Want a different perspective? These links open AI Search platforms with a prompt to explore this topic, how it works in AI Search, and how iPullRank approaches it.
*These buttons will open a third-party AI Search platform and submit a pre-written prompt. Results are generated by the platform and may vary.
Whether it’s AI Overviews in Google Search, conversational responses in ChatGPT, or synthesized answers in Perplexity, the question content creators and businesses now face is how to show up in all of these places.
Let’s look at some ways you can potentially do that.
Generative engines validate, compare, and often cite content in their summaries. In that process, concrete facts, figures, dates, and measurable data points become critical signals. The more specific your content is, the more likely it is to be selected, synthesized, and surfaced.
What to Focus On:
Measurable data helps AI systems evaluate whether content can be trusted, so they can summarize more confidently, align facts across multiple sources, and identify your content as a reliable contribution to an answer.
Generative AI models disambiguate topics, identify entities, and determine the usefulness of content without reading every word on the page. They have moved beyond simple keyword matching and rely more heavily on structured signals to interpret and reassemble information. Schema markup, meta descriptions, and other structural hints give them the clarity they need to understand the meaning, relationships, and utility of your content at the page level and within individual elements.
These signals don’t just improve discoverability. They also enhance your inclusion in generative outputs.
If you are going to create a robust, machine-readable knowledge base you have to look beyond Schema.org to provide additional layers of direction.
Here are a few ways to evolve your structured data:

What to Focus On:
For queries involving troubleshooting, product comparisons, lived experiences, or niche use cases, user-generated content (UGC) and forum discussions are often prioritized by AI systems. Generative models value this type of content because it reflects authentic, diverse, and situational insights that can’t always be found in more polished corporate content.
This trend has become more visible with Google’s Hidden Gems update and the increasing appearance of Reddit and Quora excerpts in AI Overviews and conversational results.

What to Focus On:
Monitor how AI surfaces public UGC: AI Overviews and Perplexity frequently quote Reddit threads, YouTube comments, and niche forums. Tracking when and where this happens provides insight into how informal content is influencing generative summaries.
AI engines are increasingly looking beyond corporate blogs and product pages to answer real human questions. For GEO, this means content strategy should account for where and how your audience is sharing insights.
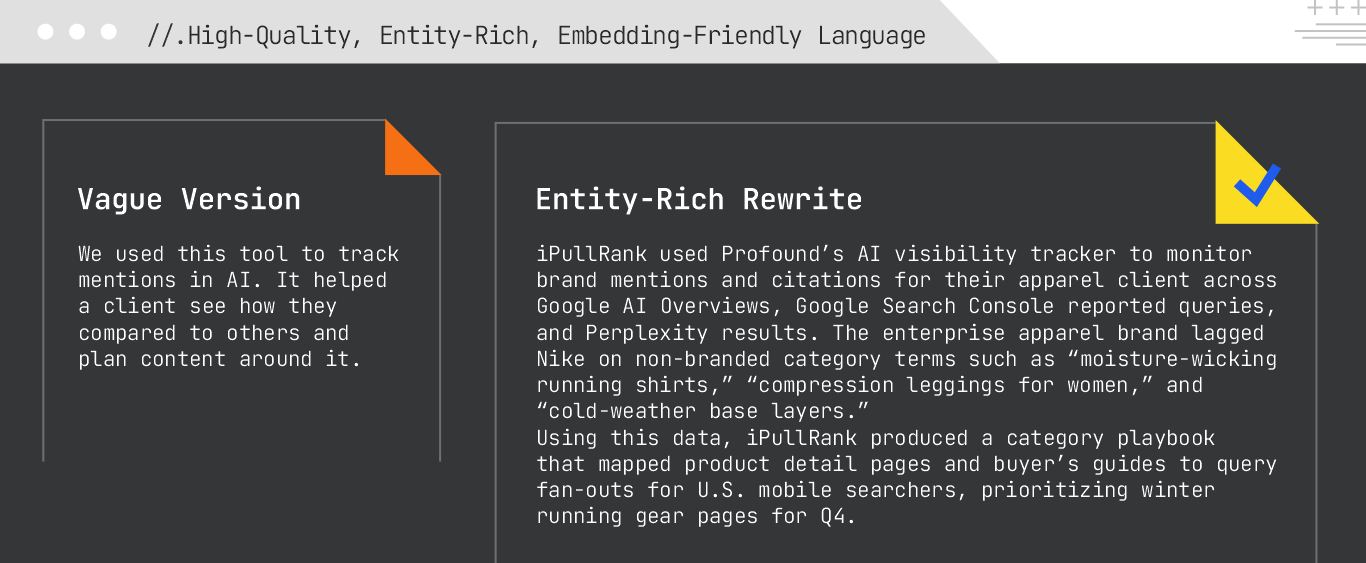
In traditional SEO, content relevance often meant placing the right keywords in the right spots. But in the context of GEO, keyword density matters less than clarity, relevance, and how well your content maps into vector space.
Generative AI systems work by encoding language into vector representations called embeddings. These embeddings capture the relationships between concepts, not just words. The clearer and more semantically rich your content, the easier it is for AI models to parse, understand, and reuse it.
What to Focus On:
Clarity fuels visibility in generative systems. Your goal is to write in a way that helps the model make accurate, meaningful associations between topics. This makes your content more retrievable and more useful as part of the AI’s response.
It doesn’t stop there, though. Considerations when creating quality content can go much deeper.
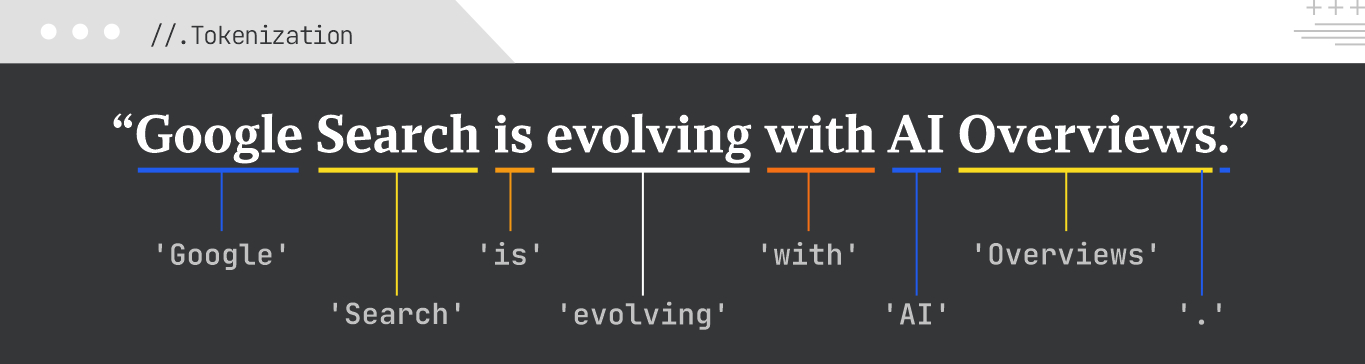
Tokenization is the process of splitting text into smaller units called tokens. These can be words, subwords, or even characters. It’s a foundational step in most natural language processing (NLP) tasks, crucial for analyzing text, calculating keyword density, and preparing input for models like BERT. Tokenization can also be used to protect sensitive data, or to process large amounts of data.
Example:
For the sentence, “Google Search is evolving with AI Overviews”, tokenization might produce the tokens “Google”; “Search”; “is”; “evolving”; “with”: “AI”: “Overviews”; and “.”
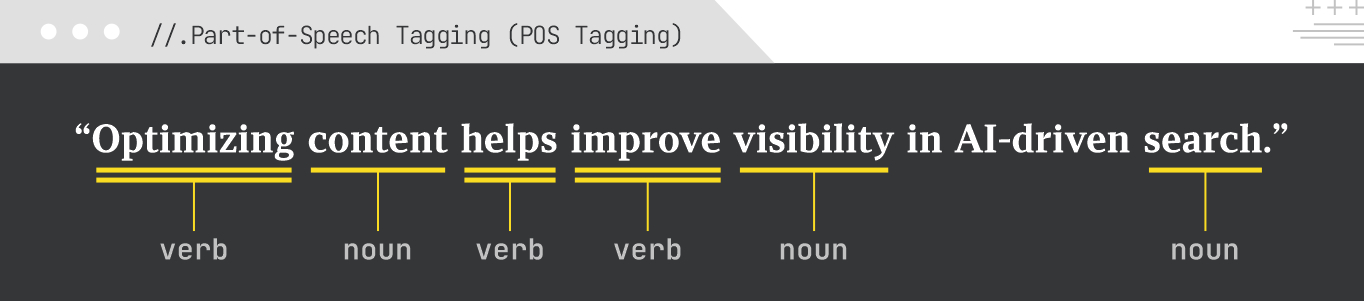
Part of Speech (POS) tagging assigns a grammatical category (e.g., noun, verb, adjective, adverb) to each word in a sentence. This helps the model with understanding the syntactic structure of the text, which is fundamental for more complex NLP tasks like dependency parsing, named entity recognition, and information extraction (which we’ll get into below).
It also works well for clarifying ambiguity in terms with numerous meanings and showing a sentence’s grammatical structure, which contributes to better semantic understanding for AI Search.
Example:
For the sentence “Optimizing content helps improve visibility in AI-driven search,” POS tagging might label “Optimizing” as a verb, “content” as a noun, “helps” as a verb, “improve” as a verb, “visibility” as a noun, and so on.
Named entity recognition (NER) is the task of identifying and classifying named entities (persons, organizations, locations, dates, etc.) in text. Crucial for semantic search, knowledge graph construction, content categorization, and understanding key concepts mentioned in a document, NER is a big part of chatbots, sentiment analysis tools, and search engines. It’s often used in industries such as healthcare, finance, human resources, customer support, and higher education.

Example:
In the sentence, “Google and OpenAI are leading companies in the AI search space,” NER would identify “Google” as an ORG (Organization) and also “OpenAI” as an ORG.
Lemmatization and stemming are both ways of reducing words to their base or root form. They help information-retrieval systems and deep learning models identify related words in tasks such as text classification, clustering, and indexing.
Lemmatization is generally preferred for semantic tasks in both SEO and AI Search because it retains meaning better, leading to more accurate keyword matching and understanding.

Example:
For the sentence “Users were searching for optimized articles regularly,”
Generative engines pull sections (a sentence, paragraph, or list) and use them to construct answers. So if your content is buried in a long-form narrative, it may be skipped. If it’s cleanly chunked and self-contained, on the other hand, it becomes far more usable.
To improve its chances of being included in generative responses, your content needs to be divided into clear, self-contained chunks, each expressing a complete idea on its own. This approach is referred to as semantic chunking.
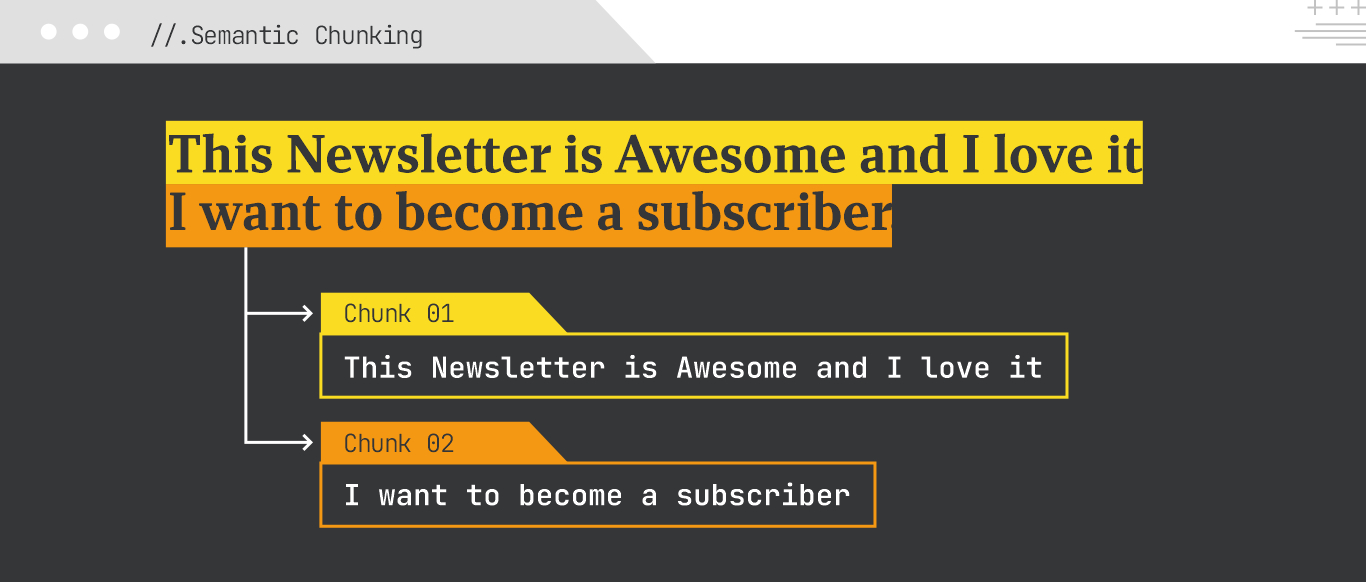
What to Focus On:
Think of every paragraph, bullet, or table row as a potential answer on its own. Semantic chunking makes your content more extractable, more quotable, and more likely to appear in summaries, featured answers, or conversational results across AI-driven platforms.
As generative engines get more sophisticated, they rely more on structured relationships between concepts. One of the most effective ways to support this is by writing in semantic triples: simple subject-predicate-object phrases that state facts clearly.
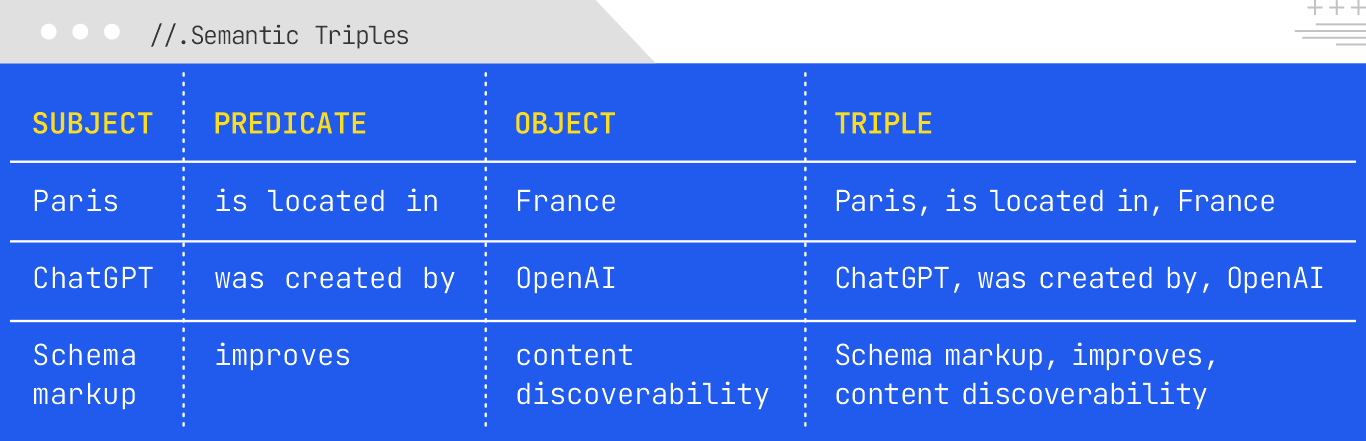
Semantic triples help search engines understand context better by identifying entities, establishing connections, and building a web of interconnected concepts, which provide richer contextual information than just keywords. These triples are the building blocks of knowledge graphs, which allow AI systems to understand relationships between entities, enabling more intelligent search results, factual verification, and structured data for AI Overviews.
What to Focus On:
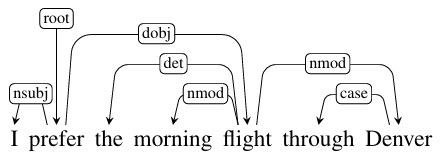
Dependency parsing analyzes the grammatical structure of a sentence by showing how words relate to each other as “heads” and “dependents.” It creates a tree-like structure, revealing the syntactic relationships between words (e.g., which word modifies which, or subject-verb relationships). For AI Search, this is crucial for understanding sentence meaning, coreference resolution, and accurate information extraction.
A dependency typically involves two words: one that acts as the head and another that acts as the child.
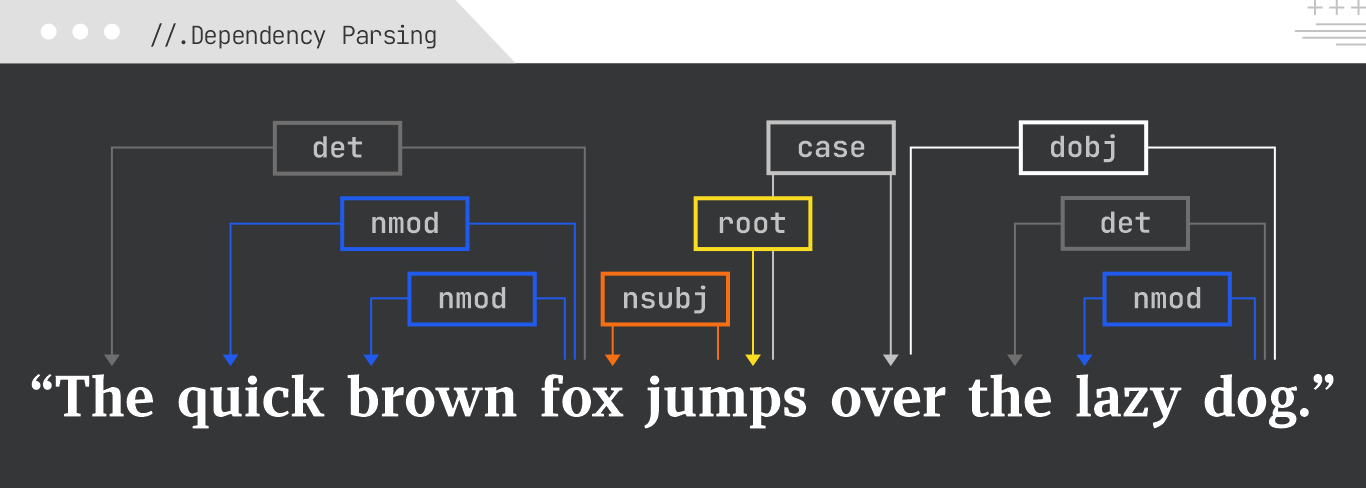
Example:
For the sentence “The quick brown fox jumps over the lazy dog,” dependency parsing would show that “quick” and “brown” modify “fox,” “jumps” is the root verb, “fox” is the subject of “jumps”, and “dog” is the object of “over.”
Daniel Jurafsky and James Martin of Stanford University created this diagram to map out the different parts of dependency parsing:
Co-reference resolution is the task of identifying all expressions that refer to the same real-world entity in a text. In “John Doe went to the store. He bought milk,” we refer to linguistic expressions like “he” or “John” or “Doe” as mentions or referring expressions, and “John Doe” as the referent. Two or more expressions that refer to the same discourse entity are said to co-refer.
Co-reference is vital for AI Search to understand the full context of a document, know who is being discussed in text, accurately summarize information, and answer complex questions in situations where pronouns or synonyms are used to refer to the same entity.

Example:
Take the text: “Google announced a new AI model. The company expects it to revolutionize search. They plan to roll it out next year.” Co-reference resolution would link “Google”; “The company”; and “They” to the same entity (Google).
Keyword extraction is an automated information-processing task that identifies the most important words or phrases in a text to provide a summary of the text. Two keyword extraction techniques include:
Both are important for understanding the main topics of a document, optimizing content for specific keywords, and informing content strategy for SEO and AI Search.

Example:
For a blog post titled “The Future of AI in SEO,” keyword extraction might identify terms like “AI”; “SEO”; “future”; “search”; “optimization”; “ranking”; etc.
Topic modeling algorithms discover abstract “topics” that occur in a collection of documents. They automatically cluster words that often occur together in the documents, with the goal of identifying groups of words and the underlying themes and topics.
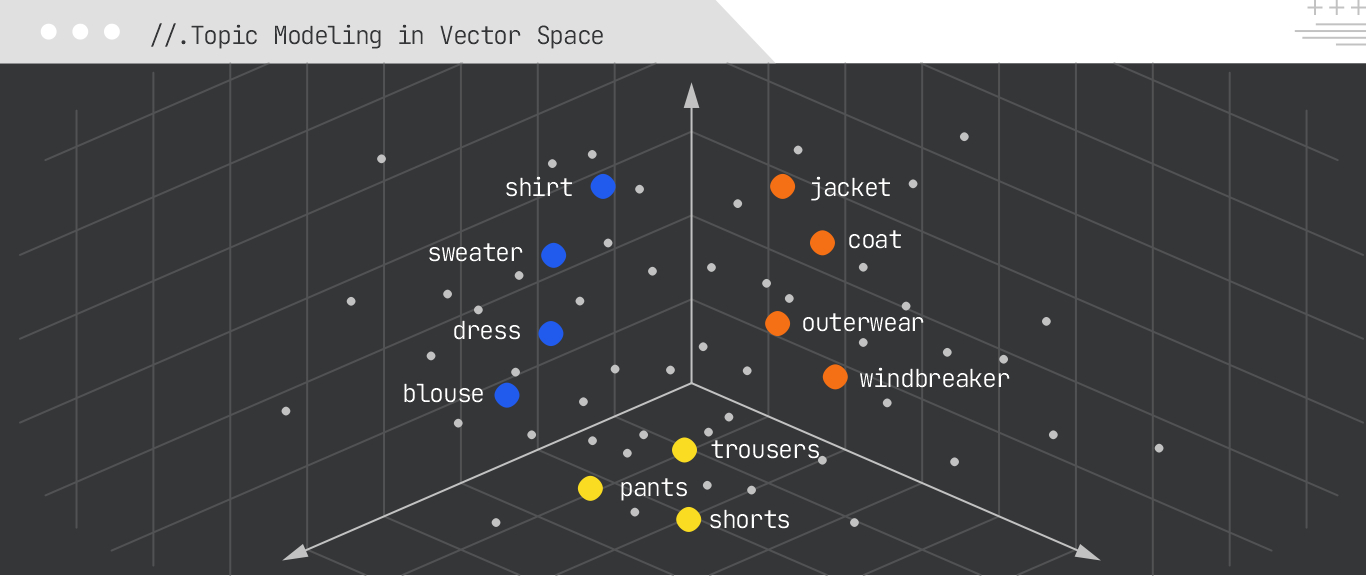
Some of the more popular models include:
Topic modeling is useful for content-gap analysis, understanding user intent across queries, grouping similar content, and informing content-cluster strategies for SEO.
Example:
Analyzing a set of SEO articles might reveal topics such as “Link Building Strategies,” “On-Page SEO Optimization,” “Technical SEO Audits,” and “Content Marketing for SEO.”
Sentiment analysis (or opinion mining) determines the emotional tone behind a piece of text, be it positive, negative, or neutral.
In SEO, sentiment analysis can be used to analyze customer reviews, social media mentions, and competitor content to gauge brand perception and identify areas for improvement. For AI Search, understanding sentiment can influence result ranking and personalized recommendations.

Example:
Here’s an example of sentiment analysis on customer reviews:
Text summarization condenses longer texts into shorter, more coherent versions. To do this, it uses two different methods:
Summarization is critical to generating AI Overviews, creating meta descriptions, summarizing long articles for quick review, and producing concise content snippets for AI Search results.
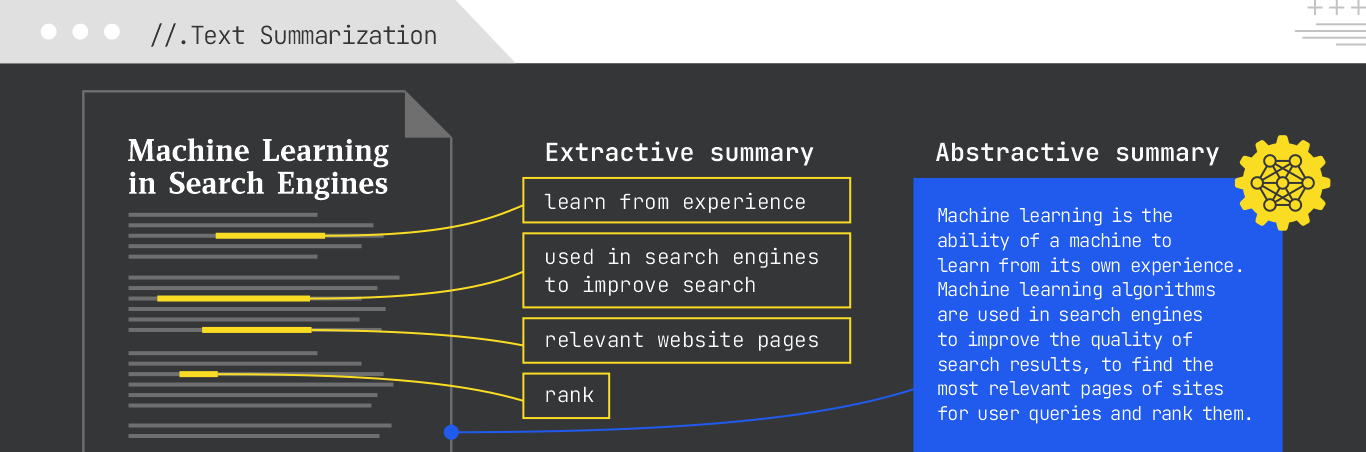
Example:
For a long article called “Machine Learning in Search Engines,” an extractive summary might pick out the main topic sentences, while an abstractive summary might synthesize a new, concise overview.
Entity linking (aka entity disambiguation) is the process of mapping named entities extracted from text to their unique, unambiguous entries in a knowledge base.
Entity linking is crucial for semantic search, as it ensures that search engines understand the exact entity a query refers to, leading to more precise results and a richer understanding of content for AI systems.

Example:
In the sentence, “Apple released a new iPhone,” “Apple” would be linked to Apple Inc. (the organization). In “I ate an apple,” “apple” would be linked to an apple (the fruit).
Text classification is the task of assigning predefined categories or labels to pieces of text, which allows computers to interpret and organize large amounts of data. It is highly versatile and can be used for:
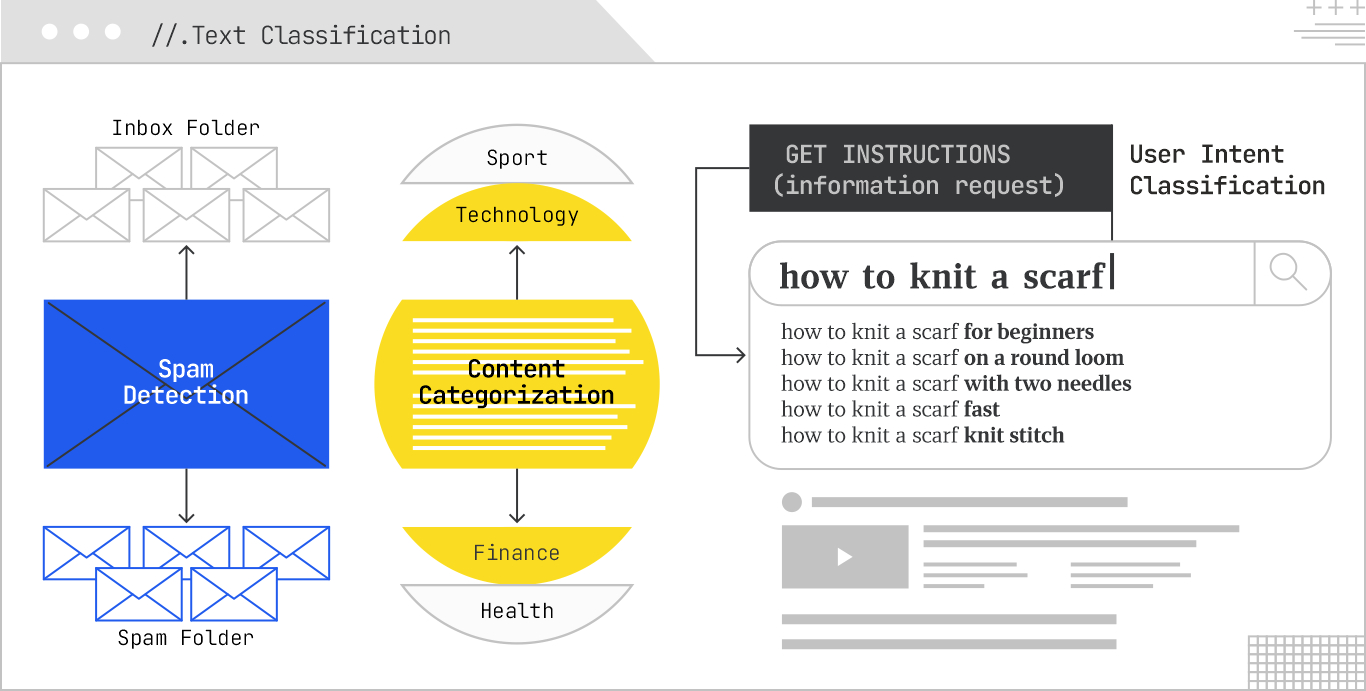
In SEO, text classification helps search categorize content for better organization, identify low-quality content, and understand the thematic relevance of pages. In AI Search, it aids in filtering irrelevant results and structuring information for better retrieval.
Example:
Word embeddings are dense vector representations of words that capture their semantic meanings. Words with similar meanings are located closer to each other in this multidimensional space, which helps with tasks such as text classification, sentiment analysis, and machine translation.
Gemini embedding, an advanced embedding model developed by Google DeepMind and built on Gemini, offers a unified approach to generate rich, context-aware embeddings for various text granularities, from words to longer phrases. It does so for text in over 250 languages and can also code.
Gemini embeddings can be used for tasks like classification, similarity search, clustering, ranking, and retrieval.
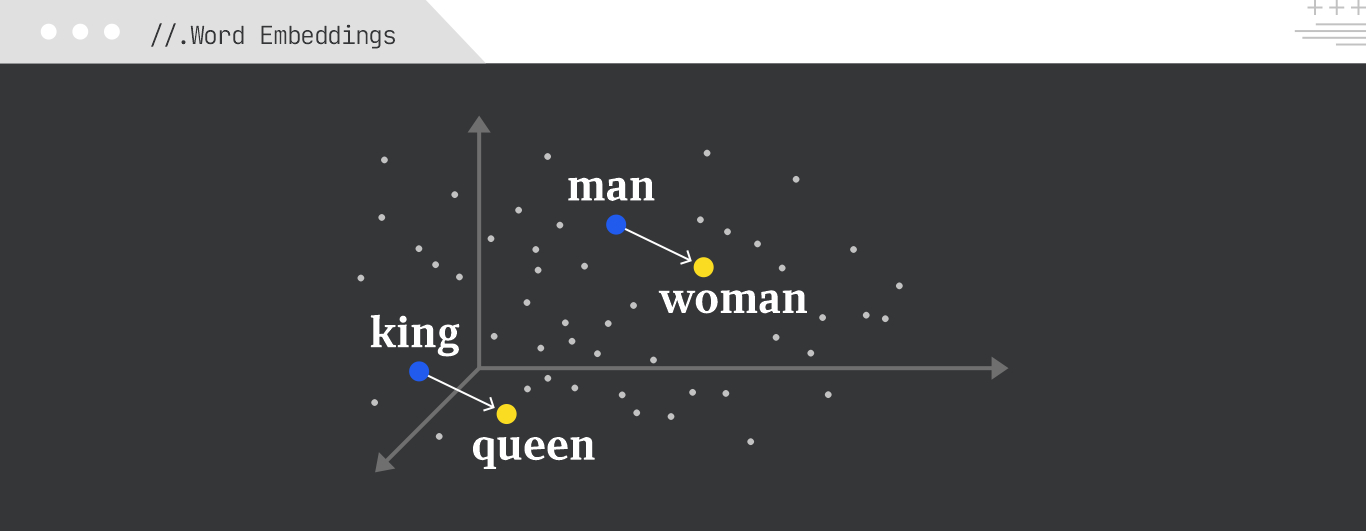
Example:
The embedding for “king” would be semantically close to “queen” and “prince,” while the vector arithmetic “king – man + woman” would be close to “queen.”
Document embeddings (or sentence embeddings) are vector representations that capture the semantic meaning of entire documents or sentences. They allow for comparing the similarity between larger chunks of text.
Three methods for generating document embeddings are:

Example:
A document embedding for an article about “sustainable energy” would be close to embeddings for other articles on renewable resources, but far from articles about “ancient Roman history.”
Plagiarism detection identifies instances where text has been copied without proper attribution. Leveraging Gemini embeddings allows for a robust semantic plagiarism check, detecting not just exact copies but also highly similar rephrased content. This is vital for maintaining content originality and avoiding search engine penalties.
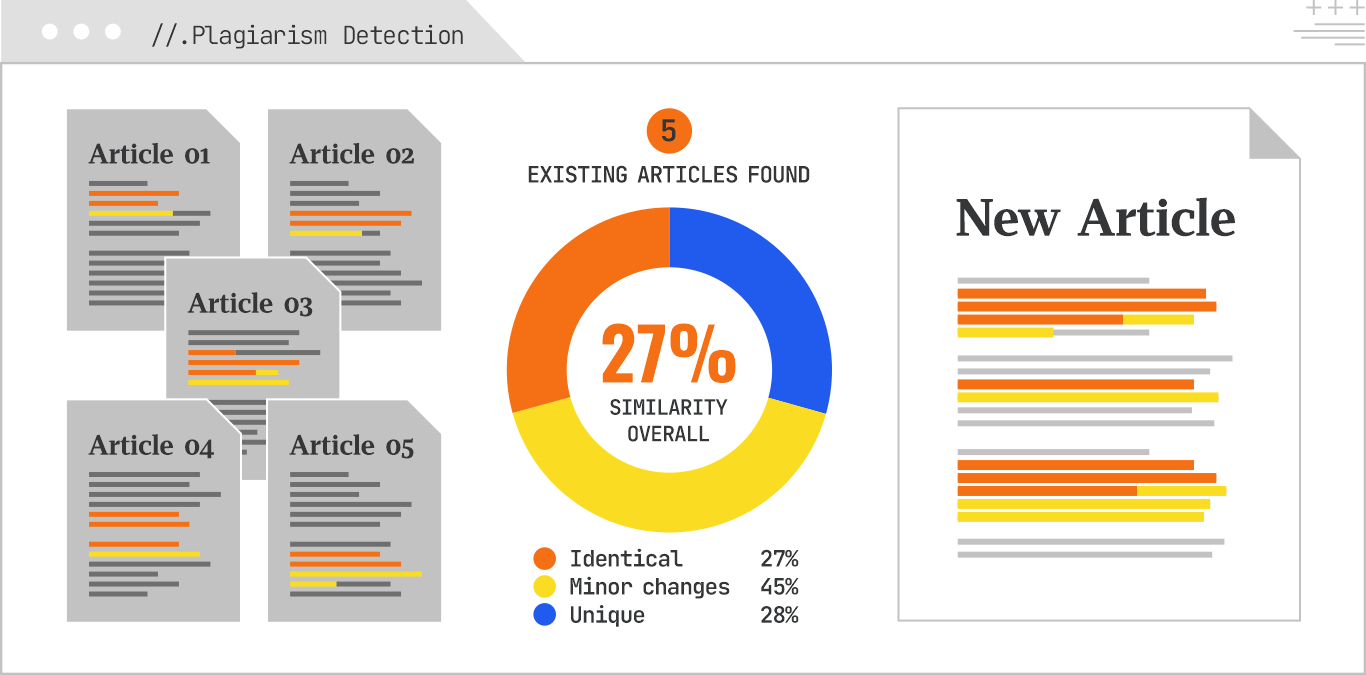
Example:
Comparing a newly generated article against a corpus of existing articles to detect copied phrases or paragraphs based on semantic closeness.
Anomaly detection identifies unusual patterns or outliers in data. In NLP for SEO, this can be applied to content quality by detecting:

This helps with proactive identification of potential content issues that could impact SEO performance or indicate a need for review, such as errors, unusual events, or potential fraud.
Example:
A sudden spike in the use of a seemingly irrelevant keyword across multiple articles, or a review with an extreme sentiment score compared to others.
Readability scoring assesses how easy it is to read and understand a text. In SEO, optimizing for readability improves user experience, reduces bounce rates, and makes content more accessible, all of which indirectly signals quality to search engines and is a direct factor for AI Overviews.
Readability tests include:
All of these metrics consider factors such as sentence length, word length, and syllable count to determine the approximate reading level of a text or how many years of education a person would need to understand it.

Example:
A complex academic paper would have a low readability score, while a simple blog post would have a high one.
Semantic search understands the meaning and intent behind a query, moving beyond keyword matching. It uses powerful embeddings like Gemini’s to find documents that are semantically similar to the query, even if exact keywords are absent. This is the cornerstone of modern AI-powered search engines, delivering more relevant and nuanced results.

Example:
A search for “sustainable energy sources” might return results about “renewable power,” “solar panels,” or “wind farms,” even if the exact phrase “sustainable energy sources” isn’t present in the documents.
There is no one-size-fits-all formula for visibility in AI Search, but the patterns are becoming clear. Structured data, semantic clarity, specific language, and technical accessibility all play a role in how content is evaluated and used by AI systems, which are trained to understand not just words but meaning, context, and usefulness.
GEO sits at the intersection of technical SEO, content strategy, and NLP. Getting it right means knowing how models interpret the web and giving them content they can trust, extract, and reuse.
Creating this content requires a focus on relevance. Engineering the most relevant content for visibility involves looking at semantic scoring, optimizing passages, and testing vector embeddings. In the next chapter, we’ll look more deeply at the process of Relevance Engineering.
If your brand isn’t being retrieved, synthesized, and cited in AI Overviews, AI Mode, ChatGPT, or Perplexity, you’re missing from the decisions that matter. Relevance Engineering structures content for clarity, optimizes for retrieval, and measures real impact. Content Resonance turns that visibility into lasting connection.
Schedule a call with iPullRank to own the conversations that drive your market.
The appendix includes everything you need to operationalize the ideas in this manual, downloadable tools, reporting templates, and prompt recipes for GEO testing. You’ll also find a glossary that breaks down technical terms and concepts to keep your team aligned. Use this section as your implementation hub.
//.eBook

The AI Search Manual is your operating manual for being seen in the next iteration of Organic Search where answers are generated, not linked.
Prefer to read in chunks? We’ll send the AI Search Manual as an email series—complete with extra commentary, fresh examples, and early access to new tools. Stay sharp and stay ahead, one email at a time.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.
We’ll break it up and send it straight to your inbox along with all of the great insights, real-world examples, and early access to new tools we’re testing. It’s the easiest way to keep up without blocking off your whole afternoon.





