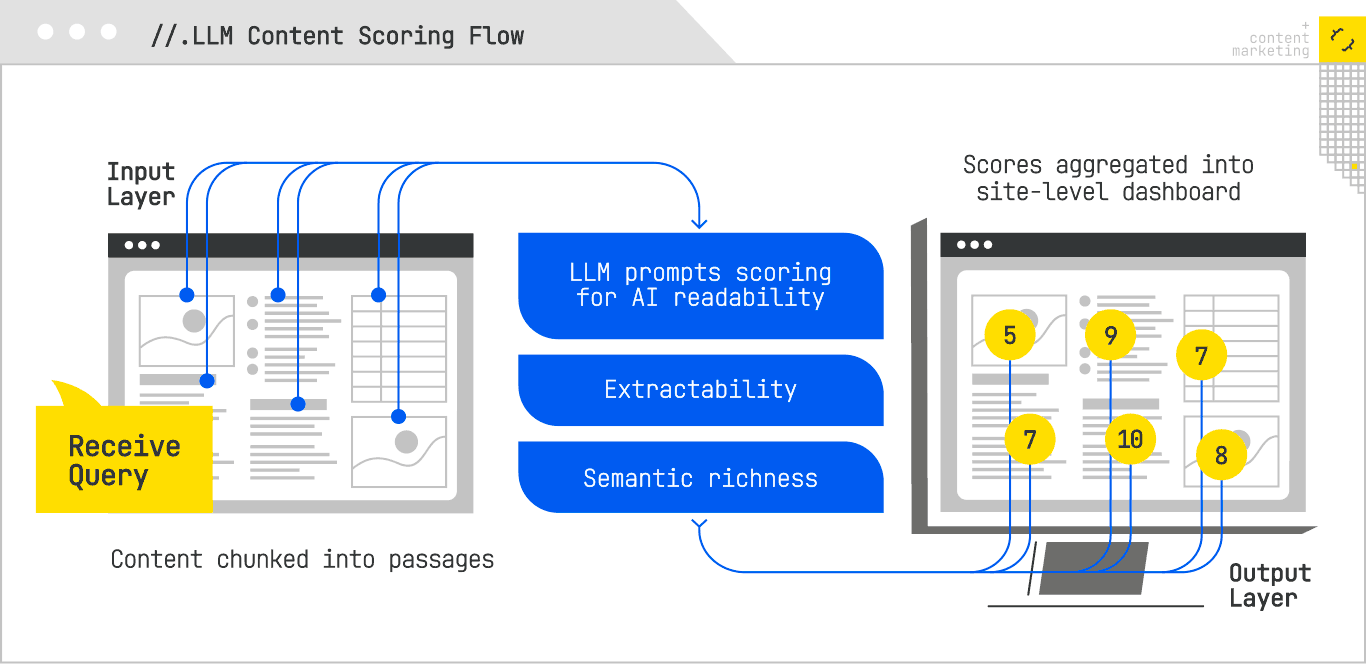
This type of scoring is not perfect. It’s still a proxy for how a proprietary retrieval model works, but when calibrated with live test results (e.g., Perplexity citation frequency), it becomes a reliable leading indicator of generative visibility.
Synthetic Queries and Retrieval Testing
While LLM-based scoring tells you how “retrievable” your content might be, retrieval testing tells you if it actually is. The process starts with generating synthetic queries designed to mimic the fan-out behavior of real AI Search systems. A single user query like “best ultralight tents for backpacking” might be decomposed into subqueries such as “ultralight tent durability comparisons,” “backpacking tent weight limits,” and “two-person ultralight tent reviews.” This is the same latent-intent expansion that AI Overviews and AI Mode use under the hood.
To generate these synthetic queries, you can use a combination of:
- Embedding Nearest Neighbors: Use a vector model like mixedbread-ai/mxbai-embed-large-v1 to find semantically close queries from your keyword corpus.
- Prompted LLM Expansion: Ask the model to produce question variations and entity-linked expansions that cover likely retrieval angles.
- Entity Injection: Seed queries with specific entities known to influence your vertical, forcing the retriever to test entity matching.
Once you have the synthetic queries, you run them through your retrieval simulation. This could be:
- A local dense retriever trained or fine-tuned on your vertical’s content.
- An API-based retriever like the Gemini embeddings we’ve used above combined with a vector search backend like Pinecone or Weaviate or Google’s own vector search library SCaNN.
The goal is to record which passages surface and compare the results to your expectations. If you control the retriever and its index, you can also simulate embedding updates to see how retrieval shifts over time.
Forward-Looking Opportunity: Over the next few years, expect to see the emergence of third-party “GEO testing suites” that can simulate the fan-out and retrieval logic of multiple AI Search systems in parallel. This will create a standardized way to preflight content before publication, much like how Core Web Vitals testing works today.
Prompt Templating for Hallucination Analysis
Even if your content is retrievable, the generative layer may distort or misrepresent it. Hallucinations, where the AI fabricates details or incorrectly attributes them, are not just a user-experience risk; they can erode brand credibility if your name is attached to incorrect facts.
All models still experience hallucinations but some are showing improvements. ChatGPT-5 has been measured to have 6 times fewer hallucinations than ChatGPT-o3.
Prompt templating is a way to systematically test how different AI models handle your content in synthesis. The process involves creating controlled prompts that reference your page either directly or indirectly and instruct the model to produce an answer. You then evaluate:
- Does the generated answer match the factual content of your page?
- Does the model correctly attribute quotes, data points, or claims to your brand?
- Does synthesis omit critical qualifiers (e.g., “only applies to US markets”)?
For example, if your page contains a section titled “How to Safely Charge an E-Bike Battery,” you might run three prompt variants:
- Direct: “According to [brand], how should you safely charge an e-bike battery?”
- Indirect: “What’s the best way to safely charge an e-bike battery?” (retriever has to decide to include your page)
- Contradictory: “What’s the best way to charge an e-bike battery overnight?” (tests whether your “don’t charge overnight” warning is preserved or overwritten)
By running these prompt templates across multiple models, you can map which ones are prone to hallucination when handling your vertical’s content and adjust your phrasing, sourcing, or disclaimers accordingly.
Building a Feedback Loop Between Simulation and Production
Simulation only pays off if it’s connected back to real-world data. The most effective GEO teams treat their simulation environment as a staging server for AI Search: Every piece of content is scored, retrieval-tested, and hallucination-checked before it goes live. Once live, its actual citations, rankings, and generative inclusions are tracked, and that data feeds back into the simulation to refine its scoring heuristics.
For example, if retrieval testing predicted a 90 percent inclusion likelihood for a page, but production monitoring shows only 20 percent citation frequency in Perplexity, you investigate the gap. Was the production retriever’s embedding model different from your simulation? Did the system favor a competitor page with stronger entity co-occurrence? Did synthesis logic truncate your key fact?
Over time, this creates a calibration cycle through which your simulation grows closer to the real system’s behavior. Eventually, you can run “what-if” tests similar to Marketbrew. For example, you can change a heading structure, add a diagram, or adjust entity density and have a high-confidence forecast of whether it will increase generative inclusion.
The Strategic Payoff
Simulating the system is not about perfectly replicating every quirk of a proprietary AI Search model; it’s about building a controlled environment where you can test ideas faster and more precisely than your competitors. In classic SEO, this role was filled by rank trackers, keyword difficulty scores, and link metrics. In GEO, it will be filled by LLM-based scoring, synthetic retrieval testing, and hallucination analysis.
Forward-Looking Opportunity: As AI Search engines evolve toward more multimodal and context-persistent designs (think MUM extended with user embeddings and conversation state), simulation environments will need to incorporate these additional modalities. That means scoring not just text but image captions, video transcripts, and even interaction flows.
Simulating the system lets you move from reactive SEO firefighting to proactive Relevance Engineering. You stop guessing what the black box wants, and start training a gray box that’s close enough to guide your next move with data, not superstition.
In the end, simulating the system is about reclaiming agency in an environment where the rules are opaque and the players are constantly shifting. GEO success will not come from guessing at how Perplexity, Copilot, or AI Mode work. It will come from systematically modeling their behaviors, stress-testing your content against those models, and iterating based on measured outcomes. The teams that invest in building and refining these simulation frameworks will not just adapt more quickly to changes in retrieval or synthesis logic; they will set the pace for the entire field. In a future where search is increasingly generative, the winners will be those who can see the shape of the system before the rest of the world, and have the discipline and data to act on it.
We don't offer SEO.
We offer
Relevance
Engineering.
If your brand isn’t being retrieved, synthesized, and cited in AI Overviews, AI Mode, ChatGPT, or Perplexity, you’re missing from the decisions that matter. Relevance Engineering structures content for clarity, optimizes for retrieval, and measures real impact. Content Resonance turns that visibility into lasting connection.
Schedule a call with iPullRank to own the conversations that drive your market.






