
Want a different perspective? These links open AI Search platforms with a prompt to explore this topic, how it works in AI Search, and how iPullRank approaches it.
*These buttons will open a third-party AI Search platform and submit a pre-written prompt. Results are generated by the platform and may vary.
The earliest search engines weren’t built to understand meaning. They were built to match strings. In the 1960s and ’70s, systems like SMART at Cornell University established the core architecture that would dominate information retrieval (IR) for the next four decades: the inverted index.
If you’ve never seen one in action, picture the index at the back of a reference book. Every term has a list of page numbers on which it appears. In IR, those “pages” are documents, and the “page numbers” are “postings lists,” or ordered references to every document that contains the term.
The workflow was simple: Tokenize the text into words, stem them to a base form, and store their locations. When a query came in, it would break it into tokens, look up each one’s postings list, and merge those lists to find documents containing all or most of the terms. Then it would rank the results according to statistical measures like TF-IDF (Term Frequency–Inverse Document Frequency), and later BM25 (Best Matching 25).
This was a purely lexical process. If you searched for “automobile,” you’d never see a page that only said “car” unless someone had hard-coded that synonym into the system. If you typed “running shoes,” you might miss “sneakers” unless they were indexed under the same term.
For SEO’s first two decades, this mechanical literalism shaped everything. Pages were engineered to match keywords exactly, because the search system couldn’t reliably connect related terms on its own. The discipline’s core tactics (keyword research, exact-match targeting, keyword-density optimization) were direct responses to these limitations. You were speaking to the index in its own primitive language.
Attempts to transcend this began in the 1990s with latent semantic indexing (LSI), which tried to infer relationships between terms by decomposing the term-document matrix into latent factors using singular value decomposition. In theory, it could connect “automobile” and “car” without explicit synonyms. In practice, it was computationally expensive, sensitive to noise, and not easily updated as new content arrived. It was a clever patch on lexical retrieval, but not a fundamental shift.
By the time early web search engines like AltaVista, Lycos, and Yahoo were indexing hundreds of millions of pages, lexical matching was straining under the weight of vocabulary variation and polysemy (words with multiple meanings). Google’s PageRank helped filter results by authority, but it didn’t solve the underlying semantic gap. The system could tell which pages were most linked, but not which ones best matched the meaning of your query.

By the early 2010s, the sheer scale and diversity of the web, combined with advances in machine learning, set the stage for a more meaning-aware approach to retrieval. The breakthrough came from a deceptively simple idea in computational linguistics: the distributional hypothesis. As British linguist J. R. Firth famously put it, “You shall know a word by the company it keeps.”
The insight was that instead of treating words as discrete symbols, you could represent them as points in a continuous vector space, where proximity reflected similarity of meaning. The closer two words were in this space, the more likely they were to be used in similar contexts. This leap from symbolic matching to geometric reasoning was the conceptual foundation for embeddings.
In 2013, Tomas Mikolov, Jeff Dean (the Chuck Norris of computer science), and their colleagues at Google released Word2Vec, a pair of neural architectures — Continuous Bag of Words (CBOW) and Skip-gram — that could learn these vector representations from massive bodies of text. CBOW predicted a target word from its surrounding context; Skip-gram did the reverse, predicting context words from a target. Both trained a shallow neural network, whose hidden layer weights became the embedding matrix.
The results were staggering. Not only could Word2Vec cluster synonyms together, it captured analogical relationships through vector arithmetic. The famous example:
vector(“king”) – vector(“man”) + vector(“woman”) ≈ vector(“queen”)
These weren’t hard-coded rules; they emerged naturally from co-occurrence patterns in the data. For the first time, machines had a numerical, manipulable representation of meaning that was portable across tasks.
Retrieval systems began to adopt embeddings in two ways:
The next evolution was scaling this from words to larger units. Paragraph Vector (Doc2Vec) extended embeddings to entire documents. Universal Sentence Encoder (USE) and later Sentence-BERT (SBERT) refined the process to produce high-quality embeddings for sentences and paragraphs, optimized for semantic similarity. This made it possible to embed every document in an index into a fixed-length vector and perform nearest-neighbor search directly on meanings, not just matching terms.
At Google, Bing, and elsewhere, dense embeddings began to appear first in reranking stages. A lexical engine would retrieve a candidate set of documents (e.g., top 1,000 by BM25), and then a neural model would rescore them based on semantic similarity. This hybrid approach kept the efficiency of inverted indexes while benefiting from the semantic reach of embeddings.
From an optimization standpoint, this was a tectonic shift. Suddenly, you could be retrieved for queries that never mentioned your exact keywords, as long as your content meant the same thing. But it also meant that keyword stuffing lost much of its mechanical advantage. The battlefront was moving from term matching to meaning matching.
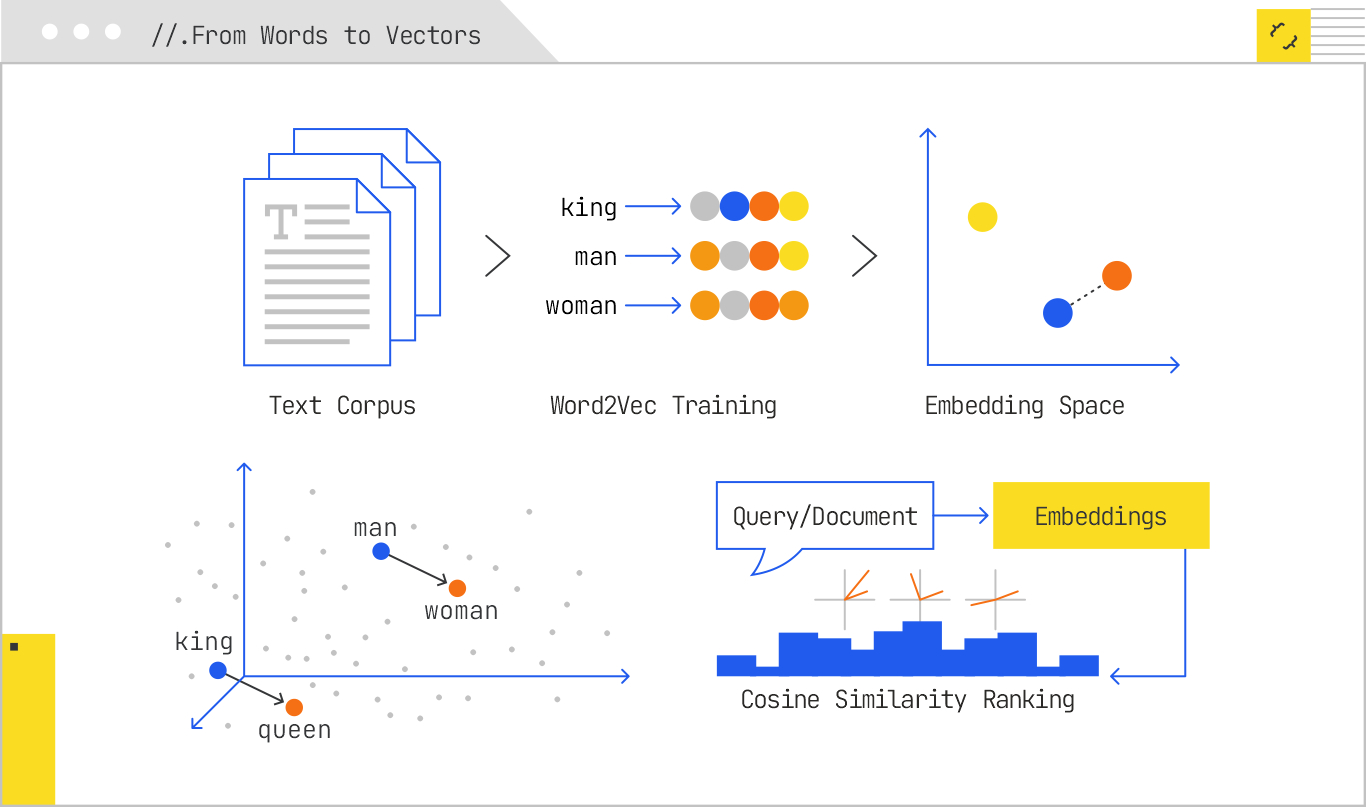
By the mid-2010s, Google had already moved far beyond using embeddings solely for words or documents. If Word2Vec and its successors gave us a way to represent meaning numerically, Google’s next leap was to embed everything it cared about in the search ecosystem. The goal wasn’t just to improve retrieval. It was to create a unified semantic framework where any object — a website, an author, an entity, a user profile — could be compared to any other in the same high-dimensional space.
This is one of the least talked-about yet most consequential shifts in modern search. Because once you can represent anything as a vector, you can measure relationships that are invisible in lexical space.
Entire websites and subdomains are now represented as domain-level embeddings that capture their topical footprint and authority. Instead of just analyzing what a site ranks for today, Google can embed the aggregate content and link patterns over time. For example, a site consistently publishing in-depth reviews of trail-running gear will develop a dense cluster in the “endurance sports equipment” region of vector space.
Then, when a new query comes in, the retrieval system doesn’t just look for pages that match — it can bias toward domains whose embeddings sit near the query’s embedding. This is part of how topical authority operates behind the curtain. Even if your specific page has limited lexical matches, the domain’s “semantic reputation” can pull it into the candidate set.
From a GEO perspective, this reinforces why topical clustering and content depth matter. You’re not just building pages; you’re training your domain embedding to occupy the right part of the space.
Google also builds embeddings for individual authors, fueled by bylines, linking, structured data, and cross-site publishing patterns. These vectors encode both topical expertise and reliability signals. An author consistently cited for “sports medicine” in reputable contexts will have an embedding tightly clustered around that domain, and Google can use that to boost or suppress their content depending on query intent.
This connects directly to “E-E-A-T” (Experience, Expertise, Authoritativeness, Trustworthiness) — not as a checklist, but as a vector profile that can be matched to relevant topics. It’s also why authorship consistency, structured author pages, and cross-site credibility are increasingly important for generative inclusion.
Every entity in Google’s Knowledge Graph (people, places, organizations, concepts) has an embedding. These vectors are grounded in multilingual and multimodal data, allowing Google to connect “Eiffel Tower” not just to “Paris” and “Gustave Eiffel” but also to similar structures, architectural styles, and historical events.
This demonstrates entity-based search at full power: the ability to reason about relationships without depending on shared language or surface form. If a query in Japanese references “鉄の塔” (iron tower), Google can still connect it to Eiffel Tower–related documents in English, French, or any other language.
For GEO, this means your entity coverage, schema markup, and linkage to authoritative nodes in the Knowledge Graph directly affect how you’re embedded and retrieved.
Perhaps the most powerful and opaque embeddings in Google’s arsenal are those representing users. Built from years of search history, click patterns, dwell time, device usage, location traces, and interaction across Google services, these vectors are a behavioral fingerprint.
When a user searches for “jaguar,” the system doesn’t just look at the query embedding. It also considers the user embedding, which may indicate a preference for luxury cars, wildlife documentaries, or even sports teams. The retrieval process can then rerank candidates to reflect the personalized intent.
And while these embeddings are invisible to us as SEOs, they matter in GEO, because they dictate that no two users are truly seeing the same generative output. Content must not only match the general query space, it must be robust enough to offer contextual utility for a variety of user embeddings.

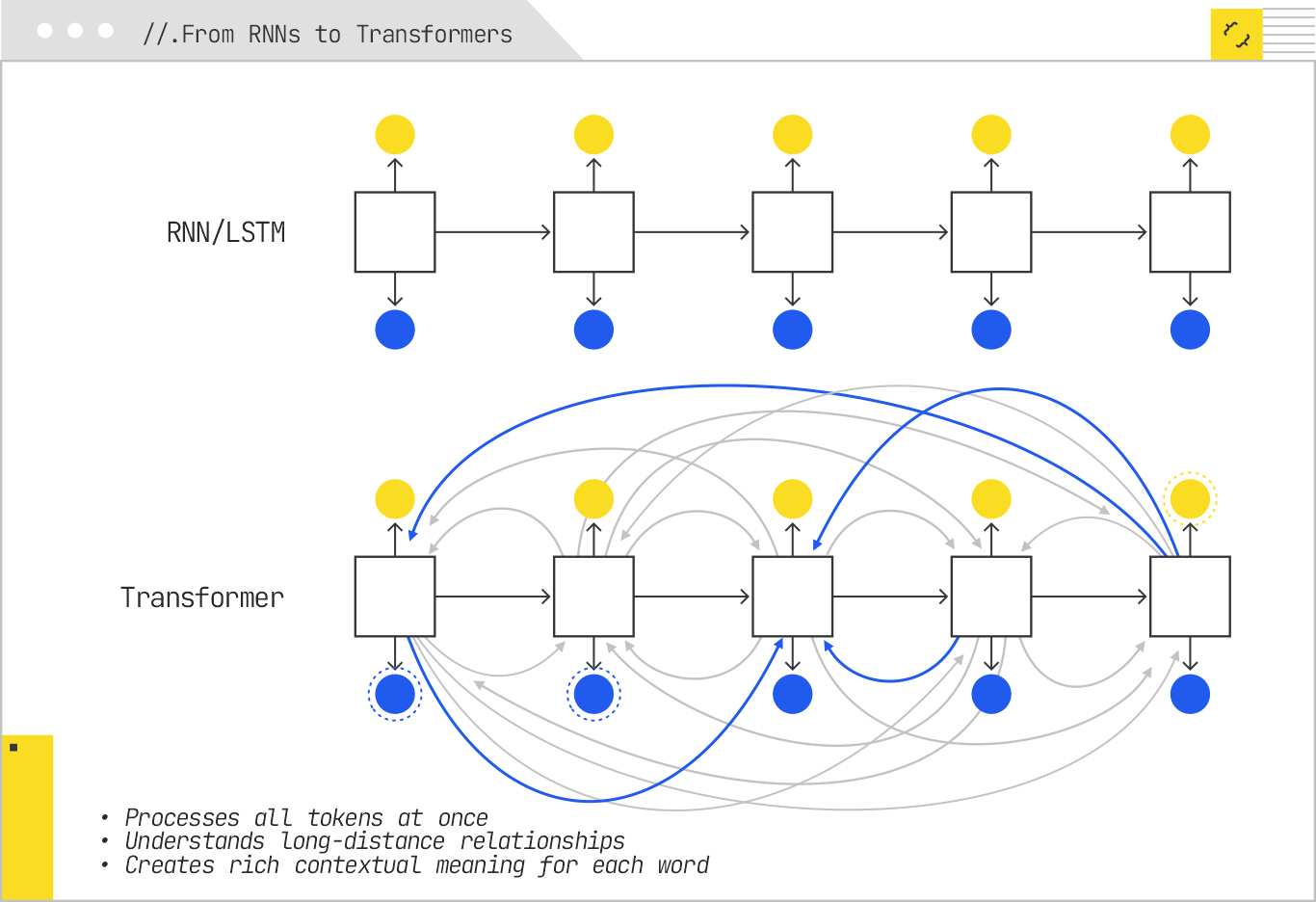
Up until 2017, even with the gains from embeddings, retrieval systems still relied on models with significant architectural constraints. Sequence modeling was handled by recurrent neural networks (RNNs) and their improved variants, long short-term memory networks (LSTMs) and gated recurrent units (GRUs). These architectures processed input tokens one step at a time, passing a hidden state forward. That made them naturally suited for sequences, but also inherently sequential in computation — limiting parallelism and slowing training on large datasets.
RNNs also had trouble maintaining context over long spans. Even with LSTMs’ gating mechanisms, meaning could “drift” as distance from the relevant token increased. This created bottlenecks for tasks like passage retrieval, where a single relevant detail might be buried deep in a thousand-word document.
The breakthrough came in June 2017, when Vaswani et al. published “Attention Is All You Need.” This paper introduced the Transformer architecture, which replaced recurrence entirely with a mechanism called self-attention. Instead of processing one token at a time, this allowed every token to directly “look at” every other token in the sequence and decide which were most relevant for interpreting its meaning.
In Transformer, each token is represented as a vector, and self-attention calculates attention weights — essentially, scores indicating how much one token should influence another. These weights are used to create context-aware representations at every layer. Crucially, the architecture is fully parallelizable, enabling massive speed gains and making it feasible to train on enormous corpora.
For IR, self-attention was revolutionary. It meant that query and document representations could capture long-range dependencies and subtle relationships without losing information over distance. Transformer could understand that “the fastest animal on land” refers to “cheetah,” even if “cheetah” appeared in the last sentence of a long paragraph.
The most direct search application of transformers arrived in late 2018 with Google’s integration of BERT (Bidirectional Encoder Representations from Transformers), which trained Transformer bidirectionally, meaning it considered the full left and right context for every token simultaneously. The embeddings it produced were contextual. For example, the vector for “bank” in “river bank” was entirely different from “bank” in “bank account.”
In Google Search, BERT was first deployed to improve passage-level understanding, allowing the engine to retrieve and highlight relevant snippets even if the exact query terms didn’t appear together in the same sentence. This effectively narrowed the semantic gap even further than Word2Vec-era embeddings. Queries that had once returned tangential matches could now surface more directly relevant results, because the model was better at understanding intent in full context.
BERT also changed ranking pipelines. Instead of relying solely on static document embeddings, Google could re-encode a query and candidate document together to assess semantic fit, allowing for more nuanced reranking in real time.
While BERT dominated the retrieval-focused world, the GPT family (Generative Pretrained Transformers) showed the other side of the Transformer coin: generation. Instead of using masked language modeling like BERT’s, GPT was trained autoregressively, predicting the next token given all previous ones. This made it exceptionally good at producing coherent, contextually relevant text at scale.
The GPT approach has since merged with retrieval through retrieval-augmented generation (RAG), in which a retriever model surfaces relevant passages and a generator model then synthesizes them into a natural-language answer. In generative search systems, these two components, retrieval and generation, are increasingly powered by Transformers, often trained or fine-tuned in tandem.
By 2021, Google had already integrated Transformers like BERT into search for context-sensitive retrieval. But the next major leap wouldn’t be just about understanding text better — it was about understanding information in any format, across any language, and connecting it into one reasoning process.
That leap was announced at Google I/O 2021 as the Multitask Unified Model (MUM). Google positioned MUM as being a thousand times more powerful than BERT, but the raw number wasn’t the real story. That was its scope: MUM is multimodal, multitasking, and multilingual by design.
Traditional IR pipelines treated each modality (text, images, audio, video) as separate silos, each with its own specialized retrieval system. MUM collapses those walls by training on multiple modalities simultaneously. In practice, this means the same underlying model can process a question about hiking Mount Fuji that contains both text (“What do I need to prepare for hiking Mount Fuji in autumn?”) and an image (a photo of your hiking boots).
MUM can retrieve relevant results from textual travel blogs, gear-review videos, photographic trail maps, even audio interviews — and then reason across them to form an answer. This is possible because the model learns a shared embedding space where content from different modalities can be directly compared. So a video segment showing how to tie crampons can sit next to a textual description of the process in the same vector neighborhood.
For GEO, this is critical: If you’re only thinking about text, you’re leaving entire retrieval channels untapped. Image alt text, structured video transcripts, and audio indexing metadata are now also first-class citizens in generative inclusion.
The “multitask” part of MUM means it can simultaneously handle retrieval, classification, summarization, translation, and reasoning in one unified process.
For example, if you ask “Compare trail conditions on Mount Fuji in October to Mount Rainier in May,” MUM can:
Previously, these steps might have required multiple discrete systems with handoff points between them. Now they can happen within a single Transformer model, reducing latency and increasing coherence in the final output.
MUM is trained across 75+ languages, enabling cross-lingual retrieval in situations when query and content languages don’t match. This allows the model to access high-quality sources without regard to language barriers, dramatically expanding the evidence pool for generative answers.
For example, an English-language search about hiking in the Dolomites could retrieve and translate a recent Italian mountain-guide review that hasn’t been covered in English media yet. From a GEO standpoint, this means content in any language can become a competitive threat — or asset — in global retrieval.
While MUM represents Google’s leap toward multimodal, multitask reasoning, MUVERA (launched in 2025) addresses a different but equally crucial challenge in modern retrieval: scaling multivector search architecture without sacrificing performance.
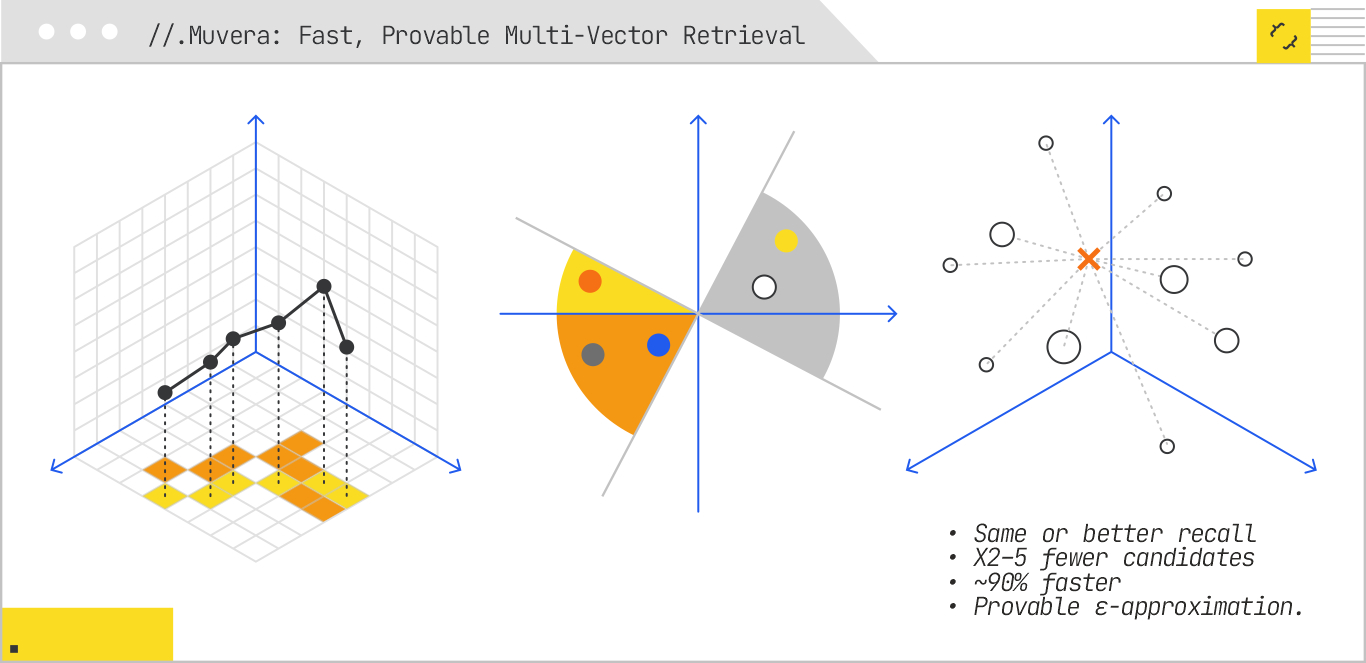
Multivector models such as ColBERT represent each query or document using multiple embeddings, typically one per token. They compute relevance via Chamfer similarity, which measures how each token in the query aligns with its closest token in the document. This method yields more nuanced retrieval decisions, especially for long-form or heterogeneous content, but at tremendous computational cost, especially during large-scale indexing and retrieval.
MUVERA introduces a clever solution: it transforms each set of embeddings (for both document and query) into a single fixed-dimensional encoding (FDE). FDEs are compact vectors that approximate multi-vector similarity with mathematical guarantees, enabling retrieval via existing maximum inner product search (MIPS) systems.
At a high level, this work achieves:
The process is elegantly simple: Multivector representations are transformed into FDEs via a data-oblivious partitioning method; a standard MIPS engine is used to quickly retrieve an approximate candidate set; and then, only for that small set, the exact Chamfer similarity is computed for final ranking. This hybrid approach delivers both scale and precision.
In the neural IR era, embeddings are the substrate for everything: retrieval, ranking, personalization, synthesis, and safety checks. They enable direct comparison across modalities and languages, collapsing the silos that lexical search could never bridge.
The GEO mindset shift is clear: success is about occupying the right neighborhoods in embedding space. That means consistently producing content across text, media, and entities that aligns semantically with the intent clusters you want to dominate.
If the evolution from lexical indexes to neural embeddings was about teaching machines to understand language, then the rise of generative search is about teaching them to speak it back to us fluently, persuasively, and in ways that reshape how visibility is won or lost.
We’ve moved from matching keywords, to matching meanings, to negotiating with systems that both retrieve and synthesize information in real time. In this new paradigm, the retrieval layer isn’t just a precursor to ranking — it’s an active gatekeeper deciding which fragments of your content, if any, make it into an AI’s composite answer.
Having explored how embeddings, transformers, and multimodal reasoning have redefined the mechanics of search, the next challenge for GEO practitioners is learning how to measure, map, and influence where and how their content appears inside generative outputs. Unlike the familiar blue-link SERP, these systems don’t provide a stable set of ten results and a visible rank position. They operate more like selective editors, weaving together pieces of multiple sources while discarding most of what they see.
Our focus now turns to the strategies, tools, and analytical frameworks required to track AI Search visibility. Chapter 7 will begin by dissecting the platforms themselves, from AI Overview and ChatGPT to emergent challengers like Perplexity and Copilot. We’ll look at how they each source and attribute content, what their transparency (or opacity) means for measurement, and where the opportunities lie for shaping your presence in their answers.
In short, if this chapter was the blueprint of the machine, the next will be about learning how to read the machine’s output in a way that informs and amplifies your GEO strategy.
If your brand isn’t being retrieved, synthesized, and cited in AI Overviews, AI Mode, ChatGPT, or Perplexity, you’re missing from the decisions that matter. Relevance Engineering structures content for clarity, optimizes for retrieval, and measures real impact. Content Resonance turns that visibility into lasting connection.
Schedule a call with iPullRank to own the conversations that drive your market.
The appendix includes everything you need to operationalize the ideas in this manual, downloadable tools, reporting templates, and prompt recipes for GEO testing. You’ll also find a glossary that breaks down technical terms and concepts to keep your team aligned. Use this section as your implementation hub.
//.eBook

The AI Search Manual is your operating manual for being seen in the next iteration of Organic Search where answers are generated, not linked.
Prefer to read in chunks? We’ll send the AI Search Manual as an email series—complete with extra commentary, fresh examples, and early access to new tools. Stay sharp and stay ahead, one email at a time.
Sign up for the Rank Report — the weekly iPullRank newsletter. We unpack industry news, updates, and best practices in the world of SEO, content, and generative AI.
iPullRank is a pioneering content marketing and enterprise SEO agency leading the way in Relevance Engineering, Audience-Focused SEO, and Content Strategy. People-first in our approach, we’ve delivered $4B+ in organic search results for our clients.
We’ll break it up and send it straight to your inbox along with all of the great insights, real-world examples, and early access to new tools we’re testing. It’s the easiest way to keep up without blocking off your whole afternoon.





